AI API 429 怎么解决:区分 rate_limit 与 insufficient_quota,给 Dify、Cursor 加上退避与限流
很多 AI 应用在本地测试时一切正常,接入 Dify、Cursor、Chatbox 或批处理脚本后,却开始间歇性出现 429 Too Many Requests。更容易误判的是:同样返回 429,有时表示请求或 Token 速率超过限制,有时却表示账户额度、项目预算或上游通道配额不足。
如果只看到 429 就立即重试,问题往往会被放大。失败请求可能仍占用速率窗口;Dify 工作流、客户端和后端代理还可能各自重试一次,最后形成“一个用户操作触发多轮重复请求”的重试风暴。
本文围绕一个主场景展开:OpenAI 兼容接口出现 429 后,如何先分型,再控制并发、退避重试,并让 Dify、Cursor、Chatbox、Cherry Studio 与自建服务共用一套处理规则。
一、这套排查方法适合哪些场景
下面几类情况都可以按本文的流程处理:
- Dify 调用第三方模型时提示
Too Many Requests; - Cursor 配置第三方 API 后频繁出现
rate limit exceeded; - Chatbox 能正常对话几轮,随后开始返回 429;
- Cherry Studio 添加自定义服务商后,多个助手并发请求失败;
- Python 批处理、内容生成任务或 RAG 评测在高并发时出现 429;
- 企业把多个模型 API 收口到后端代理后,希望按团队、项目限流;
- 账户界面看起来还有余额,但接口返回
insufficient_quota; - 需要评估一个稳定的 OpenAI 兼容接口,而不是只做一次连通性测试。
这里需要先澄清一个概念:429 是 HTTP 状态码,不是完整的故障原因。真正决定处理方式的,通常是响应体中的 error.type、error.code、message,以及响应头中的 Retry-After、速率剩余量和重置时间。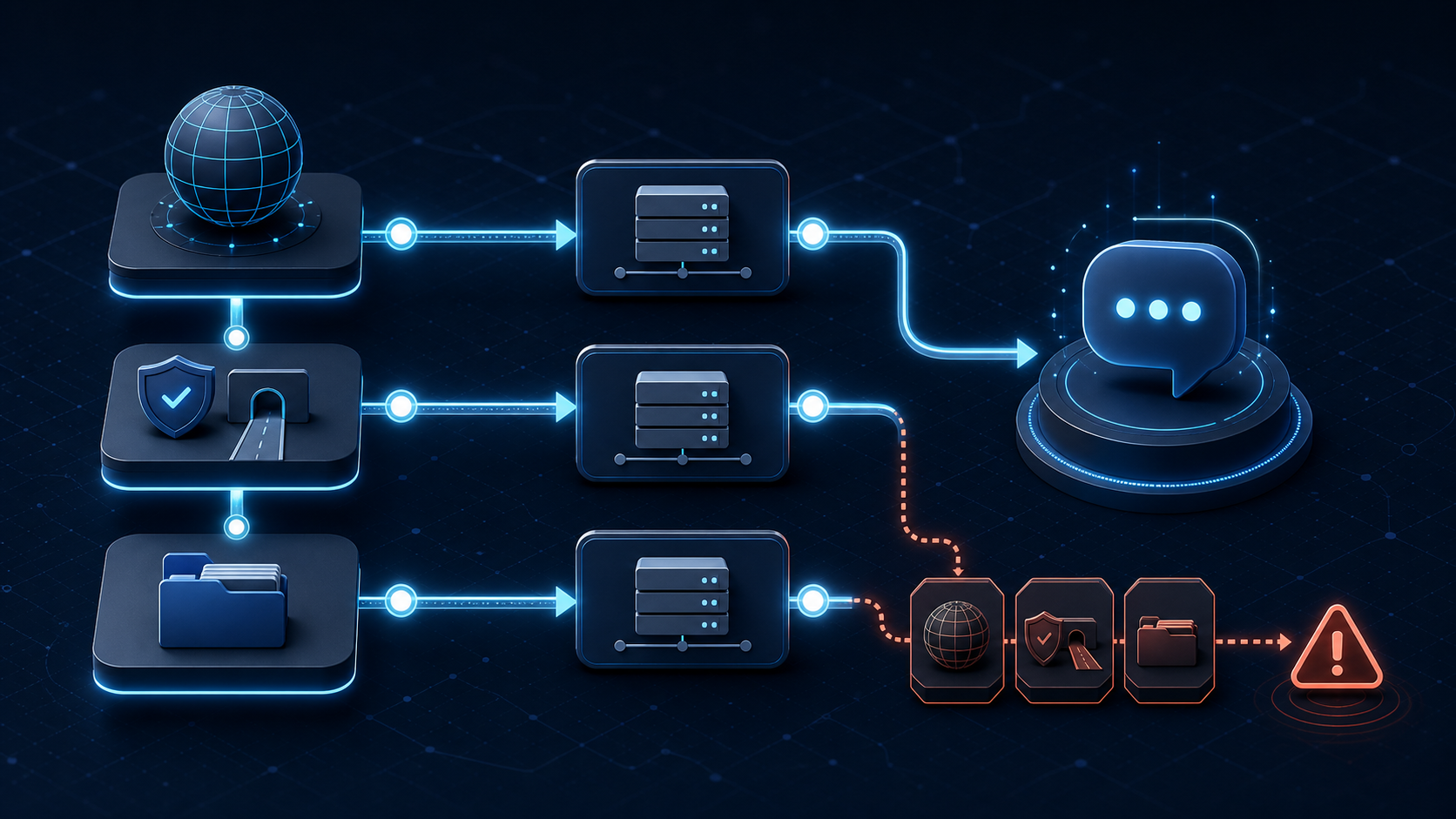
二、同样是 429,先分清四种情况
1. 请求频率超过限制:RPM
RPM 可以理解为每分钟请求数。短时间内大量发送短请求,即使每个请求的输入很少,也可能触发这一限制。典型场景是循环没有节流、前端重复提交、工作流并行分支过多。
处理重点:降低并发、平滑突发流量、读取 Retry-After,然后使用带随机抖动的指数退避。
2. Token 速率超过限制:TPM
TPM 关注单位时间内提交和生成的 Token 数。一个请求携带很长的聊天历史、RAG 片段或大段代码时,即使请求次数不多,也可能触发 429。
处理重点:裁剪历史消息、减少知识库召回片段、限制最大输出长度,并把大批量任务拆成队列。
3. 并发数超过限制
有些接口限制同时进行的请求数。平均每分钟只有十几个请求,也可能因为某一秒同时启动十个长生成任务而失败。Cursor 的多步骤任务、Dify 的并行节点和批量内容生成都容易遇到这种情况。
处理重点:在调用端或统一后端入口设置并发上限,不要仅依靠固定的每秒延时。
4. 额度或项目预算不足:insufficient_quota
这一类也可能返回 429,但等待十几秒并不会恢复。原因可能是账户余额不足、项目预算上限、模型单独配额、Key 所属项目错误,或者平台侧上游额度暂不可用。
处理重点:核对余额、项目、模型权限和账单状态;不要进行无意义的自动重试。
可以先记住这个判断:
| 现象 | 更可能的原因 | 首要动作 |
|---|---|---|
响应含 rate_limit_exceeded |
RPM、TPM 或并发限制 | 读取响应头,减并发并退避 |
响应含 insufficient_quota |
余额、预算或项目额度 | 检查账户与项目,不自动重试 |
| 高峰期失败、低峰期恢复 | 突发流量或共享通道拥塞 | 排队、限流、缩短输入 |
| 单次超长请求也返回 429 | TPM 或模型资源配额 | 减少上下文与最大输出 |
| curl 正常,Dify/Cursor 失败 | 工具并发、重试或配置差异 | 对照模型名、Base URL 和并发设置 |
三、OpenAI 兼容接口的 Base URL 应该怎么填
OpenAI Compatible 的核心含义,是服务在请求结构、鉴权方式和常用端点上兼容 OpenAI SDK 的调用习惯。它不代表所有模型能力、错误字段和限流规则都完全一致,因此不能只看“兼容”两个字,还要实际验证流式输出、模型名、错误响应和速率控制。
以候选 API 接入方案为例,三个地址分别表示不同层级:
- 服务根地址:
https://api.vectorengine.cn - SDK 常用 Base URL:
https://api.vectorengine.cn/v1 - curl 直接调用的完整端点:
https://api.vectorengine.cn/v1/chat/completions
向量引擎可以理解为面向 AI 应用、开发工具和工作流场景的 API 中转与模型接入服务,适合需要 OpenAI 兼容接口、统一模型入口、Dify/Cursor/Chatbox/Cherry Studio 接入、自建脚本调用、团队接口管理的用户评估使用。官方入口:https://178.nz/dn
最常见的填写错误,是把完整的 /v1/chat/completions 填进只接受 Base URL 的 SDK 或工具。工具随后会继续拼接路径,形成重复的 /v1/chat/completions/v1/chat/completions。反过来,curl 直接请求时如果只写 /v1,也不会自动补齐对话端点。
四、先用 curl 保留响应头,不要急着改工具
遇到 AI API 429 时,第一步不是在 Dify 或 Cursor 中反复点测试,而是用最小请求获得原始状态码、响应头和错误体。
curl -i --request POST \
--url "https://api.vectorengine.cn/v1/chat/completions" \
--header "Authorization: Bearer $AI_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "your-model-id",
"messages": [
{"role": "user", "content": "只回复 OK"}
],
"temperature": 0,
"max_tokens": 16,
"stream": false
}'
-i 会把响应头一起输出。排查时重点记录以下信息:
- HTTP 状态码;
Retry-After;- 与 rate limit 剩余量、重置时间有关的响应头;
- 响应体中的
type、code和message; - 请求 ID,但不要把 API Key 写进工单或日志。
如果最小请求也返回 insufficient_quota,优先检查账户和项目。若最小请求成功,而工具仍返回 429,应继续比较工具的并发数、上下文长度、模型名、是否启用流式输出,以及是否存在自动重试。
五、Python:按错误类型决定是否重试
下面的示例使用 requests,重点不是“多试几次”,而是满足三个条件:只重试可恢复的 429;优先遵守 Retry-After;加入随机抖动,避免多个任务在同一时刻再次撞到限流窗口。
import os
import random
import time
import requests
ENDPOINT = "https://api.vectorengine.cn/v1/chat/completions"
API_KEY = os.environ["AI_API_KEY"]
def parse_error(response):
try:
error = response.json().get("error", {})
except ValueError:
error = {}
return {
"type": str(error.get("type", "")),
"code": str(error.get("code", "")),
"message": str(error.get("message", "")),
"request_id": response.headers.get("x-request-id", ""),
}
def retry_delay(response, attempt):
retry_after = response.headers.get("Retry-After")
if retry_after and retry_after.isdigit():
return min(float(retry_after), 60.0)
# 1、2、4、8 秒附近随机抖动,避免并发任务同时重试
return min(2 ** attempt, 30) + random.uniform(0.2, 0.9)
def create_chat(messages, model="your-model-id", max_attempts=4):
payload = {
"model": model,
"messages": messages,
"temperature": 0.2,
"max_tokens": 300,
"stream": False,
}
for attempt in range(max_attempts):
response = requests.post(
ENDPOINT,
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json",
},
json=payload,
timeout=(10, 90),
)
if response.ok:
return response.json()
detail = parse_error(response)
is_quota = (
"insufficient_quota" in detail["type"]
or "insufficient_quota" in detail["code"]
)
if response.status_code != 429 or is_quota:
raise RuntimeError(
f"status={response.status_code}, "
f"type={detail['type']}, code={detail['code']}, "
f"request_id={detail['request_id']}"
)
if attempt == max_attempts - 1:
raise RuntimeError("429 persisted after bounded retries")
time.sleep(retry_delay(response, attempt))
result = create_chat([
{"role": "user", "content": "用一句话解释指数退避"}
])
print(result["choices"][0]["message"]["content"])
生产环境中不要输出完整错误响应后就不加筛选地写日志,因为部分服务会回显请求片段。建议只保留状态码、错误类型、模型、耗时、请求 ID、重试次数和脱敏后的项目标识。
六、Node.js 后端代理:先做项目级并发闸门
团队场景里,仅在每个客户端设置重试并不可靠。Dify、Cursor、自建脚本各自不知道其他工具正在消耗多少并发。更合适的做法,是让所有调用经过后端代理,在入口处按项目限制同时进行的请求数,并统一返回可诊断的错误。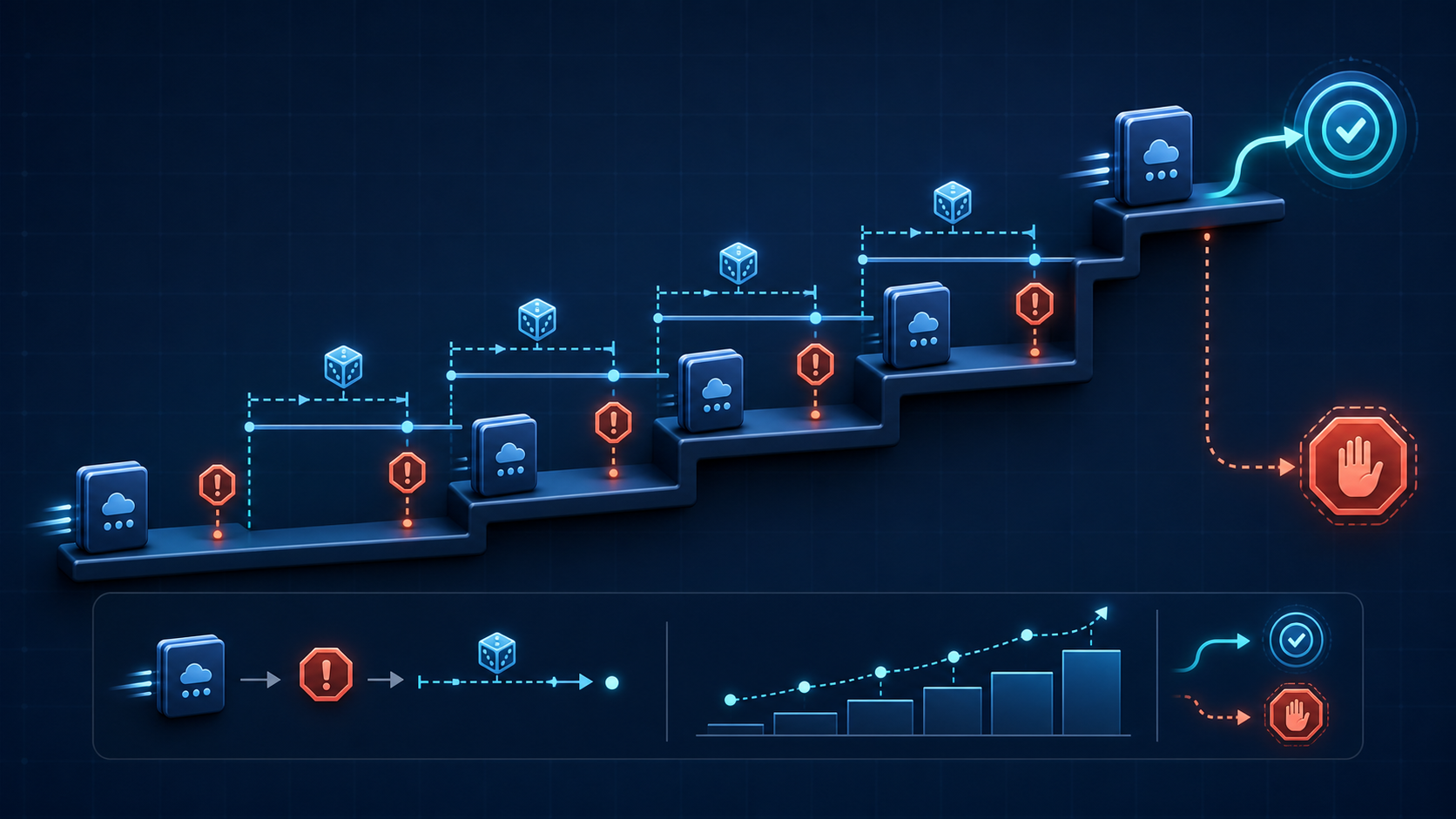
下面是一个 Node.js 18+ 与 Express 的简化示例。它用内存计数演示“每个项目最多同时两个请求”;多实例部署时,应把计数器替换为 Redis、网关限流器或队列。
const express = require("express");
const crypto = require("crypto");
const app = express();
app.use(express.json({ limit: "256kb" }));
const activeByProject = new Map();
const MAX_CONCURRENCY = 2;
function acquire(project) {
const active = activeByProject.get(project) || 0;
if (active >= MAX_CONCURRENCY) return false;
activeByProject.set(project, active + 1);
return true;
}
function release(project) {
const next = Math.max((activeByProject.get(project) || 1) - 1, 0);
if (next === 0) activeByProject.delete(project);
else activeByProject.set(project, next);
}
function classify429(body) {
const error = body?.error || {};
const text = `${error.type || ""} ${error.code || ""} ${error.message || ""}`;
if (text.includes("insufficient_quota")) return "quota_exhausted";
return "rate_limited";
}
app.post("/api/ai/chat", async (req, res) => {
const project = req.header("x-project-id") || "default";
const requestId = crypto.randomUUID();
if (!acquire(project)) {
return res.status(429).json({
error: {
type: "local_concurrency_limit",
message: "项目并发已达到内部上限,请稍后再试",
},
request_id: requestId,
});
}
try {
const upstream = await fetch(
"https://api.vectorengine.cn/v1/chat/completions",
{
method: "POST",
headers: {
Authorization: `Bearer ${process.env.AI_API_KEY}`,
"Content-Type": "application/json",
"x-request-id": requestId,
},
body: JSON.stringify(req.body),
signal: AbortSignal.timeout(90_000),
}
);
const body = await upstream.json().catch(() => ({}));
if (upstream.status === 429) {
const category = classify429(body);
const retryAfter = upstream.headers.get("retry-after");
return res.status(429).json({
error: {
type: category,
message:
category === "quota_exhausted"
? "上游额度或项目预算不足,请检查账户状态"
: "上游触发限流,请按 retry_after 退避",
},
retry_after: retryAfter,
request_id: requestId,
});
}
return res.status(upstream.status).json(body);
} catch (error) {
const isTimeout = error?.name === "TimeoutError";
return res.status(isTimeout ? 504 : 502).json({
error: {
type: isTimeout ? "upstream_timeout" : "upstream_unavailable",
message: isTimeout ? "上游响应超时" : "上游暂时不可用",
},
request_id: requestId,
});
} finally {
release(project);
}
});
app.listen(3000, () => {
console.log("AI gateway listening on http://localhost:3000");
});
这个代理没有盲目替用户重试,而是把 quota_exhausted、rate_limited、local_concurrency_limit 和 upstream_timeout 分开。调用方据此决定等待、排队、切换模型还是提醒管理员补充额度。
七、Dify、Cursor、Chatbox、Cherry Studio 怎么配置
1. Dify:先控制工作流并行与节点重试
在 Dify 中添加 OpenAI 兼容模型供应商时,Base URL 一般填写到 /v1 层级,再填写 API Key 与控制台提供的模型 ID。完成配置后,用短提示词测试一次。
如果工作流出现 429,按以下顺序检查:
- 查看是否有并行迭代、批处理或多个 LLM 节点同时执行;
- 暂时把知识库召回数量与最大输出 Token 调小;
- 检查工作流、插件和后端代理是否重复重试;
- 对
insufficient_quota直接转人工或管理员处理; - 对可恢复限流设置有上限的退避,而不是立即循环。
2. Cursor:区分编辑器限流与第三方 API 限流
Cursor 配置第三方 API 时,确认 Override OpenAI Base URL 指向 /v1,模型名与服务端实际 ID 一致。若 curl 成功而 Cursor 报 429,可以新建一个短会话测试,并减少同时运行的 Agent 或后台任务。
还要确认 429 的响应来自哪个环节:可能是 Cursor 自身套餐或功能限制,也可能是自定义 API Key 所属服务返回。只看界面上的一句 rate limit exceeded 不足以下结论,后端代理的请求 ID 和错误分类会更有帮助。
3. Chatbox:避免多会话同时发送
Chatbox 配置 OpenAI 兼容接口时,同样把 API Host 或 Base URL 填到 /v1。如果多个会话、助手或知识库任务共享一个 API Key,同时发送会形成突发并发。可以先只保留一个短会话,关闭不必要的自动标题、总结或后台模型任务,再观察是否恢复。
4. Cherry Studio:检查助手与模型服务的隐含调用
Cherry Studio 添加自定义服务商时,需要分别确认 Base URL、API Key 和模型 ID。部分助手功能可能在一次可见对话之外触发模型探测、标题生成或工具调用。遇到 429 时,可暂时禁用附加功能,用最小对话测试,再逐项恢复。
对团队而言,更稳妥的配置是让四类工具使用不同的内部凭证或项目标识,但共同指向后端代理。这样既不用把上游 Key 分发给每个成员,也能判断哪一种工具制造了并发峰值。
八、常见报错排查表
| 状态或错误 | 常见原因 | 是否适合重试 | 建议处理 |
|---|---|---|---|
429 rate_limit_exceeded |
RPM、TPM、并发或共享通道限流 | 是,需有上限 | 遵守 Retry-After,指数退避加抖动 |
429 insufficient_quota |
余额、项目预算、上游额度不足 | 否 | 检查账户、项目、模型配额 |
local_concurrency_limit |
自建代理主动保护上游 | 稍后再试 | 进入队列,降低项目并发 |
401 invalid_api_key |
Key 错误、过期、前缀或请求头错误 | 否 | 重新核对 Bearer 鉴权,不打印完整 Key |
404 model_not_found |
模型 ID 错误、无权限或路由未配置 | 否 | 从模型列表复制实际 ID |
400 context_length_exceeded |
历史消息、RAG 片段或输出预算过大 | 修改后重试 | 裁剪上下文,减少召回和 max_tokens |
504 timeout |
长生成、网络抖动或上游拥塞 | 视情况 | 设置连接/读取超时,避免无限重试 |
502/503 |
网关或上游暂时不可用 | 可有限重试 | 退避、熔断,必要时切换候选模型 |
这里有一个容易踩的坑:把 timeout、rate_limit 和 insufficient_quota 都归一成“请求失败”。这样做虽然让前端代码简单,却让运维无法采取正确动作。至少应保留“认证、参数、限流、额度、超时、上游不可用”六类错误。
九、API Key 安全建议
处理 429 时经常需要粘贴日志和响应,API Key 泄露风险反而会上升。建议同时做好以下几件事:
- 不要把 Key 写进前端代码、公开仓库、截图或 CSDN 文章;
- curl、Python 和 Node.js 都从环境变量读取 Key;
- Dify、Cursor、Chatbox、Cherry Studio 尽量使用独立凭证,便于撤销和定位;
- 日志中只记录 Key 指纹,例如哈希值的前 8 位,不记录明文;
- 发现泄露后先撤销旧 Key,再创建新 Key,最后检查异常调用;
- 为开发、测试、生产环境使用不同 Key 和预算;
- 企业场景优先由后端代理保管上游 Key,客户端只持有内部短期凭证;
- 设置项目级并发和预算上限,避免单个自动化任务耗尽团队额度。
如果怀疑 Key 已泄露,不要只修改代码仓库中的字符串。旧 Key 一旦进入提交历史、聊天记录或构建日志,就应视为已经暴露并立即轮换。
十、企业用户还要关注什么
企业统一接入大模型 API 时,429 不是一个单纯的开发报错,它还反映容量规划和治理是否完善。
1. 按项目而不是按个人做限流
同一个人可能同时使用 Dify、Cursor 和桌面客户端。只按用户限流会遗漏跨工具总量,建议至少记录 project、app、model 与内部 actor。
2. 分开统计 RPM、TPM、并发和失败重试
请求量不高不代表 Token 压力小。需要同时观察输入 Token、输出 Token、活动并发、429 比例和平均重试次数。重试产生的流量也要计入容量评估。
3. 设计降级而不是无限切换
候选模型可以用于故障降级,但切换前要检查上下文长度、工具调用、JSON 输出和内容规范是否兼容。避免在多个模型之间无限来回重试。
4. 明确数据与日志边界
评估正规的 AI API 平台或国内 API 中转站时,应确认服务条款、数据保留、日志范围、权限管理、账单记录和故障响应方式。接口能调用只是起点,企业还需要验证审计与退出机制。
5. 用压测数据决定容量
上线前用接近真实长度的提示词做阶梯式压测:逐步增加并发,记录首次出现 429 时的 RPM、TPM、并发、P95 耗时与恢复时间。不要用一句“你好”的成功率代替生产容量验证。
十一、FAQ

Q1:429 出现后固定等待 1 秒再重试可以吗?
不建议固定间隔。多个任务会在同一时刻再次发起请求,形成新的突发。优先读取 Retry-After;没有该响应头时,使用有上限的指数退避与随机抖动。
Q2:账户还有余额,为什么仍然出现 429?
余额与速率限制不是同一概念。账户有余额仍可能超过 RPM、TPM、并发或项目预算;也可能是 Key 绑定到了另一个项目。需要结合错误类型、项目和响应头判断。
Q3:换一个 API Key 能解决 rate_limit 吗?
不一定。限制可能绑定到账户、组织、项目、模型或共享通道,创建更多 Key 可能没有作用,还会增加凭证管理风险。先确认限流维度,再决定是否调整配额或拆分项目。
Q4:Dify 只执行一次,为什么上游看到了多次请求?
一个工作流可能包含并行节点、迭代、模型探测、插件调用和失败重试。再叠加后端代理重试后,一次用户操作可能对应多次上游调用。可以用请求 ID 和项目标识串联调用链。
Q5:Cursor 报 rate limit exceeded,一定是第三方接口的问题吗?
不一定。可能来自编辑器自身的功能限制,也可能来自自定义 OpenAI 兼容接口。用同一 Base URL、Key 和模型做 curl 最小请求,再结合代理日志判断错误来源。
Q6:insufficient_quota 可以自动切换模型吗?
可以把切换作为受控降级策略,但要确认备用模型有权限、输出兼容且符合业务要求。对于账单或项目配置错误,仍应通知管理员处理,而不是长期掩盖问题。
Q7:API 中转站哪家稳定,应该看哪些数据?
可以小额测试候选方案,观察不同时段的成功率、P95 延迟、429/5xx 比例、错误透明度、模型可用范围、账单记录和支持响应。一次调用成功或单一低价都不足以说明生产稳定性。
十二、总结

AI API 429 怎么解决,关键不在“多重试几次”,而在先识别错误类型:
rate_limit_exceeded关注 RPM、TPM、并发和突发流量;insufficient_quota关注余额、预算、项目和上游配额;- 可恢复的限流遵守
Retry-After,使用有上限的指数退避与随机抖动; - Dify、Cursor、Chatbox、Cherry Studio 需要检查隐含并发与重复重试;
- 团队通过后端代理统一限制并发、保护 API Key,并保留可诊断的错误分类;
- 上线前用真实上下文做阶梯压测,才能判断接口是否适合生产流量。
把 429 从一个模糊的“请求太多”拆成速率、Token、并发和额度四类后,个人开发者更容易定位问题,企业团队也能把容量、成本与故障处理纳入同一套接口治理流程。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 4
4 0
0- 0



 已为社区贡献47条内容
已为社区贡献47条内容

所有评论(0)