DeepSeek-R1本地部署实践
Ollama是一个开源的 LLM(大型语言模型)服务工具,用于简化在本地运行大语言模型,降低使用大语言模型的门槛,使得大模型的开发者、研究人员和爱好者能够在本地环境快速实验、管理和部署最新大语言模型,包括如Llama 3、Phi 3、Mistral、Gemma等开源的大型语言模型。

一、下载安装 --Ollama
Ollama是一个开源的 LLM(大型语言模型)服务工具,用于简化在本地运行大语言模型,降低使用大语言模型的门槛,使得大模型的开发者、研究人员和爱好者能够在本地环境快速实验、管理和部署最新大语言模型,包括如Llama 3、Phi 3、Mistral、Gemma等开源的大型语言模型。
下载方式:
方式1:官网下载:
官网地址:https://ollama.com/download
如果官网地址一直卡住下载不下来,选用下面的方法
方式2:GitHub下载:
GitHub官方链接:https://github.com/ollama/ollama
点击GitHub链接,relase 跳转到要下载的资源文件,鼠标右击点击复制链接。如以下示例类型:
https://github.com/ollama/ollama/releases/download/v0.4.3/OllamaSetup.exe
替换如下域名加速:
https://github.xzc888.top/
替换之后示例为:
https://github.xzc888.top/ollama/ollama/releases/download/v0.4.3/OllamaSetup.exe
下载安装,打开cmd执行ollama -h,回显成功:
PS C:\Users\Administrator> ollama -h
Large language model runner
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
stop Stop a running model
pull Pull a model from a registry
push Push a model to a registry
list List models
ps List running models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --help help for ollama
-v, --version Show version information
Use "ollama [command] --help" for more information about a command.
打开ollama的Models:https://ollama.com/search ,搜索deepseek-r1,复制命令行执行即可。
如果你的显卡有8G以上显存,可以尝试7b的模型,如果没有就直接选择1.5b模型:
ollama run deepseek-r1
常用命令:
ollama list #获得已安装模型列表
ollama run llama3.1 #ollama run + 模型名 运行模型
ollama rm #ollama rm +模型名 删除模型
二、可视化页面 --Chatbox
下载Chatbox AI:https://chatboxai.app/zh
安装完成后进行如下设置即可:
参数说明:
Temperature(温度值),是大语言模型生成文本时用于调节输出随机性和多样性的参数。
- 数值越高,模型选择低概率词语的可能性越大,输出更加随机且富有创意;
- 数值越低,模型更倾向选择高概率词语,输出更确定且保守。
通过调整温度值,可在创造性和准确性之间进行平衡,以适应不同的应用场景。如创作者写文案可以调到最大。
另外,在专属对话设置中,还可以设置角色以及TopP:

TopP(又称核采样)是一种调节语言模型生成随机性的机制,通过对词汇的累积概率进行截断筛选,仅保留累积概率不超过阈值 p 的候选词,并从中按概率分布采样生成下一个词。
- 较高的 p 值(如 0.9 - 1.0):保留更多候选词,生成结果更具多样性,但也可能增加随机性。
- 较低的 p 值(如 0.1 - 0.3):保留更少的候选词,生成结果更加集中和确定。
与温度参数不同,TopP 动态地调整候选词的数量,适用于控制生成文本的随机性和连贯性。
提示词笔记:
1.真诚对话
帮我整理这份报告,我需要把这个报告上交给我的领导看,希望文字更加的清晰整洁,每一段话都能在句首列出重点;
2.通用公式
我要XX,要给XX用,希望能够达到XX效果,担心出现XX问题,帮我达到XX效果最大化;
举例:我要做一份旅游攻略,给我和女朋友旅游福建的时候用,希望能够更加提高我们的互动效果,能够达到更多的肢体接触,担心会不会出现太油腻太唐突的问题,帮我达到情侣感情升温的最大化,
3.问完问题之后,直接加上“说人话”这三个字
比如问“流体力学”是什么,一般情况会很官方的回答,但是如果你加上说人话三个字,那么将会很普通话的给你解析这个问题,适合;
4.反方向提问法
直接提问如果你是老板,你怎么批评这个方案?;这个结果你满意吗?请帮我复盘
5.反复问同一个问题;
Deepseek具有深度思考模型,如果你反复提问同一个问题,它就会总结累计回答的问题,为什么回答不够满意等,以及把思考的小细节显示出来,你会发现它的思考方式超级像一个逻辑能力超强的人类;
6.模仿思考
给一段谁谁的的语句,让它模仿学习,以它的思想去思考问题,比如,帮我以爱因斯坦的思想去思考这个问题,是否能够有什么解决方案
7.假设法
假设你是谈过10000次恋爱的感情达人;假设你是硅谷资深投资人,投过上百家互联网公司;假设你是健身教练,你应该怎么给你的学员准备增肌的一日三餐;
三、安装自己的知识库 --AnythingLLM
3.1 RAG介绍
什么是 RAG
RAG,即检索增强生成(Retrieval-Augmented Generation),是一种先进的自然语言处理技术架构,它旨在克服传统大型语言模型(LLMs)在处理开放域问题时的信息容量限制和时效性不足。RAG的核心机制融合了信息检索系统的精确性和语言模型的强大生成能力,为基于自然语言的任务提供了更为灵活和精准的解决方案。
RAG与LLM的关系
RAG不是对LLM的替代,而是对其能力的扩展与升级。传统LLM受限于训练数据的边界,对于未见信息或快速变化的知识难以有效处理。RAG通过动态接入外部资源,使LLM得以即时访问和利用广泛且不断更新的知识库,进而提升模型在问答、对话、文本生成等任务中的表现。此外,RAG框架强调了模型的灵活性和适应性,允许开发者针对不同应用场景定制知识库,从而满足特定领域的需求。
下图是 RAG 的一个大致流程:
RAG就像是为大型语言模型(LLM)配备了一个即时查询的“超级知识库”。这个“外挂”不仅扩大了模型的知识覆盖范围,还提高了其回答特定领域问题的准确性和时效性。
想象一下,传统的LLM像是一个博学多才但记忆力有限的学者,它依赖于训练时吸收的信息来回答问题。而RAG,则是这位学者随时可以连线的庞大图书馆和实时资讯网络。当面临复杂或最新的查询时,RAG能让模型即时搜索并引用这些外部资源,就像学者翻阅最新的研究资料或在线数据库一样,从而提供更加精准、全面和最新的答案。这种设计尤其适用于需要高度专业化或快速更新信息的场景,比如医学咨询、法律意见、新闻摘要等。
基于此,RAG 技术特别适合用来做个人或企业的本地知识库应用,利用现有知识库资料结合 LLM 的能力,针对特定领域知识的问题能够提供自然语言对话交互,且答案比单纯用 LLM 准确性要高得多。
3.2 RAG 实践 --Ollama+AnythingLLM 搭建本地知识库
AnythingLLM 是一个全栈应用程序,可以将任何文档、资源(如网址链接、音频、视频)或内容片段转换为上下文,以便任何大语言模型(LLM)在聊天期间作为参考使用。此应用程序允许您选择使用哪个LLM或向量数据库,同时支持多用户管理并设置不同权限。
部署AnythingLLM 官网下载安装包 → 打开即用,选择Ollama deepseek-r1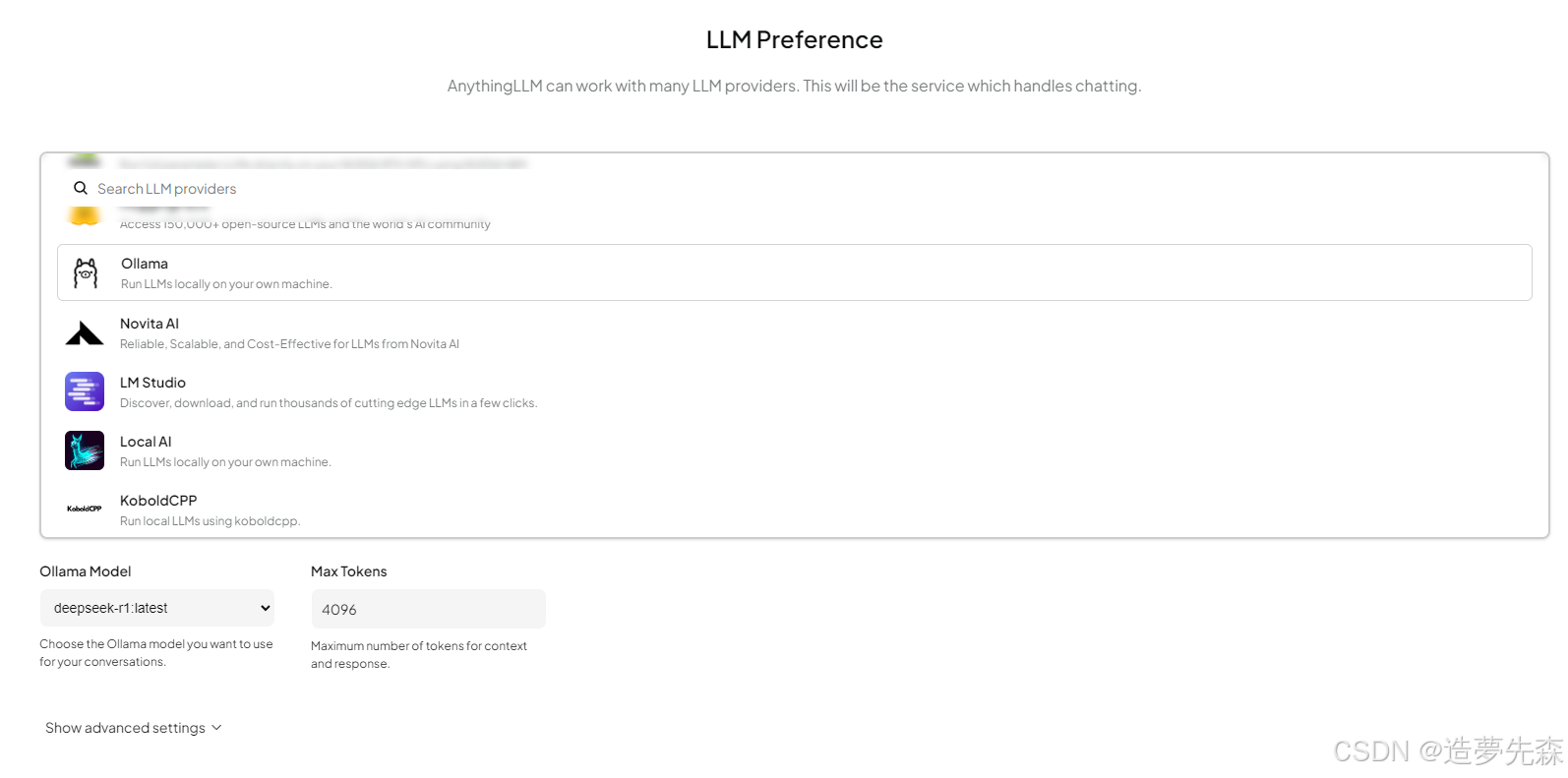
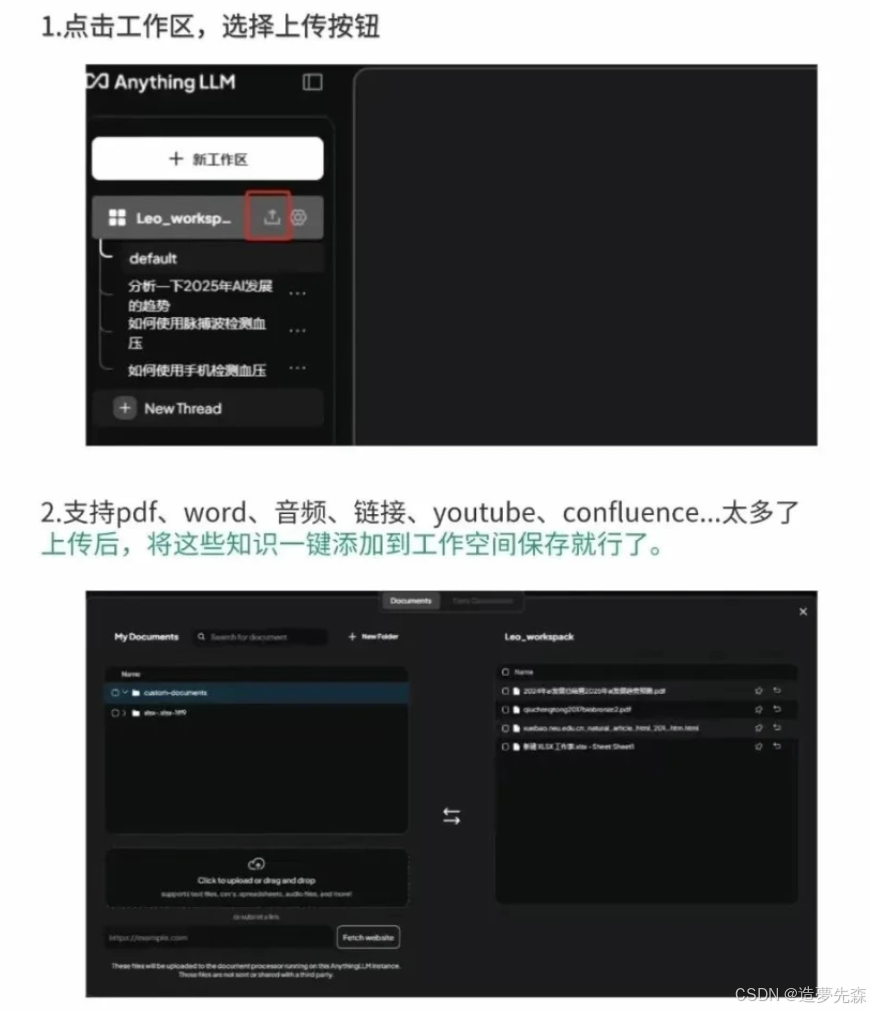
开喂知识库! 拖拽文件/粘贴链接 → 自动解析 → 随时提问! 💡 亲测能读论文、分析报表、整理会议记录,甚至当私人法律顾问!
四、DeepSeek API使用
1,注册deepseek并生成apikey
deepseek的api平台:https://www.deepseek.com/
选中apikeys菜单 -》 创建API-KEY
官方文档:https://api-docs.deepseek.com/zh-cn/
本地调用案例如下:
curl http://127.0.0.1:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <DeepSeek API Key>" \
-d '{
"model": "deepseek-r1",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
"stream": false
}'
其中model可以在本地cmd里查看:ollama list。测试结果:
2,在idea插件codegpt中配置deepseek
(1)打开idea的File->Settings->Plugins 安装CodeGPT
(2)打开idea的File->Settings->Tools->CodeGPT->Providers->Custom OpenAI
- Preset Template 选择 OpenAI
- API key 填入第二步中生成的key
- Chat Completions的URL填写
https://api.deepseek.com/v1/chat/completions或者本地调用http://127.0.0.1:11434/v1/chat/completions - 切换到Body,model配置为deepseek-reasoner(r1)或deepseek-chat(v3)
五、GGUF格式下载与加载
1、GGUF格式简介
GGUF(GPT-Generated Unified Format)是一种专为大规模机器学习模型设计的二进制文件格式。它通过将原始的大模型预训练结果进行优化后转换而成,具有加载速度快、资源消耗低等优势。GGUF格式支持内存映射技术,使得模型数据可以直接映射到内存中,从而提高了数据处理的效率。此外,GGUF还支持跨硬件平台优化,能够在CPU和GPU上高效运行。
使用GGUF格式加载Llama模型具有以下优势:
- 加载速度快:GGUF格式通过紧凑的二进制编码和优化的数据结构,显著提高了模型的加载速度。
- 资源消耗低:由于GGUF格式支持内存映射技术,模型数据可以直接映射到内存中,从而降低了资源消耗。
- 跨平台兼容性:GGUF格式旨在支持不同的硬件平台,包括CPU和GPU,使得模型能够在各种设备上高效运行。
2、从Huggingface下载GGUF文件
Huggingface是一个开放的人工智能模型库,提供了大量经过预训练的模型供用户下载和使用。要下载Llama模型的GGUF文件,请按照以下步骤操作:
(1)访问Huggingface网站: https://huggingface.co/models。
(2)搜索GGUF模型:在搜索框中输入“deepseek gguf”或相关关键词。当前在huggingface上总共有以下几种参数的deepseek R1:
DeepSeek-R1 671B
DeepSeek-R1-Zero 671B
DeepSeek-R1-Distill-Llama-70B
DeepSeek-R1-Distill-Qwen-32B
DeepSeek-R1-Distill-Qwen-14B
DeepSeek-R1-Distill-Llama-8B
DeepSeek-R1-Distill-Qwen-7B
DeepSeek-R1-Distill-Qwen-1.5B
(3)选择GGUF文件:在模型页面中,找到Files and versions栏,选择你想要下载的GGUF文件版本。通常,不同版本的GGUF文件大小不同,对应着不同的模型效果和精度。如何选择版本:
GGUF文件名中的量化标识(例如Q4_K_M、Q5_K_S等)代表不同的量化方法:
- Q2 / Q3 / Q4 / Q5 / Q6 / Q8: 量化的比特数(如Q4表示4-bit量化)。
- K: 表示量化时使用了特殊的优化方法(如分组量化)。
- 后缀字母:表示量化子类型:
- S (Small): 更小的模型体积,但性能损失稍大。
- M (Medium): 平衡体积和性能。
- L (Large): 保留更多精度,体积较大。
常见量化版本对比: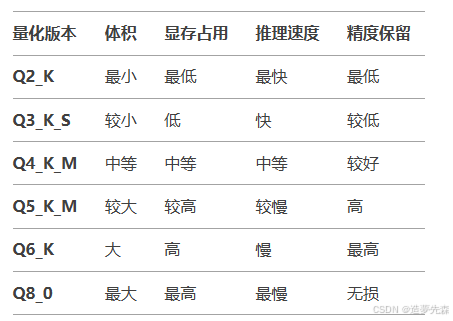
- 资源有限(如低显存GPU/CPU):选择低比特量化(如Q4_K_M或Q3_K_S),牺牲少量精度换取更低的显存占用。
- 平衡性能与速度:推荐Q4_K_M或Q5_K_S,适合大多数场景。
- 追求最高质量:选择Q5_K_M或Q6_K,接近原始模型效果,但需要更多资源。
- 完全无损推理:使用Q8_0(8-bit量化),但体积最大。
(4)下载GGUF文件:点击下载按钮,将GGUF文件保存到你的本地计算机中。注意事项:
- 大模型文件(如7B参数的GGUF文件)体积较大(可能超过10GB),直接存储或传输可能不便,将单一大文件分割为多个小文件(例如拆分成9个分片),每个分片包含模型的一部分数据。必须下载全部9个文件(从00001到00009),并确保它们位于同一目录下。
- 量化与性能关系:量化级别越低,模型回答的连贯性和逻辑性可能下降,尤其在复杂任务中(如代码生成、数学推理)。
- 硬件兼容性:
- 低量化模型(如Q2/Q3)更适合纯CPU推理。
- 高量化模型(如Q5/Q6)在GPU上表现更好。
- 实验验证:建议对不同量化版本进行实际测试,选择最适合你硬件和任务的版本。
3、使用Ollama加载GGUF模型
1,创建Modelfile文件:在你的工作目录中创建一个名为Modelfile的文本文件(扩展名可以省略)。在文件中写入一句话,指定GGUF模型文件的路径:
FROM ./path/to/your-model.gguf
2,创建Ollama模型:打开终端或命令行界面,运行以下命令来创建Ollama模型:
ollama create my_llama_model -f Modelfile
其中,my_llama_model是你为模型指定的名称,-f选项后面跟的是Modelfile文件的路径。
3,检查模型是否创建成功:运行以下命令来检查Ollama中是否已包含你创建的模型:
ollama list
你应该能在列表中看到你的模型名称。
4,运行模型:一旦模型创建成功,你就可以使用以下命令来运行它:
ollama run my_llama_model
此时,Ollama将加载你指定的GGUF模型文件,并运行该模型。
六、大模型应用实践中心
https://pangu.huaweicloud.com/gallery/solutions/ai-application.html

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 24
24 1
1- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)