DeepSeek-R1
为什么要冷启动:普通的SFT以对话格式作为微调的数据,这是因为人类可以拥有或者直接标注大量这样的数据,但是推理模型就很难获得包含推理过程的数据,因为可查看的数据资源中没有包含推理过程的,而且人工标注起来成本显然是巨大的。因此,可以得出两个结论:首先,将更强大的模型提炼成较小的模型会得到极好的结果,而依赖于本文提到的大规模强化学习的小模型则需要巨大的计算能力,甚至可能无法达到提炼的效果。例如,在具有
引言
DeepSeek-R1-Zero是一个通过大规模强化学习(RL)训练的模型,没有进行监督微调(SFT)作为初步步骤,展示了显著的推理能力。通过RL,DeepSeek-R1-Zero自然地展现出许多强大且引人入胜的推理行为。然而,它遇到了诸如可读性差和语言混合等挑战。
为了解决这些问题并进一步提高推理性能,引入了DeepSeek-R1,它在RL之前结合了多阶段训练和冷启动数据。DeepSeek-R1在推理任务上的性能与OpenAI-o1-1217相当。为了支持研究社区,开源了DeepSeek-R1-Zero、DeepSeek-R1以及从DeepSeek-R1基于Qwen和Llama蒸馏出的六个Dense模型(1.5B、7B、8B、14B、32B、70B)。
直观解读
R1-Zero是由V3-base直接经过强化学习训练得到的,也就是说,将一个只经过了pre-train的模型,不经过SFT,直接进行大规模的RL训练。这样得到的模型虽然能力很强,但是问题在于语言混淆、可读性差,比如出现中英文混杂的情况。
为了增强可读性,就有了R1模型,它需要进行几轮训练的循环。循环过程是这样的:
-
从V3-base开始,先进行SFT,用于SFT的数据被称为冷启动数据,它包含推理的思维链数据和非推理的数据。
-
SFT之后进行GRPO的强化学习训练,让训练完的模型进行输出。
-
输出的数据进行拒绝采样,之后再作为冷启动数据,用于SFT,也就是回到第一步
如下图:
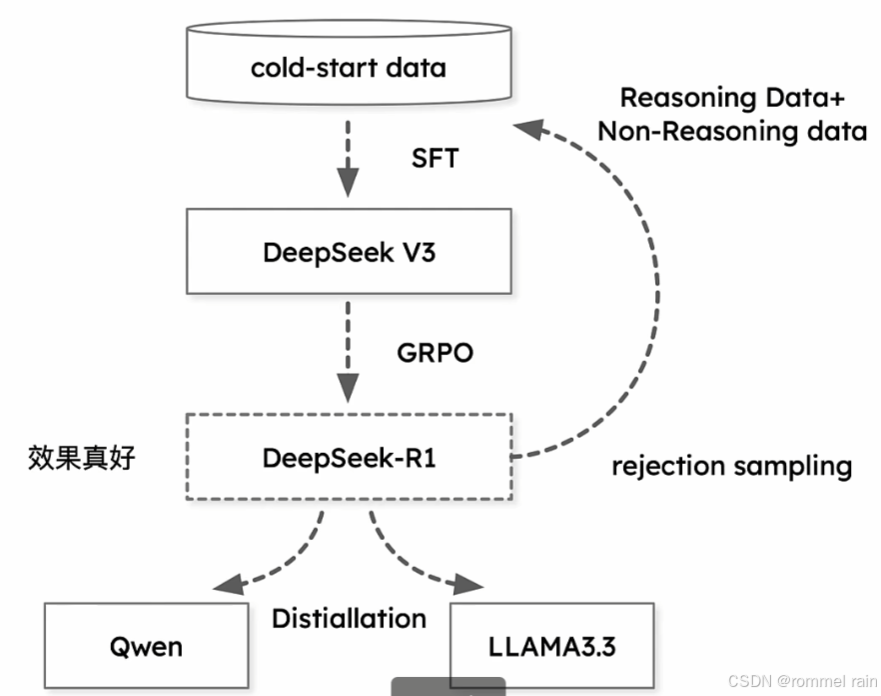
R1-Zero更具有创新性,因为首次提出不经过SFT直接RL的方式微调模型;而R1更多是一些trick,用于解决R1-Zero中存在的问题
未来的发展趋势:
-
因此MoE的整体参数量很大,因此推理将从单机走向集群,推理框架也会让位给vLLM和SGLang这些Python实现的框架
-
序列长度越来越大,进行分阶段变长的预训练
-
推理模型反哺预训练模型,来辅助预训练模型性能提升
关键技术
GRPO
GRPO肯定是最值得关注的技术,它首先被提出于DeepSeek-Math论文中,没有了解过RLHF的话第一次看这部分肯定是看不懂,可以通过以下内容来学习:
-
b站上李宏毅的强化学习课程,只看了1/4/5节,了解了policy gradient和PPO:5. 【李宏毅】强化学习课程 (完整版) - 5_哔哩哔哩_bilibili
-
知乎上猛猿的文章,从直观上了解RLHF和PPO:https://zhuanlan.zhihu.com/p/677607581
-
知乎了解PPO与GRPO的区别:https://zhuanlan.zhihu.com/p/20395188451
奖励模型
并没有使用给出奖励的神经网络,采用了一个基于规则的奖励系统,主要由两种类型的奖励组成:
-
准确性奖励:准确性奖励模型评估响应是否正确。例如,在具有确定性结果的数学问题中,模型被要求以指定的格式(例如,在一个框内)提供最终答案,从而允许基于规则的正确性验证。同样,对于LeetCode问题,可以使用编译器根据预定义的测试用例生成反馈。
-
格式奖励:除了准确性奖励模型外,我们还采用了一个格式奖励模型,它强制模型将其思考过程放在‘<think>’和‘</think>’标签之间。
在开发DeepSeek-R1-Zero时,没有应用结果或过程神经奖励模型,因为我们发现,在大规模强化学习过程中,神经奖励模型可能会遭受奖励欺骗,并且重新训练奖励模型需要额外的训练资源,并且它会使整个训练流程复杂化。
训练模板
为了训练DeepSeek-R1-Zero,首先设计了一个简单的模板,引导基础模型遵循我们指定的指令。这个模板要求-R1-Zero首先产生一个推理过程,然后给出最终答案。我们有意限制我们的约束条件仅限于这种结构格式,避免任何内容特定的偏见——例如强制进行反思性推理或推广特定的问题解决策略——以确保我们能够准确观察到模型在强化学习过程中的自然进展。
这个模板的内容为:A conversation between User and Assistant. The user asks a question, and the Assistant solves it.The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. The reasoning process and answer are enclosed within <think> </think> and<answer></answer> tags, respectively, i.e., <think> reasoning process here </think><answer> answer here </answer>. User: prompt. Assistant:
aha-moment
aha-moment翻译成汉语就是顿悟时刻,R1-Zero的训练过程中观察到一个现象,即“顿悟时刻”的出现。这个时刻发生在模型的一个中间版本中。在这个阶段,R1-Zero通过重新评估其初始方法,学会了为问题分配更多思考时间。这种行为不仅是模型日益增长推理能力的证明,也是强化学习如何导致意外和复杂结果的一个迷人例证。
这个时刻不仅是模型的“顿悟时刻”,也是观察其行为的研究人员的“顿悟时刻”。它强调了强化学习的力量:我们不是明确地教导模型如何解决问题,而是简单地提供正确的激励,它就会自主地发展出高级的问题解决策略。“顿悟时刻”作为强化学习解锁人工智能系统新智能水平潜力的强大提醒,为未来更自主和适应性更强的模型铺平了道路。
冷启动的R1训练
为什么要冷启动:普通的SFT以对话格式作为微调的数据,这是因为人类可以拥有或者直接标注大量这样的数据,但是推理模型就很难获得包含推理过程的数据,因为可查看的数据资源中没有包含推理过程的,而且人工标注起来成本显然是巨大的。因此就需要冷启动,通过少量的数据微调作为起点。
在冷启动数据上进行微调后,应用与R1-Zero中相同的大型强化学习训练过程。这一阶段专注于增强模型的推理能力,特别是在编码、数学、科学和逻辑推理等需要深入推理的任务中。在训练过程中,CoT(经常出现语言混合现象,特别是当RL提示涉及多种语言时。为了减轻语言混合的问题,在RL训练期间引入了语言一致性奖励,该奖励是根据CoT中目标语言词汇的比例来计算的。尽管这种对齐会导致模型性能轻微下降,但这种奖励与人类偏好一致,使其更易于阅读。最后,通过直接将推理任务的准确性与语言一致性奖励相加来结合两者,形成最终奖励。然后对微调后的模型应用RL训练,直到它在推理任务上达到收敛。
当这一轮的强化学习收敛时,使用得到的check point来收集下一轮的SFT数据。与最初主要关注推理的冷启动数据不同,这个阶段结合了其他领域的数据,以增强模型在通用任务方面的能力。具体来说,按照下面描述的方式生成数据并微调模型:
-
reasoning data:通过从上述强化学习训练的check point执行拒绝采样来整理推理提示并生成推理轨迹。之前的阶段只包括了可以使用基于规则的奖励进行评估的数据。然而这个阶段,通过纳入额外的数据来扩展数据集,其中一些使用生成性奖励模型,通过将真实情况和模型预测输入V3进行判断。此外,由于模型输出有时是混乱的,难以阅读,过滤掉混合语言的思维链。对于每个提示,采样多个响应并只保留正确的。总共收集了大约600k个与推理相关的训练样本。
-
non reasoning data:对于非推理型数据,例如写作、事实问答、自我认知和翻译,重用V3的SFT数据集的部分内容。对于某些非推理型任务,通过提示调用DeepSeek-V3来生成潜在的思维链,然后回答问题。然而,对于更简单的查询,例如“你好”,不提供思维链作为回应。最终,收集了大约20万与推理无关的训练样本。
讨论
蒸馏or强化学习?
通过提炼DeepSeek-R1,Qwen7B等一系列小模型可以取得不错的结果。然而存在一个问题:在不进行提炼的情况下,该模型能否通过论文中讨论的大规模强化学习训练达到可比的性能?
为了回答这个问题,使用数学、代码和STEM数据对Qwen-32B-Base进行了大规模的RL训练,训练超过10K步,结果产生了DeepSeek-R1-Zero-Qwen-32B。表6中显示的实验结果表明,Qwen32B模型,蒸馏出来的结果在所有基准测试中表现显著优于自己强化学习得到的结果。这是实验结果:

因此,可以得出两个结论:首先,将更强大的模型提炼成较小的模型会得到极好的结果,而依赖于本文提到的大规模强化学习的小模型则需要巨大的计算能力,甚至可能无法达到提炼的效果。其次,尽管提炼策略既经济又有效,但要超越智能的界限可能仍需要更强大的基础模型和更大规模的强化学习。
失败的尝试:
在开发DeepSeek-R1的早期阶段,遇到了沿途的失败和挫折。在这里分享失败经历,以提供洞察,但这并不意味着这些方法无法开发出有效的推理模型。
-
过程奖励模型PRM:PRM可以引导模型朝向更好的方法解决推理任务。然而,在实践中,PRM有三个主要的局限性可能会阻碍其最终成功。首先,在一般推理中明确定义一个细粒度的步骤很难。其次,确定当前的中间步骤是否正确是一个难题。使用模型进行自动化标注可能不会产生令人满意的结果,而手动标注不利于扩展。第三,一旦引入基于模型的PRM,它不可避免地会导致奖励欺骗,重新训练奖励模型需要额外的训练资源,并且它使整个训练流程变得复杂。
-
蒙特卡洛树搜索:受到AlphaGo,探索了使用蒙特卡洛树搜索来增强测试时的计算可扩展性。当扩大训练规模时,这种方法遇到了几个挑战。首先,与象棋相比,token生成呈现指数级更大的搜索空间。为了解决这个问题,为每个节点设置了最大扩展限制,但这可能导致模型陷入局部最优。其次,价值模型直接影响生成的质量,因为它指导搜索过程的每一步。训练一个精细的价值模型是困难的,这使得模型难以迭代改进。虽然AlphaGo的核心成功依赖于训练一个价值模型以逐步提高其性能,但这一原则在当前设置中证明难以复制,原因在于token生成的复杂性。
结论与展望
DeepSeek-R1-Zero代表了一种纯粹的强化学习方法,不依赖于冷启动数据,在各种任务上取得了强大的性能。
DeepSeek-R1更加强大,利用冷启动数据与迭代强化学习微调相结合。最终,DeepSeek-R1在一系列任务上的性能与OpenAI-o1-1217相当。
进一步探索了将推理能力蒸馏到小型密集模型中。使用DeepSeek-R1作为教师模型生成了800K训练样本,并微调了几个小型密集模型。DeepSeek-R1-Distill-Qwen-1.5B在数学基准测试中超越了GPT-4o和Claude-3.5-Sonnet,AIME得分为28.9%,MATH得分为83.9%。其他密集模型也取得了令人瞩目的成绩,显著超越了基于相同基础检查点的其他指令微调模型。
未来,计划在DeepSeek-R1的以下方向进行研究:
-
通用能力:目前,DeepSeek-R1在函数调用、多轮对话、复杂角色扮演和JSON输出等任务上的能力不及DeepSeek-V3。未来,我们计划探索如何利用长链推理(CoT)来增强这些领域的任务。
-
语言混合:DeepSeek-R1目前针对中文和英文进行了优化,这可能导致在处理其他语言查询时出现语言混合问题。例如,即使查询不是英文或中文,DeepSeek-R1也可能使用英文进行推理和回应。我们计划在未来的更新中解决这一限制。
-
提示工程:在评估DeepSeek-R1时,我们观察到它对提示敏感。少量样本提示始终会降低其性能。因此,建议用户直接描述问题,并使用零样本设置指定输出格式以获得最佳结果。
-
软件工程任务:由于评估时间长,影响了强化学习过程的效率,大规模强化学习在软件工程任务中尚未广泛应用。因此,DeepSeek-R1在软件工程基准测试上并未显示出比DeepSeek-V3有巨大的改进。未来版本将通过在软件工程数据上实施拒绝采样或在强化学习过程中引入异步评估来解决这一问题,以提高效率。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 28
28 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)