从零搭建大模型智能体:理论原理、模型选型与基于DeepSeek-v4的桌面窗体对话实战全解析
本文从智能体的理论起源出发,系统梳理大语言模型驱动的智能体(LLM-based Agent)的核心架构、记忆系统、规划范式与工具调用机制,并结合 GLM 与 DeepSeek 两大主流开源模型族的技术原理,给出一份从 0 到 1 的工程实战指南。文章理论部分基于已公开的学术综述与技术报告整合而成,工程部分给出一个完整的 Python 桌面窗体对话程序(基于 tkinter),支持流式输出、API 密钥管理、多模型切换与可调参数设置,并通过 AIGC bar 提供的统一 OpenAI 兼容接口接入 GLM-5.2(付费)与 deepseek-v4-flash(免费)两类模型。文末附带一个单文件独立运行版本,复制粘贴即可运行。API密钥获取地址: AIGC bar。
1 智能体概述与发展脉络
1.1 什么是智能体
智能体(Agent)这一概念最早可以追溯到人工智能奠基时期。在经典人工智能教材中,Russell 与 Norvig 将智能体定义为"能够感知环境(perceive its environment)并通过执行器对该环境施加作用的任何实体"。这一定义看似简单,却蕴含了智能体最核心的三要素:感知(Perception)、决策(Decision)与行动(Action)。一个完整的智能体系统必然包含"感知—决策—行动—环境反馈"的闭环,智能体通过持续不断地在这个闭环中循环,逐步逼近其设计目标。
在符号主义人工智能盛行的年代,智能体通常被实现为基于规则的专家系统,其决策过程依赖于人工编码的知识库与推理引擎。这类系统在封闭、确定性强的问题域中表现良好,但一旦面对开放、不确定的真实世界,便会暴露出知识获取瓶颈、规则爆炸、泛化能力差等根本性缺陷。强化学习智能体(如 DQN、AlphaGo)则在棋牌、游戏等环境中取得了突破,但其训练需要明确的环境模型与海量交互样本,难以直接迁移到自然语言主导的真实任务中。
大语言模型(LLM)的出现,从根本上重塑了智能体的实现范式。LLM 自身具备强大的自然语言理解与生成能力、广泛的世界知识储备以及一定程度的推理能力,这使得它天然适合作为智能体的"大脑"(Brain)。Wang 等人在其综述中明确指出,基于 LLM 的智能体(LLM-based Agent)将 LLM 作为核心控制器,通过扩展记忆、规划与工具使用等模块,构建出能够处理复杂现实任务的自主系统。这种范式与传统智能体的根本区别在于:决策逻辑不再依赖人工规则或昂贵的强化学习训练,而是通过自然语言提示(Prompt)与 LLM 的内在能力涌现出来。
1.2 智能体的发展历程
智能体的发展可以划分为三个明显的阶段,每个阶段都对应着不同的技术范式与能力边界。
第一阶段是符号智能体阶段(1950s—2000s)。这一时期的代表性工作包括 Newell 与 Simon 的逻辑理论家程序、Feigenbaum 的 DENDRAL 与 MYCIN 专家系统等。这些系统通过手工编码的规则与知识库实现特定领域的推理,其核心局限在于知识获取瓶颈——所有领域知识都需要领域专家与知识工程师协作编码,难以规模化。同时,这类系统对环境的感知能力极弱,几乎不具备自主行动能力。
第二阶段是强化学习智能体阶段(2000s—2020)。随着深度学习的兴起,深度强化学习成为智能体研究的主流方向。从 Atari 游戏上的 DQN,到围棋上的 AlphaGo,再到星际争霸与 Dota 2 上的 AlphaStar 与 OpenAI Five,强化学习智能体在封闭环境中展现出了超越人类的表现。然而,这类智能体的训练需要数百万乃至数十亿次的环境交互,训练成本极高,且其能力高度局限于训练环境,难以泛化到开放的真实世界任务。
第三阶段是大模型智能体阶段(2022 至今)。以 ChatGPT 的发布为标志,LLM 展现出了强大的零样本与少样本能力,研究者们迅速意识到 LLM 可以作为智能体的通用大脑。2022 年底,ReAct 范式被提出,首次系统地将推理(Reasoning)与行动(Acting)结合在同一个 LLM 循环中;2023 年,Toolformer、Reflexion、Tree of Thoughts 等工作相继问世,从工具使用、自我反思、搜索式推理等不同维度扩展了智能体的能力边界。同年,多篇综述文章系统梳理了这一新兴领域,标志着 LLM 智能体研究正式成为人工智能的核心方向之一。
1.3 大模型时代智能体的新范式
大模型智能体相比传统智能体,最根本的变化在于其"通用性"与"涌现性"。通用性体现在同一个 LLM 可以驱动完全不同领域的智能体——从代码编写到数学推理,从网页浏览到数据库查询,只需调整提示词与工具集,无需重新训练模型。涌现性则体现在 LLM 在大规模预训练中获得的推理、规划、工具使用等能力,并非显式训练所得,而是在模型规模与数据规模达到一定阈值后自然涌现。
Xi 等人在其综述《The Rise and Potential of Large Language Model Based Agents: A Survey》中提出了一个被广泛引用的智能体架构框架,将 LLM 智能体分解为四个核心模块:大脑(Brain,由 LLM 担任)、感知(Perception)、记忆(Memory)与行动(Action)。大脑负责推理、决策与规划;感知模块将多模态输入转化为 LLM 可理解的表示;记忆模块存储历史交互与知识;行动模块则负责调用工具、执行代码或与外部环境交互。这一框架成为后续大量智能体系统设计的基础模板。
2 大模型智能体的核心架构与理论基础
2.1 智能体的统一架构框架
要构建一个真正可用的智能体,首先需要理解其背后的统一架构。综合现有文献,一个完整的 LLM 智能体可以抽象为以下核心组件的有机组合:LLM 核心(作为推理与决策引擎)、记忆系统(短期上下文与长期知识库)、规划模块(任务分解与策略选择)、工具集(外部能力扩展)以及执行循环(感知—思考—行动的迭代闭环)。
这一架构的核心思想是"以 LLM 为中心,通过外部模块扩展其能力边界"。LLM 本身是一个无状态(stateless)的函数——给定输入文本,输出文本,模型权重在推理过程中不发生变化。这意味着所有"记忆"、“状态”、"经验"都必须通过外部系统显式管理,并在每次调用时以上下文(context)的形式注入 LLM。这一设计哲学深刻影响了智能体的工程实现:记忆管理、上下文压缩、工具调度等都成为智能体框架的核心工程问题。
从控制流的角度看,智能体的运行是一个不断迭代的循环过程。每一次迭代中,智能体首先感知外部输入(用户消息、工具返回结果等),将其与记忆中的相关信息一起组装成上下文,送入 LLM 进行推理;LLM 输出可能包含直接回复、工具调用请求或中间思考;执行模块根据 LLM 输出执行相应动作,并将结果反馈回感知模块,进入下一轮迭代。这一循环直到智能体产出最终回复或达到最大迭代次数为止。
2.2 大语言模型基础
理解智能体的能力边界,必须从其底层 LLM 的原理出发。现代大语言模型几乎全部基于 Transformer 架构,其核心是自注意力机制(Self-Attention)。给定输入序列的查询矩阵 Q Q Q、键矩阵 K K K 与值矩阵 V V V,缩放点积注意力的计算公式为:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
其中 d k d_k dk 为键向量的维度, d k \sqrt{d_k} dk 起到缩放作用,防止内积值过大导致 softmax 梯度饱和。多头注意力(Multi-Head Attention)通过并行运行多个注意力头,使模型能够在不同子空间中捕获不同维度的语义关系,其计算可表示为:
MultiHead ( Q , K , V ) = Concat ( head 1 , … , head h ) W O \text{MultiHead}(Q,K,V) = \text{Concat}(\text{head}_1, \dots, \text{head}_h)W^O MultiHead(Q,K,V)=Concat(head1,…,headh)WO
head i = Attention ( Q W i Q , K W i K , V W i V ) \text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V) headi=Attention(QWiQ,KWiK,VWiV)
其中 W i Q , W i K , W i V ∈ R d model × d k W_i^Q, W_i^K, W_i^V \in \mathbb{R}^{d_{\text{model}} \times d_k} WiQ,WiK,WiV∈Rdmodel×dk 为可学习的投影矩阵, W O W^O WO 为输出投影矩阵, h h h 为头数。Transformer 层由多头注意力与前馈网络(FFN)组成,配合残差连接与层归一化,构成深度堆叠的编码器或解码器结构。
大语言模型的训练通常分为两个阶段:预训练(Pre-training)与后训练(Post-training)。预训练阶段,模型在海量无标注文本上以自回归方式学习下一个 token 的概率分布,目标函数为负对数似然:
L pretrain = − ∑ t = 1 T log P ( x t ∣ x < t ; θ ) \mathcal{L}_{\text{pretrain}} = -\sum_{t=1}^{T} \log P(x_t \mid x_{<t}; \theta) Lpretrain=−t=1∑TlogP(xt∣x<t;θ)
其中 θ \theta θ 为模型参数, x < t x_{<t} x<t 表示位置 t t t 之前的所有 token。这一阶段赋予模型语言流畅性与广泛的世界知识。后训练阶段则通过监督微调(SFT)与基于人类反馈的强化学习(RLHF)对齐模型行为,使其更符合人类指令与价值观。RLHF 的核心是训练一个奖励模型 r ϕ ( x , y ) r_\phi(x, y) rϕ(x,y) 来模拟人类偏好,然后使用 PPO 算法优化策略模型:
L RLHF = E x ∼ D , y ∼ π θ [ r ϕ ( x , y ) − β log π θ ( y ∣ x ) π ref ( y ∣ x ) ] \mathcal{L}_{\text{RLHF}} = \mathbb{E}_{x \sim \mathcal{D}, y \sim \pi_\theta}\left[ r_\phi(x, y) - \beta \log \frac{\pi_\theta(y \mid x)}{\pi_{\text{ref}}(y \mid x)} \right] LRLHF=Ex∼D,y∼πθ[rϕ(x,y)−βlogπref(y∣x)πθ(y∣x)]
其中 π θ \pi_\theta πθ 为待优化的策略模型, π ref \pi_{\text{ref}} πref 为参考模型(通常是 SFT 后的模型), β \beta β 为 KL 散度惩罚系数,用于防止策略模型偏离参考模型过远。这一对齐过程对智能体至关重要——它使 LLM 能够遵循指令、调用工具、拒绝有害请求,从而成为可靠的智能体大脑。
2.3 注意力机制与 Transformer 的工程意义
从智能体工程的角度看,Transformer 架构有几个关键特性深刻影响了智能体的设计。首先是上下文窗口(Context Window)的限制。由于自注意力的计算复杂度为 O ( n 2 ) O(n^2) O(n2)( n n n 为序列长度),LLM 能够处理的最大上下文长度受限于显存与计算资源。这意味着智能体必须有效地管理上下文——决定哪些信息进入上下文、哪些信息被压缩或丢弃,这便是记忆系统设计的核心问题。
其次是 KV Cache 机制。在自回归生成中,已生成 token 的键值对可以缓存复用,避免重复计算,这使推理速度大幅提升。但 KV Cache 会随序列长度线性增长,对长对话与长任务的智能体而言,KV Cache 管理成为工程优化的关键。DeepSeek-V3 引入的多头潜在注意力(MLA)正是为了压缩 KV Cache 而设计的创新架构。
第三是位置编码的影响。原始 Transformer 使用正弦位置编码,后续工作发展出可学习位置编码、相对位置编码、RoPE(Rotary Position Embedding)等方案。RoPE 通过旋转矩阵将位置信息编码到查询与键向量中,具有良好的外推性,成为当前主流大模型(包括 GLM 与 DeepSeek)的标准选择。RoPE 的核心公式为:
( q i ′ q i + 1 ′ ) = ( cos ( m θ i ) − sin ( m θ i ) sin ( m θ i ) cos ( m θ i ) ) ( q i q i + 1 ) \begin{pmatrix} q'_i \\ q'_{i+1} \end{pmatrix} = \begin{pmatrix} \cos(m\theta_i) & -\sin(m\theta_i) \\ \sin(m\theta_i) & \cos(m\theta_i) \end{pmatrix} \begin{pmatrix} q_i \\ q_{i+1} \end{pmatrix} (qi′qi+1′)=(cos(mθi)sin(mθi)−sin(mθi)cos(mθi))(qiqi+1)
其中 m m m 为 token 的绝对位置, θ i \theta_i θi 为预设的频率参数。RoPE 的优势在于其相对位置特性——两个 token 的注意力分数仅取决于它们的相对距离,而非绝对位置,这使得模型在处理长序列时具有更好的泛化能力。
3 主流大模型技术原理与对比选型
3.1 GLM 系列模型技术原理
GLM(General Language Model)系列是由智谱 AI(Z.ai)与清华大学联合研发的开源大模型家族,其设计理念强调"智能体能力(Agentic)、推理能力(Reasoning)与编码能力(Coding)"三位一体,简称 ARC。最新公开技术报告的 GLM-4.5 是一个混合专家(Mixture-of-Experts, MoE)模型,总参数量达 355B,每个 token 激活参数为 32B,在多项基准测试中达到了同规模开源模型的最优水平。
GLM-4.5 的核心架构创新在于其 MoE 设计。MoE 的基本思想是将前馈网络(FFN)替换为多个并行的"专家"网络,每个 token 仅激活其中少数几个专家,从而在保持模型容量大幅提升的同时控制计算开销。形式化地,给定输入 x x x,MoE 层的输出为:
MoE ( x ) = ∑ i = 1 N g i ( x ) ⋅ E i ( x ) \text{MoE}(x) = \sum_{i=1}^{N} g_i(x) \cdot E_i(x) MoE(x)=i=1∑Ngi(x)⋅Ei(x)
其中 N N N 为专家总数, E i ( ⋅ ) E_i(\cdot) Ei(⋅) 为第 i i i 个专家网络, g i ( x ) g_i(x) gi(x) 为路由函数(通常为门控网络)输出的第 i i i 个专家的权重。GLM-4.5 采用 Top-K 路由策略,即每个 token 仅激活权重最高的 K K K 个专家(通常 K = 8 K=8 K=8),其余专家权重置零,这保证了稀疏激活与计算效率。
GLM-4.5 在智能体能力上的突出表现尤其值得关注。根据 Z.ai 官方技术博客披露的数据,GLM-4.5 在工具调用(Tool Calling)任务上的平均成功率达到 90.6%,超过了 Claude-4-Sonnet(89.5%)与 Kimi-K2(86.2%)。这一指标对智能体开发至关重要——工具调用成功率直接决定了智能体能否可靠地与外部环境交互。
3.2 DeepSeek 系列模型技术原理
DeepSeek 系列是由深度求索公司研发的开源大模型家族,其技术报告公开披露了多项架构创新,对整个开源社区产生了深远影响。DeepSeek-V3 是一个总参数 671B、激活参数 37B 的 MoE 模型,在数学、代码与推理任务上表现卓越。DeepSeek 系列的两大核心架构创新是:多头潜在注意力(Multi-head Latent Attention, MLA)与 DeepSeek MoE 稀疏路由。
MLA 是 DeepSeek 对传统多头注意力的关键改进,其目标是压缩 KV Cache 以降低长上下文推理的显存开销。在标准注意力中,每个 token 需要缓存其键向量 k k k 与值向量 v v v,当序列长度增大时,KV Cache 占用的显存急剧增长。MLA 的核心思想是将键值对投影到一个低维的潜在空间中缓存,在计算注意力时再还原回高维空间。具体而言,MLA 将 token 的隐藏状态 h h h 压缩为低维潜在向量 c c c:
c = W down h c = W_{\text{down}} h c=Wdownh
在注意力计算时,再通过上投影矩阵恢复键值向量:
k = W up k c , v = W up v c k = W_{\text{up}}^k c, \quad v = W_{\text{up}}^v c k=Wupkc,v=Wupvc
由于 c c c 的维度远小于原始键值向量,KV Cache 的显存占用大幅降低。据 DeepSeek 团队披露,MLA 在保持注意力质量的同时,将 KV Cache 压缩到原来的约 5%—10%,这使得 DeepSeek-V3 能够高效处理超长上下文。
3.3 模型对比与选型策略
在构建智能体时,模型选型是影响最终效果的关键决策。不同的模型在能力侧重、推理速度、上下文长度、价格成本等方面各有差异,开发者需要根据具体应用场景进行权衡。下表对比了 GLM 与 DeepSeek 两大主流开源模型族的关键特性:
| 维度 | GLM-4.5/4.6 | DeepSeek-V3/V3.1 |
|---|---|---|
| 架构类型 | MoE(355B总/32B激活) | MoE(671B总/37B激活)+ MLA |
| 注意力机制 | GQA + RoPE | MLA + RoPE |
| 上下文长度 | 128K | 128K |
| 智能体能力 | 工具调用成功率 90.6% | 工具调用能力优秀 |
| 推理能力 | ARC 设计,推理强 | 数学推理突出 |
| 编码能力 | 编码基准领先 | 代码生成强 |
| 中文能力 | 中文原生优化 | 中文表现良好 |
| 开源协议 | MIT 开源 | MIT 开源 |
| 训练成本披露 | 公开 | 公开(约 557 万美元) |
在本文的实战项目中,我们将通过 AIGC bar 提供的统一 OpenAI 兼容接口,在一个桌面应用内同时支持 GLM-5.2(付费模型)与 deepseek-v4-flash(免费模型)。这种多模型协同策略在实际工程中非常实用——复杂任务使用付费的高性能模型,日常简单对话使用免费模型,在保证效果的同时有效控制成本。
4 智能体记忆系统设计
4.1 记忆系统的分类
记忆是大模型智能体区别于"无状态聊天机器人"的关键能力。一个没有记忆的智能体只能处理孤立的请求,无法积累经验、维持长期对话或学习用户偏好。综合现有文献,智能体记忆系统通常按时间跨度与存储方式划分为以下几类。
短期记忆(Short-term Memory)对应 LLM 的上下文窗口,存储当前对话或任务的活跃信息。短期记忆的容量受限于上下文窗口大小(如 128K token),一旦超出便需要通过截断、压缩或转移策略处理。短期记忆的访问是即时的——所有信息直接作为 prompt 输入 LLM,无需额外检索。长期记忆(Long-term Memory)则持久化存储历史交互、用户偏好与领域知识,通常通过向量数据库实现,需要时通过检索机制召回相关片段注入上下文。工作记忆(Working Memory)是介于两者之间的概念,指当前任务执行过程中临时维护的中间状态,如已完成的子任务、待调用的工具列表等。
在本文的实战项目中,我们实现的是最基础的短期记忆——通过维护消息列表 self.messages 保存对话历史,每次调用 API 时将完整历史作为上下文传入。这是所有智能体记忆系统的基础形式,理解它之后,扩展长期记忆(如接入向量数据库)就变得水到渠成。
4.2 短期记忆与上下文管理
短期记忆管理的核心挑战是上下文窗口的有限性。当对话历史或任务执行过程超出上下文窗口时,必须采取策略处理溢出信息。常见的策略包括:截断(直接丢弃最早的消息)、摘要压缩(用 LLM 对历史对话生成摘要)、滑动窗口(保留最近 N 轮对话)以及选择性保留(根据重要性评分保留关键消息)。每种策略都有其适用场景与局限。
截断策略实现简单但会丢失早期信息,不适合需要长期连贯性的任务。摘要压缩能够保留信息要点但引入额外的 LLM 调用开销,且摘要过程可能丢失关键细节。滑动窗口在简单对话场景中表现良好,但对于需要回溯早期信息的复杂任务则力不从心。选择性保留策略通过为每条消息计算重要性评分(如基于时间衰减、内容相关性、用户标记等),动态决定保留哪些消息,是当前较为先进的方案。
在本文的实战项目中,我们使用截断策略——当消息历史累积到一定长度时,用户可以点击"清空对话"按钮重置上下文。这是一种简单但实用的策略,适合桌面对话应用的使用场景。
4.3 长期记忆与向量检索
长期记忆的实现通常依赖向量数据库与检索增强生成(RAG)技术。RAG 由 Lewis 等人在 2020 年提出,其核心思想是将外部知识以向量形式存储,在生成时检索相关片段作为上下文。在智能体场景中,RAG 不仅用于知识检索,还用于历史交互记忆的召回。完整的 RAG 流程包括:文档切分、向量化编码、索引构建、查询检索与上下文增强生成。
| 记忆类型 | 存储介质 | 访问方式 | 容量 | 持久性 | 典型实现 |
|---|---|---|---|---|---|
| 短期记忆 | LLM 上下文 | 直接作为 prompt | 受窗口限制 | 会话内 | 消息列表 |
| 工作记忆 | 内存数据结构 | 程序直接访问 | 内存限制 | 任务内 | 状态字典 |
| 长期记忆 | 向量数据库 | 相似度检索 | 近乎无限 | 持久化 | FAISS/Milvus |
| 情景记忆 | 向量数据库+元数据 | 时间+语义检索 | 近乎无限 | 持久化 | 带时间戳的向量 |
| 语义记忆 | 知识图谱 | 图查询 | 大 | 持久化 | Neo4j |
5 规划与推理范式
5.1 思维链与推理基础
规划与推理是智能体解决复杂问题的核心能力。大语言模型的推理能力很大程度上通过提示工程激发,其中最具基础性影响的工作是 Wei 等人提出的思维链(Chain-of-Thought, CoT)提示。CoT 的核心思想是:在提示中引导 LLM 生成中间推理步骤,而非直接给出答案,从而显著提升复杂推理任务的准确率。
CoT 的形式化表述如下。给定问题 x x x,标准提示让 LLM 直接生成答案 y ∼ P ( y ∣ x ) y \sim P(y \mid x) y∼P(y∣x);而 CoT 提示则让 LLM 先生成推理链 z z z,再基于推理链生成答案 y ∼ P ( y ∣ z , x ) y \sim P(y \mid z, x) y∼P(y∣z,x),其中 z ∼ P ( z ∣ x ) z \sim P(z \mid x) z∼P(z∣x)。这一看似简单的改变,在数学应用题、逻辑推理、符号操作等任务上带来了显著的性能提升。Wei 等人的实验表明,在 GSM8K 数学应用题基准上,CoT 使 PaLM-540B 的准确率从 17.7% 提升到 56.9%,提升幅度惊人。
5.2 ReAct 范式:推理与行动的协同
CoT 解决了"如何推理"的问题,但纯粹的推理无法与外部环境交互——模型只能基于自身参数化知识生成答案,无法获取实时信息或执行实际动作。Yao 等人在 ICLR 2023 上提出的 ReAct 范式填补了这一空白,首次系统地将推理(Reasoning)与行动(Acting)结合在统一的 LLM 循环中,成为大模型智能体最经典的范式之一。
ReAct 的核心思想是让 LLM 交替生成"思考(Thought)“与"行动(Action)”。思考是 LLM 对当前状态的推理与分析,行动是 LLM 决定调用的外部工具或操作。每次行动后,环境返回"观察(Observation)",LLM 基于观察继续思考与行动,直到得出最终答案。一个典型的 ReAct 轨迹如下:
Thought 1: 我需要查询北京今天的天气
Action 1: search_weather[北京]
Observation 1: 北京今天晴,气温 25-32°C
Thought 2: 天气晴朗适合户外活动,用户可能需要防晒建议
Action 2: finish[今天北京晴朗,气温25-32°C,建议防晒]
5.3 Tree of Thoughts 与反思机制
ReAct 采用的是线性推理路径——每一步基于前一步的结果继续,不回溯不分支。然而,许多复杂问题需要探索多个可能的方向,并在发现死路时回溯。Yao 等人提出的 Tree of Thoughts(ToT)范式正是为这一需求设计,它将 CoT 的线性推理扩展为树形搜索,使智能体能够系统性地探索解空间。
| 范式 | 核心思想 | 优势 | 局限 | 适用场景 |
|---|---|---|---|---|
| CoT | 线性中间推理 | 简单有效,广泛适用 | 无法纠错,易幻觉 | 数学、逻辑推理 |
| ReAct | 推理+行动交替 | 可交互,降低幻觉 | 线性路径,无回溯 | 工具调用、信息检索 |
| ToT | 树形搜索推理 | 可回溯,探索性强 | 计算开销大 | 创意、规划、博弈 |
| Reflexion | 失败反思重试 | 自我改进 | 依赖评估信号 | 代码生成、任务求解 |
| Plan-Execute | 先规划后执行 | 结构化,可控 | 规划与执行脱节 | 复杂多步任务 |
6 工具调用与函数机制
6.1 函数调用原理
工具调用(Tool Use)或函数调用(Function Calling)是智能体与外部世界交互的核心机制。Schick 等人在 Toolformer 工作中首次系统展示了 LLM 可以自学使用外部工具(如计算器、搜索引擎、日历等),通过在适当位置插入工具调用并处理返回结果,显著提升模型在事实性、数学计算等任务上的表现。
现代 LLM 的函数调用机制通常采用结构化输出方式。开发者向 LLM 提供可用函数的描述(包括函数名、功能说明、参数 schema),LLM 在生成响应时,若判断需要调用某个函数,则输出结构化的调用请求(通常为 JSON 格式),包含函数名与参数值。执行环境接收到调用请求后,实际执行对应函数,将返回结果作为新的上下文反馈给 LLM,LLM 基于结果继续生成最终响应。这一过程可以多轮迭代,支持复杂的工具链调用。
6.2 JSON Schema 与工具描述
工具描述的质量直接决定函数调用的成功率。一个完整的工具描述通常包含:函数名(function name)、功能描述(description)、参数 schema(parameters)与返回值描述。参数 schema 使用 JSON Schema 规范定义每个参数的类型、是否必填、取值范围等约束。一个规范的工具描述示例如下:
{
"type": "function",
"function": {
"name": "get_weather",
"description": "查询指定城市的当前天气信息,包括温度、湿度、天气状况",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "城市名称,如'北京'、'上海'"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "温度单位,默认摄氏度"
}
},
"required": ["city"]
}
}
}
6.3 工具调用流程与工程实践
完整的工具调用流程包括:工具注册、调用决策、参数生成、工具执行、结果反馈与最终响应。在工程实现中,这一流程通常封装在智能体框架的执行循环中。
7 从零搭建智能体项目实战:桌面窗体对话程序
理论终需落地。本章将前述理论整合为一个可直接运行的桌面窗体对话程序。项目使用 Python 内置的 tkinter 构建图形界面,通过 AIGC bar 提供的 OpenAI 兼容接口接入大语言模型,支持流式输出、API 密钥本地保存、多模型切换、参数实时调节等完整功能。
7.1 项目架构设计
项目采用分层设计,各层职责明确:
- 用户界面层:基于 tkinter 构建,提供对话展示、消息输入、参数设置等功能
- 业务逻辑层:管理 API 密钥(本地文件持久化)、对话历史(短期记忆维护)、参数配置(自动加载与保存)
- API 接入层:封装 OpenAI 兼容接口,支持普通调用与流式调用,内置重试机制
- 模型层:通过 AIGC bar 统一接口接入 GLM-5.2 与 deepseek-v4-flash 等模型
7.2 API 客户端封装:统一多模型接入
首先实现核心的 LLMClient 类。它封装了 OpenAI 兼容的 Chat Completions API,支持通过模型名称动态切换后端模型,并提供流式输出方法。
"""
LLM Client - 统一的 LLM API 客户端
支持通过 AIGC bar 聚合服务调用多种模型
"""
import os
import time
from typing import List, Dict, Optional, Any, Callable
class LLMClient:
"""统一的 LLM API 客户端,支持多模型切换与流式输出"""
BASE_URL = "https://api.aigc.bar/v1"
# 模型配置(可自由扩展)
MODEL_CONFIG = {
"glm-5.2": {
"name": "GLM-5.2",
"desc": "智谱 GLM 系列,付费模型,智能体能力强",
"paid": True,
"group": "OpenSource-MultiModal",
},
"deepseek-v4-flash": {
"name": "DeepSeek-V4-Flash",
"desc": "DeepSeek 系列,免费模型,速度快",
"paid": False,
"group": "OpenSource-MultiModal",
},
}
def __init__(
self,
model: str = "deepseek-v4-flash",
api_key: Optional[str] = None,
base_url: Optional[str] = None,
):
self.model = model
if model not in self.MODEL_CONFIG:
raise ValueError(f"不支持的模型: {model}")
# 优先使用传入的 api_key,其次从环境变量读取
self.api_key = api_key or os.environ.get("AIGC_API_KEY", "")
if not self.api_key:
raise ValueError("请设置 API Key")
self.base_url = base_url or self.BASE_URL
from openai import OpenAI
self.client = OpenAI(base_url=self.base_url, api_key=self.api_key)
def chat(
self,
messages: List[Dict[str, str]],
tools: Optional[List[Dict]] = None,
temperature: float = 0.7,
max_tokens: int = 10000,
**kwargs,
) -> Any:
"""调用 chat completions 接口(非流式)"""
request_kwargs = {
"model": self.model,
"messages": messages,
"temperature": temperature,
"max_tokens": max_tokens,
}
if tools:
request_kwargs["tools"] = tools
request_kwargs["tool_choice"] = "auto"
request_kwargs.update(kwargs)
# 重试机制:应对网络波动与限流
max_retries = 3
for attempt in range(max_retries):
try:
return self.client.chat.completions.create(**request_kwargs)
except Exception as e:
if attempt == max_retries - 1:
raise
wait_time = 2 ** attempt
print(f"API 调用失败({attempt + 1}/{max_retries}),"
f"{wait_time}秒后重试: {e}")
time.sleep(wait_time)
def chat_stream(
self,
messages: List[Dict[str, str]],
on_chunk: Callable[[str], None],
tools: Optional[List[Dict]] = None,
temperature: float = 0.7,
max_tokens: int = 10000,
**kwargs,
) -> str:
"""流式调用 chat completions 接口
Args:
messages: 消息列表
on_chunk: 每收到一个文本块时的回调函数
tools: 工具描述列表
temperature: 采样温度
max_tokens: 最大生成 token 数
Returns:
完整响应文本
"""
request_kwargs = {
"model": self.model,
"messages": messages,
"temperature": temperature,
"max_tokens": max_tokens,
"stream": True,
"stream_options": {"include_usage": True},
}
if tools:
request_kwargs["tools"] = tools
request_kwargs["tool_choice"] = "auto"
request_kwargs.update(kwargs)
full_content = ""
max_retries = 3
for attempt in range(max_retries):
try:
stream = self.client.chat.completions.create(**request_kwargs)
for chunk in stream:
delta = chunk.choices[0].delta if chunk.choices else None
if delta and delta.content:
full_content += delta.content
on_chunk(delta.content)
return full_content
except Exception as e:
if attempt == max_retries - 1:
raise
wait_time = 2 ** attempt
print(f"API 调用失败({attempt + 1}/{max_retries}),"
f"{wait_time}秒后重试: {e}")
time.sleep(wait_time)
return full_content
代码要点说明:
- 模型配置集中管理:
MODEL_CONFIG字典集中管理所有可用模型的信息,添加新模型只需在此增加一条配置 - API Key 多源读取:优先使用构造参数传入的
api_key,其次是环境变量AIGC_API_KEY - 重试机制:最多重试 3 次,使用指数退避(2^attempt 秒),应对网络波动
- 流式输出:
chat_stream方法设置stream=True,通过on_chunk回调函数实时返回文本片段
7.3 流式输出实现原理
流式输出(Streaming)是提升用户体验的关键技术。在非流式模式下,用户需要等待 LLM 完整生成全部文本后才能看到结果——对于长文本生成,这可能需要数十秒,体验极差。
流式输出的工作原理如下:
- API 请求设置
stream: true参数 - 服务端不再等待完整生成结束,而是每生成一个 token(或一小批 token)就立即通过 Server-Sent Events(SSE)推送给客户端
- 客户端边接收边显示,实现"逐字输出"的效果
在 Python 实现中,流式 API 返回一个可迭代对象,每次迭代返回一个 chunk。每个 chunk 的 choices[0].delta 字段包含本次新增的文本内容。tkinter 是线程不安全的,因此我们不能在后台线程直接更新 UI,而是通过 root.after(0, callback) 将 UI 更新任务调度到主线程执行。
7.4 完整窗体对话程序代码
以下是完整的桌面窗体对话程序,包含全部功能。代码做了详细注释,便于理解和修改。
"""
AI 智能体聊天 - 桌面窗体对话程序
支持流式输出、API 密钥管理、多模型切换、参数实时调节
"""
import os
import sys
import json
import tkinter as tk
from tkinter import ttk, messagebox, scrolledtext
from threading import Thread
# ── 配置管理 ─────────────────────────────────────────────
# 配置文件保存在用户目录下的 .aigc_chat/config.json
CONFIG_DIR = os.path.join(os.path.expanduser("~"), ".aigc_chat")
CONFIG_FILE = os.path.join(CONFIG_DIR, "config.json")
DEFAULT_CONFIG = {
"api_key": "",
"model": "deepseek-v4-flash",
"system_prompt": "你是一个友好的AI助手。",
"temperature": 0.7,
"max_tokens": 10000,
"top_p": 1.0,
"presence_penalty": 0.0,
"frequency_penalty": 0.0,
}
def load_config():
"""从本地文件加载配置"""
if not os.path.exists(CONFIG_FILE):
return dict(DEFAULT_CONFIG)
try:
with open(CONFIG_FILE, "r", encoding="utf-8") as f:
data = json.load(f)
cfg = dict(DEFAULT_CONFIG)
cfg.update(data)
return cfg
except Exception:
return dict(DEFAULT_CONFIG)
def save_config(config: dict):
"""保存配置到本地文件"""
os.makedirs(CONFIG_DIR, exist_ok=True)
with open(CONFIG_FILE, "w", encoding="utf-8") as f:
json.dump(config, f, ensure_ascii=False, indent=2)
# ── 导入 LLM 客户端 ──────────────────────────────────────
# 在实际项目中,将上一节的 LLMClient 放在 llm_agent/client.py 中
# 此处假设 LLMClient 已导入
from llm_agent import LLMClient
class ChatWindow:
"""主聊天窗口"""
def __init__(self):
self.root = tk.Tk()
self.root.title("AI 智能体聊天")
self.root.geometry("950x750")
self.root.minsize(750, 550)
# 加载配置
self.config = load_config()
# 对话历史(短期记忆)
self.messages = []
# 设置栏折叠状态
self.settings_visible = tk.BooleanVar(value=False)
self._build_ui()
self.root.protocol("WM_DELETE_WINDOW", self._on_close)
def _build_ui(self):
"""构建界面"""
# ── 顶部:API 密钥栏 ──
api_frame = ttk.Frame(self.root, padding=(10, 8))
api_frame.pack(fill=tk.X)
ttk.Label(api_frame, text="API密钥:", font=("微软雅黑", 9)).pack(side=tk.LEFT)
self.api_entry = ttk.Entry(api_frame, width=50, show="*")
self.api_entry.pack(side=tk.LEFT, padx=(5, 0), fill=tk.X, expand=True)
if self.config.get("api_key"):
self.api_entry.insert(0, self.config["api_key"])
# 获取密钥按钮
ttk.Button(
api_frame, text="获取API密钥",
command=self._open_register_url,
).pack(side=tk.LEFT, padx=(5, 0))
# 保存配置按钮
ttk.Button(
api_frame, text="保存配置",
command=self._save_config,
).pack(side=tk.LEFT, padx=(5, 0))
# 设置折叠按钮
ttk.Button(
api_frame, text="展开设置", width=10,
command=self._toggle_settings,
).pack(side=tk.RIGHT, padx=(5, 0))
# ── 可折叠的设置栏 ──
self.settings_frame = ttk.LabelFrame(
self.root, text="参数设置", padding=(10, 5)
)
# 第一行:模型选择
row1 = ttk.Frame(self.settings_frame)
row1.pack(fill=tk.X, pady=2)
ttk.Label(row1, text="模型:", font=("微软雅黑", 9)).pack(side=tk.LEFT)
self.model_var = tk.StringVar(value=self.config["model"])
self.model_combo = ttk.Combobox(
row1, textvariable=self.model_var,
values=list(LLMClient.MODEL_CONFIG.keys()),
state="readonly", width=22,
)
self.model_combo.pack(side=tk.LEFT, padx=(5, 15))
self.model_combo.bind("<<ComboboxSelected>>", lambda e: self._update_model_info())
self.model_info_label = ttk.Label(
row1, text="", font=("微软雅黑", 8), foreground="gray"
)
self.model_info_label.pack(side=tk.LEFT)
self._update_model_info()
# 第二行:温度 + 最大Token
row2 = ttk.Frame(self.settings_frame)
row2.pack(fill=tk.X, pady=2)
ttk.Label(row2, text="温度:", font=("微软雅黑", 9)).pack(side=tk.LEFT)
self.temp_var = tk.DoubleVar(value=self.config["temperature"])
ttk.Scale(
row2, from_=0.0, to=2.0, variable=self.temp_var,
orient=tk.HORIZONTAL, length=100,
).pack(side=tk.LEFT, padx=(5, 5))
self.temp_label = ttk.Label(
row2, text=f"{self.temp_var.get():.1f}", width=4
)
self.temp_label.pack(side=tk.LEFT)
ttk.Label(row2, text=" 最大Token:", font=("微软雅黑", 9)).pack(
side=tk.LEFT, padx=(15, 0)
)
self.max_tokens_var = tk.IntVar(value=self.config["max_tokens"])
ttk.Spinbox(
row2, from_=100, to=128000, increment=100,
textvariable=self.max_tokens_var, width=8,
).pack(side=tk.LEFT, padx=(5, 0))
# 第三行:Top-P + 存在惩罚 + 频率惩罚
row3 = ttk.Frame(self.settings_frame)
row3.pack(fill=tk.X, pady=2)
ttk.Label(row3, text="Top-P:", font=("微软雅黑", 9)).pack(side=tk.LEFT)
self.top_p_var = tk.DoubleVar(value=self.config["top_p"])
ttk.Scale(
row3, from_=0.0, to=1.0, variable=self.top_p_var,
orient=tk.HORIZONTAL, length=80,
).pack(side=tk.LEFT, padx=(5, 5))
ttk.Label(row3, text=" 存在惩罚:", font=("微软雅黑", 9)).pack(
side=tk.LEFT, padx=(15, 0)
)
self.presence_var = tk.DoubleVar(value=self.config["presence_penalty"])
ttk.Scale(
row3, from_=-2.0, to=2.0, variable=self.presence_var,
orient=tk.HORIZONTAL, length=80,
).pack(side=tk.LEFT, padx=(5, 5))
ttk.Label(row3, text=" 频率惩罚:", font=("微软雅黑", 9)).pack(
side=tk.LEFT, padx=(15, 0)
)
self.freq_var = tk.DoubleVar(value=self.config["frequency_penalty"])
ttk.Scale(
row3, from_=-2.0, to=2.0, variable=self.freq_var,
orient=tk.HORIZONTAL, length=80,
).pack(side=tk.LEFT, padx=(5, 5))
# ── 系统提示词栏 ──
sys_frame = ttk.Frame(self.root, padding=(10, 0, 10, 5))
sys_frame.pack(fill=tk.X)
ttk.Label(sys_frame, text="系统提示:", font=("微软雅黑", 9)).pack(side=tk.LEFT)
self.system_entry = ttk.Entry(sys_frame, width=80)
self.system_entry.insert(0, self.config["system_prompt"])
self.system_entry.pack(side=tk.LEFT, padx=(5, 0), fill=tk.X, expand=True)
ttk.Button(sys_frame, text="清空对话", command=self._clear_chat).pack(
side=tk.RIGHT
)
# ── 对话显示区域 ──
chat_frame = ttk.Frame(self.root, padding=(10, 0))
chat_frame.pack(fill=tk.BOTH, expand=True)
self.chat_display = scrolledtext.ScrolledText(
chat_frame, wrap=tk.WORD, font=("微软雅黑", 10),
bg="#f8f9fa", relief=tk.FLAT, borderwidth=1,
)
self.chat_display.pack(fill=tk.BOTH, expand=True)
# 文本标签样式(区分不同角色的消息)
self.chat_display.tag_config(
"user", foreground="#1a73e8", font=("微软雅黑", 10, "bold")
)
self.chat_display.tag_config(
"assistant", foreground="#188038", font=("微软雅黑", 10, "bold")
)
self.chat_display.tag_config(
"system_msg", foreground="#999999", font=("微软雅黑", 9)
)
self.chat_display.tag_config(
"error", foreground="#d93025", font=("微软雅黑", 10)
)
self.chat_display.tag_config("content", font=("微软雅黑", 10))
self.chat_display.config(state=tk.DISABLED)
# ── 底部输入区域 ──
input_frame = ttk.Frame(self.root, padding=(10, 5, 10, 10))
input_frame.pack(fill=tk.X)
self.input_text = scrolledtext.ScrolledText(
input_frame, height=4, wrap=tk.WORD,
font=("微软雅黑", 10), relief=tk.FLAT, borderwidth=1,
)
self.input_text.pack(side=tk.LEFT, fill=tk.BOTH, expand=True, padx=(0, 8))
self.send_btn = ttk.Button(
input_frame, text="发送", width=10, command=self._send_message
)
self.send_btn.pack(side=tk.RIGHT, expand=True)
# 绑定快捷键 Ctrl+Enter 发送
self.input_text.bind("<Control-Return>", lambda e: self._send_message())
# ── 底部状态栏 ──
self.status_bar = ttk.Label(
self.root, text="就绪", relief=tk.SUNKEN,
anchor=tk.W, font=("微软雅黑", 9),
)
self.status_bar.pack(fill=tk.X, side=tk.BOTTOM)
# ── 核心方法 ──
def _toggle_settings(self):
"""切换设置栏显示状态"""
if self.settings_visible.get():
self.settings_frame.pack_forget()
self.settings_visible.set(False)
else:
self.settings_frame.pack(
fill=tk.X, padx=10, pady=(0, 5)
)
self.settings_visible.set(True)
def _update_model_info(self):
model_id = self.model_var.get()
cfg = LLMClient.MODEL_CONFIG.get(model_id)
if cfg:
paid = "付费" if cfg["paid"] else "免费"
self.model_info_label.config(text=f"{cfg['name']} | {paid}")
def _open_register_url(self):
"""打开 AIGC bar 注册页面"""
import webbrowser
webbrowser.open("https://api.aigc.bar/register?aff=UP4F")
messagebox.showinfo(
"获取API密钥",
"已打开注册页面。注册后在控制台获取 API 密钥。",
)
def _save_config(self):
"""保存所有配置到本地"""
api_key = self.api_entry.get().strip()
if not api_key:
messagebox.showwarning("提示", "请输入 API 密钥")
return
self.config["api_key"] = api_key
self.config["model"] = self.model_var.get()
self.config["system_prompt"] = self.system_entry.get()
self.config["temperature"] = round(self.temp_var.get(), 1)
self.config["max_tokens"] = self.max_tokens_var.get()
self.config["top_p"] = round(self.top_p_var.get(), 1)
self.config["presence_penalty"] = round(self.presence_var.get(), 1)
self.config["frequency_penalty"] = round(self.freq_var.get(), 1)
save_config(self.config)
messagebox.showinfo("成功", "配置已保存,下次启动自动加载。")
def _clear_chat(self):
"""清空对话历史"""
self.messages = []
self.chat_display.config(state=tk.NORMAL)
self.chat_display.delete("1.0", tk.END)
self.chat_display.config(state=tk.DISABLED)
self._append_text("[系统] 对话已清空\n", "system_msg")
self.status_bar.config(text="对话已清空")
def _append_text(self, text: str, tag: str = "content"):
"""在对话区域追加文本(线程安全,可在后台线程调用)"""
self.chat_display.config(state=tk.NORMAL)
self.chat_display.insert(tk.END, text, tag)
self.chat_display.see(tk.END)
self.chat_display.config(state=tk.DISABLED)
def _set_input_state(self, enabled: bool):
"""设置输入区域状态"""
state = tk.NORMAL if enabled else tk.DISABLED
self.input_text.config(state=state)
self.send_btn.config(state=state)
if enabled:
self.input_text.focus_set()
def _send_message(self):
"""发送消息(主线程)"""
user_input = self.input_text.get("1.0", tk.END).strip()
if not user_input:
return
api_key = self.api_entry.get().strip()
if not api_key:
messagebox.showwarning("提示", "请先输入 API 密钥")
return
# 清空输入
self.input_text.delete("1.0", tk.END)
# 显示用户消息
self._append_text(f"\n你:\n", "user")
self._append_text(f"{user_input}\n", "content")
# 构建消息历史(短期记忆)
system_prompt = self.system_entry.get().strip() or "你是一个友好的AI助手。"
if not self.messages:
self.messages.append({"role": "system", "content": system_prompt})
self.messages.append({"role": "user", "content": user_input})
# 显示 AI 回复标签
self._append_text(f"\nAI:\n", "assistant")
# 禁用输入,开始请求
self._set_input_state(False)
model_id = self.model_var.get()
self.status_bar.config(text=f"AI 思考中...(模型: {model_id})")
# 收集参数
params = {
"temperature": self.temp_var.get(),
"max_tokens": self.max_tokens_var.get(),
"top_p": self.top_p_var.get(),
"presence_penalty": self.presence_var.get(),
"frequency_penalty": self.freq_var.get(),
}
# 在后台线程发起 API 调用(避免阻塞 UI)
Thread(
target=self._call_api_stream,
args=(api_key, model_id, params),
daemon=True,
).start()
def _call_api_stream(self, api_key: str, model_id: str, params: dict):
"""后台线程:流式调用 API"""
full_reply = ""
def on_chunk(text: str):
nonlocal full_reply
full_reply += text
# 通过 root.after 调度到主线程更新 UI
self.root.after(0, self._append_text, text, "content")
try:
client = LLMClient(model=model_id, api_key=api_key)
client.chat_stream(
self.messages,
on_chunk=on_chunk,
temperature=params["temperature"],
max_tokens=params["max_tokens"],
top_p=params["top_p"],
presence_penalty=params["presence_penalty"],
frequency_penalty=params["frequency_penalty"],
)
# 将 AI 回复加入短期记忆
self.messages.append({"role": "assistant", "content": full_reply})
# 在主线程更新状态
self.root.after(0, self._on_stream_done, full_reply)
except Exception as e:
self.root.after(0, self._on_error, str(e))
def _on_stream_done(self, reply_text: str):
"""流式完成处理"""
self._append_text("\n", "system_msg")
self._append_text("-" * 60 + "\n", "system_msg")
self.status_bar.config(
text=f"完成 | 输出长度: {len(reply_text)} 字符"
)
self._set_input_state(True)
def _on_error(self, error_msg: str):
"""错误处理"""
self._append_text(f"\n[错误] {error_msg}\n", "error")
self._append_text("-" * 60 + "\n", "system_msg")
self.status_bar.config(text=f"错误: {error_msg}")
self._set_input_state(True)
def _on_close(self):
"""关闭窗口时保存配置"""
cfg_fields = [
("model", self.model_var.get()),
("system_prompt", self.system_entry.get()),
("temperature", round(self.temp_var.get(), 1)),
("max_tokens", self.max_tokens_var.get()),
("top_p", round(self.top_p_var.get(), 1)),
("presence_penalty", round(self.presence_var.get(), 1)),
("frequency_penalty", round(self.freq_var.get(), 1)),
]
for key, val in cfg_fields:
self.config[key] = val
api_key = self.api_entry.get().strip()
if api_key:
self.config["api_key"] = api_key
save_config(self.config)
self.root.destroy()
def run(self):
"""启动应用"""
self.root.mainloop()
if __name__ == "__main__":
app = ChatWindow()
app.run()
程序功能清单:
| 功能模块 | 说明 |
|---|---|
| API 密钥管理 | 输入框(密码模式)+ 本地持久化保存,支持自动加载 |
| 获取 API 密钥 | 一键打开注册页面 https://api.aigc.bar/register?aff=UP4F |
| 模型选择 | 下拉框切换,显示当前模型信息(名称、付费/免费) |
| 参数设置(可折叠) | 温度(0-2)、最大Token(100-128000)、Top-P(0-1)、存在惩罚(-2-2)、频率惩罚(-2-2) |
| 系统提示词 | 自定义 system prompt 输入框 |
| 流式输出 | AI 回复逐字显示,无需等待完整生成 |
| 对话历史 | 维护短期记忆,支持清空重置 |
| 配置持久化 | 所有参数保存到 ~/.aigc_chat/config.json,下次启动自动加载 |
| 快捷键 | Ctrl+Enter 发送消息 |
| 错误处理 | 网络异常、API 错误等均有提示,不崩溃 |
7.5 单文件独立运行版
以下是一个完全独立的单文件版本,将 LLMClient 直接集成在同一个文件中,不依赖任何项目模块。复制保存为 chat.py,安装依赖后即可运行。
"""
AI 智能体聊天 - 单文件独立版
无需项目结构,一个文件即可运行
"""
import os
import time
import json
import tkinter as tk
from tkinter import ttk, messagebox, scrolledtext
from threading import Thread
from typing import List, Dict, Optional, Any, Callable
# ══════════════════════════════════════════════════════════════
# 第一部分:LLM 客户端(完全独立)
# ══════════════════════════════════════════════════════════════
class LLMClient:
"""统一的 LLM API 客户端,支持多模型切换与流式输出"""
BASE_URL = "https://api.aigc.bar/v1"
MODEL_CONFIG = {
"glm-5.2": {
"name": "GLM-5.2",
"desc": "智谱 GLM 系列,付费模型,智能体能力强",
"paid": True,
},
"deepseek-v4-flash": {
"name": "DeepSeek-V4-Flash",
"desc": "DeepSeek 系列,免费模型,速度快",
"paid": False,
},
}
def __init__(self, model: str = "deepseek-v4-flash",
api_key: Optional[str] = None,
base_url: Optional[str] = None):
self.model = model
if model not in self.MODEL_CONFIG:
raise ValueError(f"不支持的模型: {model},可选: {list(self.MODEL_CONFIG.keys())}")
self.api_key = api_key or os.environ.get("AIGC_API_KEY", "")
if not self.api_key:
raise ValueError("请设置 API Key,在 https://api.aigc.bar/register?aff=UP4F 注册后获取")
self.base_url = base_url or self.BASE_URL
try:
from openai import OpenAI
self.client = OpenAI(base_url=self.base_url, api_key=self.api_key)
except ImportError:
raise ImportError("请安装 openai 库: pip install openai")
def chat(self, messages: List[Dict[str, str]],
tools: Optional[List[Dict]] = None,
temperature: float = 0.7,
max_tokens: int = 10000,
**kwargs) -> Any:
"""非流式调用"""
kwargs.update({
"model": self.model, "messages": messages,
"temperature": temperature, "max_tokens": max_tokens,
})
if tools:
kwargs["tools"] = tools
kwargs["tool_choice"] = "auto"
for attempt in range(3):
try:
return self.client.chat.completions.create(**kwargs)
except Exception as e:
if attempt == 2:
raise
time.sleep(2 ** attempt)
def chat_stream(self, messages: List[Dict[str, str]],
on_chunk: Callable[[str], None],
tools: Optional[List[Dict]] = None,
temperature: float = 0.7,
max_tokens: int = 10000,
**kwargs) -> str:
"""流式调用"""
kwargs.update({
"model": self.model, "messages": messages,
"temperature": temperature, "max_tokens": max_tokens,
"stream": True, "stream_options": {"include_usage": True},
})
if tools:
kwargs["tools"] = tools
kwargs["tool_choice"] = "auto"
full_content = ""
for attempt in range(3):
try:
stream = self.client.chat.completions.create(**kwargs)
for chunk in stream:
delta = chunk.choices[0].delta if chunk.choices else None
if delta and delta.content:
full_content += delta.content
on_chunk(delta.content)
return full_content
except Exception as e:
if attempt == 2:
raise
time.sleep(2 ** attempt)
return full_content
# ══════════════════════════════════════════════════════════════
# 第二部分:配置管理
# ══════════════════════════════════════════════════════════════
CONFIG_DIR = os.path.join(os.path.expanduser("~"), ".aigc_chat")
CONFIG_FILE = os.path.join(CONFIG_DIR, "config.json")
DEFAULT_CONFIG = {
"api_key": "",
"model": "deepseek-v4-flash",
"system_prompt": "你是一个友好的AI助手。",
"temperature": 0.7,
"max_tokens": 10000,
"top_p": 1.0,
"presence_penalty": 0.0,
"frequency_penalty": 0.0,
}
def load_config():
if not os.path.exists(CONFIG_FILE):
return dict(DEFAULT_CONFIG)
try:
with open(CONFIG_FILE, "r", encoding="utf-8") as f:
data = json.load(f)
cfg = dict(DEFAULT_CONFIG)
cfg.update(data)
return cfg
except Exception:
return dict(DEFAULT_CONFIG)
def save_config(config: dict):
os.makedirs(CONFIG_DIR, exist_ok=True)
with open(CONFIG_FILE, "w", encoding="utf-8") as f:
json.dump(config, f, ensure_ascii=False, indent=2)
# ══════════════════════════════════════════════════════════════
# 第三部分:聊天窗口
# ══════════════════════════════════════════════════════════════
class ChatWindow:
"""主聊天窗口"""
def __init__(self):
self.root = tk.Tk()
self.root.title("AI 智能体聊天 - 单文件版")
self.root.geometry("950x750")
self.root.minsize(750, 550)
self.config = load_config()
self.messages = []
self.settings_visible = tk.BooleanVar(value=False)
self._build_ui()
self.root.protocol("WM_DELETE_WINDOW", self._on_close)
def _build_ui(self):
# API 密钥栏
api_frame = ttk.Frame(self.root, padding=(10, 8))
api_frame.pack(fill=tk.X)
ttk.Label(api_frame, text="API密钥:", font=("微软雅黑", 9)).pack(side=tk.LEFT)
self.api_entry = ttk.Entry(api_frame, width=50, show="*")
self.api_entry.pack(side=tk.LEFT, padx=(5, 0), fill=tk.X, expand=True)
if self.config.get("api_key"):
self.api_entry.insert(0, self.config["api_key"])
ttk.Button(api_frame, text="获取API密钥",
command=self._open_register_url).pack(side=tk.LEFT, padx=(5, 0))
ttk.Button(api_frame, text="保存配置",
command=self._save_config).pack(side=tk.LEFT, padx=(5, 0))
ttk.Button(api_frame, text="展开设置", width=10,
command=self._toggle_settings).pack(side=tk.RIGHT, padx=(5, 0))
# 设置栏
self.settings_frame = ttk.LabelFrame(self.root, text="参数设置", padding=(10, 5))
row1 = ttk.Frame(self.settings_frame)
row1.pack(fill=tk.X, pady=2)
ttk.Label(row1, text="模型:", font=("微软雅黑", 9)).pack(side=tk.LEFT)
self.model_var = tk.StringVar(value=self.config["model"])
ttk.Combobox(row1, textvariable=self.model_var,
values=list(LLMClient.MODEL_CONFIG.keys()),
state="readonly", width=22).pack(side=tk.LEFT, padx=(5, 0))
row2 = ttk.Frame(self.settings_frame)
row2.pack(fill=tk.X, pady=2)
ttk.Label(row2, text="温度:", font=("微软雅黑", 9)).pack(side=tk.LEFT)
self.temp_var = tk.DoubleVar(value=self.config["temperature"])
ttk.Scale(row2, from_=0.0, to=2.0, variable=self.temp_var,
orient=tk.HORIZONTAL, length=100).pack(side=tk.LEFT, padx=(5, 5))
ttk.Label(row2, text=" 最大Token:", font=("微软雅黑", 9)).pack(side=tk.LEFT, padx=(15, 0))
self.max_tokens_var = tk.IntVar(value=self.config["max_tokens"])
ttk.Spinbox(row2, from_=100, to=128000, increment=100,
textvariable=self.max_tokens_var, width=8).pack(side=tk.LEFT, padx=(5, 0))
row3 = ttk.Frame(self.settings_frame)
row3.pack(fill=tk.X, pady=2)
ttk.Label(row3, text="Top-P:", font=("微软雅黑", 9)).pack(side=tk.LEFT)
self.top_p_var = tk.DoubleVar(value=self.config["top_p"])
ttk.Scale(row3, from_=0.0, to=1.0, variable=self.top_p_var,
orient=tk.HORIZONTAL, length=80).pack(side=tk.LEFT, padx=(5, 5))
ttk.Label(row3, text=" 存在惩罚:", font=("微软雅黑", 9)).pack(side=tk.LEFT, padx=(15, 0))
self.presence_var = tk.DoubleVar(value=self.config["presence_penalty"])
ttk.Scale(row3, from_=-2.0, to=2.0, variable=self.presence_var,
orient=tk.HORIZONTAL, length=80).pack(side=tk.LEFT, padx=(5, 5))
ttk.Label(row3, text=" 频率惩罚:", font=("微软雅黑", 9)).pack(side=tk.LEFT, padx=(15, 0))
self.freq_var = tk.DoubleVar(value=self.config["frequency_penalty"])
ttk.Scale(row3, from_=-2.0, to=2.0, variable=self.freq_var,
orient=tk.HORIZONTAL, length=80).pack(side=tk.LEFT, padx=(5, 5))
# 系统提示词
sys_frame = ttk.Frame(self.root, padding=(10, 0, 10, 5))
sys_frame.pack(fill=tk.X)
ttk.Label(sys_frame, text="系统提示:", font=("微软雅黑", 9)).pack(side=tk.LEFT)
self.system_entry = ttk.Entry(sys_frame, width=80)
self.system_entry.insert(0, self.config["system_prompt"])
self.system_entry.pack(side=tk.LEFT, padx=(5, 0), fill=tk.X, expand=True)
ttk.Button(sys_frame, text="清空对话", command=self._clear_chat).pack(side=tk.RIGHT)
# 对话显示区域
chat_frame = ttk.Frame(self.root, padding=(10, 0))
chat_frame.pack(fill=tk.BOTH, expand=True)
self.chat_display = scrolledtext.ScrolledText(
chat_frame, wrap=tk.WORD, font=("微软雅黑", 10),
bg="#f8f9fa", relief=tk.FLAT, borderwidth=1,
)
self.chat_display.pack(fill=tk.BOTH, expand=True)
self.chat_display.tag_config("user", foreground="#1a73e8",
font=("微软雅黑", 10, "bold"))
self.chat_display.tag_config("assistant", foreground="#188038",
font=("微软雅黑", 10, "bold"))
self.chat_display.tag_config("system_msg", foreground="#999999",
font=("微软雅黑", 9))
self.chat_display.tag_config("error", foreground="#d93025",
font=("微软雅黑", 10))
self.chat_display.tag_config("content", font=("微软雅黑", 10))
self.chat_display.config(state=tk.DISABLED)
# 输入区域
input_frame = ttk.Frame(self.root, padding=(10, 5, 10, 10))
input_frame.pack(fill=tk.X)
self.input_text = scrolledtext.ScrolledText(
input_frame, height=4, wrap=tk.WORD,
font=("微软雅黑", 10), relief=tk.FLAT, borderwidth=1,
)
self.input_text.pack(side=tk.LEFT, fill=tk.BOTH, expand=True, padx=(0, 8))
self.send_btn = ttk.Button(input_frame, text="发送", width=10,
command=self._send_message)
self.send_btn.pack(side=tk.RIGHT, expand=True)
self.input_text.bind("<Control-Return>", lambda e: self._send_message())
# 状态栏
self.status_bar = ttk.Label(self.root, text="就绪", relief=tk.SUNKEN,
anchor=tk.W, font=("微软雅黑", 9))
self.status_bar.pack(fill=tk.X, side=tk.BOTTOM)
def _toggle_settings(self):
if self.settings_visible.get():
self.settings_frame.pack_forget()
self.settings_visible.set(False)
else:
self.settings_frame.pack(fill=tk.X, padx=10, pady=(0, 5))
self.settings_visible.set(True)
def _open_register_url(self):
import webbrowser
webbrowser.open("https://api.aigc.bar/register?aff=UP4F")
messagebox.showinfo("获取API密钥", "已打开注册页面。")
def _save_config(self):
api_key = self.api_entry.get().strip()
if not api_key:
messagebox.showwarning("提示", "请输入 API 密钥")
return
self.config["api_key"] = api_key
self.config["model"] = self.model_var.get()
self.config["system_prompt"] = self.system_entry.get()
self.config["temperature"] = round(self.temp_var.get(), 1)
self.config["max_tokens"] = self.max_tokens_var.get()
self.config["top_p"] = round(self.top_p_var.get(), 1)
self.config["presence_penalty"] = round(self.presence_var.get(), 1)
self.config["frequency_penalty"] = round(self.freq_var.get(), 1)
save_config(self.config)
messagebox.showinfo("成功", "配置已保存。")
def _clear_chat(self):
self.messages = []
self.chat_display.config(state=tk.NORMAL)
self.chat_display.delete("1.0", tk.END)
self.chat_display.config(state=tk.DISABLED)
self._append_text("[系统] 对话已清空\n", "system_msg")
self.status_bar.config(text="对话已清空")
def _append_text(self, text: str, tag: str = "content"):
self.chat_display.config(state=tk.NORMAL)
self.chat_display.insert(tk.END, text, tag)
self.chat_display.see(tk.END)
self.chat_display.config(state=tk.DISABLED)
def _set_input_state(self, enabled: bool):
state = tk.NORMAL if enabled else tk.DISABLED
self.input_text.config(state=state)
self.send_btn.config(state=state)
if enabled:
self.input_text.focus_set()
def _send_message(self):
user_input = self.input_text.get("1.0", tk.END).strip()
if not user_input:
return
api_key = self.api_entry.get().strip()
if not api_key:
messagebox.showwarning("提示", "请先输入 API 密钥")
return
self.input_text.delete("1.0", tk.END)
self._append_text(f"\n你:\n", "user")
self._append_text(f"{user_input}\n", "content")
system_prompt = self.system_entry.get().strip() or "你是一个友好的AI助手。"
if not self.messages:
self.messages.append({"role": "system", "content": system_prompt})
self.messages.append({"role": "user", "content": user_input})
self._append_text(f"\nAI:\n", "assistant")
self._set_input_state(False)
model_id = self.model_var.get()
self.status_bar.config(text=f"AI 思考中...(模型: {model_id})")
params = {
"temperature": self.temp_var.get(),
"max_tokens": self.max_tokens_var.get(),
"top_p": self.top_p_var.get(),
"presence_penalty": self.presence_var.get(),
"frequency_penalty": self.freq_var.get(),
}
Thread(target=self._call_api, args=(api_key, model_id, params),
daemon=True).start()
def _call_api(self, api_key: str, model_id: str, params: dict):
full_reply = ""
def on_chunk(text: str):
nonlocal full_reply
full_reply += text
self.root.after(0, self._append_text, text, "content")
try:
client = LLMClient(model=model_id, api_key=api_key)
client.chat_stream(
self.messages, on_chunk=on_chunk, **params
)
self.messages.append({"role": "assistant", "content": full_reply})
self.root.after(0, self._on_done, full_reply)
except Exception as e:
self.root.after(0, self._on_error, str(e))
def _on_done(self, reply_text: str):
self._append_text("\n", "system_msg")
self._append_text("-" * 60 + "\n", "system_msg")
self.status_bar.config(text=f"完成 | 输出长度: {len(reply_text)} 字符")
self._set_input_state(True)
def _on_error(self, error_msg: str):
self._append_text(f"\n[错误] {error_msg}\n", "error")
self._append_text("-" * 60 + "\n", "system_msg")
self.status_bar.config(text=f"错误: {error_msg}")
self._set_input_state(True)
def _on_close(self):
self.config["model"] = self.model_var.get()
self.config["system_prompt"] = self.system_entry.get()
self.config["temperature"] = round(self.temp_var.get(), 1)
self.config["max_tokens"] = self.max_tokens_var.get()
self.config["top_p"] = round(self.top_p_var.get(), 1)
self.config["presence_penalty"] = round(self.presence_var.get(), 1)
self.config["frequency_penalty"] = round(self.freq_var.get(), 1)
api_key = self.api_entry.get().strip()
if api_key:
self.config["api_key"] = api_key
save_config(self.config)
self.root.destroy()
def run(self):
self.root.mainloop()
if __name__ == "__main__":
ChatWindow().run()
7.6 运行与使用指南
环境要求:
- Python 3.8+
- 安装依赖:
pip install openai
运行方式:
# 方式一:使用完整项目结构
cd llm-agent-project
pip install -r requirements.txt
python examples/gui_chat.py
# 方式二:使用单文件独立版
# 将 7.5 节的代码保存为 chat.py
pip install openai
python chat.py
使用流程:
- 启动程序后,点击"获取API密钥"按钮,浏览器会自动打开 AIGC bar 注册页面
- 注册账号后,在控制台获取 API 密钥
- 将密钥粘贴到输入框,点击"保存配置"
- 在输入框输入问题,点击"发送"或按
Ctrl+Enter - AI 回复会以流式方式逐字显示,无需等待
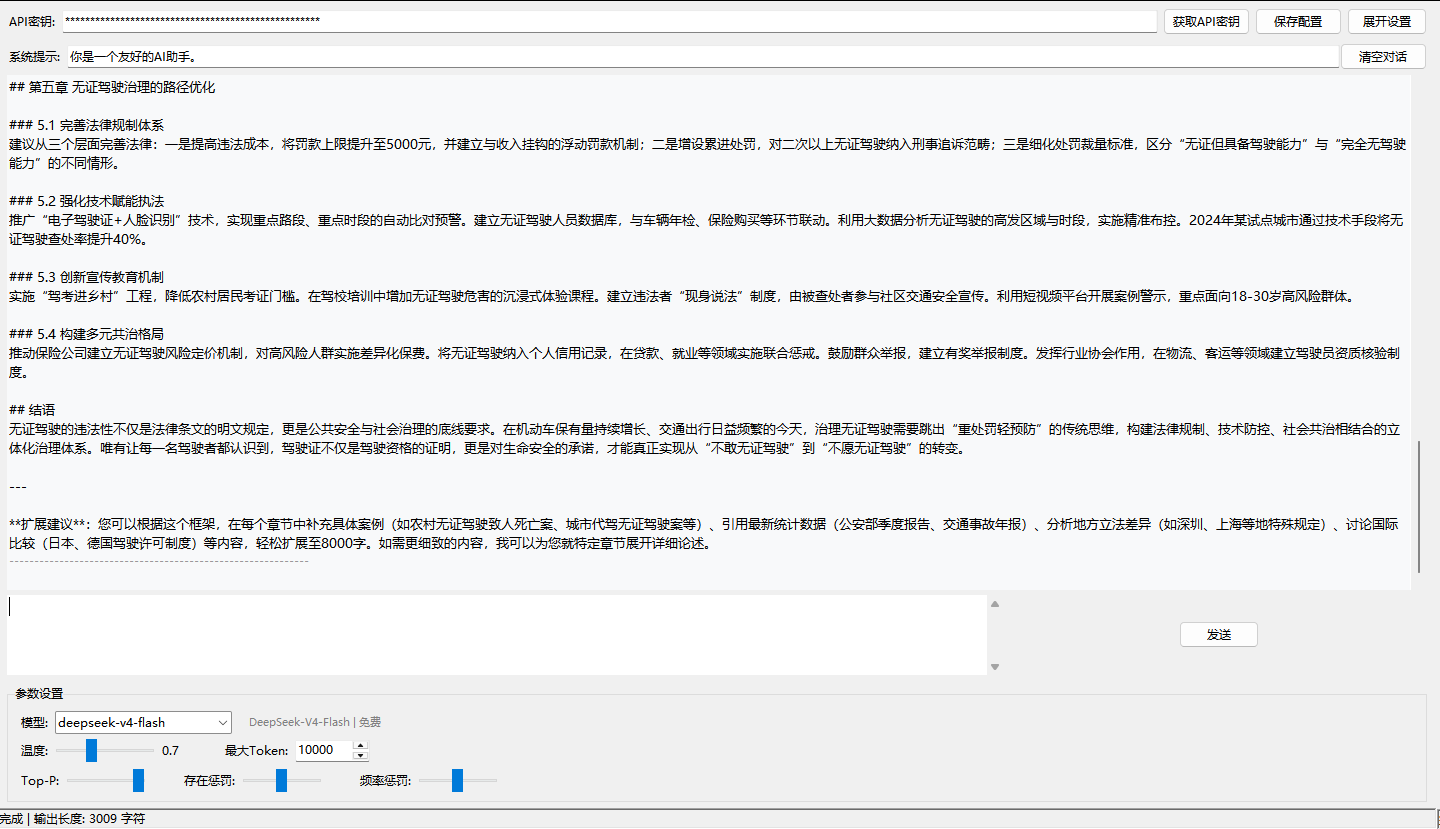
参数说明:
| 参数 | 范围 | 说明 |
|---|---|---|
| 温度(Temperature) | 0.0 - 2.0 | 越低越确定,越高越有创造性。日常对话 0.7,代码生成 0.2 |
| 最大输出Token | 100 - 50000 | 限制单次回复的最大长度。默认 10000 |
| Top-P | 0.0 - 1.0 | 核采样参数,与温度配合使用。通常保持 1.0 |
| 存在惩罚 | -2.0 - 2.0 | 正值鼓励模型谈论新话题,负值允许重复。默认 0 |
| 频率惩罚 | -2.0 - 2.0 | 正值降低逐字重复,负值允许重复。默认 0 |
8 部署、评估与未来展望
8.1 智能体评估指标
智能体的评估比传统 LLM 更为复杂,因为智能体的输出不仅是一段文本,而是一个包含多步推理、多次工具调用的完整执行轨迹。评估需要从多个维度综合考量。
| 评估维度 | 核心指标 | 评估方法 | 优化方向 |
|---|---|---|---|
| 任务效果 | 任务完成率 | 人工/自动评测 | 提示优化、模型升级 |
| 工具使用 | 调用准确率 | 对比标注 | 工具描述优化 |
| 效率 | 平均步数/Token | 日志统计 | 规划优化、上下文压缩 |
| 鲁棒性 | 异常恢复率 | 故障注入 | 错误处理、重试机制 |
| 安全性 | 越狱成功率 | 红队测试 | 安全提示、输出过滤 |
8.2 部署方案与工程考量
对于本文的桌面对话程序,部署非常简单——用户安装 Python 环境后直接运行即可。如果要将类似功能扩展到生产环境,容器化部署(Docker)是推荐的方案。
成本控制是智能体部署的关键考量。多模型路由是有效的成本优化策略——简单任务用免费或低成本模型(如 deepseek-v4-flash),复杂任务用高性能模型(如 GLM-5.2)。此外,缓存机制可以避免重复调用。
安全性方面,本程序通过密码模式隐藏 API 密钥,密钥以 JSON 格式存储在用户目录下,避免了在代码中硬编码密钥的安全风险。
8.3 未来发展方向
大模型智能体仍处于快速发展阶段,多个方向值得关注。
多模态智能体是重要趋势——未来的智能体不仅能处理文本,还能理解图像、视频、音频等多模态输入。本文的客户端封装可以轻松扩展支持多模态 API。
多智能体系统(Multi-Agent System) 是另一个前沿方向。多个专精不同领域的智能体协作,可以解决更复杂的任务。
自我进化(Self-Evolution) 能力是智能体的终极目标之一。当前的智能体主要依赖人工设计的提示与工具,而未来的智能体应能自主发现新工具、优化自身提示、从经验中学习。
回顾本文,我们从智能体的理论起源出发,系统梳理了 LLM 智能体的架构、记忆、规划、工具调用等核心机制,并结合 GLM 与 DeepSeek 两大主流模型族的技术原理,给出了一个完整的桌面窗体对话程序作为实战项目。智能体技术正在重塑人与 AI 的交互方式,从被动问答走向主动执行,从单轮对话走向自主任务完成。希望本文能为读者构建自己的智能体提供理论与实践的参考。
参考文献
-
Yao, S., Zhao, J., Yu, D., et al. “ReAct: Synergizing Reasoning and Acting in Language Models.” ICLR 2023. https://arxiv.org/abs/2210.03629
-
Wang, L., Ma, C., Feng, X., et al. “A Survey on Large Language Model based Autonomous Agents.” Frontiers of Computer Science, 2024. https://arxiv.org/abs/2308.11432
-
Xi, Z., Chen, W., Guo, X., et al. “The Rise and Potential of Large Language Model Based Agents: A Survey.” arXiv preprint, 2023. https://arxiv.org/abs/2309.07864
-
Shinn, N., Cassano, F., Berman, E., et al. “Reflexion: Language Agents with Verbal Reinforcement Learning.” NeurIPS 2023. https://arxiv.org/abs/2303.11366
-
Schick, T., Dwivedi-Yu, J., Dessì, R., et al. “Toolformer: Language Models Can Teach Themselves to Use Tools.” NeurIPS 2023. https://arxiv.org/abs/2302.04761
-
Yao, S., Yu, D., Zhao, J., et al. “Tree of Thoughts: Deliberate Problem Solving with Large Language Models.” NeurIPS 2023. https://arxiv.org/abs/2305.10601
-
Wei, J., Wang, X., Schuurmans, D., et al. “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models.” NeurIPS 2022. https://arxiv.org/abs/2201.11903
-
Lewis, P., Perez, E., Piktus, A., et al. “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.” NeurIPS 2020. https://arxiv.org/abs/2005.11401
-
DeepSeek-AI. “DeepSeek-V3 Technical Report.” arXiv preprint, 2024. https://arxiv.org/abs/2412.19437
-
Z.ai. “GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models.” Z.ai Official Blog, 2025. https://z.ai/blog/glm-4.5

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 8
8 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)