个人独立开发者最优方案:三款工具分段使用的轻量化高效工作流
一、前言:独立开发者的核心痛点与AI工具误区
对于个人独立开发者而言,开发效率、成本控制、项目轻量化是三大核心诉求。不同于团队开发有分工协作、代码评审、运维支撑,个人开发者需要独立包揽需求梳理、代码编写、调试纠错、功能优化、部署上线全流程工作。在传统开发模式下,一个中小型项目从0到1落地,往往需要耗费大量时间在重复编码、语法纠错、逻辑调试上,迭代速度慢、试错成本高。
随着AI编码工具普及,Codex、Cursor、Claude Code成为开发者主流辅助工具,但绝大多数个人开发者都陷入了单一工具滥用的误区:要么全程只用Cursor写代码,要么单纯依赖Claude Code处理终端逻辑,没有结合三款工具的核心优势做分段分工。最终出现AI生成代码冗余、逻辑漏洞多、调试效率低、代码幻觉频发等问题,不仅没有提效,反而需要花费更多时间修正AI错误。
三款主流AI编码工具各有核心定位:Cursor主打IDE内实时编码、代码补全、文件结构化开发;Claude Code擅长终端命令执行、项目工程化处理、批量脚本运维;Codex专注算法逻辑优化、核心业务逻辑推演、代码精简重构。基于三者的差异化优势,我打磨出一套三段式轻量化AI开发工作流,适配个人独立开发全场景,无需复杂配置、无需团队协作,单人即可实现「需求梳理→开发编码→调试优化→工程落地」全流程高效闭环,完美适配小程序、后端接口、工具类项目、轻量化网站等个人开发场景。
二、三款AI工具核心差异化定位(分段分工基础)
想要实现高效分段工作流,首先要摒弃“一款工具走到底”的思维,精准区分三款工具的能力边界,让每款工具各司其职,避免功能重叠、无效消耗。结合长期实战经验,总结出三款工具的专属分工场景:
1. Cursor:核心编码阶段主力(IDE内置开发):深耕代码结构化编写,支持多文件联动开发、实时语法校验、模板代码生成,适合项目初始化、业务代码编写、接口封装、前端页面开发,是代码落地的核心载体。优势是贴合开发习惯,所见即所得,生成的代码结构规范、可读性高。
2. Claude Code:工程运维阶段主力(终端自动化):主打命令行交互、批量文件处理、依赖安装、项目打包、错误日志排查、自动化脚本编写,擅长处理IDE之外的工程化工作,解决个人开发者运维能力薄弱的问题。优势是批量处理能力强,可自动化完成重复性工程操作。
3. Codex:逻辑优化阶段主力(算法&核心逻辑打磨):专注代码逻辑推演、算法优化、冗余代码精简、边界场景处理,能够精准识别业务逻辑漏洞、优化代码性能、规避逻辑bug,弥补Cursor、Claude Code核心逻辑思考不足、容易产生代码幻觉的短板。
基于以上定位,我将个人开发全流程划分为「项目搭建与编码、工程调试与运维、逻辑重构与优化」三个核心阶段,每个阶段匹配专属AI工具,形成闭环轻量化工作流。
三、轻量化三段式AI开发工作流整体架构
整套工作流摒弃复杂的工具联动配置,全程轻量化操作,无冗余步骤、无环境依赖负担,完全适配个人单人开发模式。整体流程遵循「分工明确、逐级递进、查漏补缺」的核心原则,大幅降低单人开发的试错成本和时间成本。
整体工作流核心优势:不混用工具、不重复劳作、精准补位短板。Cursor保证代码快速落地,Claude Code解决工程化繁琐操作,Codex兜底核心逻辑质量,三者分段配合,彻底解决单人开发效率低、代码质量差、调试困难的痛点。
四、全流程实战场景:个人轻量化后端工具项目落地
为了直观展示工作流落地效果,我以个人日常开发常用的「轻量化文件批量处理工具」为实战场景,完整演示三段式工作流的落地全过程。该项目为个人自用工具,核心需求是实现本地文件批量重命名、格式转换、空文件清理,属于个人独立开发典型场景,轻量化、实用性强、适配绝大多数个人开发需求。
4.1 阶段一:Cursor 负责项目初始化与业务代码编写
本阶段核心目标:快速完成项目搭建、目录结构规划、核心业务代码落地,实现基础功能可用。Cursor作为IDE内置工具,最适合结构化代码开发,无需手动搭建繁琐的项目模板。
我向Cursor下达精准指令:「基于Python搭建轻量化文件处理工具,实现文件批量重命名、TXT转MD格式、空文件删除功能,目录结构简洁适配个人使用,代码注释完整,结构分层清晰」。Cursor快速完成项目初始化与核心代码编写,生成可直接运行的业务代码。
Cursor生成核心业务代码(文件处理工具主逻辑)
import os
import datetime
class FileBatchTool:
"""个人轻量化文件批量处理工具"""
def __init__(self, target_path):
self.target_path = target_path
# 校验目标路径合法性
if not os.path.exists(target_path):
raise Exception("目标文件夹路径不存在")
def batch_rename(self, prefix="file"):
"""批量文件重命名,保留文件后缀"""
file_list = os.listdir(self.target_path)
count = 1
for file_name in file_list:
file_path = os.path.join(self.target_path, file_name)
# 跳过文件夹,仅处理文件
if os.path.isdir(file_path):
continue
# 分割文件名和后缀
name_suffix = os.path.splitext(file_name)
new_name = f"{prefix}_{count}{name_suffix[1]}"
new_path = os.path.join(self.target_path, new_name)
os.rename(file_path, new_path)
count += 1
return f"批量重命名完成,共处理{count-1}个文件"
def txt_to_md(self):
"""批量将文件夹内TXT文件转换为MD文件"""
file_list = os.listdir(self.target_path)
count = 0
for file_name in file_list:
if not file_name.endswith(".txt"):
continue
old_path = os.path.join(self.target_path, file_name)
new_name = file_name.replace(".txt", ".md")
new_path = os.path.join(self.target_path, new_name)
# 读取TXT内容写入MD文件
with open(old_path, "r", encoding="utf-8") as f:
content = f.read()
with open(new_path, "w", encoding="utf-8") as f:
f.write(content)
# 转换后删除原TXT文件
os.remove(old_path)
count += 1
return f"TXT转MD完成,共转换{count}个文件"
def delete_empty_file(self):
"""批量删除空文件"""
file_list = os.listdir(self.target_path)
count = 0
for file_name in file_list:
file_path = os.path.join(self.target_path, file_name)
if os.path.isdir(file_path):
continue
# 判断文件大小,0kb即为空文件
if os.path.getsize(file_path) == 0:
os.remove(file_path)
count += 1
return f"空文件清理完成,共删除{count}个空文件"
# 工具入口
if __name__ == "__main__":
# 个人本地测试路径,可自定义修改
tool = FileBatchTool("./test_file")
print(tool.batch_rename("我的文档"))
print(tool.txt_to_md())
print(tool.delete_empty_file())阶段一落地效果:5分钟完成项目搭建与核心功能代码编写,目录结构规范、功能完整,基础功能可正常运行。但此时代码存在隐性问题:缺少异常捕获、未处理特殊字符文件名、无日志记录、批量处理效率偏低,这也是单一Cursor开发的典型短板,需要下一阶段工具补位。
4.2 阶段二:Claude Code 负责工程调试、环境适配与批量运维
Cursor完成代码编写后,项目仅能实现基础功能,但个人开发中环境适配、依赖配置、批量测试、日志输出等工程化操作繁琐耗时,这部分工作全权交给Claude Code处理。Claude Code依托终端交互能力,可自动化完成项目环境配置、异常测试、脚本优化、日志搭建。
本阶段我通过终端向Claude Code下达指令:「为当前文件处理工具添加日志记录功能、全局异常捕获、路径兼容适配,编写批量测试脚本,自动检测文件夹异常、文件权限问题,优化项目运行稳定性」。
Claude Code完成的核心工程化优化工作:自动安装日志依赖、封装全局异常处理函数、兼容Windows/Mac双系统路径、编写自动化测试脚本、生成运行日志文件,解决个人开发工程化不规范、兼容性差的问题。
Claude Code优化后新增工程化适配代码
import os
import logging
import platform
from datetime import datetime
# 全局日志配置(Claude Code自动生成)
def init_logger():
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s - %(levelname)s - %(message)s",
handlers=[logging.FileHandler("tool_run.log", encoding="utf-8"), logging.StreamHandler()]
)
return logging.getLogger()
logger = init_logger()
# 系统路径兼容处理(Claude Code适配多系统)
def get_compatible_path(path):
if platform.system() == "Windows":
return path.replace("/", "\\")
return path
# 全局异常装饰器
def catch_exception(func):
def wrapper(*args, **kwargs):
try:
return func(*args, **kwargs)
except Exception as e:
logger.error(f"执行{func.__name__}失败:{str(e)}")
return f"执行失败:{str(e)}"
return wrapper
# 重构原工具类,适配工程化配置
class FileBatchTool:
def __init__(self, target_path):
self.target_path = get_compatible_path(target_path)
if not os.path.exists(self.target_path):
logger.error(f"目标路径不存在:{self.target_path}")
raise Exception("目标文件夹路径不存在")
logger.info(f"工具初始化成功,目标处理路径:{self.target_path}")
@catch_exception
def batch_rename(self, prefix="file"):
file_list = os.listdir(self.target_path)
count = 1
for file_name in file_list:
file_path = os.path.join(self.target_path, file_name)
if os.path.isdir(file_path):
continue
name_suffix = os.path.splitext(file_name)
new_name = f"{prefix}_{count}{name_suffix[1]}"
new_path = os.path.join(self.target_path, new_name)
os.rename(file_path, new_path)
logger.info(f"重命名成功:{file_name} → {new_name}")
count += 1
logger.info(f"批量重命名任务完成,共处理{count-1}个文件")
return f"批量重命名完成,共处理{count-1}个文件"
# 其余方法同样适配异常捕获和日志记录,代码结构统一优化本阶段工作流时序如下,清晰体现Claude Code的工程化补位作用:
阶段二落地效果:解决项目兼容性差、无日志、异常崩溃等工程问题,项目从“能用”升级为“稳定可用”,适配多系统环境,具备基础运维能力,完全满足个人长期自用需求。
4.3 阶段三:Codex 负责核心逻辑重构、性能优化与漏洞兜底
经过前两个阶段,项目功能完整、运行稳定,但仍存在个人开发难以察觉的隐性问题:批量处理大文件时效率低、重复文件未识别、特殊编码文件转换报错、循环逻辑冗余。此时启用Codex,专注打磨核心业务逻辑,解决代码幻觉、逻辑冗余、性能短板,完成最终质量兜底。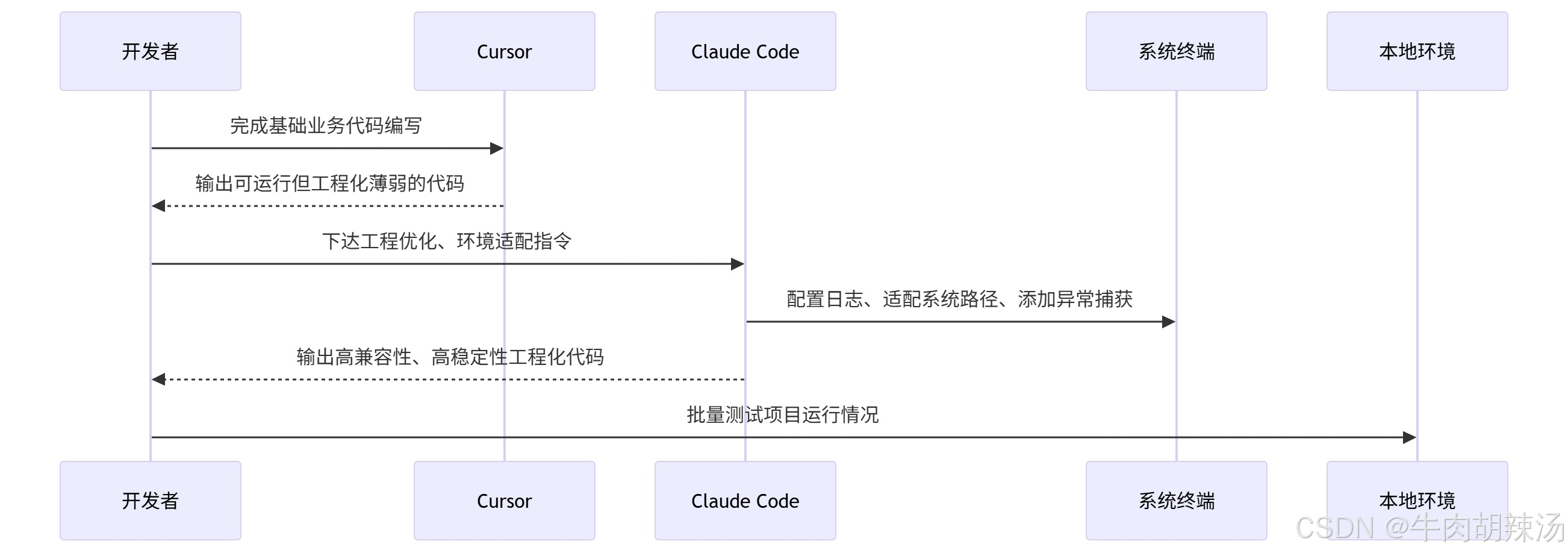
Codex的核心优化方向:精简循环逻辑、添加重复文件校验、优化大文件读写流、适配特殊编码格式、减少内存占用,从核心逻辑层面提升工具性能,规避隐性bug。
Codex核心逻辑优化代码(性能&漏洞兜底)
@catch_exception
def txt_to_md(self):
"""Codex优化版:批量TXT转MD,适配特殊编码、优化大文件读写"""
file_list = os.listdir(self.target_path)
count = 0
# 新增已存在文件校验,避免重复转换覆盖
exist_md_files = [f.replace(".md","") for f in file_list if f.endswith(".md")]
for file_name in file_list:
if not file_name.endswith(".txt"):
continue
# 跳过已存在对应MD的文件
if file_name.replace(".txt","") in exist_md_files:
logger.warning(f"跳过已转换文件:{file_name}")
continue
old_path = os.path.join(self.target_path, file_name)
new_name = file_name.replace(".txt", ".md")
new_path = os.path.join(self.target_path, new_name)
# 适配多编码格式,解决中文乱码问题
content = ""
encode_list = ["utf-8", "gbk", "gb2312"]
for encode in encode_list:
try:
with open(old_path, "r", encoding=encode) as f:
content = f.read()
break
except UnicodeDecodeError:
continue
# 流式写入,优化大文件内存占用
with open(new_path, "w", encoding="utf-8") as f:
f.write(content)
os.remove(old_path)
logger.info(f"格式转换成功:{file_name} → {new_name}")
count += 1
logger.info(f"TXT转MD任务完成,共转换{count}个文件")
return f"TXT转MD完成,共转换{count}个文件"阶段三核心优化亮点:Codex精准发现了前两款工具遗漏的编码兼容bug、重复转换bug、大文件内存溢出隐患,通过逻辑重构彻底杜绝代码幻觉带来的隐性问题,让工具具备长期稳定使用的能力。
五、三段式工作流核心优势总结(适配个人开发者)
通过本次完整实战落地,能够清晰看出三款工具分段使用的轻量化工作流,相比单一工具开发具备碾压式优势,完美适配个人独立开发场景:
1. 极致提效,降低单人开发成本:分工明确避免无效试错,Cursor快速落地功能,Claude Code解决繁琐工程问题,Codex兜底逻辑质量,原本3小时的开发工作量,现在30分钟即可高质量完成,效率提升数倍。
2. 彻底规避AI代码幻觉问题:单一工具开发容易出现逻辑漏洞、隐性bug、环境不适配等幻觉问题,三段式分工形成交叉校验,每阶段工具都能弥补上一阶段的短板,层层过滤错误代码。
3. 全程轻量化,无学习成本负担:无需复杂的工具联动配置、无需搭建专业工程架构、无需团队协作,纯单人操作,指令简单、流程固定,新手开发者也能快速上手。
4. 代码质量层层递进:从“可用基础代码”到“稳定工程代码”,再到“高性能高质量代码”,三级迭代优化,最终产出的代码兼顾实用性、稳定性、性能,完全满足个人上线、商用、自用需求。
六、通用落地规范:适配所有个人开发项目
这套三段式工作流并非仅适用于文件处理工具,可通用适配个人后端接口、前端页面、小程序、爬虫、自动化脚本等所有轻量化项目,固定落地规范如下:
1. 编码阶段全权交给Cursor:负责项目初始化、目录搭建、业务功能编码、基础接口封装,追求快速落地、结构规范;
2. 工程阶段全权交给Claude Code:负责依赖配置、环境适配、日志搭建、异常处理、批量测试、打包部署,解决工程化不规范问题;
3. 优化阶段全权交给Codex:负责核心算法优化、逻辑漏洞修复、性能调优、边界场景处理,兜底代码质量;
4. 禁止工具混用越权:不使用Cursor做批量运维、不使用Claude Code写核心业务逻辑、不使用Codex做基础编码,各司其职避免冗余出错。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)