
标注时代:DeepSeek带给数据标注行业的启示
最终数据标注作为数据价值生成的一环,或许数据标注价值不会完全统一,但DeepSeek基座提供了价值评估的"标尺"——通过将标注质量、场景价值、合规成本等维度量化,构建动态定价模型(如DeepSeek-Pricing),推动数据标注从"成本中心"向"价值中心"转型还是非常有可能的。以此为基础就可以对数据质量和场景价值作为定价的核心维度,例如可以数据质量的标注精度(如DeepSeek-R1评估的F1分
标注猿的第82篇原创
一个用数据视角看AI世界的标注猿
大家好,我是AI数据标注猿刘吉,一个用数据视角看AI世界的标注猿。
小伙伴们新年好,2025年真的会是一个巨大机遇的一年,大家做好成为乱世枭雄的准备了么?
有多少人在去年不理解国家数据局为什么要大力推广数据标注产业?并且2025年1月13日,国家发展改革委、国家数据局、财政部、人力资源和社会保障部对外发布的《关于促进数据标注产业高质量发展的实施意见》,接下来国家发展改革委、国家数据局、财政部、人力资源和社会保障部将强化数据标注产业顶层规划,协调解决产业发展过程中存在的重大问题。加强政策解读和案例征集等宣传推广,营造数据标注产业发展的良好氛围。
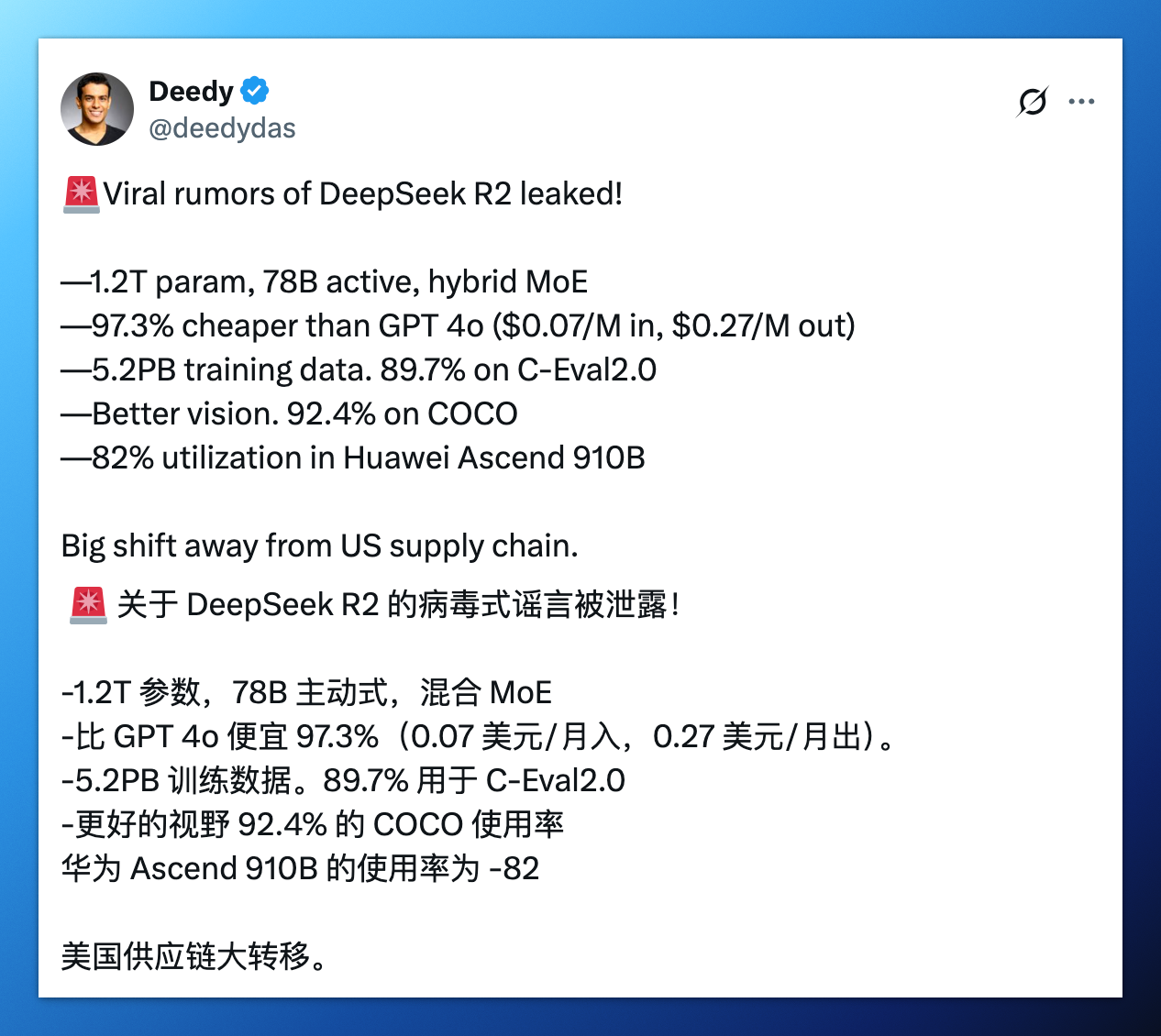
当DeepSeek以开源的方式轰动全世界的时候,数据标注产业发展的规划才正中眉心!

1月20日下午,中共中央政治局常委、国务院总理李强主持召开专家、企业家和教科文卫体等领域代表座谈会,梁文锋也在其中。
-
DeepSeek的开源让优势又回到了数据与场景
-
数据蒸馏+人类专家标注
-
基于DeepSeek基座的数据标注价值会统一么?
一.DeepSeek的开源让优势又回到了数据与场景
之前有一篇文章提到过,在开数据标注需求对接会的时候,有两个一问:
1.国家为什么在这个阶段主推数据标注基地建设,对于当时的从业者来说标注已经是红海了。
2.国家层面的需求对接会以大模型为主题,没有给自动驾驶篇幅。
再结合过年期间的DeepSeek的引起的轩辕大波,或许就能清楚了。我们国家的优势依然是在应用场景和工程化上面。
众所周知,AI发展的三驾马车“算力、算法、数据”,在算力方面我们超算中心建设规模全球领先,但是高端GPU严重依赖进口。国产AI芯片在特定场景下是可以实现替代,但是芯片的制造却受制于光刻机等核心设备。云服务商算力投入非常多,但是算力利用率却严重不足。
在算法层面基础理论研究薄弱,Transformer等突破性创新仍源自海外,国内大部分的AI项目基于海外开源框架二次开发。
而DeepSeek的开源标志着AI竞争进入新阶段,当算法壁垒被开源浪潮消解,算力差距受地缘政治制约,数据质量与场景深度的战略价值将指数级提升。
我们在数字化应用场景、垂类数据上都有明显优势,再加上数据标注的产能如果能够再集中。那么是不是熟悉的场景熟悉的配方又回来了。
不同的是,这次我们不再是孤军奋战,DeepSeek的开源拉上了全世界除了美国的所有国家下场参战。
GPT5也没有发布,在算法层面出现明显代差在短时间内来看,或许不太可能。所以同代内的产品对于应用层面来说,差点也就不重要了吧,毕竟成本在那摆着呢。况且还可以从场景数据上解决这部分的不足,勤能补拙啊。
二.数据蒸馏+人类专家标注
马斯克质疑DeepSeek使用高端显卡的数量,奥特曼声称有证据表明DeepSeek蒸馏了GPT的数据。已经开始玩小孩子那套了,谁还没抄过作业啊。
现在讨论是否蒸馏过数据这件事本身已经没有任何意义了,但是这个事对于标注行业的启示意义非凡啊。
下面就从两个角度来去聊聊这个事对于数据标注行业的影响:
数据蒸馏后再引入人类专家进行标注反馈,可以从三个方面进行处理优化:
a.标注校准:专家对蒸馏后的标注结果进行修正
b.反馈强化:将专家标注差异反向注入模型训练,这里面做的就是把标签规则进行反向注入。
c.领域知识固化:构建行业专属标注知识库
这个部分我也问了DeepSeek,在医疗领域DeepSeek-Health通过蒸馏公开病历数据生成初筛标注,专家二次核验使诊断准确率提升37%。
但同时也存在必然的瓶颈:
a.长尾问题:罕见场景标注覆盖率低(如方言语音识别错误率高达25%)
b.语义鸿沟:抽象概念标注失效(如法律文本中"善意第三人"的判定)
c.大模型生成标注存在事实性错误(如历史事件时间线混淆)
这样看来不同的标注方法存在是不同的优点其对应的成本差别也非常大,我们可以做一个成本对比:
| 标注类型 | 成本(美元/千条) | 适用场景 |
| 纯人工标注 | 50-200 | 高精度、高合规要求(如医疗) |
| 自动标注 | 0.5-5 | 标准化、高重复性(如商品分类) |
| 蒸馏+人工核验 | 10-30 | 专业性强、长尾分布(如工业质检) |
(注:成本数据参考Scale AI/Toloka 2023行业报告)
而对于自动标注部分,这里面有一个可行性公式:
自动标注渗透率 = 场景标准化程度 × 模型领域适应能力 ÷ 标注容错率阈值
例如:自动驾驶场景因容错率低(<0.01%),需保留80%人工核验;电商评论分类则可实现95%全自动标注。
通过将人类专家从重复劳动(如标框绘制)解放到高阶决策(如标注规则设计),实现"机器筛矿,人类炼金"的协同生态。而自动标注的终极目标并非追求100%替代率,而是找到成本-质量-风险平衡点。
-
数据蒸馏与人类协同的技术逻辑
首先我们先聊聊什么是数据蒸馏,数据蒸馏的定义是通过大模型(如DeepSeek-MoE)对海量低质量数据进行筛选、重构与增强,生成高信息密度的"知识精华"(如提炼出10%的优质数据覆盖90%核心知识)。
对于标注行业来说,做过大模型标注的人基本都做过。针对特定的题目给你两个结果让你进行选择最优结果、评分、排序、优化、改写,其中一个是自家模型生成的结果。另外一个呢,是未知模型生成的结果。这是否算是数据蒸馏,各位看官自行评判。
数据蒸馏有几个实现的方式,
-
合成数据:基于模型推理生成特定场景的标注样本
-
噪声过滤:通过置信度评分剔除低质量数据
-
知识蒸馏:将复杂模型的知识迁移到轻量级标注规则
-
-
自动标注的可行性边界
我一直认为自动标注是偷换概念的表述,但也的确找不到其他词语来表述数据标注领域你技术的牛B了。我们暂且还是用自动标注来表述吧。
如此看来自动标注就是对现有模型进行的数据蒸馏,在DeepSeek没有出现之前,哪家标注公司敢说自己找的开源模型要优于客户的模型?
“自动标注”从技术实现的角度我觉得可以分为三种思路:
-
预训练模型零样本标注
-
半监督学习,利用10%标注数据驱动90%未标注数据自动标注
-
自训练框架,如谷歌提出的"Snorkel"弱监督标注系统
-
三.基于DeepSeek基座的数据标注价值会统一么?
如果DeepSeek的开源可以发展成目前主流的AI基座,那么就一定会大大提速数据标注行业的发展,以及达成数据价值的共识。如果数据价值达成共识了就会反推数据标注的由成本导向定价向价值导向定价转变的可能性。
不管是数据还是数据标注发展过程中,达成共识是目前最难的问题。没有达成一致的参考标尺,就很难进行行业的认可。但是DeepSeek一旦被证实和认可,那么就可以成为共识的参考标尺。
所以从这个角度我们进行讨论基于DeepSeek基座能否衍生出标注价值体系,首先我们从技术角度来看,DeepSeek可以给数据标注提供哪几点支持:
-
模型能力标准化:DeepSeek基座通过统一预训练框架(如MoE架构)降低标注任务适配成本(如NLP领域标注效率提升60%)
-
知识迁移泛化性:跨领域标注能力增强(如DeepSeek-Legal到DeepSeek-Finance的标注规则迁移)
-
标注质量可量化:基于模型置信度评分构建标注质量评估体系(如DeepSeek-QA对标注准确率的动态监控)
以此为基础就可以对数据质量和场景价值作为定价的核心维度,例如可以数据质量的标注精度(如DeepSeek-R1评估的F1分数)、覆盖广度(如标注样本的多样性指数)、更新频率等进行评估(如标注数据的时效性评分)。场景维度的商业潜力、合规成本、替代难度进行评估。
这样以DeepSeek为基础的定价是否就可以有两种模式:
-
成本导向定价
-
标注复杂度(如DeepSeek-MoE评估的任务难度系数)
-
人力投入(如专家核验时长×时薪)
-
算力消耗(如GPU小时成本×标注时长)
-
-
价值导向定价
-
模型性能增益(如标注质量提升带来的模型准确率增幅)
-
商业回报预期(如标注数据对AI产品收入的贡献率)
-
风险折价因子(如标注错误可能导致的法律风险成本)
-
最终数据标注作为数据价值生成的一环,或许数据标注价值不会完全统一,但DeepSeek基座提供了价值评估的"标尺"——通过将标注质量、场景价值、合规成本等维度量化,构建动态定价模型(如DeepSeek-Pricing),推动数据标注从"成本中心"向"价值中心"转型还是非常有可能的。
以上就是针对DeepSeek爆火后对数据标注行业影响的思考,欢迎小伙伴们留言讨论。
相关文章阅读:
-----------------------完----------------
公众号:AI数据标注猿
知乎:AI数据标注猿
CSDN:AI数据标注猿
-----------------------完----------------

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)