
本地用 ollama跑DeepSeek真的质量不好吗?真相是什么?
针对一些视频号、自媒体说不要在本地跑ollama里的deepseek我写一文来向大家说明真相其实不是这样的。学以致用,知其然更要知其所以然。
开篇
最近很多网上视频号咬牙切齿、摇头晃脑的告诉大家不要本地跑ollama的deepseek,因为量化了INT4了。
很多人听了都一震一震的。作为参与过ollama相关开发的一员我首先要告诉大家,这个说话已经完全错误了。
量化了的INT4?are you sure?
先来看ollama里的量化吧,查一下不就知道了?
查看模型的量化指标
打开ollama命令我们用
ollama list
如果你装了多个模型在这你是可以看到它们的NAME的。
接着我们键入命令
ollama show deepseek-r1:14b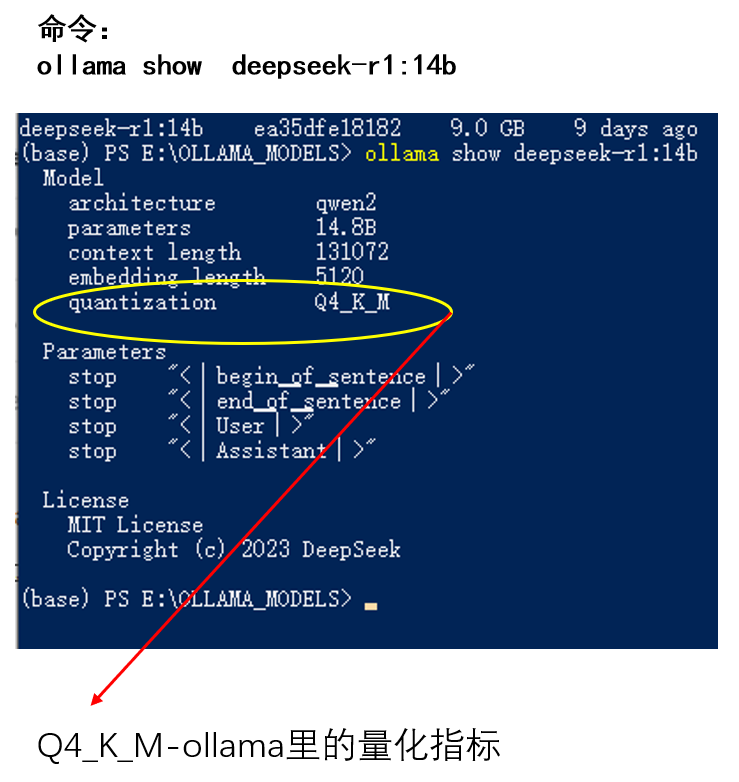
什么是ollama里的量化呢?
1. FP32(单精度浮点数)
- 32位浮点数,最高精度,占用内存最大,计算速度最慢,适合训练和需要高精度的场景。
2. FP16(半精度浮点数)
- 16位浮点数,内存占用和计算速度优于FP32,但存在数值溢出风险(如梯度消失/爆炸)。
3. BF16(Brain Floating Point 16)
- 16位格式,动态范围与FP32接近,适合Ampere架构GPU(如A100),在训练中更稳定。
4. 混合精度(Mixed Precision)
- 结合FP16/FP32:用FP16加速计算,用FP32保存关键参数(如权重、梯度),通常配合NVIDIA的AMP(自动混合精度)使用。
5.INT8(8位整数量化)
- 将模型权重和激活值量化为8位整数,显著减少内存占用和计算成本,但可能损失精度。
6.INT4(4位整数量化)
- 更激进的量化方式,模型体积进一步缩小,但对精度影响较大,常用于边缘设备推理。
7. 其他量化技术
- GPTQ:基于梯度的后训练量化方法,支持4/3/2位量化。
- AWQ(Activation-aware Weight Quantization):通过保留关键权重的高精度提升效果。
- GGUF:Ollama使用的量化格式(如q4_0、q5_k等),支持多种量化级别。
那么Q4_K_M-ollama意味着什么?
真如一般视频号里说的这是4位量化吗?
4位量位是INT4!
那 Q4_K_M和 INT4 有啥区别?都代表了参数用 4 位表示吗?
简单理解INT4是对所有参数进行了量化,而 Q4_K_M 对权重进行了分组具体量化过程可以自行查询 AI。
Q4_K_M:
在llama.cpp的评测中,7B模型的Q4_K_M量化版与FP16相比,常识推理(如PIQA)得分下降约3%,但生成流畅度接近原模型。
INT4:
直接INT4量化可能导致生成结果出现逻辑错误或重复(如HuggingFace的AutoGPTQ-4bit模型需额外校准)
性能与质量的比较
Q4_K_M
在RTX 3090上,7B模型推理速度约25 token/s,显存占用约5GB。
INT4:
相同硬件下速度可达30 token/s,显存占用仅3.5GB,但需牺牲更多质量。
放心大胆的用ollama中的模型吧

Q4_K_M适合于中小型企业本地廉价布署
- 用50-75家连锁门店的中小型商铺来说,用ollama布署14B的DeepSeek R1可以连续的批处理上百万sku的数据清洗、打标签,全程流畅。
- 用商铺数据来说,ollama中如果布署14B的DeepSeek,可用于每天跑上万份各种格式的文档进入知识库。
8个月前我就在CSDN发表过:中小型商户的AI自由之道:ollama。
因此,请大家放心大胆的用ollama里的DeepSeek吧!
学以致用,知其然更要知其所以然。
至于那些鼓吹本地ollama不行的。。。大家也就看了图个笑吧。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 28
28 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)