新年逼自己一把,学会使用DeepSeek R1
举这个例子是想告诉你,大模型看到的世界和你看到的世界是不一样的。而在Deep Seek R1模型下,你只需要清晰明确地表达你的需求就好了,就像你拥有一个比你聪明得多的清北毕业的而且具有10年工作经验的下属,你不需要一步步地套路他指导他的工作,你只需要把所有他需要知道的信息告诉他,然后将你的。当你让Deep Seek帮你完成某项工作时,提供充分的上下文背景信息,告诉它你为什么要做这件事,你面临的现实
-
使用R1的关键点
理解工作原理和局限: 第一你需要理解大语言模型的工作原理和局限,这能帮助你更好地知道AI可完成任务的边界。
管理者的思维和经验: 第二就是在和R1合作时,你最好有管理者的思维和经验,你需要知道如何向R1这个聪明程度比你更高的下属去布置你的任务。
-
使用Deep Seek R1的经验
我为你准备了19条帮助你更好使用Deep Seek R1的经验,包括五个大语言模型的特点,趋向于R1对话的技巧,以及现在作用不达大落后提示词技巧。
-
使用前的建议
尝试使用Deep Seek: 在做任何深入的介绍之前,如果你还没使用过Deep Seek的话,我强烈建议你先去做一些尝试,再回来看这个视频,效果会更好一些。
-
使用时的注意事项
深度思考选项:
关于深度思考这个选项,如果你需要一个更简单和快速的回答,那你不必打开深度思考模式,使用它的默认模型V3就可以了。
当你需要完成更复杂的任务,希望AI输出的内容更结构化、更深思熟虑时,你应该打开深度思考R1的选项,这也是我们今天这个视频在讨论的模型。
联网搜索:
这几天的话,Deep Seek的联网搜索可能还处在不太能够使用的状态,但当你发现它可以使用之后,你需要注意,如果你的任务所涉及的知识是在2023年12月之前,那你其实不太有必要打开联网搜索功能,因为大模型本身就有在此之前被充分训练过的语料知识。
但是如果你所涉及的任务知识是在2023年12月及之后,比如你想了解昨天NBA比赛的赛果或者想知道最近硅谷对R1的评价等等,那你必须打开联网搜索功能,否则大模型在回答时会缺乏对应的知识。
-
模型特点
与指令模型的区别:
(Deep Seek的R1是个与你日常使用的对话类AI非常不同的模型。像OpenAI的GPT-4、Deep Seek的V3或者豆包等模型都属于指令模型,也就是Instruct Model。)
这类模型是专门设计用于遵循指令来生成内容或执行任务的。
而Deep Seek R1则属于推理模型Reasoning Model,它是专注于逻辑推理问题解决的模型,能够自主处理需要多步骤分析、因果推断或者复杂决策的任务。
知名推理模型: 实际上还有一个非常知名的模型就是OpenAI o1,它也是推理模型,但是你必须花20美元成为Plus用户才能使用,并且即使你成了Plus用户,你每周也只有50次的使用权限。如果你想要更多的使用权限,那请你掏出200美金,每月的费用也就是1437元。
而Deep Seek R1现在是完全免费的。
实际体验: 从我实际的体验来说,R1在大量的写作、写代码的任务上甚至比R1要更强一些。按理说R1是一个擅长数学推理、编程竞赛的模型,它在这些任务上上场其实非常合理。但是非常令人意外的是,在有了这种超强的推理能力之后,R1似乎在所有任务上都获得了质的飞跃,涌现出了一些意料之外的技能。
-
大语言模型的局限性
提示词技巧的减少:
在原本指令模型的时代,AI的能力是受到很强的限制的,你需要通过提示词的各类技巧才能激发模型更好的表现。而对普通人来说,学这些技巧实在是让人头大不已。而在Deep Seek R1模型下,你只需要清晰明确地表达你的需求就好了,就像你拥有一个比你聪明得多的清北毕业的而且具有10年工作经验的下属,你不需要一步步地套路他指导他的工作,你只需要把所有他需要知道的信息告诉他,然后将你的任务布置下去就可以了。
任务布置: 但是如何布置任务呢?我觉得首先你得需要知道这个下属的特点,所以我们先来了解一下大语言模型的本质特征。
-
大语言模型的本质特征
1.内容token化:
大模型在训练时是将内容token化的。大模型所看到和理解的世界和你我是不一样的。在理解模型行为之前,我们需要了解它是如何学习的。大型语言模型的预训练本质上是让模型建立文本片段之间的关联规律。为了实现这个目标,所有训练的数据,包括书籍、网页对话记录等等,都会经过特殊处理。首先他们会将文本切割成称为token的基本单元,就类似于文字的碎片,然后会将这些token转化为数字编码。这个过程就像把现实世界的语言翻译成只有模型能理解的密码本。
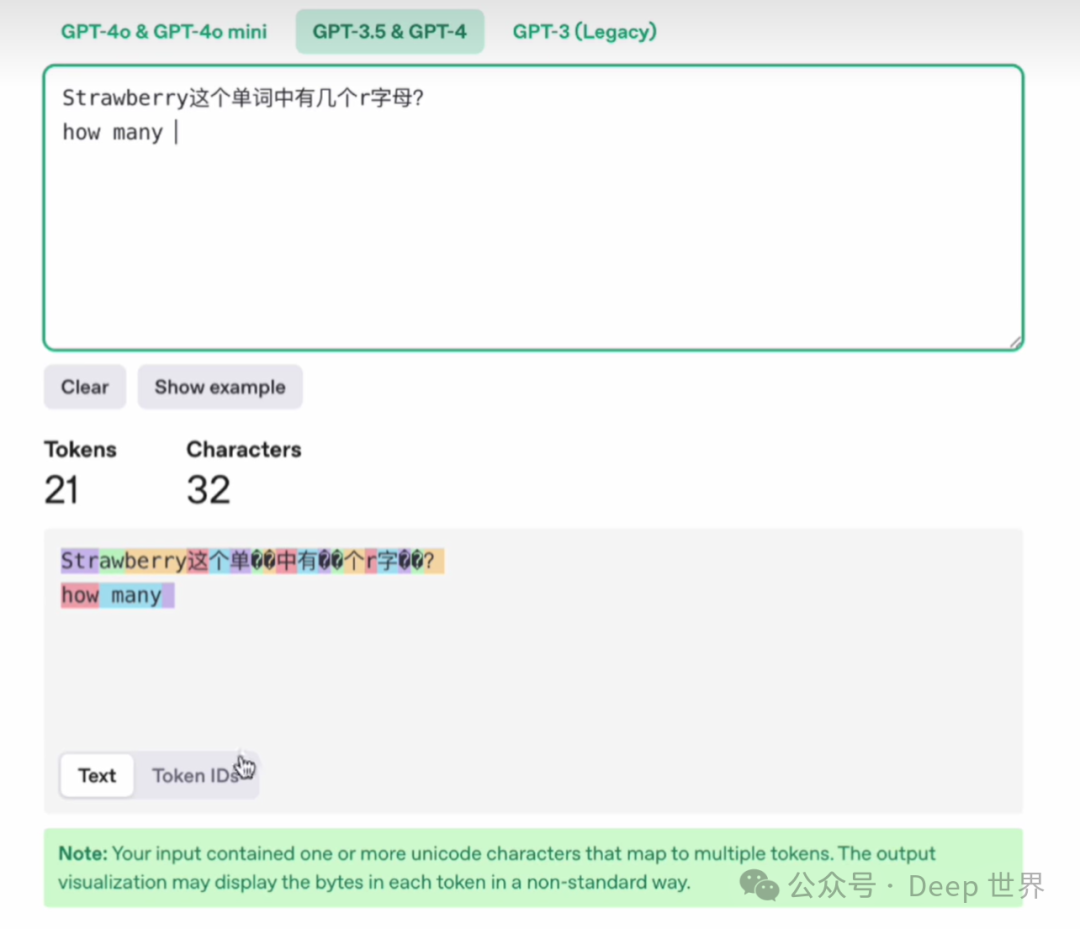
strawberry单词: 而在推理模型出来之前,很多人非常喜欢用一个问题来考察大模型的智商,就是strawberry这个单词有几个字母R。很多时候指令模型会回答错误,这不是因为模型不够聪明,而是它在被训练时的特点导致了这个结果。比方说GPT-3.5和GPT-4在训练的时候,词这个字被拆分成了两个token,strawberry则被拆分成了三个token,分别是STRAW和BERRY。
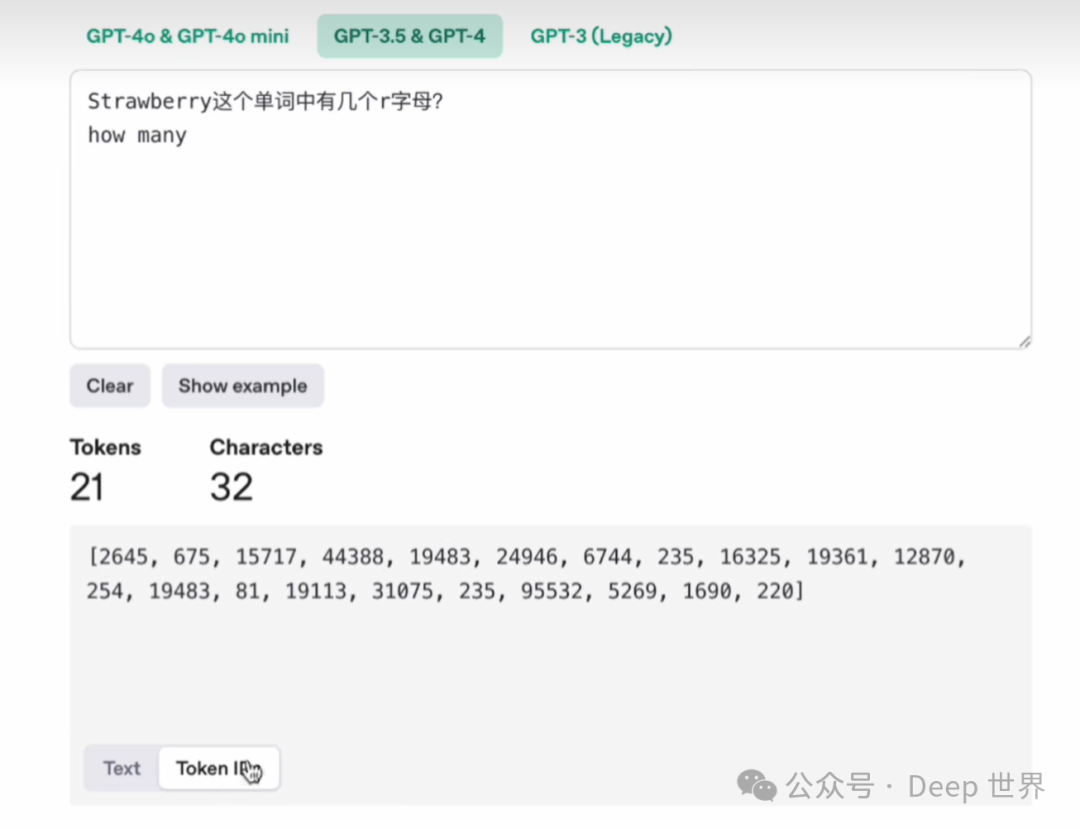
举这个例子是想告诉你,大模型看到的世界和你看到的世界是不一样的。当你在数字母时看到的是连续的字符流,而模型看到的却是经过编码的token序列。所以类似于数单词中的字母数量或者精确的要求,大模型为你输出特定字数的内容都是有些强模型所难的。它的机制决定了它不擅长处理这些任务。当然现在推理模型可以完成我例子中的这些任务,但是你看看它的推理过程,是不是觉得还是有一些费劲,有一些于心不忍呢?
2.知识截止时间:
大模型的知识是存在截止时间的
虽然Deep Seek R1在2025年1月才正式发布,但是它的基础模型的训练数据的窗口确实在很早之前就已经关闭了。具体来说,对大模型来说,它是有三重的时间壁垒。第一个是它预训练的阶段需要处理PB级别的原始数据,而这种原始数据的清洗需要经过大量的工序,会占用非常多的时间。
而且在训练完成之后,它还要经过监督微调强化学习以及基于人类反馈的强化学习等等,而这部分也是占据对应的时间。所以像Deep Seek R1,它的知识库截止时间大概是2023年的10月到12月左右。
认知局限:
而这种知识的滞后性,它其实会带来两个层面的认知局限:
①行业认知断代的问题,模型训练完成之后出现的许多新事物,比如GPT-4、Claude 3.5sonnet模型,这些都是没有办法被Deep Seek R1自动识别和理解的。
②重大事件: 外训练之后发生的一些重大事件,像最近2025年的春晚或者2024年的巴黎奥运会,其实Deep Seek也不太了解这些事件。
所以这些其实都是模型训练的特点导致的。
很多人拿类似的任务去问R1,然后发现R1答非所问,就轻易得出R1模型太差的结论,这是一个非常错误的思维。
突破知识限制:
如果你想突破这种知识限制,其实也是可以的。
-
你可以去激活联网搜索功能,给R1提供自主搜索和查找信息的权利。
-
你可以自主去补充一些必要的知识,比如上传文档或者在提示词里补充必要的信息,再让R1去执行。
3.缺乏自我认知和自我意识:
大模型一般都是缺乏自我认知和自我意识的。多数模型其实都不知道自己叫什么、什么模型,这是很正常的现象。
这种自我认知的缺乏其实会带来两个问题。第一个问题是AI有时候会给出错误的自我认知,比如Deep Seek还有很多别的模型,它们经常会认为自己是ChatGPT。这主要原因是因为ChatGPT在2022年底发布后,很多人把自己和ChatGPT的对话内容发布到了网上。所以你在问一个模型你是谁的时候,经常会出现对应的幻觉。另一个问题是你也没法让Deep Seek R1告诉你它自己有什么样的特点,使用它有什么技巧等等。这也是我依然要使用大量我自己的脑力去做这期视频的原因。
4.记忆的限制:
多数模型其实都是有上下文长度的限制。Deep Seek R1现在提供的上下文长度只有64K的token,对应到中文字符大概是34万字。
这带来的问题是你没有办法一次投喂太长的文档给它。比如你给它投喂一本红楼梦,你可以理解为它没有办法完整地读这本书的内容,而是在你对话时,它会通过RAG,也就是检索增强的方式去读取你提供的文档中的部分内容进行回答。
所以它不是完整读你提供的所有资料。另外当你和它对话的轮次过多时,它很可能会遗忘你们最初聊天的那部分内容。这部分的限制在你开展AI写代码的任务时,你的感受可能会尤其明显。
5.输出长度的限制:
相比上下文对话的输入长度,大模型的输出长度会更短很多。多数模型会将输出长度控制在4K或者8K,也就是单次对话最多给你回答两千到四千个中文字符。
所以你有些任务没有办法去做。你没有办法复制一篇万字的长文让Deep Seek一次性完成翻译。
你也不能让Deep Seek一次性帮你写一篇5000字以上的文章。
这些都是模型输出长度的限制导致的。你需要理解这个问题的存在。如果你要解决这个问题,像长文翻译类的任务,你可以通过多次复制或者自己写代码调用API多次执行的方式帮你完成一篇长文甚至一本书的翻译。而长文写作类的任务,比较妥当的做法是你先让R1梳理框架,列出提纲目录,然后再根据目录一次次分别生成不同阶段的内容。
-
R1使用技巧
技巧一:提出明确的要求: 能说清楚的信息,不要让Deep Seek去猜。
在我们的这个例子里,我们让它写一个为服饰跨境电商设计的30天新用户增长计划,我们期望突破的市场是哪里,我们希望方案中包含什么,这会比仅仅让它写一个跨境电商平台方案要好很多。
技巧二:要求特定的风格:
具有思维链的R1在进行特定风格的写作时,相比其他模型,我发现它已经出现了断层领先的水平。
比如你可以让R1用李白的风格写诗,按贴吧暴躁老哥的风格骂人,用鲁迅的文风进行讽刺,或者模仿任意作家风格进行写作,按脱口秀演员风格创作脱口秀脚本等等。
其他模型在这方面的表现都追不上R1的车尾。在这个模式下有个很有效的表达方式是让R1说人话,或者让R1认为你是初中生,这样就能把复杂的概念简化为你更容易理解的解释。又或者你完全可以尝试特定风格的写作,比如让它用半古佛仙人的风格写一篇吐槽虎扑步行街用户的公众号文章,R1甚至连表情包都帮我想好了
技巧三:提供充分的任务背景信息
当你让Deep Seek帮你完成某项工作时,提供充分的上下文背景信息,告诉它你为什么要做这件事,你面临的现实背景是什么,或者问题是什么,让Deep Seek将其纳入所生成文本的思考中,这可以让结果更符合你的需要。
比如你要Deep Seek帮你生成减肥计划时,你最好告诉它你的身体状况,你目前的饮食摄入和运动情况,这样它就能帮你生成一个更有针对性的计划。
技巧四:主动标注自己的知识状态
当你向Deep Seek寻求知识型的帮助时,最好能明确标注自己相对应的知识状态。
有点像老师备课前需要了解学生的能力水平,清晰的知识坐标能让AI输出的内容更精确地匹配你的理解层次。
像我们前面提到的,告诉R1我是初中生或者我是小学生是一个把自己放置在一个知识背景约等于零的知识状态的好方式。但是当某些内容你希望能和AI深入探讨时,你最好能更清晰表达你在这个领域的知识状态,或者你是否存在关联领域的知识,这样能帮助AI更好地理解你,为你提供更精确的回答。
技巧五:定义目标而非过程
R1作为推理模型,现在完成任务的思维过程是非常令人印象深刻的。所以我很建议你提供清楚你的目标,让R1具有一定的思考空间去帮助你执行得更好,而非提供一个机械化的执行指令。
你应该像产品经理提需求那样描述你想要什么,而不是像程序员写代码那班就是规定怎么做。
举个例子,比方说你的产品评审会在开完之后,你可能需要整理录音的文字稿。一种做法是,你可以直接要求R1去帮你进行文字稿的整理,就比方说删掉语气词,按时间分段,每段加小标题等等,这也是一个非常清晰明确的一个优质的提示语啊。但是你同样可以进一步思考下,就是这段录音文字稿所总结出的材料要如何用,你去为R1提供目标,让他创造性地帮助你去完成任务。
技巧六:提供AI不具备的知识背景
我们在第二部分的时候就提到过了,AI模型具有知识截止时间的那个特性。
当任务涉及到模型训练截止之后的新信息的话,就以R1来说,现在24年的一些赛事结果或者行业趋势,它都是不具备的。或者有些情况下,你们公司可能有一些内部的信息是AI不知道的。
那么你就需要去帮R1拼上那块他缺失的那个拼图,通过结构化的输入去帮助AI突破知识的限制,避免让它因为信息的缺乏而出现这种错误的回答。
技巧七:从开放到收敛
R1的思维链是全透明在你面前展开的。我常常会觉得我从R1思考的过程中能收获的信息比他给我提供的结果还多。
尤其是他在展开思考你提的需求时,会做一个可能性的预测。
有时在看这部分推测后,你才会发现自己原来有些方面的信息是没有考虑到的。如果你把对应的信息补充的更完善的话—通过思考过程不断收敛,那么就不需要R1再去猜了。
所以R1能在这种情况下为你提供更精确的、更符合你需要的结果。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 53
53 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)