[EAI-024] DeepSeek-R1 技术报告解读
DeepSeek-R1-Zero 模型通过 RL 进行训练,无需监督微调 (SFT) 作为预备步骤,展现出非凡的推理能力。通过RL,DeepSeek-R1-Zero 自展现出许多强大而有趣的推理行为。然而,它也面临一些挑战,例如可读性差和语言混杂。 为了解决这些问题并进一步提高推理性能,引入了 DeepSeek-R1,它在RL之前结合了多阶段训练和冷启动数据。DeepSeek-R1 在推理任务上的
Paper Card
论文标题:DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
论文作者:DeepSeek-AI
论文链接:https://arxiv.org/abs/2501.12948v1
论文出处:/
论文被引:/
项目主页:https://github.com/deepseek-ai/DeepSeek-R1,https://github.com/huggingface/open-r1
Abstract
介绍了第一代推理模型:DeepSeek-R1-Zero 和 DeepSeek-R1。 DeepSeek-R1-Zero 模型通过大规模强化学习 (RL) 进行训练,无需监督微调 (SFT) 作为预备步骤,展现出非凡的推理能力。通过RL,DeepSeek-R1-Zero 自展现出许多强大而有趣的推理行为。然而,它也面临一些挑战,例如可读性差和语言混杂。 为了解决这些问题并进一步提高推理性能,引入了 DeepSeek-R1,它在RL之前结合了多阶段训练和冷启动数据。DeepSeek-R1 在推理任务上的性能可与 OpenAI-o1-1217 相媲美。为了支持研究社区,开源了 DeepSeek-R1-Zero、DeepSeek-R1 和六个基于 Qwen 和 Llama 从 DeepSeek-R1 蒸馏出的稠密模型 (1.5B、7B、8B、14B、32B、70B)。
Summary
reasoning 模型对具身智能的影响?
- long-horizon task planning
- system2 慢思考模型,用于验证任务执行结果
- 最为 VLA 模型的骨干
DeepSeek-R1 Training Pipeline

Open-R1 Pipeline

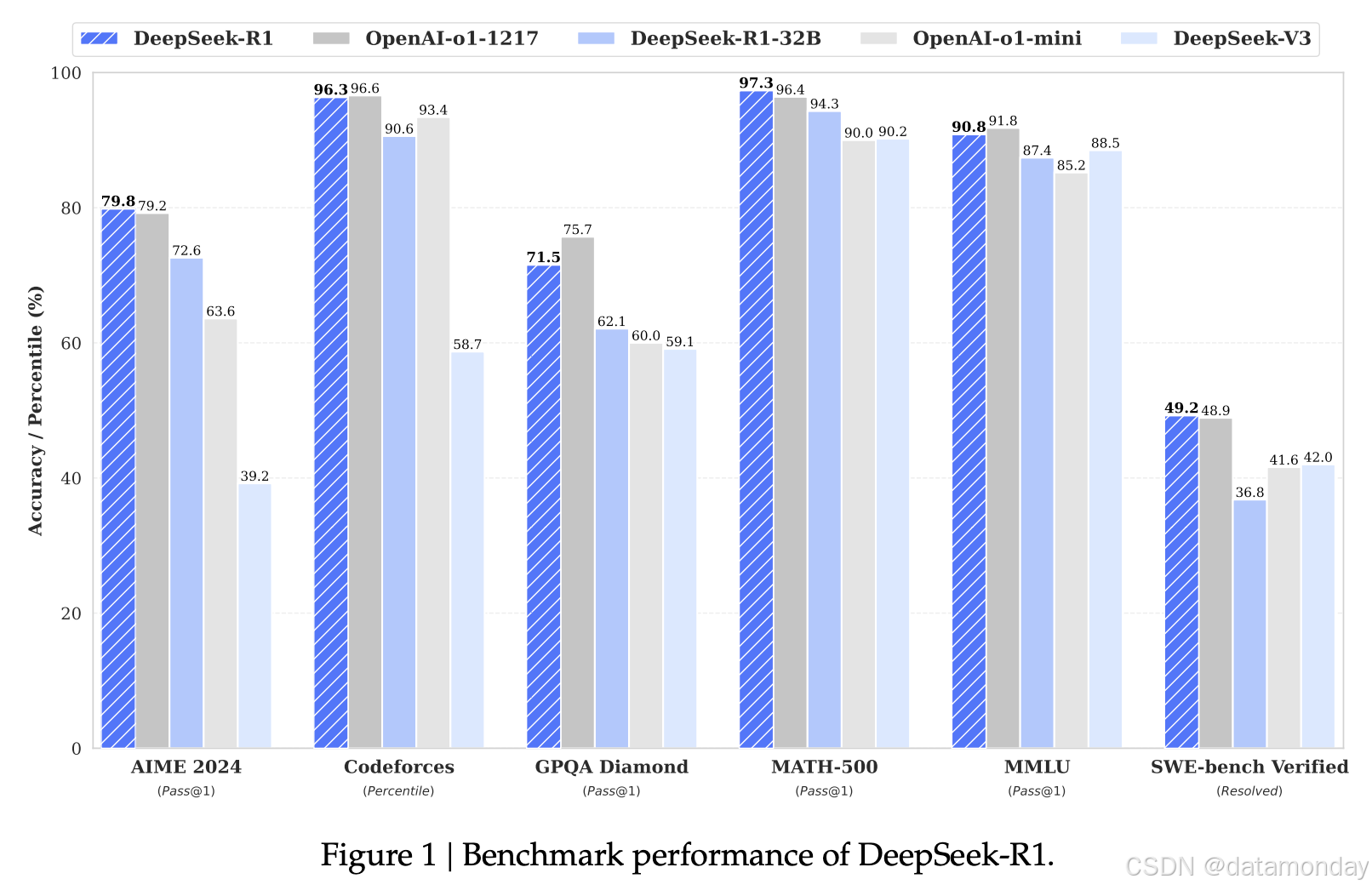
DeepSeek-R1 评测结果
研究背景
为了提高LLMs的推理能力,OpenAI o1 通过增加思维链推理过程的长度引入了推理时间scaling,在数学、变成和科学问题中取得了显著的提升。最近的一些工作探索了包括基于过程的奖励模型、RL、蒙特卡洛树搜索和波束搜索等搜索算法,但都没有达到 o1 模型的性能。
方法介绍
使用纯RL提高LLMs的推理能力,探索在没有任何监督数据的情况下提高LLMs推理能力,重点关注其通过纯 RL 过程的自我进化。具体地说,使用 DeepSeek-V3-Base 作为基础模型,采用 GRPO 作为 RL 框架提高模型推理能力,构建了DeepSeek-R1-Zero。通过数千步的RL后,该模型在 AIME2024 上的 pass@1 score 从 15.6%提升到71%。
为了解决DeepSeek-R1-Zero存在的可读性差和语言混杂的问题,构建了 DeepSeek-R1,结合了少量冷启动数据和多阶段训练流程。具体地说,首先收集数千条冷启动数据微调 DeepSeek-V3-Base 模型,然后执行类似 DeepSeek-R1-Zero 的定向推理 RL。在 RL 接近收敛时,通过对 RL 检查点进行拒绝采样,并结合来自 DeepSeek-V3 在写作、事实性回答和自我认知等领域的监督数据,创建新的 SFT 数据,然后重新训练 DeepSeek-V3-Base 模型。使用新数据微调之后,检查点将进行额外的RL过程,同时考虑来自所有场景的提示。完成这些步骤之后,得到了 DeepSeek-R1 检查点,其性能与 o1-1217 不相上下。
使用Qwen和Llama作为基础模型,直接从DeepSeek-R1进行知识蒸馏优于对其应用RL。这表明,由更大的基础模型发现的推理模式对于提高推理能力至关重要。
主要贡献:
- 后训练阶段的革新:跳过SFT,直接对基础模型进行大规模强化学习来提升基础模型的推理能力
- 蒸馏:使用更小的模型作为基础模型,直接从 DeepSeek-R1 进行蒸馏,效果具备可比性
评估结果:
- 推理任务:AIME 2024、MATH-500、Codeforces 基准测试
- 知识:MMLU、MMLU-Pro、SimpleQA 和 GPQA Diamond 基准测试
- 其他(创意写作、问答、编辑和摘要等):AlpacaEval2.0、ArenaHard 基准测试
模型架构
1-DeepSeek-R1-Zero:基于基础模型的强化学习
直接将 RL 应用于基础模型,不需要 SFT 数据
GRPO
为了节省RL的训练成本,采用分组相对策略优化(Group Relative Policy Optimization,GRPO),它放弃了通常与策略模型大小相同的评判模型,而是从分组分数中估计基线。具体来说,对于每个问题 qqq,GRPO从旧策略 πθoldπ_{θ_{old}}πθold 中采样一组输出 {o1,o2,⋯,oG}\{o_1,o_2,⋯,o_G\}{o1,o2,⋯,oG},然后通过最大化以下目标来优化策略模型 πθπ_θπθ: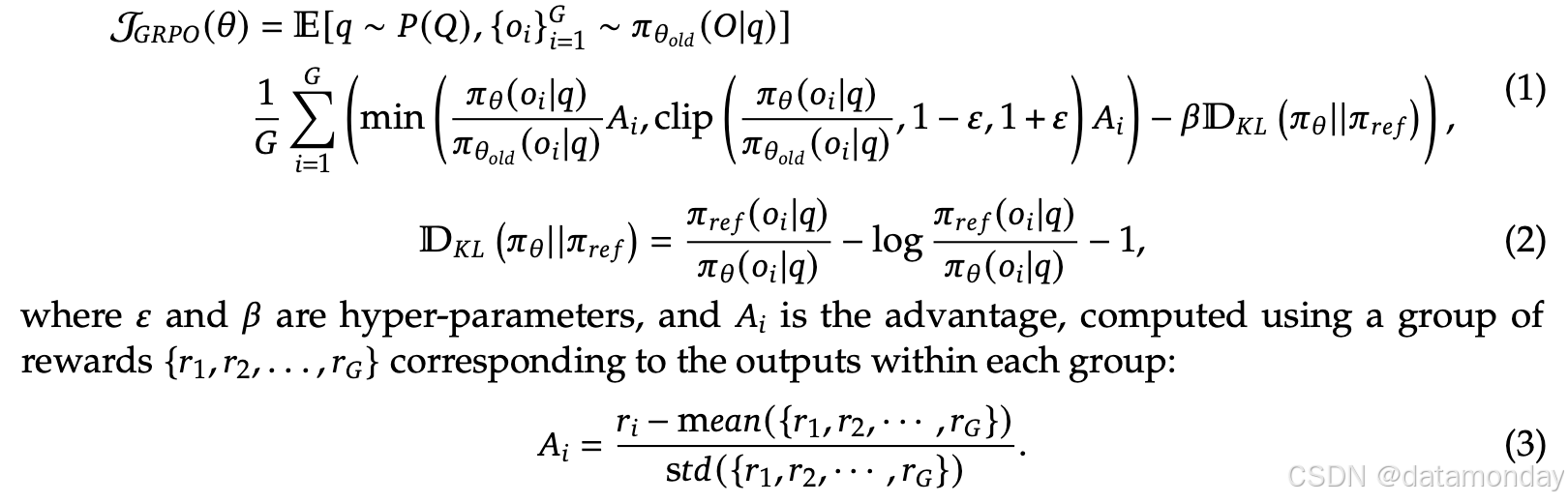
奖励建模
奖励是训练信号的来源,它决定了RL的优化方向。为了训练 DeepSeek-R1-Zero,采用了一个基于规则的奖励系统,该系统主要包含两种类型的奖励:
- 准确性奖励:评估响应是否正确。对于具有确定性结果的数学题,要求模型以指定的格式提供最终答案,从而能够可靠地基于规则验证其正确性。对于LeetCode问题,可以使用编译器根据预定义的测试用例生成反馈。
- 格式奖励:该模型强制模型将思考过程放在 标签之间。
代码实现:
"""
https://github.com/huggingface/open-r1/blob/main/src/open_r1/grpo.py
"""
def accuracy_reward(completions, solution, **kwargs):
"""Reward function that checks if the completion is the same as the ground truth."""
contents = [completion[0]["content"] for completion in completions]
rewards = []
for content, sol in zip(contents, solution):
gold_parsed = parse(sol, extraction_mode="first_match", extraction_config=[LatexExtractionConfig()])
if len(gold_parsed) != 0:
# We require the answer to be provided in correct latex (no malformed operators)
answer_parsed = parse(
content,
extraction_config=[
LatexExtractionConfig(
normalization_config=NormalizationConfig(
nits=False,
malformed_operators=False,
basic_latex=True,
equations=True,
boxed=True,
units=True,
),
# Ensures that boxed is tried first
boxed_match_priority=0,
try_extract_without_anchor=False,
)
],
extraction_mode="first_match",
)
# Reward 1 if the content is the same as the ground truth, 0 otherwise
reward = float(verify(answer_parsed, gold_parsed))
else:
# If the gold solution is not parseable, we reward 1 to skip this example
reward = 1.0
print("Failed to parse gold solution: ", sol)
rewards.append(reward)
return rewards
def format_reward(completions, **kwargs):
"""Reward function that checks if the completion has a specific format."""
pattern = r"^<think>.*?</think><answer>.*?</answer>$"
completion_contents = [completion[0]["content"] for completion in completions]
matches = [re.match(pattern, content) for content in completion_contents]
return [1.0 if match else 0.0 for match in matches]
训练模板
首先设计了一个简单的模板,指导基础模型遵从指定的指令。此模板要求DeepSeek-R1-Zero首先生成推理过程,然后给出最终答案。故意将约束限制在这个结构化格式上,避免任何内容相关的偏差——例如要求反思推理或提示特定的问题解决策略——以确保能够准确地观察模型在强化学习过程中的进展。
DeepSeek-R1-Zero的性能、自我进化过程和顿悟时刻
先解释一下指标:
- pass@1:k次回答的平均准确率
- cons@64:64次回答的一致性,多数投票
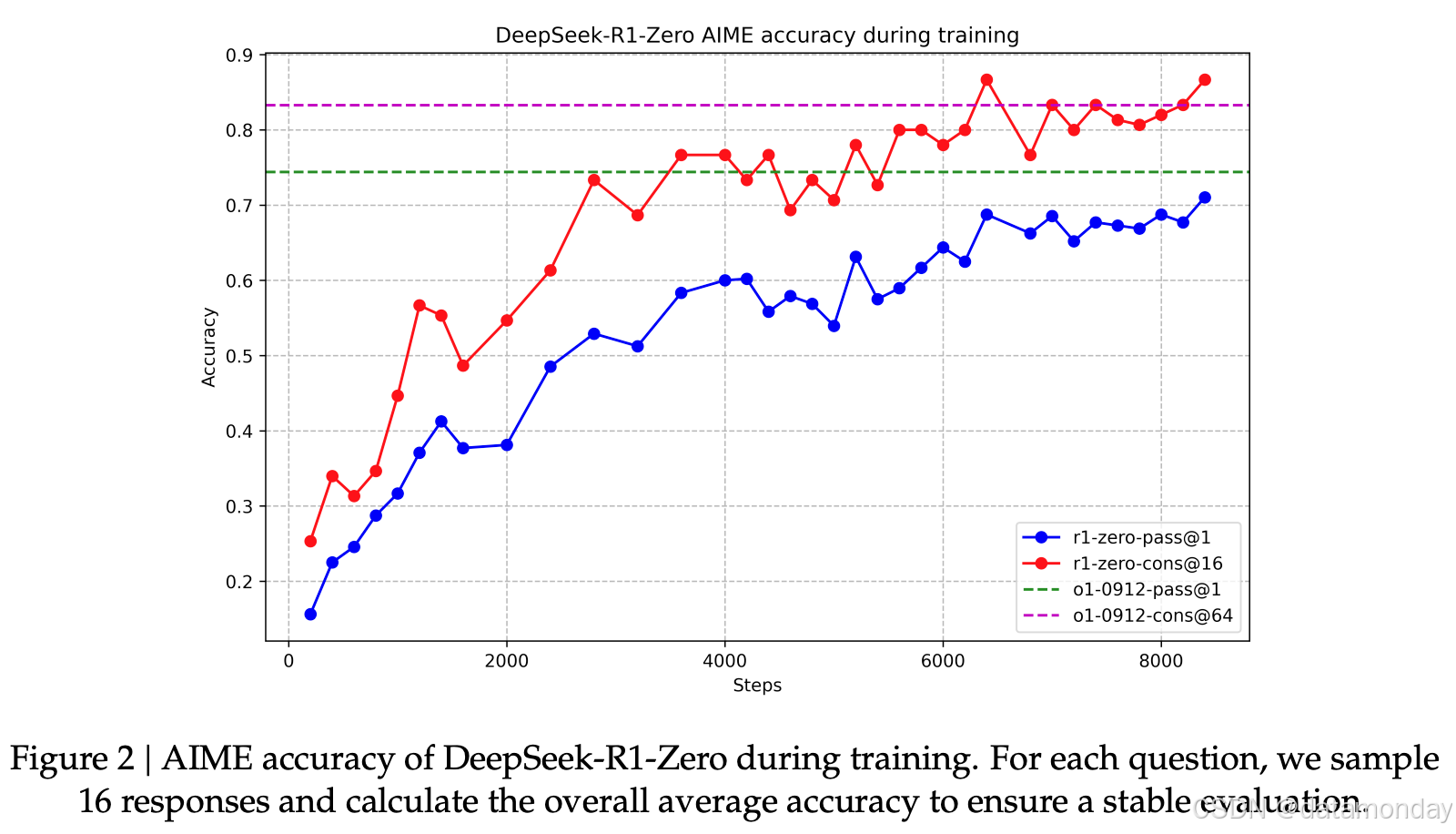
如图 2 所示,随着强化学习训练的推进,DeepSeek-R1-Zero 的性能展现出稳定且持续的提升。AIME 2024 上的平均 pass@1 分数显著提高,从最初的 15.6% 跃升至 71.0%,达到了与 OpenAI-o1-0912 相当的水平。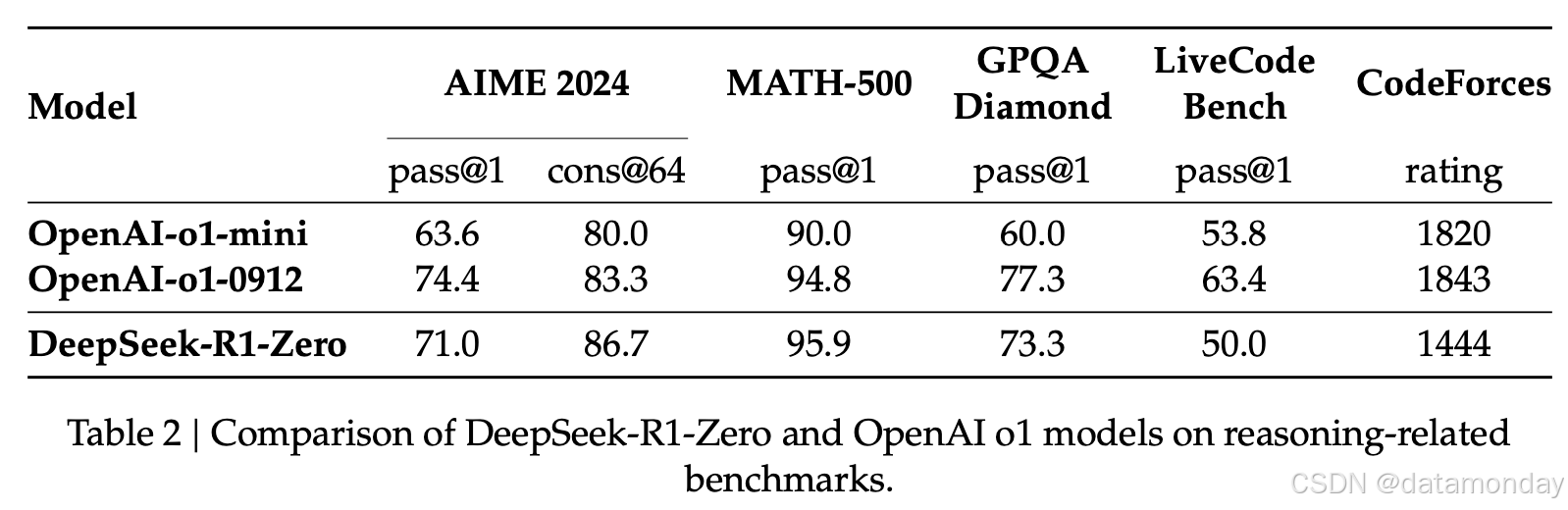
表 2 结果表明,RL 使 DeepSeek-R1-Zero 能够获得强大的推理能力,而无需任何监督微调数据。
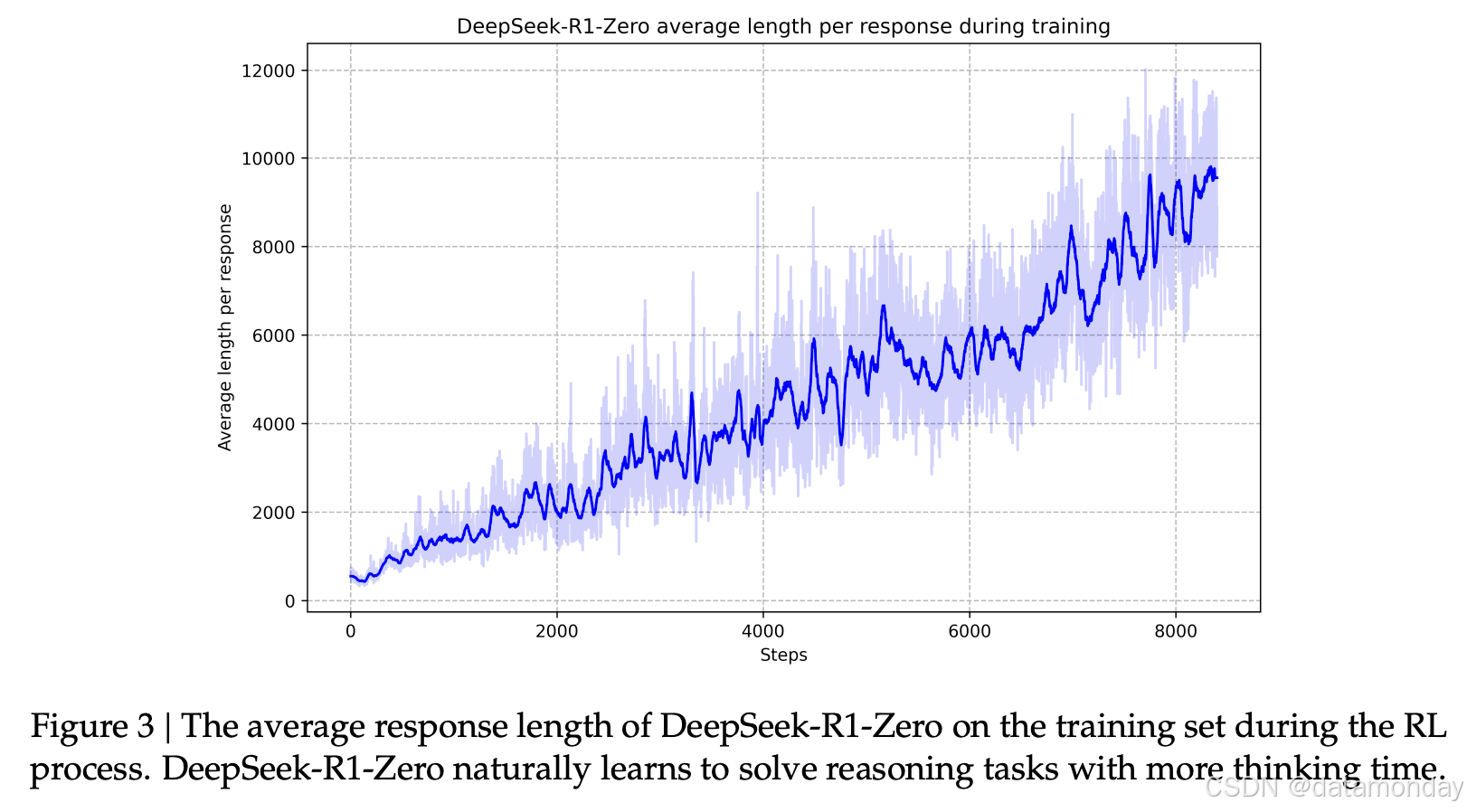
如图 3 所示,DeepSeek-R1-Zero的思考时间在整个训练过程中持续改进。这种改进是模型内部发展的体现。通过利用更长的测试时间计算,自然地获得了解决越来越复杂的推理任务的能力。诸如反思以及探索解决问题的替代方法等行为会自发出现。这些行为并非显式编程,而是模型与强化学习环境交互的结果。这种自发发展显著增强了DeepSeek-R1-Zero的推理能力,使其能够更高效、更准确地处理更具挑战性的任务。
在DeepSeek-R1-Zero的训练过程中观察到一个特别有趣的现象,即“顿悟”时刻的出现。 如表3所示,这一时刻出现在模型的中间版本中。它强调了强化学习的强大:不是显式地教模型如何解决问题,而是简单地为其提供正确的激励,它会自主开发先进的问题解决策略。 顿悟时刻”有力地提醒了强化学习在释放AI系统新智能水平方面的潜力,为未来更自主和自适应的模型奠定了基础。
2-DeepSeek-R1:数千个长CoT数据微调基础上应用强化学习
为了解决 DeepSeek-R1-Zero 可读性差和语言混合的问题,构建了 DeepSeek-R1。
结局两个问题:1)通过加入少量高质量数据作为冷启动,能否进一步提高推理性能或加快收敛速度? 2) 如何训练一个用户友好的模型,使其不仅能够生成清晰连贯的思维链 (CoT),而且展现强大的通用能力? 为了解决这些问题,设计了一个训练 DeepSeek-R1 的流程。 该流程包含四个阶段,概述如下。
Stage1:冷启动
为了避免RL训练从基础模型开始的早期不稳定冷启动阶段,构建并收集少量长的 CoT 数据来微调 DeepSeek-V3-Base 作为 RL 的起点。探索了几种方法:使用少样本提示,其中包含一个长 CoT 作为示例;直接提示模型生成包含反思和验证的详细答案;以可读格式收集 DeepSeek-R1-Zero 的输出;通过人工标注后处理来细化结果。
Stage2:面向推理的RL
在冷启动数据上微调 DeepSeek-V3-Base 后,应用与 DeepSeek-R1-Zero 中相同的 RL 训练。本阶段侧重于增强模型的推理能力,尤其是在编码、数学、科学和逻辑推理等推理密集型任务中,这些任务涉及具有明确解决方案的明确定义的问题。
当 RL 提示涉及多种语言时,CoT 经常表现出语言混合现象。为了减轻语言混合问题,在 RL 训练过程中引入了一种语言一致性奖励,该奖励计算为思维链中目标语言单词的比例。
Stage3:拒绝采样和监督微调
当 stage2 收敛之后,利用检查点作为后续轮次收集 SFT 数据。区别于冷启动阶段的数据,这个阶段结合了其他领域的数据,以增强模型在写作、角色扮演和其他通用任务中的能力。按照如下描述生成数据并微调模型。
推理数据:整理推理提示,并通过对上述 RL 检查点进行拒绝采样来生成推理轨迹。在上一阶段,只包含可以使用基于规则的奖励进行评估的数据。但在此阶段,通过合并其他数据来扩展数据集,其中一些数据使用生成式奖励模型,将真实值和模型预测输入 DeepSeek-V3 进行判断。 此外,由于模型输出有时混乱且难以阅读,过滤掉了包含混合语言、长段落和代码块的思维链。 对于每个提示,对多个响应进行采样,并仅保留正确的响应。总共收集了大约 60 万个与推理相关的训练样本。
非推理数据:例如写作、事实性问答、自我认知和翻译,采用 DeepSeek-V3 管道并复用 DeepSeek-V3 的 SFT 数据集的部分内容。对于某些非推理任务,调用 DeepSeek-V3 在通过提示回答问题之前生成潜在的思维链。但对于更简单的查询,例如“你好”,不会提供思维链作为回应。总共收集了大约 20 万个与推理无关的训练样本。
使用上述约 80 万个样本的精选数据集,对 DeepSeek-V3-Base 进行两个 epoch 的微调。
Stage4:辅助强化学习
为了进一步使模型与人类偏好保持一致,实施了一个辅助强化学习阶段,旨在提高模型的有用性和无害性,同时改进其推理能力。具体来说,使用奖励信号和多样化的提示分布组合来训练模型。对于推理数据,遵循 DeepSeek-R1-Zero 中概述的方法,该方法利用基于规则的奖励来指导数学、代码和逻辑推理领域的学习过程。对于一般数据,采用奖励模型来捕捉复杂和细微场景中的人类偏好。基于 DeepSeek-V3 管道并采用类似的偏好对和训练提示分布。对于有用性,只关注最终摘要,确保评估强调响应对用户的实用性和相关性,同时最大限度地减少对底层推理过程的干扰。对于无害性,评估模型的整个响应,包括推理过程和摘要,以识别和减轻生成过程中可能出现的任何潜在风险、偏差或有害内容。最终,奖励信号和多样化数据分布的整合能够训练一个在推理方面表现出色,同时优先考虑有用性和无害性的模型。
3-将R1推理能力蒸馏到小的稠密模型中
为了使更有效率的小型模型具备像 DeepSeek-R1 这样的推理能力,使用DeepSeek-R1整理的800k个样本对 6 个不同参数量的开源模型进行了直接微调。研究结果表明,这种直接的蒸馏方法显著增强了小型模型的推理能力。基础模型包括Qwen2.5-Math-1.5B、Qwen2.5-Math-7B、Qwen2.5-14B、Qwen2.5-32B、Llama-3.1-8B和Llama-3.3-70B-Instruct。
对于蒸馏后的模型,只应用监督微调(SFT),不包括强化学习(RL)阶段,仅仅是为了验证蒸馏的有效性。
消融实验
评估指标:pass@1、cons@64
最大生成长度:32768 tokens
R1 评估
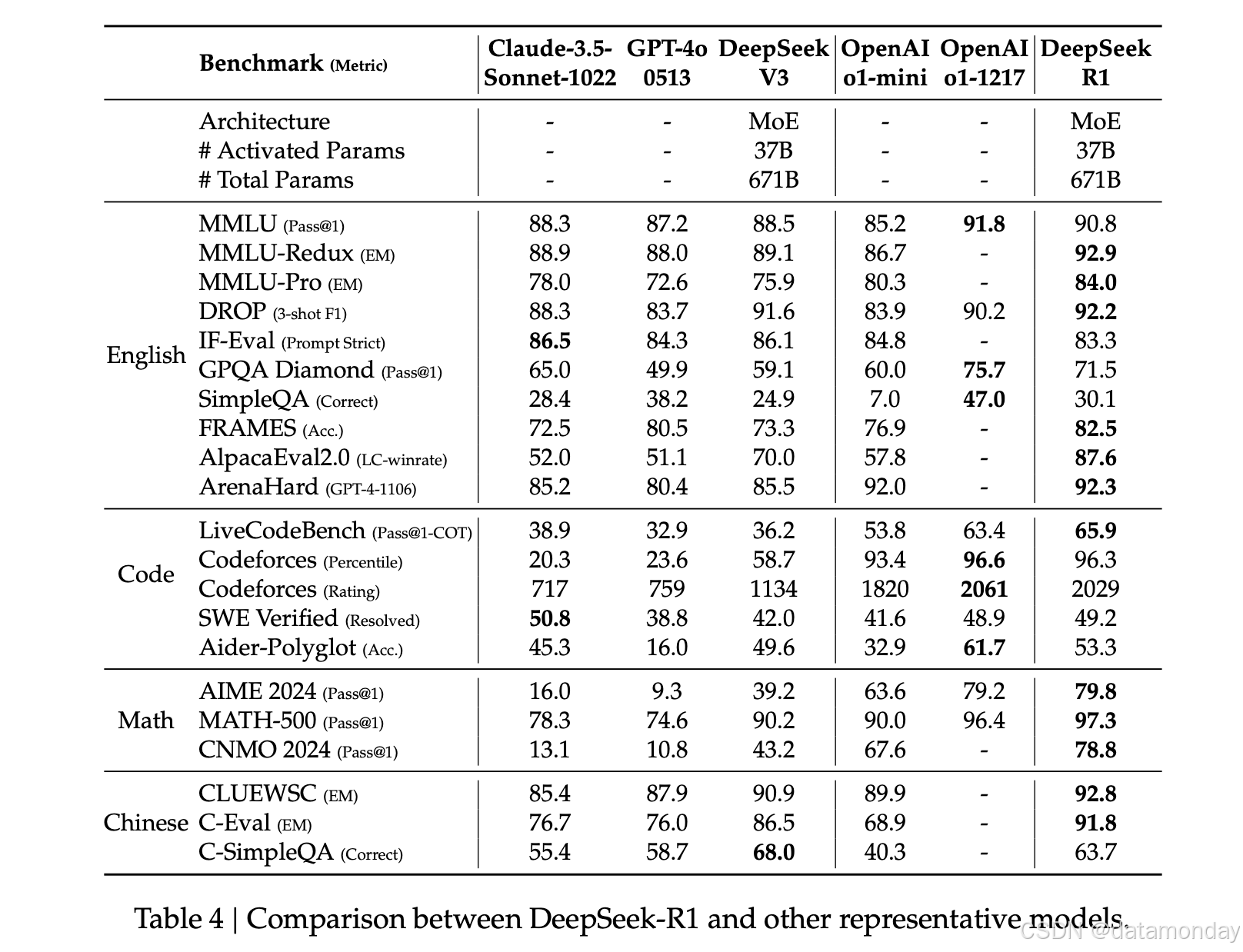
对于面向教育的知识基准测试,例如 MMLU、MMLU-Pro 和 GPQA Diamond,DeepSeek-R1 表现出优于 DeepSeek-V3 的性能。 此改进主要归因于 STEM 相关问题准确性的提高,其中通过大规模强化学习取得了显著进展。 此外,DeepSeek-R1 在 FRAMES 上表现出色,FRAMES 是一项依赖长上下文的问答任务,展示了其强大的文档分析能力。 这突出了推理模型在人工智能驱动的搜索和数据分析任务中的潜力。 在事实基准 SimpleQA 上,DeepSeek-R1 的性能优于 DeepSeek-V3,证明其处理基于事实查询的能力。 在此基准测试中,OpenAI-o1 优于 GPT-4o,也观察到了类似的趋势。 但是,DeepSeek-R1 在中文 SimpleQA 基准测试中的性能不如 DeepSeek-V3,这主要是因为其在安全强化学习后倾向于拒绝回答某些查询。 在没有安全强化学习的情况下,DeepSeek-R1 可以达到超过 70% 的准确率。
DeepSeek-R1还在 IF-Eval 上取得了令人印象深刻的结果,IF-Eval 是一个旨在评估模型遵循格式指令能力的基准测试。 这些改进可以与监督微调 (SFT) 和 RL 训练的最后阶段包含指令跟踪数据有关。 此外,在 AlpacaEval2.0 和 ArenaHard 上观察到卓越的性能,表明 DeepSeek-R1 在写作任务和开放领域问答方面的优势。 它显著优于 DeepSeek-V3,突显了大规模强化学习的泛化优势,这不仅提高了推理能力,而且还提高了跨不同领域的性能。 此外,DeepSeek-R1 生成的摘要长度简洁,在 ArenaHard 上平均为 689 个符元,在 AlpacaEval 2.0 上平均为 2,218 个字符。 这表明 DeepSeek-R1 在基于 GPT 的评估中避免了引入长度偏差,进一步巩固了其在多种任务中的鲁棒性。
在数学任务上,DeepSeek-R1 的性能与 OpenAI-o1-1217不相上下,远超其他模型。 在编码算法任务(例如 LiveCodeBench 和 Codeforces)上也观察到了类似的趋势,其中注重推理的模型在这些基准测试中占据主导地位。 在面向工程的编码任务上,OpenAI-o1-1217 在 Aider 上的性能优于 DeepSeek-R1,但在 SWE Verified 上取得了相当的性能。 我们相信 DeepSeek-R1 的工程性能将在下一个版本中得到改进,因为目前相关的强化学习训练数据仍然非常有限。
蒸馏模型评估
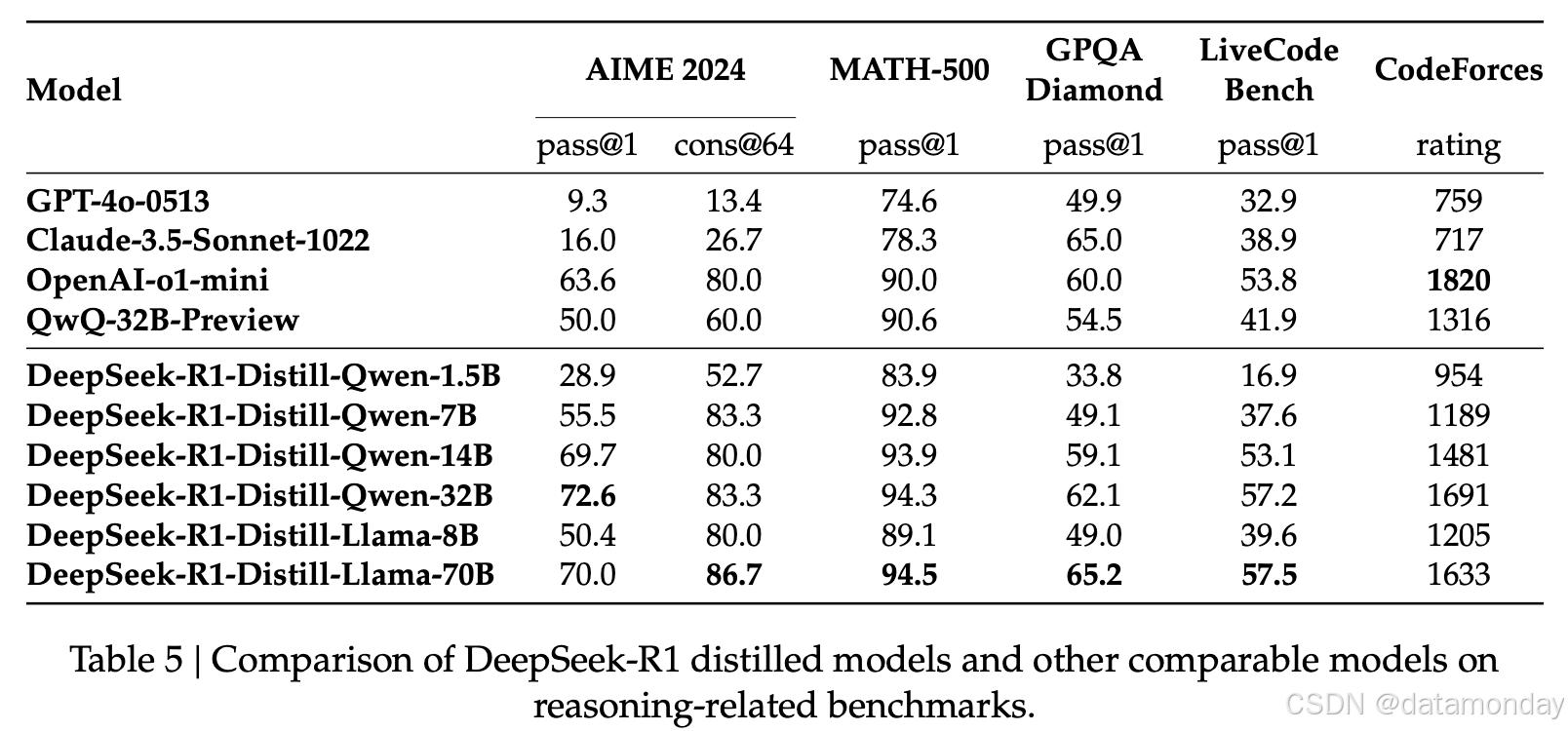
如表 5 所示,简单地蒸馏 DeepSeek-R1 的输出使高效的 DeepSeek-R1-7B(即 DeepSeek-R1-Distill-Qwen-7B,以下类似缩写)能够全面超越像 GPT-4o-0513 这样的非推理模型。 DeepSeek-R1-14B 在所有评估指标上都超过了 QwQ-32B-Preview,而 DeepSeek-R1-32B 和 DeepSeek-R1-70B 在大多数基准测试上都显著超过了 o1-mini。 这些结果证明了蒸馏的强大潜力。此外,将 RL 应用于这些蒸馏模型会产生进一步的显著增益。这值得进一步探索,因此这里仅展示简单的 SFT 蒸馏模型的结果。
蒸馏与RL
通过蒸馏DeepSeek-R1,小型模型可以取得令人印象深刻的结果。 然而,还有一个问题尚待解答:在没有蒸馏的情况下,模型能否通过论文中讨论的大规模强化学习训练达到可比的性能?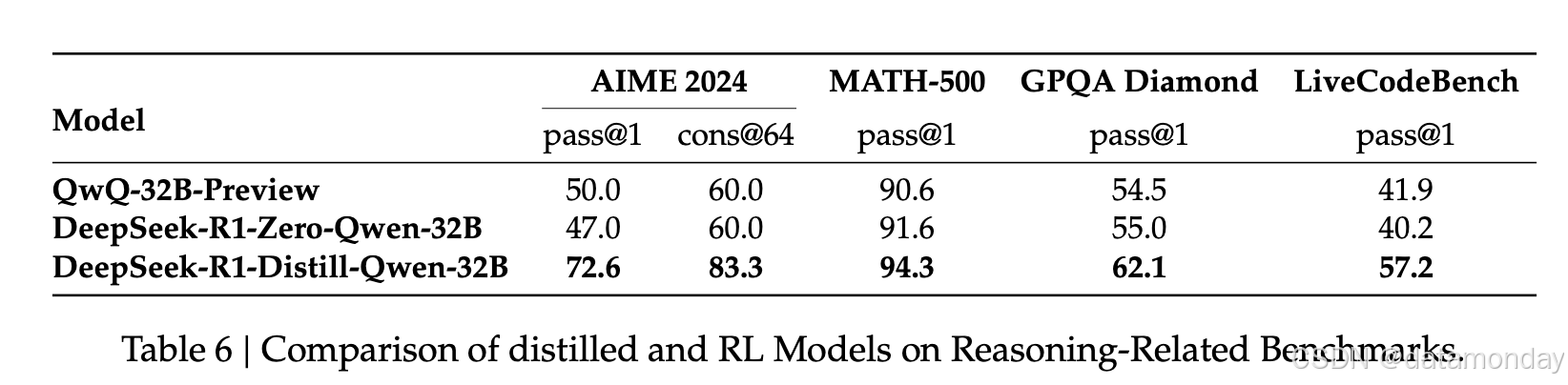
为了回答这个问题,使用数学、代码和STEM数据对Qwen-32B-Base进行了大规模强化学习训练,训练步数超过10K步,最终得到DeepSeek-R1-Zero-Qwen-32B。表 6 所示的实验结果表明,经过大规模强化学习训练的32B基础模型,其性能与QwQ-32B-Preview不相上下。 然而,从DeepSeek-R1蒸馏而来的DeepSeek-R1-Distill-Qwen-32B在所有基准测试中的性能都显著优于DeepSeek-R1-Zero-Qwen-32B。
因此,可以得出两个结论:
- 首先,将更强大的模型蒸馏成更小的模型可以产生优异的结果,而依赖于本文中提到的大规模强化学习的小型模型需要巨大的计算能力,甚至可能无法达到蒸馏的性能。
- 其次,虽然蒸馏策略既经济又有效,但要突破智能的界限,可能仍然需要更强大的基础模型和更大规模的强化学习。
未成功的尝试1:过程奖励模型(PRM)
PRM 是一种合理的引导模型朝着更好方法解决推理任务的方法。然而,在实践中,PRM具有三个主要的局限性。
- 首先,在一般的推理中很难明确定义细粒度的步骤。
- 其次,确定当前中间步骤是否正确是一项具有挑战性的任务。使用模型进行自动标注可能无法得到令人满意的结果,而人工标注不利于大规模扩展。
- 第三,一旦引入基于模型的PRM,它不可避免地会导致奖励挟持,而对奖励模型进行再训练需要额外的训练资源,并且会使整个训练流程复杂化。
总之,虽然PRM在重新排序模型生成的Top-N响应或辅助引导搜索方面表现出良好的能力,但与我们在实验中大规模强化学习过程中引入的额外计算开销相比,其优势有限。
未成功的尝试2:蒙特卡洛树搜索(MCTS)
受AlphaGo和AlphaZero的启发,探索使用蒙特卡洛树搜索 (MCTS) 来增强测试时间的计算可扩展性。此方法涉及将答案分解成更小的部分,以允许模型系统地探索解空间。为此,提示模型生成多个标签,这些标签对应于搜索所需的特定推理步骤。对于训练,首先使用收集到的提示,通过预训练的价值模型引导的MCTS来查找答案。 随后,使用生成的问答对来训练actor模型和价值模型,迭代地改进该过程。
然而,这种方法在大规模扩展训练时遇到了一些挑战。
- 首先,与搜索空间相对明确的国际象棋不同,token 生成呈现出指数级更大的搜索空间。为了解决这个问题,为每个节点设置了最大扩展限制,但这可能会导致模型陷入局部最优解。
- 其次,价值模型直接影响生成的质量,因为它指导搜索过程的每个步骤。训练细粒度的价值模型本身就很难,这使得模型难以迭代改进。虽然AlphaGo的核心成功依赖于训练价值模型以逐步提高其性能,但由于 token 生成的复杂性,目前难以复制。
总之,虽然MCTS可以与预训练的价值模型结合使用,在推理过程中提高性能,但通过自我搜索迭代地提高模型性能仍然是一个巨大的挑战。
实验结论
本文介绍了通过强化学习增强模型推理能力的方法。DeepSeek-R1-Zero 代表了一种纯粹的强化学习方法,无需依赖冷启动数据,在各种任务中都取得了优异的性能。DeepSeek-R1 更加强大,它利用冷启动数据以及迭代式强化学习微调。 最终,DeepSeek-R1 在一系列任务上的性能与 OpenAI-o1-1217 相当。
进一步探索了将推理能力蒸馏到小型稠密模型中。使用 DeepSeek-R1 作为教师模型生成 80 万个训练样本,微调几个小型稠密模型。结果令人鼓舞:DeepSeek-R1-Distill-Qwen-1.5B 在数学基准测试中优于 GPT-4o 和 Claude-3.5-Sonnet,在 AIME 上达到 28.9% 的准确率,在 MATH 上达到 83.9% 的准确率。其他稠密模型也取得了令人印象深刻的结果,显著优于基于相同底层检查点的其他指令调优模型。
未来计划:
- 通用能力: 目前,DeepSeek-R1 在函数调用、多轮对话、复杂角色扮演和 JSON 输出等任务上的能力不如 DeepSeek-V3。未来计划探索如何利用更长的思维链 (CoT) 来增强这些领域的任务。
- 语言混合: DeepSeek-R1 目前针对中文和英文进行了优化,这可能会导致在处理其他语言的查询时出现语言混合问题。例如,即使查询并非英文或中文,DeepSeek-R1 也可能使用英文进行推理和响应。计划在未来的更新中解决此限制。
- 提示工程: 在评估 DeepSeek-R1 时,它对提示很敏感。少样本提示始终会降低其性能。因此,建议用户直接描述问题并使用零样本设置指定输出格式以获得最佳结果。
- 软件工程任务:由于漫长的评估时间影响了强化学习过程的效率,因此大规模强化学习尚未广泛应用于软件工程任务中。DeepSeek-R1 在软件工程基准测试中并没有比 DeepSeek-V3 产生巨大的改进。未来版本将通过在软件工程数据上实现拒绝采样或在强化学习过程中结合异步评估来提高效率,从而解决这个问题。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 44
44 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)