Janus:解耦视觉编码实现统一的多模态理解和生成
24年10月来自DeepSeek-AI团队、香港大学和北大的技术报告“Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation”。Janus,是一个统一多模态理解和生成的自回归框架。先前的研究通常依赖于单个视觉编码器来完成这两项任务,例如 Chameleon。然而,由于多模态理解和生成
24年10月来自DeepSeek-AI团队、香港大学和北大的技术报告“Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation”。
Janus,是一个统一多模态理解和生成的自回归框架。先前的研究通常依赖于单个视觉编码器来完成这两项任务,例如 Chameleon。然而,由于多模态理解和生成所需的信息粒度级别不同,这种方法可能会导致性能不佳,尤其是在多模态理解方面。为了解决这个问题,将视觉编码解耦为单独的路径,同时仍然利用单个统一的Transformer架构进行处理。解耦不仅缓解视觉编码器在理解和生成中的角色冲突,而且还增强框架的灵活性。例如,多模态理解和生成组件都可以独立选择最合适的编码方法。实验表明,Janus 超越之前的统一模型,并达到或超过特定任务模型的性能。
近年来,多模态大模型在理解和生成领域都取得重大进展 [20, 51]。在多模态理解领域,研究人员遵循 LLaVA [51] 的设计,使用视觉编码器作为桥梁,使大语言模型 (LLM) 能够理解图像。在视觉生成领域,基于扩散的方法 [9, 20, 20, 67] 取得显著的成功。最近,一些研究探索视觉生成的自回归方法 [73, 79],实现与扩散模型相当的性能。为了构建更强大、更通用的多模态模型,研究人员试图将多模态理解和生成任务结合起来 [75, 77, 94]。例如,一些研究试图将多模态理解模型与预训练的扩散模型联系起来 [27, 28, 75]。例如,Emu [75] 使用 LLM 的输出作为预训练扩散模型的条件,然后依靠扩散模型生成图像。但严格来说,这种方法不能被视为真正统一的模型,因为视觉生成功能由外部扩散模型处理,而多模态 LLM 本身缺乏直接生成图像的能力。
其他方法 [77, 85, 86, 94] 使用单个Transformer来统一多模态理解和生成任务,从而改善视觉生成的指令遵循能力,释放潜在的涌现能力,并减少模型冗余。这类方法通常使用单个视觉编码器来处理两个任务的输入。然而,多模态理解和生成任务所需的表示有很大不同。在多模态理解任务中,视觉编码器的目的是提取高级语义信息(例如,图像中的目标类别或视觉属性)。理解任务的输出不仅涉及从图像中提取信息,还涉及复杂的语义推理。因此,视觉编码器的表示粒度主要倾向于高维语义表示。相比之下,在视觉生成任务中,主要关注的是生成局部细节和保持图像的全局一致性。这种情况下,表示需要一种能够细粒度空间结构和纹理细节表达的低维编码。将这两个任务的表示统一在同一个空间内会导致冲突和权衡。因此,现有的多模态理解和生成的统一模型,往往会在多模态理解性能上做出妥协,与最先进的多模态理解模型相比差距很大。
视觉生成
视觉生成是一个快速发展的领域,它将自然语言处理的概念与 Transformer 架构的进步相结合。受语言处理成功的影响,自回归模型利用 Transformer 来预测离散视觉token序列(码本 ID)[24、65、75]。这些模型对视觉数据进行token化,并采用类似于 GPT 风格 [64] 技术的预测方法。此外,掩码预测模型 [7、8] 借鉴 BERT 风格 [19] 的掩码方法,预测视觉输入的掩码部分以提高合成效率,并已适用于视频生成 [89]。同时,连续扩散模型在视觉生成方面展示了能力 [33、67、71],通过概率视角来处理生成,补充离散方法。
多模态理解
多模态大语言模型 (MLLM) 集成文本和图像 [6、80、81]。通过利用预训练的 LLM,MLLM [1、2、12、51、55、82、95] 展示理解和处理多模态信息的强大能力。最近的进展探索使用预训练的扩散模型扩展 MLLM 以促进图像生成 [27、29、36、75、76]。这些方法属于工具利用的范畴,其中扩散模型用于根据 MLLM 输出条件生成图像,而 MLLM 本身,不具备直接执行视觉生成的能力。此外,整个系统的生成能力,通常受到外部扩散模型的限制,使其性能不如直接使用扩散模型 [27、75]。
统一的多模态理解和生成
统一的多模态理解和生成模型,被认为能够有效地促进跨不同模态的无缝推理和生成 [77、94]。这些模型中的传统方法,通常使用单一的视觉表征来完成理解和生成任务,无论它们是基于自回归 (AR) 模型 [77, 85] 还是基于扩散模型 [86, 94]。例如,Chameleon [77] 采用 VQ Token化器对图像进行编码,以实现多模态理解和生成。然而,这种做法可能会导致次优结果,因为视觉编码器可能会在理解和生成的需求之间做出权衡。
Janus 是一个统一的多模态框架,它将视觉编码与多模态理解和生成分离开来。具体来说,引入两条独立的视觉编码路径:一条用于多模态理解,一条用于多模态生成,由相同的 Transformer 架构统一。Janus 比一些具有更多参数的任务特定模型表现更好(如图所示)。具体来说,在多模态理解基准 MMBench [54]、SEED-Bench [42] 和 POPE [48] 上,Janus (1.3B) 分别取得 69.4、63.7 和 87.0 的分数,优于 LLaVA-v1.5 (7B) [50] 和 Qwen-VL-Chat (7B) [3]。在视觉生成基准 MSCOCO-30K [11] 和 GenEval [30] 上,Janus 的 FID 得分为 8.53,准确率为 61%,超越 DALL-E 2 [66] 和 SDXL [62] 等文本-到-图像生成模型。

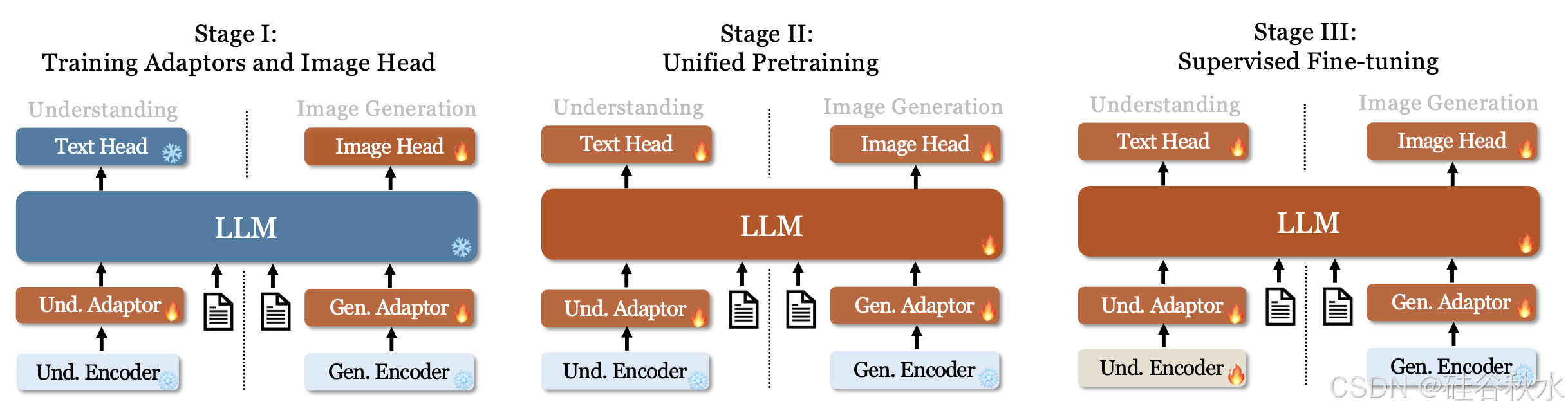
Janus 的训练分为三个阶段,如图所示。详细信息如下:
第一阶段:训练适配器和图像头。此阶段的主要目标是在嵌入空间内建立视觉和语言元素之间的概念联系,使 LLM 能够理解图像中显示的实体并具有初步的视觉生成能力。在此阶段保持视觉编码器和 LLM 冻结,只允许更新理解适配器、生成适配器和图像头中的可训练参数。
第二阶段:统一预训练。在此阶段,用多模态语料库进行统一预训练,使 Janus 能够学习多模态理解和生成。解冻 LLM 并利用所有类型的训练数据:纯文本数据、多模态理解数据和视觉生成数据。受 Pixart [9] 的启发,首先使用 ImageNet-1k 进行简单的视觉生成训练,以帮助模型掌握基本的像素依赖关系。随后,使用一般的文本-到-图像数据,增强模型的开放域视觉生成能力。
第三阶段:监督微调。在此阶段,用指令调整数据对预训练模型进行微调,以增强其指令遵循和对话能力。微调除生成编码器之外的所有参数。专注于监督答案,同时屏蔽系统和用户提示。为了确保 Janus 在多模态理解和生成方面的熟练程度,不会针对某项任务微调单独的模型。相反,用纯文本对话数据、多模态理解数据和视觉生成数据的混合,确保在各种场景中的多功能性。
Janus是一个自回归模型,训练中采用交叉熵做损失项。在推理过程中,模型采用下一个token预测方法。对于纯文本理解和多模态理解,遵循从预测分布中顺序采样token的标准做法。对于图像生成,用无分类器指导 (CFG),类似于先前的研究 [8, 26, 73]。
值得注意的是,本文设计具有用于理解和生成的独立编码器,简单易扩展。
多模态理解。(1)对于多模态理解组件,可以选择更强大的视觉编码器,而不必担心编码器是否能够处理视觉生成任务,例如 EVA-CLIP [74]、InternViT [13] 等。(2)要处理高分辨率图像,可以使用动态高分辨率技术 [50]。这允许模型扩展到任何分辨率,而无需对 ViT 执行位置嵌入插值。可以进一步压缩tokens以节省计算成本,例如使用像素混洗操作 [12]。
视觉生成。(1)对于视觉生成,可以选择更细粒度的编码器,以便在编码后保留更多图像细节,例如 MoVQGan [93]。(2)可以采用专门为视觉生成设计的损失函数,例如扩散损失 [46]。 (3)在视觉生成过程中,使用中可以结合AR(因果注意)和并行(双向注意)方法,以减少视觉生成过程中的累积误差 [79]。
支持其他模态。Janus 的架构简单易懂,可以轻松与其他编码器集成,适应各种模态,如 3D 点云 [53]、触觉 [88] 和 EEG [4]。这使得 Janus 有可能成为更强大的多模态通用模型。
在实验中,用 DeepSeek-LLM (1.3B) [5] 作为基础语言模型,其最大支持序列长度为 4096。对于理解任务中使用的视觉编码器,选择 SigLIP-Large-Patch16-384 [92]。生成编码器具有大小为 16,384 的码本,并将图像下采样 16 倍。理解适配器和生成适配器都是两层 MLP。下表提供每个阶段的详细超参数。
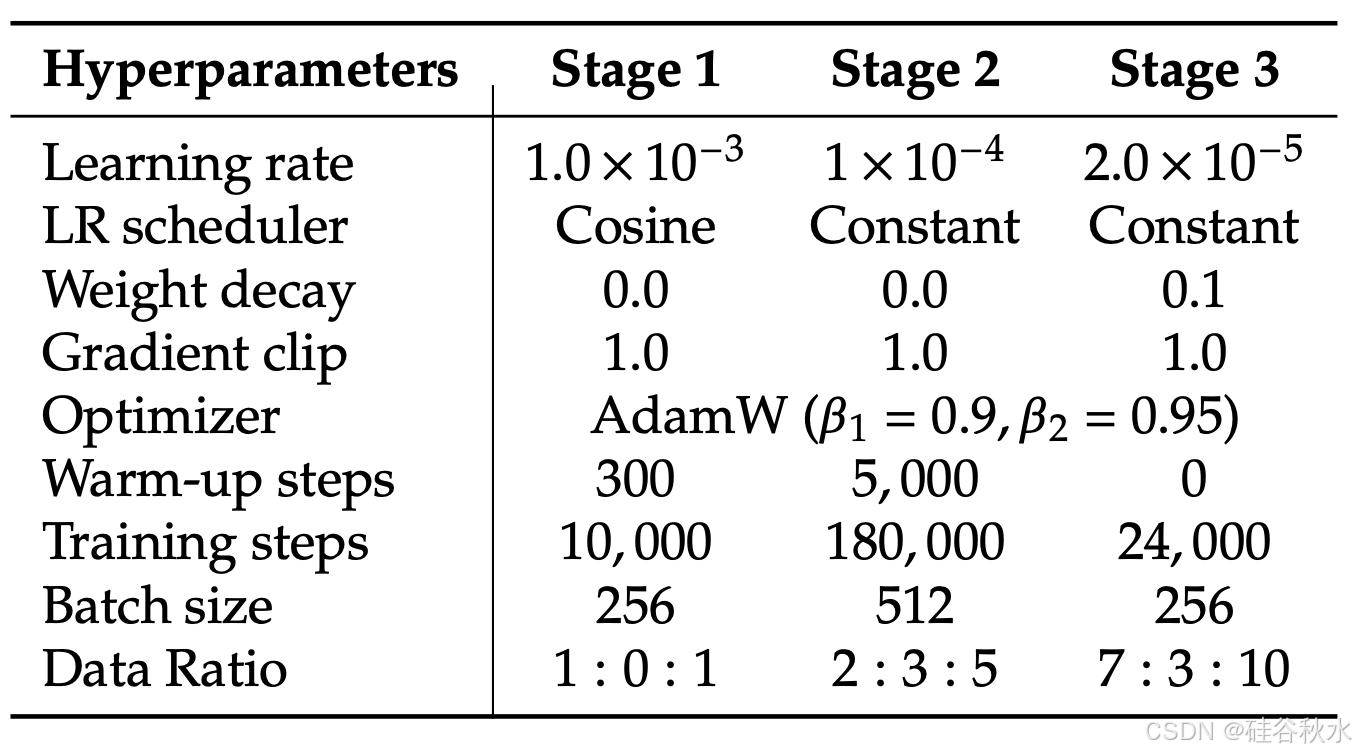
所有图像均调整为 384×384 像素。对于多模态理解数据,调整图像的长边大小,并用背景色(RGB:127,127,127)填充短边以达到 384。对于视觉生成数据,短边调整为 384,长边裁剪为 384。在训练期间使用序列打包以提高训练效率。在单个训练步骤中根据指定的比例混合所有数据类型。Janus 使用 HAI-LLM [32] 进行训练和评估,这是一个基于 PyTorch 构建的轻量级高效分布式训练框架。整个训练过程在一个由 16 个节点组成的集群上耗时 7 天,每个节点配备 8 个 Nvidia A100 (40GB) GPU。
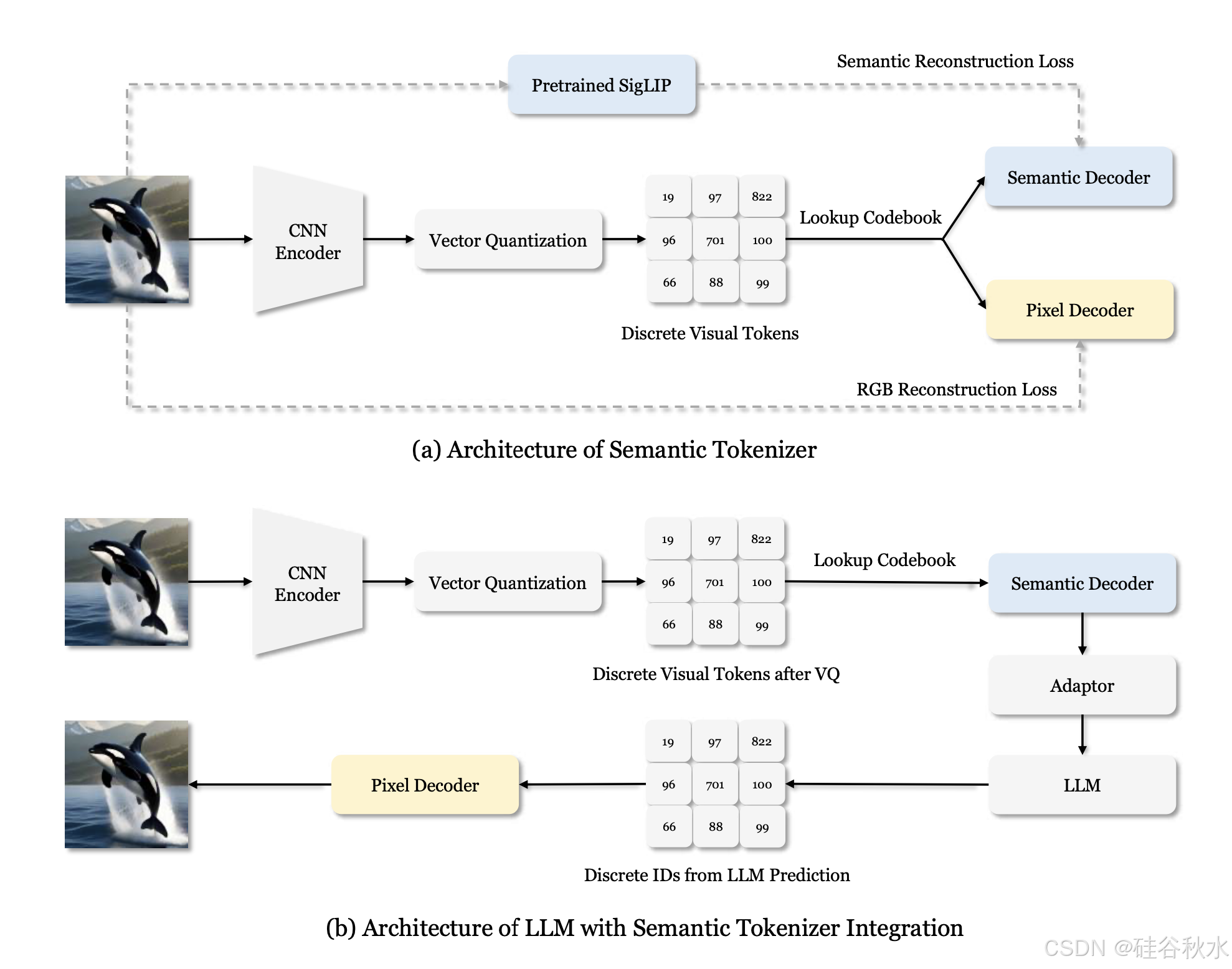
如下图补充语义 token 化器和LLM集成语义token化器的的架构图:(a)语义token化器训练期间使用的架构。用预训练的 SigLIP [92] 来监督语义信息的重建,同时使用原始图像来监督 RGB 值的重建。(b)将 LLM 与语义解码器集成。语义解码器输出具有高级语义的连续特征,这些特征通过适配器传递,然后用作 LLM 的输入。请注意,语义 token 化器仅用于消融研究,而不是在主实验。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 30
30 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)