调查研究-205 Unlimited-OCR 深度解析:OCR 正在从“逐页识别“走向“一次性长文档解析“
Unlimited-OCR 深度解析:OCR 正在从"逐页识别"走向"一次性长文档解析"
TL;DR
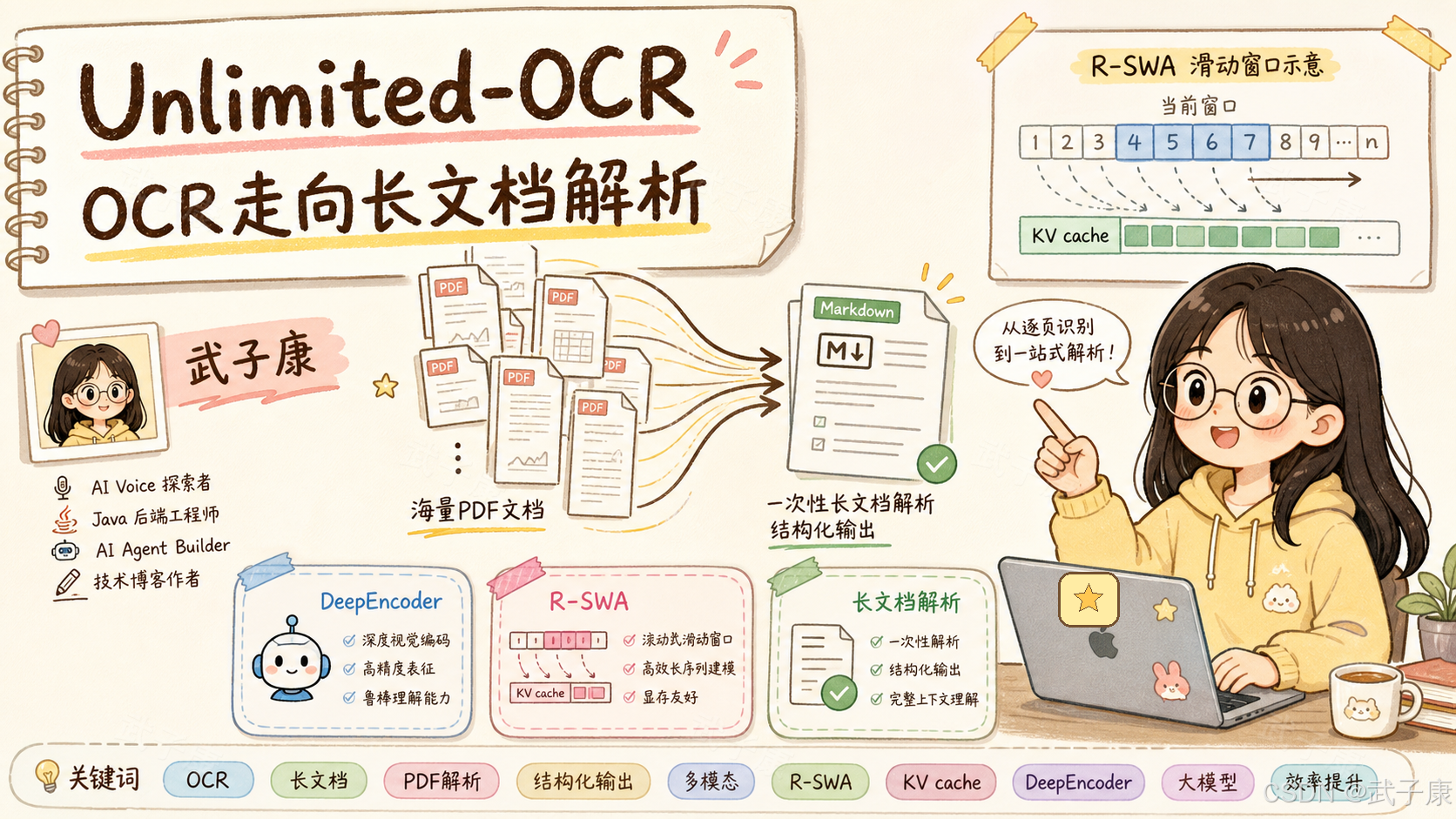
- 场景:长 PDF 一次性解析、复杂版面文档转 Markdown、企业知识库与 RAG 入库。Unlimited-OCR(百度 2026 年 6 月 22 日发布、6 月 25 日开源)瞄准 OCR 从"单页识别"转向"长时域连续解析"。
- 结论:核心是 R-SWA(Reference Sliding Window Attention)——把 decoder 的 KV cache 从线性增长压成常数,模型始终看得见视觉参考区和 Prompt,只保留最近一段输出窗口。
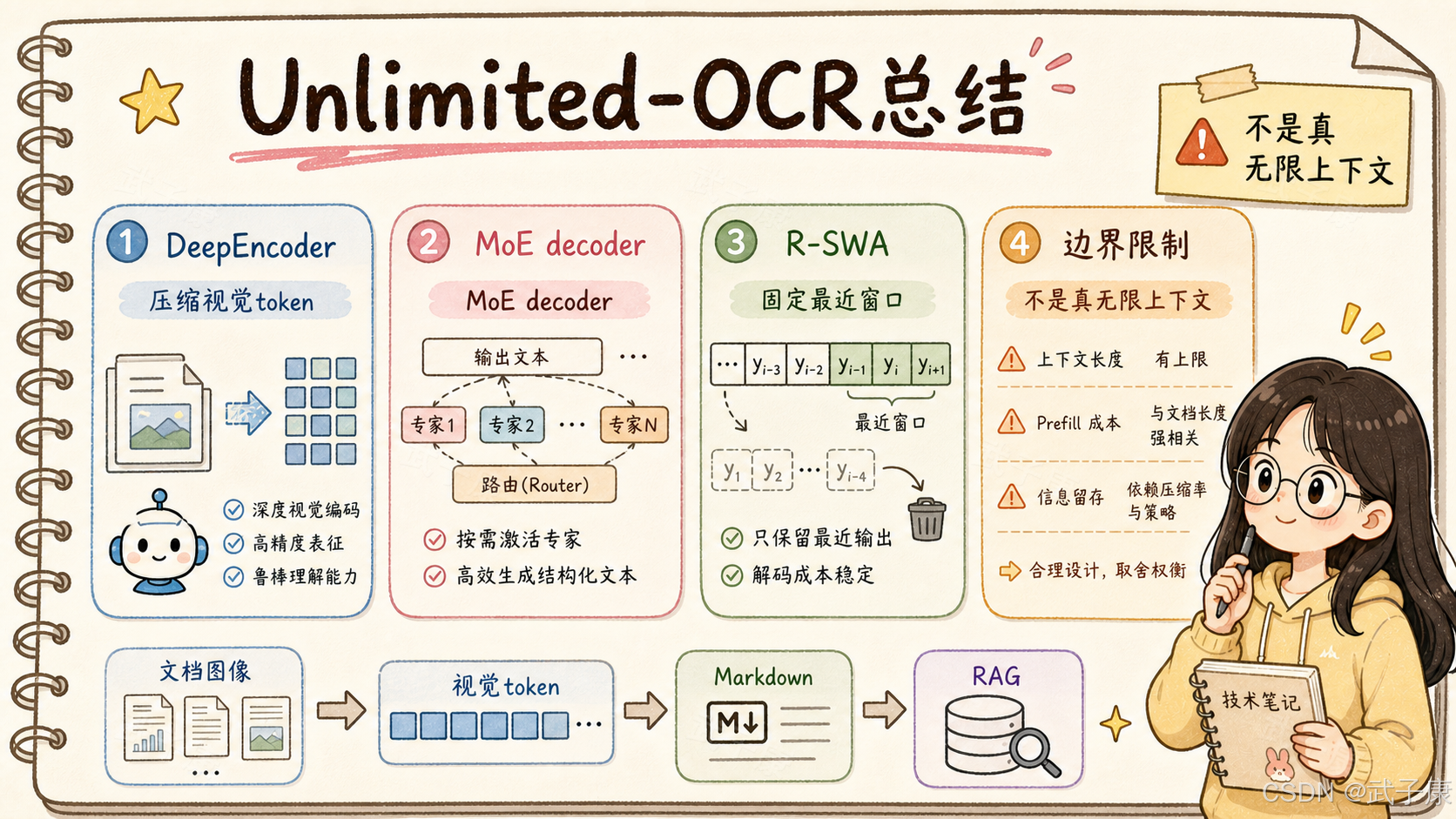
- 产出:3B 总参数 / 激活约 570M 的 MoE 解码器 + DeepEncoder 高压缩视觉编码,OmniDocBench v1.6 综合分 93.92%,端到端 SOTA,单次前向可解析 40+ 页 PDF,速度较 DeepSeek-OCR 提升约 35%。
版本矩阵
| 功能 | 状态 | 说明 |
|---|---|---|
| 基于 DeepSeek-OCR 架构改造 | ✅ 已验证 | 延续 DeepEncoder + MoE decoder 组合 |
| R-SWA(Reference Sliding Window Attention) | ✅ 已验证 | 把 decoder KV cache 从线性增长压成常数 |
| 总参数 3B / 激活约 570M | ✅ 已验证 | MoE 结构,BF16 权重 |
| DeepEncoder 视觉压缩 1024×1024 → 256 token | ✅ 已验证 | 16× 压缩,单页 base 模式 |
| OmniDocBench v1.6 综合分 93.92% | ✅ 已验证 | 端到端 SOTA |
| 单次前向解析 40+ 页 PDF | ✅ 已验证 | 多页连续解析能力 |
| 速度较 DeepSeek-OCR 提升 ~35% | ✅ 已验证 | long-horizon OCR 评测 |
| Transformers + SGLang 双推理后端 | ✅ 已验证 | HuggingFace 标准接口 + 服务化部署 |
| “Unlimited” = 真无限上下文 | ❌ 误解 | 仍受 context length / prefill 长度约束 |
| 适合强监管票据/合同字段抽取 | ⚠️ 待验证 | 推荐 pipeline + 模型校验混合方案 |
| 128K 上下文训练版本 | ⚠️ 待验证 | 报告披露的未来方向,尚未发布 |
TL;DR
Unlimited-OCR 值得关注的地方,不是它又把 OCR 做成了一个更大的视觉语言模型,而是它把问题从"单页能不能识别"推进到了"长文档能不能连续、稳定、高效地解析"。
它基于 DeepSeek-OCR 继续改造,保留 DeepEncoder 对文档图像的高压缩能力,同时把 decoder 里的标准注意力替换为 R-SWA,也就是 Reference Sliding Window Attention。简单说,模型生成结果时始终能看见原始参考区,也就是视觉 token 和 prompt,但只保留最近一段输出历史,而不是把已经生成的全部 token 都放进 KV cache。
这让 Unlimited-OCR 更适合 OCR 这种 reference-based parsing 任务:文档本身一直在那里,模型不一定需要记住所有已经抄过的内容,只要持续看参考材料、保留最近上下文、继续向前解析。
1. OCR 的老问题:不是"不认识字",而是"读不完整"
过去我们提到 OCR,很容易把它理解成"图片转文字"。
给它一张图片,它识别文字;给它一页 PDF,它输出 Markdown;给它一张表格,它尽量还原行列结构。这个理解没有错,但它更像单页工具的视角。
真实业务里的文档往往不是一张孤立图片。
一份合同可能有几十页,一份研报可能有上百页,一篇论文里有正文、脚注、公式、表格、图片、跨页引用。扫描件还可能有歪斜、阴影、低分辨率、小字体、压缩噪声和复杂水印。
真正困难的不是"某一页能不能认出来",而是:
整份文档能不能一次性读完?
跨页结构能不能保持连续?
表格、公式、标题层级、阅读顺序能不能稳定输出?
长文档解析时,速度会不会越跑越慢?
显存会不会随着输出越来越长被 KV cache 撑爆?
Unlimited-OCR 正是朝这个问题去的。
它不是又一个普通 OCR 模型,而是一次针对"长时域文档解析"的 decoder 结构改造。
2. 为什么 LLM 做 OCR 会遇到长输出瓶颈
端到端 OCR 的基本流程可以理解成:
文档图片输入
视觉编码器压缩成视觉 token
LLM decoder 逐 token 生成文字、表格、公式、阅读顺序和 Markdown
传统 OCR 常常是多阶段 pipeline:版面检测、文本检测、文本识别、表格结构识别、公式识别、阅读顺序恢复、后处理。端到端 OCR 则把这些任务统一到视觉语言模型里,直接从图像生成结构化文本。
但问题出在 decoder。
LLM 自回归生成时,会保存历史 token 的 Key / Value,也就是 KV cache。这样生成下一个 token 时,不需要每一步都重新计算全部历史内容。
对于普通对话,这不是大问题,因为输出可能只有几百到几千 token。
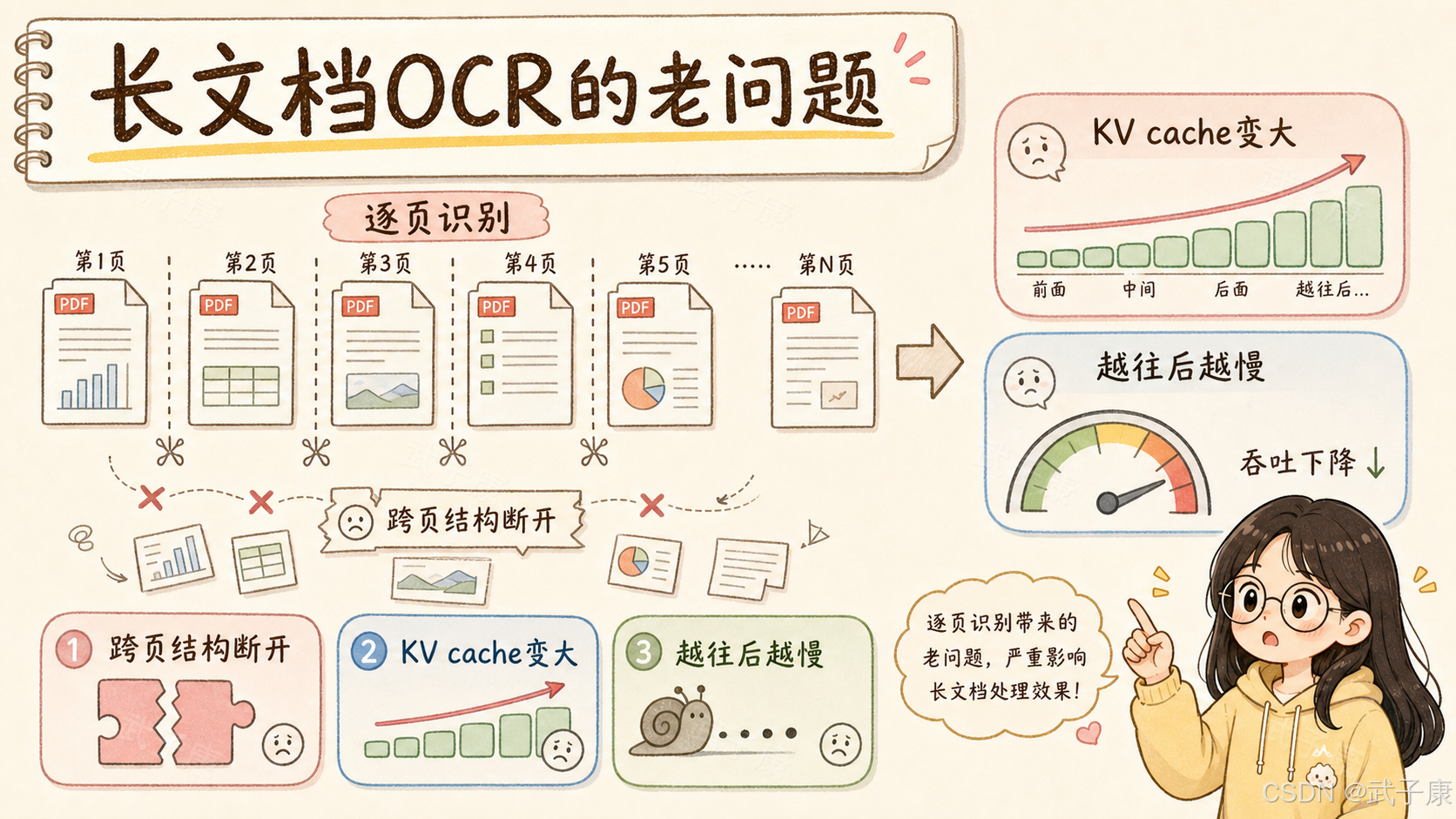
但 OCR 是一种很典型的"拷贝型长输出任务"。一份长 PDF 可能需要输出几万甚至十几万 token。文档越长,输出越长,KV cache 越大,显存占用越高,注意力计算也越来越重。
在标准注意力下,decode 阶段的 KV cache 基本会随着输出长度线性增长,于是会出现一个很反直觉的问题:
模型刚开始解析很快,越往后越慢。
短文档表现不错,长文档显存和延迟开始失控。
把每页拆开单独 OCR,又容易丢失跨页上下文。
所以长文档 OCR 的核心瓶颈,不只是识别精度,而是长输出过程中的推理机制。
3. Unlimited-OCR 的核心思想:像人类抄书一样工作
Unlimited-OCR 技术报告里用了一个很直观的类比:人类抄书。
一个人抄一本书时,并不会把自己已经抄过的全部内容都牢牢记在脑子里。真正需要关注的东西大概只有三类:
原文在哪里
刚刚抄到哪里
下一小段要抄什么
换句话说,人类做长文本抄写时,并不是依赖"完整历史记忆",而是依赖"原始参考材料 + 最近工作记忆 + 当前进度"。
Unlimited-OCR 的 R-SWA 就是把这个思路放进注意力机制里。
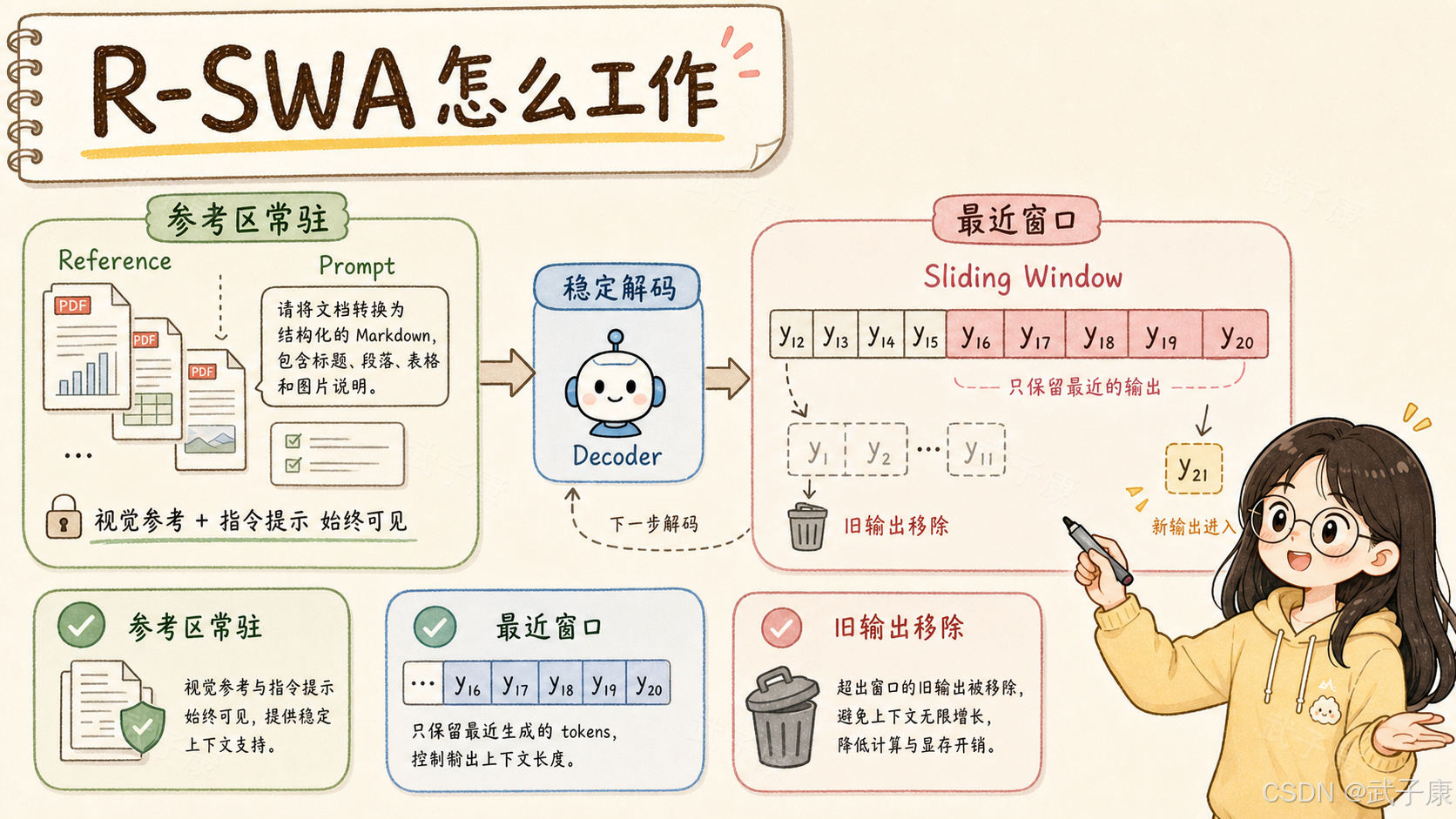
R-SWA 的全称是 Reference Sliding Window Attention。
它让每个新生成的 token 始终能看到参考区,也就是视觉 token 和 prompt;同时只看最近一小段已经生成的输出 token,而不是看全部历史输出。
可以把它拆成三部分:
Reference:一直保留的参考信息
Sliding Window:只保留最近输出窗口
Attention:生成下一个 token 时可以关注哪些 token
标准 decoder 更像这样:
生成第 100 个 token:看输入 + 前 99 个输出 token
生成第 10000 个 token:看输入 + 前 9999 个输出 token
R-SWA 改成:
每一步都能看完整参考区
每一步只看最近 n 个输出 token
更早输出从工作记忆中移除
因此,模型不是"不记得文档",而是一直看着原始文档;它只是不会把所有已经输出过的文字都塞进 decoder 的工作记忆。
这对 OCR 很合理。
OCR 大多数时候不是自由创作,而是根据图像逐段转写。模型真正需要的是源文档和最近上下文,而不是完整历史生成文本。
4. 为什么它适合 OCR,但不是通用记忆方案
R-SWA 成立有一个前提:任务有稳定的外部参考源。
OCR 有文档图像,ASR 有音频,翻译有原文。这些任务都可以看成 reference-based parsing,也就是"基于参考内容做连续解析"。模型只要能持续访问参考材料,并保留最近输出,就可以继续向前推进。
但小说创作、复杂推理、多轮规划、代码生成往往需要长程依赖。前面很远的设定、变量、约束和推理链条,可能影响后面输出。如果只保留最近窗口,就可能丢掉全局一致性。
所以 R-SWA 的结论不是"所有 LLM 都应该这么做",而是:它很适合 OCR、ASR、翻译这类有外部参考源、输出主要跟随输入推进的任务。
5. 架构:DeepEncoder + 带 R-SWA 的 MoE decoder
Unlimited-OCR 由两部分组成。
第一部分是 DeepEncoder。
第二部分是带 R-SWA 的 MoE LLM decoder。
DeepEncoder 来自 DeepSeek-OCR。它的作用是把高分辨率文档图像压缩成较少的视觉 token。技术报告中提到,DeepEncoder 可以把 1024 x 1024 的 PDF 页面图像压缩到 256 个 token。
这很关键。
如果视觉 token 太多,长文档还没开始输出,prefill 阶段就会被输入 token 撑爆。OCR 模型要处理多页文档,第一步必须先把页面图像压缩得足够狠,同时还不能丢掉文字细节。
第二部分是 MoE LLM decoder。报告中描述的 Unlimited-OCR 采用 3B 总参数、约 500M 激活参数的 MoE 结构。MoE 的好处是模型总容量可以较大,但每次推理只激活部分专家,从而控制实际计算量。
真正的核心改动在 decoder:把标准 Multi-Head Attention 替换成 R-SWA。
这让 decode 侧 KV cache 不再随着长输出持续增长。
6. “Unlimited” 不是无限上下文,而是固定 decode 成本
Unlimited-OCR 这个名字容易让人误解。
它不是说模型真的可以无限页、无限 token、无限上下文。
技术报告里也明确讨论了这个边界:当前模型仍然受 context length 和 prefill 长度限制。页面越多,视觉 token 仍然会累积,输入阶段仍然会越来越长。
所以 “Unlimited” 更准确的含义是:
在给定输入已经放进上下文后,
输出过程不会因为生成越来越长而持续增加 decode 侧 KV cache。
长文档 OCR 可以拆成两个阶段:
prefill:把文档图像编码后放进模型
decode:逐 token 输出识别结果
Unlimited-OCR 主要解决的是 decode 阶段问题,而不是彻底消灭所有长上下文问题。
如果输入是几百页扫描件,prefill 本身仍然可能成为瓶颈。报告里也提到,未来方向包括训练更长上下文版本,比如 128K,以及构建 prefill pool,让模型自动获取需要的 reference KV chunk,模拟人类翻页。
这说明它更像是长文档 OCR 的关键一步,而不是最终形态。
7. 效果:长文档更稳,也没有放弃单页能力
从论文和项目材料看,Unlimited-OCR 的评估重点不是单纯刷单页 OCR 分数,而是证明 R-SWA 对长输出有实际帮助。
报告中给出了 OmniDocBench v1.5、v1.6 等基准结果,也给出了覆盖 2、5、10、15、20、40+ 页的 long-horizon OCR 测试。重点不是单页刷分,而是长输出时能否保持连续解析能力。
效率上,报告也展示了一个很符合预期的趋势:
短输出时,R-SWA 的优势不一定夸张。
输出越长,标准 attention 的 decode 成本越容易下滑。
R-SWA 因为只保留固定输出窗口,吞吐更稳定。
这就是 Unlimited-OCR 真正想证明的点:当文档变长、输出变长时,模型不会被越来越长的历史输出拖垮。
8. 和传统 OCR pipeline 的区别
传统 OCR pipeline 更像工厂流水线:
版面检测
文本框检测
文字识别
表格结构识别
公式识别
阅读顺序恢复
Markdown / JSON 后处理
这种方式可控、可调、可解释,适合生产系统。缺点是链路长、模块多,复杂版面和跨页结构会让误差不断传递。
Unlimited-OCR 代表的是端到端文档智能路线。
它直接从图像生成结构化文本,把布局理解、文字识别、阅读顺序、表格和公式处理统一进一个模型。
优势是简单、统一、上限高;劣势是可控性弱、错误定位难、工程稳定性仍要验证。
所以实际生产选型不能简单说"端到端一定替代 pipeline"。
更合理的判断是:
复杂文档解析、长 PDF 转 Markdown、多页连续阅读:
端到端 OCR 会越来越强。
强监管、强字段校验、强可解释的票据、合同、财务系统:
pipeline + 模型校验仍然有价值。
未来主流形态很可能是混合式:端到端模型负责主解析,传统 OCR / layout / rule engine 负责校验、纠错和结构约束。
9. 工程部署:更像模型工程组件,不是开箱即用小工具
从开源资料看,Unlimited-OCR 支持 Transformers 推理,也提供了 SGLang 相关部署方式。
Transformers 方式适合研究、单机测试和快速验证。它通过 AutoTokenizer、AutoModel 加载模型,调用 model.infer 处理单图,调用 model.infer_multi 处理多页图像或 PDF 转图片后的输入。
单图推理有两类配置:
Gundam:base_size=1024, image_size=640, crop_mode=True
Base:base_size=1024, image_size=1024, crop_mode=False
多页 / PDF 场景使用 Base 模式,也就是 image_size=1024。
PDF 本身需要先用 PyMuPDF 转成图片,再输入 infer_multi。
SGLang 方式更偏服务化,README 中给了 launch server 示例,包括 --attention-backend fa3、--context-length 32768、--enable-custom-logit-processor 等参数。
这说明 Unlimited-OCR 目前不是一个"pip install 后直接生产可用"的简单工具,更像适合模型工程团队二次封装的开源模型组件。
10. 适合哪些场景
更适合它的场景有五类:
长 PDF 转 Markdown
复杂版面文档解析
OCR + RAG 文档入库
企业知识库和私有文档处理
多页连续信息抽取
核心判断很简单:只要任务需要跨页连续阅读,它就比"逐页 OCR + 拼接"更值得评估。
11. 不适合哪些场景
Unlimited-OCR 也不是所有 OCR 场景的最优解。
不适合它的场景也很明确:
超轻量边缘设备
验证码、单行文本、车牌、快递单号
发票、票据、合同字段等强结构抽取
模糊、小字、压缩、倾斜、遮挡、手写扫描件
任意超长 PDF 无脑一次性输入
所以它不是万能 OCR,而是长文档解析方向上的一个强信号。
12. 对 RAG 和 AI Infra 的启发
Unlimited-OCR 的价值不只在 OCR。它给了一个更通用的思路:对于有参考源的长时域任务,不一定要让 decoder 记住全部历史。
传统长上下文优化常常围绕"如何让模型看更多 token"展开。Unlimited-OCR 换了个角度:如果任务本身有稳定参考源,模型可以一直看参考源,只保留最近工作记忆。
对 RAG 系统来说,它也提醒我们:很多时候检索效果差,不是因为向量库不够高级,而是因为入库前的文档解析就已经坏了。
一个更可靠的文档入库链路应该是:
PDF / 图片输入
OCR / 文档解析模型输出 Markdown、表格、公式、阅读顺序和页标记
结构化清洗,保留页码、坐标、标题层级
按语义结构 chunk,而不是固定字数切分
embedding + sparse index + rerank
回答时回溯原始页面区域
在这个链路里,Unlimited-OCR 负责第一层:把不可控的视觉文档变成尽可能可靠的结构化文本。这一层越好,后面的 RAG 才越有意义。
13. 生产落地建议
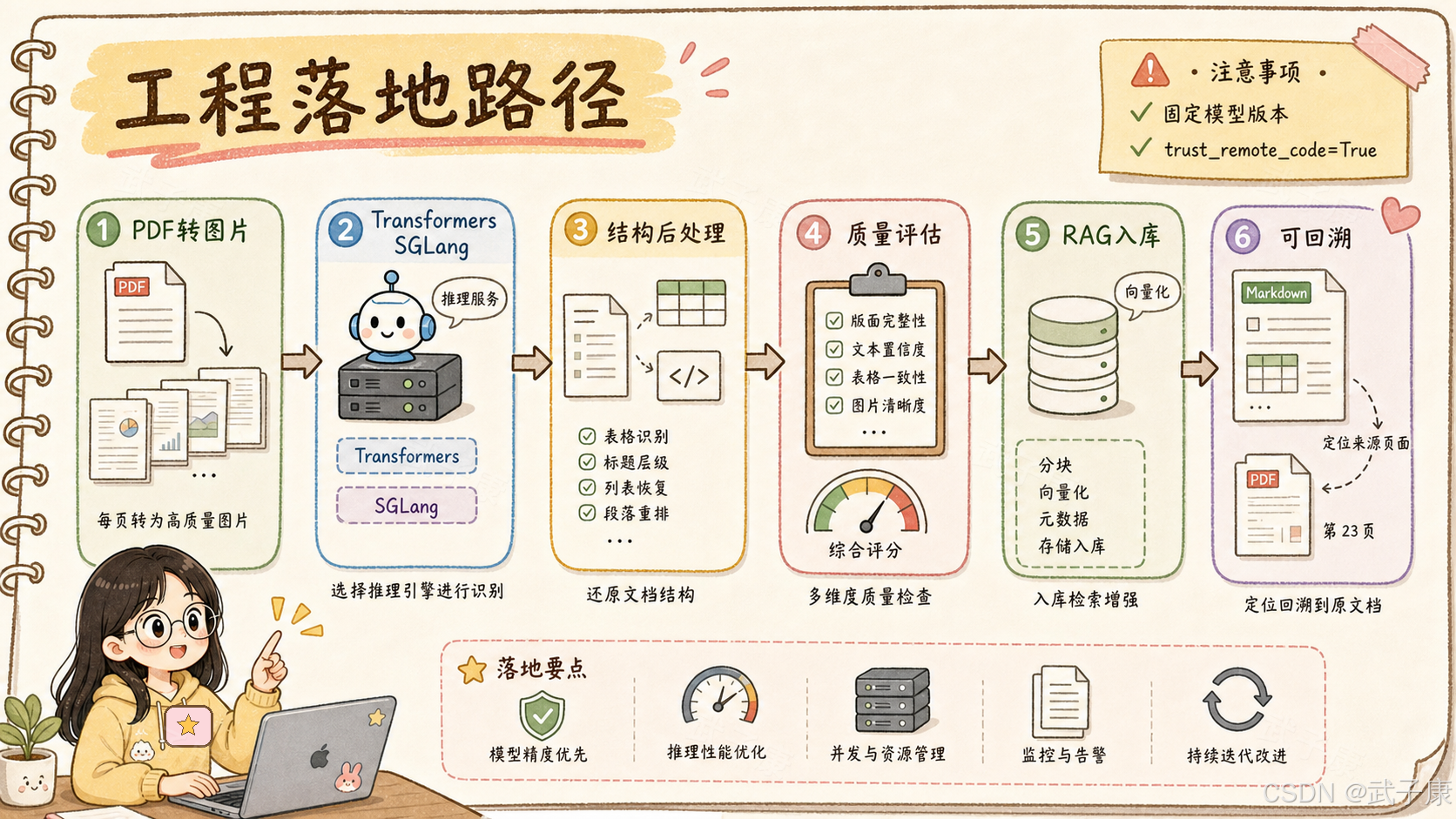
如果要把 Unlimited-OCR 放进生产系统,建议不要直接裸用模型输出。
更合理的链路是:文件预处理、模型解析、结构后处理、质量评估、入库、回溯。
文件预处理处理 PDF 转图片、DPI、旋转、空白页和损坏页;结构后处理恢复页码、修复表格、提取标题层级;质量评估覆盖空页率、重复率、乱码率和页码连续性;入库时保留 Markdown、表格 JSON、图片区域和原 PDF 页码;回答时必须能回溯到原始页面。
部署时还要固定模型 commit,审查 trust_remote_code,控制 CUDA / PyTorch / Transformers / SGLang 版本,并压测 DPI、显存、页数和重复输出。
14. 总结
Unlimited-OCR 可以用一句话概括:
它是在 DeepSeek-OCR 基础上,
通过 R-SWA 改造 decoder 注意力机制,
让端到端 OCR 模型更适合一次性长文档解析。
它解决的核心不是"图片里某个字认不认得",而是"几十页文档能不能连续、稳定、高效地解析"。
它的关键技术点有三个:
DeepEncoder:高压缩视觉 token,让多页文档输入更可承受。
MoE LLM decoder:保留生成和结构化能力,同时控制激活参数。
R-SWA:让 decode 侧 KV cache 不随生成长度线性增长。
它的限制也很明确:
仍受 context length 和 prefill 长度约束。
低质量小字扫描件仍然敏感。
需要工程后处理、质量评估和生产级部署封装。
但从趋势看,Unlimited-OCR 代表了 OCR 的一个新方向:从 pipeline OCR 走向端到端文档解析,从逐页处理走向长时域解析,从"识别文字"走向"理解文档结构"。
错误速查卡
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| 长 PDF 解析到后面越来越慢,吞吐下降到不可用 | 标准 attention 的 KV cache 随输出长度线性增长,长输出场景下显存与算力被输出历史拖垮 | 监控 GPU 显存曲线与 decode 阶段 token/s,确认是否随输出长度单调下降;对照 long-horizon OCR 评测中的 throughput 曲线 | 切换到 Unlimited-OCR(R-SWA)或同类固定输出窗口方案;评估是否需要拆分 PDF、缩短单次输入 |
| 单页 OCR 准确率还不错,但整份 PDF 拼起来跨页结构全乱了 | 把每页拆开单独 OCR 再拼接,丢失跨页标题、阅读顺序、表格延续与跨页引用 | 抽取跨页场景样本(如跨页表格、跨页公式、跨页章节标题),人工核对拼接结果是否结构连贯 | 改为 Unlimited-OCR 这类一次性长时域解析方案,或在拼接层引入版面/语义连续性后处理 |
| 短文本/单行 OCR(验证码、车牌、快递单号)效果差或过度慢 | Unlimited-OCR 是面向长文档的端到端方案,需要复杂 pipeline 和较高推理成本,不适合极轻量短文本场景 | 看输入是否只是单字段短文本,且对延迟/成本极敏感 | 切回专用轻量 OCR(如 PaddleOCR、Tesseract、按字段裁剪的小模型),端到端长文档模型不放在该链路 |
| 显存没有爆炸,但 decode 仍有异常停顿或 OOM | prefill 阶段视觉 token 累积过多,或 SGLang --context-length 与实际输入不匹配 |
打印 prefill 长度、检查 attention-backend 与 context-length 配置、复现单页 token 数 |
控制单次输入页数;按需调高或拆分 context;模型侧等待更长上下文训练版本(如 128K 方向)落地 |
接入 HuggingFace Transformers 后报 trust_remote_code 相关错误 |
Unlimited-OCR 自定义 DeepEncoder/R-SWA 实现,需 trust_remote_code=True 才能加载 |
检查加载日志是否提示需要信任远端代码 | AutoModel.from_pretrained(..., trust_remote_code=True);生产侧固定 commit、审计代码后再启用 |
| OCR 输出缺少页码、表格结构、图注等结构信息 | 直出模型 Markdown 未做结构后处理,跨页内容会丢页码、表格、坐标 | 对照原始 PDF 核查结构后处理是否覆盖页码标记、表格 JSON、图注 | 加入结构后处理:恢复页码、提取标题层级、表格转 HTML/JSON;入库按语义结构 chunk 而非固定字数切分 |
| 端到端 OCR 出错后无法定位、不能回溯到原始页面 | 模型直接生成结构化文本,缺少位置/页码锚点 | 在 RAG 回答链路中尝试回溯原始页码,看是否能定位 | 入库阶段为每段文本附带原 PDF 页码、坐标、图片区域;回答侧强制要求返回页码锚点,无法定位时拒答 |
| 把 Unlimited-OCR 当成"无限上下文",几百页 PDF 一次输入 | prefill 阶段视觉 token 随页数线性累积,超过 context length 后处理失败 | 看 prefill 长度与 context-length 配置、复现是否 OOM 或截断 |
控制单次输入页数(如 40+ 页一档);等更长上下文版本(128K 方向)落地;结合 prefill pool + 翻页策略 |
| SGLang 启动后解码报错或吞吐异常低 | --attention-backend 未指定 FA3、或与 R-SWA 不兼容 |
检查 launch server 日志与 attention backend 配置 | 按 README 指定 --attention-backend fa3 并保证硬件支持,必要时回退 Transformers 推理 |
作者:武子康的个人博客

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 3
3 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)