ClaudeCode_测试Ontology_MCP实战
我用 Claude Code 搭了一个测试 Ontology
让 AI 看懂需求、用例、缺陷和上线风险
适用场景:测试质量管理、AI 测试助理、MCP 实战、企业 AI 落地
先看最终效果:Claude Code 通过本地 MCP 查询 Ontology 数据后,能识别
REL-1.2.0 当前仍有 2 个未关闭 Bug,其中 1 个 P1,并给出建议回归范围。

图 1:Claude Code 基于 sqa-ontology MCP 输出版本风险速览。
一、为什么要做这个 Demo
前面讲 MCP 时,我们解决的是“AI 怎么连接工具”的问题。但连接之后,AI
还需要理解业务对象之间的关系。对测试团队来说,真正重要的不是让 AI 查到
Bug,而是让它知道 Bug
关联哪个用例、哪个需求、哪个版本,以及这些关系是否形成上线风险。
所以这次 Demo 的目标不是做一个复杂平台,而是搭一个最小可运行的测试质量
Ontology:
Release 版本
└── Requirement 需求
├── TestCase 测试用例
└── Bug 缺陷
└── Risk 上线风险
最终我们希望在 Claude Code 里问:“请分析 REL-1.2.0 是否还有上线风险。”
它能基于本地数据给出结构化结论,而不是泛泛回答。
二、本次 Demo 的项目结构
整个项目只保留几个核心文件,便于读者照着复现。

图 2:Demo 项目目录。核心文件包括
CLAUDE.md、ontology.json、query_ontology.py、mcp_server.py。
| 文件 | 作用 |
|---|---|
| CLAUDE.md | 给 Claude Code 的项目说明和行为约束,避免它编造需求、用例或缺陷。 |
| ontology.json | 测试质量 Ontology 数据模型,表达需求、版本、用例和缺陷之间的关系。 |
| query_ontology.py | 本地查询脚本,用于聚合版本风险、未关闭 Bug 和建议回归范围。 |
| mcp_server.py | 把本地查询能力封装成 MCP 工具,供 Claude Code 调用。 |
| README.md | Demo 项目说明。 |
三、第一步:定义测试质量 Ontology
这一步的重点不是建数据库,而是先把测试工作中的关键对象和关系显式表达出来。我们先定义
5 类对象:Requirement、Release、Module、TestCase、Bug。
| 对象 | 含义 | 示例 |
|---|---|---|
| Requirement | 需求 | 报销审批规则优化 |
| Release | 版本 | REL-1.2.0 |
| Module | 模块 | H5端、数据导出、报销审批 |
| TestCase | 测试用例 | H5端提交报销后状态变为审批中 |
| Bug | 缺陷 | H5端提交报销后状态未刷新 |
对象之间的关系是 Ontology 的核心:
| 关系 | 含义 |
|---|---|
| Release includes Requirement | 版本包含需求 |
| Requirement has TestCase | 需求被用例覆盖 |
| TestCase found Bug | 用例执行发现缺陷 |
| Bug belongs to Module | 缺陷归属模块 |
| Bug blocks Release | 缺陷可能影响版本上线 |
完成 ontology.json
后,我先用一个简短脚本读取对象统计,确认数据结构没有问题。

图 3:Ontology
对象统计。能看到需求、版本、模块、用例、缺陷数量,以及未关闭 Bug。
四、第二步:本地脚本输出版本风险
有了结构化对象后,下一步用 query_ontology.py
做本地聚合。这个脚本会做几件事:
• 根据 release_id 找到版本包含的需求。
• 根据需求找到关联测试用例和失败用例。
• 根据需求找到未关闭 Bug。
• 统计 Bug 优先级分布和模块分布。
• 根据 P0/P1 未关闭问题判断是否存在阻断风险。
• 根据失败用例和 Bug 模块推荐回归范围。
本地执行效果如下:

图 4:本地执行 query_ontology.py 后输出的版本风险分析。
这一步已经能看出 Ontology 的价值:它不是把 Bug
孤立列出来,而是把版本、需求、用例、Bug 和回归范围关联起来。
五、第三步:准备 MCP Python 环境
接下来把本地查询能力暴露给 Claude Code。因为 MCP Python SDK 需要 Python
3.10+,本次本地环境使用 Python 3.11 创建虚拟环境。
cd ~/sqa-ontology-demo
python3.11 -m venv .venv
source .venv/bin/activate
python -m pip install --upgrade pip
pip install mcp
python -c “import mcp; print(‘mcp ok’)”

图 5:MCP Python SDK 安装完成,import mcp 校验通过。
这里遇到过一个实际问题:系统默认 Python 是 3.9.6,安装 mcp
会失败。因此不要动系统 Python,直接用 Python 3.11 重建 .venv 更稳。
六、第四步:把查询能力封装成 MCP 工具
mcp_server.py 只暴露 3
个只读工具。第一版不做写入,避免误改真实系统数据。
| MCP 工具 | 作用 |
|---|---|
| query_release_risk | 查询版本风险,返回需求数、用例数、失败数、未关闭 Bug、风险分布。 |
| query_requirement_quality | 查询某个需求的质量状态,包括关联用例和未关闭 Bug。 |
| get_regression_scope | 根据失败用例和未关闭 Bug 推荐回归范围。 |
from mcp.server.fastmcp import FastMCP
mcp = FastMCP(“sqa-ontology-mcp”)
@mcp.tool()
def query_release_risk(release_id: str):
return get_release_risk(release_id)@mcp.tool()
def query_requirement_quality(requirement_id: str):
return get_requirement_quality(requirement_id)@mcp.tool()
def get_regression_scope(requirement_id: str):
return recommend_regression_scope(requirement_id)
如果手动执行 python mcp_server.py 后出现 JSON-RPC EOF
报错,不一定是代码问题。stdio MCP Server 本来就是给 Claude Code
拉起并通信的,不适合在普通终端里人工交互。
七、第五步:注册到 Claude Code
拿到虚拟环境 Python 路径和 mcp_server.py 的绝对路径后,执行:
claude mcp add --transport stdio sqa-ontology – \
/Users/vito/sqa-ontology-demo/.venv/bin/python \
/Users/vito/sqa-ontology-demo/mcp_server.pyclaude mcp list
claude mcp get sqa-ontology
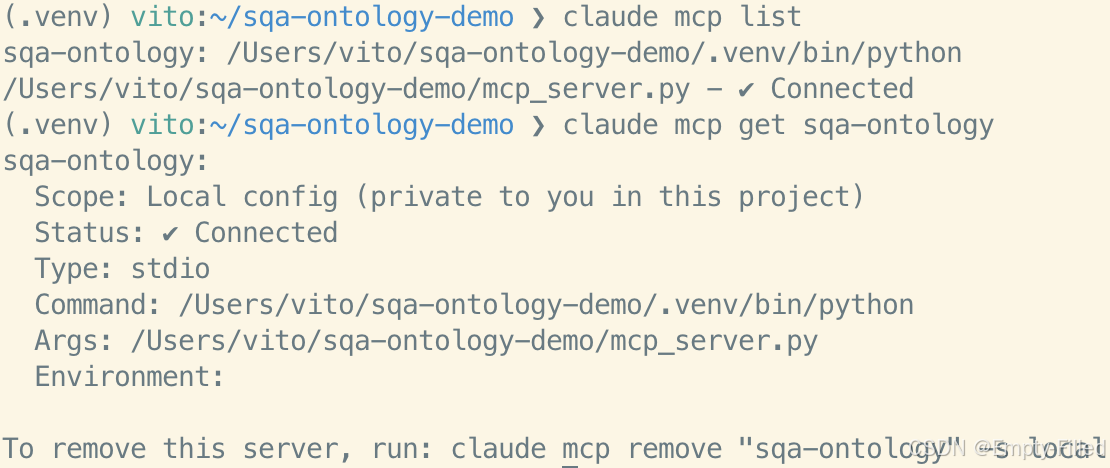
图 6:sqa-ontology 已成功注册为 Claude Code 的本地 stdio MCP Server。
截图里可以看到 Status 为 Connected,说明 Claude Code 已经能连接本地 MCP
Server。
八、第六步:让 Claude Code 分析上线风险
在 Claude Code 中输入:
请使用 sqa-ontology MCP 的 query_release_risk 工具,分析 REL-1.2.0
的上线风险。要求:
- 必须基于 MCP 返回的数据;
- 不要编造不存在的需求、Bug 或用例;
- 输出未关闭 Bug 数量、优先级分布、模块分布;
- 输出建议回归范围;
- 不要直接给出“可以上线/不可以上线”的绝对结论。
为了方便截图,我让 Claude Code 再输出一版“一屏内风险速览”:

图 7:Claude Code 基于 MCP + Ontology 输出的一屏内风险速览。
这个结果的重点不是“语言写得像报告”,而是它的结论来自结构化数据:版本包含需求,需求关联用例,用例失败发现
Bug,未关闭 P1 形成上线风险。
九、这套 Demo 的价值
这个 Demo 很小,但跑通了一个关键闭环:
测试对象建模
→ 本地风险查询
→ MCP 工具暴露
→ Claude Code 调用
→ 输出上线风险分析
它说明 MCP 和 Ontology 的关系可以这样理解:
| 组件 | 价值 |
|---|---|
| MCP | 解决 AI 怎么连接工具和数据。 |
| Ontology | 解决 AI 怎么理解业务对象、关系和动作。 |
| Claude Code | 作为 AI 工作入口,调用 MCP 工具并生成分析结果。 |
只让 AI 查询 Bug,价值有限;让 AI 理解 Bug
关联哪个用例、哪个需求、哪个版本,才更接近真实测试助理。
十、落地建议
如果要把这个思路放到团队里,不建议一上来就做自动写入。更稳的路线是:
| 阶段 | 建议 |
|---|---|
| 阶段 1:只读查询 | 查询需求、用例、Bug、测试结果、构建结果,输出风险摘要。 |
| 阶段 2:草稿生成 | 生成测试报告草稿、Bug 草稿、回归建议,人工确认后使用。 |
| 阶段 3:受控写入 | 对低风险动作做写入,关键动作必须保留确认和审计。 |
对测试团队来说,最适合先做的是“只读查询 +
风险汇总”。这类场景风险低、价值高,也容易让团队建立信任。
十一、写在最后
企业 AI
落地不能只靠大模型。大模型能理解语言,但它未必理解企业内部的业务对象;MCP
能连接工具,但连接之后仍然需要业务地图。Ontology
的价值,就是把需求、用例、缺陷、版本、风险这些测试对象组织成 AI
能理解和查询的业务世界。
一句话总结:MCP 解决连接,Ontology 解决理解。当 Claude Code 能通过 MCP
查询数据,又能通过 Ontology
理解需求、用例、缺陷和版本之间的关系,它才真正开始接近一个测试助理。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)