deepseek-r1大模型探索笔记
最近我们中国出了一个deepseek大模型,对标甚至超越了外国的open AI等大模型。抱着要跟上科技潮流的想法,我在自己电脑的本地部署了一个deepseek。本文便是我的部署笔记和一些得出的结论。
deepseek-r1大模型探索笔记
文章目录
日志
upd on 20250205 [latest] 删去了被和谐掉的图片
upd on 20250204 文章初次发布
前言
最近我们中国出了一个deepseek-r1大模型,对标甚至超越了外国的open AI等大模型,暴击了美国的科技股。抱着要跟上科技潮流的想法,我在自己电脑的本地部署了一个deepseek。
一、为什么想到deepseek?
这是个很有意思的事情。之前同学发给我一个小红书上的帖子(link),
点开一看,内容还挺____的,是问“如果搞chatgpt和deepseek CP,他俩谁攻谁受”
以下↓几张图为帖子原图,为方便叙述所加,不代表我个人主观立场。
这些是那个帖子的作者去问了AI之后得到的反馈:


[中间这里有张图被和谐掉了,所以就不放了]

[中间这里也有张图被和谐掉了,所以就不放了]

这跟我想的AI完全不在一个level啊!?
我记得以前AI都是比较单纯木讷的,怎么现在像人一样了?
结果我就是因为这个才打算自己整一个deepseek看看效果。
二、部署过程
我用的是苹果电脑,所以用法和Windows有些区别,但是我个人感觉比Windows方便多了。
1.安装ollama
先去官网(link),点击download,正常的话会跳到一个github Release,但是最近github直接访问很不稳定,如图:

但是我们知道文件的网址是https://ollama.com/download/Ollama-darwin.zip,
找出我之前的一个网页版代理,croxyproxy(link),把前面.zip的网址拷进框里,点"Go!"

接下来会有一个"Proxy is launching"的界面,表示代理正在启动

等个两三秒,zip就会开始下载了

下载完毕它会在“下载”文件夹中出现,把它解压了之后是一个叫ollama.app的文件,长这样:

然后在访达(Finder)下按下Command + Shift + G组合键或者右键访达图标再点“前往文件夹…”,会弹出来一个输入框,往里面敲/Applications按回车会转到应用程序文件夹,或者你直接点左侧快捷标签也可以(如果你有的话),再把刚下载好的ollama.app拖进应用程序文件夹里
至此,ollama安装完成!
你去启动台看,会发现多了一个图标(千万不要眼疾手快去打开它,因为没必要):
小羊驼还怪可爱的是不是?
如果你有brew的话(想安装brew自己搜别的教程去,这不是本篇重点),在github比较顺畅时直接在终端(Terminal)下一行代码就能装ollama了:
brew install ollama
2.下载deepseek-r1大模型
ollama官网上有各种模型,直接点上方搜索框就能搜,我们以deepseek-r1为例子
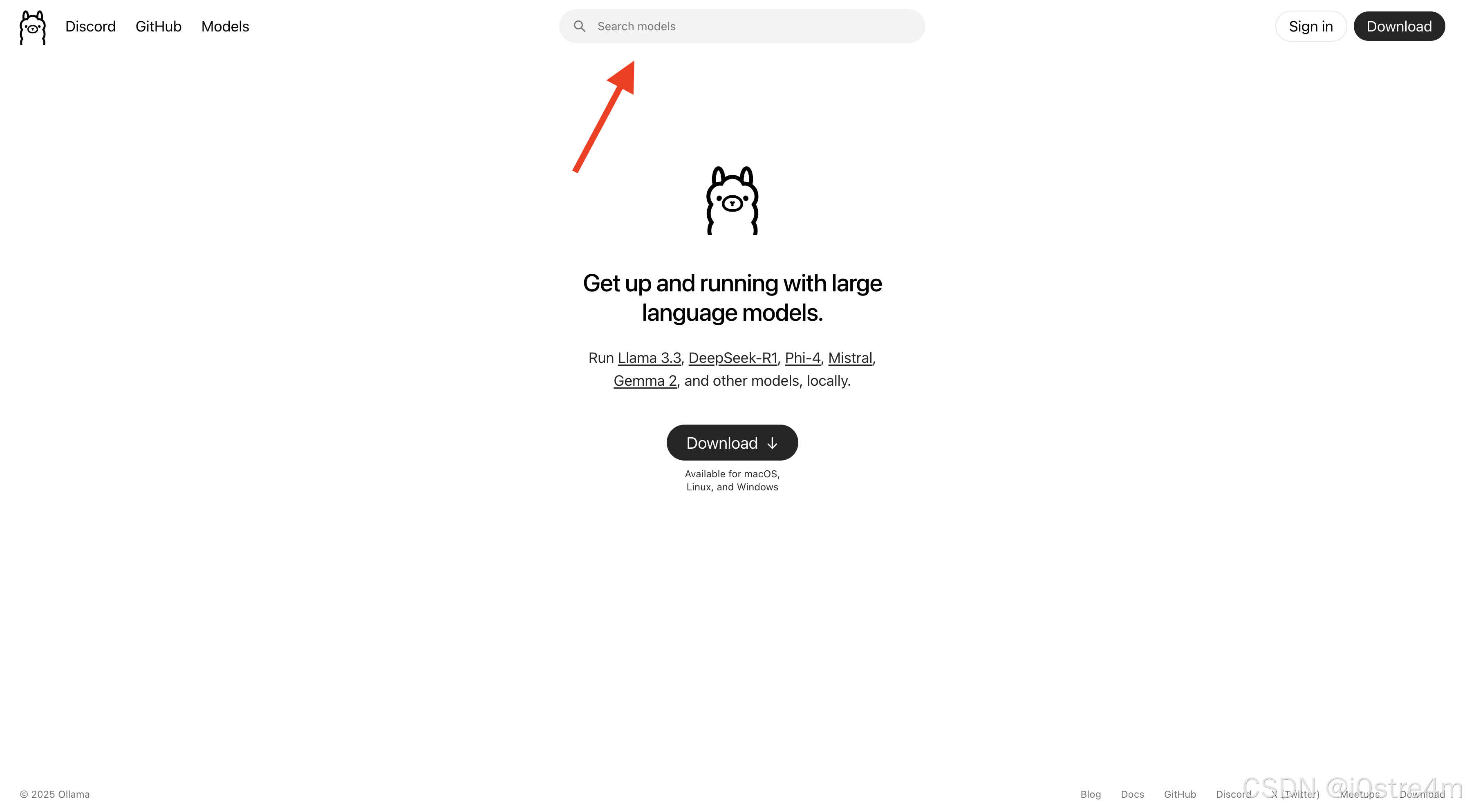
一搜就能搜到deepseek-r1的模型

如果将上图中7b的部分下拉展开,会发现有多个选项可选,
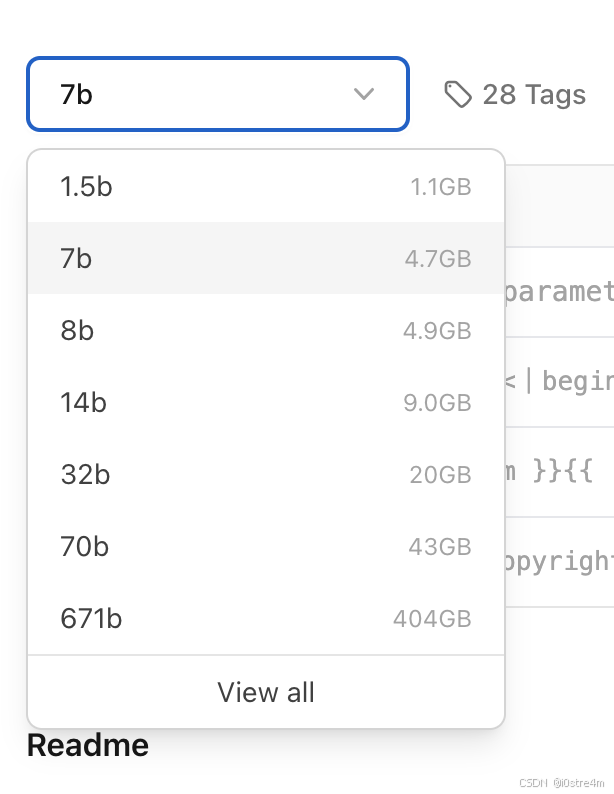
接着我们要看按自己的电脑配置适合多大参数的模型(这里几b就表示多少billion的参数,数值越大模型涵盖的信息就更多,后面搭出来的AI就有多智能)。点击电脑最左上角的苹果图标![]() ,再点关于本机
,再点关于本机![]() ,会弹出如下窗口:
,会弹出如下窗口:

能跑得动多大的模型主要是看GPU的,在上图中GPU就是图形卡那一栏,我的是4GB的,算性能好的,自己去查按自己的电脑配置能带得动几b参数。
我一开始不敢搞太大,试的是1.5b的,就是最小的那个,下载下来跑过了,还挺正常的,没有明显的欠缺之类的,可能是因为deepseek模型里有蒸馏技术(distill)和LLM啥的,这个还没专门去了解,后续有时间查好资料整理好我再更新吧。
好,回到正题,正常电脑的话跑个7b参数或8b参数的没问题,我相信我的电脑(毕竟按我这种喜欢折腾电脑的德行,这机子还能连续运行4个月不用重启),所以直接选择8b参数的(想选其他参数的自己看着本文融会贯通吧)
在终端下敲上这么一行:
ollama serve
这是为了让自己的电脑作为服务器在localhost:11434上运行(可以用这里来检查是否成功,如果正常的话会显示一行Ollama is running),后面的过程需要这样,
这时候终端里应该会弹出来一堆日志之类的东西,不用管,记住别把这个窗口关了就行,
然后再新开一个终端窗口,输入
ollama run deepseek-r1:8b
我这里以8b参数的模型举例,:后面就是参数的选项,可以根据ollama官网上的去选,
回车之后就开始自动下载了,是这样的:
xxx@xxxdeMacBook-Pro ~ % ollama run deepseek-r1:8b
pulling manifest
pulling 6340dc3229b0... 10% ▕█ ▏ 0.4/4.9 GB 1.5MB/s 51m12s
一开始很快,但后面会越来越慢,直到最后会在百分之九十几上等好久,所以你要有耐心,要么你就用caffeinate指令让电脑一个晚上不休眠来下载。
最终下载好之后是这样的:
Last login: Mon Feb 3 20:40:27 on ttys024
xxx@xxxdeMacBook-Pro ~ % ollama run deepseek-r1:8b
pulling manifest
pulling 6340dc3229b0... 100% ▕████████████████▏ 4.9 GB
pulling 369ca498f347... 100% ▕████████████████▏ 387 B
pulling 6e4c38e1172f... 100% ▕████████████████▏ 1.1 KB
pulling f4d24e9138dd... 100% ▕████████████████▏ 148 B
pulling 0cb05c6e4e02... 100% ▕████████████████▏ 487 B
verifying sha256 digest
writing manifest
success
>>> Send a message (/? for help)
这时候其实核心部分已经ok了,输入你要说的话,deepseek就已经能进行应答了,但是一直在终端下玩,没有一个像样的前端,总是差那么点意思,所以还要搞个前端。
3.加上chatbox前端
直接跑去chatbox官网下载,
下载下来之后是一个.dmg文件

双击打开,然后按它的指示去把Chatbox.app拖进Applications

这样启动台里也有chatbox的图标了,就跟之前的ollama是一样的

现在我们有俩新软件。
打开Chatbox,点左下角“设置” ,按我这样配置:
,按我这样配置:

主要设置就是这些,“严谨与想象”那一栏后续可以按照自己的喜好调整,但是那个系数拉的越大,生成的就越慢。
点侧面左上角的"Just chat"那一栏,把右下角模型设置成刚刚下载的(我这里就是8b的那个)

这时候就可以输入“你好”检验效果了!
4.大功告成
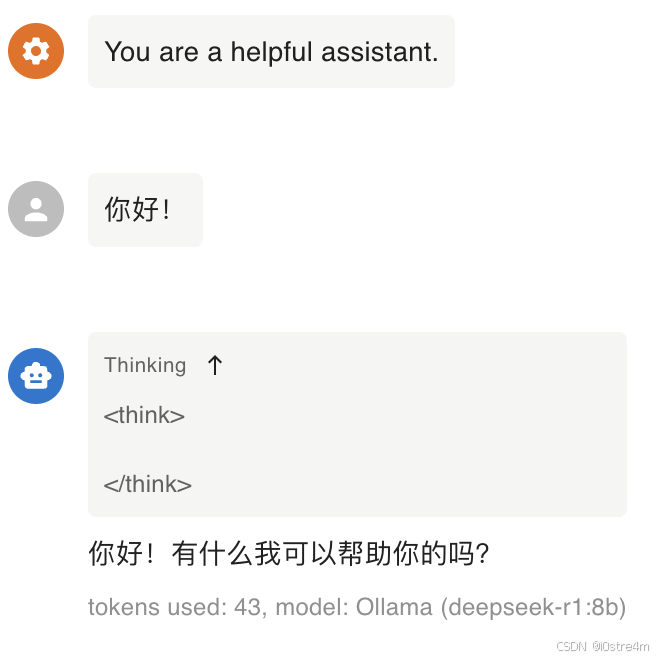
然后我又不忘初心地回到最初驱使我去研究deepseek的那个问题,并问给了deepseek:

得到了与小红书那个帖子中相似的回答(反正都是自己嬷自己)
三、得出结论
为什么最后结果看着还是比小红书中的那个逊色很多呢?我研究了一下,这和参数量有很大关系。
鉴于民用电脑只能到这个程度,我用的模型只有8b参数,而小红书上人家用的是手机APP,稍微动脑筋想想,很容易就能想到这么大运算量,放在电脑上都跑得不容易,怎么可能能在手机上跑呢,显然手机APP的原理和网页版的是一样的,都是发送用户的话给deepseek官方强大的服务器,然后在服务器上跑参数最多的大模型处理出来之后再返回给用户;而像我这种实实在在搭载在本地的偏小的大模型,能有这样的结果已经很不错了!
近期deepseek服务器遭到了攻击,中国红客联盟也是进行了反击,但这场攻击也导致deepseek服务器不稳定,而恰恰我是新注册的账号,会受到影响,问上去的问题都回给我一句“服务器繁忙,请稍后再试”,那我也没办法,只能等以后看服务器会不会好了。
总结
好了,以上就是本文的全部内容了,关于deepseek的话题,大家如果有什么想说的也可以写在评论区里,欢迎交流!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)