WorkBuddy Skill 开发实战:从入门到写出高质量技能
WorkBuddy Skill 开发实战:从入门到写出高质量技能
文章目录
一、Skill 到底是什么
1.1 一句话定义
Skill 就是给 AI 编程助手(Claude Code、CodeBuddy、WorkBuddy 等)"加装"的能力包。本质上是一种结构化的 Prompt Engineering——通过标准的文件格式,把分散的领域知识、操作流程和最佳实践,转化为 AI 可理解、可执行的指令集。
物理上看,它就是一个文件夹,里面包含:
| 组成部分 | 作用 | 是否必需 |
|---|---|---|
| 指令(Instructions) | 告诉 AI 怎么干活,按什么步骤来 | 必需 |
| 上下文(Context) | 项目背景、团队规范等 AI 不可能凭空知道的东西 | 推荐 |
| 工具(Tools) | 辅助脚本、配置模板,AI 可以直接拿来用 | 可选 |
打个比方:裸着的 AI 就像一个刚入职的新人,啥都得问;装了 Skill 之后,就像拿到了老员工整理的操作手册,照着就能干。
1.2 渐进式加载机制
Skill 不是一股脑全塞进 AI 上下文的,而是采用三层渐进式加载,兼顾触发精准度和 Token 成本:
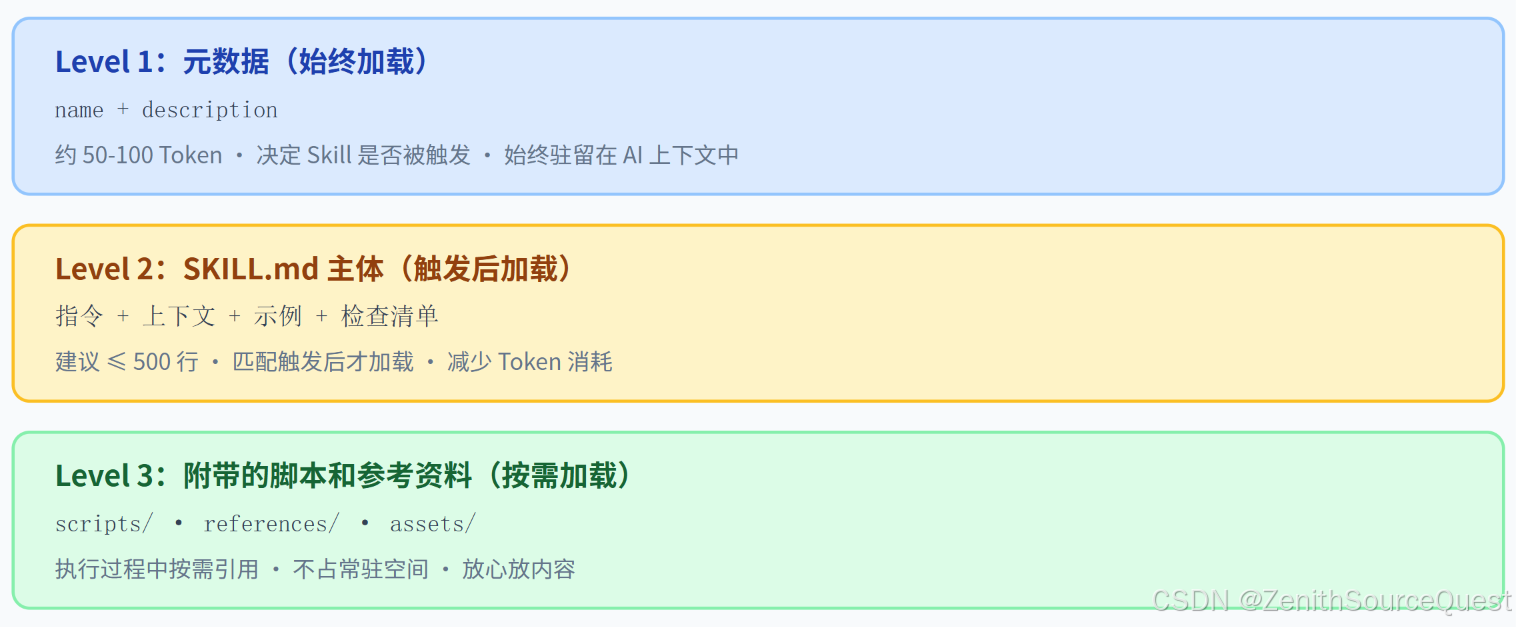
各层的作用和约束:
| 层级 | 内容 | 加载时机 | Token 消耗 | 编写建议 |
|---|---|---|---|---|
| Level 1 | name + description | 始终驻留在 AI 上下文中 | 约 50-100 | 越精准越好,决定触发时机 |
| Level 2 | SKILL.md 正文 | Skill 被匹配触发时加载 | 建议 ≤ 500 行 | 越精简越好,减少 Token 消耗 |
| Level 3 | scripts/ references/ assets/ | 执行过程中按需引用 | 按需 | 放心放,不占常驻空间 |
核心原则:Level 1 越精准越好(决定触发时机),Level 2 越精简越好(减少 Token 消耗),Level 3 放心放(按需加载不占常驻空间)。
二、WorkBuddy Skill 的目录结构
WorkBuddy 上 Skill 的标准目录结构如下:

各文件职责详解
| 文件/目录 | 必选 | 说明 |
|---|---|---|
SKILL.md |
✅ | 核心灵魂。YAML 元数据(name、description)+ Markdown 正文指令 |
scripts/ |
可选 | Python/Bash 脚本。前置检查、数据转换、API 调用等逻辑 |
references/ |
可选 | 参考文档。API 规范、编码规范、模板文件 |
assets/ |
可选 | 静态资源。JSON 模板、配置文件等 |
三、Quick Start:5 分钟用 Python 写第一个 WorkBuddy Skill
以"Python 代码安全检查"为例,跟着做一遍。
第一步:创建目录
mkdir python-security-check
cd python-security-check
mkdir scripts references
第二步:编写 SKILL.md
---
name: python-security-check
description: >
对 Python 代码进行安全审查。当用户要求检查代码安全、审计 Python 脚本、
或查找安全漏洞时触发。适用于所有 Python 项目。
---
# Python 代码安全检查
## 目标
对指定的 Python 文件或代码片段进行安全审查,识别常见安全漏洞。
## 检查清单
按以下维度逐项检查:
### 1. 敏感信息硬编码
- 搜索关键词:`password`、`secret`、`api_key`、`token`、`private_key`
- 错误示例:`API_KEY = "sk-xxxxx"`
- 正确示例:`API_KEY = os.environ.get("API_KEY")`
### 2. SQL 注入风险
- 搜索字符串拼接的 SQL 语句
- 错误示例:`f"SELECT * FROM users WHERE name='{name}'"`
- 正确示例:使用参数化查询
### 3. 命令注入风险
- 搜索 `os.system()`、`subprocess.call(shell=True)`
- 推荐使用 `subprocess.run([...])` 且不启用 shell
### 4. 反序列化风险
- 搜索 `pickle.loads()`、`yaml.load()`
- 推荐使用 `yaml.safe_load()` 或避免 pickle
### 5. 路径遍历风险
- 搜索用户输入直接拼接到文件路径
- 推荐使用 `os.path.realpath()` 校验
## 输出格式
按以下结构输出审查报告:
- 🔴 严重问题:可直接导致安全漏洞
- 🟡 改进建议:存在风险但未必立即触发
- 🟢 可选优化:编码规范层面的建议
第三步:编写检查脚本
scripts/check_secrets.py:
import ast
import sys
import re
SECRET_PATTERNS = [
r'(?i)(api[_-]?key|secret[_-]?key|access[_-]?token)\s*=\s*["\'][^"\']{8,}["\']',
r'(?i)(password|passwd|pwd)\s*=\s*["\'][^"\']+["\']',
r'(?i)(private[_-]?key)\s*=\s*["\']',
]
def check_file(filepath: str) -> list:
issues = []
with open(filepath, "r", encoding="utf-8") as f:
content = f.read()
for lineno, line in enumerate(content.split("\n"), 1):
for pattern in SECRET_PATTERNS:
if re.search(pattern, line):
issues.append({
"line": lineno,
"type": "硬编码凭据",
"content": line.strip(),
"severity": "严重"
})
return issues
if __name__ == "__main__":
if len(sys.argv) < 2:
print("用法: python check_secrets.py <filepath>")
sys.exit(1)
results = check_file(sys.argv[1])
for r in results:
print(f"[{r['severity']}] 第{r['line']}行 - {r['type']}: {r['content']}")
if not results:
print("未发现硬编码凭据。")
第四步:测试
在 WorkBuddy 对话中输入:
“帮我检查
app/config.py有没有安全漏洞”
AI 应该自动触发 python-security-check Skill,执行检查并输出报告。
四、写出好 Skill 的关键技巧
4.1 Description 是成败的关键
AI 就是靠 description 来判断"用户现在说的这个事,该不该用这个 Skill"。写得太笼统,触发不精准;写得太窄,该触发的场景又漏了。
反面案例:
description: 处理代码问题
正面案例:
description: >
对 Python 代码进行安全漏洞审查。当用户提到"安全检查"、"代码审计"、
"安全漏洞"、"查找安全问题"时触发。覆盖硬编码凭据、SQL注入、
命令注入、反序列化、路径遍历五大类问题。
实用技巧:触发评估法——自己想 20 个问题(一半该触发、一半不该触发),测试 AI 是否能正确判断。命中率不够就回来调 description。
4.2 用祈使句下指令,并解释"为什么"
写 Skill 有两个核心原则:
第一,别用商量的口吻,直接说做什么:
# ❌ 不推荐
你应该检查 Python 版本,然后选择合适的依赖管理方式。
# ✅ 推荐
检查 Python 版本。根据版本号选择方案:
- Python < 3.8 → 不兼容,提示升级
- Python >= 3.8 → 使用 pip + venv
第二,与其堆砌"MUST",不如讲清楚为什么:
# ❌ 不推荐
必须使用参数化查询。绝对不能拼接字符串。
# ✅ 推荐
使用参数化查询而非字符串拼接来构建 SQL。
字符串拼接会导致 SQL 注入漏洞——攻击者可以通过输入
`'; DROP TABLE users; --` 来删除整张表。
AI 理解了背后的道理,遇到你没想到的情况也能做出合理判断。
4.3 给出 Before/After 对比示例
这是 Skill 中最关键的部分——让 AI 清楚知道"改什么"和"改成什么"。
方式一:注释标注(适合简单变更)
# Before
import requests
def fetch(url):
return requests.get(url).json()
# After
import httpx
def fetch(url):
with httpx.Client(timeout=30) as client:
return client.get(url).json()
方式二:完整文件对比(适合复杂变更)
# Before: app/db.py
import sqlite3
def get_user(name):
conn = sqlite3.connect("app.db")
cursor = conn.cursor()
cursor.execute(f"SELECT * FROM users WHERE name='{name}'")
return cursor.fetchone()
# After: app/db.py
import sqlite3
def get_user(name):
conn = sqlite3.connect("app.db")
cursor = conn.cursor()
cursor.execute("SELECT * FROM users WHERE name=?", (name,))
return cursor.fetchone()
4.4 Few-Shot:3-5 个高质量示例让 AI 稳定输出
在 Skill 里放 3-5 个输入/输出示例,AI 的表现会稳定很多。几个关键原则:
- 覆盖典型场景:正常情况、边界情况、错误情况各来一个
- 输入输出成对出现:每个示例都要有"给什么"和"出什么"
- 示例之间有差异:别搞 3 个长得差不多的,要展示不同的处理分支
- 先放最典型的:AI 更倾向于模仿前面的示例
以"代码审查 Skill"的 Few-Shot 示例为例:
## 审查报告格式
### 示例 1:安全漏洞(严重问题)
**输入**:
```python
def get_user(name):
sql = "SELECT * FROM users WHERE name = '" + name + "'"
return db.execute(sql)
输出:
🔴 严重问题
- [第2行] SQL 注入风险:使用字符串拼接构建 SQL 查询。
- 修复建议:
db.execute("SELECT * FROM users WHERE name = ?", (name,)) - 风险等级:Critical
- 修复建议:
示例 2:代码规范(轻微问题)
输入:
class user_service:
def GetAllUsers(self):
Data = UserRepository.Find()
return Data
输出:
🟢 可选优化
- [第1行] 类名应使用 PascalCase:
user_service→UserService - [第2行] 方法名应使用 snake_case:
GetAllUsers→get_all_users - [第3行] 变量名不应用大写开头:
Data→data
### 4.5 善用表格呈现结构化信息
AI 读表格比读大段文字准确得多。能结构化的信息,尽量用表格:
```markdown
## 依赖版本兼容矩阵
| 依赖 | 最低版本 | 推荐版本 | 备注 |
|------|----------|----------|------|
| workbuddy-sdk | 1.2.0 | 1.5.0+ | 技能开发核心 SDK |
| Python | 3.8 | 3.10+ | 3.7 已停止维护 |
| httpx | 0.23.0 | 0.27.0+ | HTTP 请求库 |
| pydantic | 2.0.0 | 2.5.0+ | 数据校验 |
五、模块化拆分:Skill 太长了怎么办
5.1 什么时候该拆
一个 Skill 干一件事是最理想的状态。以下情况该考虑拆分:
- 文件超过 500 行(Anthropic 官方建议上限)
- 有些步骤可以单独用,没必要每次都跑整个流程
- 不同部分改动频率差很多(一个每月改三次,另一个半年不动)
5.2 拆分模式
简单场景:一个文件搞定
my-skill/
└── SKILL.md
复杂场景:主 Skill + 子 Skill
project-migration/ # 主 Skill:流程编排
├── SKILL.md
└── references/
├── 00-env-setup.md
├── 01-dependency-update.md
└── 02-api-migration.md
project-migration-env-setup/ # 子 Skill:可独立调用
├── SKILL.md
└── scripts/
└── check_env.py
5.3 拆分原则
- 单一职责:一个子 Skill 只管一件事(如
env-setup、api-migration) - 写明依赖关系:子 Skill 之间有先后顺序的,在文档里标注前置条件
- 每个子 Skill 都能独立使用:拆出来的子 Skill 不应离了主流程就没法跑
六、安全设计:别让 Skill 变成漏洞入口
6.1 绝不硬编码敏感信息
# ❌ 千万别这样
API_KEY = "sk-abc123xyz"
headers = {"Authorization": f"Bearer {API_KEY}"}
# ✅ 通过环境变量
import os
API_KEY = os.environ.get("API_KEY")
if not API_KEY:
raise ValueError("请设置环境变量 API_KEY")
Skill 文件通常会提交到 Git 仓库。一旦硬编码了 API Key、数据库密码、Token 等,就等于把密钥公开了。
6.2 危险操作必须加确认
# ❌ 不加确认直接删
os.remove("/data/old_backup/")
# ✅ 先确认再操作
import shutil
target = "/data/old_backup/"
print(f"即将删除目录: {target}")
confirm = input("确认删除?(y/N): ")
if confirm.lower() != "y":
print("已取消")
exit(0)
shutil.rmtree(target)
在 SKILL.md 中也要标注风险步骤:
### Step 3: 清理旧数据
⚠️ **此步骤会永久删除旧版配置文件,请确认已备份后再执行。**
6.3 脚本沙箱与最小权限
WorkBuddy 强制要求所有 Python 脚本必须在预设白名单目录中运行。编写脚本时应遵循最小权限原则——只访问必要的文件、只调用必要的 API。
七、常见反模式与避坑
| 反模式 | 表现 | 正确做法 |
|---|---|---|
| 万能 Skill | description 写成"处理任何编程任务" | 精确定义触发场景和适用范围 |
| 流水账式指令 | “步骤1:读取文件。步骤2:解析 JSON…” | 描述目标而非路径,给 AI 自由度 |
| 单文件超级大 | SKILL.md 超过 800 行 | 拆分为 references/ 子文件 |
| 缺少反面示例 | 只写了什么时候该触发 | 同时写清楚什么时候不该触发 |
| 忽略 Token 成本 | 装了 20 个 Skill 不评估消耗 | 定期用 tokenizer 估算,精简 Level 2 |
| 无验证清单 | AI 做完不知道对不对 | 每个 Skill 末尾加上检查清单 |
八、完整开发流程总览
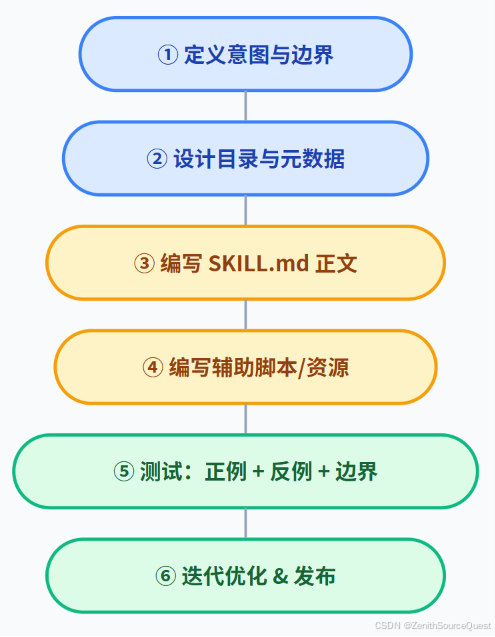
8.1 各阶段要点
| 阶段 | 关键动作 | 产出物 |
|---|---|---|
| ① 定义意图与边界 | 明确 Skill 做什么、不做什么 | 一句话描述 + 触发词列表 + 排除词列表 |
| ② 设计目录与元数据 | 决定是否拆分、写 YAML 头 | 目录结构 + description |
| ③ 编写 SKILL.md | 指令、示例、检查清单 | SKILL.md(≤ 500 行) |
| ④ 编写辅助脚本 | 前置检查、数据转换、API 调用 | scripts/*.py |
| ⑤ 测试 | 正例 10 条 + 反例 10 条 + 边界 5 条 | 测试用例 + 触发准确率 |
| ⑥ 迭代优化 | 根据测试结果调整 description 和指令 | 优化后的 SKILL.md |
8.2 关于 WorkBuddy 的特别说明
WorkBuddy 提供两种生成 Skill 的方式:
- AI 自动生成(推荐):直接在对话中描述需求,WorkBuddy 自动生成完整的 Skill 包
- 手动封装:手动完成一次任务后,让 WorkBuddy 把操作"封装"成 Skill
对于初学者,建议先用方式 1 快速上手,再用手动方式理解 Skill 的内部结构。
九、总结
写好一个 Skill,核心就是三件事:
- 把 description 写对——这是 Skill 的"门禁卡",决定 AI 何时触发它
- 把内容写精——Instruction 精简、示例充足、表格化结构化信息,控制在 500 行内
- 把安全守好——不硬编码凭据、危险操作加确认、脚本遵循最小权限
Skill 不是一次性写完就扔的东西,它是一个需要持续迭代的工程资产。好的 Skill 应该在上百次调用中都稳定有效。
延伸阅读:
感谢阅读,记得点赞、关注、收藏,欢迎各位评论区交流!!!


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)