Prompt Engineering:从民间技艺到生产工程
引言:Prompt Engineering 并未消亡,而是进化了
如果你在 2023 年问一位资深 ML 工程师"Prompt Engineering 会不会很快过时",得到的答案很可能是"会的,模型变聪明后就不需要精心措辞了"。三年后的 2026 年,这个预测被证明是严重错误的。
事实是:GPT-5.4、Claude Opus 4.7、Gemini 3.1 Pro 等前沿模型的能力确实大幅提升,但平庸提示与精心工程化提示之间的差距不仅没有缩小,反而在 Agentic 任务上显著扩大。社区基准测试显示,在 SWE-bench Verified 上,Claude Opus 4.7 使用默认提示得分约 79%,而经过显式任务分解、工具使用规范和结构化中间状态设计的提示,可以将同一模型推升至 84% 以上 。在 Terminal-Bench 上,GPT-5-Codex 在朴素单轮提示与结构化 Agent 循环之间也展现出显著的性能差异。
Prompt Engineering 已经从 2022 年的"民间技艺"(Folk Art)演变为 2026 年的生产工程学科。它不再只是"如何写出更好的提示",而是关于如何构建可重复、可观测、可度量的 AI 工作流。
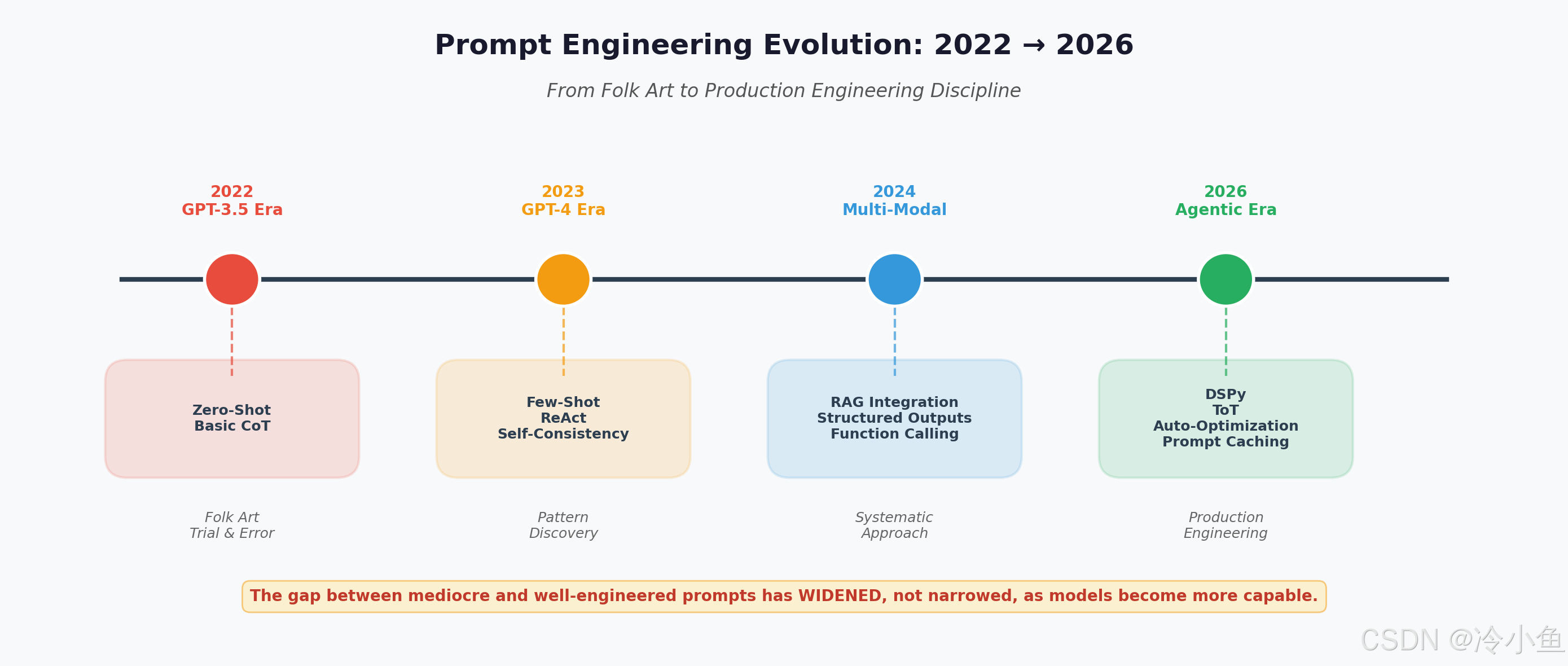
一、核心框架全景:从 Zero-Shot 到 Agentic Loop
2026 年的 Prompt Engineering 拥有一套成熟且可度量的技术体系。以下是六大核心框架的系统性对比:
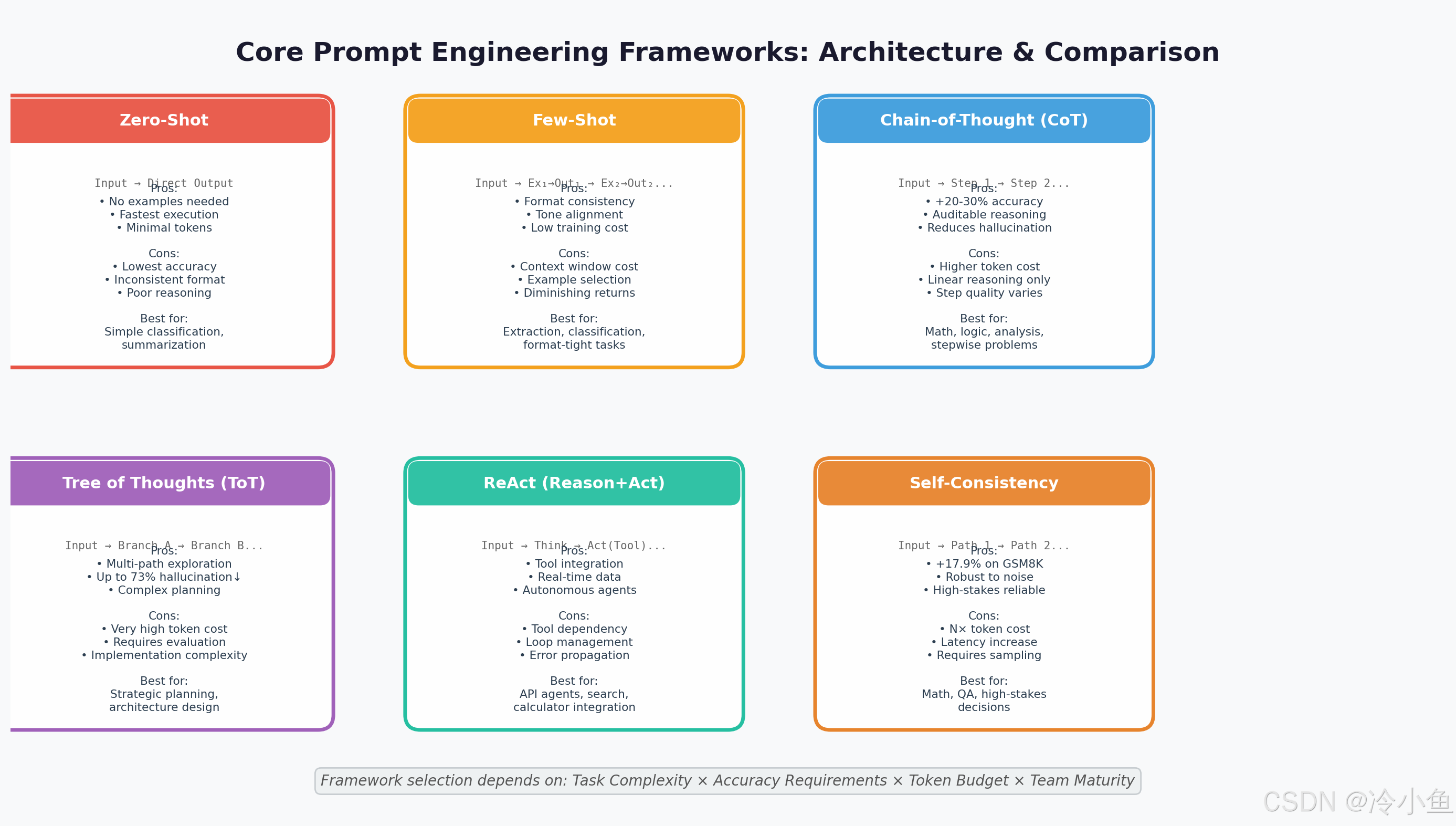
1.1 Zero-Shot & Few-Shot:基础但不可轻视
Zero-Shot 适用于简单分类、摘要等低复杂度任务,无需示例,执行最快、Token 消耗最低。但准确率天花板明显,格式一致性差。
Few-Shot 通过提供 3-10 个输入/输出示例,显著提升格式一致性和语调对齐。研究表明,Few-Shot 的效果在 10-20 个示例后趋于饱和 。关键技巧包括:
- 示例选择:选择多样化且边界清晰的示例,而非随机采样
- 示例排序:将最复杂的示例放在最后,因为模型对末尾示例的注意力权重更高
- 动态 Few-Shot:根据输入语义相似度从示例库中动态检索最相关的示例
1.2 Chain-of-Thought (CoT):强制算法化思考
CoT 的核心思想是强制模型"大声思考",在给出最终答案前显式生成推理步骤。2026 年的最佳实践是使用 XML 标签严格隔离推理过程与最终输出:
Analyze the following IT support ticket and classify its urgency.
Before giving your final answer, use the <reasoning> tag to explicitly
analyze the business impact, the number of affected users, and whether
a temporary workaround is available.
<reasoning>
(your step-by-step impact analysis here)
</reasoning>
<classification>(High/Medium/Low)</classification>
这种结构化 CoT 的数学原理在于:强制模型先生成推理 Token,会改变其内部注意力状态,使得最终预测(分类 Token)以正确的底层逻辑为条件,而非直接猜测 。
在 2026 年的前沿模型上,CoT 的绝对提升幅度相比 2023 年有所减小(模型本身已具备更强的推理能力),但在需要审计轨迹的高风险场景中,CoT 仍是不可或缺的。
1.3 Tree of Thoughts (ToT):多路径探索
当线性 CoT 不足以应对复杂规划或架构设计时,ToT 通过生成多个候选方案、评估各分支优劣、选择最优路径来解决问题。典型结构如下:
- 生成 3 种不同的架构方案
- 批判性评估每种方案的潜在瓶颈、技术债务和实施成本
- 为每种方案分配 1-10 的可行性评分
- 选择最高分方案并扩展为详细行动计划
ToT 在复杂规划任务上可将幻觉率降低高达 73% ,但代价是极高的 Token 消耗和实现复杂度。它最适合战略级决策,而非日常查询。
1.4 ReAct (Reason + Act):推理与行动的交织
ReAct 框架将推理(Reasoning)与行动(Action) 交织在一起,形成循环:模型先思考,然后调用工具,观察结果,再思考下一步。这是 2026 年 Agentic 系统的核心模式。
# 典型的 ReAct Agent 循环
while not done and iterations < max_iter:
response = llm.generate(system_prompt + history)
if response.has_tool_call:
result = execute_tool(response.tool_call)
history.append({"role": "tool", "content": result})
else:
return validate_output(response)
ReAct 的关键在于提示中必须精确定义可用工具(名称、参数、描述),并明确输出格式规范(如 <thinking>、<tool_call>、<answer> 标签)。
1.5 Self-Consistency:多数投票的稳健性
Self-Consistency 通过对同一问题采样多条推理路径,然后取多数投票的结果。在 GSM8K 数学基准上,相比标准 CoT 提升了 17.9% 的准确率,在 AQuA 代数基准上提升 12.2% 。
实现要点:
- 使用较高的 Temperature(如 0.7)以获得多样化的推理路径
- 对最终答案进行归一化和聚类
- 适用于数学、QA 等答案空间离散的高风险场景
二、生产级 Prompt 架构设计
一个生产级的 Prompt 系统远不止是"写一段好文字"。它是分层、可控、可观测、可迭代的工程资产。
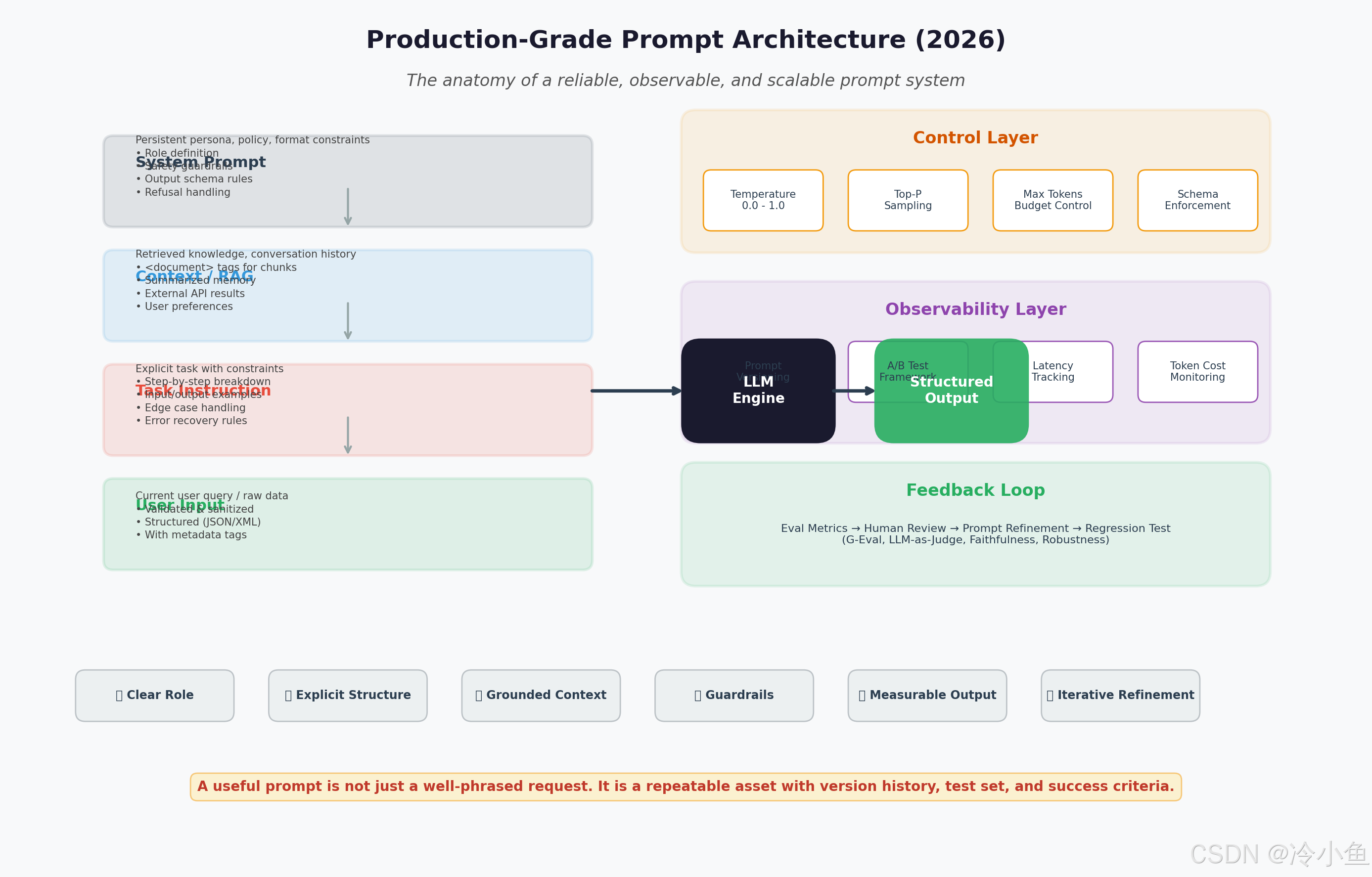
2.1 四层 Prompt 结构
System Prompt(系统提示):定义持久性角色、安全策略、输出格式约束。这是模型的"操作系统层",在所有交互中保持不变。
Context / RAG(上下文层):注入检索到的知识、对话历史、外部 API 结果。2026 年的最佳实践:
- 使用 XML 标签(如
<document id="42">...</document>)分隔不同来源的上下文,在 Claude 家族模型上检索准确率显著优于 Markdown 标题 - 对长对话历史进行摘要压缩,每 50-100 轮将旧对话压缩为记忆摘要
- 将关键指令同时放在上下文开头和结尾,因为中间位置是注意力衰减最快的区域
Task Instruction(任务指令层):显式的任务描述,包含:
- 步骤分解(Step-by-step breakdown)
- 输入/输出示例(Input/output examples)
- 边界情况处理(Edge case handling)
- 错误恢复规则(Error recovery rules)
User Input(用户输入层):经过验证和清理的当前查询,通常以结构化格式(JSON/XML)传入,附带元数据标签。
2.2 控制层:Schema 强制与参数调优
2026 年,结构化输出(Structured Outputs) 已经取代了脆弱的 Regex 解析。JSON Schema 强制的最佳实践:
- 始终设置
additionalProperties: false:防止模型发明不存在字段 - 所有字段标记为 required,使用 nullable 类型替代可选字段:
"due_date": string | null优于可选的"due_date": string - 大量使用 enums:分类字段的幻觉率从自由文本的"几个百分点"降至接近零
- 避免深层嵌套 union:超过两层
oneOf会导致可测量的延迟惩罚 - 为每个字段提供 description:Schema 的
description值会被模型读取,充当内联指令
2.3 观测层:Prompt 的版本化与 A/B 测试
生产级 Prompt 必须具备:
- 版本控制:每次修改都有版本号、变更原因、性能基线
- A/B 测试框架:对比不同 Prompt 变体在真实任务上的表现
- 延迟追踪:监控首 Token 延迟和总生成时间
- Token 成本监控:Prompt Caching 可将成本降低 70-90%,但需要精确追踪缓存命中率
2.4 反馈循环:Eval-Driven 设计
Prompt 优化的唯一可靠方式是基于评估指标驱动迭代。2026 年的评估栈包括:
- G-Eval:使用 LLM 作为评判者,基于自定义标准打分
- Faithfulness:验证模型推理与真实证据的对齐度
- Robustness:测试输入变化时输出的一致性
- Human-in-the-Loop:高风险决策保留人工审核节点
三、Agentic Prompt Loop:2026 年的核心范式
随着模型能力的提升,Prompt Engineering 的核心战场已经从"单次问答"转移到了多轮 Agent 循环。
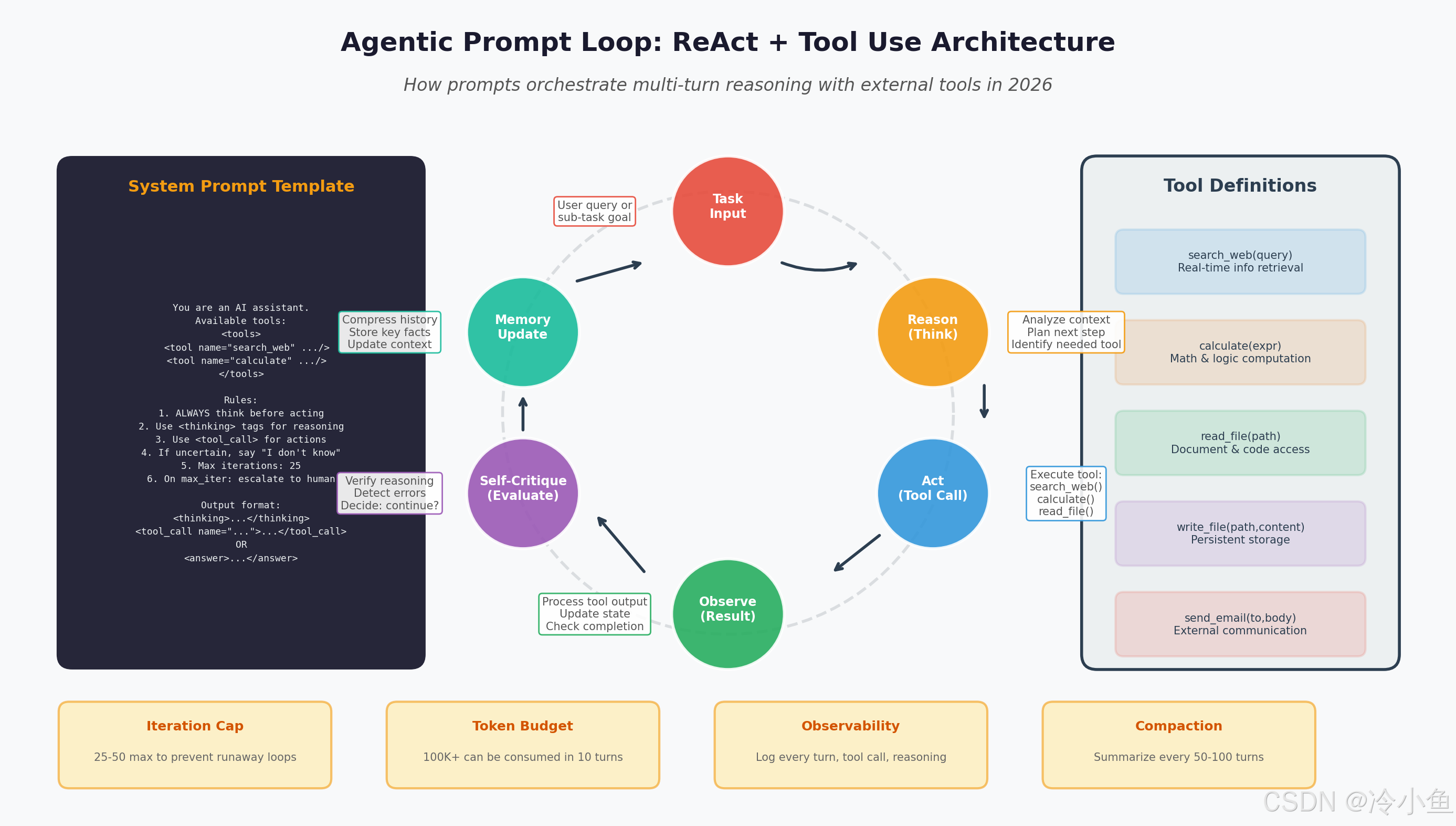
3.1 ReAct + Tool Use 的完整循环
一个可靠的 Agent 循环在 2026 年看起来像这样:
# Agent Loop Pattern (2026)
def agent_loop(task, max_iterations=25):
history = [system_prompt, tool_definitions, task]
for i in range(max_iterations):
# 1. 模型生成:思考 + 工具调用 或 最终答案
response = llm.generate(history, tools=available_tools)
if response.has_tool_call:
# 2. 执行工具
result = execute_tool(response.tool_call)
history.append({"role": "assistant", "content": response.text})
history.append({"role": "tool", "content": result})
else:
# 3. 验证输出 Schema
if validate_schema(response.final_answer):
return response.final_answer
else:
history.append({"role": "system", "content": "Schema validation failed. Please retry."})
# 4. 每 N 轮压缩历史
if i % 50 == 49:
history = compress_history(history)
# 5. 达到最大迭代次数,升级处理
return escalate_to_human(task, history)
3.2 关键工程约束
迭代上限(Iteration Cap):必须设置硬性的最大迭代次数(通常 25-50),防止 Agent 陷入无限循环。没有上限的 Agent 是生产事故的温床。
Token 预算(Token Budget):推理模型在 10 轮内可能消耗 100K+ Token。需要单独设置总 Token 消耗预算,并在接近上限时触发降级策略。
可观测性(Observability):记录每一轮的状态、每次工具调用的参数和结果、每次推理摘要。没有 Trace 的 Agent 调试几乎不可能。
历史压缩(Compaction):每 50-100 轮将旧对话压缩为摘要,重新开始上下文窗口。Anthropic 对 Claude Agent 的官方建议正是如此 。
3.3 工具定义的 Prompt 设计
工具定义本身也是 Prompt Engineering 的一部分。2026 年的最佳实践:
<tools>
<tool name="search_web">
<description>Search the web for current factual information.
Use this when the user asks about events after 2024.</description>
<parameters>
<param name="query" type="string" required="true">
<description>A specific, concise search query (max 10 words)</description>
</param>
</parameters>
</tool>
</tools>
工具描述的质量直接影响 Agent 选择正确工具的能力。描述应包含:
- 何时使用(When to use)
- 何时不使用(When NOT to use)
- 参数约束(Parameter constraints)
- 典型示例(Typical examples)
四、决策矩阵:如何选择合适的技术
面对众多技术,如何做出正确选择?以下矩阵基于任务复杂度和准确率要求两个维度进行决策:
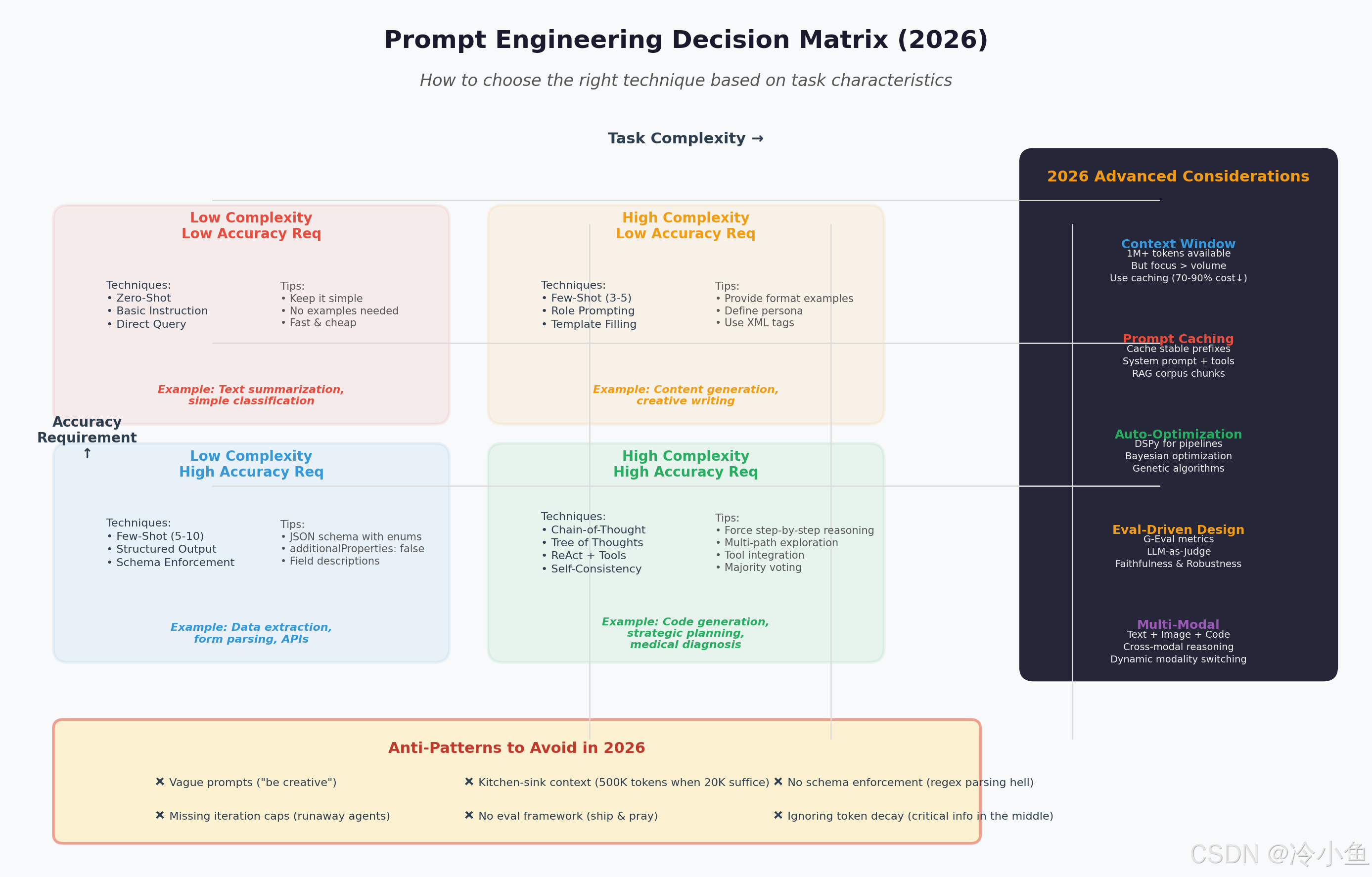
4.1 象限一:低复杂度 × 低准确率要求
- 技术:Zero-Shot、Basic Instruction
- 策略:保持简单,无需示例,追求速度和低成本
- 示例:文本摘要、简单分类
4.2 象限二:高复杂度 × 低准确率要求
- 技术:Few-Shot (3-5)、Role Prompting、Template Filling
- 策略:提供格式示例,定义角色人设,使用 XML 标签结构化
- 示例:内容生成、创意写作
4.3 象限三:低复杂度 × 高准确率要求
- 技术:Few-Shot (5-10)、Structured Output、Schema Enforcement
- 策略:JSON Schema 强制、所有字段 required、enums 防幻觉
- 示例:数据提取、表单解析、API 响应格式化
4.4 象限四:高复杂度 × 高准确率要求
- 技术:Chain-of-Thought、Tree of Thoughts、ReAct + Tools、Self-Consistency
- 策略:强制逐步推理、多路径探索、工具集成、多数投票
- 示例:代码生成、战略架构设计、医疗诊断
五、2026 年的前沿实践
5.1 Prompt Caching:成本优化的核武器
OpenAI、Anthropic、Google 均支持 Prompt Caching——缓存稳定的前缀 Token 以远低于全量输入的价格计费。对于包含固定系统提示、工具定义和不变化检索语料库的 Prompt,Caching 可将成本削减 70-90% 。
关键设计原则:将静态内容放在 Prompt 前缀,动态内容放在后缀,最大化缓存命中率。
5.2 长上下文管理:1M Token 不是万能药
Gemini 3.1 Pro、GPT-5.4、Claude Opus 4.7 均支持约 1M Token 的上下文窗口。但"Lost in the Middle"效应依然存在——虽然对单事实检索已大幅改善,但对需要综合 5+ 个分散事实的 500K+ Token 任务,准确率仍会可测量地下降。
2026 年的最佳实践:
- 精准检索优于全量注入:20K Token 的 RAG Prompt(8 个精选 Chunk)在准确率、延迟和成本上均优于 500K Token 的全量注入
- 重复关键约束:在上下文开头和结尾同时放置关键指令
- 显式分隔符:XML 标签 > Markdown 标题 > 纯文本换行
5.3 自动化 Prompt 优化
手动调优 Prompt 的回报率在达到某个点后急剧下降。2026 年,自动化 Prompt 优化已成为最大的单一杠杆:
- DSPy:将 Prompt 工程转化为 Python 编程,支持模块化 Prompt 块、条件分支、循环和状态管理,可版本控制、单元测试和 CI/CD 集成
- 贝叶斯优化:自动探索 Prompt 变体空间,基于评估指标指导搜索
- 遗传算法:通过交叉和变异生成更优 Prompt 组合
5.4 反模式:2026 年必须避免的错误
| 反模式 | 后果 | 正确做法 |
|---|---|---|
| 模糊提示(“be creative”) | 输出不可预测 | 提供具体约束和评估标准 |
| 厨房水槽式上下文(500K 全量注入) | 注意力稀释、成本爆炸 | 精准 RAG,20K 精选 Chunk |
| 无 Schema 强制 | Regex 解析地狱、下游崩溃 | JSON Schema + additionalProperties: false |
| 缺失迭代上限 | Agent 无限循环、Token 耗尽 | 硬性 cap(25-50)+ 降级策略 |
| 无评估框架 | “Ship & Pray” | G-Eval + 回归测试集 |
| 忽略 Token 衰减 | 关键信息被模型"遗忘" | 关键约束放在开头和结尾 |
六、实战案例:从需求到生产级 Prompt
场景:构建一个医疗报告结构化提取系统
需求:从非结构化的医生手写报告中提取关键字段(诊断、用药、随访建议),输出为结构化 JSON。
Step 1: 系统提示设计
You are a medical information extraction specialist.
Your task is to extract structured information from clinical notes.
You MUST follow these rules:
1. Only extract information explicitly stated in the text
2. If information is missing, use null, do not invent
3. Use exact medical terminology from the source text
4. Flag any ambiguous or contradictory information
Output MUST conform to the provided JSON schema.
Step 2: Schema 设计
{
"type": "object",
"additionalProperties": false,
"required": ["diagnosis", "medications", "follow_up", "confidence"],
"properties": {
"diagnosis": {
"type": "array",
"items": {"type": "string"},
"description": "Primary and secondary diagnoses mentioned in the note"
},
"medications": {
"type": "array",
"items": {
"type": "object",
"required": ["name", "dosage", "frequency"],
"properties": {
"name": {"type": "string"},
"dosage": {"type": "string"},
"frequency": {"type": "string"}
}
}
},
"follow_up": {
"type": ["string", "null"],
"description": "Follow-up instructions or null if not mentioned"
},
"confidence": {
"type": "string",
"enum": ["high", "medium", "low"],
"description": "Your confidence in the extraction completeness"
}
}
}
Step 3: Few-Shot 示例
<example>
Input: "Patient presents with Type 2 diabetes, prescribed Metformin 500mg twice daily.
Return in 2 weeks for glucose monitoring."
Output:
{
"diagnosis": ["Type 2 diabetes"],
"medications": [{"name": "Metformin", "dosage": "500mg", "frequency": "twice daily"}],
"follow_up": "Return in 2 weeks for glucose monitoring",
"confidence": "high"
}
</example>
Step 4: 评估与迭代
- 构建 100 条标注好的测试集
- 使用 G-Eval 评估字段级 F1 分数
- 对低置信度输出进行人工审核
- 每两周基于新数据迭代 Prompt
七、总结与展望
Prompt Engineering 在 2026 年已经从一个"写作技巧"演变为系统性的工程学科。它的核心转变体现在:
- 从单次提示到工作流设计:Prompt 是可重复、可版本化、可测试的资产
- 从文本优化到架构设计:分层结构、Schema 强制、工具集成、观测反馈
- 从人工调优到自动优化:DSPy、贝叶斯优化、遗传算法成为标准工具
- 从通用技巧到场景定制:根据任务复杂度、准确率要求和 Token 预算选择框架
展望未来,Prompt Engineering 的演进方向包括:
- 混合多模态提示:文本、图像、代码、音频的跨模态推理
- 动态提示自适应:推理过程中根据中间输出实时调整提示组件
- 元学习:模型跨任务泛化提示策略,减少人工设计负担
正如 2026 年的共识所言:“A useful prompt is not just a well-phrased request. It is a repeatable asset with a clear purpose, a version history, a test set, and success criteria tied to the job it needs to do.”
参考资源
- The 2026 ChatGPT Prompt Engineering Best Practices Guide
- Advanced Prompt Engineering Frameworks 2026
- Prompt Engineering in 2026: 10 Patterns That Actually Work
- Prompt Engineering Best Practices 2026
- Advanced Prompt Engineering 2026: Definitive Guide
- Prompt Engineering Techniques: The 2026 Enterprise Guide

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)