【OpenClaw】非视觉模型处理微信图文消息:三层架构方案
DeepSeek 不是 VLM 模型,微信发来图片+文字就超时或秒回"看不到图片"?本文给出完整的三层架构方案,让任何文本模型都能处理图文混合消息。
文章目录
问题场景
用 DeepSeek V4 Flash 作为 openclaw 主模型,用户通过微信发送一条消息包含图片 + 文字描述,期望 AI 理解图片内容后结合文字给出回复。实际发生的是:
微信发图+文 → DeepSeek → 30-900 秒超时 → Request timed out
# 或者
微信发图+文 → DeepSeek → 0.5 秒回复 "你没附带图片,我看不到"
根因很简单:DeepSeek V4 Flash 在本文环境中作为纯文本主模型使用,不具备视觉能力。openclaw 把整张图片(base64)塞进 prompt,模型处理不过来。
同样的问题也出现在文档附件(.docx、.pdf)——模型收到后秒回"没有文件"。
我的日常工作模式
在展开方案之前,先介绍一下我的主力工具链——这套组合可以在一台 Windows 机器上运转:
| 工具 | 角色 | 说明 |
|---|---|---|
| Claude Code | 主力编程助手 | Windows 原生,负责代码审查、重构、项目开发 |
| DeepSeek V4 Flash | openclaw 主模型 | 通过 API 调用,处理微信日常对话、翻译审校 |
| WSL Codex (OpenAI Codex CLI) | 图片分析 / 疑难咨询 | WSL2 Ubuntu 内运行,Plus 会员调用 GPT-5.5 |
| openclaw | AI 网关 | 部署在 Windows 宿主机,对接微信渠道,统一调度模型 |
为什么需要 Codex
Codex CLI 在 WSL 里运行,Plus 会员可以调用 GPT-5.5——它有原生的视觉能力。当 DeepSeek(无视觉)收到微信图片时,由 Codex 负责看图并返回文字描述,DeepSeek 再基于描述回复用户。
Claude Code ← 主力编码
DeepSeek ← 微信对话主引擎
Codex ← 图片分析 / 难题介入
三者在 openclaw 的调度下协同,用户只需在微信里发消息,感受不到背后的模型切换。
目标
实现一个三层架构,让用户感觉不到模型的能力边界:
- 图片+文字 → 自动分析图片,结合用户文字给出一次合并回复
- 文档+文字 → 自动提取文档内容,结合用户文字给出一次合并回复
- 尽量不回复"看不到图片"或"没文件"(LLM 行为无法 100% 保证,但规则可以显著降低概率)
实际效果演示
场景一:图+文
用户在微信发了一张截图,附带文字 “这个报错是什么意思?”
用户发送: [一张 openclaw 报错截图] 这个报错是什么意思?
openclaw 回复 (一次合并):
这张截图显示 openclaw 的 Agent 回复前失败,原因是 session
文件被锁定超时。错误提示包含进程 ID 37392 和锁文件路径,
建议用 `openclaw logs --follow` 查看详细日志。大概率是
之前的会话异常退出后锁文件未释放,重启 Gateway 可以解决。
需要我帮你重启吗?
背后发生的事:tools.media 拦截图片 → codex-image-analyze.mjs → WSL Codex 分析 → DeepSeek 收到"图片描述 + 用户文字"→ 合并回复。
场景二:文档+文
用户在微信发了一个 .docx 文件,附带文字 “帮我审校这份技术方案”
用户发送: [附件2_低空智联网关键技术研究-详细设计说明书.docx] 帮我审校这份技术方案
openclaw 回复 (一次合并):
这份文档是"低空数据安全自动化分级关键技术研究"的详细设计说明书。
我看了下内容,结构完整,包含系统架构、数据流设计、安全分级
算法等核心章节。有几个建议:
1. 第3章的API接口定义缺少错误码说明
2. 安全分级标准建议引用国标GB/T 39786-2021
3. 性能指标部分缺压力测试数据
需要我展开修改某个章节吗?
背后发生的事:LLM 收到文档附件标记 → 用 exec 调 python-docx 提取文本 → 结合用户文字审校 → 合并回复。
架构概览
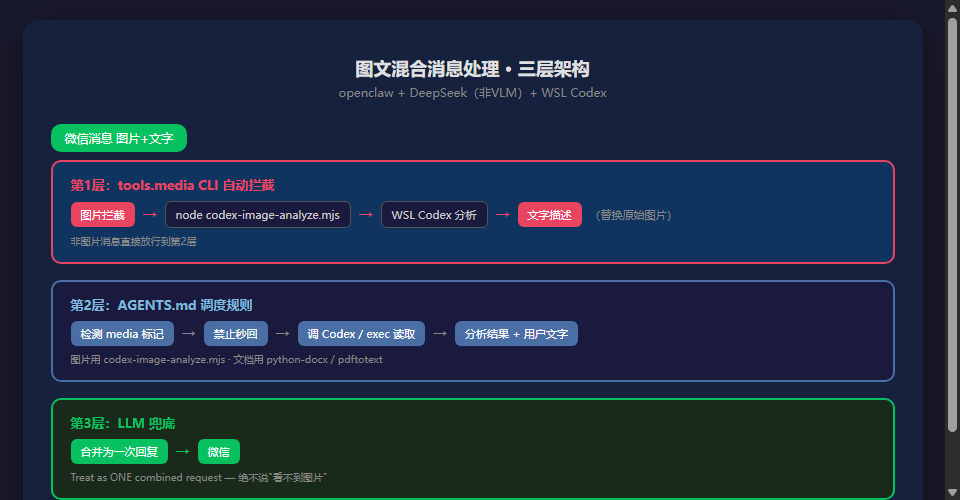
如果图片未显示,以下是等价的 Mermaid 结构图:
第1层:tools.media CLI 自动拦截
openclaw 2026.6.10 的 tools.media 配置支持 CLI 类型的图片处理:
{
"tools": {
"media": {
"image": {
"models": [
{
"type": "cli",
"command": "node",
"args": [
"C:\\Users\\<用户名>\\.openclaw\\scripts\\codex-image-analyze.mjs",
"{{MediaPath}}"
],
"maxChars": 500, // 描述上限;复杂图可调至 1000-2000
"maxBytes": 10485760, // 10MB 图片上限
"timeoutSeconds": 120 // Codex 分析超时
}
]
}
}
}
}
这层在消息到达 LLM 之前拦截图片,调用本地脚本转成文字描述。
codex-image-analyze.mjs
脚本的核心逻辑是:接收 Windows 路径 → 转 WSL 路径 → stdin 传给 Codex → 返回文字:
import { spawn } from "node:child_process";
const mediaPath = process.argv[2];
// C:\Users\...\xxx.jpg → /mnt/c/Users/.../xxx.jpg
const wslPath = mediaPath
.replace(/\\/g, "/")
.replace(/^([A-Z]):/i, (_, d) => `/mnt/${d.toLowerCase()}`);
const prompt = `Analyze this image: ${wslPath}.
Reply in Chinese, concise, one paragraph.`;
const proc = spawn("wsl.exe", [
"-e", "bash", "-c",
"cd /mnt/d/AI/openclaw ; timeout 90 codex exec"
], { timeout: 120_000 });
let stdout = "";
proc.stdout.on("data", d => { stdout += d.toString(); });
proc.on("close", code => {
if (code !== 0) process.exit(code ?? 1);
// 提取 Codex 的最后一段回复
const lines = stdout.split("\n");
for (let i = lines.length - 1; i >= 0; i--) {
if (lines[i].trim() === "codex") {
console.log(lines.slice(i + 1).join("\n").trim());
process.exit(0);
}
}
console.log(stdout.trim());
});
proc.stdin.write(prompt);
proc.stdin.end();
关键细节:用 stdin 传 prompt 而非命令行参数,避免嵌套引号转义地狱。
💡 替换为你的视觉模型:本文使用 WSL Codex 是因为我本地刚好有 Codex CLI。你可以把
analyzeImageViaWsl函数中的wsl.exe codex exec替换为任何视觉模型 API 调用:
- OpenAI GPT-4o / GPT-5:调用
https://api.openai.com/v1/chat/completions,传图片 base64- Gemini:调用 Gemini API 或使用 Gemini CLI
- Qwen-VL:通过 DashScope / 阿里云 API
- 本地 Ollama:
ollama run llava "描述这张图片: <path>"只需要改
spawn的目标——输入 Windows 路径,输出中文描述,其余架构不变。
第2层:AGENTS.md 调度规则
tools.media 可能因为脚本失败、超时或配置未加载而没产出分析结果。第2层是 AGENTS.md 中的显式规则,告诉 LLM 必须处理附件:
## Image Dispatch (Highest Priority)
→ The image IS attached. Do NOT reply "no image attached"
→ tools.media analyzes the image via Codex before you see the message
→ **Treat the Codex image analysis + user text as ONE combined request.**
Merge both into a single cohesive reply.
→ If no analysis result, call Codex via the bundled script:
node "C:\Users\<用户名>\.openclaw\scripts\codex-image-analyze.mjs" \
"<image_path_from_media_marker>"
Do NOT modify or concatenate the path.
## Document & File Handling
→ The file IS attached. Do NOT reply "no file attached"
→ Read using available tools (python-docx, pdftotext, etc.)
→ Respond based on actual content
为什么必须写成"规则"而非"建议"
早期版本写的是"route to WSL Codex"这种模糊指令——LLM 会回复"好的我来调 Codex"然后继续干别的。
三处关键措辞:
| 措辞 | 效果 |
|---|---|
Do NOT reply "no image attached" |
负向约束,阻止最快路径 |
Treat as ONE combined request |
正向指令,强调整合 |
Do NOT modify or concatenate the path |
防 LLM 拼接路径出错 |
第3层:LLM 自身兜底
如果前两层都失败(极端情况),LLM 仍然可以自己判断:看到 [media attached: ...] 标记 → 知道有附件 → 用 exec 工具调 Codex 脚本。
三层下来,用户永远不会看到"看不到图片"这种回复。
文档处理为什么不用 Codex
图片必须走 Codex 是因为主模型 DeepSeek 没有视觉能力——这是硬限制。
文档(.docx、.pdf)不同——LLM 可以用 exec 工具直接调用 python-docx 或 pdftotext 提取文本,不需要外部模型。
依赖安装:
.docx需要pip install python-docx,PDF 需要pdftotext(poppler-utils)或PyPDF2。扫描版 PDF 需要额外 OCR(Tesseract),本文方案不涵盖扫描件。
# LLM 可以自己执行
python -c "from docx import Document; doc=Document('file.docx'); \
print('\n'.join([p.text for p in doc.paragraphs]))"
所以文档只用了第2层(AGENTS.md 规则)和第3层(LLM 兜底),没有第1层自动拦截。
踩坑记录
| # | 坑 | 根因 | 解决 |
|---|---|---|---|
| 1 | tools.media Command failed |
PowerShell 脚本嵌套引号转义错误 | 改用 Node.js + stdin 传参 |
| 2 | LLM 回复"没看到图片" | AGENTS.md 规则太模糊,LLM 走最快路径 | 加 Do NOT reply 负向约束 |
| 3 | LLM 把图片分析和文字分开回复 | 没强调整合 | 加 Treat as ONE combined request |
| 4 | LLM 调 wsl.exe 路径拼接错误 |
LLM 不会正确构造 WSL 路径 | 改用封装好的 .mjs 脚本 |
| 5 | before_dispatch hook 从未触发 |
openclaw #5513 已知 bug | 放弃 hook,改用 AGENTS.md 规则驱动 |
| 6 | 图片超时 900 秒 | 系统 prompt 太大(45KB) | 裁剪 AGENTS.md 到 3KB,prompt 降 30% |
最终效果
用户: [一张截图] 这个报错是什么意思?
AI: 这张截图显示 openclaw 的 Agent 回复前失败,原因是 session
文件被锁定超时。错误信息提示进程 ID 和锁文件路径,建议用
`openclaw logs --follow` 查看详细日志。大概率是之前的会话异常
退出后锁文件未释放,重启 Gateway 可以解决。
一次回复,图文整合,用户无感。
关键文件清单
~/.openclaw/
├── openclaw.json # tools.media CLI 配置
├── scripts/codex-image-analyze.mjs # WSL Codex 图片分析脚本
└── workspace/AGENTS.md # Image Dispatch + Document Rules
环境:openclaw 2026.6.10 + DeepSeek V4 Flash + WSL2 Codex + Windows 11
代码仓库
codex-image-analyze.mjs 完整源码:https://gitcode.com/gcw_A202cbBm/codex-image-analyze
如果您觉得有用,欢迎 点赞、转发、评论、关注。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 1
1 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)