DeepSeek 本地部署及接口调用
通过代码调用 Ollama 提供的 API 接口,实现模型的能力。如果需要,可以安装一个简易界面来使用模型。在 PyCharm 中运行输出。
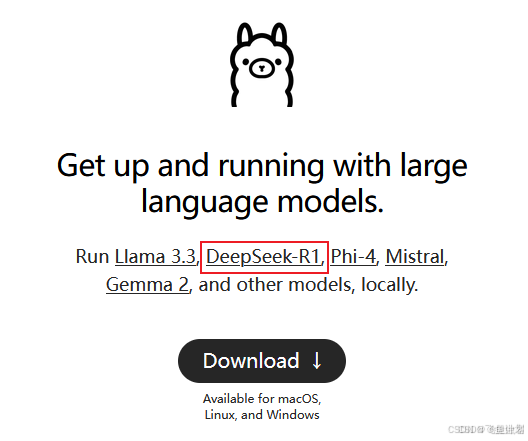
1、下载并安装 Ollama
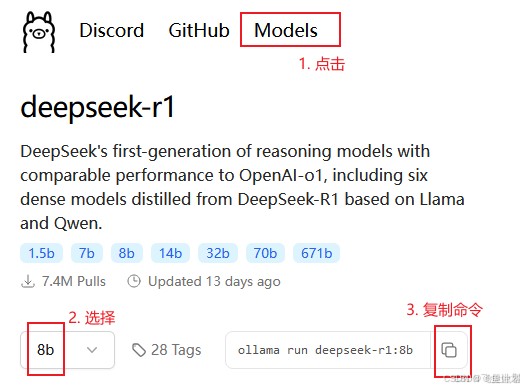
3、运行模型
ollama run deepseek-r1:8b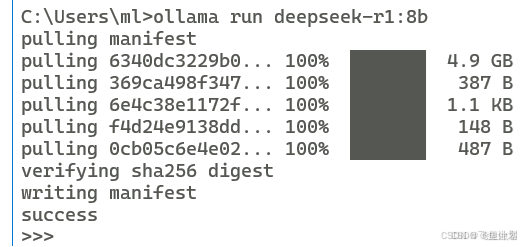
其它有用命令:
- 启动 Ollama 服务:
-
ollama serve - 查看当前模型列表:
-
ollama list
如运行模型成功后可以提问:

回答如下:
<think>
好的,现在我需要帮助用户理解DeepSeek的V3和R1模型之间的区别。用户之前问过公司推出的大模型,但现在更具体地询问了V3和
R1的不同。
首先,我应该明确这两个模型各自的定位。V3可能是一个通用的大模型,而R1可能专注于特定的领域,比如知识检索或对话应用。这
有助于用户理解它们在不同的应用场景中的用途。
接下来,功能特点方面,我需要列出关键区别,如模型架构、训练目标、性能优化等。V3可能在通用性上更强,而R1则针对高效率和
准确率进行了优化。
用户可能的需求是评估这两个模型是否适合他们的项目,或者了解它们之间的优劣比较。我应该以简明扼要的方式呈现信息,帮助用
户快速做出决策。
最后,总结部分需要简洁明了地指出V3和R1各自适用的场景,这样用户可以根据自己的需求选择最合适的模型。
</think>
4、使用 allama_gui
如果需要,可以安装一个简易界面来使用模型
- 安装:
python -m pip install ollama_gui - 运行:
-
python -m ollama_gui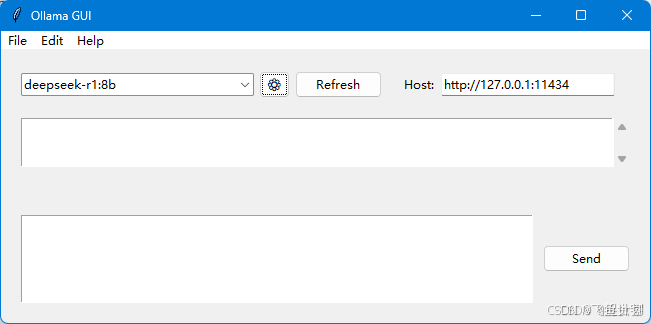
5、API 接口调用
通过代码调用 Ollama 提供的 API 接口,实现模型的能力
常用接口如下:
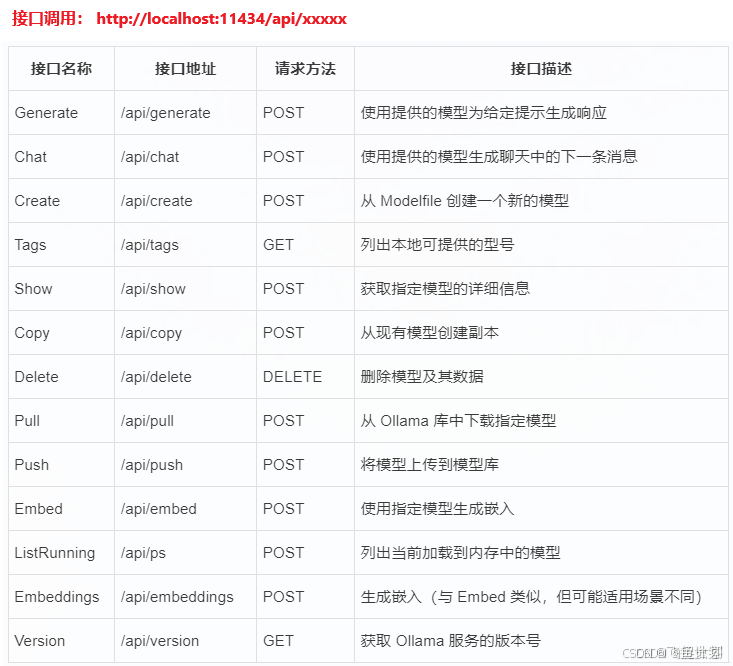
如:使用 api/chat 接口
import requests
# Ollama中提供的chat功能的API地址
url = 'http://127.0.0.1:11434/api/chat'
# 要发送的数据
data = {
"model": "deepseek-r1:8b",
"messages": [{
"role": "user",
"content": "北京的面积是多少?"}],
"stream": False
}
# 发送POST请求
response = requests.post(url, json=data)
# 打印模型的输出文本
print(response.json()["message"]["content"])在 PyCharm 中运行输出

二、定制化训练(Fine-tuning)
由于 Ollama 目前不支持直接在 Ollama 内训练模型,你需要使用 LoRA/QLoRA 或 全量微调,然后再将训练后的模型打包进 Ollama。
1. 训练方式
Ollama 主要支持的是 基于 Hugging Face Transformers 训练后,再打包到 Ollama,你可以选择:
LoRA/QLoRA(轻量微调):适用于本地训练,显存占用少。
全量微调(Full Fine-tuning):适用于大显存 GPU 服务器。
(1)LoRA 训练(推荐)
安装依赖:
pip install peft transformers accelerate bitsandbytes训练代码
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments, Trainer
from peft import get_peft_model, LoraConfig, TaskType
# 加载模型
model_path = "deepseek/deepseek-llm-7b"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto")
# 配置 LoRA
config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
r=8,
lora_alpha=32,
lora_dropout=0.1
)
model = get_peft_model(model, config)
model.print_trainable_parameters()
# 训练数据
train_data = [
{"input": "你好,你叫什么名字?", "output": "我是DeepSeek模型。"},
{"input": "1+1等于多少?", "output": "1+1=2。"}
]
# 数据格式化
train_encodings = tokenizer([d["input"] for d in train_data], padding=True, truncation=True, return_tensors="pt")
labels = tokenizer([d["output"] for d in train_data], padding=True, truncation=True, return_tensors="pt")["input_ids"]
training_args = TrainingArguments(
output_dir="./results",
per_device_train_batch_size=2,
num_train_epochs=1,
save_strategy="epoch"
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_encodings
)
trainer.train()
model.save_pretrained("fine_tuned_model")
tokenizer.save_pretrained("fine_tuned_model")这样,你的 LoRA 微调模型 就准备好了。
(2)全量微调(Full Fine-tuning)
全量微调会调整 所有模型参数,需要 大量 GPU 计算资源,建议:
GPU:A100 (80GB) 或多个 3090 (24GB)
CUDA & cuDNN:CUDA 11.8+
框架:Hugging Face transformers + DeepSpeed 或 FSDP(分布式训练)
2.1 安装依赖
先安装必要的 Python 库:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
pip install transformers datasets accelerate deepspeed bitsandbytes2.2 下载 DeepSeek 模型
Ollama 目前不支持直接训练,你需要 先用 Hugging Face 下载模型:
git clone https://huggingface.co/deepseek-ai/deepseek-llm-7b或者:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = "deepseek-ai/deepseek-llm-7b"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto")
2.3 准备训练数据
训练数据应采用 指令微调格式(如 Alpaca):
[
{
"instruction": "介绍一下 Python 的优点。",
"input": "",
"output": "Python 具有易学、社区活跃、库丰富等优点。"
},
{
"instruction": "计算 10 的平方根。",
"input": "",
"output": "10 的平方根是 3.162277。"
}
]存储为 train.json,然后加载:
from datasets import load_dataset
dataset = load_dataset("json", data_files="train.json")2.4训练配置
创建 train.py:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments, Trainer
from datasets import load_dataset
# 1. 加载模型和 Tokenizer
model_name = "deepseek-ai/deepseek-llm-7b"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model=AutoModelForCausalLM.from_pretrained(model_name,torch_dtype=torch.float16,device_map="auto")
# 2. 加载数据集
dataset = load_dataset("json", data_files="train.json")["train"]
# 3. 训练参数
training_args = TrainingArguments(
output_dir="./fine_tuned_model",
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
num_train_epochs=3,
save_strategy="epoch",
logging_dir="./logs",
report_to="none",
fp16=True,
optim="adamw_torch",
evaluation_strategy="epoch",
save_total_limit=2
)
# 4. 定义 Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset,
tokenizer=tokenizer
)
# 5. 训练模型
trainer.train()
# 6. 保存训练后的模型
model.save_pretrained("fine_tuned_model")
tokenizer.save_pretrained("fine_tuned_model")
运行:
python train.py三、重新部署到 Ollama
Ollama 支持自定义模型,你可以用 Modelfile 来创建一个新的模型:
1. 创建 Ollama 模型文件
在你的工作目录下创建 Modelfile:
FROM deepseek/deepseek-llm-7b
# 加载 Fine-tuned 模型
PARAMETERS_FILE ./fine_tuned_model/pytorch_model.bin
TOKENIZER ./fine_tuned_model/tokenizer.json2. 编译并添加到 Ollama
运行:
ollama create deepseek-custom -f Modelfile3. 运行定制模型
ollama run deepseek-custom总结
1.本地 Ollama 部署 DeepSeek
ollama pull deepseek/deepseek-llm-7b
或使用 Modelfile 来手动加载 DeepSeek 模型。
2.定制化训练
选择 LoRA/QLoRA(推荐)或者 全量微调。
使用 transformers + peft 进行训练。
3.重新部署
训练完成后,把模型打包进 Ollama:
创建 Modelfile
ollama create deepseek-custom -f Modelfile
运行 ollama run deepseek-custom
这样,你就可以在 Ollama 里运行自己的 Fine-tuned DeepSeek 了!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)