Memory——让 AI 助手跨会话记住你的偏好
在 Agent 工程化落地中,上下文窗口始终是核心瓶颈:不压缩,token 开销爆炸;一压缩,关键细节就会在摘要中退化;更棘手的是跨会话失忆 —— 用户反复强调的代码风格、项目背景、禁忌规则,新开一个对话就全部清零。
Claude Code 给出了一套轻量且工程化的持久记忆层方案:基于本地文件系统构建记忆库,通过「索引常驻 + 按需加载 + 异步提取」的分层设计,在几乎不阻塞主对话流程的前提下,实现了跨会话、不丢失细节的长期记忆能力。
一、问题根源:上下文压缩的天生缺陷
之前文章中讲到的autoCompact 机制解决了单会话上下文膨胀问题,但本质是有损压缩,存在两个固有局限:
- 细节退化:「代码缩进必须使用 tab 而非空格」会被摘要简化为「用户有代码风格偏好」,执行精度大幅下降
- 会话隔离:LLM 本身没有持久状态,所有信息仅存活于当前上下文窗口,新开会话一切归零
我们需要一层不参与上下文压缩、跨会话永久保留的独立存储,专门沉淀稳定、高复用的信息。
二、整体架构:分层存储 + 按需召回
整套记忆系统的核心设计原则是:索引用最低成本打底,详情只在相关时加载,写入全部异步执行。
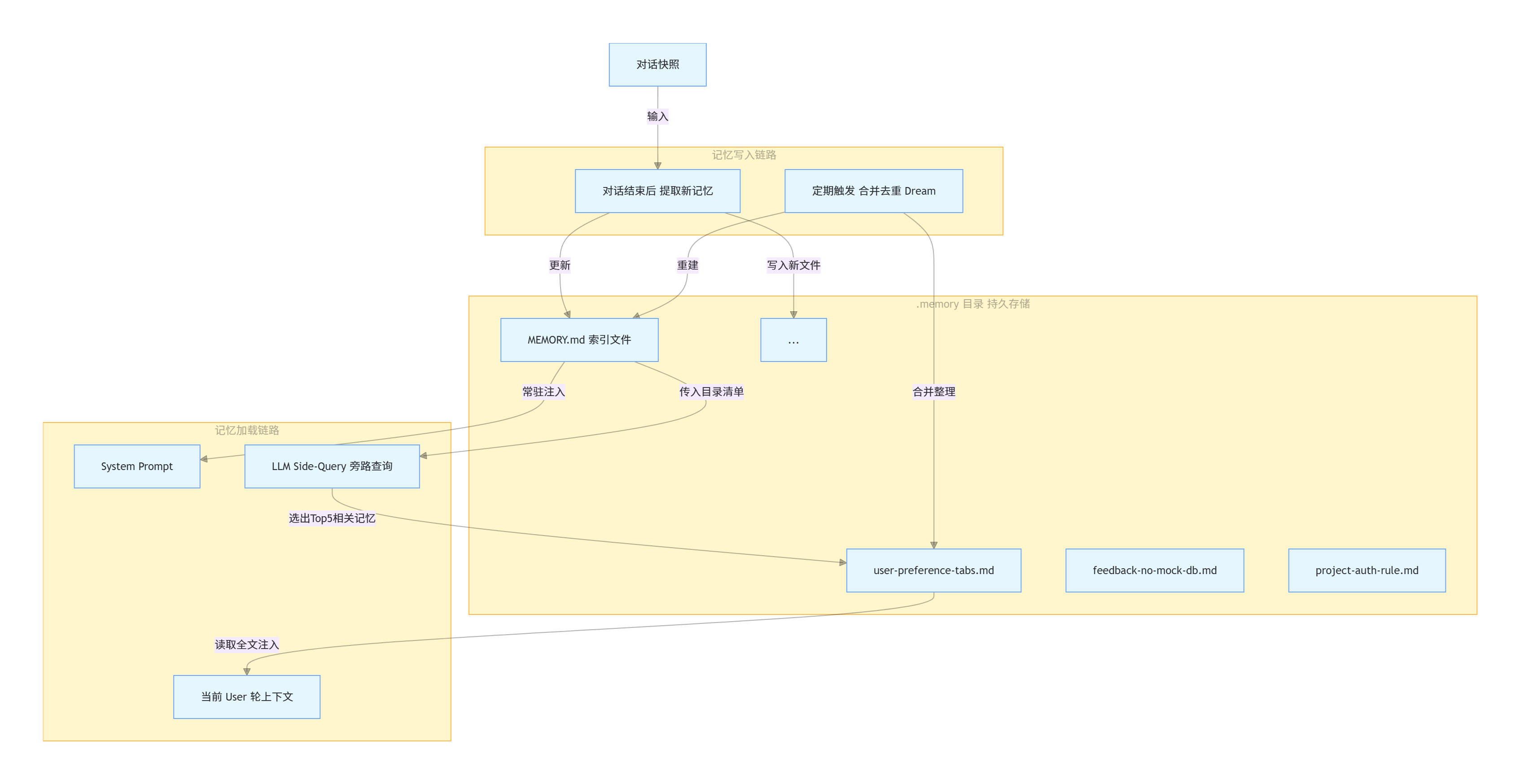
存储全部落在本地 .memory/ 目录下,加载和写入完全解耦:
- 加载侧:两条路径配合,兼顾成本与精准度
- 写入侧:全异步执行,不占用主对话耗时
整体涉及到的模块也就是这些:(文末的demo代码会给出)
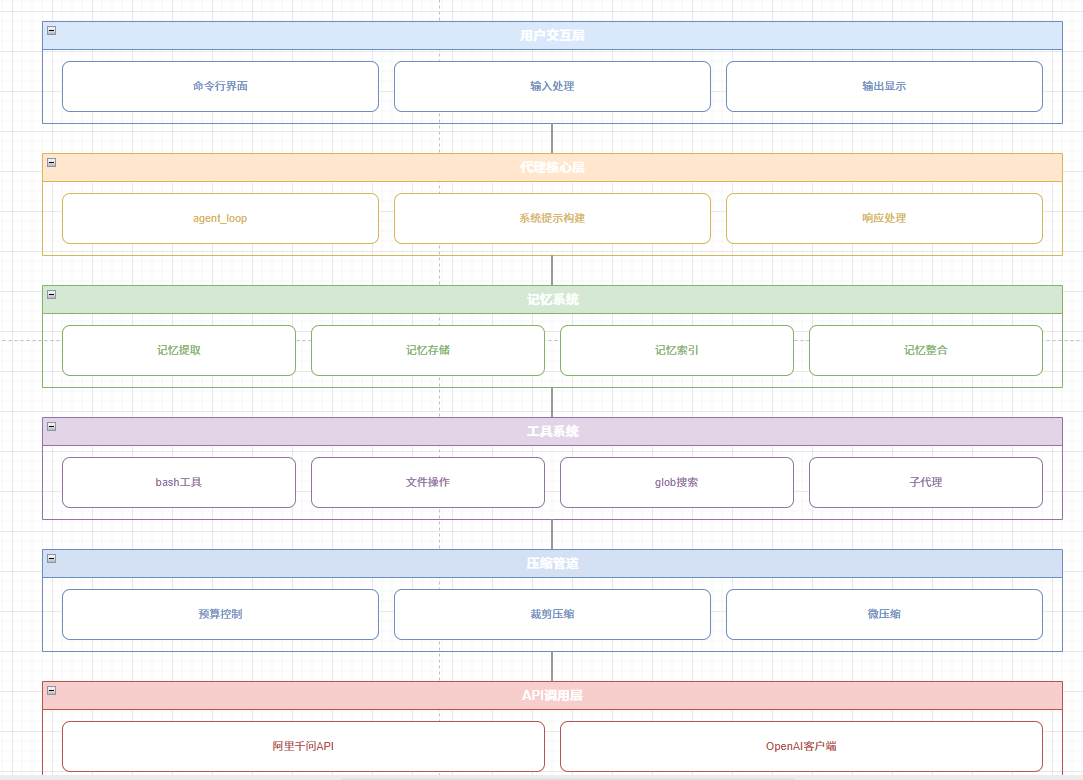
三、存储结构:单文件 + 统一索引
记忆采用「单记忆单文件 + 全局索引」的文件化设计,无需数据库,轻量可编辑。
1. 单记忆文件
每个记忆对应一个 .md 文件,头部用 YAML Frontmatter 记录元数据,正文存储完整细节:
---
name: user-preference-tab-indentation
description: 偏好使用制表符(Tab)进行代码缩进
type: user
---
- 用户明确表示在编写代码时更习惯使用制表符(Tab)作为缩进单位,而非空格。
- 要求助手在未来的代码生成、格式调整或工程配置建议中严格遵循此设定。2. 全局索引
MEMORY.md 作为记忆目录,一行一条记录,仅包含名称与描述,体积极小:
- [user-preference-tab-indentation](user-preference-tab-indentation.md) — 偏好使用制表符(Tab)进行代码缩进每次记忆变更时自动重建索引。
这是我使用demo测试时的结果(放在文章最后面)
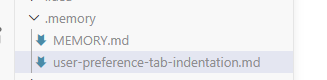
输入:我更习惯用制表符(Tab)来缩进代码,而非空格,记住这点。
然后模型就会将这个记忆归档成md文档
3. 四类记忆分工
按用途将记忆分为四类,覆盖长期协作的核心诉求:
|
类型 |
定位 |
典型示例 |
|
user |
用户偏好与身份 |
缩进用 tab、字符串用单引号 |
|
feedback |
做事规则与禁忌 |
不要 mock 数据库、输出不用 emoji |
|
project |
项目背景与事实 |
auth 模块重写由合规要求驱动 |
|
reference |
信息入口与线索 |
流水线故障排查入口在 Linear INGEST |
四、全链路工作流程
每一轮用户请求,都会完整走过「加载 → 对话 → 提取 → 整理」四个阶段。
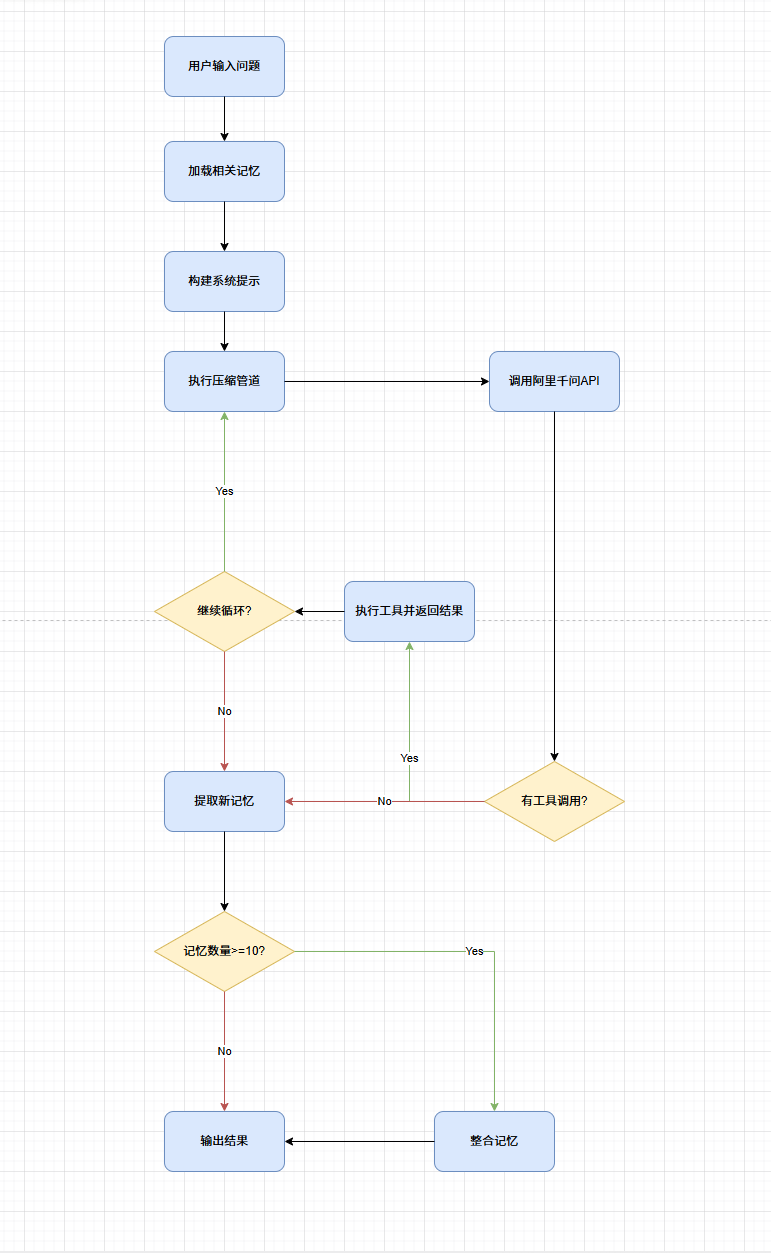
1. 加载:双路径平衡成本与精准
- 路径一:索引常驻。每次请求构建 System Prompt 时,直接读取
MEMORY.md(注意这个里面只是存储的记忆的索引) 注入。内容稳定可被 Prompt Cache 缓存,token 开销极低,作用是让模型知道「我有这些记忆可用」。

例如这样的一段提示词构建:
def build_system() -> str:
index = read_memory_index() # 读取记忆索引
memories_section = f"\n\n可用记忆:\n{index}" if index else ""
return (
f"你是位于{WORKDIR}的编码代理。" # 角色定义
f"{memories_section}\n" # 记忆上下文
"相关记忆已注入下方。尊重记忆中的用户偏好。\n" # 行为规范
"当用户说'remember'或表达明确偏好时,将其提取为记忆。" # 记忆提取指令
)实际效果
系统提示注入了记忆索引后,AI模型会看到类似:
你是位于D:\JavaProject\IdeaProject\learn-claude-code的编码代理。
可用记忆:
- [user-preference-tabs](user-preference-tabs.md) — 用户喜欢4空格缩进
- [project-react](project-react.md) — 项目使用React框架
相关记忆已注入下方。尊重记忆中的用户偏好。
当用户说'remember'或表达明确偏好时,将其提取为记忆。这样AI就知道要记住并尊重用户的偏好设置。
- 路径二:按需召回。发起一次轻量 LLM 旁路查询(Side-Query),将最近对话与记忆目录清单传给模型,选出最多 5 条最相关的记忆,读取全文注入当前用户轮次。如果旁路查询失败,自动降级为关键词匹配,保证可用性。

例如这样一段代码:
def agent_loop(messages):
memories_content = load_memories(messages) # 根据用户消息加载相关记忆的具体内容
# 注入到当前用户消息中
request_messages[memory_turn] = {
**messages[memory_turn],
"content": memories_content + "\n\n" + messages[memory_turn]["content"],
}作用:将相关记忆的具体内容注入到对话中
2. 提取:轮后自动沉淀
不需要用户主动说「记住这个」,系统会自动从对话中提取稳定信息:
- 触发时机:本轮对话完全结束(停止原因不是工具调用)
- 执行逻辑:取最近 10 轮对话,与已有记忆做去重对比,由 LLM 判断是否产生新的稳定偏好、约束或项目事实
- 输出格式:标准 JSON 数组,无新信息则返回空数组,避免重复写入
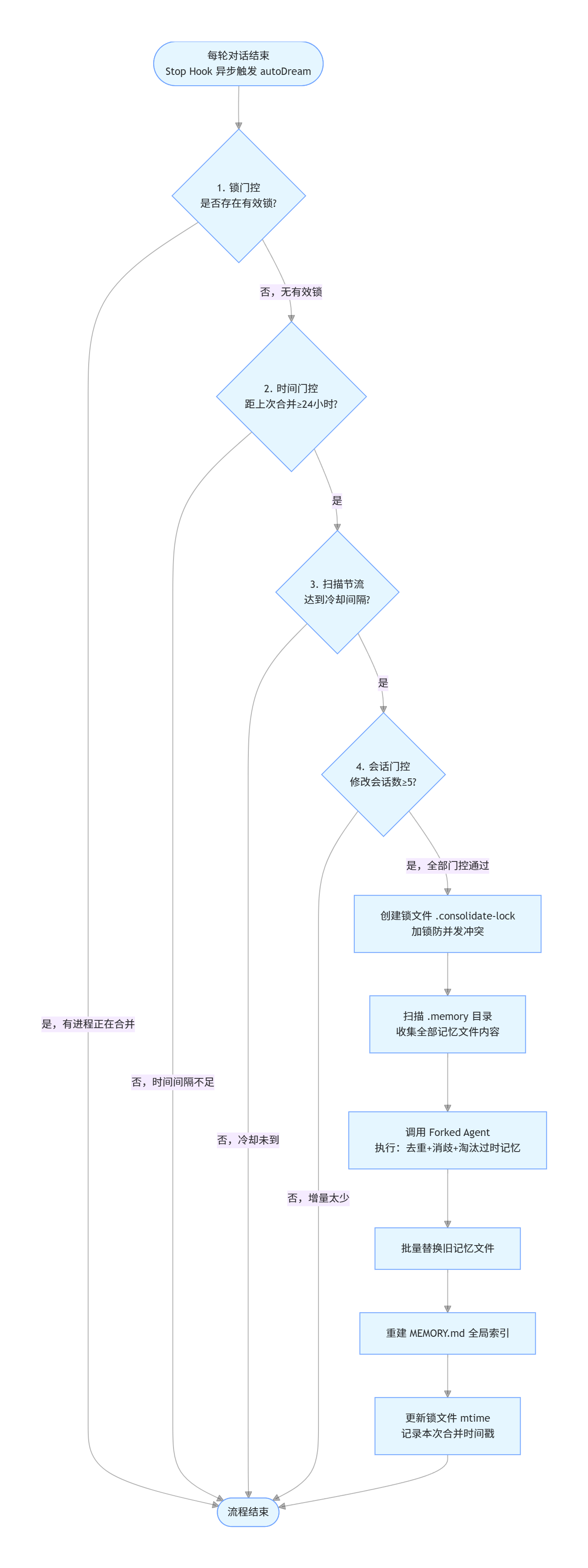
3. 整理:定期合并去重(Dream)
记忆长期积累会出现冗余、矛盾、过时内容,需要定期整理,这一机制被称为 Dream:
- 教学简化版:记忆文件数 ≥ 10 时触发
- 源码生产版:四层门控严格控制触发频率
-
- 时间门控:距上次合并 ≥ 24 小时
- 扫描节流:限制文件系统扫描频率
- 会话门控:上次合并后 ≥ 5 个会话产生修改
- 锁门控:文件锁保证多进程并发安全,1 小时自动过期防死锁
五、关键设计决策解析
1. 为什么用 LLM 选记忆,而不是 Embedding 向量召回?
记忆量级控制在 200 条以内时,LLM 直接选择有明显优势:
- 语义理解更精准,能判断真实相关性,避免字面相似但语义无关的误召回
- 无需额外维护向量数据库,架构更轻量
- 直接返回文件名,链路简单,调试成本低
2. 为什么写入全部异步执行?
记忆提取和整理都放在对话结束后异步执行,核心原因:
- 不阻塞主对话流程,用户无感知延迟
- 对话完整后提取信息更准确,避免碎片化提取导致的冗余
- 整理操作耗时较长,异步执行不会影响正常交互
3. 为什么用文件系统存储?
- 零依赖,无需额外部署数据库
- 文件可直接查看、编辑,符合开发者的使用习惯
- 项目级隔离,不同项目的记忆完全独立存储
六、长期记忆 vs 会话记忆
注意区分两个容易混淆的记忆概念,二者是互补关系而非替代:
|
长期记忆(User Memory) |
会话记忆(Session Memory) |
|
|
持久性 |
跨会话永久保留 |
仅当前会话有效 |
|
存储位置 |
|
|
|
核心作用 |
沉淀长期稳定的知识与偏好 |
保证上下文压缩后对话连续,其实就是摘要 |
|
注入位置 |
System Prompt + 用户轮次 |
压缩摘要中 |
七:demo代码
#!/usr/bin/env python3
"""
s09_memory.py - 记忆系统
为编码代理提供持久化、跨会话的知识存储。
存储结构:
.memory/
MEMORY.md ← 索引文件(每行一个记忆条目,≤200行)
feedback_tabs.md ← 单个记忆文件(Markdown + YAML frontmatter)
user_profile.md
project_facts.md
在agent_loop中的流程:
1. 将MEMORY.md索引加载到SYSTEM提示中(成本低,始终存在)
2. 通过文件名/描述选择相关记忆 → 注入内容
3. 运行s08的压缩管道
4. 每轮结束后 → 从原始消息中提取新记忆
5. 定期整合(Dream)
基于s08(上下文压缩)构建。使用方法:
python s09_memory/code.py
需要:pip install openai python-dotenv + 在.env中设置OPENAI_API_KEY
"""
import os, subprocess, json, time, re
from pathlib import Path
try:
import readline
readline.parse_and_bind('set bind-tty-special-chars off')
except ImportError:
pass
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv(override=True)
WORKDIR = Path.cwd()
MEMORY_DIR = WORKDIR / ".memory"; MEMORY_DIR.mkdir(exist_ok=True)
MEMORY_INDEX = MEMORY_DIR / "MEMORY.md"
SKILLS_DIR = WORKDIR / "skills"
TRANSCRIPT_DIR = WORKDIR / ".transcripts"
TOOL_RESULTS_DIR = WORKDIR / ".task_outputs" / "tool-results"
# 阿里千问配置(OpenAI兼容API)
client = OpenAI(
api_key=os.getenv("OPENAI_API_KEY"),
base_url=os.getenv("OPENAI_BASE_URL", "https://dashscope.aliyuncs.com/compatible-mode/v1")
)
MODEL = os.getenv("MODEL_ID", "qwen-plus")
# ═══════════════════════════════════════════════════════════
# s09新增:记忆系统
# ═══════════════════════════════════════════════════════════
MEMORY_TYPES = ["user", "feedback", "project", "reference"]
def _parse_frontmatter(text: str) -> tuple[dict, str]:
"""解析YAML frontmatter"""
if not text.startswith("---"):
return {}, text
parts = text.split("---", 2)
if len(parts) < 3:
return {}, text
meta = {}
for line in parts[1].strip().splitlines():
if ":" in line:
k, v = line.split(":", 1)
meta[k.strip()] = v.strip().strip('"').strip("'")
return meta, parts[2].strip()
def write_memory_file(name: str, mem_type: str, description: str, body: str):
"""写入单个记忆文件,包含YAML frontmatter"""
slug = name.lower().replace(" ", "-").replace("/", "-")
filename = f"{slug}.md"
filepath = MEMORY_DIR / filename
filepath.write_text(
f"---\nname: {name}\ndescription: {description}\ntype: {mem_type}\n---\n\n{body}\n",
encoding='utf-8'
)
_rebuild_index()
return filepath
def _rebuild_index():
"""从所有记忆文件重建MEMORY.md索引"""
lines = []
for f in sorted(MEMORY_DIR.glob("*.md")):
if f.name == "MEMORY.md":
continue
raw = f.read_text(encoding='utf-8')
meta, body = _parse_frontmatter(raw)
name = meta.get("name", f.stem)
desc = meta.get("description", body.split("\n")[0][:80])
lines.append(f"- [{name}]({f.name}) — {desc}")
MEMORY_INDEX.write_text("\n".join(lines) + "\n" if lines else "", encoding='utf-8')
def read_memory_index() -> str:
"""读取MEMORY.md索引(每轮注入到SYSTEM中)"""
if not MEMORY_INDEX.exists():
return ""
text = MEMORY_INDEX.read_text(encoding='utf-8').strip()
return text if text else ""
def read_memory_file(filename: str) -> str | None:
"""读取单个记忆文件的完整内容"""
path = MEMORY_DIR / filename
if not path.exists():
return None
return path.read_text(encoding='utf-8')
def list_memory_files() -> list[dict]:
"""列出所有记忆文件及其元数据"""
result = []
for f in sorted(MEMORY_DIR.glob("*.md")):
if f.name == "MEMORY.md":
continue
raw = f.read_text(encoding='utf-8')
meta, body = _parse_frontmatter(raw)
result.append({
"filename": f.name,
"name": meta.get("name", f.stem),
"description": meta.get("description", ""),
"type": meta.get("type", "user"),
"body": body,
})
return result
def select_relevant_memories(messages: list, max_items: int = 5) -> list[str]:
"""通过匹配最近对话与记忆名称/描述来选择相关的记忆文件。
使用简单的LLM调用(或回退到关键词匹配)"""
files = list_memory_files()
if not files:
return []
# 收集最近的用户文本作为上下文
recent_texts = []
for msg in reversed(messages):
if msg.get("role") == "user":
content = msg.get("content", "")
if isinstance(content, list):
content = " ".join(
str(getattr(b, "text", "")) for b in content
if getattr(b, "type", None) == "text"
)
if isinstance(content, str):
recent_texts.append(content)
if len(recent_texts) >= 3:
break
recent = " ".join(reversed(recent_texts))[:2000]
if not recent.strip():
return []
# 构建名称+描述的目录供LLM选择
catalog_lines = []
for i, f in enumerate(files):
catalog_lines.append(f"{i}: {f['name']} — {f['description']}")
catalog = "\n".join(catalog_lines)
prompt = (
"给定以下最近对话和记忆目录,"
"选择明显相关的记忆索引。"
"仅返回一个JSON整数数组,例如[0, 3]。"
"如果没有相关的,返回[]。\n\n"
f"最近对话:\n{recent}\n\n"
f"记忆目录:\n{catalog}"
)
try:
response = client.chat.completions.create(
model=MODEL,
messages=[{"role": "user", "content": prompt}],
max_tokens=200,
)
text = response.choices[0].message.content.strip()
# 从响应中提取JSON数组
match = re.search(r'\[.*?\]', text, re.DOTALL)
if match:
indices = json.loads(match.group())
selected = []
for idx in indices:
if isinstance(idx, int) and 0 <= idx < len(files):
selected.append(files[idx]["filename"])
if len(selected) >= max_items:
break
return selected
except Exception:
pass
# 回退:基于名称和描述的关键词匹配
keywords = [w.lower() for w in recent.split() if len(w) > 3]
selected = []
for f in files:
text = (f["name"] + " " + f["description"]).lower()
if any(kw in text for kw in keywords):
selected.append(f["filename"])
if len(selected) >= max_items:
break
return selected
def load_memories(messages: list) -> str:
"""加载相关记忆内容以注入到上下文中"""
selected_files = select_relevant_memories(messages)
if not selected_files:
return ""
parts = ["<relevant_memories>"]
for filename in selected_files:
content = read_memory_file(filename)
if content:
parts.append(content)
parts.append("</relevant_memories>")
return "\n\n".join(parts)
def extract_memories(messages: list):
"""从最近对话中提取新记忆。每轮结束后运行。"""
# 收集最近的对话文本
dialogue_parts = []
for msg in messages[-10:]:
role = msg.get("role", "?")
content = msg.get("content", "")
if isinstance(content, list):
content = " ".join(
str(getattr(b, "text", "")) for b in content
if getattr(b, "type", None) == "text"
)
if isinstance(content, str) and content.strip():
dialogue_parts.append(f"{role}: {content}")
dialogue = "\n".join(dialogue_parts)
if not dialogue.strip():
return
# 检查现有记忆以避免重复
existing = list_memory_files()
existing_desc = "\n".join(f"- {m['name']}: {m['description']}" for m in existing) if existing else "(无)"
prompt = (
"从以下对话中提取用户偏好、约束或项目事实。\n"
"返回一个JSON数组。每个项目:{name, type, description, body}。\n"
"- name:简短的kebab-case标识符(例如'user-preference-tabs')\n"
"- type:'user'(用户偏好)、'feedback'(指导)、"
"'project'(项目事实)、'reference'(外部指针)之一\n"
"- description:用于索引查找的一行摘要\n"
"- body:markdown格式的完整详情\n"
"如果没有新内容或已被现有记忆覆盖,返回[]。\n\n"
f"现有记忆:\n{existing_desc}\n\n"
f"对话:\n{dialogue[:4000]}"
)
try:
response = client.chat.completions.create(
model=MODEL, messages=[{"role": "user", "content": prompt}], max_tokens=800
)
text = response.choices[0].message.content.strip()
# 从响应中提取JSON数组
match = re.search(r'\[.*\]', text, re.DOTALL)
if not match:
return
items = json.loads(match.group())
if not items:
return
count = 0
for mem in items:
name = mem.get("name", f"memory_{int(time.time())}")
mem_type = mem.get("type", "user")
desc = mem.get("description", "")
body = mem.get("body", "")
if desc and body:
write_memory_file(name, mem_type, desc, body)
count += 1
if count:
print(f"\n\033[33m[记忆:提取了{count}个新记忆]\033[0m")
except Exception:
pass
CONSOLIDATE_THRESHOLD = 10
def consolidate_memories():
"""合并重复/过时的记忆。当文件数量≥阈值时触发。"""
files = list_memory_files()
if len(files) < CONSOLIDATE_THRESHOLD:
return
catalog = "\n\n".join(
f"## {f['filename']}\nname: {f['name']}\ndescription: {f['description']}\n{f['body']}"
for f in files
)
prompt = (
"整合以下记忆文件。规则:\n"
"1. 将重复项合并为一个\n"
"2. 删除过时/矛盾的记忆\n"
"3. 保持总数在30个记忆以下\n"
"4. 首先保留重要的用户偏好\n"
"返回一个JSON数组。每个项目:{name, type, description, body}。\n\n"
f"{catalog[:16000]}"
)
try:
response = client.chat.completions.create(
model=MODEL, messages=[{"role": "user", "content": prompt}], max_tokens=3000
)
text = response.choices[0].message.content.strip()
match = re.search(r'\[.*\]', text, re.DOTALL)
if not match:
return
items = json.loads(match.group())
# 删除旧的记忆文件(保留MEMORY.md)
for f in MEMORY_DIR.glob("*.md"):
if f.name != "MEMORY.md":
f.unlink()
for mem in items:
name = mem.get("name", f"memory_{int(time.time())}")
mem_type = mem.get("type", "user")
desc = mem.get("description", "")
body = mem.get("body", "")
if desc and body:
write_memory_file(name, mem_type, desc, body)
print(f"\n\033[33m[记忆:整合了{len(files)} → {len(items)}个记忆]\033[0m")
except Exception:
pass
# 构建带有记忆索引的SYSTEM提示
def build_system() -> str:
index = read_memory_index()
memories_section = f"\n\n可用记忆:\n{index}" if index else ""
return (
f"你是位于{WORKDIR}的编码代理。"
f"{memories_section}\n"
"相关记忆已注入下方。尊重记忆中的用户偏好。\n"
"当用户说'remember'或表达明确偏好时,将其提取为记忆。"
)
SUB_SYSTEM = (
f"你是位于{WORKDIR}的编码代理。"
"完成分配给你的任务,然后返回简洁的摘要。"
"不要进一步委派。"
)
# ═══════════════════════════════════════════════════════════
# 来自s02-s08(骨架):基本工具
# ═══════════════════════════════════════════════════════════
def safe_path(p: str) -> Path:
"""安全路径检查,确保路径在工作区内"""
path = (WORKDIR / p).resolve()
if not path.is_relative_to(WORKDIR): raise ValueError(f"路径逃逸工作区:{p}")
return path
def run_bash(command: str) -> str:
"""运行bash命令"""
try:
r = subprocess.run(command, shell=True, cwd=WORKDIR, capture_output=True, text=True, timeout=120)
out = (r.stdout + r.stderr).strip()
return out[:50000] if out else "(无输出)"
except subprocess.TimeoutExpired: return "错误:超时(120秒)"
def run_read(path: str, limit: int | None = None) -> str:
"""读取文件内容"""
try:
lines = safe_path(path).read_text().splitlines()
if limit and limit < len(lines): lines = lines[:limit] + [f"... (还有{len(lines) - limit}行)"]
return "\n".join(lines)
except Exception as e: return f"错误:{e}"
def run_write(path: str, content: str) -> str:
"""写入文件内容"""
try:
file_path = safe_path(path); file_path.parent.mkdir(parents=True, exist_ok=True)
file_path.write_text(content); return f"向{path}写入了{len(content)}字节"
except Exception as e: return f"错误:{e}"
def run_edit(path: str, old_text: str, new_text: str) -> str:
"""编辑文件内容"""
try:
file_path = safe_path(path)
text = file_path.read_text()
if old_text not in text: return f"错误:在{path}中未找到文本"
file_path.write_text(text.replace(old_text, new_text, 1))
return f"编辑了{path}"
except Exception as e: return f"错误:{e}"
def run_glob(pattern: str) -> str:
"""查找匹配模式的文件"""
import glob as g
try:
results = []
for match in g.glob(pattern, root_dir=WORKDIR):
if (WORKDIR / match).resolve().is_relative_to(WORKDIR):
results.append(match)
return "\n".join(results) if results else "(无匹配)"
except Exception as e: return f"错误:{e}"
def extract_text(content) -> str:
"""从内容中提取文本"""
if not isinstance(content, list): return str(content)
return "\n".join(getattr(b, "text", "") for b in content if getattr(b, "type", None) == "text")
# 子代理(从s06-s07简化)
SUB_TOOLS = [
{"type": "function", "function": {"name": "bash", "description": "运行shell命令。",
"parameters": {"type": "object", "properties": {"command": {"type": "string"}}, "required": ["command"]}}},
{"type": "function", "function": {"name": "read_file", "description": "读取文件内容。",
"parameters": {"type": "object", "properties": {"path": {"type": "string"}}, "required": ["path"]}}},
{"type": "function", "function": {"name": "write_file", "description": "将内容写入文件。",
"parameters": {"type": "object", "properties": {"path": {"type": "string"}, "content": {"type": "string"}}, "required": ["path", "content"]}}},
]
SUB_HANDLERS = {"bash": run_bash, "read_file": run_read, "write_file": run_write}
def spawn_subagent(description: str) -> str:
"""启动子代理处理子任务"""
print(f"\n\033[35m[子代理已启动]\033[0m")
messages = [{"role": "user", "content": description}]
for _ in range(30):
response = client.chat.completions.create(model=MODEL,
messages=[{"role": "system", "content": SUB_SYSTEM}] + messages,
tools=SUB_TOOLS, max_tokens=8000)
assistant_message = response.choices[0].message
messages.append({"role": "assistant", "content": assistant_message.content})
if not assistant_message.tool_calls: break
results = []
for tool_call in assistant_message.tool_calls:
function = tool_call.function
handler = SUB_HANDLERS.get(function.name)
args = json.loads(function.arguments)
output = handler(**args) if handler else f"未知:{function.name}"
print(f" \033[90m[子] {function.name}: {str(output)[:100]}\033[0m")
results.append({"type": "tool_result", "tool_use_id": tool_call.id, "content": output})
messages.append({"role": "user", "content": results})
result = extract_text(messages[-1]["content"])
if not result:
for msg in reversed(messages):
if msg["role"] == "assistant":
result = extract_text(msg["content"])
if result: break
if not result: result = "子代理在30轮后停止,没有最终答案。"
print(f"\033[35m[子代理完成]\033[0m")
return result
# ═══════════════════════════════════════════════════════════
# 来自s08(骨架):压缩管道
# ═══════════════════════════════════════════════════════════
CONTEXT_LIMIT = 50000; KEEP_RECENT = 3; PERSIST_THRESHOLD = 30000
def estimate_size(msgs):
"""估算消息大小"""
return len(str(msgs))
def _block_type(block):
"""获取块类型"""
return block.get("type") if isinstance(block, dict) else getattr(block, "type", None)
def _message_has_tool_use(msg):
"""检查消息是否包含工具使用"""
if msg.get("role") != "assistant":
return False
content = msg.get("content")
if not isinstance(content, list):
return False
return any(_block_type(block) == "tool_use" for block in content)
def _is_tool_result_message(msg):
"""检查消息是否为工具结果"""
if msg.get("role") != "user":
return False
content = msg.get("content")
if not isinstance(content, list):
return False
return any(isinstance(block, dict) and block.get("type") == "tool_result" for block in content)
def snip_compact(msgs, mx=50):
"""裁剪压缩消息"""
if len(msgs) <= mx: return msgs
head_end, tail_start = 3, len(msgs) - (mx - 3)
if head_end > 0 and _message_has_tool_use(msgs[head_end - 1]):
while head_end < len(msgs) and _is_tool_result_message(msgs[head_end]):
head_end += 1
if (tail_start > 0 and tail_start < len(msgs)
and _is_tool_result_message(msgs[tail_start])
and _message_has_tool_use(msgs[tail_start - 1])):
tail_start -= 1
if head_end >= tail_start:
return msgs
return msgs[:head_end] + [{"role": "user", "content": f"[裁剪了{tail_start - head_end}条消息]"}] + msgs[tail_start:]
def collect_tool_results(msgs):
"""收集工具结果"""
blocks = []
for mi, msg in enumerate(msgs):
if msg.get("role") != "user" or not isinstance(msg.get("content"), list): continue
for bi, block in enumerate(msg["content"]):
if isinstance(block, dict) and block.get("type") == "tool_result": blocks.append((mi, bi, block))
return blocks
def micro_compact(msgs):
"""微压缩消息"""
tr = collect_tool_results(msgs)
if len(tr) <= KEEP_RECENT: return msgs
for _, _, b in tr[:-KEEP_RECENT]:
if len(b.get("content", "")) > 120: b["content"] = "[早期工具结果已压缩。]"
return msgs
def persist_large(tid, out):
"""持久化大输出"""
if len(out) <= PERSIST_THRESHOLD: return out
TOOL_RESULTS_DIR.mkdir(parents=True, exist_ok=True)
p = TOOL_RESULTS_DIR / f"{tid}.txt"
if not p.exists(): p.write_text(out, encoding='utf-8')
return f"<持久化输出>\n完整:{p}\n预览:\n{out[:2000]}\n</持久化输出>"
def tool_result_budget(msgs, mx=200_000):
"""工具结果预算控制"""
last = msgs[-1] if msgs else None
if not last or last.get("role") != "user" or not isinstance(last.get("content"), list): return msgs
blocks = [(i, b) for i, b in enumerate(last["content"]) if isinstance(b, dict) and b.get("type") == "tool_result"]
total = sum(len(str(b.get("content", ""))) for _, b in blocks)
if total <= mx: return msgs
for _, block in sorted(blocks, key=lambda p: len(str(p[1].get("content", ""))), reverse=True):
if total <= mx: break
c = str(block.get("content", ""))
if len(c) <= PERSIST_THRESHOLD: continue
block["content"] = persist_large(block.get("tool_use_id", "?"), c)
total = sum(len(str(b.get("content", ""))) for _, b in blocks)
return msgs
def write_transcript(msgs):
"""写入对话记录"""
TRANSCRIPT_DIR.mkdir(parents=True, exist_ok=True)
p = TRANSCRIPT_DIR / f"transcript_{int(time.time())}.jsonl"
with p.open("w", encoding='utf-8') as f:
for m in msgs: f.write(json.dumps(m, default=str, ensure_ascii=False) + "\n")
return p
def summarize_history(msgs):
"""总结历史对话"""
conv = json.dumps(msgs, default=str)[:80000]
r = client.chat.completions.create(model=MODEL, messages=[{"role": "user", "content":
"总结此编码代理对话以便继续工作。\n"
"保留:1. 当前目标,2. 关键发现,3. 已更改文件,4. 剩余工作,5. 用户约束。\n\n" + conv}],
max_tokens=2000)
return r.choices[0].message.content.strip()
def compact_history(msgs):
"""压缩历史对话"""
write_transcript(msgs)
summary = summarize_history(msgs)
return [{"role": "user", "content": f"[已压缩]\n\n{summary}"}]
def reactive_compact(msgs):
"""反应式压缩"""
write_transcript(msgs)
tail_start = max(0, len(msgs) - 5)
if (tail_start > 0 and tail_start < len(msgs)
and _is_tool_result_message(msgs[tail_start])
and _message_has_tool_use(msgs[tail_start - 1])):
tail_start -= 1
summary = summarize_history(msgs[:tail_start])
return [{"role": "user", "content": f"[反应式压缩]\n\n{summary}"}, *msgs[tail_start:]]
# ═══════════════════════════════════════════════════════════
# 工具定义(骨架 - 较少工具以专注于记忆)
# ═══════════════════════════════════════════════════════════
TOOLS = [
{"type": "function", "function": {"name": "bash", "description": "运行shell命令。",
"parameters": {"type": "object", "properties": {"command": {"type": "string"}}, "required": ["command"]}}},
{"type": "function", "function": {"name": "read_file", "description": "读取文件内容。",
"parameters": {"type": "object", "properties": {"path": {"type": "string"}}, "required": ["path"]}}},
{"type": "function", "function": {"name": "write_file", "description": "将内容写入文件。",
"parameters": {"type": "object", "properties": {"path": {"type": "string"}, "content": {"type": "string"}}, "required": ["path", "content"]}}},
{"type": "function", "function": {"name": "edit_file", "description": "在文件中替换精确文本。",
"parameters": {"type": "object", "properties": {"path": {"type": "string"}, "old_text": {"type": "string"}, "new_text": {"type": "string"}}, "required": ["path", "old_text", "new_text"]}}},
{"type": "function", "function": {"name": "glob", "description": "查找匹配glob模式的文件。",
"parameters": {"type": "object", "properties": {"pattern": {"type": "string"}}, "required": ["pattern"]}}},
{"type": "function", "function": {"name": "task", "description": "启动子代理处理子任务。",
"parameters": {"type": "object", "properties": {"description": {"type": "string"}}, "required": ["description"]}}},
]
TOOL_HANDLERS = {
"bash": run_bash, "read_file": run_read, "write_file": run_write,
"edit_file": run_edit, "glob": run_glob, "task": spawn_subagent,
}
# ═══════════════════════════════════════════════════════════
# agent_loop — s09:注入记忆 + 每轮后提取
# ═══════════════════════════════════════════════════════════
MAX_REACTIVE_RETRIES = 1
def agent_loop(messages: list):
"""代理循环:s09 - 注入记忆 + 每轮后提取"""
reactive_retries = 0
# s09:将相关记忆内容注入到当前用户轮次
memories_content = load_memories(messages)
memory_turn = len(messages) - 1 if messages and isinstance(messages[-1].get("content"), str) else None
# s09:每用户轮次构建一次系统提示;记忆在循环返回后更新
system = build_system()
while True:
# s09:保存压缩前快照以便准确提取记忆
pre_compress = [m if isinstance(m, dict) else {"role": m.get("role",""),
"content": str(m.get("content",""))} for m in messages]
# s08:压缩管道(预算 → 裁剪 → 微压缩)
messages[:] = tool_result_budget(messages)
messages[:] = snip_compact(messages)
messages[:] = micro_compact(messages)
if estimate_size(messages) > CONTEXT_LIMIT:
print("[自动压缩]")
messages[:] = compact_history(messages)
try:
request_messages = messages
if memories_content and memory_turn is not None and memory_turn < len(messages):
request_messages = messages.copy()
request_messages[memory_turn] = {
**messages[memory_turn],
"content": memories_content + "\n\n" + messages[memory_turn]["content"],
}
response = client.chat.completions.create(
model=MODEL, messages=[{"role": "system", "content": system}] + request_messages,
tools=TOOLS, max_tokens=8000
)
reactive_retries = 0
except Exception as e:
if ("prompt_too_long" in str(e).lower() or "too many tokens" in str(e).lower()) and reactive_retries < MAX_REACTIVE_RETRIES:
print("[反应式压缩]")
messages[:] = reactive_compact(messages)
reactive_retries += 1
continue
raise
assistant_message = response.choices[0].message
messages.append({"role": "assistant", "content": assistant_message.content})
if not assistant_message.tool_calls:
# s09:从压缩前快照提取以获得完整保真度
extract_memories(pre_compress)
consolidate_memories()
return
results = []
for tool_call in assistant_message.tool_calls:
function = tool_call.function
print(f"\033[36m> {function.name}\033[0m")
handler = TOOL_HANDLERS.get(function.name)
args = json.loads(function.arguments)
output = handler(**args) if handler else f"未知:{function.name}"
print(str(output)[:200])
results.append({"type": "tool_result", "tool_use_id": tool_call.id, "content": output})
messages.append({"role": "user", "content": results})
if __name__ == "__main__":
print("s09:记忆系统 — 持久化跨会话知识")
print("输入问题,回车发送。输入 q 退出。\n")
history = []
while True:
try: query = input("\033[36ms09 >> \033[0m")
except (EOFError, KeyboardInterrupt): break
if query.strip().lower() in ("q", "exit", ""): break
history.append({"role": "user", "content": query})
agent_loop(history)
# 处理OpenAI格式的响应
last_message = history[-1]
if isinstance(last_message.get("content"), str):
print(last_message["content"])
elif isinstance(last_message.get("content"), list):
for block in last_message["content"]:
if isinstance(block, dict) and block.get("type") == "text":
print(block.get("text", ""))
print()
感兴趣的宝子可以关注一波,后续会更新更多有用的知识!!!


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)