Cat2Bug-Platform利用DeepSeek生成测试用例
2025年首,DeepSeek席卷全球,也有一些朋友问我Cat2Bug何时可以接入DeepSeek,趁着这个周末,我来整理说明一下Cat2Bug下如何快速使用DeepSeek生成测试用例,顺便测试对比一下“DeepSeek”、“千问”和“llama”三种开源模型在创建中文测试用例时的优劣。
·
2025年首,DeepSeek席卷全球,也有一些朋友问我Cat2Bug何时可以接入DeepSeek,趁着这个周末,我来整理说明一下Cat2Bug下如何快速使用DeepSeek生成测试用例,顺便测试对比一下“DeepSeek”、“千问”和“llama”三种开源模型在创建中文测试用例时的优劣。
Cat2Bug-Platform系统中使用DeepSeek
- 点击进入项目设置中的【大模型】页面。

- 在右侧输入框输入"deepseek-r1:7b",点击【下载模型】按钮,等待列表中的模型下载完成。

- 模型下载完成后,选择列表中【deepseek-r1:7b】所在行的【业务识别模型】单选按钮,代表所有业务相关操作用此模型。

- 点击【测试用例】页面的【AI用例生成】按钮,进入创建用例界面。

- 在【提示词区域】输入想要创建的用例描述,点击【添加需求】按钮,便会通过deepseek-r1:7b模型生成测试用例。

- 生成的测试用例将会在一下列表中展示,右侧调整修改,并可以批量导入到系统中。

以上操作也可通过Demo平台进行体验
- 体验账号:demo
- 体验密码:123456
演示地址:https://www.cat2bug.com:8022
模型分析对比
测试方法及说明
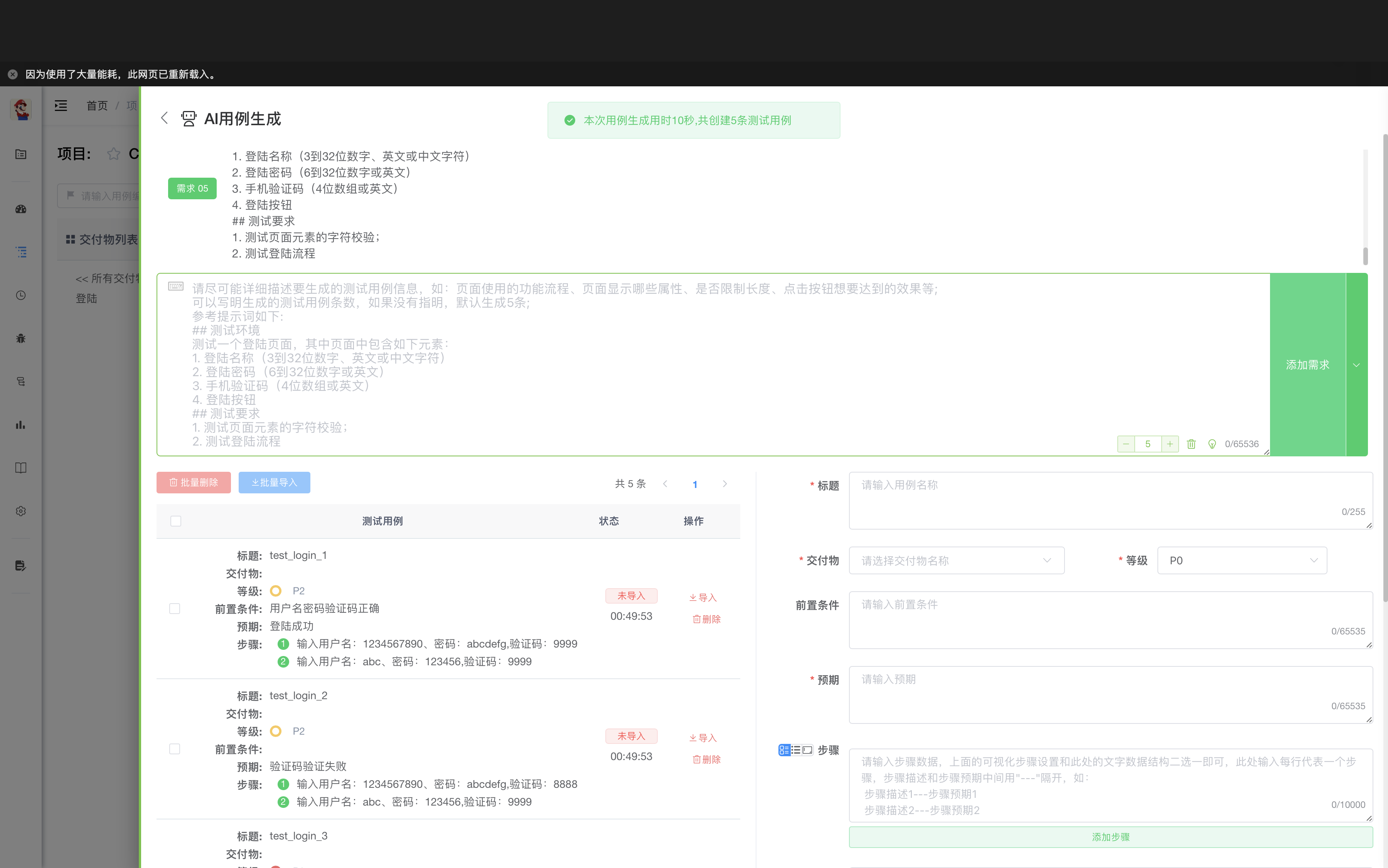
测试采用7b大小的三种模型,通过统一的提示词生成测试用例进行比较,提示词图下:
## 测试环境
测试一个登陆页面,其中页面中包含如下元素:
1. 登陆名称(3到32位数字、英文或中文字符)
2. 登陆密码(6到32位数字或英文)
3. 手机验证码(4位数组或英文)
4. 登陆按钮
## 测试要求
1. 测试页面元素的字符校验;
2. 测试登陆流程
以下是三种模型生成的测试用例截图
- qwen2.5:7b生成截图

- deepseek-r1:7b生成截图

- llama3.2:7b生成截图

测试结果统计
| 模型名称 | 模版版本 | 执行时间 | 生成用例稳定性 | 生成用例完整性 | 用例可用性 |
|---|---|---|---|---|---|
| qwen2.5 | 7b | 7秒 | 良 | 良 | 优 |
| deepseek-r1 | 7b | 10秒 | 优 | 良 | 差 |
| llama3.2 | 7b | 8秒 | 良 | 良 | 良 |
- 用例稳定性:
在实验中,每种模型分别创建了5次用例,每次要求创建5条用例数据,此次测试deepseek-r1比较稳定,而qwen2.5每次创建的数量在4至5条之间,llama3.2在返回时有时会反馈英文结果; - 用例完整性:
在用例完整性上,三种模型均未完全达到理想状态,偶尔会缺少部分属性; - 用例可用性:
令人失望的是,deepseek-r1生成的测试用例还无法直接使用,如用例标题全是英文加序号,测试步骤莫名输入两次账号密码等问题,而qwen2.5和llama3.2都能很好的根据不同属性分别生成测试用例;
综上所属,笔者还是推荐qwen2.5作为主要生成用例的模型使用。
需要注意,如果用户需要自己部署私有化的大模型平台,需要考虑硬件性能的问题,目前根据我们测试的结果,推荐的硬件参考如下:
| 模版大小 | 显卡型号 | 显卡数量 | 执行时间 | 使用场景 |
|---|---|---|---|---|
| 7b | RTX4060 | 1 | 10秒 | 个人或小团体使用,模型稳定性差,偶尔创建用例时会报错 |
| 7b | RTX4090 24G | 2 | 5秒 | 有一定预算的个人或小团队使用,性能较快 |
| 7b | A100 40G | 2 | 2秒 | 不建议A100使用7b模型 |
| 32b | RTX4060 | 1 | 20分 | 不建议RTX4060使用32b模型,执行非常慢 |
| 32b | RTX4090 24G | 2 | 3分 | 研发或团队使用,个人感觉32b模型是一个分水岭,效果和稳定性较好 |
| 32b | A100 40G | 2 | 30秒 | 预算充裕,对执行效果和时间有要求的用此方案 |
| 72b | RTX4060 | 1 | 30分 | 不建议RTX4060使用32b模型,执行非常慢 |
| 72b | RTX4090 24G | 2 | 3分 | 不建议RTX4090使用72b模型,显存无法一次存放整个模型,性能较慢 |
| 72b | A100 40G | 2 | 10秒 | 预算充裕,专业团队,推荐使用此方案 |
以上为单个任务执行模型的时间和配置,官网推荐8块RTX4090或6块A100,有预算的朋友可以试试。
最后欢迎大家访问我们的官网或微信群进行沟通交流


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)