deepseek 蒸馏模型本地部署
这样可以激发模型的创造力,生成更多意想不到的内容。敏感数据保护:某些行业的数据具有高度敏感性,如金融、医疗、政府等,将数据存储和处理在本地可以更好地控制数据访问和使用权限,降低数据泄露风险,确保敏感数据不被未授权访问和使用。系统集成:本地部署的系统可以更容易地与企业内部的其他系统进行集成,如ERP、CRM等,实现数据的共享和业务流程的自动化,提高企业的运营效率和竞争力。冗余备份:可以在本地建立数据
deepseek 本地部署
在不同的应用场景,本地部署deepseek模型具有很大的应用价值:
通常有以下几个主要原因:
敏感数据保护:某些行业的数据具有高度敏感性,如金融、医疗、政府等,将数据存储和处理在本地可以更好地控制数据访问和使用权限,降低数据泄露风险,确保敏感数据不被未授权访问和使用。
合规性要求:许多国家和地区都有严格的数据保护法规,如欧盟的GDPR等,要求企业在处理用户数据时必须遵守特定的隐私和安全标准。本地部署可以更容易地满足这些合规性要求,确保企业不会因违反法规而面临巨额罚款和法律风险。
低延迟需求:对于一些对实时性要求极高的应用,如自动驾驶、工业自动化控制等,本地部署可以大大减少数据传输延迟,提高系统响应速度,确保系统的实时性和可靠性。
带宽限制:在一些网络带宽有限或不稳定的环境下,将数据和应用部署在本地可以避免因网络拥堵或中断而导致的服务不可用或性能下降问题,确保应用的稳定运行。
系统集成:本地部署的系统可以更容易地与企业内部的其他系统进行集成,如ERP、CRM等,实现数据的共享和业务流程的自动化,提高企业的运营效率和竞争力。
独立性:本地部署的系统可以在一定程度上独立于外部网络和云服务提供商运行,减少了对第三方服务的依赖,提高了系统的自主性和灵活性。
冗余备份:可以在本地建立数据和应用的冗余备份,当主系统出现故障或数据丢失时,可以快速切换到备份系统,确保业务的连续性和数据的完整性。
模型选择
根据自身硬件配置来决定适用的模型。
1.低显存配置
显卡要求:集成显卡或者独立显卡的显存不足 2GB。
模型选择:DeepSeek-R1-Distill-Llama-1.5B 模型。该模型对硬件资源的需求极低,能够在显存较小的设备上稳定运行,可轻松应对日常对话、简单文本生成等基础文本处理任务。
2.中等显存配置
显卡要求:显卡显存为 4 - 6GB。
模型选择:DeepSeek-R1-Distill-Llama-7B 或 DeepSeek-R1-Distill-Qwen-7B 模型。这类模型在中等配置的电脑上能够充分发挥潜力,运行效率较高,能够轻松处理简单代码生成、文章润色等具有一定复杂度的任务。
3.高显存配置
显卡要求:显存高达 8GB 及以上,如 NVIDIA GeForce RTX 30 系列、AMD Radeon RX 6000 系列等高性能独立显卡。
模型选择:DeepSeek-R1-Distill-Llama-32B 甚至更高版本的模型。它们能够承担复杂的自然语言处理任务,如专业领域的文本深度分析、复杂代码的编写与调试等。
4.量化模型
显卡要求:8GB 显存。
模型选择:4bit 量化模型。7B/8B 模型需要 8GB 显存,14B 模型需要 16GB 显存,32B 模型需要 22GB 显存,70B 模型需要 48GB 显存
模型下载
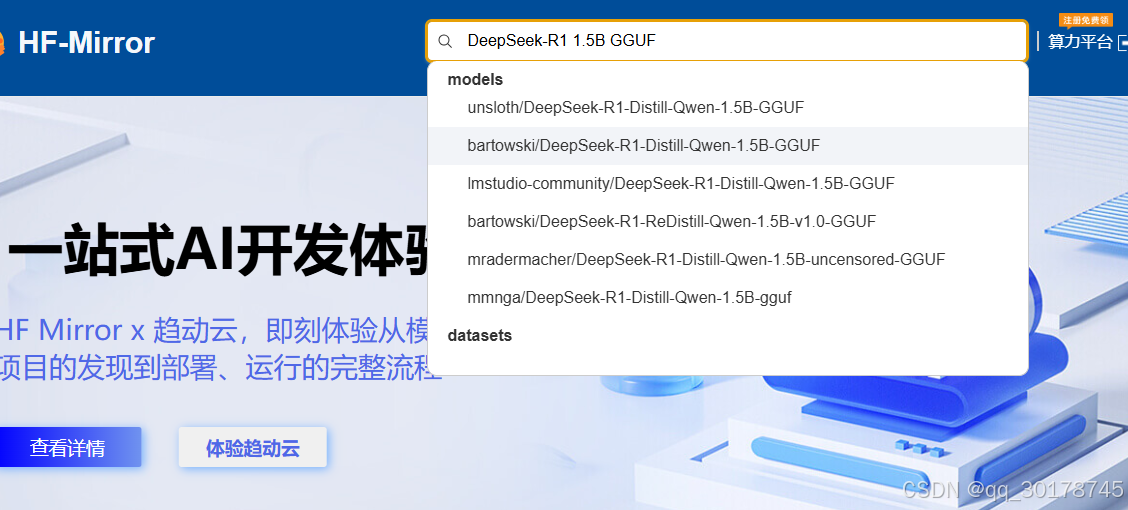
模型下载国内推荐网址为
国内大模型镜像网站
输入后缀需要加gguf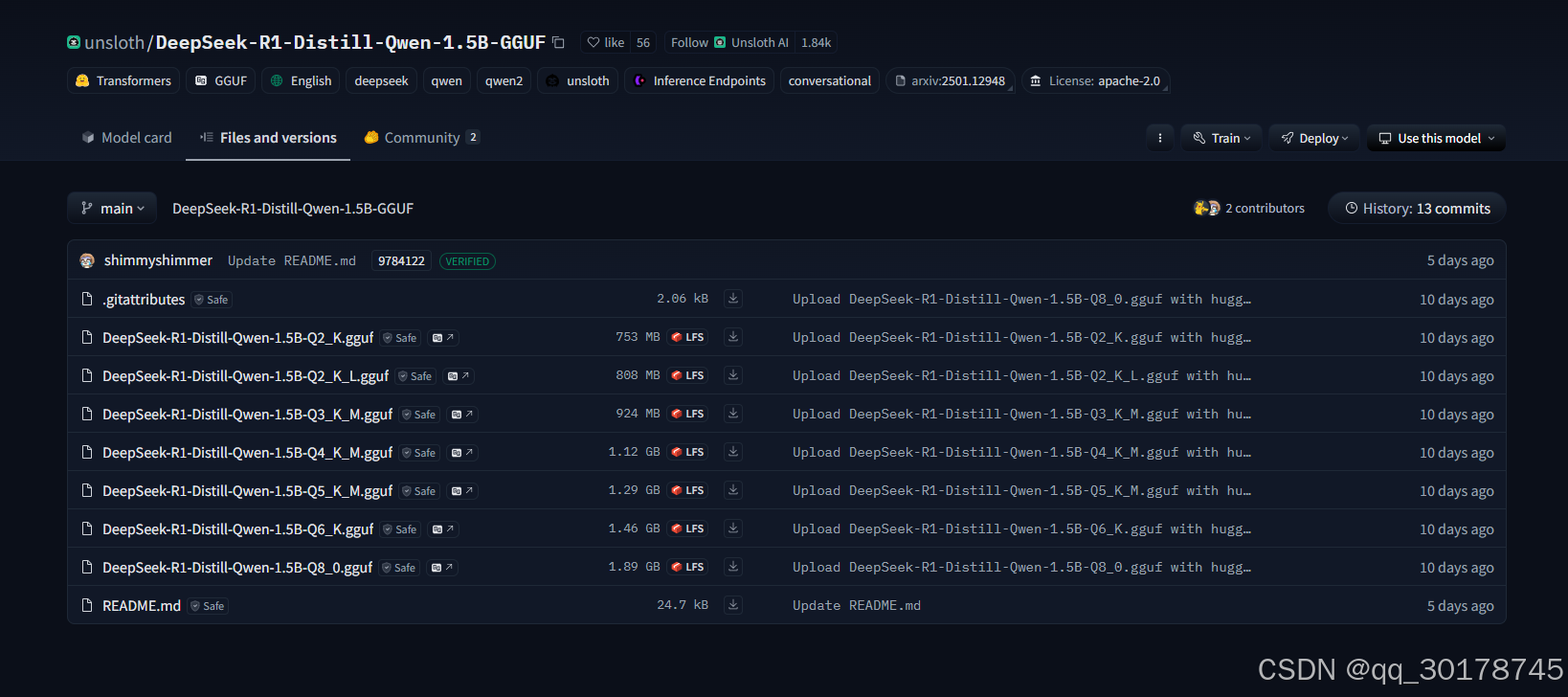
选择相应的gguf即可点击下载
如果下载的很慢推荐一个方法:
也可使用如下网址下载
modelscope
下载得到相应gguf文件
模型部署
-
下载lmstudio
lmstudio网址 -
安装好lmstudio
-
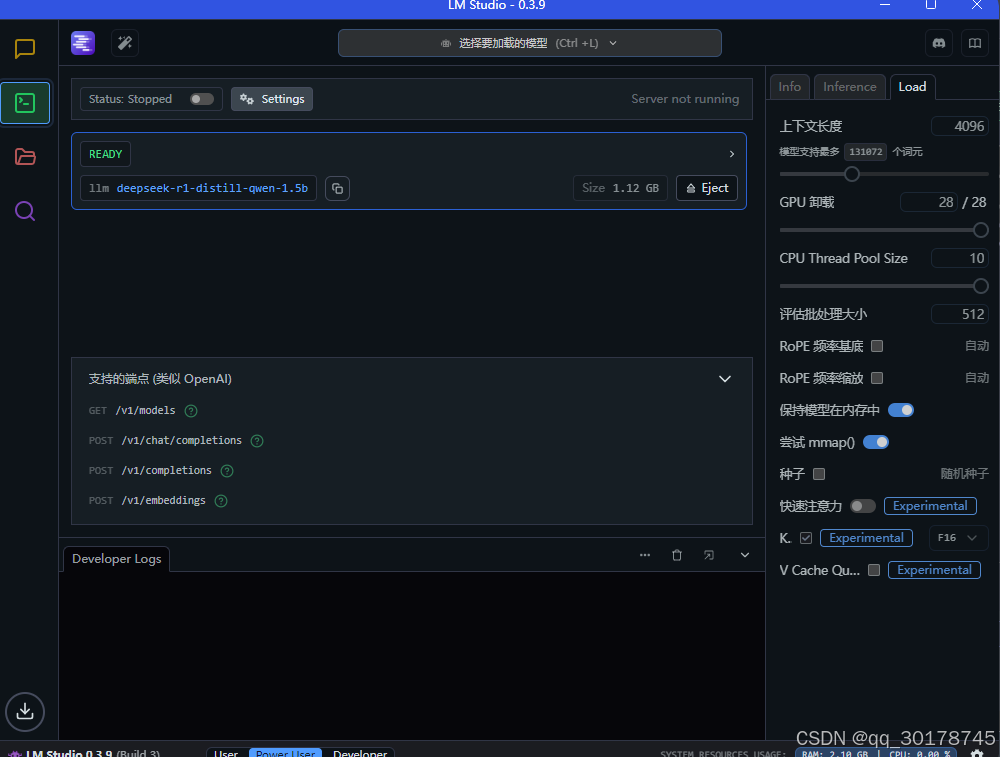
将下载的gguf文件放置在相应位置
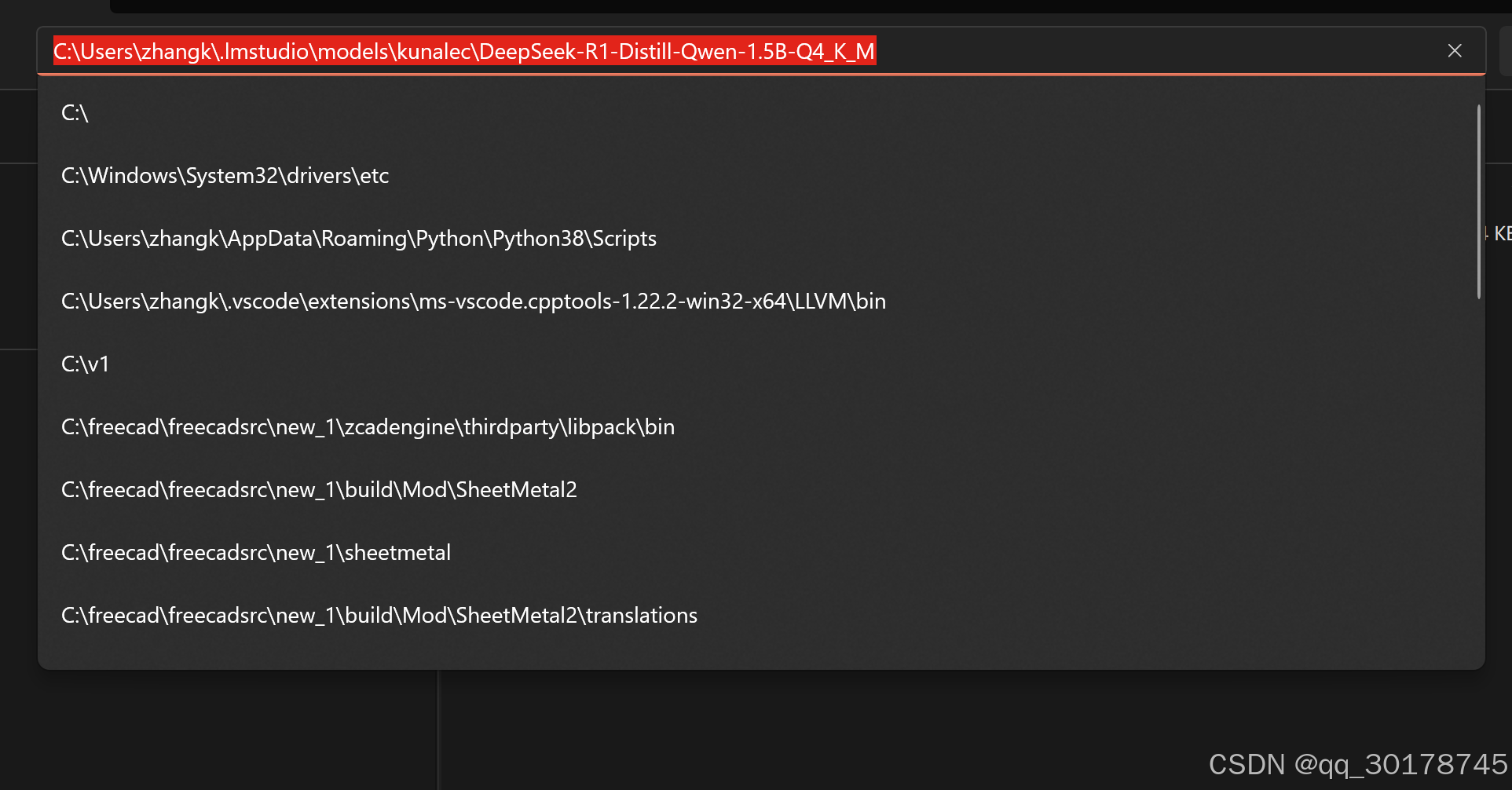
这部非常重要,需要在models自建一个文件夹,进入后再次创建,最后拷贝下载的gguf文件到该文件夹。 -
重启lmstudio 加载模型
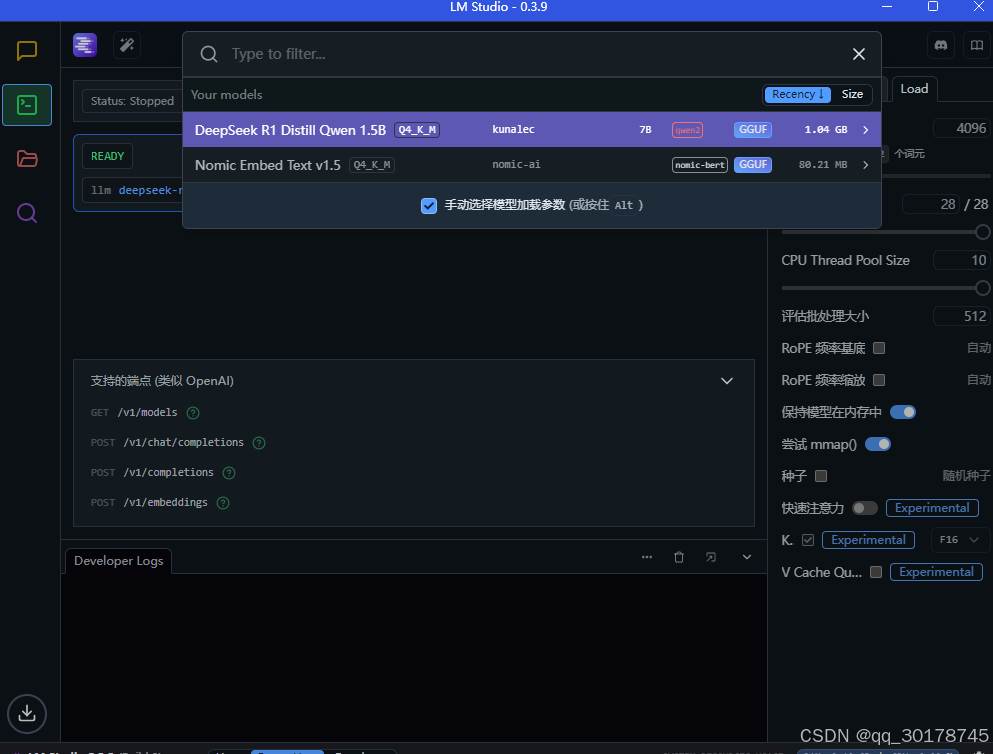
-
加载模型后进行测试
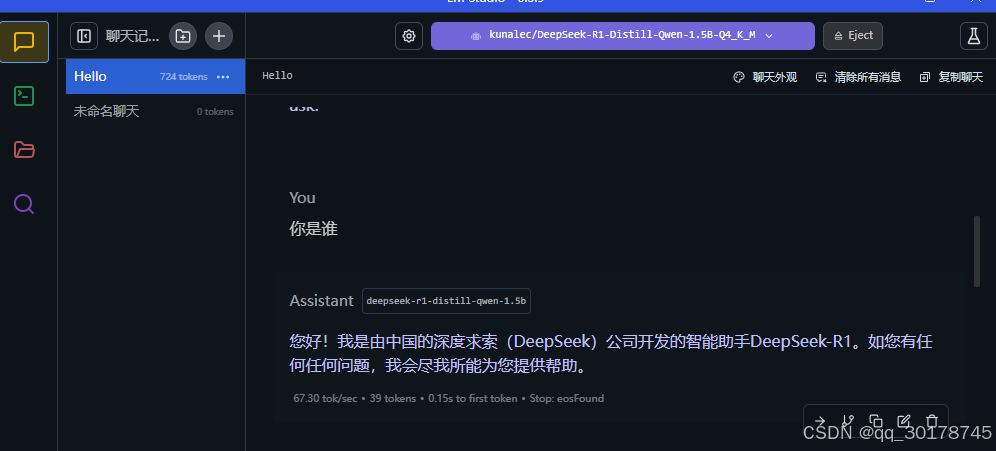
说明已成功加载模型
模型调试
1.尽量使用GPU来加载模型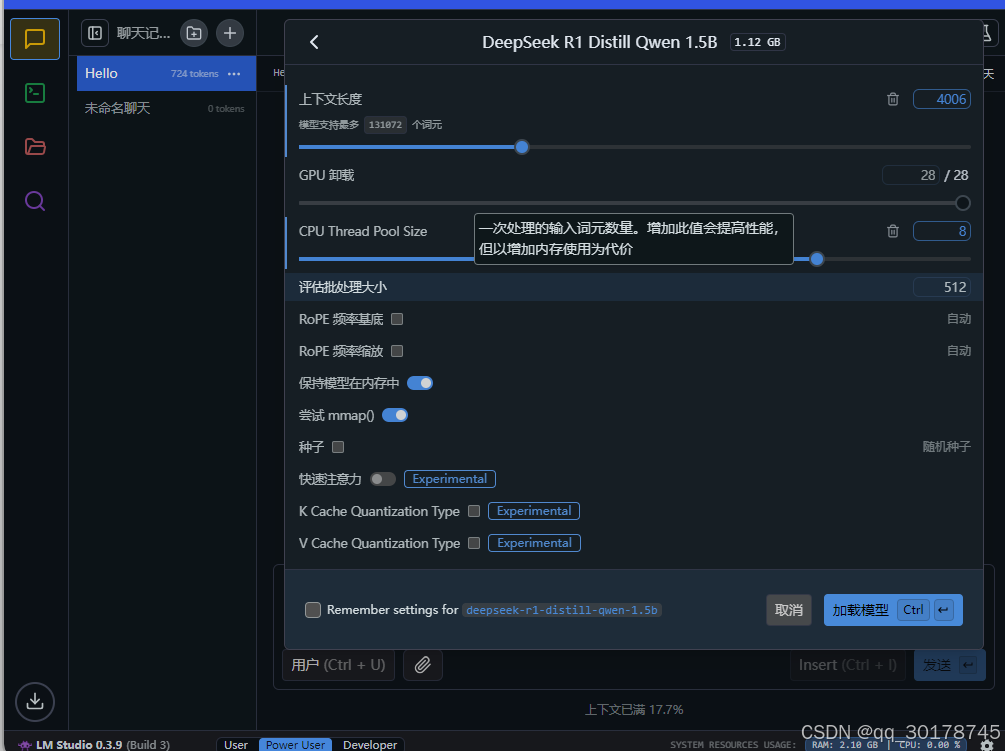
2.进行预设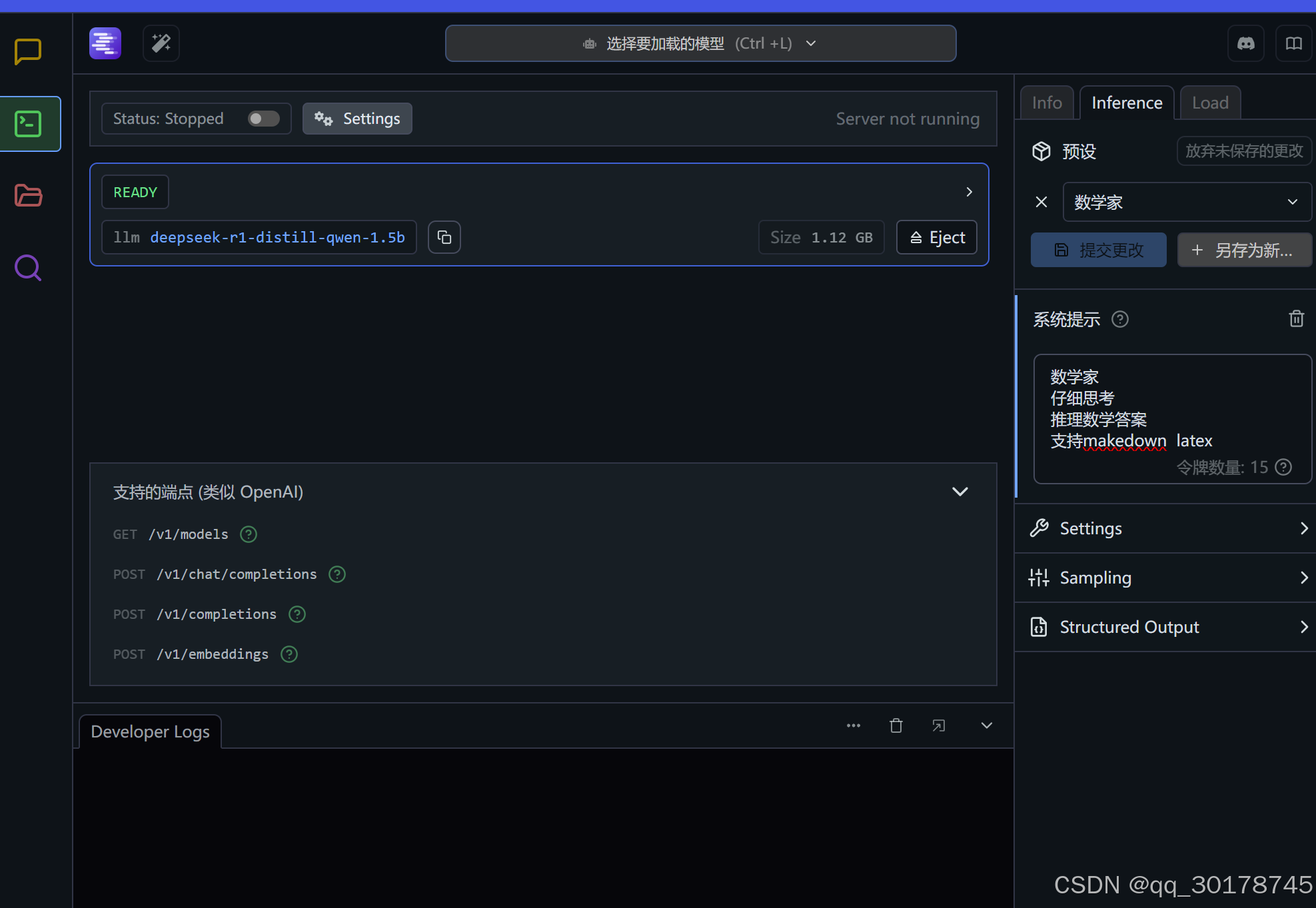
3.设置温度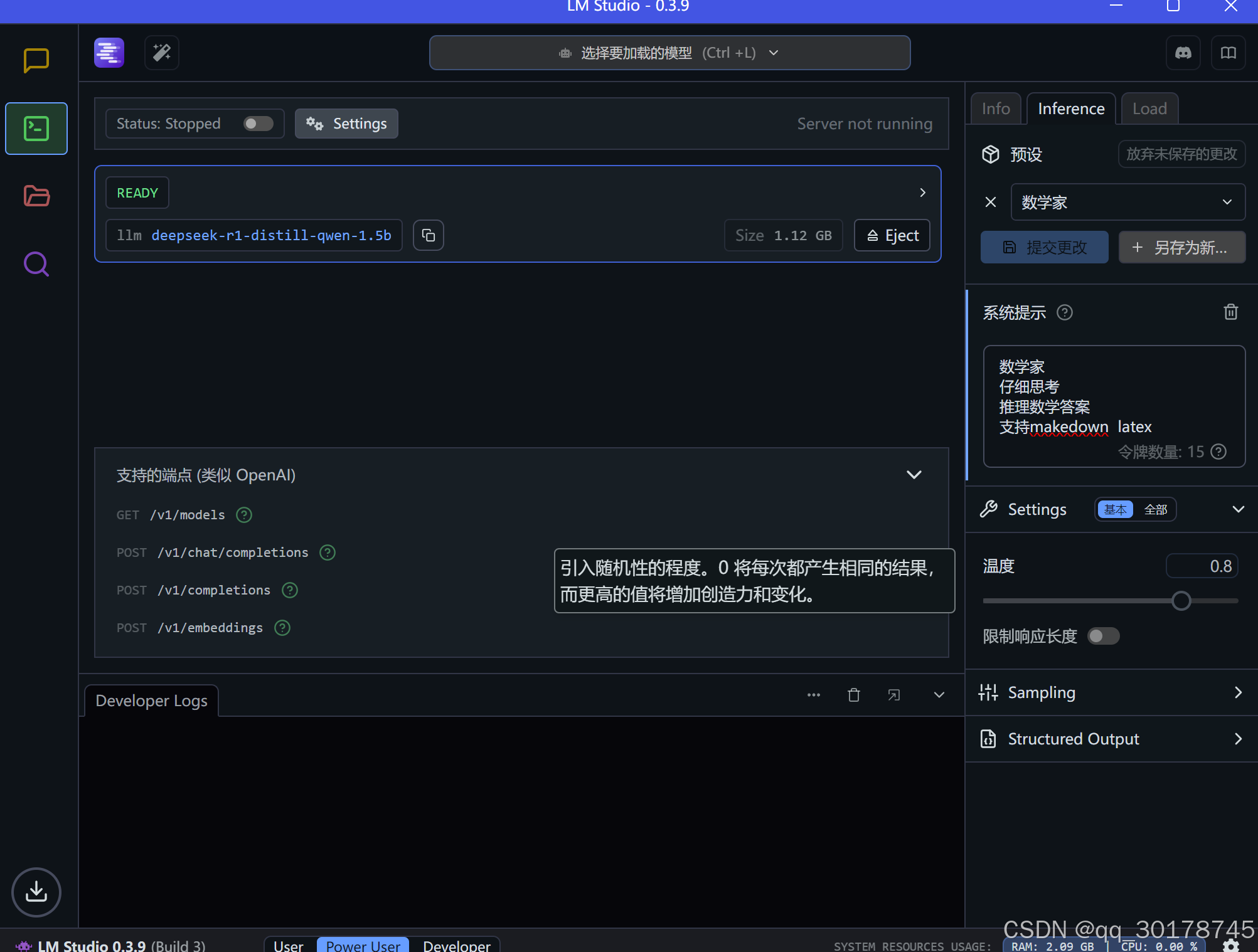
温度设置的作用
温度越高:模型生成的文本越随机、越有创意。适合需要多样化和创新性内容的场景,如创意写作、头脑风暴等。
温度越低:模型生成的文本越可预测、越稳定。适合需要准确性和一致性的场景,如正式写作、技术文档等。
温度设置与需求的关系
创意写作:如果用户需要生成富有创意和多样性的文本,如故事创作、诗歌生成等,可以将温度设置得较高,例如 0.7 到 1.0 之间。这样可以激发模型的创造力,生成更多意想不到的内容。
正式写作:如果用户需要生成准确、一致的文本,如学术论文、技术报告等,可以将温度设置得较低,例如 0.2 到 0.5 之间。这样可以确保生成的文本更加符合预期,减少错误和不一致。
多轮对话:在进行多轮对话时,温度设置可以适中,例如 0.5 到 0.7 之间,以平衡创意和一致性。这样可以在保持对话流畅的同时,生成具有一定创意的回复。
头脑风暴:如果用户需要快速生成大量想法和概念,可以将温度设置得较高,例如 0.8 到 1.0 之间。这样可以激发模型的创造力,生成更多新颖的想法。
lmstudio断网处理

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 42
42 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)