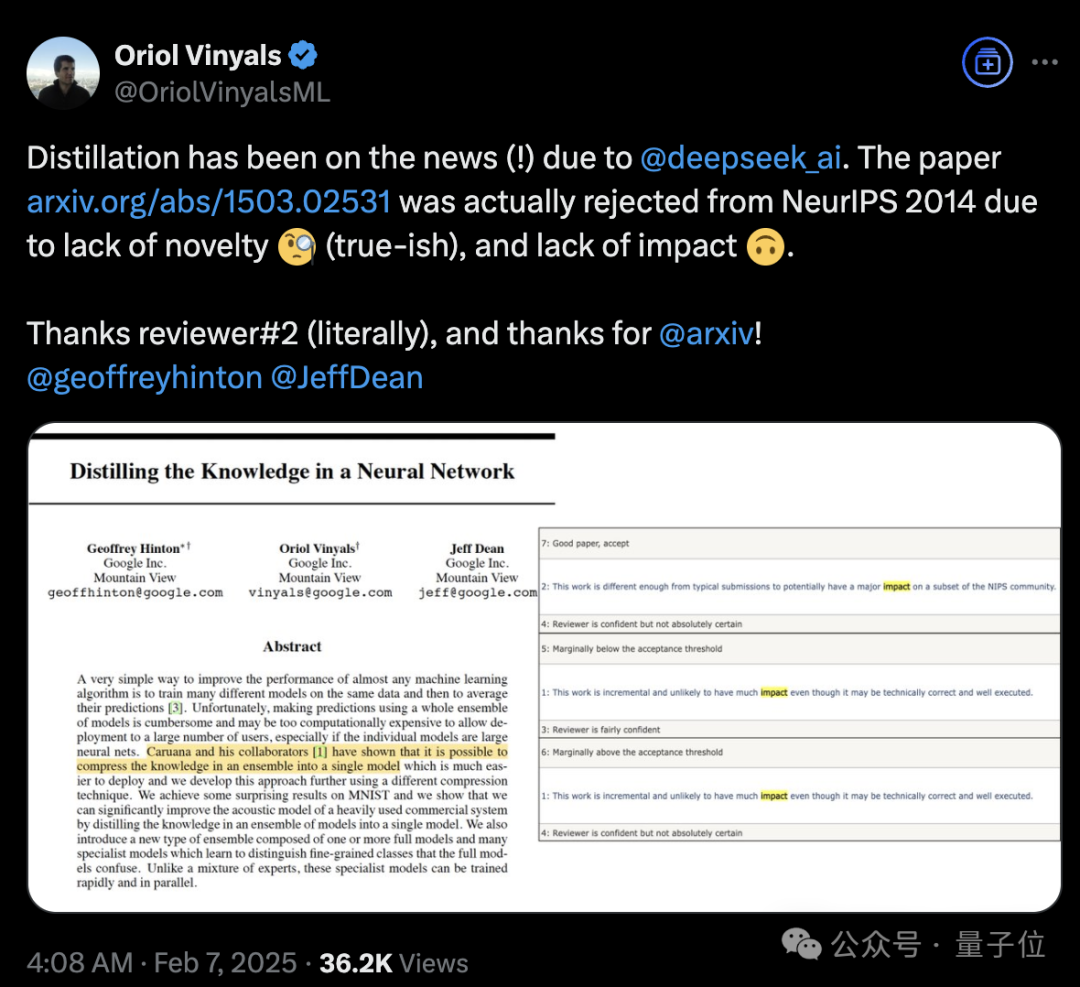
被DeepSeek带火的知识蒸馏,开山之作曾被NeurIPS拒收,Hinton坐镇都没用
称得上是“蒸馏圣经”、由Hinton、Oriol Vinyals、Jeff Dean三位大佬合写的**《Distilling the Knowledge in a Neural Network》**,当年被NeurIPS 2014拒收。如何评价这篇论文的含金量?它提出了知识蒸馏这一概念,能在保证准确率接近的情况下,大幅压缩模型参数量,让模型能够部署在各种资源受限的环境。自它之后,大模型用各种方法提
DeepSeek带火知识蒸馏,原作者现身爆料:原来一开始就不受待见。
称得上是“蒸馏圣经”、由Hinton、Oriol Vinyals、Jeff Dean三位大佬合写的**《Distilling the Knowledge in a Neural Network》**,当年被NeurIPS 2014拒收。
如何评价这篇论文的含金量?
它提出了知识蒸馏这一概念,能在保证准确率接近的情况下,大幅压缩模型参数量,让模型能够部署在各种资源受限的环境。
比如Siri能够出现在手机上,就是用知识蒸馏压缩语音模型。
自它之后,大模型用各种方法提高性能上限,再蒸馏到小模型上已经成为一种行业标配。

再来看它的主创阵容。
Hinton,深度学习之父,如今已是诺奖得主。
Oriol Vinyals,Google DeepMind研究科学家,参与开发的明星项目包括TensorFlow、AlphaFold、Seq2Seq、AlphaStar等。
Jeff Dean,Google DeepMind首席科学家、从2018年开始全面领导谷歌AI。大模型浪潮里,推动了PaLM、Gemini的发展。
不过,那又怎样?
主创之一Oriol Vinyals表示,因为缺乏创新和影响力,这篇论文被拒啦。谢谢审稿人(字面意思),谢谢arxiv!
方法简单、适用于各种模型
简单粗暴总结,《Distilling the Knowledge in a Neural Network》是一篇更偏工程性改进的文章,但是带来的效果提升非常显著。
Caruana等人在2006年提出了将集成知识压缩到单模型的可能性,论文中也明确提到了这一点。
Hinton等人的工作是提出了一种简单有效的知识迁移框架,相较于Caruana团队的方法更加通用。
方法看上去非常简单:
-
用软目标代替硬目标
-
在softmax层加入温度参数T。当T=1时,就是普通的softmax输出。T越大,输出的概率分布越平滑(soft)。
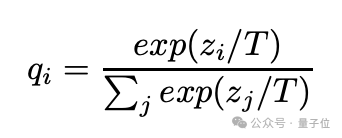
他们认为此前人们习惯性地将模型中的知识与模型的具体参数绑定在一起,因此很难想到该如何在改变模型结构的同时仍旧保留这些知识。
如果把知识看作是输入向量到输出向量的一个抽象映射,而不是某种固定的参数实现,就能更容易理解如何将知识从一个模型转移到另一个模型。
知识蒸馏的关键就是让小模型模仿大模型的“理解方式”,如果大模型是多个模型的集成,表现出很强的泛化能力,那就通过蒸馏训练小模型去学习这种泛化方式,这种方法能让小模型集成大模型的知识精髓,同时更适合实际应用部署。
怎么将泛化能力转移?
让大模型生成类别概率作为软目标,以此训练小模型。
在这个转移阶段,使用与原始训练相同的数据集,或者单独准备一个“迁移”数据集。
如果大模型是由多个模型集成,那就取它们的预测平均值。
软目标的特点是,它具有高熵时(即预测的概率分布更平滑),每个训练样本中包含的信息量比硬目标要多得多,训练样本之间的梯度变化也更小。
因此,用软目标训练小模型时,往往可以使用比原始模型更少的数据,并且可以采用更高的学习率。
小模型可以用无标签数据或原始训练。如果用原始训练数据,可以让小模型同时学习来自大模型的软目标和真实标签,这样效果会更加好。
具体方法是使用软目标的交叉熵损失、真实标签的交叉熵损失两个目标函数加权平均。如果真实标签的交叉熵损失权重较小时,往往能获得最佳效果。
此外,他们还发现软目标的梯度大小随着T²缩放,同时使用真实标签和软目标时,比如将软目标的梯度乘以T²,这样可以确保在调整蒸馏温度这一超参数时,硬目标和软目标的相对贡献保持大致不变。
实验结果显示,在MINIST数字时延中,教师模型(1200层)的错误案例为67个,学生模型(800层)使用蒸馏后的错误案例为74个。
在JFT数据集上,基准模型的错误率为27.4%,集成模型的错误率为25%。蒸馏模型错误率为25.6%,效果接近集成模型但计算量大幅减少。
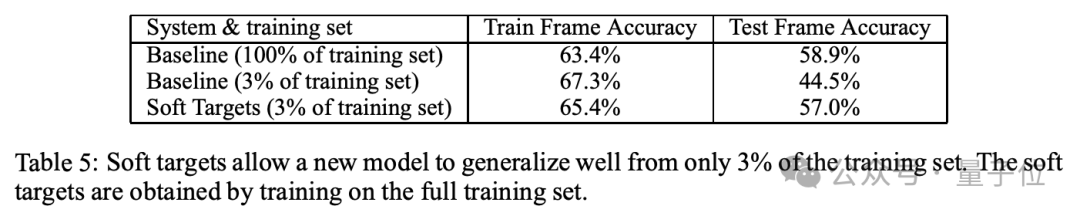
语音识别实验上,蒸馏模型也达到了与集成模型相同的性能,但是仅使用了3%的训练数据。
或许还有很多沧海遗珠
值得一提的是,Vinyals还表示,提出了LSTM的Jürgen Schmidhuber在1991年发表的一篇文章,这可能与现在火热的长上下文息息相关。
他提到的应该是**《Le****arning complex, extended sequences using the principle of history compression》**这篇论文。其核心内容是利用历史压缩的原则,即通过模型结构和算法将序列的历史信息有效地编码和存储,从而减少处理长序列时的计算开销,同时保留关键的信息。
有人就说,不妨设置一个时间检验奖颁给那些未被接收的论文吧。

同时也有人在这个话题下想到了DeepSeek。
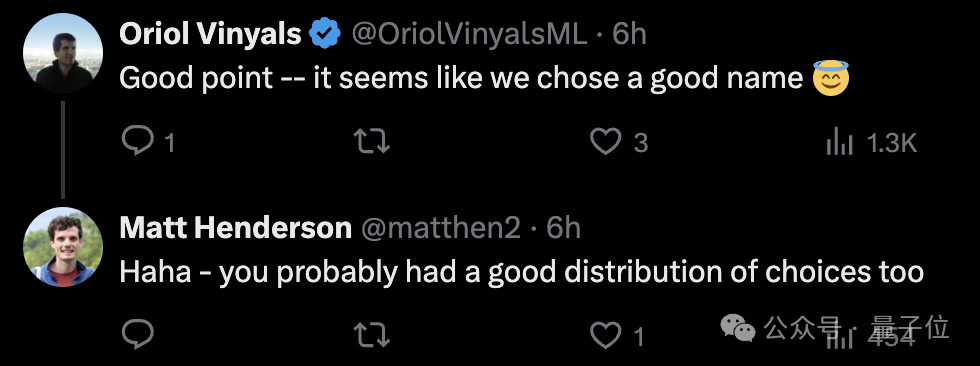
曾在苹果、谷歌工作过的Matt Henderson表示,DeepSeek做的蒸馏只是基于教师模型输出的微调,并没有用到软目标(因为模型的分词方式不同)。

Vinyals回应说,那看来我们取蒸馏这个名字真的不错~
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)
👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)

👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 29
29 0
0- 0



 已为社区贡献53条内容
已为社区贡献53条内容

所有评论(0)