DEEPSEEK技术要点
DeepSeek-R1-Zero 是一个完全通过强化学习训练的模型,没有使用监督学习作为预训练步骤。以往的研究工作大多依赖于大量的监督数据来提升模型性能。在本研究中展示了即使不依赖监督微调(SFT)作为预训练步骤,通过大规模强化学习(RL)也能显著提升推理能力。此外,我们还展示了通过引入可以进一步提升性能。在接下来的章节中,将按顺序介绍:(1)DeepSeek-R1-Zero,它直接在基础模型上应
DeepSeek-R1-Zero 是一个完全通过强化学习训练的模型,没有使用监督学习作为预训练步骤。
以往的研究工作大多依赖于大量的监督数据来提升模型性能。在本研究中展示了即使不依赖监督微调(SFT)作为预训练步骤,通过大规模强化学习(RL)也能显著提升推理能力。此外,我们还展示了通过引入少量冷启动数据可以进一步提升性能。在接下来的章节中,将按顺序介绍:
(1)DeepSeek-R1-Zero,它直接在基础模型上应用 RL,不依赖任何监督微调数据;
(2)DeepSeek-R1,它从经过长推理链(Chain-of-Thought, CoT)数据微调的检查点开始应用 RL;
(3)将 DeepSeek-R1 的推理能力蒸馏到小型dense模型中。
1. DeepSeek-R1-Zero:基础模型上应用RL
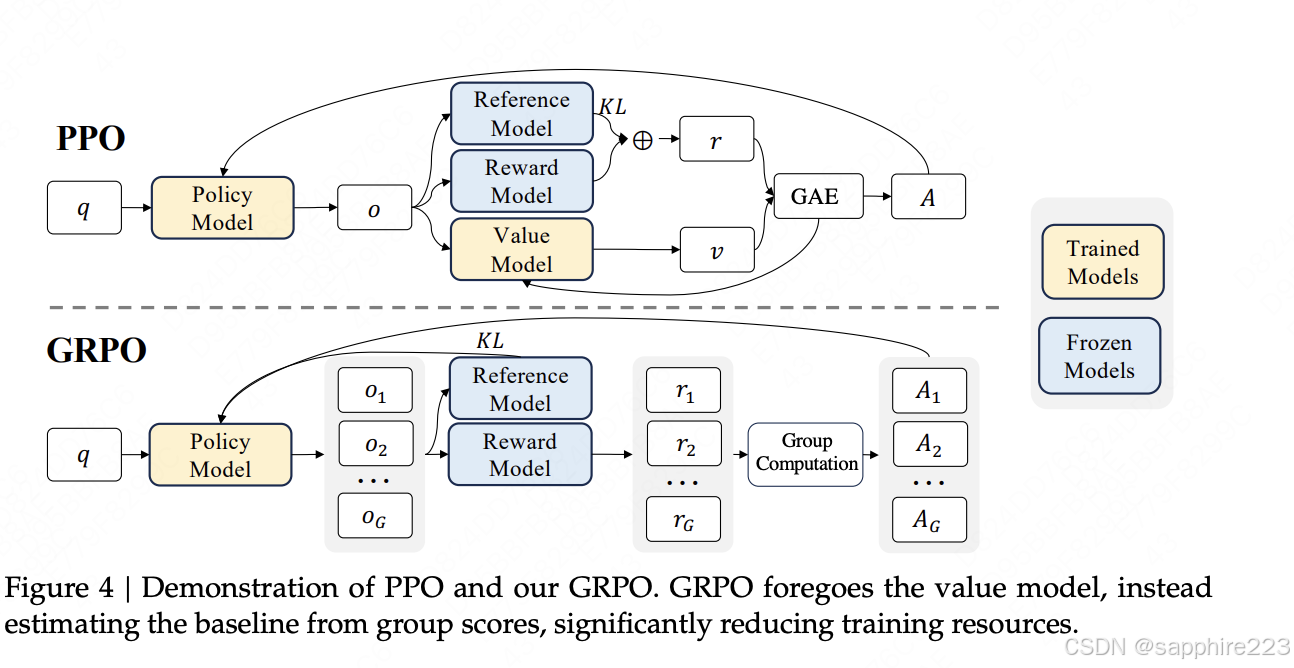
为了节省 RL 的训练成本,我们采用了 Group Relative Policy Optimization(GRPO)。GRPO 放弃了通常与策略模型大小相同的批判模型(critic model),而是通过组分数来估计Baseline。
为了训练 DeepSeek-R1-Zero,设计了一个简单的模板,指导基础模型按照我们的指定指令进行操作。如上表所示,该模板要求 DeepSeek-R1-Zero 首先生成推理过程,然后提供最终答案。我们故意将约束限制在这一结构化格式上,避免任何内容相关的偏见——例如强制要求反思性推理或推广特定的解决问题策略——以确保我们能够准确观察模型在强化学习(RL)过程中的自然发展。
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning

随着强化学习(RL)训练的推进,DeepSeek-R1-Zero 的性能呈现出稳定且一致的提升。值得注意的是,AIME 2024 的平均 pass@1 分数显著提高,从初始的 15.6% 提升至 71.0%,达到了与 OpenAI-o1-0912 相当的性能水平。这一显著提升突显了我们 RL 算法在优化模型性能方面的有效性。
研究结果表明,通过 RL,DeepSeek-R1-Zero 能够在无需任何监督微调数据的情况下获得强大的推理能力。这一成就值得关注,因为它突出了模型通过 RL 单独学习和泛化的能力。此外,通过应用多数投票(majority voting),DeepSeek-R1-Zero 的性能还可以进一步提升。例如,在 AIME 基准测试中应用多数投票后,DeepSeek-R1-Zero 的性能从 71.0% 提升至 86.7%,超过了 OpenAI-o1-0912 的性能。
它突显了强化学习的力量和美丽:我们不是明确地教模型如何解决问题,而是仅仅提供正确的激励,模型就会自主发展出高级的问题解决策略。“顿悟时刻” 有力地提醒我们,RL 解锁人工系统中智力新水平的潜力,为未来更自主、更适应性强的模型铺平了道路。
DeepSeek-R1-Zero 的缺点:
尽管 DeepSeek-R1-Zero 展示了强大的推理能力,并且能够自主发展出意外且强大的推理行为,但它面临着一些问题。例如,DeepSeek-R1-Zero 在可读性方面表现不佳,存在语言混用的问题。
2. DeepSeek-R1:引入冷启动的强化学习
DeepSeek-R1:引入冷启动的强化学习
受到 DeepSeek-R1-Zero 令人鼓舞的结果的启发,自然会提出两个问题:
1)通过引入少量高质量数据作为冷启动,是否可以进一步提升推理性能或加速收敛?
2)如何训练一个用户友好的模型,使其不仅能够产生清晰连贯的推理链(CoT),还具备强大的通用能力?
为了解决这些问题,我们重新设计了 DeepSeek-R1 的训练流程。该流程包括以下四个阶段:冷启动、面向推理的强化学习、拒绝采样与监督微调、面向所有场景的强化学习。
1. 冷启动:
为了避免RL训练早期的不稳定,R1中构建并收集了一小部分长CoT数据用于微调模型作为RL训练的起始点。为了收集这些数据,我们探索了几种方法:使用长 CoT 示例进行少样本提示,直接提示模型生成详细的答案并进行反思和验证,收集 DeepSeek-R1-Zero 的可读格式输出,并通过人工标注进行后处理以完善结果。
2. 面向推理的强化学习
在训练过程中,我们观察到 CoT 经常出现“语言混用”,尤其是在涉及多种语言的 RL 提示中。为了解决语言混用问题,我们在 RL 训练中引入了语言一致性奖励:计算方法是 CoT 中目标语言单词的比例。尽管消融实验表明,这种对齐会导致模型性能略有下降,但这种奖励符合人类偏好,使输出更具可读性。最后,我们将推理任务的准确性奖励和语言一致性奖励直接相加,形成最终奖励。然后我们在微调后的模型上应用强化学习(RL)训练,直到模型在推理任务上收敛。
3.拒绝采样与监督微调
当面向推理的 RL 收敛时,我们利用由此产生的检查点为下一轮收集监督微调(SFT)数据。与仅关注推理的初始冷启动数据不同,这一阶段纳入了来自其他领域的数据,以增强模型在写作、角色扮演和其他通用任务中的能力。具体来说,我们按照以下方式生成数据并微调模型:
推理数据:我们策划了推理提示,并通过从上述 RL 训练的检查点进行“拒绝采样”来生成推理轨迹。在前一阶段,我们仅纳入了可以通过基于规则的奖励进行评估的数据。然而,在这一阶段,我们通过扩展数据集,纳入了一些使用生成式奖励模型的数据,即将真实值和模型预测输入 DeepSeek-V3 进行判断。此外,由于模型输出有时混乱且难以阅读,我们过滤掉了混用语言、长段落和代码块的 CoT。对于每个提示,我们采样多个回答,并仅保留正确的回答。总共收集了大约 600k 条与推理相关的训练样本。
非推理数据:对于写作、事实问答、自我认知和翻译等非推理数据,我们采用了 DeepSeek-V3 的流程,并重用了 DeepSeek-V3 的部分 SFT 数据集。对于某些非推理任务,我们通过提示 DeepSeek-V3 生成潜在的 CoT,然后再回答问题。然而,对于简单的查询(如“你好”),我们不提供 CoT 回答。最终,我们收集了大约 200k 条与推理无关的训练样本。
我们使用上述策划的数据集(约 800k 样本)对 DeepSeek-V3-Base 进行了两个周期的微调。
4.面向所有场景的强化学习:
为了进一步使模型符合人类偏好,我们实施了一个次要的强化学习阶段,旨在提升模型的有用性和无害性,同时优化其推理能力。具体来说,我们使用组合的奖励信号和多样化的提示分布来训练模型。
对于推理数据,我们遵循 DeepSeek-R1-Zero 中概述的方法,使用基于规则的奖励来指导数学、编程和逻辑推理领域的学习过程。
对于通用数据,我们依赖于奖励模型来捕捉复杂且微妙场景中的人类偏好。我们基于 DeepSeek-V3 流程,采用了类似的偏好对和训练提示分布。
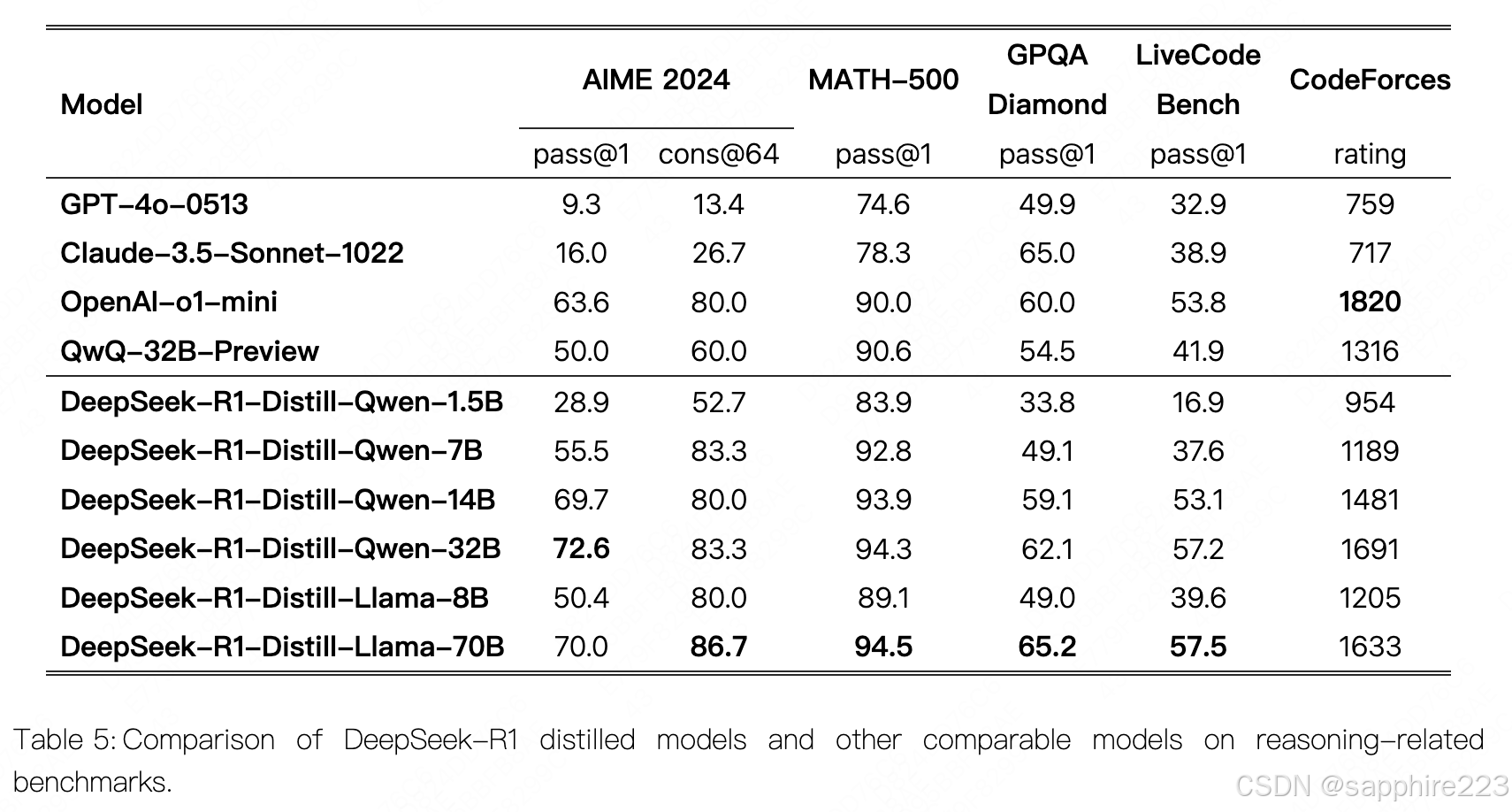
3.将80万样本用于微调小模型—赋予小模型推理能力
对于蒸馏模型,我们仅应用了 SFT,并没有 RL 阶段,尽管加入 RL 可能会显著提升模型性能。我们的主要目标是展示蒸馏技术的有效性,将 RL 阶段的探索留给更广泛的学术界。
其他讨论:
蒸馏与强化学习的对比:
可以得出以下两个结论:
-
将更强大的模型的能力蒸馏到小型模型中可以取得出色的结果,而小型模型仅依靠本文提到的大规模 RL 训练需要巨大的计算资源,且可能无法达到蒸馏的效果。
-
虽然蒸馏策略既经济又有效,但要突破智能的边界,可能仍然需要更强大的基础模型和更大规模的强化学习。
失败的尝试:
- MCTS 可以提升性能,但通过自我搜索迭代提升模型性能仍然是一个重大挑战。
- PRM 在重新排序模型生成的前N个回答或协助引导搜索方面表现出色(Snell et al., 2024),但与它在大规模强化学习过程中引入的额外计算开销相比,其优势是有限的。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)