DeepSeek-V3——国产AI黑马如何用“东方魔法”颠覆全球AI格局?
DeepSeek V3出现的基本情况、国内外业内人士对DeepSeek-V3的看法、DeepSeek-V3背后的团队介绍、DeepSeek-V3牛在哪里、如何使用DeepSeek-V3、DeepSeek-V3有哪些不足、DeepSeek-V3对行业的影响等内容。
摘要
DeepSeek-V3出圈有一段时间了,作者在网上搜集DeepSeek-V3的资料,发现绝大多都是零散的信息,在充分阅读DeepSeek官网资料及其论文、以及网上的相关公开信息后,整理形成此文,主要内容包括DeepSeek V3出现的基本情况、国内外业内人士对DeepSeek-V3的看法、DeepSeek-V3背后的团队介绍、DeepSeek-V3牛在哪里、如何使用DeepSeek-V3、DeepSeek-V3有哪些不足、DeepSeek-V3对行业的影响等内容。
01.“东方魔法”DeepSeek-V3横空出世
国产开源MoE(Mixture-of-Experts混合专家)大模型DeepSeek-V3横空出世,全球AI圈炸了!引发全球关注,外媒称其为“东方魔法”。
据了解,DeepSeek-V3基于2048张H800GPU、14.8T Token高质量训练数据训练了两个月,总共花费557万美元,干出OpenAI、谷歌数亿美元才能达到的效果,很多方面甚至实现了超越,以其卓越的性能和极低的成本,打破了AI大模型领域的传统格局,我们今天来深度解读一下DeepSeek-V3。
02.各路神仙眼中的DeepSeek-V3
国外独立评测机构Artificial Analysis评价DeepSeek-V3为“超越了迄今为止所有开源模型”,并在多项基准测试中与OpenAI的GPT-4o和Anthropic的Claude 3.5 Sonnet不相上下。DeepSeek-V3的人工智能分析质量指数得分为80,领先于OpenAI的GPT-4o和Meta的Llama 3.3 70B等模型。目前唯一仍然领先于DeepSeek-v3的模型是谷歌的Gemini 2.0 Flash和OpenAI的o1系列模型。DeepSeek-V3领先于阿里巴巴的Qwen2.5 72B,已然成为中国的大模型领先者。
来自广发证券观点:DeepSeek-V3总体能力与其他大模型相当,逻辑推理和代码生成具有自身特点。2024年12月29日广发证券计算机行业分析师发布研报称:“为了深入探索DeepSeek-V3的能力,我们采用了覆盖逻辑、数学、代码、文本等领域的多个问题对模型进行测试,将其生成结果与豆包、Kimi以及通义千问大模型生成的结果进行比较。”测试结果显示,DeepSeek-V3总体能力与其他大模型相当,但在逻辑推理和代码生成领域具有自身特点。例如,在密文解码任务中,DeepSeek-V3是唯一给出正确答案的大模型;而在代码生成的任务中,DeepSeek-V3给出的代码注释、算法原理解释以及开发流程的指引是最为全面的。在文本生成和数学计算能力方面,DeepSeek-V3并未展现出明显优于其他大模型之处。
AI领域的顶尖人物对DeepSeek-V3 的评价褒贬不一:OpenAI创始成员卡帕西(Karpathy)称赞道:“DeepSeek-V3让在有限算力预算上进行模型预训练这件事变得容易。”他认为,DeepSeek-V3 的性能超越了Llama-3-405B,而训练消耗的算力仅为后者的1/11。
科技媒体Maginative的创始人兼主编Chris McKay对DeepSeek-V3评论称,对于人工智能行业来说,DeepSeek-V3代表了一种潜在的范式转变,即大型语言模型的开发方式。这一成就表明,通过巧妙的工程和高效的训练方法,可能无需以前认为必需的庞大计算资源,就能实现人工智能的前沿能力。他还表示,DeepSeek-V3的成功可能会促使人们重新评估人工智能模型开发的既定方法。随着开源模型与闭源模型之间的差距不断缩小,公司可能需要在一个竞争日益激烈的市场中重新评估他们的策略和价值主张。
Meta的扎克拍格在与政府对话的过程中,说DeepSeek的效果很好,并以此为由要求政府放松监管。
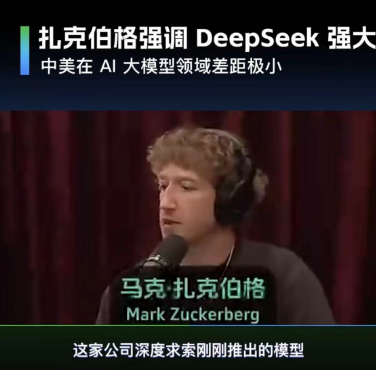
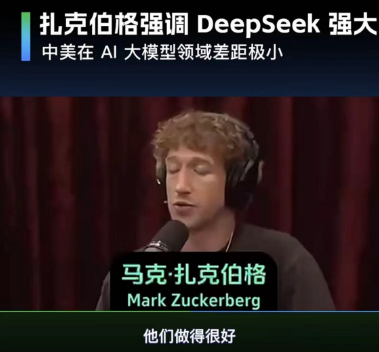
然而,OpenAI CEO山姆·奥特曼(Sam Altman)则在社交媒体上暗讽DeepSeek-V3“没有创新”,暗示其可能依赖现有技术而非真正的突破。
最终用户反应:DeepSeek-V3 的发布不仅在技术圈引发热议,也吸引了普通用户的关注。许多用户因未在讨论中提及DeepSeek-V3而表示抗议,评论区充斥着“国货之光”的赞誉。
03.DeepSeek-V3 金榜提名
DeepSeek-V3为啥会火,它的亮点在哪里?
首先看效果。每次出来一个新的大模型,他们都会在各大评测榜单上进行测评排名,DeepSeek也不例外,在DeepSeek官网我们可以查看到其汇总的BenchMark。
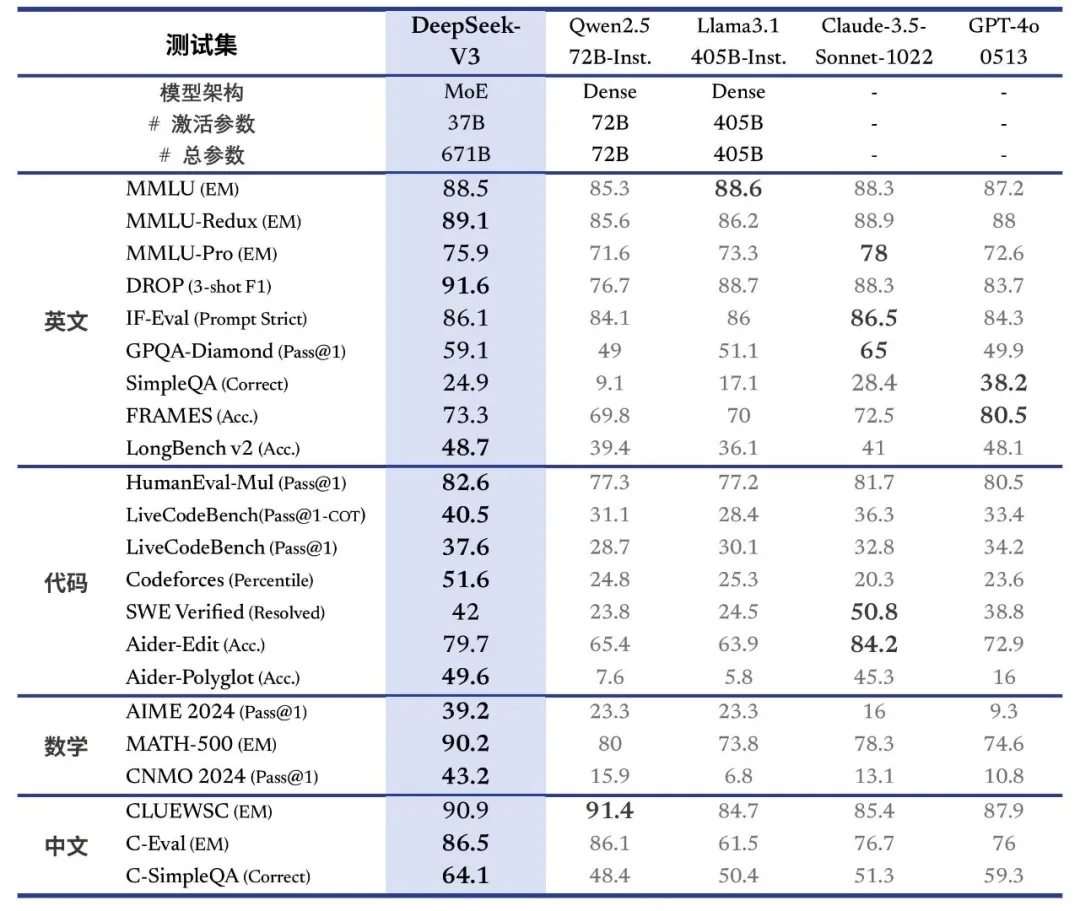
可以从此榜单上看出,DeepSeek-V3的性能表现在多个方面登顶开源之最,超越Llama3.1、Qwen2.5。在数学、编程等复杂任务上逼近Claude 3.5和GPT-4。各方面能力如下:
百科知识:DeepSeek-V3 在知识类任务(MMLU, MMLU-Pro, GPQA, SimpleQA)上的水平相比前代 DeepSeek-V2.5 显著提升,接近当前表现最好的模型 Claude-3.5-Sonnet-1022。
长文本:长文本测评方面,在DROP、FRAMES 和 LongBench v2 上,DeepSeek-V3 平均表现超越其他模型。
代码:DeepSeek-V3 在算法类代码场景(Codeforces),远远领先于市面上已有的全部非 o1 类模型,并在工程类代码场景(SWE-Bench Verified)逼近 Claude-3.5-Sonnet-1022。
数学:在美国数学竞赛(AIME 2024, MATH)和全国高中数学联赛(CNMO 2024)上,DeepSeek-V3 大幅超过了所有开源闭源模型。
中文能力:DeepSeek-V3 与 Qwen2.5-72B 在教育类测评 C-Eval 和代词消歧等评测集上表现相近,但在事实知识 C-SimpleQA 上更为领先。
有人会说,现在的大模型评测榜单已经泛滥了,很多大模型可以刷榜单,可信度是不是不高哇。这里,还有一个更为权威的榜单,即LiveBench,LiveBench大有来头,它是由图灵奖得主、Meta 首席 AI 科学家杨立昆(Yann LeCun)联合 Abacus.AI、纽约大学等机构推出的大模型测评基准。简单来说,经常对当今由 OpenAI 引领的大模型技术路线一通抨击的杨立昆牵头做了一个对刷榜行为异常警觉的大模型评测基准——而就是这样一个十分严苛的榜单LiveBench 包括数学、推理、编程、语言理解、指令遵循和数据分析在内的多个复杂维度对模型进行评估。之所以名字里有个「live」,就是因为这个榜单采用了新颖的数据来源并保持每月更新,这杜绝了大模型通过预训练和微调作弊的可能性。LiveBench 也被行业内誉为「世界上第一个不可玩弄的 LLM 基准测试」,官网上明晃晃地写着「A Challenging,Contamination-Free LLM Benchmark」。
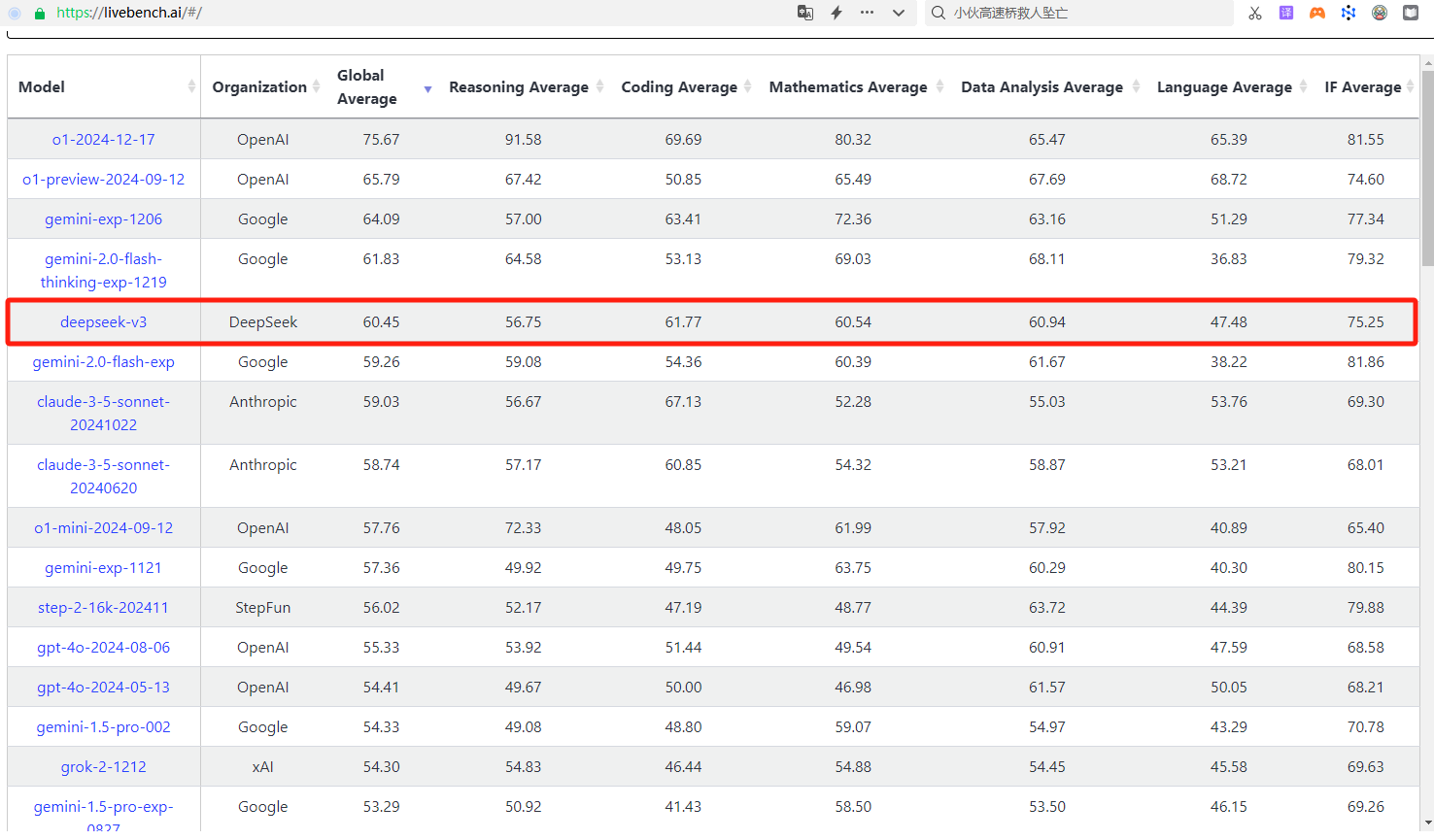
从榜单上可以看出DeepSeek-V3也是名列前茅的。
其次看价格。即使效果再好,但是费用很高,这肯定也是不行的,我们小老百姓需要实惠,DeepSeek-V3的价格怎样呢?我们了解到,其训练成本仅为557万美元,推理成本低至每百万Token 1元,约为GPT-4 Turbo的1/70。训练和使用成本上有着具大的优势。被网友称为“AI拼多多”、“英伟达大空头”、“黑科技”。
04.DeepSeek 背后的金主爸爸
DeepSeek-V3这一次火爆出圈,谁这么强呢?深扒之后,我们发现基后边的公司是杭州深度求索人工智能基础技术研究有限公司,我们下文称其为深度求索公司。进一步了解到,深度求索公司则是由幻方量化投资创立,是真正的背后大佬。这是一家依靠数学与人工智能进行量化投资的对冲基金公司,成立于2008年。团队成员具有丰富的科学研究、软件架构、软硬件工程和投资经验,对量化交易技术及策略造诣颇深。创始人梁文峰是技术出身,是个80后,团队全部来自本土,专注大模型研发,据说,其实他们一开始就是做大模型,只是想在金融领域先做出成绩来,所以做了量化,难怪人家在2021年,GPT3.5出来之前就投资10亿,屯了上万张A100的GPU卡,这眼光也是没谁了,当时放眼全中国,也就只有那几家大厂有这个实力。
05.DeepSeek-V3的金箍棒在哪里
先讲个段子。孙悟空问土地公公:“我的金箍棒在哪里?”土地公公回答说:“你的金箍棒就棒在很配你的发型”。DeepSeek-V3的金箍棒在哪里呢?前边我们讲了它又好用又便宜,底层的技术强在哪里呢?
通过对DeepSeek-V3的论文的解读(我们可以通过以下链接查看论文:https://github.com/DeepSeek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf)。我们了解到DeepSeek-V3有以下技术特性:
(1)高效的架构设计
1)采用DeepSeekMoE 架构
MoE架构不是新技术了,最早由欧洲Mistray公司推出,推出的时候也广受关注,但有一段时间没有新的东西出来,MoE包含数百个专门化的子模型(专家),每个专家擅长处理特定类型的任务。系统根据输入内容动态选择最合适的专家进行处理,从而提升整体效率。像一家医院,里面有几百位不同领域的专家医生。当病人来看病时,系统会根据病情自动分诊,让最擅长的医生来治疗,既快又准!此次DeepSeek-V3也采用混合专家模型架构,相比传统的 MoE 架构(如 GShard),它采用了更细粒度的专家划分,并将部分专家作为共享专家,提升了模型的训练效率和推理性能。
2)多头潜在注意力机制(Multi-head Latent Attention, MLA)
MLA是DeepSeek在24年5月份发布的DeepSeek-V2大模型中用到的KV Cache压缩技术,正是在该技术的加持下DeepSeek-V2可以大幅压缩KV Cache的大小,减小内存占用,进而大幅提升吞吐量,提升训练效率。MLA是少有的由国内公司做出的硬核创新,在出现新的KV Cache压缩技术之前后续的大模型可能都会采用MLA,它的压缩效果接近MQA,但是生成效果却还比MHA更好。MLA相比MQA和MHA相比做到了既要又要,着实牛逼。简单理解就是,MLA就像读书时用荧光笔划重点,只标记最关键的内容,忽略无关的部分,这样读得更快,记得更牢。
(2)无辅助损失的负载均衡策略
DeepSeek-V3 采用了无辅助损失的负载均衡策略,以优化混合专家(MoE)模型中专家任务的分配。该策略通过智能算法动态调整专家任务分配,避免某些专家因任务过载而成为瓶颈。为了防止单个序列内的极端不平衡,DeepSeek-V3 还引入了序列级负载均衡损失,进一步优化了专家负载的分配。
(3)多 token 预测训练目标MTP
MTP技术:(Multi-Token Prediction,MTP,多 Token 预测)是一种用于大语言模型(LLM)训练和推理的创新技术。与传统的单 Token 预测不同,MTP 技术允许模型同时预测多个连续的 Token,从而显著提升模型的效率和上下文理解能力。传统的语言模型通常采用自回归(Autoregressive)方式,即每次预测一个 Token,然后将该 Token 作为输入继续预测下一个 Token。这种方式虽然简单,但效率较低,尤其是在生成长文本时。MTP 技术通过以下方式改进这一过程:多 Token 并行预测:模型在每次推理时同时预测多个连续的 Token,而不是逐个预测。这种策略不仅提高了数据效率,还使模型能够更好地规划其表示,从而提升整体性能。
(4)高效的训练框架
1)基于FP8的混合精度训练兼顾精度与效率
DeepSeek-V3 在训练过程中采用了 FP8(8位浮点数)混合精度技术,这一技术为其带来了显著的优势,尤其是在计算效率、内存占用和成本控制方面。FP8 是一种低精度浮点数格式,仅使用8位二进制数表示数据,相比于传统的 FP16(16位)和 FP32(32位),FP8 的计算量大幅减少。对于DeepSeek-V3高达671B参数量的模型如果采用高精度训练,其需要耗费的资源及时间不可想像。当然,整个模型训练过程中还是有一些数据需要进行高精度计算,如梯度计算等,还是需要使用FP16或FP32。
2)DualPipe 算法
DeepSeek-V3在训练过程中采用了DualPipe 跨节点通信优化技术。DualPipe 是一种创新的跨节点通信技术,旨在解决分布式训练中数据传输与计算之间的瓶颈问题。DualPipe 通过设计两条并行流水线,使得数据传输和计算能够同时进行,避免了传统单流水线中因等待数据传输而导致的计算资源闲置,DualPipe 使得 DeepSeek-V3 的训练速度提升了 50%,同时通信开销减少了 20%。
- 内存优化
DeepSeek-V3 通过重新计算 RMSNorm 和 MLA 上投影操作,减少了激活内存的存储需求,进一步优化了内存使用。
(5)高效的推理与部署
1)预填充和解码分离
DeepSeek-V3 在推理时采用了预填充和解码分离的策略,通过冗余专家部署和动态路由优化,确保了推理时的负载均衡和高吞吐量。
- 低延迟通信
在推理阶段,DeepSeek-V3 使用了高效的跨节点全对全通信内核,充分利用了 InfiniBand 和 NVLink 的带宽,进一步降低了推理延迟。
(6)其它优化技术
混合并行策略:DeepSeek-V3 采用了混合并行策略,结合了数据并行、模型并行和流水线并行的优势,以最大化训练效率。可以根据模型结构和硬件资源,灵活选择最适合的并行策略。通过混合并行策略,DeepSeek-V3 能够在不同训练阶段动态调整并行方式,进一步提升训练效率。
通信优化技术:在分布式训练中,通信开销是影响效率的关键因素。DeepSeek-V3 也通过多种通信优化技术减少通信开销。例如梯度压缩:在梯度同步过程中,使用梯度压缩技术减少通信数据量。异步通信:通过异步通信机制,使得计算和通信能够部分重叠,减少等待时间。
知识蒸馏:DeepSeek-V3 从 DeepSeek-R1 系列模型中蒸馏了推理能力,显著提升了其在数学和代码任务上的表现。
自奖励机制:在强化学习阶段,DeepSeek-V3 采用了自奖励机制,通过模型自身的反馈来优化生成结果,进一步提升了模型的生成质量和推理能力。
通过算法和工程上的创新,DeepSeek-V3 的生成吐字速度从 20 TPS 大幅提高至 60 TPS,相比 V2.5 模型实现了 3 倍的提升,为用户带来更加迅速流畅的使用体验。
06.DeepSeek-V3有哪些玩法?
大家都看到了DeepSeek-V3好牛掰呀,我们普通人能不能上手试一下。答案是完全可以,而且现在就可以。跟着作者快来一试吧。我们从易到难来给大家讲解。最简单的使用方式就是我们上官网或下载APP直接用,如果要开发自己的应用或集成到自己的应用中,则能过官方提供的API来调用,再难一点的呢,我们自己部署DeepSeek-V3进行推理应用,当然对于大模型骨灰级玩来来说可以尝试基于DeepSeek-V3进行微调来实现自己垂直行业的模型。下边我们逐一探讨。
(1)官网直接使用
访问DeepSeek官网https://www.deepseek.com/,当然需要注册和登录哦。

我们直接开始对话,可以测试一下效果。
DeepSeek页面极为简洁,主框仅有深度思考、联网搜索、上传文件、发送四个按钮。
如果不打开联网搜索功能,将无法搜索网上相关的信息,只能当作本地大模型使用,且深度思考和联网搜索无法同时开启。提供联网搜索(可即时上网搜索相关资料作为提示词内容)、深度模式(采用思维链进行深度思考,回答问题更准确与全面),支持文件上传(文档解析与理解)。
下面来进行一个简单的测试,针对国内几个主流的大模型来进行对比。
提示词:strrawberrry里有几个“r”,请逐个帮我数出来,各家大模型回答情况如下:
纳米搜索(360):回答3,错误。
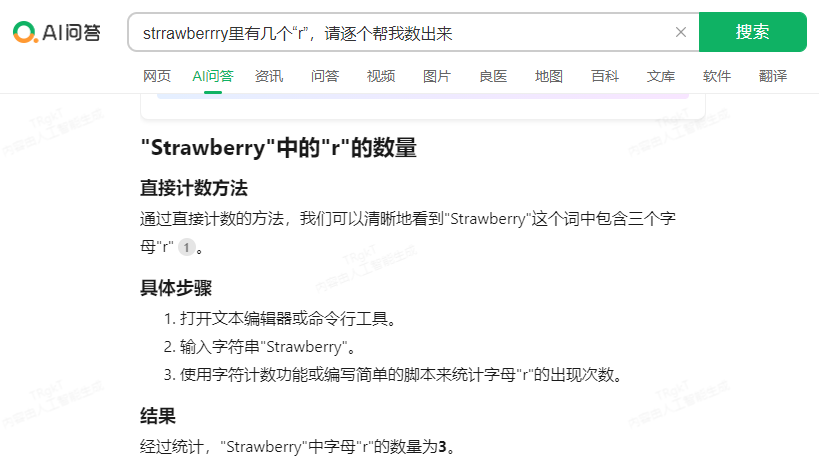
智谱GLM-4:回答2,错误。
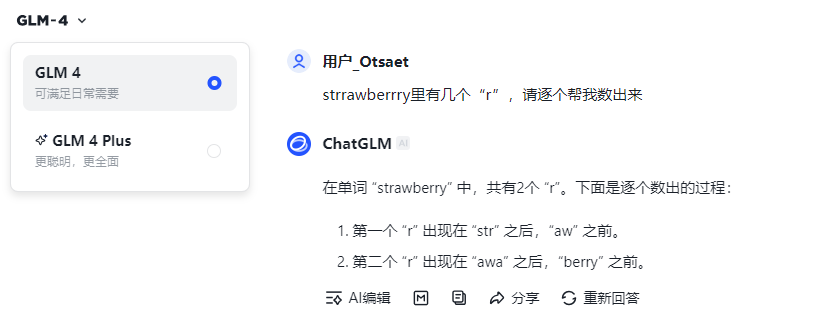
文心大模型3.5:回答4,错误。
豆包:回答2,错误。
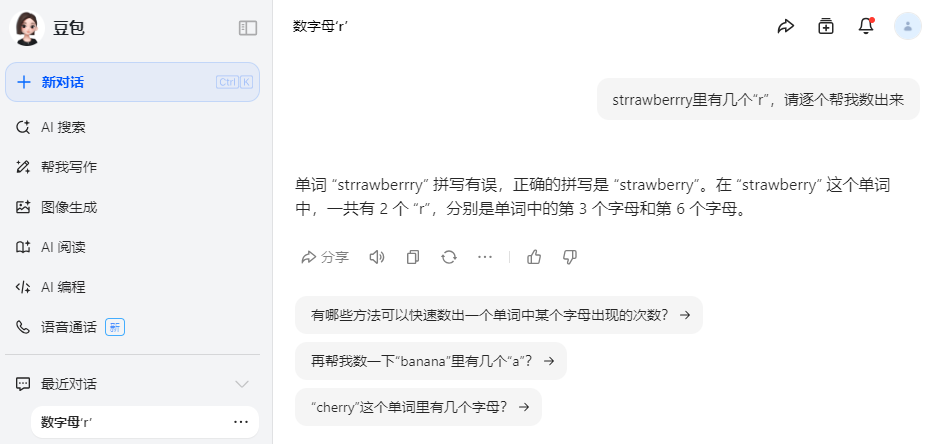
DeepSeek-V3:回答5,指定位置也正确,完胜。

(2)API调用
在官网注册后,进入开放平台,在左侧菜单中创建并获取API 信息(包括名称和Key)。
VSCODE中安装Cline插件(Cline是一个开源的VSCode插件,能够与DeepSeek等AI模型无缝集成,提供智能代码编辑功能。),在VSCODE中打开CLINE,选择DeepSeek-chat模型,输入API 地址及API Key,如下图所示:
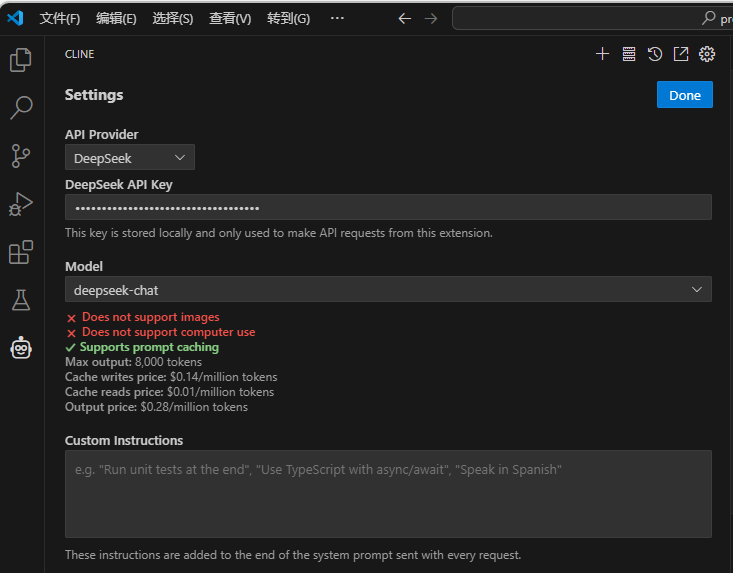
进行测试使用:
可通过官网提供的在线文档https://api-docs.DeepSeek.com/zh-cn/ 编写curl、python、nodejs调用API的代码,以Python为例:
# Please install OpenAI SDK first: `pip3 install openai`
from openai import OpenAI
client = OpenAI(api_key="", base_url="https://api.DeepSeek.com")
response = client.chat.completions.create(
model="DeepSeek-chat",
messages=[
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "Hello"},
],
stream=False
)
print(response.choices[0].message.content)执行效果如下:
(3)自己部署DeepSeek-V3
DeepSeek-V3模型的参数规模为6710亿,模型的文件大小约为642G,参数量巨大,需要的推理资源也相对高许多,需要16块H100GPU,以下是相关资源配置要求:
我们知道,绝大部分读者呢,是不太可能有这些资源的,怎么办呢?我们就得找免费的资源,类似我们去超市吃试吃的食品,不要不好意思,自己得实惠最重要。
这里给大家推荐九章云极的《DeepSeek-V3 开启分布式推理时代,实践看这篇就够了》这篇文章,链接地地址如下:https://docs.alayanew.com/docs/documents/bestPractice/bigModel/DeepSeekV3Inference,厂家正在做促销活动,提供试用资源,想自己上手测试一下的筒子们可以尽早申请,资源有限,先到先得,抢完为止。薅羊毛地址如下,当然也是需要注册的哦:https://docs.alayanew.com/docs/documents/newActivities/DeepSeekv3。
另外,后续作者经过实践后,再编写基于DeepSeek-V3的微调垂直大模型文章,希望看到这里的筒子们点个关注,以免走丢。
诚然,我们国产大模型DeepSeek-V3这次给大家长脸了,但是我们要保持冷静,才能有持续的进步,因此我们也要分析一下DeepSeek-V3的不足之处。据DeepSeek官方自己描述及广大试用过的网友反馈,我们发现它有以下不足之处:
(1)无多模态支持
功能相对单一,只有自然语言对话功能,官方表示下一步会拓展至多模态领域。现在能上传图片,但只能实现OCR提取图像中的文字。
(2)上下文长度限制为64K
这一点对需要进行长上下文理解和推理的用户来说不太友好,据厂家介绍DeepSeek-V3目前没有用RAG,所以比不上Kimi Chat的128k的上下文长度。
(3)未来会涨价
现在的价格极低,但DeepSeek官网表示北京时间 2025 年 2 月 8 日 24:00后会涨价,尽管还是比其它厂家便宜很多,但对于调用量大的用户来说也是一笔不小的费用。
(4)其它的局限
蒸馏技术的局限性:DeepSeek-V3使用了数据蒸馏技术来提升训练效率。这种技术虽然可以提高模型训练的效率,但也存在一定的局限性。例如,有学者指出,使用蒸馏技术训练的模型可能无法超越其基础模型的能力。此外,在处理多模态数据方面,这种技术的效果可能不佳。
处理复杂场景的局限性:尽管DeepSeek模型在多模态处理、高性能计算等方面展现出显著优势,但在处理极端复杂或者非常规的视觉-语言场景时,模型可能还需要进一步优化。
与顶级模型的差距:DeepSeek模型虽然在某些评测中领先于一众开源模型,但与顶级模型如GPT-4相比,仍存在一定的差距。例如,在谷歌发布的指令跟随评测集中,DeepSeek模型的得分落后于GPT-4。
07.DeepSeek-V3大闹龙宫,在AI行业掀起波澜
DeepSeek-V3在 AI 领域掀起了不小的波澜,对整个行业产生了多方面的深远影响。
价格层面,它引发了一场价格地震。此前,高昂的成本使得一些优质模型如 OpenAI,价格高达 200 刀,将许多用户拒之门外,仅能让小部分人率先使用。而 DeepSeek-V3的出现,打破了这一局面,促使AI行业再度打响价格战。各企业为了竞争,不得不降低大模型价格,从而让更多普通人和企业能够用上性能优良的模型,推动了AI技术的普及。
思维层面,DeepSeek-V3 带来了一场革命。它展现出的东方工程精细化实现方式,吸引了各方目光。尽管它采用的部分核心技术并非全新发明,但通过巧妙整合与优化,取得了显著成效。这让各大厂商意识到,在追求理论创新的同时,不能忽视工程的精细化。企业开始在两者之间寻求平衡,由此引发了效率方式的竞赛,为行业发展注入新的活力。类比小米Su7,DeepSeek-V3 通过整合和优化现有技术,提供高性价比的AI解决方案,正在颠覆AI行业的传统格局。小米Su7 的成功在于用成熟技术打造出具有竞争力的产品,而DeepSeek-V3 则通过类似的策略,将AI技术从高不可攀的神坛拉入寻常百姓家。这种模式不仅改变了AI技术的获取方式,还为整个行业注入了新的活力。未来,随着更多类似DeepSeek-V3 的低成本高性能模型的出现,AI技术将更加普及,应用场景将更加丰富,最终推动整个行业向更高效、更普惠的方向发展。
在开源领域,DeepSeek-V3 的蝴蝶效应显著。它是开源模型,这一特性使得开源之王的地位从Llama过渡到了DeepSeek。原本依赖Llama的开源社区和企业,尤其是国内相关群体,看到 DeepSeek 的崛起,仿佛看到自家兄弟取得成就,内心充满安心。此外,DeepSeek-V3 训练成本仅 557 万美元,相较于其他动辄数亿美金的模型,成本大幅降低。这使得更多科技公司,包括小型企业,都有机会参与到训练大模型的行列中,增加了入场玩家数量,有力地加速了 AI 民主化进程,为 AI 走向大众、迈向通用人工智能(AGI)清除了部分障碍。
最后,真心希望我们国家在人工智能领域,特别是大模型和GPU芯片领域尽早实现全面的自主可控、全面超车,这些要靠千千万万的人工智能同行的共同努力。
声明:本文部分文字与图片来源于网络,如有侵权,请联系作者删除。
需要交流或技术支持的朋友请关注以下VX公众号:峰哥AI研习社;及加VX群:seedzhang。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 13
13 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)