
DeepSeek-R1模型5分钟下载本地对话——忘掉CUDA、GPU和烦人的代码:OLLAMA本地部署DeepSeek R1全攻略
Ollama 支持在 Modelfile 中导入 GGUF 模型:创建一个名为Modelfile的文件,并在其中包含一个FROM指令,该指令指向你想要导入的模型的本地文件路径。在 Ollama 中创建模型运行模型。
1话不多说,手把手教你打造专属AI应用
在这个Deepseek官方APP卡顿、API网络不通的时候,人们都开始把目光转向自己部署Deepseek R1享受独属于自己的模型对话体验。然而作为一看到代码就头疼的普通人,模型的下载使用成为了一个难题。什么命令行、什么conda、什么python、什么GPU,听着就觉得头晕脑胀。
这个时候一只可爱的羊驼蹦蹦跳跳来到大家面前,展示了无痛部署模型的友好体验。
低代码!低代码!低代码!
ollama相当于大模型的STEAM平台,下载客户端后使用简单的复制粘贴就可以自动下载模型,然后就可以打字对话!!它能自动适配电脑配置,无论您是苹果电脑还是windows系统、无论您是GPU还是集成显卡,它都能自动适配硬件条件运行。从此您不用管什么英伟达英特尔AMD,不用管什么CUDA不CUDA,打开命令行对话就完了。(CMD OLLAMA)
开源社区贡献:自开源后,Ollama 吸引了全球开发者参与,GitHub 上有超过 300 名贡献者,代码提交活跃(截至 2024 年 9 月)。
预构建模型库
覆盖广泛:提供 1700+ 模型,涵盖从轻量级(0.5B)到超大规模(236B 参数)的多种架构,包括 LLaMA、Qwen、Mistral、Gemma、Phi 等。
任务适配:模型针对不同场景优化,例如:
文本生成(如 LLaMA 3、Code Llama);
多语言支持(如 Qwen 的中英双语模型);
代码生成与推理(如 DeepSeek-R1)。
模型导入与定制
格式兼容性:支持从 Hugging Face 等平台导入 GGUF、PyTorch(
.pth)、Safetensors 等格式的模型。自定义配置:通过编写
Modelfile文件,用户可调整模型参数(如温度、top_p)或定义对话模板,实现个性化输出。量化支持:支持 Q4、Q5、Q6 等量化方法,降低显存占用(例如 32B 模型经 Q4 量化后显存需求减少 60%)。
模型管理功能
通过命令行工具实现模型下载(
ollama pull)、运行(ollama run)、删除(ollama rm)等操作,类似 Docker 的体验。支持多 GPU 并行推理加速,通过环境变量指定硬件资源。
1.1OLLAMA傻瓜式下载对话
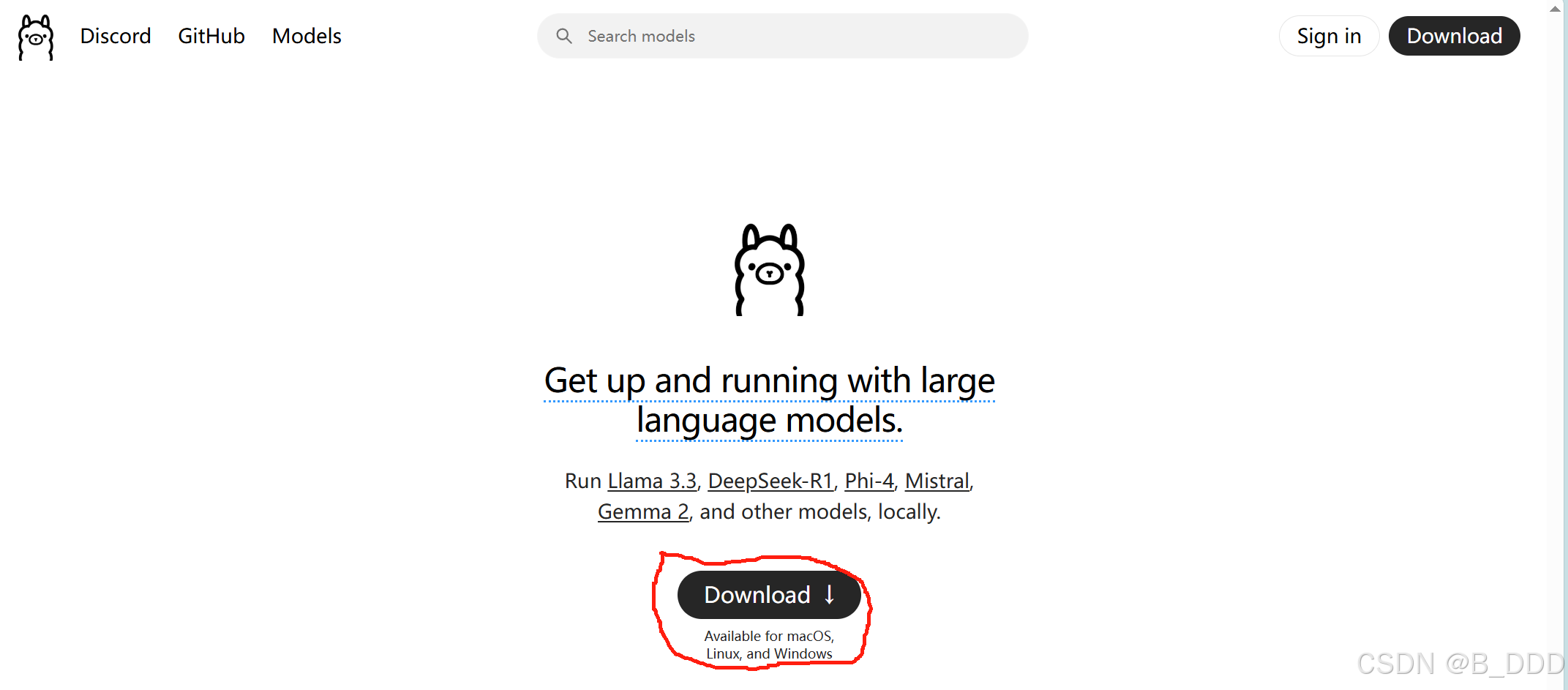
来到OLLAMA官方网站进行客户端下载 (Ollama)

选择您的系统:如果您不知道自己是什么系统,那多半不是Linux,苹果电脑就是macOS,普通人选windows。开发者程序员基本知道自己在用什么电脑。
选择好后,将进入一段常规的软件下载安装流程,程序会自动完成安装步骤。
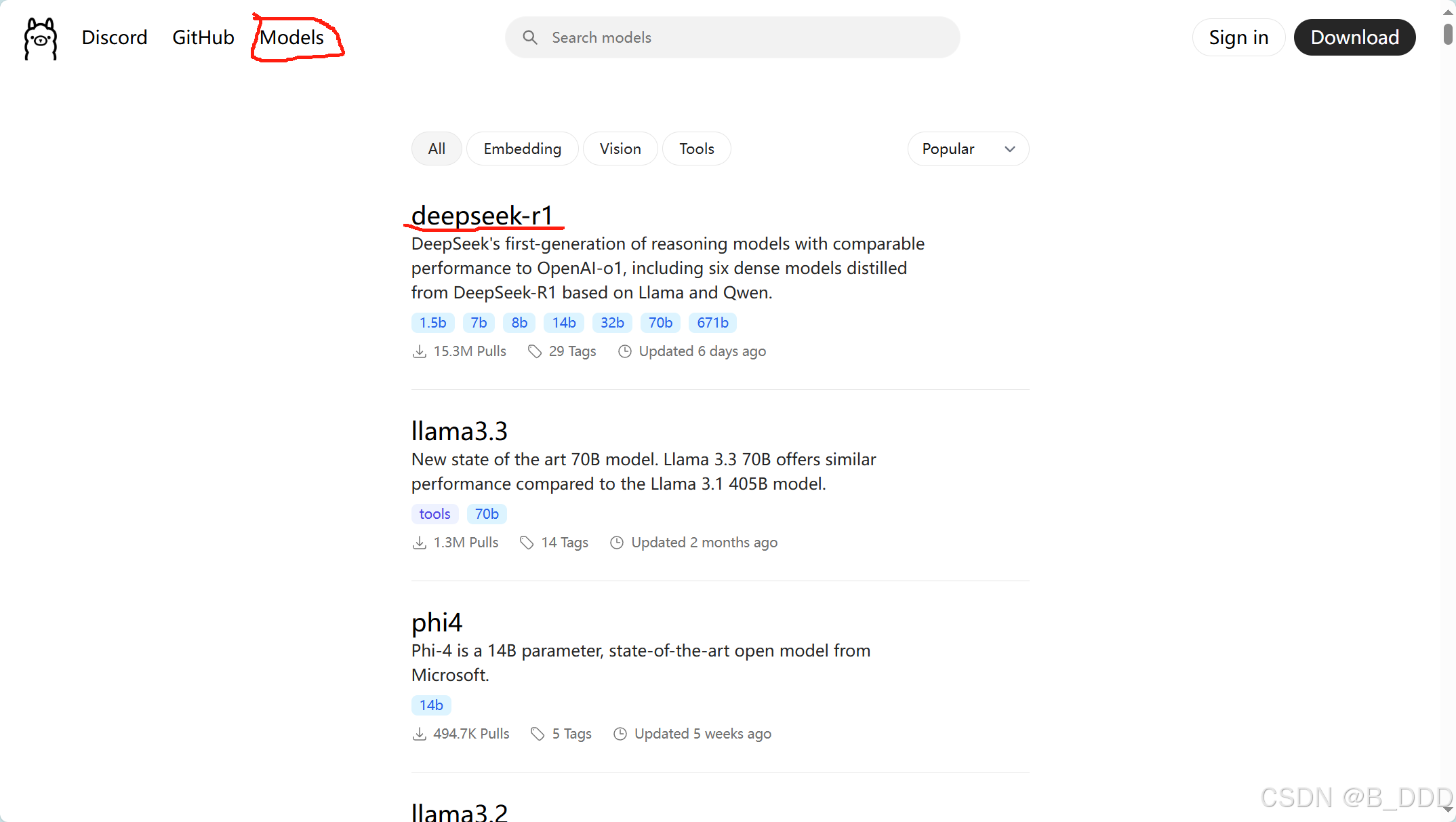
在程序安装的时候,我们点击官网的“Models”,进入模型选择界面。进入让我们魂牵梦绕的“Deepseek R1"
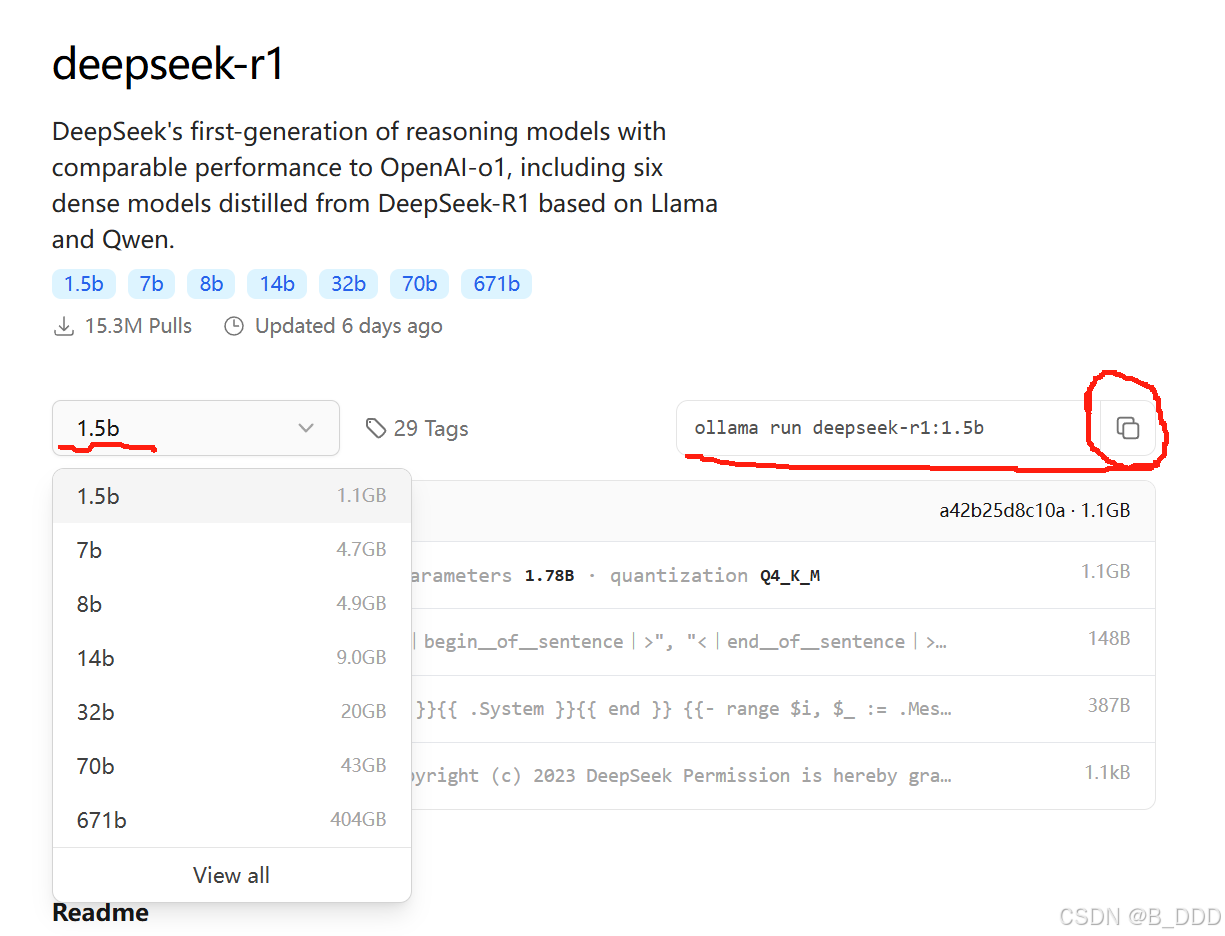
对自己电脑十分自信的朋友可以选择”7b"版本,像我一样长期用便宜电脑的朋友老实从最小的“1.5b"版本开始尝试。点击右侧复制按钮获得咒语:
ollama run deepseek-r1:1.5b这里的b是英文Billion的意思,代表着模型的参数量是15亿左右。模型的参数量大小代表着能力的强弱,圆满的版本是671B模型。由于这么大的模型实际上需要在价值数百万美元的服务器上运行,家用的消费级电脑完全没有可能跑得动。官方贴心地进行了很多种版本的简化,使得各种不同层级的电脑都能找到合适的方案。
打开命令行工具

Ollama
输入字母ollama即可进入界面
ollama
下载模型
复制粘贴上面的咒语,pulling manifest即表示正在下载。下载完成后会自动开始对话界面,只要进行文字输入输出即可。

模型对话
”ollama+空格+run+空格+模型名“即可唤出模型进行对话。
ollama run deepseek-r1:1.5b如果你不清楚自己模型的具体名称就用”ollama+空格+list"唤出下面列表来找找模型名
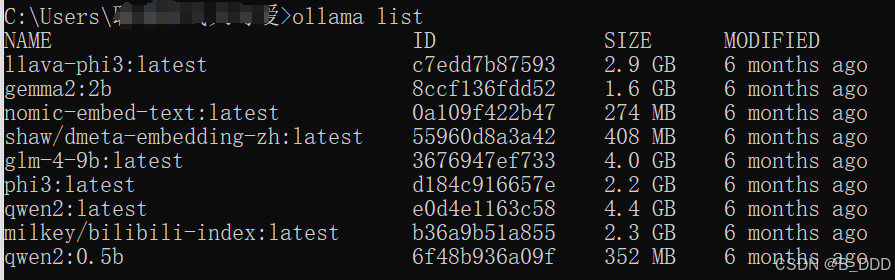
下载完成!提个问题!

恭喜你!你完成了本地化部署,并且见证了你的电脑生产第一个token,完成了第一次推理!
推荐一个简单的测试
#语文测试
1蓝牙耳机坏了需要看医院的哪个科室?
2左手一只鸭,右手一只鸡。交换两次后左右手里各是什么?
3为什么鲁智深不能倒拔垂杨柳而林黛玉却可以?
#数学测试
鸡兔同笼,共35只头,94只脚,问鸡兔各多少?
#逻辑测试
左手一只鸭,右手一只鸡。交换两次双手物品后,左右手中各是啥?
#代码测试
生一个用纯c编写的目录遍历函数
#数据分析
有一个用户表userinfo,包括字段username,userid,birthday,salary, address. 有一个工作量表 workload,包括字段userid,workload,workdate. 请找到最近五天工作量大于50的人的名字和地址。
#中英文互译
将以下中文翻译成英文:穿衣需要适应天气变化,夏天你能穿多少穿多少,冬天你能穿多少穿多少。退出对话
如果想要推出对话可以按“ctrl+d"或者输入对话”/bye"

1.2普通人使用Deepseek R1
普通人使用Deepseek R1往往有那么几种方式:官方在线服务(云端API或APP)、本地部署小参数模型(1.5B/7B/14B)、本地部署中规模模型(32B/70B)、量化版完整模型(671B动态压缩版)、第三方工具链集成(如Dify、LangChain)。一般大家普通的四五千块钱笔记本电脑只能本地部署小参数模型:流畅运行2B左右的模型,而上到7B左右的模型已经分勉强。所以并不容易在电脑上用出Deepseek R1强大的功能。
但是普通人想办法本地使用Deepseek R1依然十分重要!
1对于新技术的祛魅,必须要能亲手把控之后才会实现。当你把一个AI模型放在自己的电脑里进行全方位的对话(肆意玩弄)后,你才能够认识到这玩意到底是个什么东西,才能进一步到思考如何把AI模型更深入地转化为工作流中的工具。
个人开发者可通过量化技术体验前沿模型,加速技术扩散(如学生利用本地模型完成科研项目)。
2数据隐私与合规性 金融、医疗等行业需严格遵守数据本地化法规(如中国《数据安全法》),本地部署避免敏感信息外流。企业可自主控制数据访问权限,防范第三方滥用风险。
3技术自主权与可定制性 开源社区提供插件生态(如知识增强、多模态扩展),突破云端模型的功能限制。随着社区生态逐渐的开发,每次OLLAMA适配的新模型都总有惊喜在等待,比如通过简单的开源套件可以实现漂亮的交互界面的WEBUI项目、比如通过OLLAMA接入DIFY、CHATBOT等应用、比如开源大佬实现的高效量化、蒸馏和各种加速推理项目等。
Ollama+DeepSeek R1 组合最低启动参考配置
测试主机配置一:因特尔12核24线程CPU、6 GB内存、GT730 2GB显存显卡(可运行deepseek-r1:1.5b、7b、70b模型)
测试主机配置二:AMD6核12线程CPU、32GB内存、GT710 2GB显存显卡 (可运行deepseek-r1:1.5b、7b模型)
Ollama+DeepSeek R1 组合最低启动参考配置_ollama deepseek r1最少需要多大显存-CSDN博客
1.3普通人使用OLLAMA
对于没有IT开发经验和代码基础的普通人而言,Ollama 的意义远超一个技术工具——它本质上是一个“去技术化”的AI普惠桥梁“,真正让普通人以零门槛体验前沿大模型能力,甚至参与AI技术变革。
每一次各大模型公司发布新的模型,都会很快上架OLLAMA模型库,它已经成为一个快速体验窗口。只要在命令行内使用 ollama run <模型名> 命令就可以无痛下载,一键开盒。
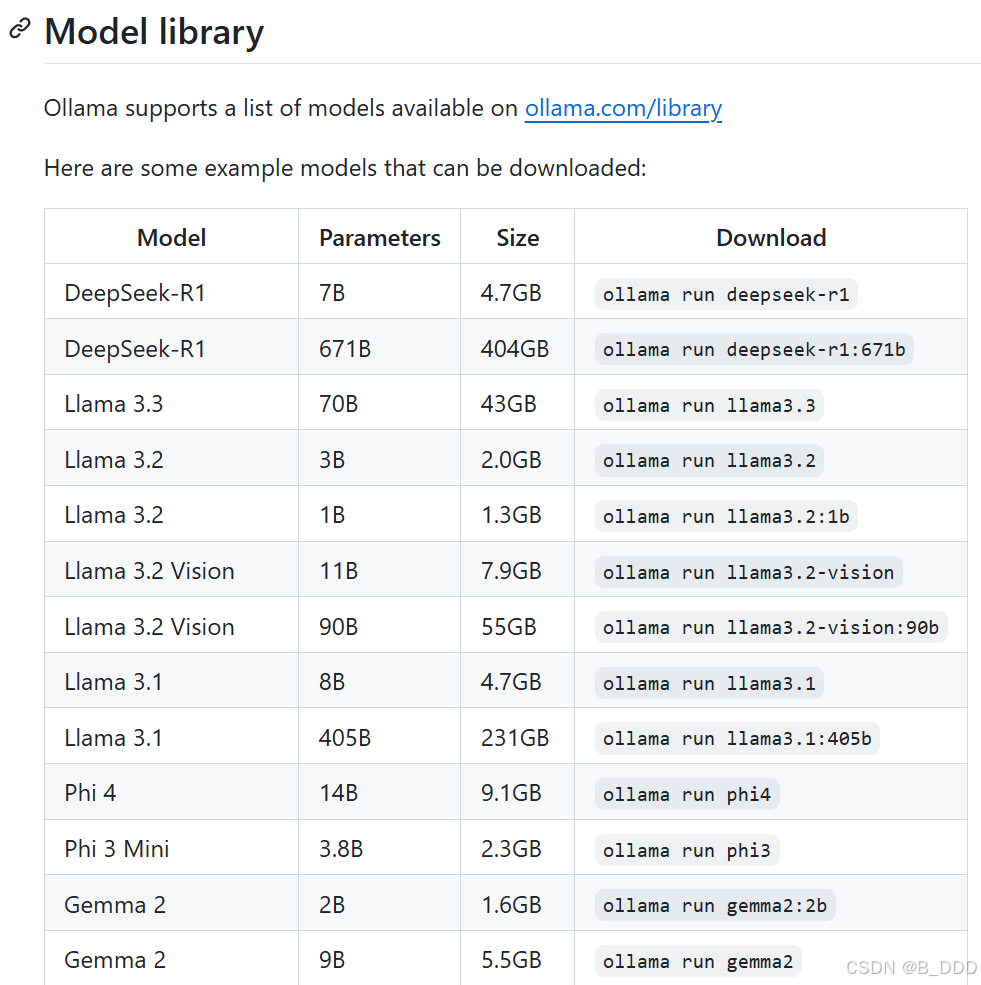
比如Phi-4模型由微软研究院开发,首次展示是在2024年12月12日,而其完整开源则发生在2025年1月8日,上架了huggingface社区并且几日后上架ollama。如今Ollama模型库中已经有Phi4、Phi3.5、Phi3、Phi2以及llava-phi3等多个衍生模型。
微软的Phi系列、Meta的Llama系列、阿里的qwen系列、谷歌的gemma系列、Mistral AI的mistral系列等都在Ollama发布了多款不同参数不同类型的模型,实际上已然成为了下载模型的最方便平台。
即使毫无技术背景,也能通过Ollama实现以下场景:
1. 对话与娱乐
-
个性化聊天:定制“虚拟伴侣”,设置角色(如历史人物、心理咨询师),通过调整
temperature参数控制对话风格。 -
家庭娱乐:与孩子玩故事接龙,用7B模型生成童话剧情(如“生成一个关于太空猫的冒险故事”)。
2. 学习与生产力提升
-
知识库问答:
-
上传本地文档(如PDF、Word),通过Open WebUI构建个人知识库,实现“私有化ChatGPT”。
-
示例:教师将教材上传后,快速提取考点生成练习题。
-
-
语言学习:
-
调用多语言模型(如Qwen-72B)进行实时翻译、语法纠正,甚至模拟外语对话。
-
3. 生活与创作辅助
-
内容生成:
-
小红书文案、短视频脚本、朋友圈金句一键生成(需搭配提示词模板)。
-
示例:博主用14B模型生成“周末露营攻略”,包含装备清单、拍照技巧。
-
-
Function Call实战:
-
通过预设指令调用模型功能,如“查天气”“算汇率”(需集成第三方API,但Ollama提供可视化配置工具)。
-
4. 小微企业赋能
-
低成本客服:
-
用32B模型+微信机器人框架(如ItChat),搭建24小时自动回复系统,处理常见咨询。
-
-
数据分析:
-
上传Excel表格,指令模型生成销售趋势报告(如“分析2023年季度营收增长率”)。
-
1.4与Deepseek官方APP对比我们差了些什么?
联网搜索功能
官方APP通过后端服务器支持实时联网搜索,能够动态获取最新信息。本地部署通常依赖于预训练模型的知识库(截至训练时间点的数据),无法实时访问互联网。
多轮对话能力
官方APP的多轮对话功能依赖于云端的服务架构,能够更好地维护上下文记忆和会话状态。本地部署的模型需要额外配置来支持多轮对话,例如通过外部工具或自定义代码管理对话历史。
性能优化
官方APP运行在经过深度优化的云端基础设施上,具备更高的推理速度和稳定性。本地部署受限于个人设备的硬件性能,尤其是显存和CPU/GPU资源。
插件与扩展功能
Deepseek官方APP未来可能会集成开发多种插件(如图像生成、语音识别等),这些功能通常依赖于专门的API和服务。本地部署需要用户自行集成第三方工具或服务,增加了复杂性。
知识更新
官方APP通常可以通过定期更新模型参数和知识库,保持最新的知识水平。本地部署的模型一旦下载完成,其知识库固定不变,除非手动更新模型文件。
1.5Ollama部署比官方差了什么?
使用 OLLAMA 部署的 DeepSeek R1 在功能和性能上与官方 APP 存在明显差距,尤其是在联网搜索、多轮对话连贯性、多模态支持和性能优化方面。然而,它在隐私保护、成本控制和定制化潜力方面具有独特优势。对于普通用户而言,官方 APP 更加便捷;而对于注重隐私和成本的企业及开发者来说,则需权衡功能完整性与本地部署的优势,选择最适合的方案。
一、功能缺失
1. 联网搜索与实时数据更新
-
官方APP:
-
集成了实时网络搜索能力,能够调用最新的新闻、天气、股票等动态信息。
-
动态知识库更新支持上下文理解,确保模型始终基于最新数据进行推理。
-
-
OLLAMA部署的DeepSeek R1:
-
模型的知识库固定在训练截止时间(如2024年),无法主动获取新数据。
-
若要实现联网搜索功能,需额外集成第三方工具(如 LangChain + 爬虫),这会增加复杂性,并可能导致延迟或隐私风险。
-
2. 多轮对话的连贯性
-
官方APP:
-
使用云端存储对话历史,支持超长上下文窗口(如32k token),确保多轮对话的连贯性和逻辑一致性。
-
-
OLLAMA部署的DeepSeek R1:
-
受硬件内存限制,上下文窗口通常较小(默认为2048 token)。
-
如果需要扩展上下文窗口,需手动调整
num_ctx参数,但会显著降低生成速度。 -
对于较长的对话,容易丢失历史信息,导致上下文不完整。
-
3. 多模态与高级功能
-
官方APP:
-
支持图像生成、语音交互等扩展功能。
-
提供企业级服务,如 API 计费、用户权限管理等。
-
-
OLLAMA部署的DeepSeek R1:
-
缺乏内置的多模态能力,需通过插件或代码集成(如 Whisper 语音识别)。
-
功能碎片化且兼容性较差,用户体验受限。
-
4. 性能优化与稳定性
-
官方APP:
-
基于分布式算力动态优化模型推理,响应速度稳定(如20+ token/秒)。
-
支持高并发访问,适合大规模应用场景。
-
-
OLLAMA部署的DeepSeek R1:
-
受限于本地硬件(如显存、内存带宽),量化版模型生成速度波动较大(1-10 token/秒)。
-
在处理长文本任务时容易崩溃,特别是在资源不足的情况下。
-
二、性能限制
1. 算力瓶颈
-
官方APP:
-
使用云端计算资源,支持 MoE 架构的完整版模型(如671B参数模型)。
-
实现专家层动态路由的高效调度,确保推理效率。
-
-
OLLAMA部署的DeepSeek R1:
-
本地单机部署难以支持 MoE 架构的复杂计算。
-
即使是量化后的模型(如4位量化),仍可能因硬件限制而表现不佳。
-
2. 内存占用
-
官方APP:
-
云端服务器具备足够的内存和显存,能够轻松处理超长上下文窗口(如32k token)。
-
-
OLLAMA部署的DeepSeek R1:
-
长上下文窗口需要缓存大量历史 token,占用显存/内存资源。
-
例如,32B 模型处理 4096 token 上下文时,可能额外消耗 8GB 显存,超出消费级显卡的能力。
-
3. 动态量化与优化
-
官方APP:
-
使用深度优化的软硬件协同设计(如专用 NPU 加速),提供端到端的功能支持。
-
-
OLLAMA部署的DeepSeek R1:
-
缺乏类似的端到端优化工具链,仅提供基础推理框架。
-
当前的动态量化技术(如1.58-bit混合量化)尚未完全适配本地部署场景。
-
三、安全与合规
1. 官方APP:
-
提供官方维护的内容过滤和版权合规机制,确保生成内容的安全性。
-
用户无需自行承担法律风险。
2. OLLAMA部署的DeepSeek R1:
-
缺乏官方审核机制,用户需自行配置内容过滤规则。
-
若涉及联网搜索功能,可能面临隐私泄露和版权侵权的风险。
1.6华为云、腾讯云上线Deepseek推理服务是什么意思?
用一句话概括:这些云服务商相当于“AI模型超市”,让普通人无需自建“厨房”(服务器),就能直接“点餐”(调用大模型能力)。
一、什么是大模型推理?
可以理解为“超级智能大脑”,它通过海量数据训练(比如读遍全网书籍和论文),能完成写文章、解数学题、写代码等复杂任务。例如DeepSeek R1有2140亿参数,性能接近GPT-4。
推理是让这个“大脑”实际工作的过程。比如你问它“如何做番茄炒蛋”,它根据学到的知识生成菜谱。类比人类思考,推理就是“从已知信息得出结论”。
二、大模型安装在哪里?
云端部署:模型安装在云服务商的服务器上(类似存在巨型机房里的电脑),用户通过互联网访问。普通人无需购买昂贵显卡,就像用水电一样按需调用。
本地部署:少数企业可下载模型到自己的服务器,但成本高(如满血版671B需A100显卡集群)。
三、云服务商怎么做生意?
1. 卖算力:提供服务器、显卡等硬件资源,用户按使用量付费。例如华为昇腾云服务提供“澎湃算力”。
2. 卖服务:简化技术流程。比如腾讯云HAI让开发者3分钟部署模型,省去装驱动、配网络等麻烦。
3. 卖生态:集成多种工具(如数据存储、安全审核),帮企业快速搭建AI应用。
类比:云服务商就像“商业地产商”,出租装修好的商铺(算力+工具),让商家(开发者)专注经营(开发应用)。
四、云服务商与DeepSeek如何赚钱?
1. 分成模式:用户调用DeepSeek API时,云服务商收取费用,与DeepSeek分成。例如百度智能云推出“超低价API方案”。
2. 引流变现:通过DeepSeek吸引更多用户使用自家云平台,再销售其他服务(如数据存储、安全防护)。
3. 技术增值:华为云用自研推理引擎优化模型性能,企业为“加速服务”付费。
关键点:DeepSeek开源模型降低技术门槛,云服务商通过规模化服务摊薄成本,实现“薄利多销”。
五、提供API是什么意思?
API的作用:像“点餐接口”。开发者无需懂模型原理,只需发送问题(如“写一首诗”),API返回结果(生成的诗)。
用户价值:小白开发者也能快速开发智能客服、AI写作工具,无需雇佣专业算法团队。
六、技术普惠背后的商业逻辑
华为云、腾讯云等通过降低使用门槛(一键部署)和优化成本(自研加速引擎),让大模型从“实验室玩具”变成“生产力工具”。
对普通人:花几块钱就能体验顶尖AI,比如用DeepSeek写周报、辅导孩子作业。
对行业:中国企业首次在通用大模型领域掌握技术话语权,打破海外垄断。
1.7满血版671B Deepseek R1 的成本
普遍认为,真正部署完整版Deepseek R1的成本十分高昂,预计成本数百万美元。这种部署成本非常高主要是因为它需要使用非常高端的硬件配置,包括64核以上的服务器集群、512GB以上的内存、300GB以上的硬盘以及多节点分布式训练(如8x A100/H100),还需要高功率电源和散热系统。这种级别的配置适用于超大规模AI研究或通用人工智能(AGI)探索。
模型参数与显存需求
- Deepseek R1 671B 是一个超大规模语言模型,参数量为 6710 亿。
- 在 FP8 精度下,每 1B 参数需要约 1GB 显存,因此总显存需求为:
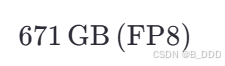
- 如果使用 FP16/BF16 精度,则显存需求翻倍:

1. 英伟达H100/H800方案
-
H100单卡部署
-
显存需求:FP8精度需800GB显存,H100单卡显存为80GB,需至少10卡通过NVLink互联(如DGX H100系统,单机8卡+扩展)。
-
性能表现:
-
单机推理速度:10-15 token/秒(FP8精度,短文本);
-
多节点训练:配合InfiniBand网络,训练速度可达3.5 exaFLOPS。
-
-
优势:支持动态批处理与混合精度优化,适合高并发企业级场景。
-
-
H800多节点方案
-
显存限制:H800单卡显存与H100相同(80GB),但网络带宽降低(从900GB/s降至450GB/s)。
-
性能差异:
-
多节点训练时,通信延迟增加30%-50%,训练周期延长10%-20%;
-
推理速度与H100接近(单卡9-12 token/秒),但集群扩展性受限。
-
-
2. 国产芯片适配方案
-
华为昇腾/海光DCU
-
显存能力:海光DCU单卡显存48GB,需34卡集群部署(FP8精度);
-
性能表现:推理速度约为H100的60%-70%(6-8 token/秒),但支持全栈国产化,适合政企敏感场景。
-
成本优势:国产卡采购成本低30%-50%,但需额外投入软件适配优化。
-
3. 消费级硬件极限方案
-
Mac Studio统一内存
-
配置需求:两台192GB内存的Mac Studio,运行1.58-bit量化版(131GB);
-
性能表现:10+ token/秒(短文本),长文本生成降至1-2 token/秒;
-
适用场景:个人开发者或小型团队低成本尝鲜。
-
二、服务器与机房需求
1. 单机部署(高端方案)
-
硬件配置:
-
浪潮元脑R1 NF5688G7服务器:单机1128GB HBM3e显存,支持FP8精度全量推理58;
-
或双节点H100集群(16卡,总显存1280GB)。
-
-
机房要求:
-
机架空间:42U标准机柜,单机占用8U;
-
电力供应:单机满载功耗8-10kW,需配置20kW冗余电源;
-
散热系统:液冷或强制风冷(建议温控≤25℃)。
-
2. 多节点分布式部署
-
硬件规模:
-
训练场景:256节点(2048张H800),显存总量163TB;
-
推理场景:4节点(32张H100),支持50-100并发用户。
-
-
机房要求:
-
电力:每节点功耗5-6kW,总需求1.2-1.5MW(千卡级集群);
-
网络:InfiniBand HDR/EDR或RoCEv2,延迟≤1μs;
-
面积:1000平方米(含配电、冷却、运维区)。
-
三、成本核算
1. 硬件采购成本
| 方案 | 硬件配置 | 成本估算 |
|---|---|---|
| H100单机推理 | 8×H100 + DGX系统 | 350,000−350,000−500,000 |
| H800训练集群 | 2048卡 + InfiniBand网络 | 80M−80M−100M |
| 国产DCU集群 | 34×海光DCU + 自研服务器 | 15M−15M−20M |
| Mac Studio轻量部署 | 2×192GB内存版 | $11,200 |
2. 运营成本
-
电力消耗:
-
H100单机:年耗电70,000 kWh(¥56,000,按0.8元/kWh);
-
千卡级H800集群:年耗电8.76GWh(¥7,008万)。
-
-
散热成本:占电力支出的20%-30%(液冷可降低至10%)。
-
网络与存储:分布式存储年成本约50万(PB级),InfiniBand网络维护费50万(PB级),InfiniBand网络维护费10万/年。
3. 总拥有成本(TCO)
-
企业级训练集群:5年TCO约$120M(含硬件折旧、电费、运维);
-
中小型推理节点:5年TCO $1.2M(8卡H100 + 机房租赁)。
2OLLAMA是什么
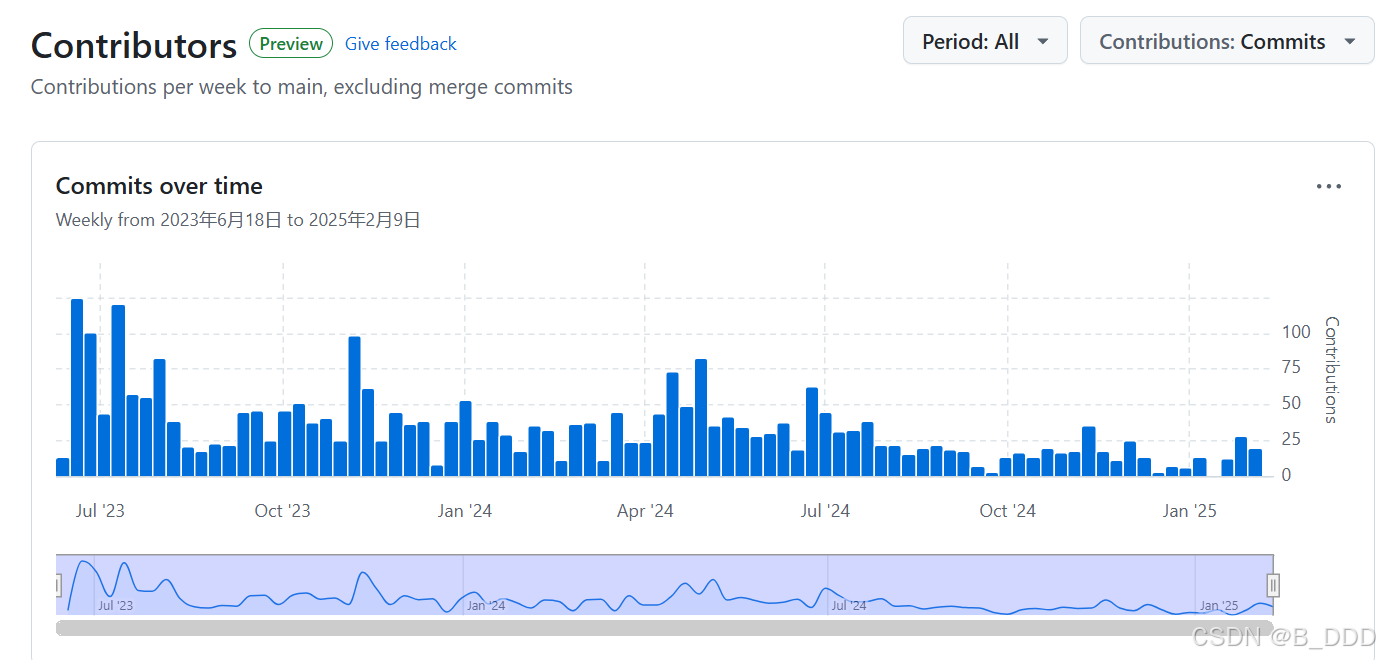
这是一个年轻的项目,由许多年轻的开发者共同维护。 开源社区贡献:自开源后,Ollama 吸引了全球开发者参与,GitHub 上有超过 300 名贡献者,代码提交活跃(截至 2024 年 9 月)。
Ollama 是一个开源的框架和工具,专为本地运行大型语言模型(LLM)而设计。它简化了大模型的部署、管理和使用流程,使开发者和企业能够在本地环境中快速启动和运行各种预训练的语言模型。Ollama 提供了一个类似于 Docker 的命令行工具,用户可以通过简单的命令(如 pull、run 等)来下载、运行和管理模型。此外,它还提供了一个 Web 界面和 API 接口,方便用户与模型进行交互或集成到应用程序中。
-
预构建模型库
-
覆盖广泛:提供 1700+ 模型,涵盖从轻量级(0.5B)到超大规模(236B 参数)的多种架构,包括 LLaMA、Qwen、Mistral、Gemma、Phi 等。
-
任务适配:模型针对不同场景优化,例如:
-
文本生成(如 LLaMA 3、Code Llama);
-
多语言支持(如 Qwen 的中英双语模型);
-
代码生成与推理(如 DeepSeek-R1)。
-
-
-
模型导入与定制
-
格式兼容性:支持从 Hugging Face 等平台导入 GGUF、PyTorch(
.pth)、Safetensors 等格式的模型。 -
自定义配置:通过编写
Modelfile文件,用户可调整模型参数(如温度、top_p)或定义对话模板,实现个性化输出。 -
量化支持:支持 Q4、Q5、Q6 等量化方法,降低显存占用(例如 32B 模型经 Q4 量化后显存需求减少 60%)。
-
-
模型管理功能
-
通过命令行工具实现模型下载(
ollama pull)、运行(ollama run)、删除(ollama rm)等操作,类似 Docker 的体验。 -
支持多 GPU 并行推理加速,通过环境变量指定硬件资源。
-
2.1OLLAMA本地部署意味着什么
尽管本地部署模型的性能弱于云端满血版,但其不可替代性体现在:
| 维度 | 云端服务(如ChatGPT) | Ollama本地部署 |
|---|---|---|
| 数据隐私 | 数据上传至服务器,存在泄露风险 | 数据完全本地处理,敏感信息不出设备 |
| 网络依赖 | 必须联网,偏远地区或弱网环境无法使用 | 完全离线运行,无网络仍可调用AI能力 |
| 成本控制 | 按量付费,长期使用成本高 | 一次性硬件投入,边际成本趋零 |
| 功能自由度 | 受限于平台规则(如内容过滤、功能阉割) | 可自定义内容审查规则,甚至破解道德限制* |
| 模型多样性 | 仅能使用平台提供的少数模型 | 自由切换Hugging Face上数千个开源模型 |
*注:部分用户通过修改Modelfile解除伦理限制,但需承担风险。
2.2OLLAMA同类工具
| 工具 | 核心特点 | 适用场景 | 局限性 |
|---|---|---|---|
| OLLAMA | - 开源、安装便捷,支持多操作系统和Docker - 预训练模型丰富,社区活跃 - 适合快速部署轻量级应用(如聊天机器人) |
个人开发者、中小企业本地化AI应用 | 模型支持受官方限制,扩展性不足 |
| LM Studio | - 用户界面友好,适合非技术人员 - 支持Hugging Face模型库,功能全面(训练、评估、部署) - 多硬件加速(GPU/CPU) |
科研、教育、创意写作 | 仅支持桌面环境,不适用于生产级部署 |
| LocalLLM | - 支持自定义训练和多样化模型 - 硬件要求低(可运行于CPU) |
技术团队定制化需求 | 部署复杂,依赖Docker和命令行 |
| vLLM | - 基于Python,支持动态批处理 - 高效KV内存管理(PagedAttention) |
高性能推理场景 | 硬件要求高(需支持AVX指令集),ARM架构兼容性差 |
2.3OLLAMA进阶下载方法
从 Safetensors 权重导入微调适配器
Safetensors 是一种用于存储深度学习模型权重的文件格式,由 Hugging Face 提供支持。它的设计目标是提高模型权重文件的安全性和易用性,同时解决传统
.pt(PyTorch 的默认权重格式)文件可能存在的问题。在大语言模型(LLM)领域,直接对整个模型进行微调(Full Fine-Tuning)需要大量的计算资源和时间。为了解决这个问题,研究者提出了 参数高效微调(Parameter-Efficient Fine-Tuning, PFT) 技术,其中一种常见的方法是使用 适配器(Adapter)。
微调适配器是一种小型的神经网络模块,插入到预训练模型的某些层中。通过仅训练这些适配器模块的参数,而不是调整整个模型的所有参数,可以显著减少计算成本和内存占用。
将存储在 Safetensors 格式中的微调适配器权重加载到模型中。具体来说:
- Safetensors 文件中的内容:Safetensors 文件中存储的是微调适配器的权重(即适配器模块的参数)。这些权重通常是通过某种微调技术(如 LoRA 或 Prefix Tuning)训练得到的。
- 导入过程:将 Safetensors 文件中的适配器权重加载到预训练模型中。加载后,适配器模块会插入到模型的相应位置,并与预训练模型一起运行。
首先,创建一个 Modelfile,其中包含一个指向你用于微调的基础模型的 FROM 命令,以及一个指向你的 Safetensors 适配器目录的 ADAPTER 命令:
FROM <base model name>
ADAPTER /path/to/safetensors/adapter/directory
确保你在 FROM 命令中使用与创建适配器时相同的基模型,否则你会得到不一致的结果。大多数框架使用不同的量化方法,因此最好使用非量化(即非 QLoRA)适配器。如果适配器与你的 Modelfile 在同一目录中,使用 ADAPTER . 来指定适配器路径。
现在从创建 Modelfile 的目录中运行 ollama create:
ollama create my-model
最后,测试模型:
ollama run my-model
Ollama 支持基于几种不同的模型架构导入适配器,包括:
- Llama(包括 Llama 2、Llama 3、Llama 3.1 和 Llama 3.2);
- Mistral(包括 Mistral 1、Mistral 2 和 Mixtral);和
- Gemma(包括 Gemma 1 和 Gemma 2)
你可以使用能够输出 Safetensors 格式适配器的微调框架或工具来创建适配器,例如:
从 Safetensors 权重导入模型
Safetensors 是一种用于存储深度学习模型权重的文件格式,由 Hugging Face 提供支持。它的设计目标是提高模型权重文件的安全性和易用性,同时解决传统
.pt(PyTorch 的默认权重格式)文件可能存在的问题。
将存储在 Safetensors 格式中的模型权重加载到一个预训练模型的架构中,从而完成模型的初始化或微调。具体过程:
- 下载 Safetensors 文件:获取包含模型权重的 Safetensors 文件(通常是通过开源社区、模型库或其他来源下载)。
- 加载模型架构:使用框架(如 PyTorch 或 Transformers)加载模型的架构(Architecture)。这个架构定义了模型的层结构和参数形状。
- 导入权重:将 Safetensors 文件中的权重加载到模型架构中,完成模型的初始化。
- 运行模型:模型加载完成后,即可运行推理任务或继续进行微调。
首先,创建一个 Modelfile,其中包含一个指向包含你的 Safetensors 权重的目录的 FROM 命令:
FROM /path/to/safetensors/directory
如果你在权重文件所在的同一目录中创建了 Modelfile,你可以使用命令 FROM .。
现在从你创建 Modelfile 的目录中运行 ollama create 命令:
ollama create my-model
最后,测试模型:
ollama run my-model
Ollama 支持导入多种不同架构的模型,包括:
- Llama(包括 Llama 2、Llama 3、Llama 3.1 和 Llama 3.2);
- Mistral(包括 Mistral 1、Mistral 2 和 Mixtral);
- Gemma(包括 Gemma 1 和 Gemma 2);以及
- Phi3
这包括导入基础模型以及任何与基础模型 融合 的微调模型。
导入基于 GGUF 的模型或适配器
GGUF(General General Unified Format) 是一种专门为存储大语言模型(LLM)及其相关数据设计的文件格式,由 GPT4All 项目团队开发和推广。GGUF 格式旨在提供一种高效、灵活且标准化的方式来存储模型权重、元数据以及其他相关信息。
GGUF 的特点:
高效性:
GGUF 文件采用二进制格式存储模型权重,加载速度更快,占用空间更小。
灵活性:
GGUF 不仅可以存储模型权重,还可以包含元数据(如模型架构信息、训练配置、词表等),使得文件更加完整和易用。
跨平台支持:
GGUF 文件可以在多种硬件平台上运行,包括 CPU、GPU 和专用加速器(如 Apple Silicon 或 ARM 设备)。
开源与社区驱动:
GGUF 是一个开源格式,得到了许多开源项目的支持,例如 GPT4All、Ollama 等。
兼容性:
GGUF 文件可以与现有的深度学习框架(如 PyTorch、TensorFlow)结合使用,方便开发者进行模型推理或微调。
将存储在 GGUF 文件中的模型权重或适配器权重加载到模型中,从而完成模型的初始化或微调。具体过程:
-
下载 GGUF 文件:获取包含模型权重或适配器权重的 GGUF 文件(通常是通过开源社区、模型库或其他来源下载)。
-
加载模型架构:使用框架(如 PyTorch 或 Transformers)加载模型的架构(Architecture)。这个架构定义了模型的层结构和参数形状。
-
导入权重:将 GGUF 文件中的权重加载到模型架构中,完成模型的初始化或适配器的加载。
-
运行模型:模型加载完成后,即可运行推理任务或继续进行微调。
如果你有一个基于 GGUF 的模型或适配器,可以将其导入 Ollama。你可以通过以下方式获取 GGUF 模型或适配器:
- 使用 Llama.cpp 中的
convert_hf_to_gguf.py脚本将 Safetensors 模型转换为 GGUF 模型; - 使用 Llama.cpp 中的
convert_lora_to_gguf.py脚本将 Safetensors 适配器转换为 GGUF 适配器;或 - 从 HuggingFace 等地方下载模型或适配器
要导入 GGUF 模型,创建一个 Modelfile,内容包括:
FROM /path/to/file.gguf
对于 GGUF 适配器,创建 Modelfile,内容如下:
FROM <model name>
ADAPTER /path/to/file.gguf
在导入 GGUF 适配器时,重要的是使用与创建适配器时所用的相同基础模型。你可以使用:
- Ollama 中的模型
- GGUF 文件
- 基于 Safetensors 的模型
一旦你创建了 Modelfile,请使用 ollama create 命令来构建模型。
ollama create my-model自定义模型
从 GGUF 导入
Ollama 支持在 Modelfile 中导入 GGUF 模型:
创建一个名为 Modelfile 的文件,并在其中包含一个 FROM 指令,该指令指向你想要导入的模型的本地文件路径。
FROM ./vicuna-33b.Q4_0.gguf在 Ollama 中创建模型
ollama create example -f Modelfile运行模型
ollama run example2.4OLLAMA进阶使用方法
一、Ollama 的社区集成
Ollama 是一个开源项目,因此它能够很好地与开源社区中的其他工具和框架集成。以下是 Ollama 在社区集成方面的主要特点:
1. 模型库支持
Ollama 提供了一个内置的模型库(https://ollama.com/library),用户可以从该库中下载并运行多种流行的开源大语言模型,例如:
- LLaMA 系列(如 LLaMA2、Alpaca、Vicuna)
- DeepSeek 系列(如 DeepSeek-Max、DeepSeek-Lite)
- Mistral 系列(如 Mistral-7B)
- Qwen 等国产模型
这些模型由开源社区贡献和支持,用户可以通过简单的命令(如 ollama pull <model_name>)快速获取并使用。
2. 与其他工具的集成
Ollama 可以轻松与其他开源工具和框架结合,构建更强大的应用。常见的集成包括:
- LangChain:用于构建复杂的对话系统或知识检索应用。
- Flask/Django:将 Ollama 集成到 Web 应用中,提供 API 接口供前端调用。
- FastAPI:用于开发高性能的 RESTful API,支持并发请求。
- Gradio:快速搭建交互式界面,方便测试和演示模型功能。
3. 社区贡献
Ollama 的开源特性使其能够接受来自全球开发者的贡献。社区成员可以通过以下方式参与:
- 提交新的模型或适配器(如 LoRA 权重)。
- 改进 Ollama 的代码或文档。
- 分享使用案例或教程,帮助其他用户更好地理解和使用 Ollama。
二、Ollama 的进阶用法
除了基本的模型管理和运行功能外,Ollama 还提供了许多高级功能,适合需要更复杂操作的用户。
1. 模型微调
Ollama 支持对模型进行微调,以便适应特定任务或领域。常见的微调方法包括:
- LoRA(Low-Rank Adaptation):通过引入低秩矩阵调整模型权重,显著减少计算资源需求。
- P-Tuning/V-Prompting:通过优化连续提示向量来调整模型行为。
- 全量微调(Full Fine-Tuning):适用于资源充足的场景,直接调整模型的所有参数。
微调后的模型可以保存为 Safetensors 或 GGUF 格式的文件,并通过 Ollama 加载和运行。
2. 多模型管理
Ollama 支持同时安装和运行多个模型。用户可以通过以下方式管理模型:
- 使用
ollama list查看已安装的模型。 - 使用
ollama run <model_name>指定运行特定模型。 - 通过 API 接口动态切换模型,满足不同任务的需求。
3. 量化与性能优化
Ollama 内置了模型量化技术(如 4-bit 和 8-bit 量化),能够在不显著降低性能的情况下减少显存占用。用户可以通过以下方式优化模型性能:
- 设置量化级别(如
--quantization参数)。 - 调整推理批大小(Batch Size)和最大生成长度(Max Tokens)。
- 利用硬件加速(如 GPU 或 Apple Silicon)提高推理速度。
4. API 接口与自动化
Ollama 提供了 RESTful API 接口,允许开发者通过 HTTP 请求与模型交互。这使得 Ollama 可以轻松集成到自动化工作流中。常见用法包括:
- 构建聊天机器人或客服系统。
- 开发文本生成工具或内容创作平台。
- 实现批量文本处理或数据分析任务。
API 示例代码(Python):
import requests
url = "http://localhost:11434/api/generate"
data = {
"model": "llama2",
"prompt": "Write a short story about a magical forest.",
"max_tokens": 100
}
response = requests.post(url, json=data)
print(response.json()["response"])5. Web 界面定制
Ollama 提供了一个内置的 Web 界面,默认地址为 http://localhost:11434。用户可以通过以下方式定制界面:
- 修改 CSS 样式以匹配品牌设计。
- 添加自定义功能模块(如上传文件或调用外部 API)。
- 将 Web 界面嵌入到更大的应用程序中。
6. 分布式部署
对于需要更高性能或更大规模的应用场景,Ollama 可以通过分布式部署的方式扩展其能力。常见的方案包括:
- 使用 Docker 容器化 Ollama,便于在多台服务器上运行。
- 结合 Kubernetes 实现自动伸缩和负载均衡。
- 通过消息队列(如 RabbitMQ 或 Kafka)分发推理任务。
7. 模型融合
Ollama 支持加载多个模型的权重并进行融合,从而生成一个新的模型。这种方法可以结合不同模型的优点,提升整体性能。具体步骤包括:
- 下载多个模型的权重文件。
- 使用工具(如 Hugging Face Transformers)合并权重。
- 将融合后的模型保存为 Safetensors 或 GGUF 格式,并通过 Ollama 加载。
8. 日志与监控
Ollama 提供了详细的日志记录功能,帮助用户跟踪模型运行状态和性能指标。此外,还可以通过以下方式增强监控能力:
- 集成 Prometheus 和 Grafana 实现实时监控。
- 记录推理延迟、吞吐量等关键指标。
- 定期分析日志数据以优化模型性能。
三、Web 与桌面端
- Open WebUI 【AI】Ollama+OpenWebUI+llama3本地部署保姆级教程,没有连接互联网一样可以使用AI大模型!!!_ollama webui-CSDN博客
- Enchanted (macOS 原生)
- Hollama
- Lollms-Webui
- LibreChat
- Bionic GPT
- HTML UI
- Saddle
- Chatbot UI
- Chatbot UI v2
- Typescript UI
- Minimalistic React UI for Ollama Models
- Ollamac
- big-AGI
- Cheshire Cat assistant framework
- Amica
- chatd
- Ollama-SwiftUI
- Dify.AI (接入 Ollama 部署的本地模型 | Dify
 https://docs.dify.ai/zh-hans/development/models-integration/ollama
https://docs.dify.ai/zh-hans/development/models-integration/ollama - MindMac
- NextJS Web Interface for Ollama
- Msty
- Chatbox
- WinForm Ollama Copilot
- NextChat 附带 入门文档
- Alpaca WebUI
- OllamaGUI
- OpenAOE
- Odin Runes
- LLM-X (渐进式 Web 应用)
- AnythingLLM (Docker + macOS/Windows/Linux 原生应用)
- Ollama Basic Chat: 使用 HyperDiv 反应式 UI
- Ollama-chats RPG
- QA-Pilot (与代码仓库聊天)
- ChatOllama (基于 Ollama 的开源聊天机器人,支持知识库)
- CRAG Ollama Chat (简单的 Web 搜索,带有纠正的 RAG)
- RAGFlow (基于深度文档理解的开源检索增强生成引擎)
- StreamDeploy (LLM 应用框架)
- chat (团队聊天 Web 应用)
- Lobe Chat 附带 集成文档
- Ollama RAG Chatbot (使用 Ollama 和 RAG 与多个 PDF 文件本地聊天)
- BrainSoup (灵活的原生客户端,带有 RAG 和多代理自动化)
- macai (macOS 客户端,支持 Ollama、ChatGPT 和其他兼容的 API 后端)
- Ollama Grid Search (评估和比较模型的应用)
- Olpaka (用户友好的 Flutter Web 应用,支持 Ollama)
- OllamaSpring (macOS 客户端,支持 Ollama)
- LLocal.in (易于使用的 Electron 桌面客户端,支持 Ollama)
- Shinkai Desktop (两步安装本地 AI,使用 Ollama + 文件 + RAG)
- AiLama (Discord 用户应用,允许你在 Discord 中与 Ollama 互动)
- Ollama with Google Mesop (使用 Ollama 的 Mesop 聊天客户端实现)
- R2R (开源 RAG 引擎)
- Ollama-Kis (一个简单易用的 GUI,带有示例自定义 LLM,用于驾驶员教育)
- OpenGPA (开源离线优先的企业代理应用)
- Painting Droid (带有 AI 集成的绘画应用)
- Kerlig AI (macOS 的 AI 写作助手)
- AI Studio
- Sidellama (基于浏览器的 LLM 客户端)
- LLMStack (无代码多代理框架,用于构建 LLM 代理和工作流)
- BoltAI for Mac (Mac 的 AI 聊天客户端)
- Harbor (以 Ollama 为默认后端的容器化 LLM 工具包)
- PyGPT (适用于 Linux、Windows 和 Mac 的 AI 桌面助手)
- AutoGPT (AutoGPT Ollama 集成)
- Go-CREW (强大的 Golang 离线 RAG)
- PartCAD (使用 OpenSCAD 和 CadQuery 生成 CAD 模型)
- Ollama4j Web UI - 基于 Java 的 Ollama Web UI,使用 Vaadin、Spring Boot 和 Ollama4j 构建
- PyOllaMx - macOS 应用,支持与 Ollama 和 Apple MLX 模型聊天
- Claude Dev - VSCode 扩展,支持多文件/全仓库编码
- Cherry Studio (支持 Ollama 的桌面客户端)
- ConfiChat (轻量级、独立、多平台、注重隐私的 LLM 聊天界面,可选加密)
- Archyve (支持 RAG 的文档库)
- crewAI with Mesop (运行 crewAI 的 Mesop Web 界面,支持 Ollama)
- Tkinter-based client (基于 Python tkinter 的 Ollama 客户端)
- LLMChat (注重隐私、100% 本地、直观的全功能聊天界面)
- Local Multimodal AI Chat (基于 Ollama 的 LLM 聊天,支持多种功能,包括 PDF RAG、语音聊天、图像交互和 OpenAI 集成)
- ARGO (在 Mac/Windows/Linux 上本地下载和运行 Ollama 和 Huggingface 模型,支持 RAG)
- OrionChat - OrionChat 是一个用于与不同 AI 提供商聊天的 Web 界面
- G1 (使用提示策略改进 LLM 推理的原型,通过 o1 类推理链)
- Web management (Web 管理页面)
- Promptery (Ollama 的桌面客户端)
- Ollama App (现代且易于使用的多平台客户端,支持 Ollama)
- ollamarama-matrix (Matrix 聊天协议的 Ollama 聊天机器人)
- ollama-chat-app (基于 Flutter 的聊天应用)
- Perfect Memory AI (根据你在屏幕上的所见、会议中的所听和所说,个性化辅助的生产力 AI)
- Hexabot (对话式 AI 构建器)
- Reddit Rate (搜索和评分 Reddit 主题,带有加权求和)
- OpenTalkGpt
- VT (一个最小的多模态 AI 聊天应用,支持动态对话路由。通过 Ollama 支持本地模型)
- Nosia (基于 Ollama 的易于安装和使用的 RAG 平台)
- Witsy (适用于 Mac/Windows/Linux 的 AI 桌面应用)
- Abbey (可配置的 AI 接口服务器,支持笔记本、文档存储和 YouTube 支持)
四、扩展与插件
- Raycast 扩展
- Discollama(Ollama Discord 频道内的 Discord 机器人)
- Continue
- Vibe(使用 Ollama 转录和分析会议)
- Obsidian Ollama 插件
- Logseq Ollama 插件
- NotesOllama(Apple Notes Ollama 插件)
- Dagger Chatbot
- Discord AI 机器人
- Ollama Telegram 机器人
- Hass Ollama 会话
- Rivet 插件
- Obsidian BMO Chatbot 插件
- Cliobot(支持 Ollama 的 Telegram 机器人)
- Copilot for Obsidian 插件
- Obsidian Local GPT 插件
- Open Interpreter
- Llama Coder(使用 Ollama 的 Copilot 替代方案)
- Ollama Copilot(允许你将 Ollama 用作类似 Github Copilot 的代理)
- twinny(使用 Ollama 的 Copilot 和 Copilot 聊天替代方案)
- Wingman-AI(使用 Ollama 和 Hugging Face 的 Copilot 代码和聊天替代方案)
- Page Assist(Chrome 扩展)
- Plasmoid Ollama Control(KDE Plasma 扩展,允许你快速管理和控制 Ollama 模型)
- AI Telegram 机器人(使用 Ollama 作为后端的 Telegram 机器人)
- AI ST Completion(支持 Ollama 的 Sublime Text 4 AI 助手插件)
- Discord-Ollama 聊天机器人(通用的 TypeScript Discord 机器人,附带调优文档)
- Discord AI 聊天/管理机器人(用 Python 编写的聊天/管理机器人。使用 Ollama 创建个性。)
- Headless Ollama(脚本自动在任何操作系统上安装 Ollama 客户端和模型,适用于依赖 Ollama 服务器的应用程序)
- Terraform AWS Ollama & Open WebUI(一个 Terraform 模块,用于在 AWS 上部署一个即用型 Ollama 服务,附带前端 Open WebUI 服务)
- node-red-contrib-ollama
- Local AI Helper(Chrome 和 Firefox 扩展,允许与当前标签页和自定义 API 端点进行交互。包括用户提示的安全存储。)
- vnc-lm(支持附件和网页链接的容器化 Discord 机器人)
- LSP-AI(开源 AI 功能语言服务器)
- QodeAssist(Qt Creator 的 AI 功能编码助手插件)
- Obsidian Quiz Generator 插件
- TextCraft(使用 Ollama 的 Word 中的 Copilot 替代方案)
- Alfred Ollama(Alfred 工作流)
3OLLAMA上的各种Deepseek模型
DeepSeek 的第一代推理模型,性能可与 OpenAI-o1 相媲美,包括从 DeepSeek-R1 中提炼出来的基于 Llama 和 Qwen 的 6 个密集模型。
蒸馏模型
DeepSeek 团队已经证明,较大模型的推理模式可以提炼成更小的模型,与通过 RL 在小型模型上发现的推理模式相比,性能更好。
以下是使用 DeepSeek-R1 生成的推理数据对研究界广泛使用的几个密集模型进行微调而创建的模型。评估结果表明,蒸馏的较小密集模型在基准上表现非常出色。
DeepSeek-R1-蒸馏-Qwen-1.5B
ollama run deepseek-r1:1.5b
DeepSeek-R1-蒸馏-Qwen-7B
ollama run deepseek-r1:7b
DeepSeek-R1-蒸馏-骆驼-8B
ollama run deepseek-r1:8b
DeepSeek-R1-蒸馏-Qwen-14B
ollama run deepseek-r1:14b
DeepSeek-R1-蒸馏-Qwen-32B
ollama run deepseek-r1:32b
DeepSeek-R1-蒸馏-骆驼-70B
ollama run deepseek-r1:70b
deepseek-v3
一个强大的专家混合 (MoE) 语言模型,总共有 671B 个参数,每个标记激活了 37B。与以前的模型相比,DeepSeek-V3 在推理速度上实现了重大突破。它在开源模型中名列前茅,可与全球最先进的闭源模型相媲美。
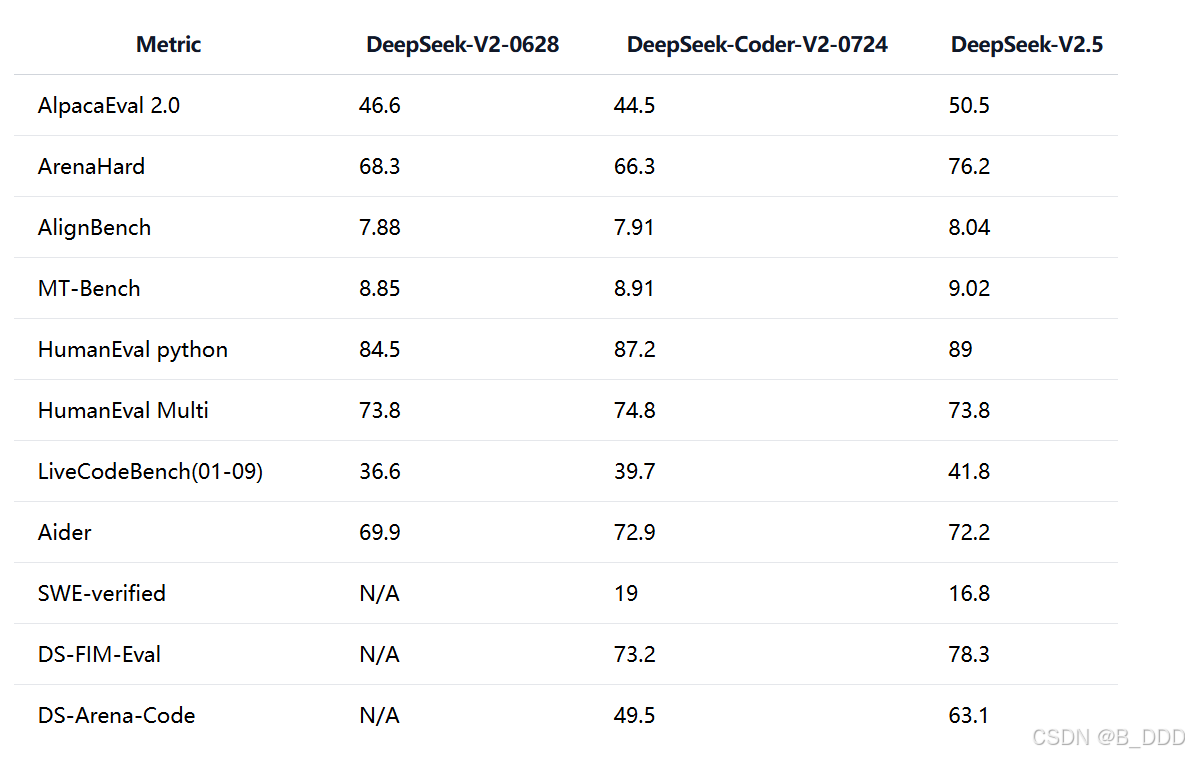
DeepSeek-V2.5 是 DeepSeek-V2-Chat 和 DeepSeek-Coder-V2-Struct 的升级版本。新模型集成了前两个版本的通用和编码功能。DeepSeek-V2.5 更贴近人类偏好,并在包括编写和指令遵循等各个方面进行了优化:
deepseek-v2
DeepSeek-V2 是一种强大的专家混合 (MoE) 语言模型,其特点是经济的训练和高效的推理。注:此型号为中英文双语模式。该型号有两种尺寸:
- 16B 精简版:
ollama run deepseek-v2:16b - 236B 中:
ollama run deepseek-v2:236b
DeepSeek-Coder-V2 是一种开源的混合专家 (MoE) 代码语言模型,可在特定于代码的任务中实现与 GPT4-Turbo 相当的性能。DeepSeek-Coder-V2 从 DeepSeek-Coder-V2-Base 进一步预训练,使用来自高质量和多源语料库的 6 万亿个令牌。
Deepseek-R1-Distilled-Qwen-1.5B 的微调版本,在流行的数学评估中仅具有 1.5B 参数,其性能超过了 OpenAI 的 o1-preview。
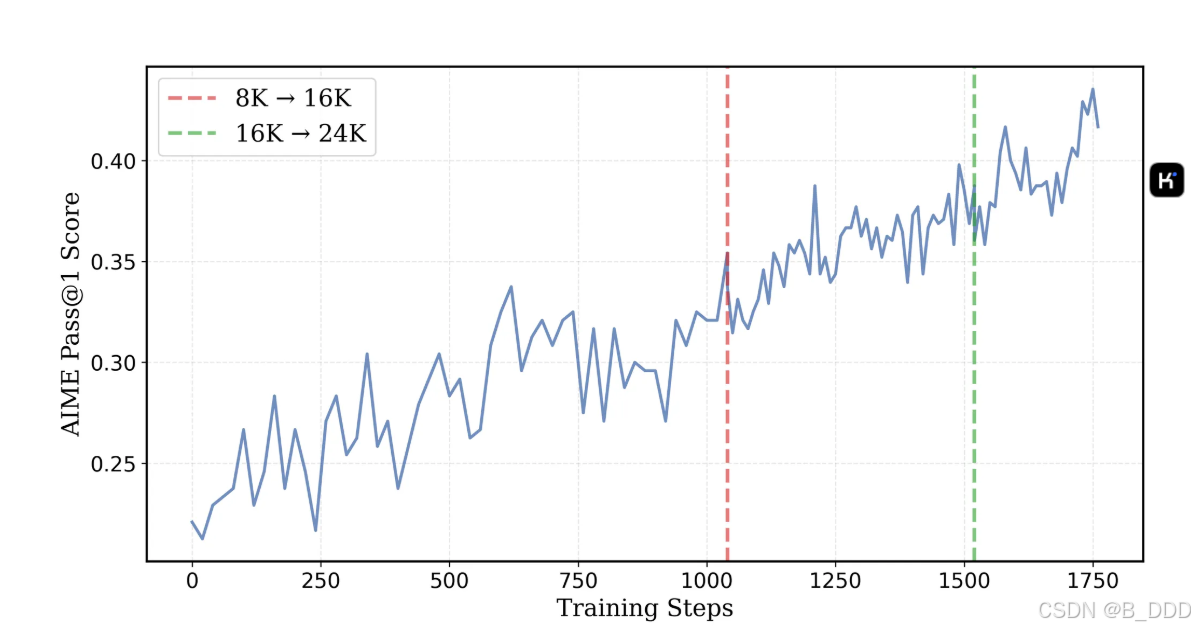
DeepScaleR-1.5B-Preview 是一种语言模型,使用 DeepSeek-R1-Distilled-Qwen-1.5B 进行微调,使用分布式强化学习 (RL) 扩展到较长的上下文长度。该模型在 AIME 2024 上实现了 43.1% 的 Pass@1 准确率,比基本模型 (28.8%) 提高了 15%,仅以 1.5B 参数超过了 OpenAI 的 O1-Preview 性能。
huggingface
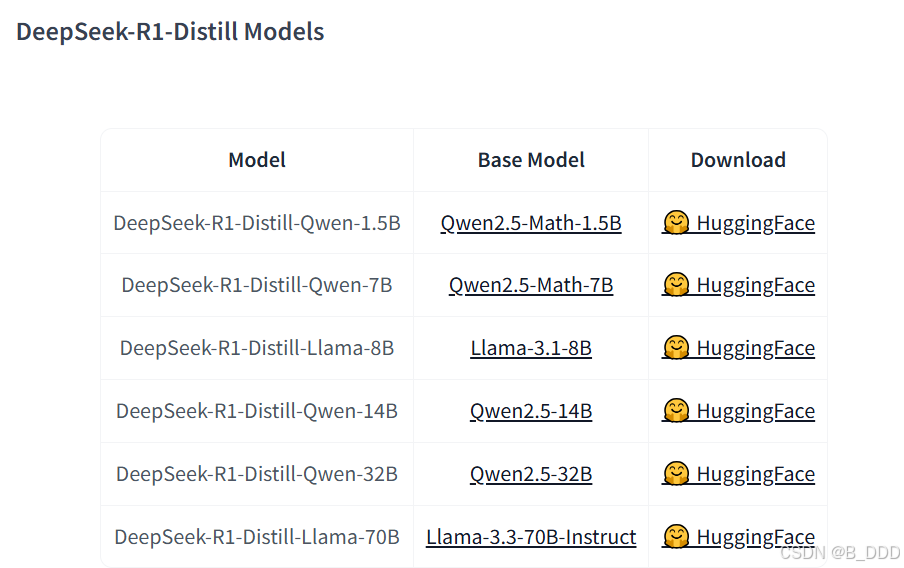
除了以上模型外,官方还发布了很多蒸馏模型
| Model | Base Model | Download |
|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | Qwen2.5-Math-1.5B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Qwen-7B | Qwen2.5-Math-7B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Llama-8B | Llama-3.1-8B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Qwen-14B | Qwen2.5-14B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Qwen-32B | Qwen2.5-32B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Llama-70B | Llama-3.3-70B-Instruct | 🤗 HuggingFace |
-
DeepSeek-R1-Distill-Qwen-1.5B
- Base Model: Qwen2.5-Math-1.5B
- Description: 这是一个基于Qwen2.5-Math-1.5B的蒸馏模型,模型大小为1.5B参数。
- Performance: 通常在推理速度和资源消耗方面优于原始模型,但可能在某些任务上略有精度损失。
-
DeepSeek-R1-Distill-Qwen-7B
- Base Model: Qwen2.5-Math-7B
- Description: 基于Qwen2.5-Math-7B的蒸馏模型,模型大小为7B参数。
- Performance: 在保持较高性能的同时,减少了模型大小和计算成本。
-
DeepSeek-R1-Distill-Llama-8B
- Base Model: Llama-3.1-8B
- Description: 基于Llama-3.1-8B的蒸馏模型,模型大小为8B参数。
- Performance: 提供了较好的平衡,在资源消耗和性能之间取得了良好的折中。
-
DeepSeek-R1-Distill-Qwen-14B
- Base Model: Qwen2.5-14B
- Description: 基于Qwen2.5-14B的蒸馏模型,模型大小为14B参数。
- Performance: 在大规模模型的基础上进行蒸馏,保留了大部分性能,同时减少了资源需求。
-
DeepSeek-R1-Distill-Qwen-32B
- Base Model: Qwen2.5-32B
- Description: 基于Qwen2.5-32B的蒸馏模型,模型大小为32B参数。
- Performance: 针对非常大的模型进行蒸馏,适用于需要高性能但资源受限的场景。
-
DeepSeek-R1-Distill-Llama-70B
- Base Model: Llama-3.3-70B-Instruct
- Description: 基于Llama-3.3-70B-Instruct的蒸馏模型,模型大小为70B参数。
- Performance: 针对超大规模模型进行蒸馏,提供了极高的性能,同时减少了资源消耗。
4OLLAMA上的各种量化是什么意思
量化类型
| 类型 | 介绍 |
|---|---|
| q2_K |
|
| q3_K_L |
|
| q3_K_M |
|
| q3_K_S |
|
| q4_0 |
|
| q4_1 |
|
| q4_K_M |
|
| q4_K_S |
|
| q5_0 |
|
| q5_1 |
|
| q5_K_M |
|
| q5_K_S |
|
| q6_K |
|
| q8_0 |
|
量化模型
量化一个未量化的模型。
请求
curl http://localhost:11434/api/create -d '{
"model": "llama3.1:quantized",
"modelfile": "FROM llama3.1:8b-instruct-fp16",
"quantize": "q4_K_M"
}'
响应
返回一个 JSON 对象流:
{"status":"quantizing F16 model to Q4_K_M"}
{"status":"creating new layer sha256:667b0c1932bc6ffc593ed1d03f895bf2dc8dc6df21db3042284a6f4416b06a29"}
{"status":"using existing layer sha256:11ce4ee3e170f6adebac9a991c22e22ab3f8530e154ee669954c4bc73061c258"}
{"status":"using existing layer sha256:0ba8f0e314b4264dfd19df045cde9d4c394a52474bf92ed6a3de22a4ca31a177"}
{"status":"using existing layer sha256:56bb8bd477a519ffa694fc449c2413c6f0e1d3b1c88fa7e3c9d88d3ae49d4dcb"}
{"status":"creating new layer sha256:455f34728c9b5dd3376378bfb809ee166c145b0b4c1f1a6feca069055066ef9a"}
{"status":"writing manifest"}
{"status":"success"}5Deepseek最近到底发布了多少模型
DeepSeek在近期发布了多个大模型,涵盖了不同的应用场景和技术特点。以下是具体的汇总:
一、基座模型(Foundation Models)

DeepSeek V3
参数量:671B
特点:作为基座模型,DeepSeek V3 是一个混合专家(MoE)语言模型,使用了 14.8T tokens 进行预训练,性能与 OpenAI 的 GPT-4 和 Anthropic 的 Claude-3.5-Sonnet 相媲美。
训练成本:约 557.6 万美元,显著低于其他顶级模型。
二、推理模型(Inference Models)

DeepSeek R1
基于 DeepSeek V3 进行后训练(SFT+RL),推理能力表现卓越,可与 OpenAI 的 O1 正式版对标。
特点:经过多轮强化学习迭代,提升了端侧模型的推理能力上限,API 定价低于海外同行。
三、多模态模型(Multimodal Models)

JanusPro
参数规模:1.5B 和 7B
特点:开源多模态模型,能够处理和生成多种模态的数据(如文本、图像、视频等)。
训练方式:仅使用 128 颗英伟达 A100 GPU 训练 7 天,成本极低。
性能:在多模态理解基准 MMBench 上得分 79.2,超越了 MetaMorph (75.2) 和其他竞品。
四、蒸馏模型(Distilled Models)
DeepSeek 还发布了一系列蒸馏模型,旨在降低资源消耗并保持高性能:
DeepSeek-R1-Distill-Qwen-1.5B
基于 Qwen2.5-Math-1.5B 蒸馏而来。
DeepSeek-R1-Distill-Qwen-7B
基于 Qwen2.5-Math-7B 蒸馏而来。
DeepSeek-R1-Distill-Llama-8B
基于 Llama-3.1-8B 蒸馏而来。
DeepSeek-R1-Distill-Qwen-14B
基于 Qwen2.5-14B 蒸馏而来。
DeepSeek-R1-Distill-Qwen-32B
基于 Qwen2.5-32B 蒸馏而来。
DeepSeek-R1-Distill-Llama-70B
基于 Llama-3.3-70B-Instruct 蒸馏而来。
6Deepseek到底是如何震惊了世界
在去年12月,由国内大模型公司“深度求索”开发的DeepSeek应用推出的DeepSeek-V3在全球AI领域掀起巨大波澜,它以极低的训练成本,实现了与GPT-4o等顶尖模型相媲美的性能。时隔不到一个月,DeepSeek又一次震动全球AI圈。
1月27日,随着DeepSeek推出新模型DeepSeek-R1,Deepseek应用登顶苹果中国地区和美国地区应用商店免费App下载排行榜,在美区下载榜上超越了ChatGPT。
DeepSeek当前所创造的“神话”,主要是两类叙事。第一类,是DeepSeek的算力成本投入与表现出来的性能对比,超出了行业的一般认知。据部分行业媒体报道,DeepSeek r1的训练成本仅为ChatGPT o1的零头。第二类神话则是,DeepSeek的成功证明了开源路线的逆袭胜利,对大公司、巨头的闭源路线进行了一次底层颠覆。
很多业内人士甚至喊出了“DeepSeek接班OpenAI”的口号。
比如,前Meta AI工作人员、知名AI论文推特作者Elvis就强调,DeepSeek-R1的论文堪称瑰宝,因为它探索了提升大语言模型推理能力的多种方法,并发现了其中更明确的涌现特性。
另一位AI圈大V Yuchen Jin则认为,DeepSeek-R1论文中提出的,模型利用纯RL方法引导其自主学习和反思推理这一发现,意义非常重大。
英伟达GEAR Lab项目负责人Jim Fan在推特中也提到了,DeepSeek-R1用通过硬编码规则计算出的真实奖励,而避免使用任何 RL 容易破解的学习奖励模型。这使得模型产生了自我反思与探索行为的涌现。
Jim Fan 甚至认为,它们做了OpenAI本来应该做的事,开源。

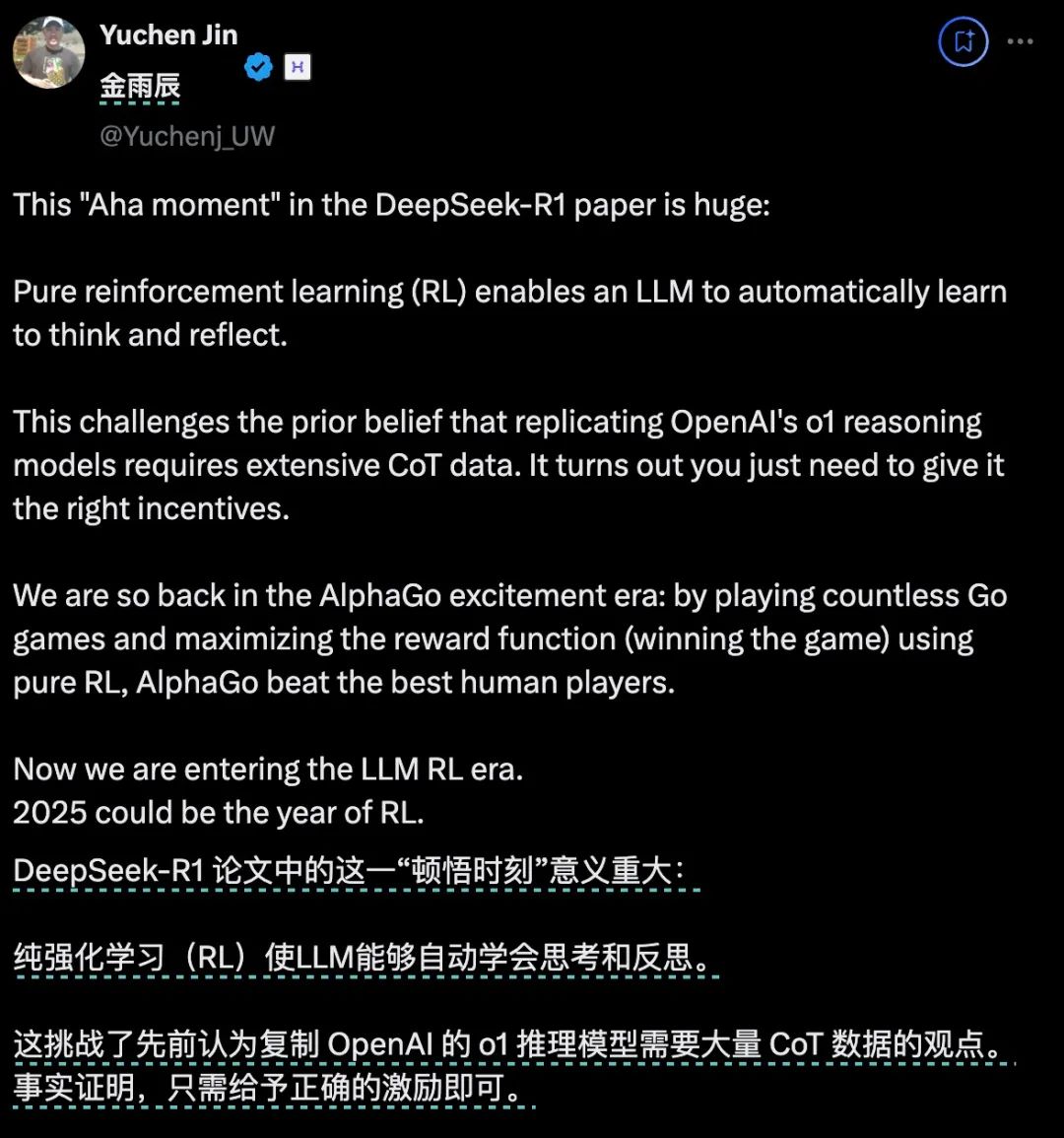
2025年1月27日至2月12日,Wind DeepSeek指数(1月26日发布)7个交易日暴涨58.29%,DeepSeek概念股并行科技同期暴涨234.73%。
DeepSeek指数和相关个股股价狂飙的背后,是AI(人工智能)大模型公司DeepSeek的横空出世,不仅震撼了美国,引发美国AI芯片巨头英伟达股价单日暴跌17%,同时也震撼了全球。
微软 CEO Satya Nadella 在达沃斯世界经济论坛上直言:“DeepSeek 新模型的表现令人印象深刻,尤其是在模型推理效率方面。我们必须认真对待来自中国的这些发展。”Scale AI 的 CEO Alexandr Wang 甚至将其称为一款“震撼世界的模型(earth-shattering model)”。“我们发现 DeepSeek...... 的性能与美国最好的模型不相上下。”
图丨 Alexandr Wang 相关采访(来源:CNBC)
事实上,DeepSeek-R1 的出现确实引发了硅谷的一场小型地震。沃顿商学院教授 Ethan Mollick 对 R1 的内部思考过程赞叹不已:“DeepSeek 的原始思维链非常迷人。它真的读起来就像一个人在大声思考。既迷人又奇特”。著名风险投资人、Mosaic 浏览器联合发明人马克·安德森也表示:“DeepSeek R1 是我见过的最令人惊叹和印象深刻的突破之一,作为开源项目,这是给世界的一份重要礼物。”这种开源精神甚至让一位软件工程师将“OGOpenAI.com”域名重定向到了 DeepSeek,以此暗示 DeepSeek 更像早期的 OpenAI,践行着开源 AI 的理念。


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 44
44 1
1- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)