【LLMs篇】02:国产之光DeepSeek
2025年春节前后,一个“来自东方的神秘力量”引发全球资本市场和AI圈震荡。DeepSeek,让英伟达股价下跌16.97%,市值一日内蒸发近6000亿美元,创美国历史上任何一家公司的单日最大市值损失。此外,人工智能领域的衍生品,比如电力供应商也受到重创,美国联合能源公司股价下跌21%,Vistra的股价下跌29%。DeepSeek的最新突破,动摇了美国科技行业的地位,引发全球关注。从下载量来看,根
2025年春节前后,一个“来自东方的神秘力量”引发全球资本市场和AI圈震荡。
DeepSeek,让英伟达股价下跌16.97%,市值一日内蒸发近6000亿美元,创美国历史上任何一家公司的单日最大市值损失。此外,人工智能领域的衍生品,比如电力供应商也受到重创,美国联合能源公司股价下跌21%,Vistra的股价下跌29%。DeepSeek的最新突破,动摇了美国科技行业的地位,引发全球关注。
从下载量来看,根据AI产品榜数据显示,DeepSeek成为全球增速最快AI应用,上线20天日活突破2000万。
根据Appfigures的数据显示(不包括中国的第三方应用商店),DeepSeek App于1月26日登上苹果App Store全球下载榜榜首。
根据Sensor Tower的研究,该应用在谷歌Play商店美国区下载排行榜中位居榜首。Sensor Tower数据显示,DeepSeek在发布的前18天内累计下载量达1600万次。
DeepSeek是搅动全球模型市场的一条鲶鱼,带来了性能、价格、开源三重冲击。
性能比肩国际顶尖模型:DeepSeek R1在数学、代码、自然语言推理等任务上的性能可比肩OpenAI o1模型正式版。在AIME2024数学基准测试中,DeepSeek R1得分率为79.8%,OpenAI o1的得分率为79.2%;在MATH-500基准测试中,DeepSeek R1得分率为97.3%,OpenAI o1的得分率为96.4%。
低成本颠覆市场格局:DeepSeek V3整个训练过程仅用了不到280万个GPU小时,相比之下,Llama3405B的训练时长是3080万GPU小时。DeepSeek V3的训练成本仅为约557.6万美元,而GPT-4等模型的训练成本则高达数亿美元。DeepSeek API服务定价远低于OpenAI,以输出为例,每百万输出tokens16元(约2.2美元),GPT o1每百万输出tokens60美元。
践行开源理念:DeepSeek V3和推理模型DeepSeek R1均开源,R1同步开源了其模型权重,并允许用户利用模型输出,通过模型蒸馏等方式训练其他模型。
1. DeepSeek
DeepSeek成立于2023年7月,由知名量化资管巨头幻方量化创立,梁文锋是DeepSeek的创始人,他从始至终都表明“这一波浪潮里,我们的出发点,就不是趁机赚一笔,而是走到技术的前沿,去推动整个生态发展。”
一年多,模型已然迭代多个版本,目前模型能力可比肩OpenAI o1-mini。
2. 创新之处
DeepSeek最强大的地方在于降低了行业成本,另外,对国内大模型来说,更适合中国企业的口味。
首先,DeepSeek在算法上进行了相应的优化,使得训练成本大幅降低。以前如果说OpenAI是“大力出奇迹”,如今DeepSeek则是“小力也可以出奇迹”——小的算力用新的方法也能创造奇迹。其新模型DeepSeek R1以十分之一的成本达到了GPT o1级别的表现。
DeepSeek V3算力成本降低的原因有两点。
-
第一,DeepSeek V3采用的DeepSeek MoE是通过参考了各类训练方法后优化得到的,避开了行业内AI大模型训练过程中的各类问题。
-
第二,DeepSeek V3采用的MLA架构可以降低推理过程中的kv缓存开销,其训练方法在特定方向的选择也使得其算力成本有所降低。
其次,DeepSeek在AI Agent的生产环节中,中文能力显著更强。DeepSeek-V3与Qwen2.5-72B(通义千问)在教育类测评C-Eval和代词消歧等评测集上表现相近,但在事实知识C-SimpleQA上更为领先。
具体来看,DeepSeek在成语、古文和专业术语的理解上进行了专项优化,让它更适合中文用户的使用需求。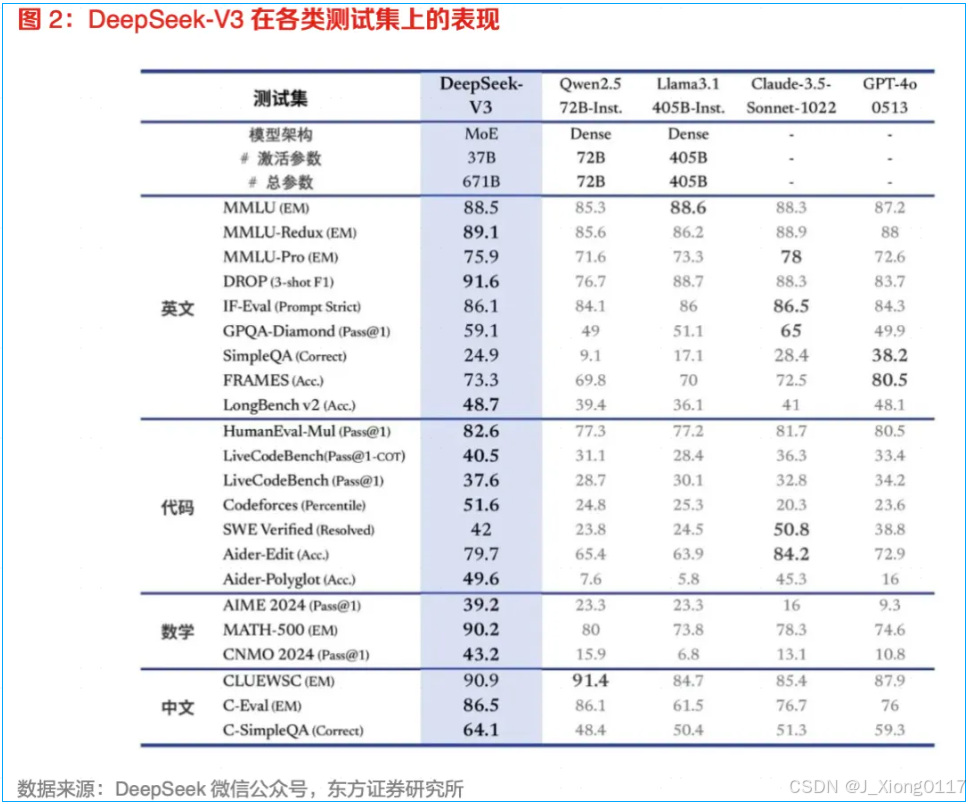
3. 模型详解
3.1 DeepSeek V1
DeepSeek V1是2024年1月份发布的第一版DeepSeek模型,包含DeepSeek的核心构建方式,核心技术点分为数据端、模型端、优化端、对齐4个部分,前面3个部分处于模型的预训练阶段,对齐阶段使用SFT进行人类风格对齐。
数据端:在数据的处理上,包括去重、过滤、混合3个步骤,目的是构建一个多样性强、纯净的高质量预训练数据。在去重阶段,对于Common Crawl数据集进行全局的去重过滤,可以提升去重比例。在过滤阶段,构建了一套详细的包括文法语法分析在内的评估流程,去除低质量数据。在混合阶段,对不同domain的数据进行采样,平衡不同domain数据量,让数据量较少的domain也能有足够的样本占比,提升数据集多样性和全面性。
此外,在数据处理方面,使用Byte-level Byte-Pair Encoding (BBPE)作为tokenizer,相比BPE是在字符粒度进行字符串分割,BBPE在字节粒度进行处理,整体算法逻辑和BPE类似。
整体参与预训练的token数量为2 trillion。在V2和V3中,训练的token数量不断上升,V2为8 trillion,V3为14 trillion。
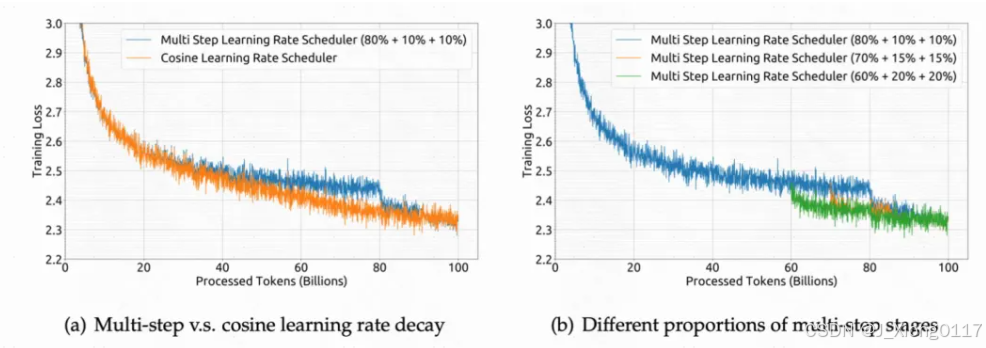
模型端:模型的主体结构基本沿用LLaMA。LLaMA主体就是Transformer结构,主要差异包括RMSNorm的Pre-normalization(每层Transformer输入使用RMSNorm进行归一化)、激活函数采用SwiGLU、位置编码采用Rotary Embeddings。模型包括7B和67B两种尺寸,67B尺寸的Transformer中的attention采用了Grouped Query Attention代替最普通的self-attention降低inference开销。Grouped Query Attention每组query共用同一组key和value。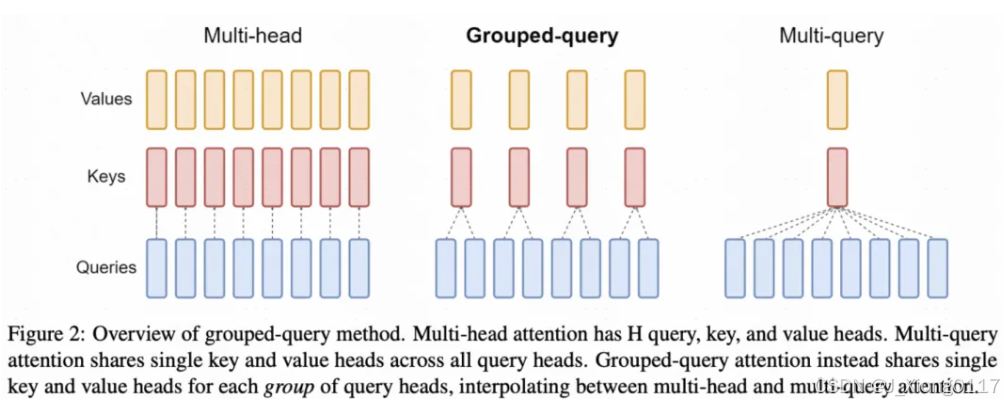 优化端:使用multi-step learning rate代替LLaMA中的cosine learning rate schedule,主要原因是实验发现两者虽然最终收敛到的loss差不多,但是前者在连续学习上loss能够保证一致性,连续学习更加方便。先用2000个step的warmup将学习率提升到最大值,然后在训练完80%的训练数据后将学习率降低到31.6%,在训练完90%的训练数据后进一步降低到10%。
优化端:使用multi-step learning rate代替LLaMA中的cosine learning rate schedule,主要原因是实验发现两者虽然最终收敛到的loss差不多,但是前者在连续学习上loss能够保证一致性,连续学习更加方便。先用2000个step的warmup将学习率提升到最大值,然后在训练完80%的训练数据后将学习率降低到31.6%,在训练完90%的训练数据后进一步降低到10%。
对齐:使用Supervised Fine-Tuning、DPO两种方式进行预训练模型的finetune,进行风格对齐。Supervised Fine-Tuning使用120w搜集到的SFT数据(一些根据指令给出答案的文本,由人类标注的高质量数据,帮助预训练模型迁移人类风格)进行finetune。DPO是针对之前ChatGPT中基于强化学习的RHLF风格迁移的一种升级,不用强化学习,只使用一个指定对应的两个答案之前的相对偏好关系作为损失函数加入到模型中。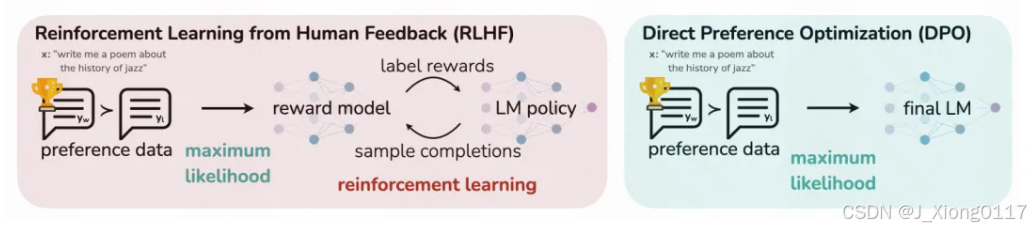
3.2 DeepSeek V2
DeepSeek V2最核心的2点改动都在模型结构上,一个是提出了一种Multi-head Latent Attention提升了inference效率;另一个是构建了基于DeepSeekMoE的语言模型结构。
Multi-head Latent Attention:MLA的主要目的是减少KV缓存占用的空间。KV缓存是大模型都会使用的技术,在inference阶段,每一个token的输出都要和历史所有token计算attention,每次新增token都有很多重复计算,因此可以将前面token计算出的key和value缓存起来。但是直接缓存key和value占用较大的空间,因此MLA对KV进行了一个低维映射,只存储这个低维的向量,节省了缓存存储空间。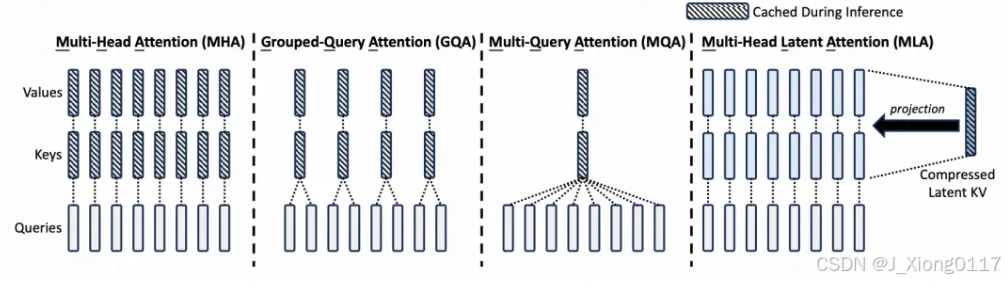
DeepSeekMoE:MoE是目前大模型在探索应用的一项技术,基础的MoE将原来的每个token的单个FFN层变成多个并行的FFN层(对应多个expert),并根据输入生成一个路由到各个FFN的打分,选择topN个专家,实现在单token运算量没有显著提升的前提下,扩大模型的参数空间的目的。如下图a中,即是一个激活2个专家的MoE。
而DeepSeekMoE相比MoE有2个核心优化。一个是把Expert变多了(文中称为Fine-Grained Expert),其实就是把原来每个Expert的FFN维度调小,增加Expert数量,并且最终激活的Expert数量也变多。另一个就是增加了几个所有token都走的公用Expert,通过让所有token都走这些Expert,让这些Expert提取通用信息,其他Expert就能更专注于提取差异化的信息。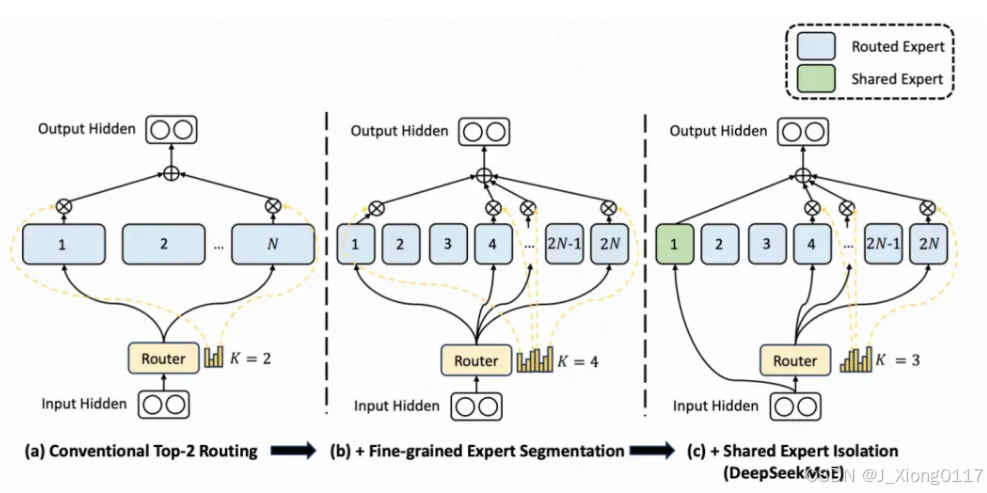
3.3 DeepSeek V3
DeepSeekV3在模型结构上的核心优化,一方面是对DeepSeekMoE中的多专家负载均衡问题,提出了一种不需要辅助loss就能实现的解决方案,相比使用辅助loss提升了模型性能;另一方面是引入了Multi-Token Prediction技术,相比原来每次只能预测一个token,显著提升了infer的速度。
Auxiliary-Loss-Free Load Balancing:MoE的一个核心问题是有可能会出现坍缩问题,即训练到最后,激活的总是那么几个Expert,没有实现各个Expert的均衡,从而失去了多专家的意义。一般的解决方法会显示引入一个负载均衡loss(DeepSeekV2,以及一些其他MoE的做法),但是显示引入一个和目标不相关的loss会影响训练效果。因此,DeepSeek V3采用了无需loss的负载均衡方法,在每个Expert打分增加一个这个相应的bias项,bias项只影响路由不影响后续的Expert加权求和计算,每个step都会监控各个Expert的负载均衡情况,对于过载的Expert降低bias项减少其相应的激活数量,对于比较稀疏的Expert增大其bias项提升激活其的样本比例。
Multi-Token Prediction:语言模型都是逐个预测的,每次将当前预测结果作为最新的一个输入,再次预测下一个。改成多token预测,一方面可以显著提升infer的速度,另一方面也可以让模型在生成后续token的时候有一个全局性,提升生成效果,对训练数据利用的也更加充分,加速收敛。
具体做法为,在训练阶段,除了原来的主模型外,还会有几个并行的MTP模块,这些MTP模块的Embedding层和Output Head和主模型共享,内部有一个Transformer层。在主模型预测了next token后,将这个预测token的表征和之前token的Embedding拼接到一起,生成一个新的输入(超出长度的更久远的token被才减掉)。这个拼接好的Embedding输入到第一个MTP中预测next next token。以此类推,将MTP Module1的当前预测token表征和历史token拼接到一起,作为MTP Module2的输入,再预测next next next token。
文中引入Multi-Token Prediction主要为了提升训练效果,inference阶段直接去掉这些MTP模块,也可以引入这些MTP模块提升inference效率。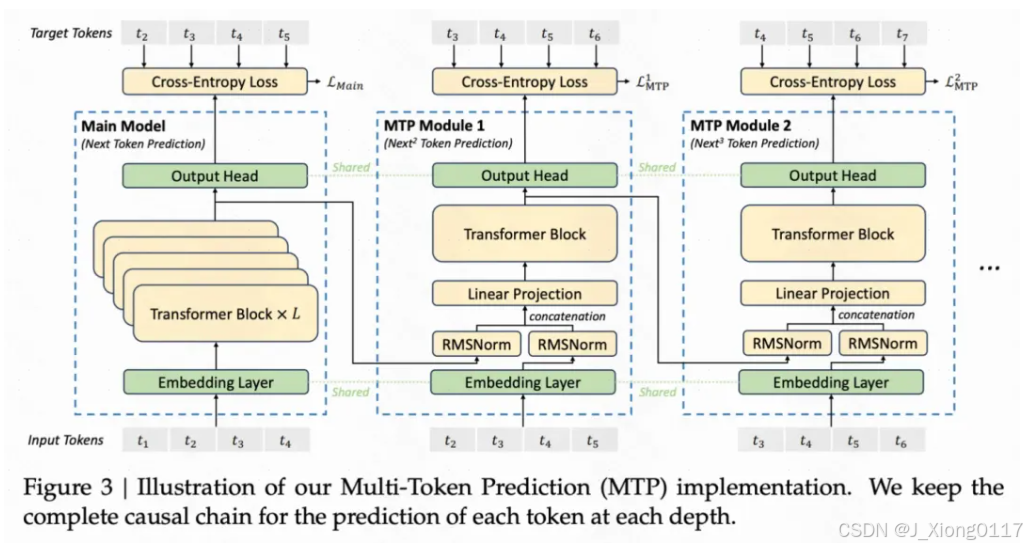
3.4 DeepSeek R1
Deepseek-R1 通过大规模强化学习 (RL) 训练,无需监督微调 (SFT) 作为初步步骤,展示了卓越的推理能力。通过纯 RL进行自我进化,模型能够自然而然地出现许多强大而有趣的推理行为。然而,之前的Deepseek-R1-zero遇到了可读性差和语言混杂等挑战。为了解决这些问题并进一步提高推理性能,DeekSeek-R1提出了在 RL 之前结合多阶段训练和冷启动数据。最终DeepSeek-R1 在推理任务上实现了与 OpenAI-o1-1217 相当的性能。同时开源了 DeepSeek-R1-Zero、DeepSeek-R1 和基于 Qwen 和 Llama 从 DeepSeek-R1 提炼出的六个密集模型(1.5B、7B、8B、14B、32B、70B)。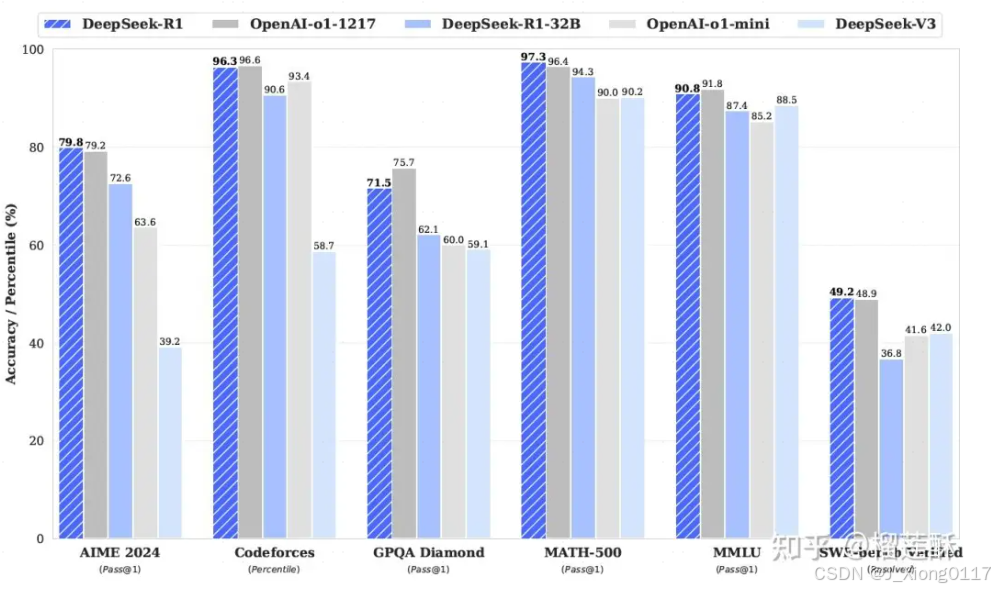
纯RL训练步骤
Deepseek-R1 使用少量冷启动数据 + 多阶段训练流程:
首先收集数千个冷启动数据来微调 DeepSeek-V3-Base 模型;
然后,执行类似 DeepSeek-R1-Zero 的面向推理的 RL,以下是 RL 中涉及到的一些基本原理:
Group Relative Policy Optimization (GRPO群体相对策略优化):是一种在强化学习领域中的优化策略,与传统的仅考虑个体的策略优化不同,GRPO将多个智能体(或策略)视为一个群体。在这个群体中,每个智能体的策略评估和优化不是孤立进行的,而是相对其他智能体的策略进行。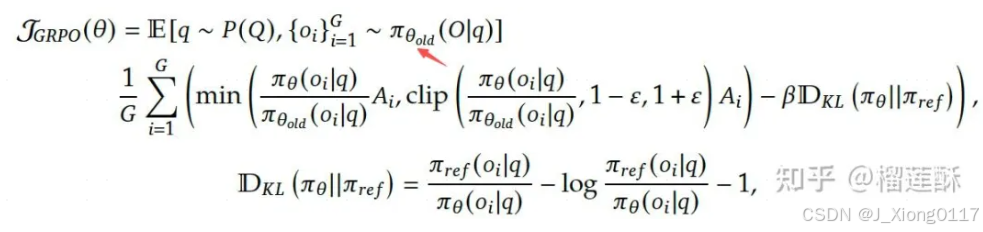
最终的 (advantage),通过对应输出的一组奖励 reward group { 1, 2, . . . , } 计算:
Reward modeling奖励模型:奖励是训练信号的来源,决定了强化学习的优化方向。DeepSeek-R1-Zero 采用了基于规则的奖励系统,主要包含两种类型的奖励:
准确度奖励:评估响应是否正确。例如,对于具有确定性结果的数学问题,要求模型以指定的格式(例如,在框内)提供最终答案,从而实现可靠的基于规则的正确性验证。同样,对于 LeetCode 问题,可以使用编译器根据预定义的测试用例生成反馈。
格式奖励:强制模型将其思考过程置于“”和“”标签之间。
在 DeepSeek-R1-Zero 训练中没有用结果或过程神经奖励模型。
训练:设计了一个简单的模板,指导基础模型遵循指定的指令。如图所示,此模板要求 DeepSeek-R1-Zero 首先生成一个推理过程,然后给出最终答案。
在 RL 过程接近收敛后,通过对 RL 的 ckpt 进行拒绝采样 (rejection sample) 创建新的 SFT 数据:
• 在上一阶段,只用了那些可以使用基于规则的奖励进行评估的数据。但是,在此阶段,合并较多其他数据来扩展数据集,其中一些数据使用生成奖励模型,将基本事实和模型预测输入 DeepSeek-V3 进行判断。
• 由于模型输出有时比较混乱,难以阅读,这里过滤掉了混合语言、长段落和代码块的思路链。对于每个prompt都抽取多个响应并仅保留正确的响应。最红一共收集了大约 60 万个与推理相关的训练样本。
• 对于非推理数据,例如写作、事实问答、自我认知和翻译,采用 DeepSeek-V3 的 pipeline 并重用 DeepSeek-V3 的 SFT 数据集。总共收集了大约 20 万个与推理无关的训练样本。
• 即共计约 80 万个精选样本对 DeepSeek-V3-Base 进行两阶段的微调。
在使用新数据进行微调后,模型会再用到来自各种场景的prompt来进行额外的 RL 。
Deepseek-R1蒸馏
从 DeepSeek-R1 到较小的 dense 模型的蒸馏:使用 Qwen2.5-32B 作为基础模型,从 DeepSeek-R1 直接蒸馏的效果优于在原本小模型上进行 RL。这表明,更大的基础模型所发现的推理模式对于提高推理能力至关重要。
DeepSeek-R1 开源了蒸馏后的 Qwen 和 Llama 系列。蒸馏后的 14B 模型的表现远胜于最先进的开源 QwQ-32B-Preview ,同时蒸馏后的 32B 和 70B 模型在dense模型的推理 benchmark 上也创下了新纪录。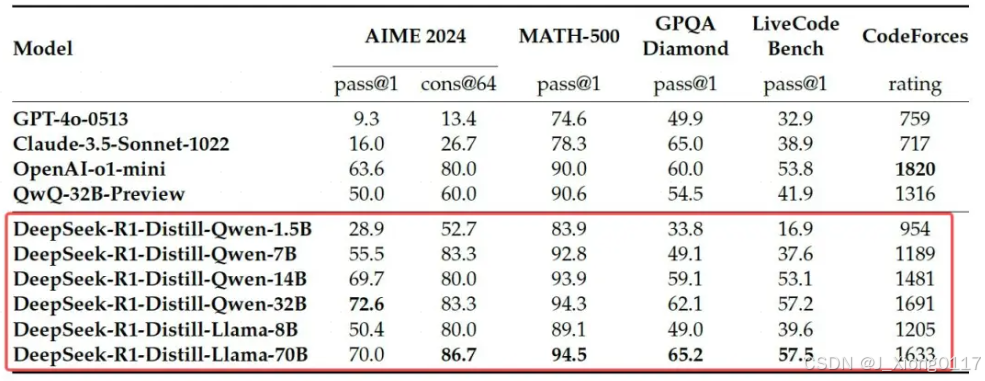
DeepSeek V3 Vs. DeepSeek R1
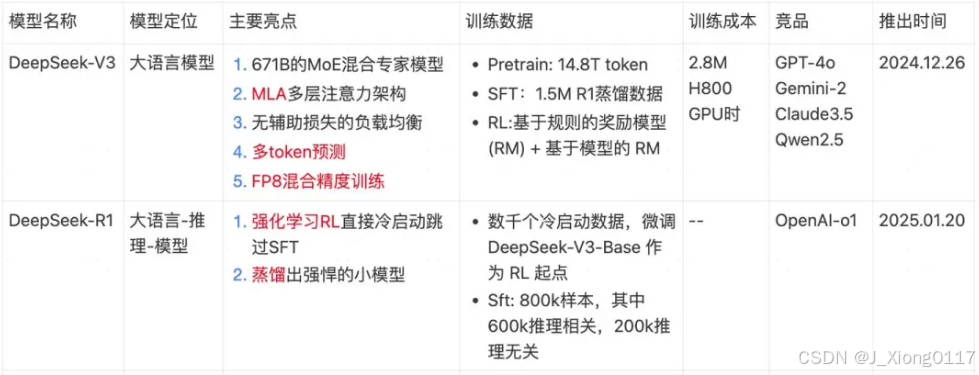
DeepSeek-R1 是由 V3 训练而来,但是随 R1 论文发布的不仅仅只有 R1,还有V3、R1-Zero、R1-Distillation 以及 4 个训练节点。
他们之间是什么关系,V3 是如何最终训练为 R1?下图来自于Sebastian Raschka 在《Understanding Reasoning LLMs》中对 R1 构建流程的建模,明显看到从 V3 到 R1 并不是直接训练而来,中间经过了非常多的步骤。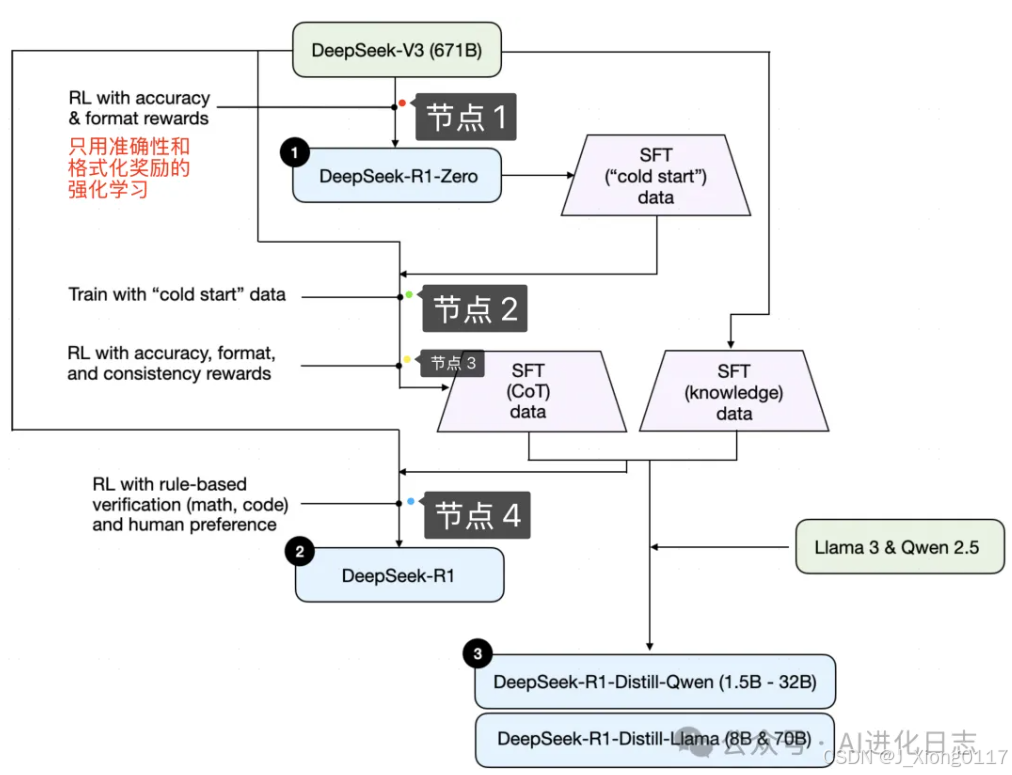
第一步:V3——>R1-Zero

从 V3 纯强化训练得到 R1-Zero——最 Drama 的,也是最历史性的一步。在之前的的大模型强化学习训练中,广泛采用 PPO,但是从 DeepSeekMath 开始,采用 GRPO进行强化训练,没有额外的评价结果的模型,全靠模型自己“练习”。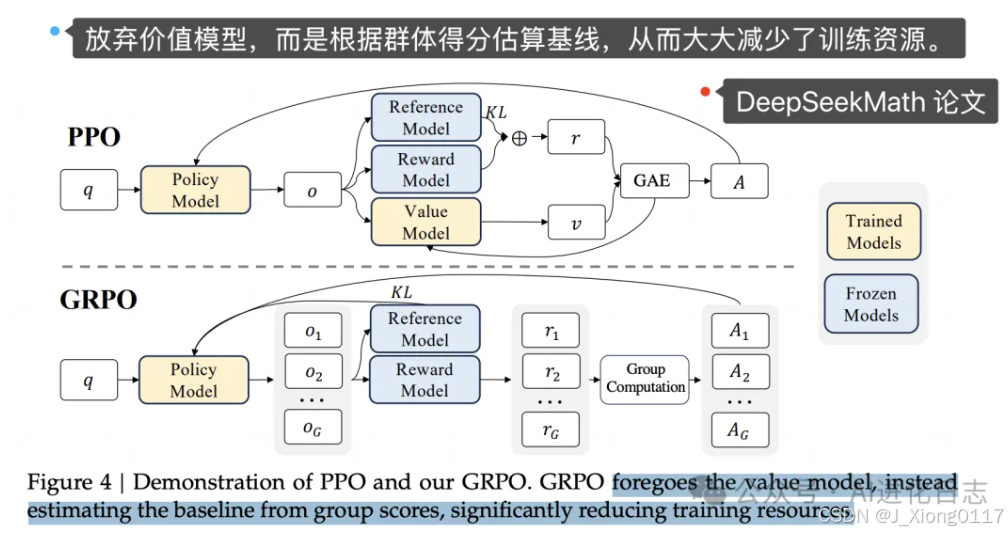
以 DeepSee-V3 模型为基础,只设定上述两个最简单的激励目标:1、答案准确;2、格式正确,然后训练出来的R1-Zero,性能强大到直接“逼近甚至超过”OpenAI-o1-mini!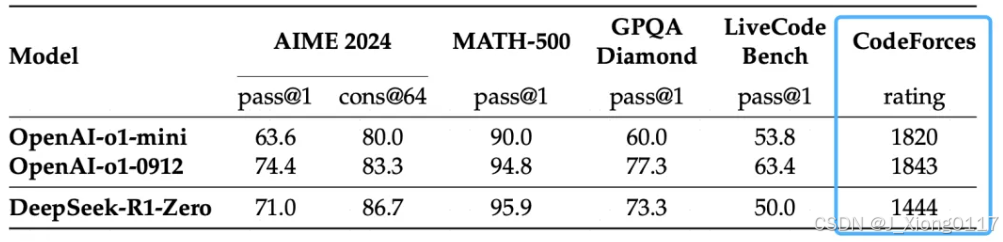
并且随着强化学习次数的增多,R1-Zero 开始使用更多的思考时间解决推理问题。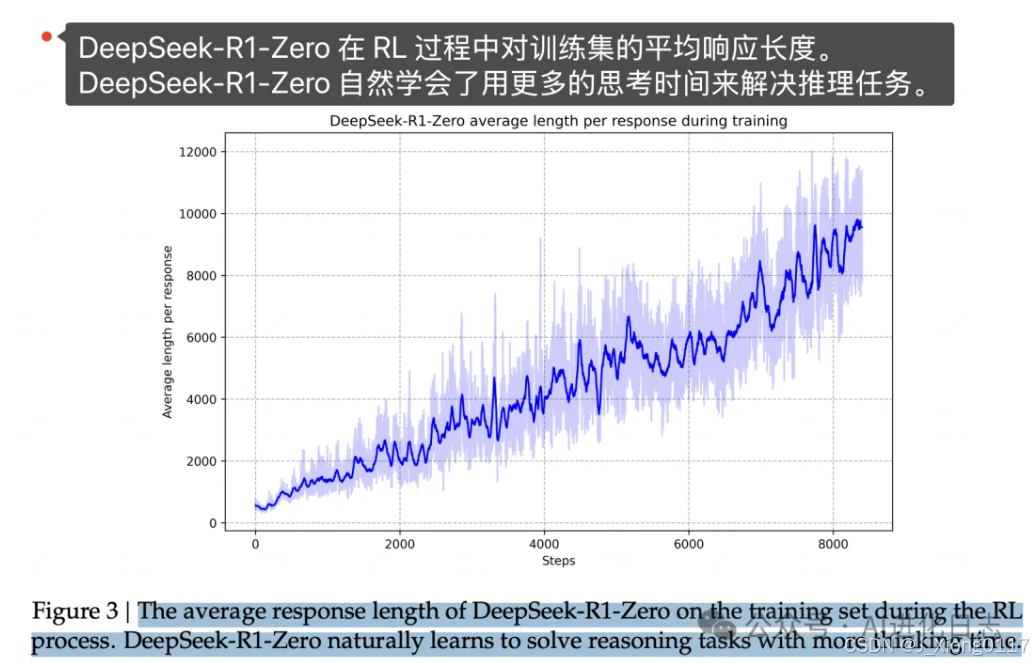
用 DeepSeek-R1 的原文就是:这种提升并非外部调整的结果,而是模型内部的一种内在发展。。。这种自我进化最显著的方面之一是,随着测试时计算量的增加,复杂行为逐渐出现。
第二步:R1-Zero 得到冷启动数据,再次训练 V3,并在此基础上继续强化训练,最终得到优质“思维链”数据集+从 V3 得到知识集数据
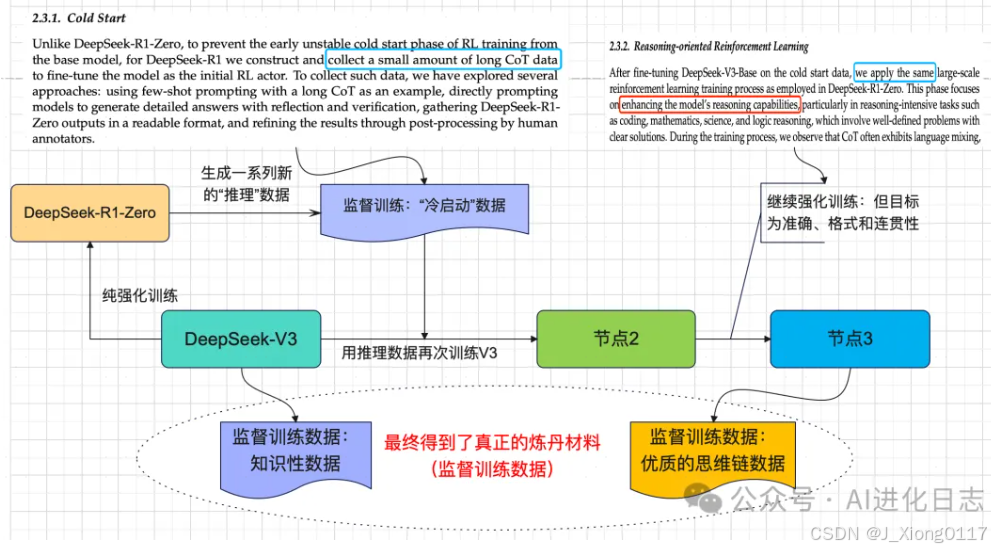
R1-Zero 只是用来生成冷启动思维链数据,然后将这个冷启动数据再去训练 V3!生成过程结果节点 2,然后对节点 2 进行相同的强化训练,但是和上面那个激励模型简单的强化训练不同!这一步的激励模型重点在准确、格式以及回答的连贯性。通过节点 3 生成的优质的思维链数据集以及 最初 V3 模型生成知识性数据集。(所以,到这一步就能看出,虽然是 R1 论文,但是真正的核心模型是 DeepSeek-V3!!!)
第三步:用上述数据集微调 V3,用适用于所有场景的强化学习继续训练 V3,最终得到 DeepSeek-R1
利用得到的监督数据,依然是对 V3 进行微调,然后最后再进行一轮强化学习,这次强化学习不像第一次那么简单,而是多样化的奖励模型,以及更符合人类偏好,所谓“对齐”,大功告成!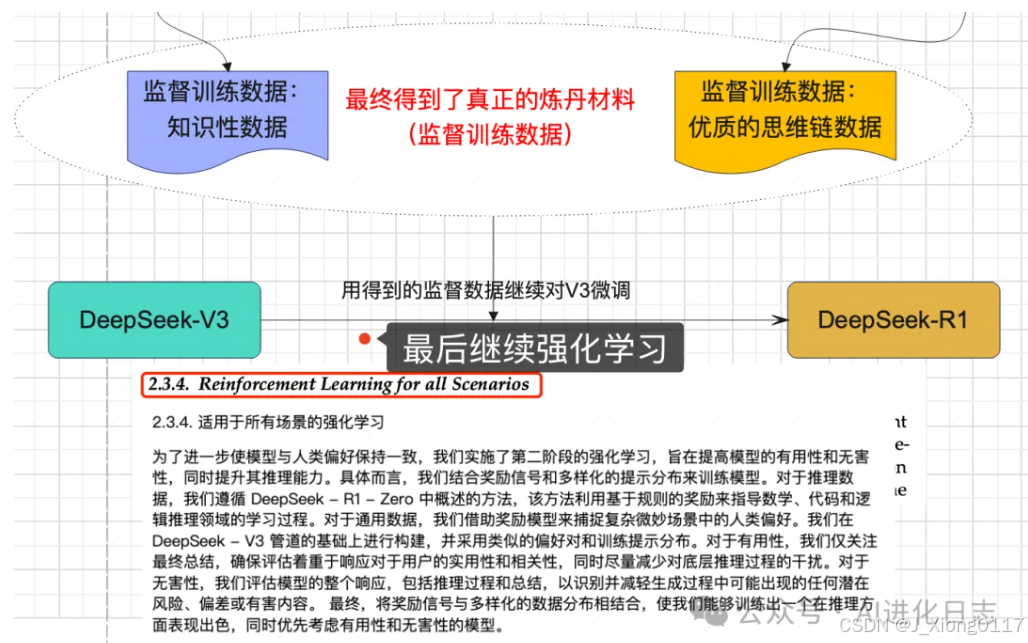
这么看,似乎还是从 V3 直接训练出了 R1,但是如果没有第二张图片中的两个数据集微调,也许 V3 的性能并不会那么惊艳。
为了验证这两个数据集,DeepSeek 将他们用在了两个开源模型上,一个国内阿里的 Qwen,一个是国外的 Meta 的 Llama。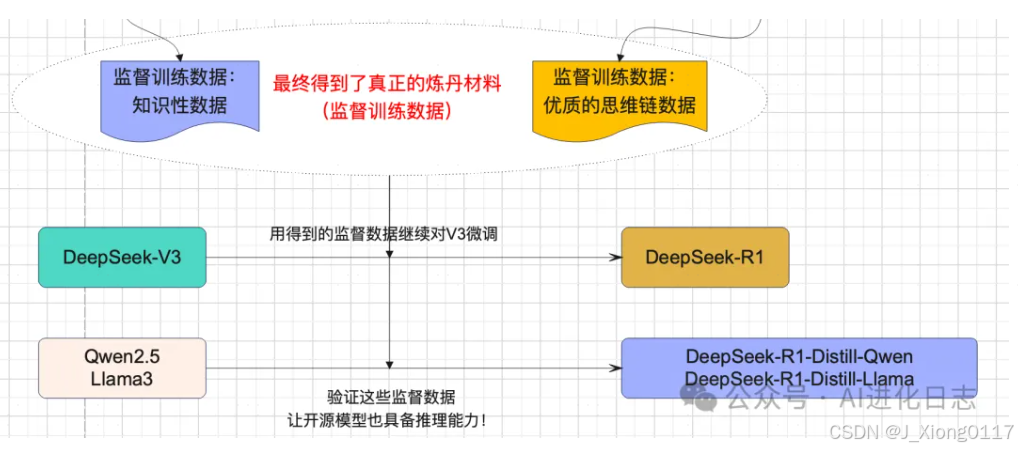
效果惊人!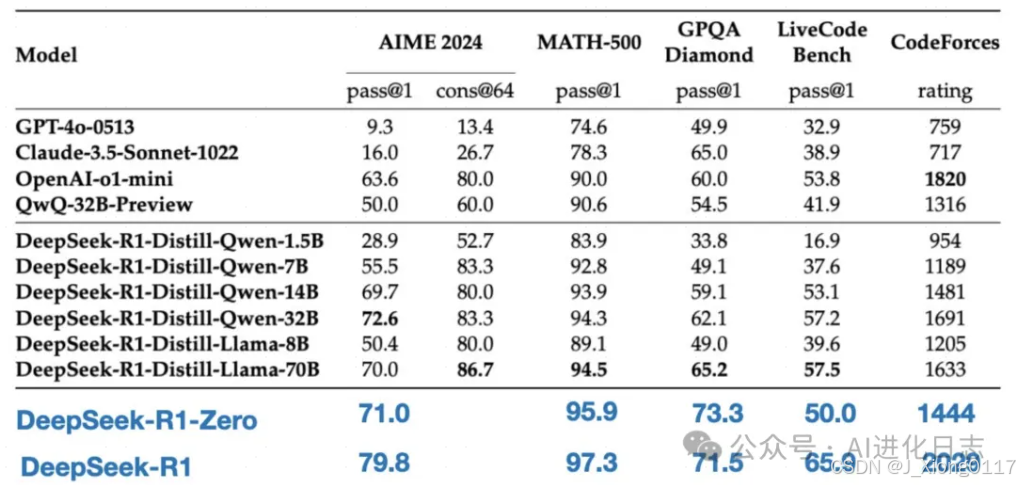
DeepSeek的出现,让全世界看到AGI的实现又更近了一步,也给全球科技巨头进一步上紧发条。DeepSeek出现之前,科技巨头采取的是“不惜一切代价建设”的策略,即通过大规模资本开支,提高算力,从而获得更好的模型。但DeepSeek的出现可能导致市场质疑科技巨头大规模资本开支的合理性。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)