DeepSeek_R1论文翻译附原文地址
推理任务:(1)DeepSeek-R1在AIME 2024上的Pass@1得分率为79.8%,略微超过OpenAI-o1-1217。在MATH-500任务中,它获得了97.3%的高分,与OpenAI-o1-1217的表现相当,明显优于其他模型。(2)在编码相关任务中,DeepSeek-R1在代码竞赛任务中表现出专家级水平,它在Codeforces上的Elo评分达到2,029分,超过96.3%的人类
目录
1 导言
我们介绍了第一代推理模型DeepSeek-R1-Zero和DeepSeek-R1。DeepSeek-R1-Zero是一个通过大规模强化学习(RL)训练出来的模型,没有经过超级微调(SFT)这一初步步骤,但却展示了非凡的推理能力。通过强化学习,DeepSeek-R1-Zero 自然而然地出现了许多强大而有趣的推理行为。然而,它也遇到了可读性差和语言混杂等挑战。为了解决这些问题并进一步提高推理性能,我们引入了DeepSeek-R1,它在RL之前结合了多阶段训练和冷启动数据。DeepSeek-R1在推理任务上取得了与OpenAI o1-1217相当的性能。为了支持研究社区,我们开源了DeepSeek-R1-Zero、DeepSeek-R1以及基于Qwen和Llama从DeepSeek-R1中提炼出的六个密集模型(1.5B、7B、8B、14B、32B、70B)。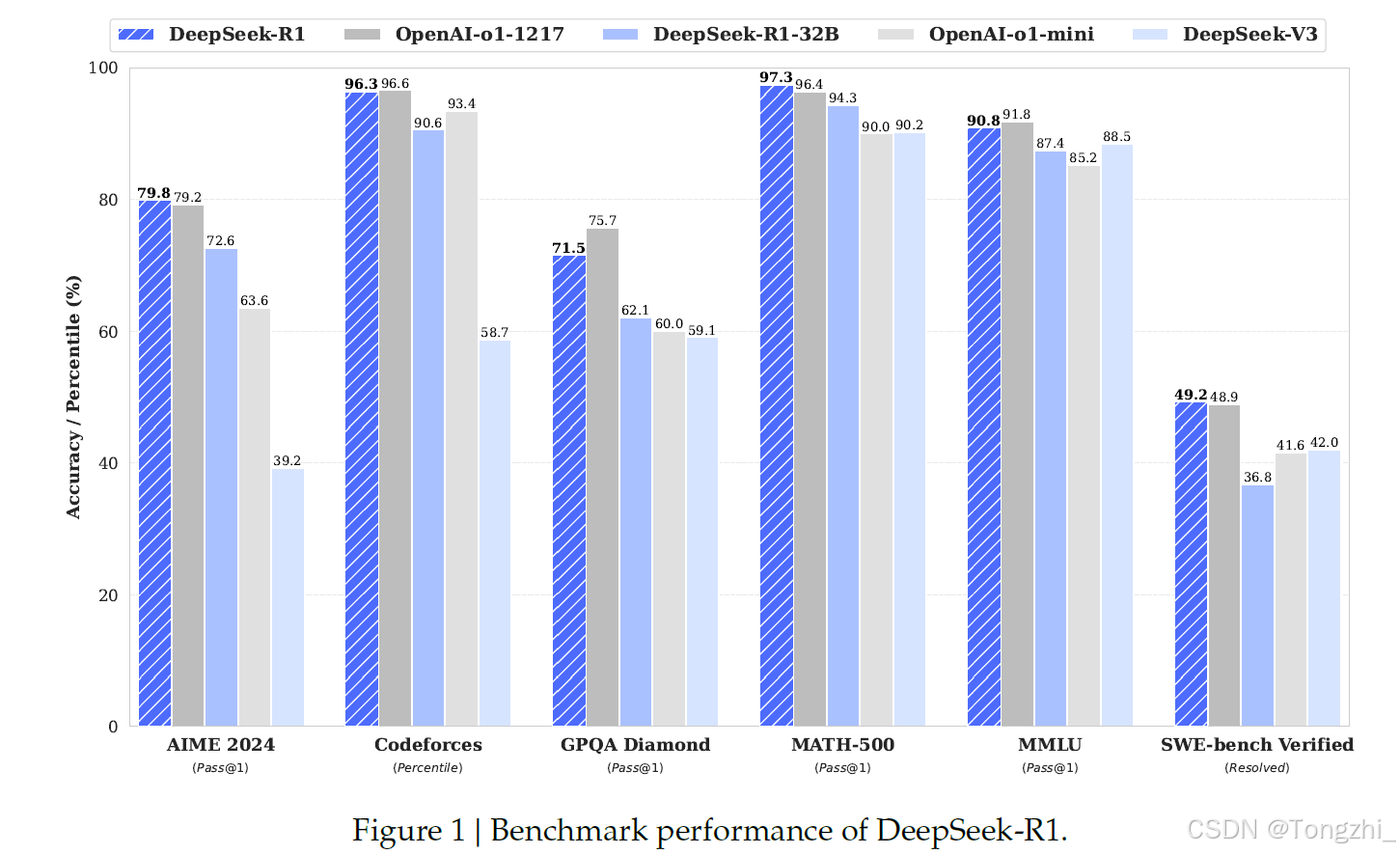
1.1 贡献
后期训练:基础模型的大规模强化学习
我们直接将 RL 应用于基础模型,而不依赖作为初步步骤的监督微调(SFT)。这种方法允许模型探索解决复杂问题的思维链(CoT),从而开发出 DeepSeek-R1-Zero。DeepSeek-R1-Zero展示了自我验证、反思和生成长CoT等能力,是研究界的一个重要里程碑。值得注意的是,这是第一项公开研究,验证了LLM的推理能力可以纯粹通过RL来激励,而无需SFT。这一突破为该领域未来的发展铺平了道路。
蒸馏:较小的型号也可以很强大
我们证明,大型模型的推理模式可以被提炼到小型模型中,从而比通过小型模型上的RL发现的推理模式具有更好的性能。开源的DeepSeek-R1及其应用程序接口将有助于研究界在未来提炼出更好的小型模型。
1.2 评估结果摘要
推理任务:(1)DeepSeek-R1在AIME 2024上的Pass@1得分率为79.8%,略微超过OpenAI-o1-1217。在MATH-500任务中,它获得了97.3%的高分,与OpenAI-o1-1217的表现相当,明显优于其他模型。(2)在编码相关任务中,DeepSeek-R1在代码竞赛任务中表现出专家级水平,它在Codeforces上的Elo评分达到2,029分,超过96.3%的人类参赛者。在工程相关任务中,DeepSeek-R1的表现略好于DeepSeek-V3,这可以帮助开发人员完成实际任务。
知识:在MMLU、MMLU-Pro和GPQA Diamond等基准测试中,DeepSeek-R1取得了优异成绩,MMLU得分90.8%,MMLU-Pro得分84.0%,GPQA Diamond得分71.5%,明显优于DeepSeek-V3。虽然DeepSeek-R1在这些基准测试中的表现略低于OpenAI-o1-1217,但它超越了其他闭源模型,显示了它在教育任务中的竞争优势。在事实基准SimpleQA上,DeepSeek-R1的表现优于DeepSeek-V3,这表明它有能力处理基于事实的查询。OpenAI-o1在该基准测试中超越了4o,也呈现出类似的趋势。
2 方法
2.1 概述
以往的工作主要依赖大量的监督数据来提高模型性能。在本研究中,我们证明了即使不使用监督微调(SFT)作为冷启动,也能通过大规模强化学习(RL)显著提高推理能力。此外,加入少量冷启动数据还能进一步提高性能。在下面的章节中,我们将介绍:(1)DeepSeek-R1-Zero,它在没有任何SFT数据的情况下将RL直接应用于基础模型,以及(2)DeepSeek-R1,从使用长思维链(CoT)示例微调的检查点开始应用RL。3) 将DeepSeek-R1的推理能力提炼为小型密集模型。
2.2 DeepSeek-R1-Zero:基础模型的强化学习
强化学习在推理任务中表现出了显著的有效性,我们之前的工作(Shao 等人,2024 年;Wang 等人,2023 年)也这一点。证明了然而,这些工作在很大程度上依赖于监督数据,而监督数据的收集需要大量时间。在本节中,我们将探索 LLMs 在没有任何监督数据的情况下开发推理能力的潜力,重点关注它们通过纯强化学习过程进行自我进化的情况。我们首先简要介绍了我们的 RL 算法,然后展示了一些令人兴奋的结果,希望能为社区提供有价值的见解。
2.2.1 强化学习算法
组相对策略优化 为了节省 RL 的训练成本,我们采用了组相对策略优化(GRPO)(Shao 等人,2024 年)。通常情况下,GRPO 与政策模型的规模相同,并根据小组得分估算基线。具体来说,对于每个问题𝑞,GRPO 从旧政策𝜋𝜃𝑜𝑙𝑑 中抽取一组输出 {𝑜 (1),𝑜 (2),- - - 𝑜𝐺 },然后通过最大化以下目标来优化政策模型𝜋𝜃: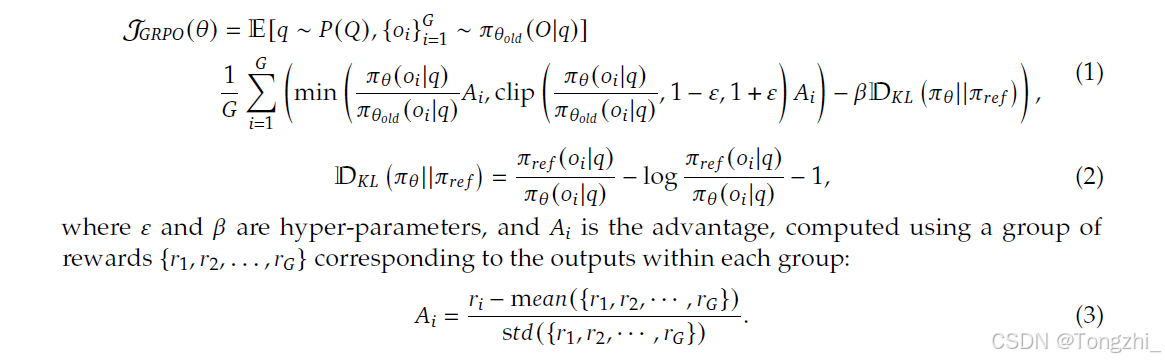

用户与助手之间的对话。用户提出一个问题,助手解决它。助手首先在脑海中思考推理过程,然后向用户提供答案。推理过程和答案分别用 < think>< /think> 和 < answer>< /answer> 标签包围,即 < think> 推理过程在此 < /think> < answer> 答案在此 < /answer>。用户:提示。助手:
表 1 | DeepSeek-R1-Zero 的模板。在训练期间,提示将被特定的推理问题替换。
2.2.2 奖励模型
奖励是训练信号的来源,它决定了 RL 的优化方向。为了训练 DeepSeek-R1-Zero,我们采用了基于规则的奖励系统,主要包括两类奖励:准确性奖励和格式奖励。准确性奖励模型可评估答案是否正确,对于具有确定结果的数学问题,模型需要以指定格式(如在方框内)提供最终答案,从而对正确性进行可靠的基于规则的验证。同样,对于 LeetCode 问题,可以使用编译器根据预定义的测试用例生成反馈。格式奖励模型则强制模型将其思考过程置于"<思考>“和”</思考>"标记之间。在开发 DeepSeek-R1-Zero 时,我们没有使用结果或过程神经奖励模型,因为我们发现神经奖励模型在大规模强化学习过程中可能会出现奖励黑客(reward hacking)问题,而且重新训练奖励模型需要额外的训练资源,会使整个训练流水线变得复杂。
2.2.3 培训模板
为了训练 DeepSeek-R1-Zero,我们首先设计了一个简单明了的模板,引导基础模型遵守我们指定的指令。如表 1 所示,该模板要求 DeepSeek-R1-Zero 首先生成推理过程,然后生成最终答案。我们有意将限制条件限制在这种结构形式上,避免任何与具体内容有关的偏差–比如强制要求进行反思性推理或提倡特定的问题解决策略–以确保我们能够准确地观察到模型在 RL 过程中的自然发展。
2.2.4 DeepSeek-R1-Zero 的性能、自我进化过程和 Aho时刻(顿悟时刻)
DeepSeek-R1-Zero 的性能 图 2 描述了 DeepSeek-R1-Zero 在 AIME 2024 基准上整个 RL 训练过程中的性能轨迹。如图所示,随着 RL 训练的推进,DeepSeek-R1-Zero 表现出了稳定而持续的性能提升。值得注意的是,AIME 2024 的平均 pass@1 分数有了显著提高,从最初的 15.6% 跃升至令人印象深刻的 71.0%,达到了与 OpenAI-o1-0912 不相上下的性能水平。这一重大改进凸显了我们的 RL 算法在不断优化模型性能方面的功效。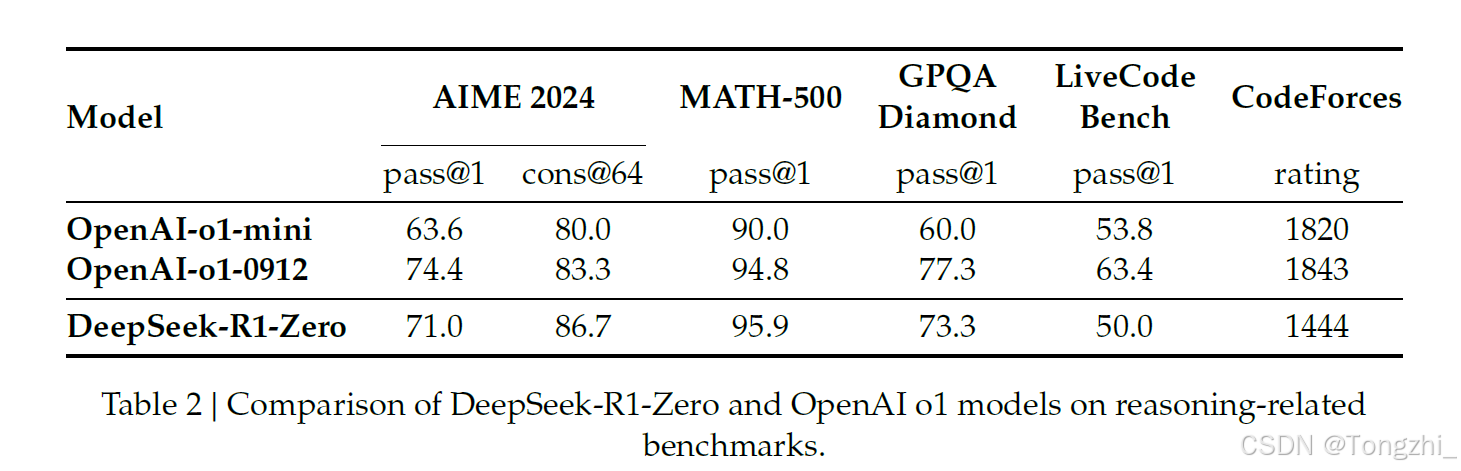
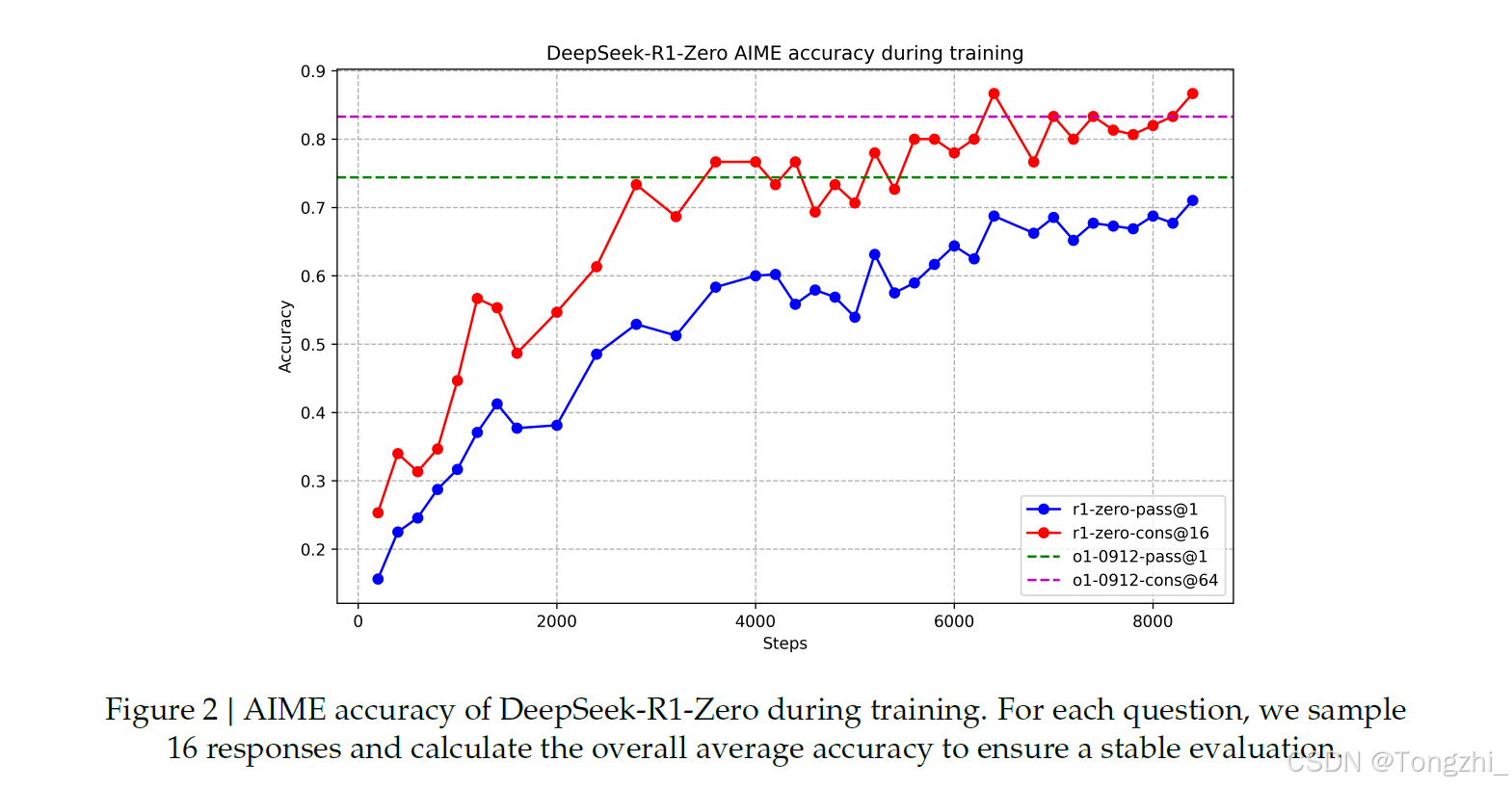
表 2 提供了 DeepSeek-R1-Zero 与 OpenAI 的 o1-0912 模型在各种推理相关基准方面的比较分析。研究结果表明,RL 训练的 DeepSeek-R1-Zero 在多项任务中表现出色,与 OpenAI-o1-0912 模型相当。值得注意的是,DeepSeek-R1-Zero 在 AIME 2024 基准测试中,通过多数投票机制,性能从 71.0% 提升到 86.7%,超过了 OpenAI-o1-0912 的性能。这表明 DeepSeek-R1-Zero 在推理任务中具有强大的基础能力,并且通过 RL 训练能够不断优化其性能。
DeepSeek-R1-Zero 的自我进化过程引人入胜地展示了 RL 如何驱动模型自主提高推理能力。通过直接从基础模型启动 RL,我们可以密切监控模型的进展,而不受监督微调阶段的影响。通过这种方法,我们可以清楚地看到模型是如何随着时间的推移而演变的,尤其是在处理复杂推理任务的能力方面。如图 3 所示,DeepSeek-R1-Zero 的思考时间显示出了持续的改进。这种改进不是外部调整的结果,而是模型内在发展的结果。DeepSeek-R1-Zero 利用扩展的测试时间计算,自然而然地获得解决日益复杂的推理任务的能力。这种计算从生成数百到数千个推理标记不等,使模型能够更深入地探索和完善其思维过程。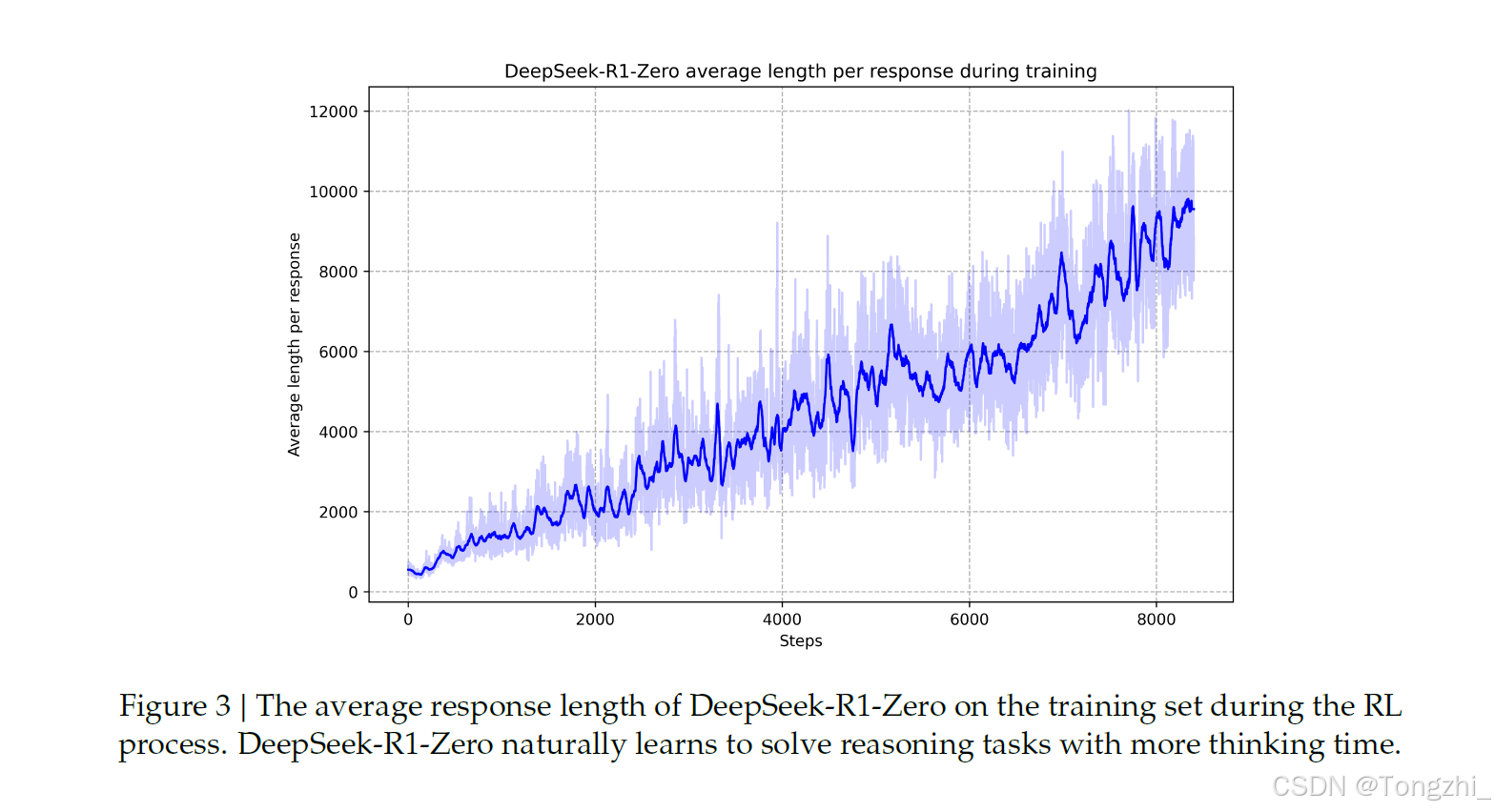
在 DeepSeek-R1-Zero 的训练过程中观察到的一个特别有趣的现象是出现了 “顿悟时刻”。如表 3 所示,这一时刻出现在模型的中间版本中。在这一阶段,DeepSeek-R1-Zero 通过重新评估其初始方法,学会为问题分配更多思考时间。这一行为不仅证明了模型推理能力的不断提高,也是强化学习如何带来意想不到的复杂结果的一个引人入胜的例子。这一刻不仅是模型的 “顿悟时刻”,也是观察其行为的研究人员的 “顿悟时刻”。它彰显了 强化学习 的力量和魅力:我们无需明确教导模型如何解决问题,只需向它提供正确的激励,它就能自主开发出先进的解决问题的策略。这个 “顿悟时刻” 有力地提醒我们,RL 有潜力为人工系统开启新的智能水平,为未来更自主、更自适应的模型铺平道路。
DeepSeek-R1-Zero 的缺点:尽管 DeepSeek-R1-Zero 表现出强大的推理能力,并自主开发出意外而强大的推理行为,但它面临几个问题。例如,DeepSeek-R1-Zero 在可读性差和语言混合等挑战中挣扎。为了让推理过程更易于理解并与开源社区分享,我们探索了 DeepSeek-R1,这是一种利用强化学习(RL)和用户友好的冷启动数据的方法。
2.3 DeepSeek-R1:冷启动强化学习
受 DeepSeek-R1-Zero 令人鼓舞的成果的启发,两个问题自然而然地产生了:1)作为冷启动,通过纳入少量高质量数据,能否进一步提高推理性能或加速收敛?2)如何才能训练出一个用户友好型模型,不仅能生成清晰连贯的思维链(CoT),还能展示强大的通用能力?为了解决这些问题,我们设计了一个训练 DeepSeek-R1 的管道。管道包括四个阶段,概述如下。
2.3.1 冷启动
与 DeepSeek-R1-Zero 不同的是,为了防止从基础模型开始的 RL 训练出现早期不稳定的冷启动阶段,对于 DeepSeek-R1,我们构建并收集了少量长 CoT 数据,以微调模型作为初始 RL 行为体。为了收集这些数据,我们探索了几种方法:以长 CoT 为例,使用少量提示;直接提示模型生成详细答案,并进行反思和验证;以可读格式收集 DeepSeek-R1-Zero 的输出结果;通过人工注释者的后期处理完善结果。在这项工作中,我们收集了数千个冷启动数据,以微调 DeepSeek-V3-Base 作为 RL 的起点。与 DeepSeek-R1-Zero 相比,冷启动数据的优势在于包括可读性和潜力。通过精心设计具有人类先验的冷启动数据模式,我们观察到与 DeepSeek-R1-Zero 相比有更好的表现。我们相信,迭代训练是推理模型的更好方法。
2.3.2 以推理为导向的强化学习
根据冷启动数据对 DeepSeek-V3-Base 进行微调后,我们采用了与 DeepSeek-R1-Zero 相同的大规模强化学习训练过程。这一阶段的重点是增强模型的推理能力,尤其是在编码、数学、科学和逻辑推理等推理密集型任务中,因为这些任务涉及具有明确解决方案的定义明确的问题。在训练过程中,我们发现 CoT 经常出现语言混杂的问题,尤其是当 RL 提示涉及多种语言时。为了缓解语言混合的问题,我们在 RL 训练过程中引入了语言一致性奖励,其计算方法是 CoT 中目标语言单词所占的比例。尽管消融实验表明,这种一致性会导致模型性能略有下降,但这种奖励符合人类的偏好,使其更具可读性。最后,我们将推理任务的准确性和语言一致性奖励直接相加形成最终奖励。然后,我们对微调后的模型进行 RL 训练,直到它在推理任务上达到收敛。
2.3.3 拒绝采样和监督微调
当面向推理的 RL 收敛时,我们会利用由此产生的检查点为下一轮收集 SFT(监督微调)数据。与最初主要关注推理的冷启动数据不同,这一阶段纳入了其他领域的数据,以增强模型在写作、角色扮演和其他通用任务中的能力。具体来说,我们生成数据并对模型进行微调,如下所述。推理数据我们通过对上述 RL 训练中的检查点进行拒绝采样,策划推理提示并生成推理轨迹。在前一阶段,我们只包含可使用基于规则的奖励进行评估的数据。然而,在本阶段,我们通过纳入更多数据来扩展数据集,其中一些数据使用了生成式奖励模型,将地面实况和模型预测输入 DeepSeek-V3 进行判断。此外,由于模型输出有时混乱难读,我们过滤掉了混合语言的思维链、长段落和代码块。对于每个提示,我们都会对多个回答进行抽样,只保留正确回答。我们总共收集了约 600k 个与推理相关的训练样本。非推理数据对于非推理数据,如写作、事实问答、自我认知和翻译,我们采用 DeepSeek-V3 的管道,并重复使用 DeepSeek-V3 的 SFT 数据集的部分内容。对于某些非推理任务,我们会调用 DeepSeek-V3 生成潜在的思维链,然后再通过提示回答问题。不过,对于诸如 “你好” 之类的简单查询,我们并不提供 CoT 作为回应。最后,我们总共收集了约 20 万个与推理无关的训练样本。我们使用上述由大约 800k 个样本组成的数据集对 DeepSeek-V3-Base 进行了两次历时微调。
2.3.4 所有场景的强化学习
为了使模型进一步符合人类的偏好,我们实施了二级强化学习阶段,旨在提高模型的帮助性和无害性,同时完善其推理能力。具体来说,我们结合使用奖励信号和不同的提示分布来训练模型。对于推理数据,我们采用 DeepSeek-R1-Zero 中概述的方法,利用基于规则的奖励来指导数学、代码和逻辑推理领域的学习过程。对于一般数据,我们采用奖励模型来捕捉人类在复杂和细微场景中的偏好。我们以 DeepSeek-V3 管道为基础,采用类似的偏好对分布和训练提示。对于有用性,我们只关注最终摘要,确保评估强调响应对用户的实用性和相关性,同时尽量减少对底层推理过程的干扰。在无害性方面,我们会对模型的整个回复进行评估,包括推理过程和摘要,以识别并降低生成过程中可能出现的任何潜在风险、偏差或有害内容。最终,奖励信号和不同数据分布的整合使我们能够训练出一个在推理中表现出色的模型,同时优先考虑有用性和无害性。
2.4 蒸馏:赋予小型模型推理能力
为了让更高效的小型模型具备像 DeepSeek-R1 那样的推理能力,我们使用 DeepSeek-R1 策划的 800k 样本直接微调了 Qwen(Qwen,2024b)和 Llama(AI@Meta,2024)等开源模型,详见第 2.3.3 节。我们的研究结果表明,这种直接提炼的方法大大增强了较小模型的推理能力。我们在这里使用的基础模型是 Qwen2.5-Math-1.5B、Qwen2.5-Math-7B、Qwen2.5-14B、Qwen2.5-32B、Llama-3.1-8B 和 Llama-3.3-70B-Instruct。我们选择 Llama-3.3 是因为它的推理能力略优于 Llama-3.1。对于蒸馏模型,我们只应用 SFT,而不包括 RL 阶段,尽管纳入 RL 可以大大提高模型性能。我们在此的主要目标是展示蒸馏技术的有效性,而将 RL 阶段的探索留给更广泛的研究界。
3 实验
基准测试:我们对模型进行了广泛的基准测试,包括 MMLU(Hendrycks 等人,2020 年)、MMLU-Redux(Gema 等人,2024 年)、MMLU-Pro(Wang 等人,2024 年)、C-Eval(Huang 等人,2023 年)、CMMLU(Li 等人,2023 年)、IFEval(Zhou 等人,2023 年)、FRAMES(Krishna 等人,2024 年)、GPQA Diamond(Rein 等人,2023 年)、SimpleQA(OpenAI,2024 年 c)、C-SimpleQA(He 等人,2024 年)、SWE-Bench Verified(OpenAI,2024 年 d)、Aider(1)、LiveCodeBench(Jain 等人,2024 年)(2024 年 8 月 - 2025 年 1 月)、Codeforces(2)、中国全国高中数学奥林匹克竞赛(CNMO 2024 年)(3)和 2024 年美国数学邀请赛(MAA,AIME 2024 年)(4)。除了标准基准测试外,我们还在开放式生成任务中使用 LLM 作为评委对我们的模型进行了评估。具体来说,我们采用 AlpacaEval 2.0(Dubois 等人,2024 年)和 Arena-Hard(Li 等人,2024 年)的原始配置,利用 GPT-4 Turbo-1106 作为评委进行配对比较。在此,我们只将最终摘要提供给评估,以避免长度偏差。对于经过提炼的模型,我们报告了 AIME 2024、MATH-500、GPQA Diamond、Codeforces 和 LiveCodeBench 的代表性结果。
评估提示:根据 DeepSeek-V3 中的设置,使用 simple-evals 框架中的提示对 MMLU、DROP、GPQA Diamond 和 SimpleQA 等标准基准进行评估。对于 MMLU-Redux,我们采用 Zero-Eval 提示格式(Lin 2024)在零次设置中进行评估。就 MMLU-Pro、C-Eval 和 CLUE-WSC 而言,由于原始提示是少量样本,我们稍微修改提示以适应零次设置。少量样本中的 CoT 可能会影响 DeepSeek-R1 的性能。其他数据集遵循其原始评估协议,使用其创建者提供的默认提示。对于代码和数学基准,HumanEval-Mul 数据集涵盖了八种主流编程语言(Python、Java、C++、C#、JavaScript、TypeScript、PHP 和 Bash)。使用 CoT 格式评估 LiveCodeBench 上的模型性能,数据收集时间为 2024 年 8 月至 2025 年 1 月。Codeforces 数据集使用来自 10 个 Div.2 竞赛的问题以及专家制作的测试用例进行评估,之后计算预期评分和参赛者的百分比。通过无代理框架(Xia 等人,2024 年)获得 SWE-Bench 验证结果。与 AIDER 相关的基准使用“diff”格式进行测量。DeepSeek-R1 的输出在每个基准上限制为最多 32,768 个标记。
基线:我们对几个强大的基线进行全面评估,包括 DeepSeek-V3、Claude-Sonnet-3.5-1022、GPT-4o-0513、OpenAI-o1-mini 和 OpenAI-o1-1217。由于在中国大陆访问 OpenAI-o1-1217 API 具有挑战性,我们根据官方报告报告其性能。对于蒸馏模型,我们还比较了开源模型 QwQ-32B-Preview(Qwen 2024a)。
评估设置 我们将模型的最大生成长度设置为 32,768 个标记。我们发现,使用贪婪解码来评估长输出推理模型会导致更高的重复率和在不同检查点间的显著变异性。因此,我们默认使用 pass@k 评估(Chen 等人,2021 年)并使用非零温度报告 pass@1。具体来说,我们使用采样温度 0.6 和 top-p 值 0.95 为每个问题生成 k 个响应(通常在 4 到 64 之间,取决于测试集的大小)。然后计算 pass@1:
pass@1 = 1 k ∑ i = 1 k p i \text{pass@1} = \frac{1}{k} \sum_{i=1}^{k} p_i pass@1=k1i=1∑kpi
其中 pi 表示第 i 个响应的正确性。这种方法提供了更可靠的性能估计。对于 AIME 2024,我们还报告了共识(多数投票)结果(Wang 等人,2022 年),使用 64 个样本,记为 cons@64。
3.1 DeepSeek-R1 评估

DeepSeek-R1 在多个基准测试中表现出色,与 OpenAI-o1-1217 相当。在教育相关的知识基准测试(如 MMLU、MMLU-Pro 和 GPQA Diamond)中,DeepSeek-R1 的表现明显优于 DeepSeek-V3。这种改进主要归功于 STEM 相关问题的准确性提高,在这些问题上,通过大规模强化学习取得了显著收益。此外,DeepSeek-R1 在 FRAMES(一种依赖长语境的质量保证任务)中表现出色,展示了其强大的文档分析能力。这凸显了推理模型在人工智能驱动的搜索和数据分析任务中的潜力。在事实基准 SimpleQA 中,DeepSeek-R1 的表现优于 DeepSeek-V3,这表明它有能力处理基于事实的查询。在该基准测试中,OpenAI-o1 的表现也超过了 GPT-4o,呈现出类似的趋势。然而,DeepSeek-R1 在中文 SimpleQA 基准测试中的表现不如 DeepSeek-V3,这主要是由于它在安全 RL 后倾向于拒绝回答某些查询。如果没有安全 RL,DeepSeek-R1 可以达到 70% 以上的准确率。
DeepSeek-R1 在 IF-Eval 上也取得了令人瞩目的成绩,IF-Eval 是一项用于评估模型遵循格式指令能力的基准测试。这些改进与在监督微调(SFT)和 RL 训练的最后阶段纳入指令跟踪数据有关。此外,DeepSeek-R1 在 AlpacaEval2.0 和 ArenaHard 上的出色表现也表明了它在写作任务和开放域问题解答方面的优势。DeepSeek-R1 的表现明显优于 DeepSeek-V3,这凸显了大规模 RL 的泛化优势,它不仅增强了推理能力,还提高了在不同领域的表现。此外,DeepSeek-R1 生成的摘要长度也很简洁,在 ArenaHard 和 AlpacaEval 2.0 中,摘要平均长度分别为 689 个字符和 2218 个字符。这表明 DeepSeek-R1 避免了在基于 GPT 的评估过程中引入长度偏差,进一步巩固了其在多个任务中的稳健性。在数学任务上,DeepSeek-R1 的表现与 OpenAI-o1-1217 不相上下,远远超过了其他模型。在编码算法任务(如 LiveCodeBench 和 Codeforces)上也有类似的趋势,注重推理的模型在这些基准测试中占主导地位。在面向工程的编码任务上,OpenAI-o1-1217 在 Aider 上的表现优于 DeepSeek-R1,但在 SWE Verified 上的表现不相上下。我们相信,DeepSeek-R1 的工程性能将在下一个版本中得到改善,因为目前相关的 RL 训练数据量仍然非常有限。
3.2 蒸馏模型评估
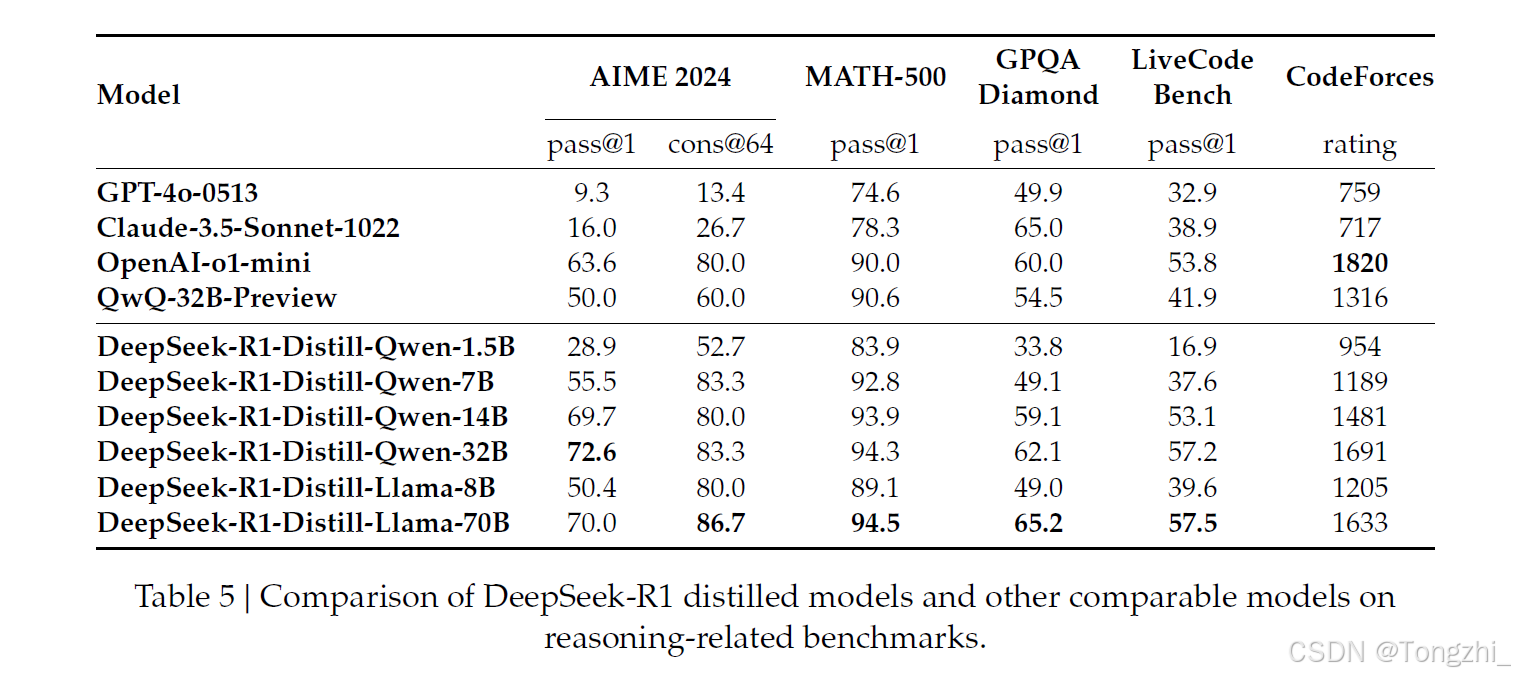
DeepSeek-R1 的蒸馏模型在多个基准测试中表现出色,明显优于其他模型。例如,DeepSeek-R1-Distill-Qwen-7B 在 AIME 2024 上的得分率达到 55.5%,超过了 QwQ-32B-Preview。此外,DeepSeek-R1-Distill-Qwen-32B 在 AIME 2024 上的得分率为 72.6%,在 MATH-500 上的得分率为 94.3%,在 LiveCodeBench 上的得分率为 57.2%。这些结果明显优于以前的开源模型,与 o1-mini 不相上下。我们向社区开源了基于 Qwen2.5 和 Llama3 系列的 1.5B、7B、8B、14B、32B 和 70B 检查点。
4 谈论
4.1 蒸馏与强化学习
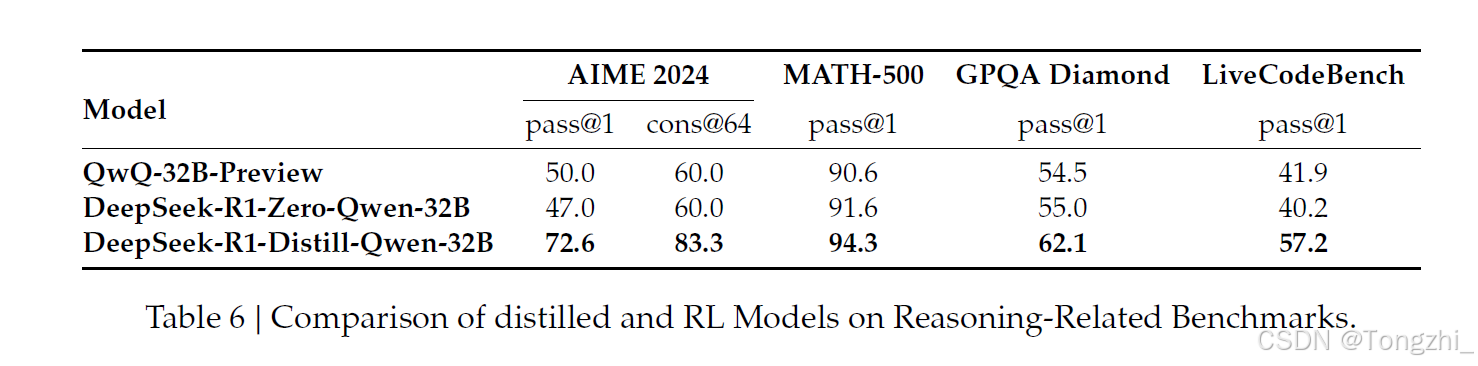
在第 3.2 节中,我们可以看到,通过蒸馏 DeepSeek-R1,小型模型可以取得令人印象深刻的结果。然而,还有一个问题:通过本文讨论的大规模 RL 训练,该模型能否在不进行蒸馏的情况下取得与之相当的性能?为了回答这个问题,我们使用数学、代码和 STEM 数据对 Qwen-32B-Base 进行了大规模 RL 训练,训练步数超过 10K 步,最终得到了 DeepSeek-R1-Zero-Qwen-32B。表 6 所示的实验结果表明,32B 基本模型在经过大规模的 RL 训练后,性能与 QwQ-32B-Preview 相当。然而,从 DeepSeek-R1 提炼出来的 DeepSeek-R1-Distill-Qwen-32B 在所有基准测试中的表现都明显优于 DeepSeek-R1-Zero-Qwen-32B。因此,我们可以得出两个结论:首先,将更强大的模型蒸馏为更小的模型会产生出色的结果,而依赖本文提到的大规模 RL 的更小模型则需要巨大的计算能力,甚至可能达不到蒸馏的性能。其次,虽然蒸馏策略既经济又有效,但要超越智能的界限,可能仍需要更强大的基础模型和更大规模的强化学习。
4.2 不成功的尝试
在开发 DeepSeek-R1 的早期阶段,我们也遇到了失败和挫折。我们在此分享我们的失败经验,希望能给大家一些启示,但这并不意味着这些方法无法开发出有效的推理模型。
5 结论、局限性和未来工作
在这项工作中,我们分享了通过强化学习提高模型推理能力的历程。DeepSeek-R1-Zero 代表了一种不依赖冷启动数据的纯 RL 方法,在各种任务中都取得了优异的性能。DeepSeek-R1 则更加强大,它在利用冷启动数据的同时,还进行了迭代 RL 微调。最终,DeepSeek-R1 在一系列任务中取得了与 OpenAI-o1-1217 不相上下的性能。我们进一步探索将推理能力提炼为小型密集模型。我们使用 DeepSeek-R1 作为教师模型,生成 800K 个训练样本,并对多个小型密集模型进行微调。结果令人欣喜:在数学基准测试中,DeepSeek-R1-Distill-Qwen-1.5B 的表现优于 GPT-4o 和 Claude-3.5-Sonnet,在 AIME 测试中优于 28.9%,在 MATH 测试中优于 83.9%。其他密集模型也取得了令人瞩目的成绩,明显优于基于相同底层检查点的其他指令调整模型。
在未来,我们计划在以下方向上投资 DeepSeek-R1 的研究:
通用能力:目前,DeepSeek-R1 的能力在函数调用、多轮对话、复杂角色扮演和 JSON 输出等任务上不如 DeepSeek-V3。展望未来,我们计划探索如何利用长链推理(CoT)来增强这些领域的任务。
语言混合:DeepSeek-R1 当前针对中文和英文进行了优化,这可能导致在处理其他语言查询时出现语言混合问题。例如,即使查询使用的不是英文或中文,DeepSeek-R1 也可能使用英文进行推理和响应。我们计划在未来的更新中解决这一限制。
提示工程:在评估 DeepSeek-R1 时,我们观察到它对提示很敏感。少量样本提示一致地降低了其性能。因此,我们建议用户直接描述问题并使用零次设置指定输出格式,以获得最佳结果。
软件工程任务:由于评估时间较长,影响了强化学习过程的效率,大规模强化学习尚未广泛应用于软件工程任务。因此,DeepSeek-R1 在软件工程基准测试中尚未显示出对 DeepSeek-V3 的巨大改进。未来的版本将通过在软件工程数据上实施拒绝采样或在强化学习过程中引入异步评估来提高效率。
参考
AI@Meta. Llama 3.1 model card, 2024. URL https://github.com/meta-llama/llama-m odels/blob/main/models/llama3_1/MODEL_CARD.md.
Anthropic. Claude 3.5 sonnet, 2024. URL https://www.anthropic.com/news/claude-3 -5-sonnet.
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. de Oliveira Pinto, J. Kaplan, H. Edwards, Y. Burda, N. Joseph, G. Brockman, A. Ray, R. Puri, G. Krueger, M. Petrov, H. Khlaaf, G. Sastry, P. Mishkin, B. Chan, S. Gray, N. Ryder, M. Pavlov, A. Power, L. Kaiser, M. Bavarian, C. Winter, P. Tillet, F. P. Such, D. Cummings, M. Plappert, F. Chantzis, E. Barnes, A. Herbert-Voss, W. H. Guss, A. Nichol, A. Paino, N. Tezak, J. Tang, I. Babuschkin, S. Balaji, S. Jain, W. Saunders, C. Hesse, A. N. Carr, J. Leike, J. Achiam, V. Misra, E. Morikawa, A. Radford, M. Knight, M. Brundage, M. Murati, K. Mayer, P. Welinder, B. McGrew, D. Amodei, S. McCandlish, I. Sutskever, and W. Zaremba. Evaluating large language models trained on code. CoRR, abs/2107.03374, 2021. URL https://arxiv.org/abs/2107.03374.
A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Yang, A. Fan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024.
Y. Dubois, B. Galambosi, P. Liang, and T. B. Hashimoto. Length-controlled alpacaeval: A simple way to debias automatic evaluators. arXiv preprint arXiv:2404.04475, 2024.
X. Feng, Z. Wan, M. Wen, S. M. McAleer, Y. Wen, W. Zhang, and J. Wang. Alphazero-like tree-search can guide large language model decoding and training, 2024. URL https: //arxiv.org/abs/2309.17179.
L. Gao, J. Schulman, and J. Hilton. Scaling laws for reward model overoptimization, 2022. URL https://arxiv.org/abs/2210.10760.
A. P. Gema, J. O. J. Leang, G. Hong, A. Devoto, A. C. M. Mancino, R. Saxena, X. He, Y. Zhao, X. Du, M. R. G. Madani, C. Barale, R. McHardy, J. Harris, J. Kaddour, E. van Krieken, and P. Minervini. Are we done with mmlu? CoRR, abs/2406.04127, 2024. URL https://doi.or g/10.48550/arXiv.2406.04127.
Google. Our next-generation model: Gemini 1.5, 2024. URL https://blog.google/techno logy/ai/google-gemini-next-generation-model-february-2024.
Y. He, S. Li, J. Liu, Y. Tan, W. Wang, H. Huang, X. Bu, H. Guo, C. Hu, B. Zheng, et al. Chinese simpleqa: A chinese factuality evaluation for large language models. arXiv preprint arXiv:2411.07140, 2024.
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300, 2020.
Y. Huang, Y. Bai, Z. Zhu, J. Zhang, J. Zhang, T. Su, J. Liu, C. Lv, Y. Zhang, J. Lei, et al. C-Eval: A multi-level multi-discipline chinese evaluation suite for foundation models. arXiv preprint arXiv:2305.08322, 2023.
N. Jain, K. Han, A. Gu, W. Li, F. Yan, T. Zhang, S. Wang, A. Solar-Lezama, K. Sen, and I. Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code. CoRR, abs/2403.07974, 2024. URL https://doi.org/10.48550/arXiv.2403.07974.
S. Krishna, K. Krishna, A. Mohananey, S. Schwarcz, A. Stambler, S. Upadhyay, and M. Faruqui. Fact, fetch, and reason: A unified evaluation of retrieval-augmented generation. CoRR, abs/2409.12941, 2024. doi: 10.48550/ARXIV.2409.12941. URL https://doi.org/10.485 50/arXiv.2409.12941.
A. Kumar, V. Zhuang, R. Agarwal, Y. Su, J. D. Co-Reyes, A. Singh, K. Baumli, S. Iqbal, C. Bishop, R. Roelofs, et al. Training language models to self-correct via reinforcement learning. arXiv preprint arXiv:2409.12917, 2024.
H. Li, Y. Zhang, F. Koto, Y. Yang, H. Zhao, Y. Gong, N. Duan, and T. Baldwin. CMMLU: Measuring massive multitask language understanding in Chinese. arXiv preprint arXiv:2306.09212, 2023.
T. Li, W.-L. Chiang, E. Frick, L. Dunlap, T. Wu, B. Zhu, J. E. Gonzalez, and I. Stoica. From crowdsourced data to high-quality benchmarks: Arena-hard and benchbuilder pipeline. arXiv preprint arXiv:2406.11939, 2024.
H. Lightman, V. Kosaraju, Y. Burda, H. Edwards, B. Baker, T. Lee, J. Leike, J. Schulman, I. Sutskever, and K. Cobbe. Let’s verify step by step. arXiv preprint arXiv:2305.20050, 2023.
B. Y. Lin. ZeroEval: A Unified Framework for Evaluating Language Models, July 2024. URL https://github.com/WildEval/ZeroEval.
MAA. American invitational mathematics examination - aime. In American Invitational Mathematics Examination - AIME 2024, February 2024. URL https://maa.org/math -competitions/american-invitational-mathematics-examination-aime.
OpenAI. Hello GPT-4o, 2024a. URL https://openai.com/index/hello-gpt-4o/.
OpenAI. Learning to reason with llms, 2024b. URL https://openai.com/index/learnin g-to-reason-with-llms/.
OpenAI. Introducing SimpleQA, 2024c. URL https://openai.com/index/introducing -simpleqa/.
OpenAI. Introducing SWE-bench verified we’re releasing a human-validated subset of swebench that more, 2024d. URL https://openai.com/index/introducing-swe-bench -verified/.
Qwen. Qwq: Reflect deeply on the boundaries of the unknown, 2024a. URL https://qwenlm .github.io/blog/qwq-32b-preview/.
Qwen. Qwen2.5: A party of foundation models, 2024b. URL https://qwenlm.github.io/b log/qwen2.5.
D. Rein, B. L. Hou, A. C. Stickland, J. Petty, R. Y. Pang, J. Dirani, J. Michael, and S. R. Bowman. GPQA: A graduate-level google-proof q&a benchmark. arXiv preprint arXiv:2311.12022, 2023.
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, M. Zhang, Y. Li, Y. Wu, and D. Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024.
D. Silver, T. Hubert, J. Schrittwieser, I. Antonoglou, M. Lai, A. Guez, M. Lanctot, L. Sifre, D. Kumaran, T. Graepel, T. P. Lillicrap, K. Simonyan, and D. Hassabis. Mastering chess and shogi by self-play with a general reinforcement learning algorithm. CoRR, abs/1712.01815, 2017a. URL http://arxiv.org/abs/1712.01815.
D. Silver, J. Schrittwieser, K. Simonyan, I. Antonoglou, A. Huang, A. Guez, T. Hubert, L. Baker, M. Lai, A. Bolton, Y. Chen, T. P. Lillicrap, F. Hui, L. Sifre, G. van den Driessche, T. Graepel, and D. Hassabis. Mastering the game of go without human knowledge. Nat., 550(7676):354–359, 2017b. doi: 10.1038/NATURE24270. URL https://doi.org/10.1038/nature24270.
C. Snell, J. Lee, K. Xu, and A. Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters, 2024. URL https://arxiv.org/abs/2408.033 14.
T. Trinh, Y. Wu, Q. Le, H. He, and T. Luong. Solving olympiad geometry without human demonstrations. Nature, 2024. doi: 10.1038/s41586-023-06747-5.
J. Uesato, N. Kushman, R. Kumar, F. Song, N. Siegel, L. Wang, A. Creswell, G. Irving, and I. Higgins. Solving math word problems with process-and outcome-based feedback. arXiv preprint arXiv:2211.14275, 2022.
P. Wang, L. Li, Z. Shao, R. Xu, D. Dai, Y. Li, D. Chen, Y. Wu, and Z. Sui. Math-shepherd: A labelfree step-by-step verifier for llms in mathematical reasoning. arXiv preprint arXiv:2312.08935, 2023.
X. Wang, J. Wei, D. Schuurmans, Q. Le, E. Chi, S. Narang, A. Chowdhery, and D. Zhou. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171, 2022.
Y. Wang, X. Ma, G. Zhang, Y. Ni, A. Chandra, S. Guo, W. Ren, A. Arulraj, X. He, Z. Jiang, T. Li, M. Ku, K. Wang, A. Zhuang, R. Fan, X. Yue, and W. Chen. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark. CoRR, abs/2406.01574, 2024. URL https://doi.org/10.48550/arXiv.2406.01574.
C. S. Xia, Y. Deng, S. Dunn, and L. Zhang. Agentless: Demystifying llm-based software engineering agents. arXiv preprint, 2024.
H. Xin, Z. Z. Ren, J. Song, Z. Shao, W. Zhao, H. Wang, B. Liu, L. Zhang, X. Lu, Q. Du, W. Gao, Q. Zhu, D. Yang, Z. Gou, Z. F. Wu, F. Luo, and C. Ruan. Deepseek-prover-v1.5: Harnessing proof assistant feedback for reinforcement learning and monte-carlo tree search, 2024. URL https://arxiv.org/abs/2408.08152.
J. Zhou, T. Lu, S. Mishra, S. Brahma, S. Basu, Y. Luan, D. Zhou, and L. Hou. Instruction-following evaluation for large language models. arXiv preprint arXiv:2311.07911, 2023.
附录
A.贡献与致谢



在每个角色中,作者按名字的字母顺序排列。标有*的姓名表示已离开我们团队的个人。
原文地址

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)