Hermes学习
目录
Layer 1: Prompt Memory(MEMORY.md + USER.md)
Layer 2: Session Retrieval(SQLite + FTS5)
1.概述:Hermes 是什么?
Hermes Agent (社区俗称“爱马仕”)是 NousResearch 开发的开源(MIT License)AI Agent 框架。
核心理念:一个Agent 的能力应该随使用时间叠加增长——它不是每次会话都从零开始的聊天机器人,而是一个会从经验中学习、积累技能、建立用户模型的持久智能体。
与claude code 的关系:
- Claude Code 是 Anthropic 的专有编程 Agent(闭源,专注代码)
- Hermes Agent 是通用 Agent 框架(开源,多平台多模型)
- 两者都实现了 Harness 架构模式,但哲学不同
2.Harness 九大组件全景
Arize 这类做 Agent 观测、评测的行业公司,总结出一套能稳定商用、不出乱子的 AI 智能体必备 9 件配套能力,Hermes 全部做齐了,一件没缺。
| # | 组件 | Hermes 如何实现 |
|---|---|---|
| 1 | 外层迭代循环:AI 自动思考 - 调用工具的主流程 | 固定一套流水线,无限循环: 标准 model-call → tool-dispatch → result-append → repeat,通过 Provider 抽象层归一化不同 API |
| 2 | 上下文管理与压缩:防止对话太长 AI 失忆、超限 |
问题:聊久了所有历史、工具返回内容全堆在上下文,会超模型窗口、AI 记不住重点、计费变贵。 Hermes 五步精简逻辑:
简单说:自动给聊天记录 “瘦身”,长对话也不崩。 |
| 3 | 技能与工具管理:按需给 AI 开放工具,不全部暴露 |
注册与暴露分离;70+ 工具,28 个工具集;按场景决定模型可见的工具子集 手里一共 70 多个工具,打包成 28 套工具组(文件操作、网络、数据库等)。 不是一次性把所有工具全塞给 AI,干什么活只给对应工具。 例:只让 AI 写文档时,就屏蔽代码执行、系统命令工具,减少 AI 乱调用出错。 工具注册和对外展示分开,新增工具不用改核心流程。 |
| 4 | 子代理管理:AI 派小助手单独处理复杂子任务 |
delegate_task,独立 task_id + 终端上下文,结构化摘要返回;危险命令默认拒绝;递归深度封顶 复杂任务拆分交给小代理去单独干活:
|
| 5 | 内置技能包:现成标准化工具库,开箱即用 | 166 个技能(87 内置直接能用 + 79 可选按需开启),遵循 agentskills.io 开放标准 |
| 6 | 会话持久化与恢复:关掉程序下次打开继续聊 |
SQLite + FTS5 全文搜索 + WAL 日志;跨平台会话衔接 本地SQLite数据库存所有对话,支持全文检索历史聊天记录;日志防丢失;Windows/Mac/Linux 多端打开,能读取上次没做完的任务,无缝接续 |
| 7 | System Prompt 组装:分层管理 AI 人设、规则 |
三层提示词架构:stable(身份/SOUL.md)→ context(AGENTS.md)→ volatile(时间戳/元数据)
|
| 8 | 生命周期钩子:全程可插自定义逻辑(插件机制) |
两面:进程内插件钩子 + 文件系统驱动的 Gateway 钩子 分两种自定义入口,你能在 Agent 任意阶段插入自己代码:
|
| 9 | 权限与安全层:防泄密、防 AI 执行危险操作 |
智能审批(学习安全命令)、PII 脱敏、密钥脱敏、危险命令检测 一套安全防护全套功能:
|
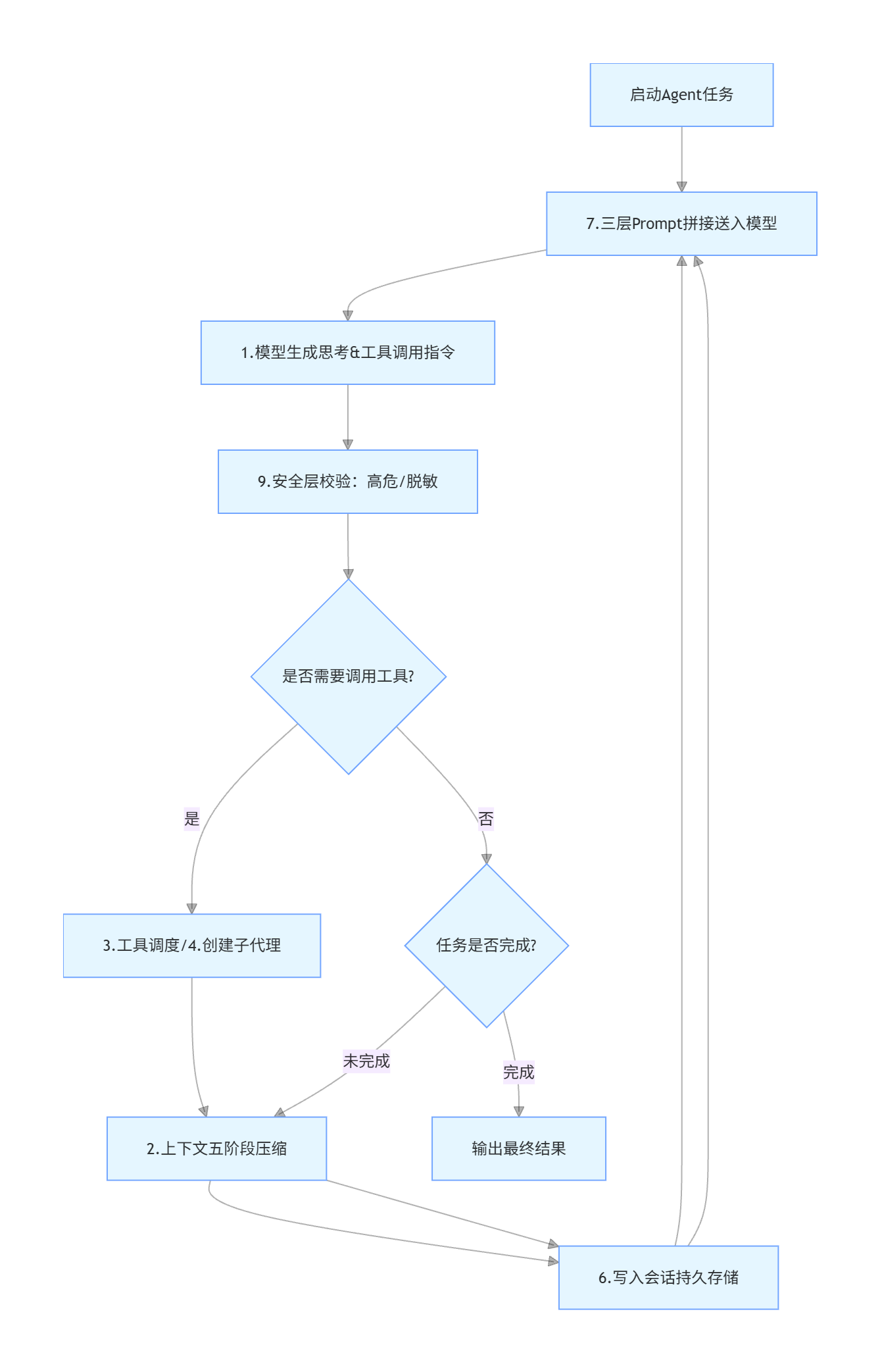
核心流程
3. 核心架构
3.1 统一执行引擎 AIAgent
所有入口共享同一个核心类 AIAgent(run_agent.py),无论消息来自 CLI、Telegram、Discord 还是 API:
CLI (cli.py) │ Gateway (gateway/run.py) │ ACP (acp_adapter/) │ API Server │ Batch Runner
│ │ │ │ │
└─────────────────────┴────────────────────────┴──────────────────┴───────────────┘
│
AIAgent Core
┌─────────────────┼─────────────────┐
Prompt Builder Provider Resolution Tool Dispatch
Compression (3 API modes) Registry (70+ tools)设计原则:
- Prompt 稳定性:System prompt 在会话期间永不改变(保护 Anthropic prefix caching)
- 平台无关核心:一个
AIAgent类服务所有入口 - 松耦合:可选子系统使用注册模式 +
check_fn门控,无硬依赖 - Profile 隔离:每个 profile 有独立的
HERMES_HOME、配置、记忆、会话
执行循环:
Message Arrives → Generate Task ID
→ Load System Prompt (冻结快照: MEMORY.md/USER.md + skill 索引)
→ Compression Pre-check (上下文是否接近阈值?)
→ LLM API Call
→ If tool call → Execute tool → Append result → Loop
→ If final text → Store session in SQLite → Deliver response总结:一套共用的 AI 核心执行引擎 AIAgent,不管是命令行、机器人、接口还是批量任务,全都走它统一处理,内置提示词、模型适配、工具调度三大模块,按固定标准化流程处理消息,兼顾缓存优化、多配置隔离、模块解耦。
3.2 Provider 抽象层
Hermes 支持 18+ LLM 提供商,通过三种 API 模式归一化:
| API 模式 | 适用提供商 |
|---|---|
chat_completions |
OpenAI, DeepSeek, 兼容端点 |
anthropic_messages |
Anthropic (原生) |
codex_responses |
GitHub Copilot, Codex |
Provider 路由:
model_routing:
default: anthropic/claude-sonnet-4-6
high_precision: anthropic/claude-opus-4-8
low_latency: deepseek/deepseek-v4-pro
fallback_providers:
- openai/gpt-5.1
- google/gemini-3-pro三层弹性架构:
| 层级 | 机制 | 作用域 |
|---|---|---|
| Credential Pools | 同一 Provider 多 API Key 轮转 | 同 Provider 内 |
| Primary Model Fallback | fallback_providers 列表自动切换 |
跨 Provider,每轮 |
| Auxiliary Task Fallback | 辅助任务独立 Provider 解析(视觉、压缩、标题生成等) | 按任务维度 |
总结:Hermes 统一兼容 18 + 大模型厂商,分三类接口做格式归一,还通过密钥轮询、跨模型兜底、任务专属模型三套机制实现高可用弹性调度。
3.3 工具注册与暴露分离
Hermes 的工具系统最关键的架构决策:注册 ≠ 暴露。
tools/registry.py ← 零依赖,被所有工具文件导入
↑
tools/*.py ← 每个文件在 import 时自注册: registry.register()
↑
model_tools.py ← 导入 registry + 触发工具发现
↑
run_agent.py, cli.py ← Agent 核心和 CLI核心机制:
# 每个工具文件自注册
registry.register(
name="example_tool",
toolset="example",
schema={"name": "example_tool", "description": "...", "parameters": {...}},
handler=lambda args, **kw: example_tool(...),
check_fn=check_requirements, # 门控函数:环境是否满足?
requires_env=["EXAMPLE_API_KEY"], # 所需环境变量
)关键设计:
- 70+ 注册工具,但模型每次只看到相关的子集
- check_fn 决定工具是否可用(API Key 是否配置?依赖是否安装?)
- 按场景(CLI / 某聊天平台 / 某 Profile)暴露不同工具组合
- 新增一个工具只需改 3 个文件:工具实现 →
model_tools.py导入 →toolsets.py注册
总结:所有工具统一注册入库,但不会全部一次性给 AI 使用,依靠门控函数、场景分组按需开放,新增工具接入流程简单。
3.4 技能系统与渐进式加载
Hermes 的技能系统实现了三级渐进式披露(Progressive Disclosure):
Tier 0: 分类名 (~50 tokens)
└─ Tier 1: 技能名 + 一行描述 (~20 tokens/skill)
└─ Tier 2: 完整 SKILL.md 内容 (~500–5,000 tokens, 按需加载)
└─ Tier 3: 附件文件 (references/, templates/, scripts/)Tier1:
作用:让模型知道 “我有哪些技能、大概能干什么”,用于意图匹配选工具,仅此而已
Tier2:
只有模型判定要使用某技能时,才调用
skill_view(name)拉取完整技能规则、入参、流程Tier3:
仅执行阶段才加载配套 API 文档、模板、案例,绝大多数对话完全不会走到这一层,几乎不增加基线开销
这意味着 200 个技能的上下文开销 ≈ 40 个技能。
技能遵循 agentskills.io 开放标准(Markdown + YAML frontmatter),跨 Agent 可移植——在 Hermes 中创建的技能可以被 Claude Code、Cursor、Copilot 等使用。
4. 四层记忆系统
Hermes 最核心的设计——将记忆按时间尺度和用途分为四个独立层:
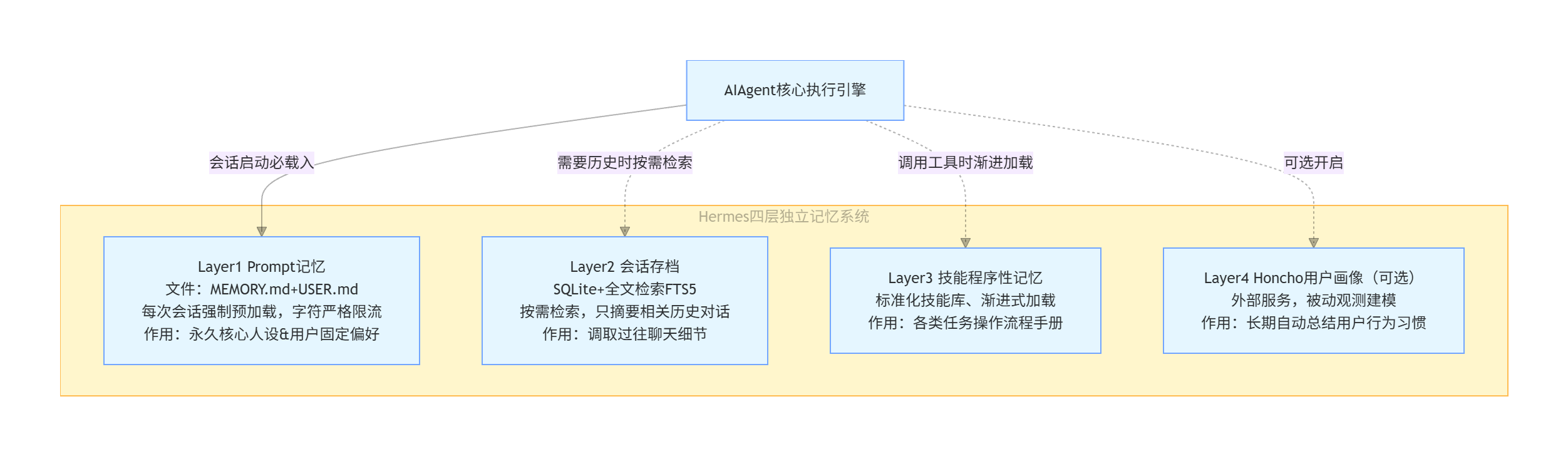
Layer 1: Prompt Memory(MEMORY.md + USER.md)
| 属性 | 详情 |
|---|---|
| 存储 | ~/.hermes/memories/ 下的扁平 Markdown 文件 |
| 加载方式 | 每次会话第一条消息前注入 system prompt |
| 容量限制 | MEMORY: 2,200 字符 / USER: 1,375 字符 / 总计: 3,575 字符 |
| 管理方式 | Agent 使用 memory 工具(add / replace / delete) |
| 生效时机 | 修改在下次会话生效(本会话内冻结,保护 prompt caching) |
强制字符限制的哲学:只让真正高价值的信息存活。
Layer 2: Session Retrieval(SQLite + FTS5)
| 属性 | 详情 |
|---|---|
| 存储 | SQLite + FTS5 全文索引 |
| 加载方式 | 按需搜索——Agent 自行判断何时需要历史上下文 |
| 处理方式 | 检索匹配对话 → LLM 生成聚焦摘要(绝不把整个旧对话倒入上下文窗口) |
关键区分:Memory 文件始终加载(持久事实);Session 存档按需搜索(特定历史上下文)。
Layer 3: Skills(程序性记忆 / 操作手册)
| 属性 | 详情 |
|---|---|
| 存储 | ~/.hermes/skills/ 下结构化 Markdown + YAML |
| 加载方式 | 渐进式披露(见 3.4 节) |
| 格式 | agentskills.io 开放标准 |
| 用途 | "怎么做"——SOP、工作流、陷阱、验证步骤 |
Layer 4: Honcho(辩证用户建模,可选)
| 属性 | 详情 |
|---|---|
| 存储 | Plastic Labs 的 Honcho 外部服务 |
| 机制 | 被动观察——跨会话构建用户画像,无需显式写入 |
| 模型 | 12 层身份模型,同时建模用户和 Agent 与用户的关系 |
| 是否必需 | 否——大多数任务型部署不需要 |
四层总结
Layer 1: Prompt Memory ← "你是谁,我喜欢什么"(始终加载,高信号) Layer 2: Session Archive ← "上次发生了什么"(按需搜索,低延迟) Layer 3: Skills ← "某任务怎么做"(渐进加载,操作手册) Layer 4: Honcho ← "你的行为模式"(被动建模,长期画像)
5. 自进化学习循环
这是 Hermes 区别于其他 Agent 框架的核心差异点。
普通 Agent:干完活就完事,不会总结经验,下次遇到同类问题还要重新摸索。
Hermes 自带自动进化闭环,不用你手动改配置、写工具,后台悄悄复盘优化,四步循环循环往复。
学习循环四机制
┌──────────────────────────────────────────────────┐
│ Self-Improving Loop │
│ │
│ ┌─────────┐ ┌──────────┐ ┌─────────┐ ┌──────┐│
│ │ Memory │ │ Skill │ │ Skill │ │Cross ││
│ │Curation │→│Generation│→│Patching │→│Session││
│ │ │ │ │ │ │ │Search ││
│ └─────────┘ └──────────┘ └─────────┘ └──────┘│
│ ↑ ↓ │
│ └──────── Nudge Engine ────────┘ │
└──────────────────────────────────────────────────┘机制 1:自主记忆策展(Memory Curation)
在会话中每隔固定间隔,Agent 收到内部系统提示,回顾最近活动并判断是否有值得永久保存的内容。无需用户干预。
每聊 10 轮,后台悄悄复盘聊天,自动挑出长期有用信息存入永久记忆(L1 MEMORY.md),没用的垃圾自动丢掉,不用你手动记录偏好、关键规则。
例:你多次强调报表要导出 Excel,它自动把这条要求永久存起来,以后不用反复提醒。
机制 2:自动技能生成(Skill Generation)
任务完成后,Agent 判断是否将此次工作流编码为可复用技能。触发条件:
- 5+ 工具调用
- 任务中恢复了错误
- 用户给出了纠正指导
- 发现了非平凡的工作流
只要单次任务满足:连续调用 5 次以上工具 / 踩坑修复过报错 / 你纠正过它的操作 / 流程复杂有复用价值,就自动把整套操作写成标准化技能存入技能库。
例:你让它批量下载表格、清洗数据、汇总图表重复操作 3 次,它自动生成一套「批量数据报表」工具,下次一键调用。
机制 3:技能自我修补(Skill Patching)
技能不会冻结——未来使用时如果发现缺失步骤、过时命令或新陷阱,Agent 会用 skill_manage(action='patch') 原地修补。这是精准的 find-and-replace,而非全量重写,既保持正确性又最小化 token 开销。
之前生成的技能不是一成不变,下次使用发现步骤漏了、命令失效、有新坑,只精准修改出错片段,不重写全部技能,省 Token、不破坏原有逻辑。
例:旧技能里某 API 地址过期,它只替换这一行地址,其余流程不动。
机制 4:跨会话搜索与 LLM 摘要
所有对话归档在 SQLite + FTS5 中。Agent 需要历史上下文时,搜索归档并用 LLM 仅总结相关内容。
所有历史对话存在数据库,复盘 / 执行任务时只检索相关历史,用大模型精简摘要,不会把几万条聊天全塞进上下文。
Nudge Engine(后台反思引擎)
记忆和技能的写入需要一个触发器——这就是 Nudge Engine:
相当于内置两个定时器,到点自动开一个隐形后台小 Agent偷偷进化:
| 计数器 | 粒度 | 默认间隔 |
|---|---|---|
| Memory Nudge | 按用户轮次计数 | 每 10 轮 |
| Skill Nudge | 按工具迭代计数 | 每 10 次迭代 |
触发时分叉一个后台 Agent 实例(独立线程):
- 输出重定向到
/dev/null(用户无感) - 最多 8 次工具调用以控制成本
- 共享主 Agent 的 Memory 存储
- 自身 Nudge 关闭防止无限递归
后台小 Agent 特点:你看不到输出、限制工具调用次数控成本、不会无限循环、和主程序共用记忆库。
闭环逻辑
跨会话检索拿到历史经验 → 触发记忆整理 → 产出新技能 → 使用中自动修补技能 → 再检索历史持续迭代,全程后台静默运行。
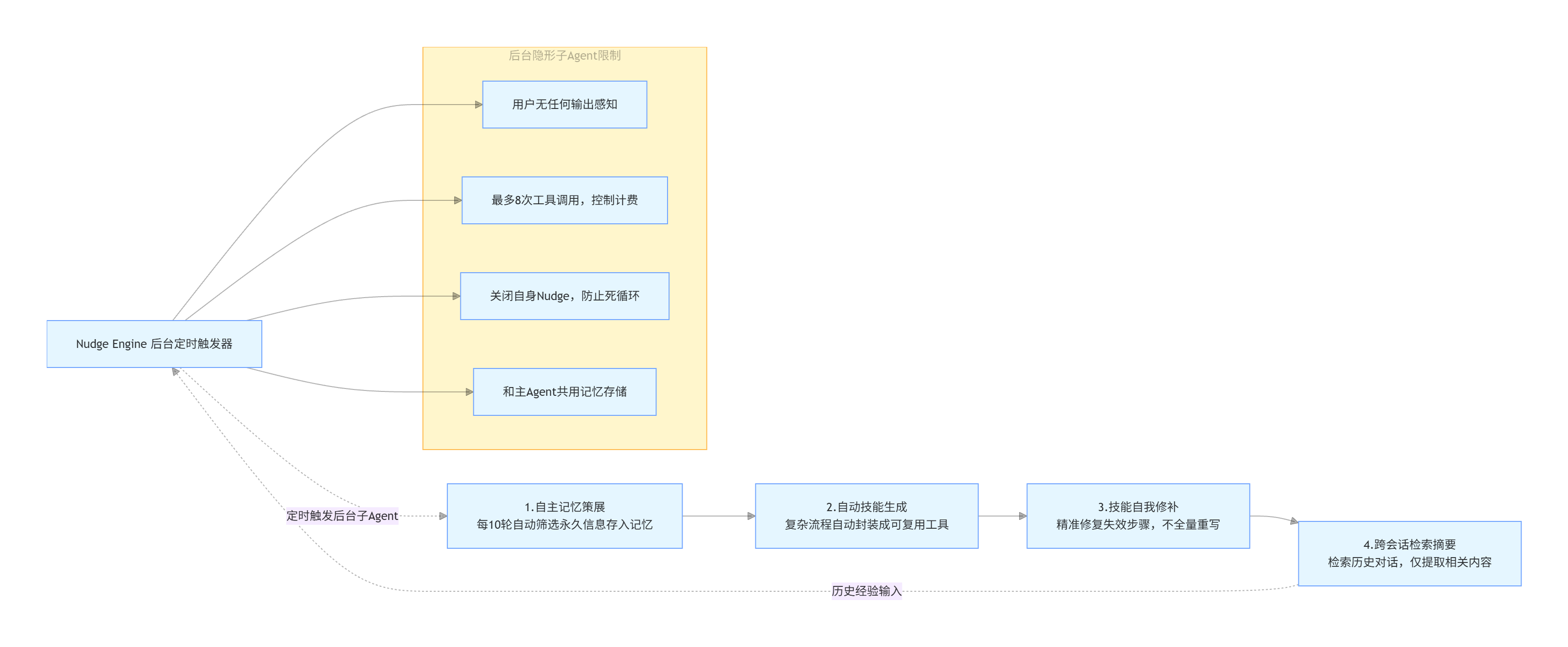
总结:
Hermes 靠定时后台反思引擎驱动一套闭环自学流程:自动沉淀长期记忆、把复杂工作流做成工具、随时修补失效技能、调取历史对话辅助优化,全程无需人工干预,越用越适配你的使用习惯。
6. 上下文压缩
对话记录相当于行李箱,模型窗口是行李箱固定容量。 行李装到一半(50%)自动走五步精简流水线,只丢没用的、保住关键内容; 万一没压好、快塞满(85%),网关还有一道兜底强制压缩,防止直接超限报错。
Hermes 实现了五阶段压缩管线(顺序不能乱),由 ContextCompressor(agent/context_compressor.py)管理:
触发标准:上下文 Token 占到模型窗口一半(50%)
触发条件: Token 使用量达到上下文窗口的 50%
│
▼
Stage 1: 工具输出裁剪(粗剪) ← 廉价预裁剪,修整冗长工具结果
| AI 查文件、联网、运行代码返回一大段原始文本,先无脑砍掉冗余换行、重复日志、无效长文本,低成本先瘦身一轮。
│
▼
Stage 2: 头部保护(不动核心规则) ← 保护关键开头上下文(身份、指令)
| 最开头的人设、任务要求、固定指令全程不动,绝不删减,保障 AI 基础逻辑不变。
│
▼
Stage 3: 尾部 Token 预算 ← 保证最近消息完整保留(compression.protect_last_n,默认 20)
| 强制保留最近 20 条聊天完整原文,最新沟通不做摘要,保证当前对话不脱节。
│
▼
Stage 4: LLM 摘要 ← 中间部分由辅助模型调用压缩摘要
| 夹在 “头部固定规则” 和 “最新聊天” 中间的老旧内容,交给小模型浓缩成简短总结,大幅省 Token。
│
▼
Stage 5: flush_memories() ← 压缩前 Agent 获得一次机会将重要信息存入 Layer 1 记忆
正式压缩清空旧内容前,AI 先自动把长期有用信息存进一层永久记忆,避免压缩把重要内容彻底删掉。
会话血统(Session Lineage): 压缩触发分裂时,新会话的 parent_session_id 链接到旧会话——在 SQLite 中保留完整历史,同时保持活跃上下文精简。
压缩会生成一段全新精简上下文,新会话会记录父会话 ID 绑定旧记录。
活跃对话是精简版方便 AI 处理,完整原始聊天全部存在数据库可回溯,不会丢失记录。
双层安全网:(错开阈值避免频繁压缩)
| 压缩器 | 触发阈值 | 位置 |
|---|---|---|
|
Agent Compressor 主Agent压缩器 |
上下文窗口的 50% | 工具循环内,精确 token 计数 |
|
Gateway Safety Net 网关兜底压缩 |
上下文窗口的 85% | Gateway 层,粗略字符估算。最后防线,防止窗口溢出报错 |
两个阈值故意错开——如果都设在 50%,会导致每次轮次都过早压缩。不会每次对话都反复压缩、浪费算力。
总结:
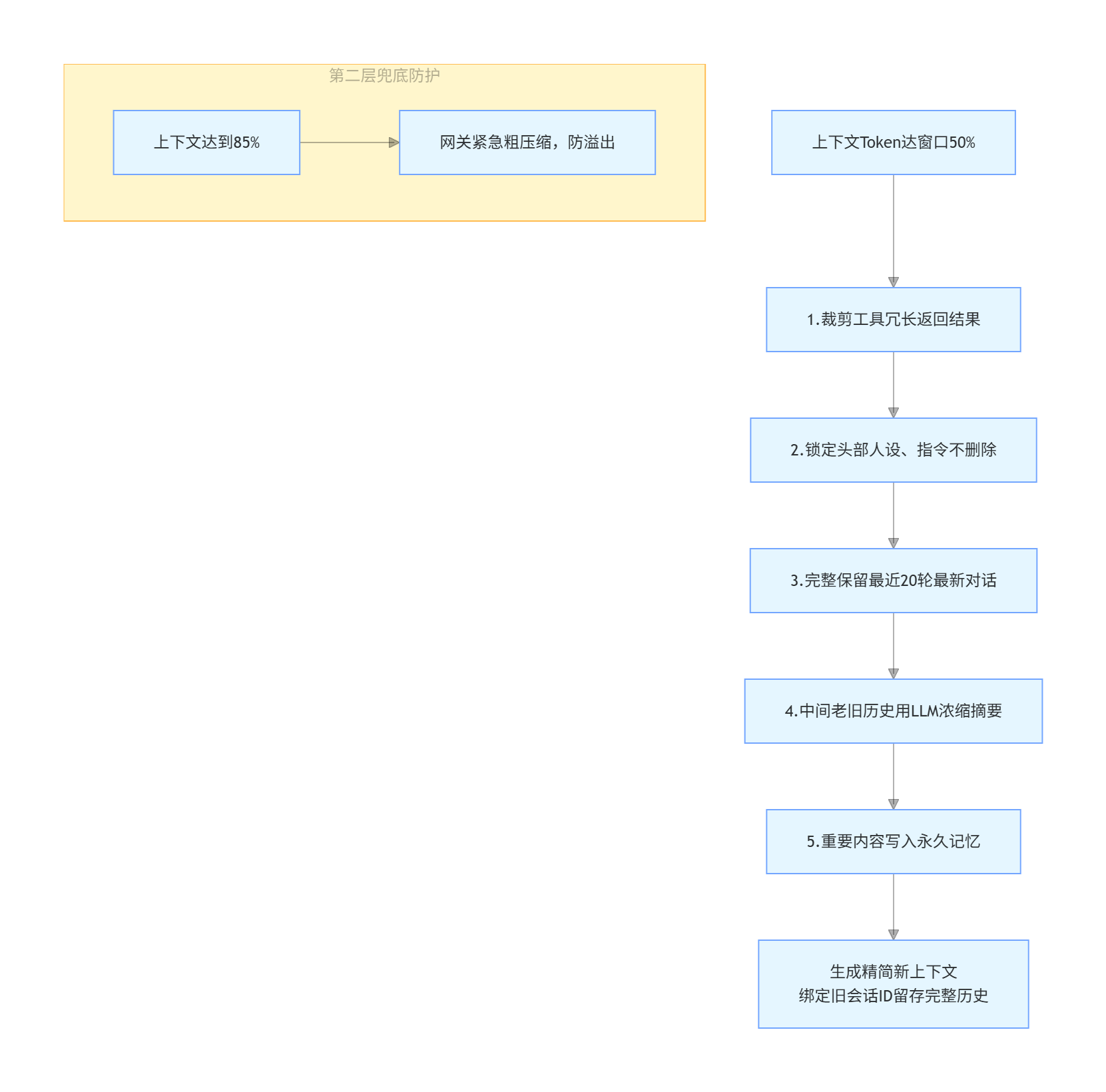
对话内容过半就启动五阶分层精简,死守开头规则、保留最新聊天、中间老内容做摘要,压缩前自动沉淀关键信息;同时设置 50%/85% 两级错开压缩阈值,既保证上下文短小好用,又不会丢失全部历史记录。
7. 会话持久化(SQLite + FTS5)
所有聊天记录、会话数据全部存在本地单个文件 state.db,不用额外装数据库服务;开启 WAL 读写分离,多人 / 多端同时访问不卡顿。
数据库位置:~/.hermes/state.db
Schema 架构
state.db (WAL mode, schema version 11)
├── sessions — 会话总表,每一轮独立对话一条记录。元数据、token 计数、计费、血统(父子会话关联、来自哪个平台-命令行/电报/Discord等)
├── messages — 完整消息历史,每一句用户提问、AI回复、工具调用原始完整内容,永久留存原始数据,不会因为上下文压缩被删掉。
├── messages_fts — 全文检索索引表,FTS5 虚拟表 (content + tool_name + tool_calls)。自动同步所有消息内容,专门用来快速搜关键词,不用全库遍历翻记录。
├── messages_fts_trigram — 中文 / 短句增强索引,FTS5 trigram 分词器 (CJK / 子串搜索)。适配中文、零散片段搜索,搜半句话、词语碎片也能匹配到结果。
├── state_meta — key/value 元数据。全局配置键值对
└── schema_version — 迁移追踪,跟踪数据库结构升级,更新 Hermes 时自动迁移数据不丢失。
核心设计决策
| 特性 | 实现 |
|---|---|
| 并发 | WAL 模式——多读一写(可以同时很多地方读聊天记录(查询、检索、前端展示);写入对话时单独排队,不会出现 “一边读一边写卡死”。) |
| 全文搜索 | FTS5 + 自动同步触发器(INSERT/UPDATE/DELETE) |
| 会话血统 | parent_session_id 链(压缩触发的分裂)----上下文压缩后会生成新会话,新记录会标注上一代会话 ID,形成完整链路。 前台 AI 只用精简后的新上下文,但后台数据库能顺着链条查到全部历史对话。 |
| 来源标记 | source 字段:cli, telegram, discord, slack... 搜索时可以只查某一个平台的聊天记录。 |
| 写竞争处理 |
1s SQLite 超时 + 应用层重试(20-150ms 随机抖动,最多 15 次)+
多线程同时保存消息容易锁库,Hermes 三层防护:
|
|
WAL Checkpoint 定时归档 |
每 50 次成功写入触发一次(PASSIVE 模式) 每成功写入 50 条消息,自动同步缓存到数据库文件,防止断电丢最近记录。 |
FTS5 搜索能力(Agent 自带搜历史工具)
- 完整 FTS5 查询语法:关键词(隐式 AND)、引号短语、
OR/NOT布尔、前缀匹配(deploy*) - 按来源平台、角色、日期范围过滤
- 返回带
>>>match<<<标记的摘录、±1 条消息上下文、会话元数据 session_search工具让 Agent 自动执行跨会话召回
- 支持标准搜索语法:精准短语引号、或 / 非逻辑、前缀模糊匹配;
- 可筛选:只查某平台、指定时间段、仅工具调用记录;
- 搜索结果高亮匹配文字,顺带带出前后相邻消息,附带会话基础信息;
- Agent 内置
session_search技能,AI 自己能主动检索几年前的历史对话,调取过往经验辅助当前任务。
总结:用单文件 SQLite 搭配中文友好全文检索存全部对话,靠 WAL、重试机制解决多端并发读写;压缩拆分的会话通过父子 ID 完整串联历史,AI 可自主跨会话关键词检索旧记录,所有原始消息永久留存不丢失。
8. Gateway 多平台网关
Gateway 就是 Hermes 的常驻后台总调度服务,开机启动后一直挂着不退出,统一对接 20 多款聊天软件,不用分开开多个程序。
Gateway 是一个守护进程(hermes gateway),保持 Agent 在所有平台上持久在线:
┌─────────────┐
│ Gateway │
│ (daemon) │
└──────┬──────┘
│
┌────────────┬───────────┼───────────┬──────────┬──────┐
▼ ▼ ▼ ▼ ▼ ▼
Telegram Discord WhatsApp Slack/Email SMS CLI/Web
支持平台(20+):Telegram, Discord, Slack, WhatsApp, Signal, Matrix, Mattermost, Email, SMS, DingTalk, 飞书/Lark, 企业微信, 微信, QQBot, LINE, SimpleX Chat, IRC, Microsoft Teams, Google Chat, Home Assistant...
关键特性:
- 跨平台对话连续性:Telegram 上开始,CLI 上继续,记忆、上下文互通,不分平台隔离对话。
- Telegram "项目主题":每个主题绑定特定技能 + 独立上下文
- 消息路由、投递、定时任务触发全部流经同一 Gateway
好比一个统一客服总后台: Telegram、飞书、企业微信、Discord、网页端、命令行全是各个客户进线渠道,所有消息、定时提醒、指令全部先发给这个网关,再统一转给底层 AIAgent 核心处理。
所有平台的消息分发、消息推送、定时任务(定时提醒、定时执行任务)都由网关统一管控,不用给每个聊天客户端单独写一套调度逻辑,一套底层 Agent 引擎对接全部渠道。
9. 权限与安全模型
Hermes 的安全哲学与 Claude Code 不同——它明确声明:保护操作者免受 LLM 行为影响,但不防御恶意共驻者(co-tenant)。
| 安全机制 | 实现 |
|---|---|
| 智能审批 | 学习哪些命令是安全的,自动批准已知安全模式 |
| PII 脱敏 | 输出中自动检测和脱敏个人信息 |
| 密钥脱敏 | API Key、Token、数据库密码自动遮蔽 |
| 危险命令检测 | rm -rf /、chmod 777 等默认阻断 |
/stop 中断 |
随时中断 Agent 执行 |
| DM 配对授权 | 消息平台上的 DM 访问需要配对确认 |
| 5 层防御模式 | 记忆威胁扫描、上下文注入扫描、OSV 恶意软件检查、凭证剥离、结构化上下文压缩 |
10. 与Claude Code Harness对比
这是理解两种 Harness 哲学的关键:
| 维度 | Claude Code | Hermes Agent |
|---|---|---|
| 核心关注 | 权限系统 + 上下文管理 | Agent Loop 密度 + 多平台消息 |
| 语言 | TypeScript(CLI-first) | Python(多平台 Agent) |
| 模型锁 | Claude only | 任意模型(200+ via Provider 适配器) |
| 开源 | 否(专有) | 是(MIT License, 96K+ Stars) |
| 设计赌注 |
Harness 应该做减法——模型变强就移除脚手架 认为大模型能力会越来越强,现在加的复杂配套功能以后都能删掉;脚手架只是临时补丁。 |
Harness 应该做加法——随时间积累经验、技能、记忆 就算模型再厉害,它也记不住你几个月前的需求、不会自动沉淀工作流程,所以要永久配套记忆、技能、历史检索整套底座,长期持续积累经验。 |
上下文压缩对比
| Claude Code | Hermes | |
|---|---|---|
| 方式 | 服务端 Compaction API(单参数,完全托管) | 客户端五阶段管线(精确控制) |
| 触发 | 达到 Token 阈值,API 自动压缩 | Agent 50% + Gateway 85% 双层触发 |
| 可控性 | 低——压缩块不透明 | 高——结构化模板,可追踪 Resolved/In Progress/Pending |
| 哲学 | 简单优先 | 控制优先 |
Claude Code
- 压缩交给 Anthropic 服务端黑盒 API,你只能设一个阈值,内部怎么精简看不到、改不了
- 到 token 上限自动压缩,人无法干预细节
- 追求简单省事,牺牲自定义控制能力
Hermes
- 本地五层自定义压缩流水线,每一步逻辑完全透明可改
- 双保险:AI 运行到 50% 容量先精细压缩;网关 85% 紧急兜底,防止溢出报错
- 能查看每段内容状态(已归档 / 待压缩 / 使用中),精细化管控上下文内容
记忆系统对比
| Claude Code | Hermes | |
|---|---|---|
| 方式 | 文件驱动、模型驱动 | 分层、系统驱动 |
| 主存储 | CLAUDE.md + MEMORY.md(max 200 行, 25KB) |
SQLite + FTS5 + 8 个外部 Provider 插件 |
| 检索 | 文件加载到 System Prompt——模型"全看" | Prefetch-inject 循环:先搜索后预加载 |
| 跨会话 | 有限——完全依赖 CLAUDE.md 质量 | 深度——会话血统、父子压缩链、session_search 工具 |
| 哲学 | "模型够聪明——给它文件就行" | "模型需要帮助在多个时间尺度上积累" |
Claude Code
- 极简文件记忆,只有两个 md 文件,严格限制行数大小
- 每次对话直接把文件全文塞进提示词,模型一次性读完
- 跨会话记忆很弱,只能靠手动写文件留存信息,没法自动检索历史对话
- 逻辑:模型足够聪明,把文档丢给它自己看懂就行
Hermes
- 四层分级记忆体系 + SQLite 带全文检索数据库,完整保存全部聊天记录
- 不会一次性灌入所有历史,先检索匹配相关内容,再摘要注入上下文
- 支持会话父子链路,压缩拆分的对话完整溯源,AI 能主动调用工具搜索几个月前的跨会话历史
- 逻辑:人脑都没法记住所有往事,模型也需要专门存储、检索、摘要系统辅助调取长期信息
架构哲学的根本分歧
- Claude Code:把对模型局限性的假设编码进 Harness,模型变强后移除这些功能。(如 Opus 4.6 移除了 "Sprint" 机制)
- Hermes:建造不随模型变强而过期的东西——记忆层、技能文件、跨会话搜索、用户建模。"模型会变强,但它仍然需要知道你上周问了什么。"
11. 11个Harness设计模式
业界从 Claude Code 和 Hermes 两个代码库中提炼出 15 个通用 Harness 设计模式:
| # | 模式 | 核心思想 |
|---|---|---|
| 1 | The Harness Paradigm | 模型本身不是产品——需要编排层 |
| 2 | Tool Architecture & Tool Contract | 推理与执行后果之间的边界设计 |
| 3 | The Query/Agent Loop | 模型 tool call 与下一轮之间发生了什么 |
| 4 | Permission Systems & Safety Guardrails | 对破坏性操作的门控 |
| 5 | Tool Orchestration & Execution | 安全操作与串行操作的分区 |
| 6 | Context Management at Scale | 压缩前的五种策略 |
| 7 | Multi-Agent Coordination | 一个 Agent 不够时的协调模式 |
| 8 | Memory Systems & State Persistence | 三层记忆,一种缓存 |
| 9 | Observability & Debugging | 非确定性系统的分布式追踪 |
| 10 | Production Deployment Patterns | SDK-first vs Gateway-first |
| 11 | Hook/Event-Driven Automation | Loop 之上的自动化层 |
| 12 | The Skill System Pattern | 能力即内容,而非代码 |
| 13 | MCP Integration | 将 Agent 连接到世界 |
| 14 | Model Routing & Provider Abstraction | 失败时优雅降级 |
| 15 | Structured Output & Schema-Constrained Generation | 当自由文本不够时 |
总结
Hermes 的核心创新
| 创新点 | 说明 |
|---|---|
| 自进化能力 | Agent 从经验中学习,自动生成和改进技能——不是每次从零开始 |
| 四层记忆 | 按时间尺度和用途分层的记忆架构,让 Agent 既有"常识"也有"经验" |
| 注册与暴露分离 | 70+ 工具注册但按需暴露,不浪费上下文窗口 |
| 渐进式技能加载 | 200 个技能的上下文开销等于 40 个——只在需要时才加载完整内容 |
| Provider 无关 | 18+ LLM Provider,三层弹性 fallback,不被任何一家锁定 |
| 多平台统一 | CLI、Telegram、Discord、Slack...同一 Agent 跨平台服务 |
| 会话即基础设施 | SQLite + FTS5 + WAL + 会话血统——把会话当作一等公民的基础设施 |
越来越多的生产实践采用 Hermes(编排)+ Claude Code(编码) 的双栈模式:
- Hermes 作为持久编排层:管理会话、记忆、多平台接入、定时任务
- Claude Code 作为专业编码执行器:通过 MCP 桥接,处理复杂代码任务
- 两者互补——Hermes 提供"永远不会忘记"的持久性,Claude Code 提供最顶级的代码智能


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)