ollama v0.30.11发布:Thinking能力检测、Claude Code与OpenCode自动安装、Windows Vulkan修复、MLX推测解码大升级全解析
一、版本总览:ollama v0.30.11到底更新了什么
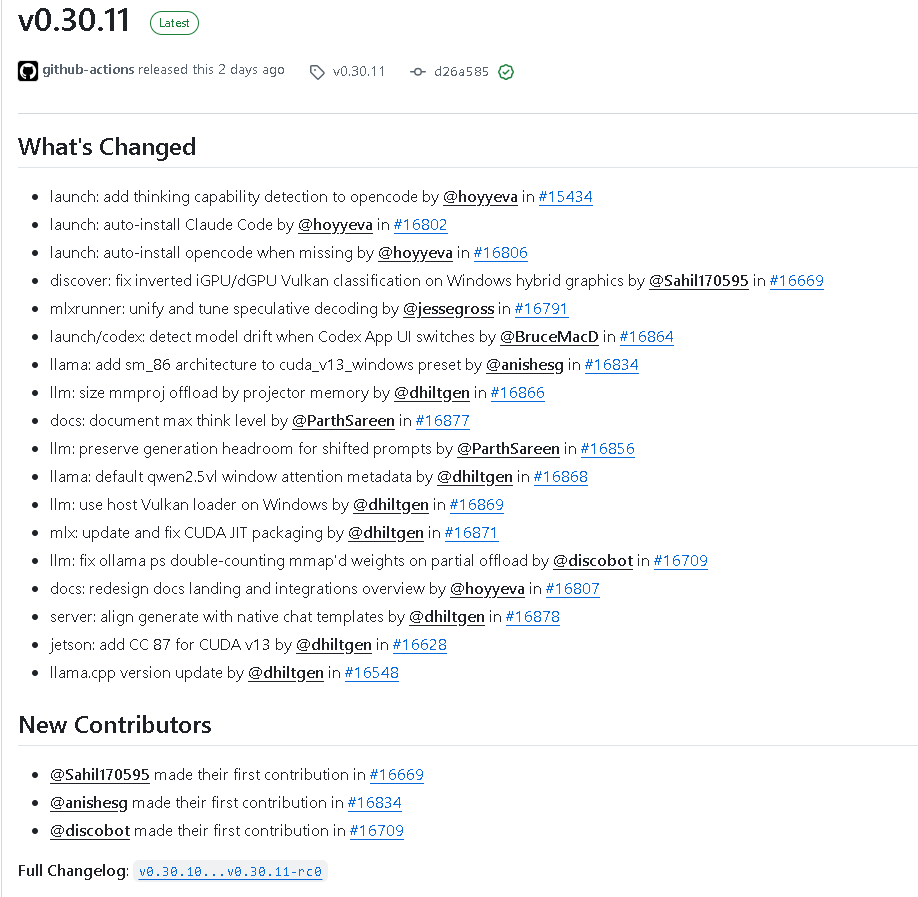
ollama v0.30.11 已正式发布。从这次更新内容来看,这是一个覆盖面非常广的版本,涉及启动能力增强、自动安装体验优化、Windows 图形与 Vulkan 相关修复、MLX 推测解码链路统一调优、Codex 启动侧模型漂移检测、CUDA 预设补充、多模态投影卸载策略优化、文档完善、生成空间管理优化、Qwen2.5VL 元数据默认处理、Windows Vulkan Loader 调整、CUDA JIT 打包修复、Ollama 进程统计修复、服务端模板对齐、Jetson 平台支持增强,以及 llama.cpp 版本更新等多个方面。
如果用一句话概括,ollama v0.30.11 的核心价值主要体现在三个方向:
- 启动与集成体验更完整
- 推理与生成链路更稳、更快、更合理
- Windows、Jetson、CUDA、Vulkan、多模态等平台兼容性进一步提升
这意味着,无论你是本地部署开发者、桌面端使用者,还是关注多模态模型、Windows GPU 环境、Jetson 嵌入式部署和 MLX 推理链路的工程用户,这个版本都值得重点关注。
二、本次版本更新清单完整梳理
根据发布说明,ollama v0.30.11 包含以下更新内容:
- launch:为 opencode 增加 thinking capability detection
- launch:自动安装 Claude Code
- launch:当缺失时自动安装 opencode
- discover:修复 Windows 混合显卡环境下 iGPU 与 dGPU 的 Vulkan 分类颠倒问题
- mlxrunner:统一并调优 speculative decoding
- launch/codex:当 Codex App UI 发生切换时检测 model drift
- llama:为 cuda_v13_windows preset 增加 sm_86 架构
- llm:按照 projector memory 来确定 mmproj offload 大小
- docs:补充 max think level 文档
- llm:为 shifted prompts 保留 generation headroom
- llama:默认设置 qwen2.5vl window attention metadata
- llm:在 Windows 上使用 host Vulkan loader
- mlx:更新并修复 CUDA JIT packaging
- llm:修复 ollama ps 在 partial offload 场景下对 mmap 权重重复统计的问题
- docs:重新设计 docs landing 和 integrations overview
- server:让 generate 与 native chat templates 对齐
- jetson:为 CUDA v13 增加 CC 87
- llama.cpp version update
此外,本次对比信息中还给出了本版本的整体开发规模:
- 贡献者数量:10
- 提交次数:24
- 变更文件数:67
从这些数字也能看出,v0.30.11 并不是一次小修小补,而是一次具有明显工程推进意义的版本更新。
三、启动能力升级:从“能启动”走向“更智能地启动”
本次更新中,launch 相关内容非常亮眼,直接影响开发者和终端用户的使用体验。
1. 为 opencode 增加 thinking capability detection
这项更新的关键词是“thinking capability detection”。从字面理解,它在启动 opencode 的过程中增加了对 thinking 能力的检测。这个变化非常重要,因为它意味着启动流程不再只是简单拉起组件,而是开始具备能力识别意识。
对于使用者来说,这种能力检测的加入,价值主要体现在两个层面:
- 启动阶段对能力状态的识别更明确
- 后续围绕思考能力或推理能力的联动更具基础性支持
这也说明,ollama 在启动链路上已经不满足于“运行即可”,而是朝着“根据能力特征做更准确处理”的方向推进。
2. 自动安装 Claude Code
launch 侧另一个非常重要的更新,是自动安装 Claude Code。这个变化的直接意义非常清晰:如果环境里需要 Claude Code,系统将不再完全依赖用户手动准备,而是通过自动化方式降低接入门槛。
这类更新通常会带来几个明显收益:
- 首次接入配置更省事
- 缺少相关组件时更容易补齐依赖
- 降低因安装缺失导致的启动失败概率
对很多本地部署用户来说,自动安装能力是提升“开箱即用”体验的关键一步。
3. 当缺失时自动安装 opencode
除了 Claude Code,本次更新还加入了在缺失 opencode 时自动安装的能力。这项改动与前一项形成互补,说明 ollama 正在进一步完善启动阶段的依赖治理。
自动安装 opencode 的意义在于:
- 启动链路对外部依赖的容错能力更强
- 用户无需反复排查“为什么启动不了”
- 整体集成体验更趋向自动化、智能化
如果把这三项 launch 更新合在一起看,就会发现一个明显趋势:ollama v0.30.11 正在把启动流程从“人工配置驱动”转向“自动探测、自动补齐驱动”。
四、Windows 图形识别修复:混合显卡 Vulkan 分类问题被纠正
本次 discover 模块的更新聚焦于 Windows 混合显卡环境:
- 修复 Windows hybrid graphics 下 iGPU 和 dGPU 的 Vulkan classification inverted 问题
这项修复非常关键,尤其是针对同时具备集成显卡和独立显卡的 Windows 设备。更新说明表明,之前在某些混合显卡场景下,iGPU 与 dGPU 的 Vulkan 分类出现了颠倒。
这类问题一旦存在,可能影响的不仅是“识别显示不准确”,更有可能波及后续资源选择、设备判断和相关推理执行路径。因为在 GPU 相关环境中,集显和独显的判断如果反了,会让系统对设备能力产生错误理解。
此次修复说明:
- ollama 对 Windows 图形环境识别进一步细化
- Vulkan 设备分类准确性得到提升
- 混合显卡用户的运行稳定性和判断一致性更有保障
对于笔记本用户、轻薄本用户,尤其是采用混合显卡方案的 Windows 机器来说,这是一个非常实用的更新。
五、MLX 推测解码大升级:不仅统一,而且进行了系统级调优
本次版本中,mlxrunner 的更新可以说是最成体系的一部分。发布总览中直接给出一句总结:
- mlxrunner:unify and tune speculative decoding
而在提交时间轴中,又进一步拆分出了多项相关提交,说明这不是单点改动,而是一组围绕推测解码链路展开的系统性优化。
具体包括:
- 统一 MTP decode paths
- 在 text generation pipeline 中承载 speculative decoding
- 支持维护 draft caches 的 draft heads
- 将 in-flight drafts 应用于 proposal penalty history
- 每个 MTP decode step 只运行一次 target forward
- 在一次 host sync 中完成每轮 speculative round 的 resolve
- 选择 speculative draft length 以最大化 throughput
下面逐项来看。
1. 统一 MTP decode paths
“统一解码路径”意味着之前可能存在多条实现路径,而现在进行了整合。统一路径的价值通常在于:
- 降低维护复杂度
- 提升行为一致性
- 为后续性能优化提供更清晰的基础
2. 在文本生成管线中承载 speculative decoding
把 speculative decoding 放进 text generation pipeline,说明推测解码不再是边缘性的附加逻辑,而是更正式地成为文本生成流程中的一部分。这会让它和整体生成链路之间的衔接更自然。
3. 支持能够维护 draft caches 的 draft heads
这个更新说明 draft head 的能力进一步增强,不只是参与草稿生成,还能维护 draft cache。对于推测解码来说,缓存管理是效率优化中的关键环节之一,这意味着 mlxrunner 在内部执行机制上更成熟。
4. 将 in-flight drafts 应用于 proposal penalty history
这里反映出推测解码并不是孤立处理,而是与 proposal penalty history 发生更紧密的联动。也就是说,在飞行中的草稿结果,会影响惩罚历史相关逻辑,整个生成控制更加连续。
5. 每个 MTP 解码步骤只运行一次 target forward
这项改动的方向非常明确,就是减少冗余计算。每个步骤只进行一次 target forward,说明执行路径被进一步压缩,对性能提升具有直接意义。
6. 每轮 speculative round 在一次 host sync 中完成 resolve
这体现出主机同步次数被控制。同步通常是性能链路中的关键开销点,把每轮推测处理集中到一次 host sync 内完成,对整体吞吐有积极帮助。
7. 选择最优 speculative draft length 以最大化吞吐
这项内容点出了调优目标:throughput 最大化。也就是说,草稿长度不再是固定策略,而是为了提升吞吐而进行选择。这种更新非常工程化,说明优化不只是功能层面,而是明确面向性能表现。
综合来看,mlxrunner 的这一组提交说明:
- 推测解码路径被统一
- 执行流程被标准化
- 缓存与惩罚历史联动更完整
- 计算和同步开销进一步压缩
- 草稿长度选择更强调吞吐表现
对于关注 MLX、文本生成性能和推测解码质量的用户来说,这无疑是 v0.30.11 中最值得关注的一大亮点。
六、Codex 相关增强:UI 切换时检测模型漂移
launch/codex 增加了一项很有针对性的改动:
- 当 Codex App UI 发生切换时,检测 model drift
这里的关键在于“UI switches away from…”以及“detect model drift”。这说明在 Codex App 的界面切换场景中,ollama 新增了模型漂移检测能力。
这个改动的意义在于,应用 UI 状态的变化可能影响模型状态认知或上下文一致性,系统现在开始主动关注这种变化,并进行漂移检测。
从工程角度看,这体现了两个信号:
- launch/codex 逻辑与上层应用行为耦合得更紧密
- 模型状态一致性的问题被更认真地纳入启动与运行链路考虑
这类优化虽然不像“速度提升”那么直观,但对于复杂应用集成环境来说,往往决定了实际使用时是否稳定、是否可控。
七、CUDA 与硬件适配增强:Windows 和 Jetson 都有更新
本次版本在 CUDA 相关硬件适配方面也有两项明确增强。
1. 为 cuda_v13_windows 预设增加 sm_86 架构
更新内容显示:
- llama:add sm_86 architecture to cuda_v13_windows preset
这代表在 Windows 的 CUDA v13 预设中,新增了对 sm_86 架构的支持。对对应架构用户而言,这意味着预设覆盖能力进一步扩大,适配更完整。
对于依赖 CUDA 预设的环境来说,这项变化往往可以减少额外配置成本,也能让运行环境更贴近硬件实际情况。
2. Jetson 为 CUDA v13 增加 CC 87
另一项是:
- jetson:add CC 87 for CUDA v13
Jetson 平台一直是边缘 AI、嵌入式部署和本地推理的重要方向。新增 CC 87,说明 ollama 在 CUDA v13 下对 Jetson 的适配范围继续扩展。
将这两项放在一起看,可以得出一个非常明确的结论:ollama v0.30.11 在继续完善不同硬件平台上的 CUDA 兼容性,不仅照顾桌面端 Windows,也覆盖嵌入式 Jetson 平台。
八、多模态与生成空间管理优化:更细致,也更实际
本次 llm 与 llama 相关更新中,有几项非常值得关注。
1. 按 projector memory 决定 mmproj offload 大小
更新内容为:
- llm:size mmproj offload by projector memory
这意味着 mmproj 的 offload 大小不再采用较粗粒度方式,而是与 projector memory 建立直接对应关系。
这类调整的好处通常体现在:
- 卸载策略更贴合实际内存情况
- 多模态相关资源管理更精细
- 有助于提高资源利用合理性
对于涉及多模态模型、尤其是视觉投影相关处理的场景来说,这是一个偏底层但很关键的优化。
2. 为 shifted prompts 保留 generation headroom
更新内容为:
- llm:preserve generation headroom for shifted prompts
这项更新关注的是 shifted prompts 场景下的生成空间保留问题。换句话说,系统在处理这类提示时,会有意识地为生成阶段保留足够 headroom。
这说明 ollama 对 prompt 处理与生成资源分配之间的平衡考虑得更细了。对于实际生成来说,这种“提前预留空间”的策略可以避免某些边界情况下生成阶段受限。
3. 默认设置 qwen2.5vl window attention metadata
更新内容为:
- llama:default qwen2.5vl window attention metadata
这项改动与 Qwen2.5VL 相关,重点在于 window attention metadata 的默认处理。加入默认元数据意味着这一类模型在使用时,相关注意力窗口信息有了更明确的基础设定。
这个更新体现的是模型适配层面的细化,对于多模态模型使用一致性和默认行为规范化具有积极意义。
九、Windows Vulkan Loader 调整:主机侧加载方式更明确
本次还有一项与 Windows Vulkan 直接相关的重要变化:
- llm:在 Windows 上使用 host Vulkan loader
这说明在 Windows 环境中,llm 侧对 Vulkan Loader 的使用方式发生了调整,转向 host Vulkan loader。
结合前面提到的混合显卡 Vulkan 分类修复可以看出,v0.30.11 对 Windows 平台图形与底层加载链路进行了连续优化。前者解决识别判断问题,后者则调整底层加载路径,这说明 Windows 平台上的 Vulkan 相关处理正在被进一步梳理和强化。
十、MLX CUDA JIT 打包修复:更新之外更强调可用性
发布说明中还有一项:
- mlx:update and fix CUDA JIT packaging
这意味着 MLX 相关的 CUDA JIT packaging 不只是更新了,而且进行了修复。单从措辞看,这类问题往往与实际分发、运行或依赖打包有关。
因此,这项更新的价值更多体现在“可用性”和“部署完整性”上:
- 打包链路更可靠
- CUDA JIT 相关交付更稳
- MLX 相关环境问题有望减少
十一、统计修复:partial offload 场景下的 ollama ps 更准确
本次 llm 还修复了一个非常具体的问题:
- 修复 ollama ps 在 partial offload 情况下对 mmap 权重 double-counting 的问题
这个问题看似细节,实际上非常重要。因为它关系到 ollama ps 统计结果的准确性。partial offload 本身就是资源分配和运行方式较复杂的场景,如果再出现 mmap 权重被重复统计,那么监控结果就会失真。
这项修复的意义在于:
- ollama ps 输出更准确
- partial offload 场景下资源统计更可信
- 用户排查内存占用时参考价值更高
对于重视运行观测、排障分析和容量评估的用户来说,这是一个非常实际的优化。
十二、文档更新:不仅补内容,还重做结构
本次 docs 相关更新有两项:
- 补充 max think level 文档
- 重新设计 docs landing 和 integrations overview
1. document max think level
这说明关于 max think level 的文档得到了明确补充。既然 launch 中已经加入了 thinking capability detection,那么文档层面对 think level 相关能力进行说明,也是很自然的一步。
这代表 ollama 不只是增加能力,同时也在推进能力说明的可读性和可理解性。
2. redesign docs landing and integrations overview
文档首页和集成概览被重新设计,这是一次偏结构性的文档升级。它的重点不在某个具体参数,而在于整体阅读入口和集成信息组织方式。
从使用体验来看,这种更新通常会带来:
- 文档入口更清晰
- 集成能力展示更集中
- 新用户理解产品边界更容易
文档更新看似不如性能优化“硬核”,但对于工具链生态发展来说,文档质量往往决定了上手效率和传播效果。
十三、服务端对齐:generate 与 native chat templates 保持一致
本次 server 更新为:
- align generate with native chat templates
这项改动非常值得关注,因为它直接触及生成接口和原生聊天模板之间的一致性问题。
“对齐”意味着两者此前可能在模板行为、格式表现或调用结果上存在差异,而此次更新的目标就是减少这种差异,让 generate 更贴近 native chat templates 的表现方式。
这类改动带来的价值通常包括:
- 服务端生成行为更统一
- 模板相关结果更可预期
- 开发者在不同调用方式之间切换时成本更低
对于通过 API、服务端或集成方式使用 ollama 的开发者来说,这是一个很实用的变化。
十四、llama.cpp 版本更新:底层依赖继续演进
发布说明最后还提到:
- llama.cpp version update
虽然这里只给出一句概括,没有展开更多细节,但这依然是一个重要信息。因为 llama.cpp 本身就是底层能力的重要组成部分,版本更新往往意味着依赖栈持续演进。
在整个 v0.30.11 的更新框架中,llama.cpp 的版本更新与其他修复和增强一起,构成了底层能力升级的一部分。
十五、提交时间轴梳理:v0.30.11 是如何逐步成型的
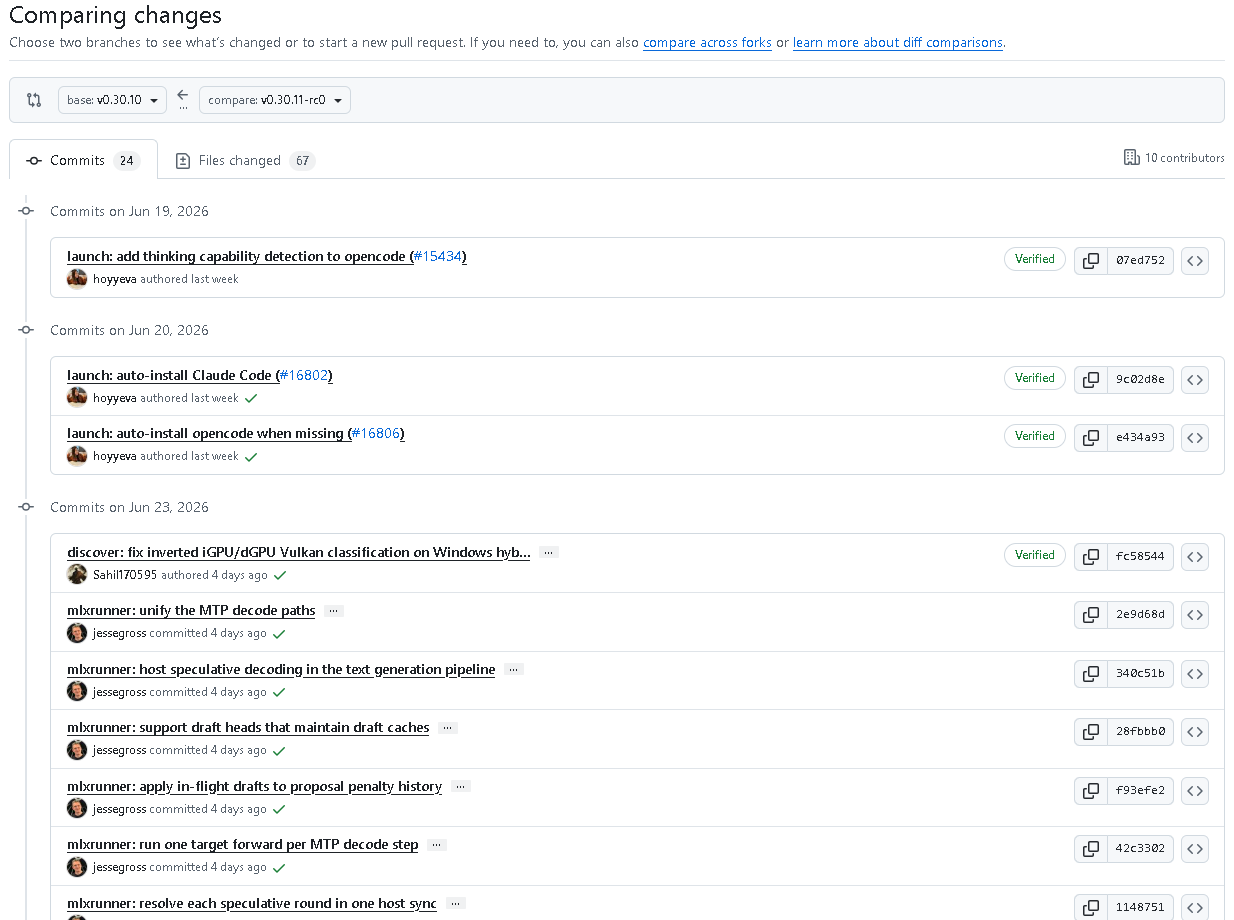
为了更直观理解这个版本,我们还可以按照时间轴梳理此次更新过程。
2026年6月19日
- launch:为 opencode 增加 thinking capability detection
这是本次版本中最早出现的更新之一,也为后续 think level 文档补充形成了呼应。
2026年6月20日
- launch:自动安装 Claude Code
- launch:当缺失时自动安装 opencode
这一天的重点非常清晰,就是继续强化启动阶段的自动化能力。
2026年6月23日
- discover:修复 Windows 混合显卡环境下 iGPU 与 dGPU 的 Vulkan 分类颠倒问题
- mlxrunner:统一 MTP decode paths
- mlxrunner:在文本生成管线中承载 speculative decoding
- mlxrunner:支持维护 draft caches 的 draft heads
- mlxrunner:将 in-flight drafts 应用于 proposal penalty history
- mlxrunner:每个 MTP 解码步骤只运行一次 target forward
- mlxrunner:每轮 speculative round 在一次 host sync 中完成 resolve
- mlxrunner:选择 speculative draft length 以最大化 throughput
- launch/codex:当 Codex App UI 切换时检测 model drift
- llama:为 cuda_v13_windows 预设增加 sm_86 架构
这一天是本版本更新最密集的节点之一,特别是 mlxrunner 的一整套推测解码优化,构成了 v0.30.11 的技术亮点核心。
2026年6月24日
- llm:按照 projector memory 来确定 mmproj offload 大小
- docs:补充 max think level 文档
- llm:为 shifted prompts 保留 generation headroom
这一天的更新更多偏向资源管理细化和文档能力补全。
2026年6月25日
- llama:默认设置 qwen2.5vl window attention metadata
- llm:在 Windows 上使用 host Vulkan loader
- mlx:更新并修复 CUDA JIT packaging
- llm:修复 ollama ps 在 partial offload 下对 mmap 权重重复统计的问题
- docs:重新设计 docs landing 和 integrations overview
- server:让 generate 与 native chat templates 对齐
- jetson:为 CUDA v13 增加 CC 87
- llama.cpp version update
从时间轴来看,v0.30.11 的更新推进节奏非常清晰:先强化启动能力,再集中优化推测解码与平台识别,随后继续补齐文档、生成逻辑、硬件适配和底层版本演进。
十六、版本价值总结:ollama v0.30.11 为什么值得升级关注
综合本次所有更新,ollama v0.30.11 的价值主要体现在以下几个方面。
第一,启动与依赖管理更智能。
通过增加 opencode 的 thinking capability detection、自动安装 Claude Code、自动安装缺失的 opencode,ollama 明显在推动启动链路自动化和能力感知化。
第二,MLX 推测解码体系化升级。
这次不是简单优化,而是从解码路径、缓存、惩罚历史、target forward 次数、host sync、draft length 选择等多个层面进行统一与调优,直接体现出对吞吐与链路完整性的重视。
第三,Windows 平台体验得到实质改善。
无论是混合显卡 Vulkan 分类修复,还是 llm 改为使用 host Vulkan loader,都是对 Windows 环境兼容性和识别准确性的强化。
第四,多模态与生成资源控制更细。
mmproj offload 按 projector memory 定大小、shifted prompts 保留 generation headroom、默认设置 qwen2.5vl window attention metadata,这些改动都说明 ollama 对模型适配与生成资源管理正在进入更精细化阶段。
第五,服务端与文档生态继续完善。
generate 与 native chat templates 对齐,max think level 文档补充,docs landing 和 integrations overview 重构,这些更新对开发者使用体验和理解成本都有直接帮助。
第六,硬件适配范围继续扩大。
Windows CUDA v13 预设新增 sm_86,Jetson 的 CUDA v13 新增 CC 87,再加上 llama.cpp 版本更新,说明整个底层适配矩阵仍在持续推进。
十七、结语
从整体上看,ollama v0.30.11 不是一个只修一两个问题的小版本,而是一次覆盖启动、推理、平台兼容、多模态、文档、服务端和底层依赖的综合更新。
它一方面通过自动安装、能力检测、模板对齐和文档重构增强易用性,另一方面又通过推测解码统一调优、显卡识别修复、Vulkan Loader 调整、CUDA 与 Jetson 适配、统计修复等内容,持续提升专业用户最关心的稳定性、吞吐和部署体验。
如果你正在关注 ollama 在本地大模型生态中的演进,那么 v0.30.11 这个版本,值得你重点阅读更新说明,也值得你在自己的环境中尽快验证升级效果。
附:ollama v0.30.11 更新要点速览
- 发布时间:2026年6月27日
- 贡献者数量:10
- 提交次数:24
- 变更文件数:67
完整更新项
- launch:为 opencode 增加 thinking capability detection
- launch:自动安装 Claude Code
- launch:当缺失时自动安装 opencode
- discover:修复 Windows 混合显卡环境下 iGPU 与 dGPU 的 Vulkan 分类颠倒问题
- mlxrunner:统一并调优 speculative decoding
- launch/codex:当 Codex App UI 切换时检测 model drift
- llama:为 cuda_v13_windows preset 增加 sm_86 架构
- llm:按照 projector memory 确定 mmproj offload 大小
- docs:补充 max think level 文档
- llm:为 shifted prompts 保留 generation headroom
- llama:默认设置 qwen2.5vl window attention metadata
- llm:在 Windows 上使用 host Vulkan loader
- mlx:更新并修复 CUDA JIT packaging
- llm:修复 ollama ps 在 partial offload 场景下对 mmap 权重重复统计的问题
- docs:重新设计 docs landing 和 integrations overview
- server:让 generate 与 native chat templates 对齐
- jetson:为 CUDA v13 增加 CC 87
- llama.cpp 版本更新

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 0
0 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)