解读DeepSeek-V3技术要点
更令人瞩目的是,DeepSeek-V3的API价格仅为Claude 3.5 Sonnet的。近日,AI圈再度迎来重磅消息,DeepSeek团队正式发布了全新一代模型——DeepSeek-V3。这款模型不仅延续了“高性能、低成本”的传统,还首次开源了训练细节,迅速引发了业内的广泛关注。此外,DeepSeek-V3的发布也被视为开源AI领域的一次重要突破。DeepSeek-V3在多个基准测试中击败了G
近日,AI圈再度迎来重磅消息,DeepSeek团队正式发布了全新一代模型——DeepSeek-V3。这款模型不仅延续了“高性能、低成本”的传统,还首次开源了训练细节,迅速引发了业内的广泛关注。
DeepSeek-V3是一款671B参数的MoE(混合专家)模型,激活参数为37B,基于14.8T高质量数据进行预训练。其性能表现令人惊叹:不仅全面超越了Llama 3.1 405B,还能与GPT-4o、Claude 3.5 Sonnet等顶尖闭源模型正面竞争。更令人瞩目的是,DeepSeek-V3的API价格仅为Claude 3.5 Sonnet的1/15,堪称“性价比之王”。以下是几款主流模型的API价格对比:
从表中可以看出,其成本控制远超竞争对手,尤其适合需要大规模调用的开发者和企业。
1、技术亮点:如何做到极致?
DeepSeek-V3的成功离不开其背后的技术创新。以下是论文中提到的几大核心亮点:
-
高效的MoE架构:通过动态激活37B参数,显著降低了计算成本,同时保证了模型性能。
-
大规模高质量数据训练:14.8T高质量数据的预训练,使模型在多任务场景下表现卓越。
-
优化的推理速度:生成速度提升3倍,每秒生成60个tokens,大幅提升了用户体验。
-
开源透明:首次公开训练细节,为研究者和开发者提供了宝贵的参考。
社区反响:一片赞誉
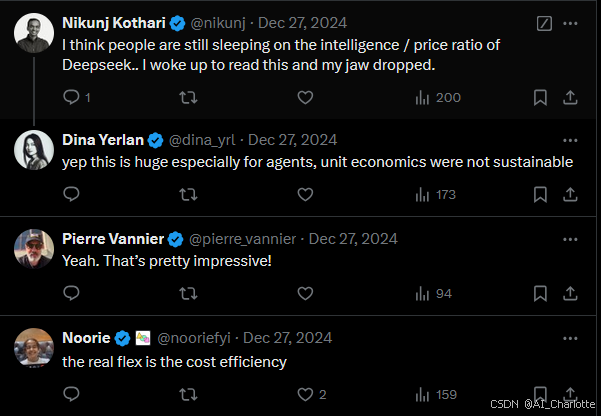
DeepSeek-V3的发布在社交媒体上引发热烈讨论,许多业内人士对其性能与成本的平衡表示赞叹:
Nikunj Kothari:“我觉得大家还没有意识到DeepSeek在智能与性价比上的优势。今天早上看到这个消息,简直惊呆了。”Dina Yerlan:“这对AI代理尤其重要,单元经济学的可持续性终于有了突破。”
Noorie:“真正的亮点是成本效率。”
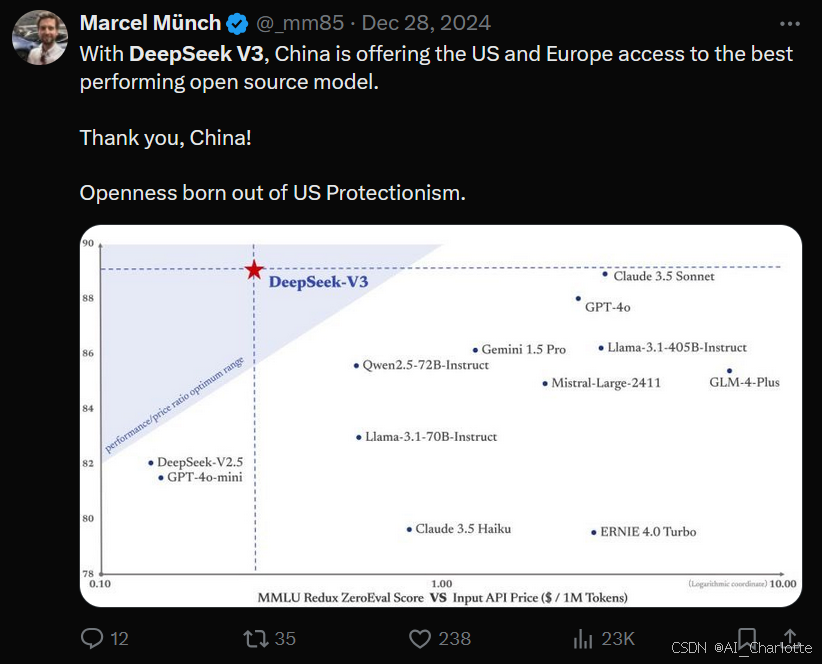
此外,DeepSeek-V3的发布也被视为开源AI领域的一次重要突破。正如Marcel Münch所言:“中国通过DeepSeek-V3为欧美市场提供了性能最强的开源模型。这是中国科技公司在美国保护主义下的胜利。”
性能超越闭源模型
DeepSeek-V3在多个基准测试中击败了GPT-4o和Claude 3.5 Sonnet,成为开源领域的佼佼者。它不仅快,还支持联网功能,并且完全免费试用!
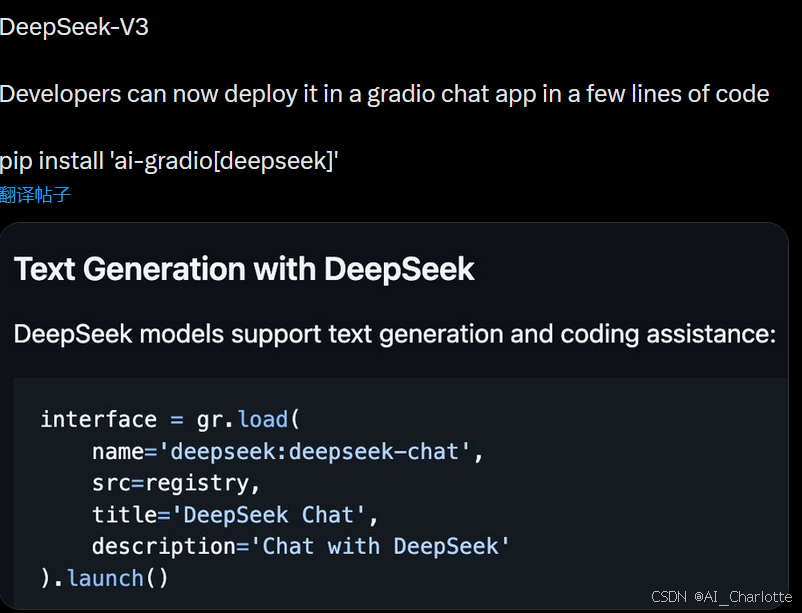
轻松部署,开发者友好
只需几行代码即可通过Gradio快速部署DeepSeek-V3,支持文本生成和代码辅助功能,极大降低了开发门槛:
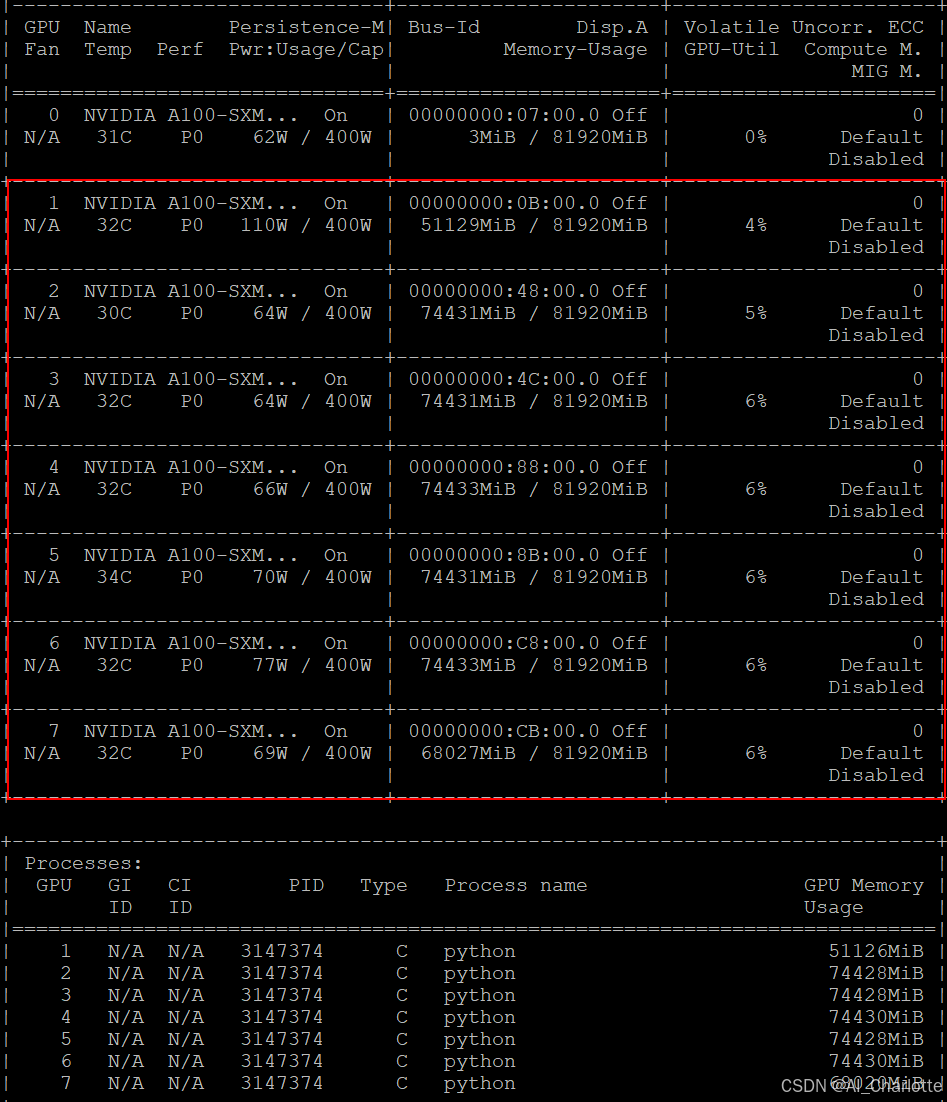
高效算力利用,资源友好
运行半参数的DeepSeek-V2仅需7张80G A100显卡,占用490G显存。暗示着本地私有部署DeepSeek-V3也变为可能:
最后:欢迎想要使用deepseek14b、32b、70b不同版本体验的小伙伴们后台私信我哦~

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)