从0到1搭建企业级RAG系统(四):混合检索、Reranker精排、双层缓存与端到端问答实战
前言
在上一篇文章中,我们完成了知识库的规模化建设——通过 AI 爬虫抓取了 14 篇高质量 AI 技术文章,并成功将 718 条文本块向量化存入 Milvus。至此,我们的 RAG 系统已经拥有了一个扎实的“数据底座”。
但数据只是基础,真正的挑战在于:如何从海量知识库中精准召回最相关的文档片段,并基于这些片段生成无幻觉、高质量的回答? 并且,如何保证这个过程在生产环境下的响应速度?
本文是本系列的“集大成之作”,我们将完整记录以下核心模块的落地:
-
混合检索引擎:向量检索 + BM25 关键词检索 + RRF 融合算法
-
Reranker 二次精排:动态显存管理机制与效果量化对比
-
大模型(LLM)接入:防幻觉 Prompt 工程与 API 封装
-
RESTful API 构建:使用 FastAPI 串联全链路
-
高性能双层缓存架构:L1 精确缓存 + L2 语义缓存,将 20 秒延迟暴力降至毫秒级!
全文将延续“设计理念 → 代码实现 → 踩坑复盘”的硬核风格,并附带真实的量化对比数据,为你的项目落地和面试提供最扎实的素材。
一、起点回顾:我们现在处于什么位置?
在写代码之前,先盘点一下我们在第三篇结束时积累的资产:
| 核心组件 | 当前状态 |
| Milvus 向量数据库 | lite_rag_docs Collection 运行中,IVF_FLAT 索引 |
| 知识库规模 | 14 篇垂直领域 AI 文章,切分为 718 条向量(384 维) |
| Embedding 模型 | BGE-small 本地化封装完成 |
| 文档分块模块 | splitter.py 稳定支持 PDF/MD/TXT 解析 |
| 数据流水线 | ingest.py 脚本支持一键增量入库 |
亟待补齐的关键能力:
-
❌ 无法根据用户自然语言提问检索文档。
-
❌ 无法对粗排召回的结果进行高精度筛选。
-
❌ 无法调用大语言模型(LLM)生成最终答案。
-
❌ 尚未提供标准的对外 API 接口。
接下来的所有工作,就是为了完美补齐这四块拼图。
二、混合检索(Hybrid Search):让召回不再“偏科”
2.1 为什么必须用混合检索?
💡 设计理念:纯向量检索(基于 Embedding 相似度)擅长捕捉“语义层面的相关性”,但对精确术语(如“HNSW”、“IVF_FLAT”、“RRF”等)的硬匹配能力极差。 比如搜“Milvus 的 IVF_SQ8 索引”,向量检索可能召回一堆讲 Milvus 但没提 SQ8 的废话;而传统的 BM25 关键词检索则能精准命中。混合检索就是取向量之长,补 BM25 之短,通过融合算法得到最强候选集。
2.2 技术选型与架构
| 模块 | 技术方案 | 核心优势 |
| 向量检索 | Milvus search() |
384维 COSINE 相似度,高并发支持 |
| 倒排检索 | rank_bm25 库 |
轻量级 Python 原生实现,无需额外部署 ES |
| 中文分词 | jieba |
解决 BM25 默认空格分词对中文失效的致命缺陷 |
| 融合算法 | RRF (Reciprocal Rank Fusion) | 无需调参的经典排名融合算法(设 k=60) |
| 索引持久化 | pickle 序列化 |
首次构建后保存为 .pkl,服务重启实现秒级加载 |
2.3 核心代码实现
创建 app/core/retrieval/hybrid_search.py,核心融合逻辑如下:
Python
import jieba
from rank_bm25 import BM25Okapi
from typing import List
def tokenize(text: str) -> List[str]:
"""智能分词引擎:中文使用 jieba,纯英文保留空格切分"""
if any('\u4e00' <= char <= '\u9fff' for char in text):
return list(jieba.cut(text))
return text.lower().split()
class HybridSearchService:
def __init__(self):
self.collection.load()
self._build_bm25_index() # 从 Milvus 全量拉取文档构建 BM25 内存树
def reciprocal_rank_fusion(self, vector_results, bm25_results, k=60):
"""RRF 融合算法实现"""
rrf_scores = {}
for rank, (doc_id, _, _) in enumerate(vector_results):
rrf_scores[doc_id] = rrf_scores.get(doc_id, 0) + 1 / (k + rank)
for rank, (doc_id, _, _) in enumerate(bm25_results):
rrf_scores[doc_id] = rrf_scores.get(doc_id, 0) + 1 / (k + rank)
# 按 RRF 综合得分降序排列
return sorted(rrf_scores.items(), key=lambda x: x[1], reverse=True)
2.4 踩坑实录
-
坑 1:BM25 中文失效。直接传入中文句子,BM25 会把整句话当成一个词。解决:引入
jieba进行智能分词。 -
坑 2:Milvus 检索报类型错误。提示
required argument is not a float。解决:Numpy 的float32Python 原生不认,必须强转astype(np.float32).flatten().tolist()。 -
坑 3:
collection.is_loaded不存在。高版本 PyMilvus 移除了该属性检查。解决:直接调用具有幂等性的collection.load()。
三、Reranker 精排:画龙点睛之笔
混合检索通常会返回一个较大的候选集(如 Top-20),但大模型的输入窗口有限,且输入越多越容易发生“注意力涣散(Lost in the Middle)”。Reranker(重排序模块)就是用更复杂的交叉注意力机制,对这 20 个粗排结果进行二次审阅,挑出最精锐的 Top-3。
3.1 模型选型
选用 BAAI/bge-reranker-base,原因:
-
与 BGE Embedding 同源,生态兼容性好
-
模型大小适中(约 1.1GB),支持中文和英文
-
在 MTEB 重排序榜单上表现优异
3.2 动态显存管理
Reranker 模型不能常驻显存,否则会挤占 Embedding 模型和后续 LLM 推理的空间。我设计了动态加载/释放机制:
Python
class RerankerService:
def load_model(self):
if self.model is None:
self.model = AutoModelForSequenceClassification.from_pretrained(
model_name, torch_dtype=torch.float16
).to(self.device)
def unload_model(self):
if self.model is not None:
del self.model
torch.cuda.empty_cache() # 强制清空 GPU 缓存
self.model = None
每次重排序时加载模型,完成后立即释放显存,确保显存占用始终在可控范围内。
3.3 模型本地化下载
使用 hf download 将模型预先下载到本地,支持完全离线运行:
Bash
export HF_ENDPOINT=https://hf-mirror.com
hf download BAAI/bge-reranker-base --local-dir ./app/models/bge-reranker-base
3.4 效果量化对比
为了验证 Reranker 的真实价值,我设计了对比实验:对同一查询分别测试有/无 Reranker 的 Top-1 结果。
| 查询 | 无 Reranker Top-1 | 有 Reranker Top-1 | 关键变化 |
| 什么是RAG? | article_1709964.md |
article_1709964.md |
来源一致,精排优化了片段选择 |
| How does RAG work? | ...3-tiered-graph-rag-system.md |
article_1709964.md |
⭐ 来源改变,Reranker 纠正了 BM25 偏差 |
| RAG系统中如何优化检索召回率? | article_1709964.md |
article_1709964.md |
来源一致,精排优化了片段选择 |
核心发现:对于英文查询 How does RAG work?,原始混合检索由于 BM25 权重较高,返回了一篇深度 Graph-RAG 文章,而 Reranker 精准地将其纠正为更通用、更适合回答基础概念的中文 RAG 文章。这说明 Reranker 具备语义纠偏能力,能有效提升最终答案的准确性。
四、LLM 集成:从检索到生成
4.1 模型选型
经过对比,我选择了阿里云百炼平台的 qwen3.5-plus 模型,理由如下:
-
免费额度充足(100 万 Token),适合开发测试
-
兼容 OpenAI API 格式,迁移成本低
-
中文理解和生成能力强,适合中文技术文章问答
4.2 Prompt 工程
RAG 场景下,Prompt 的核心要求是强制模型基于上下文回答,严禁幻觉。我设计的 Prompt 模板如下:
Plaintext
你是一个专业的 AI 助手。请严格基于以下上下文信息回答问题。
如果上下文中没有相关信息,请如实回答"根据现有知识库,我无法回答这个问题",不要编造任何内容。
上下文信息:
---
{context}
---
请用清晰、专业的语言回答,并在回答末尾注明引用的信息来源(如文件名)。
4.3 API 封装
创建 app/core/llm.py,使用 OpenAI SDK 统一调用:
Python
from openai import OpenAI
class LLMService:
def __init__(self):
self.client = OpenAI(
api_key=settings.LLM_API_KEY,
base_url=settings.LLM_BASE_URL
)
def generate(self, prompt: str, context: str = "") -> str:
system_content = self._build_system_prompt(context)
response = self.client.chat.completions.create(
model=self.model,
messages=[
{"role": "system", "content": system_content},
{"role": "user", "content": prompt}
],
temperature=0.1, # RAG 场景建议低温度
timeout=60.0
)
return response.choices[0].message.content
4.4 踩坑记录
| 问题 | 原因 | 解决方案 |
| 首次调用超时(Request timed out) | 代理配置导致 API 请求走代理变慢 | 关闭代理,增加 timeout=60.0 |
五、FastAPI 接口:全链路串联
5.1 接口设计
HTTP
POST /api/v1/chat
{
"query": "什么是RAG?",
"top_k": 3,
"use_rerank": true
}
响应结构:
JSON
{
"answer": "RAG(检索增强生成)是...",
"sources": [
{
"file": "docs/article_1709964.md",
"snippet": "...",
"score": 5.0586
}
],
"latency_ms": 23738
}
5.2 核心处理流程
Python
@router.post("/chat", response_model=ChatResponse)
async def chat(request: ChatRequest):
start_time = time.time()
# 1. 混合检索 + Reranker 精排
search_results = search_service.search(
query=request.query,
top_k=request.top_k,
use_rerank=request.use_rerank
)
# 2. 构建上下文
context = "\n\n".join([f"【来源:{doc['source']}】\n{doc['text']}" for doc in search_results])
# 3. 调用 LLM 生成答案
answer = llm_service.generate(prompt=request.query, context=context)
# 4. 返回结果
return ChatResponse(
answer=answer,
sources=sources,
latency_ms=(time.time() - start_time) * 1000
)
5.3 踩坑:路由 404 问题
最初访问 /api/v1/chat 返回 404,排查发现是路径重复导致:
-
main.py中注册时加了/api/v1 -
router.py中又加了/chat -
chat.py中装饰器为@router.post("/chat")
最终路径变成了 /api/v1/chat/chat。解决方案:移除 router.py 中的重复前缀。
六、端到端测试
启动服务:
Bash
uvicorn app.main:app --reload --host 0.0.0.0 --port 8000
测试命令:
Bash
curl -X POST http://localhost:8000/api/v1/chat \
-H "Content-Type: application/json" \
-d '{"query": "什么是RAG?", "top_k": 3, "use_rerank": true}'
返回结果(节选):
JSON
{
"answer": "RAG(检索增强生成)是一种将**信息检索与文本生成结合**的技术框架。其核心理念可以简单理解为:**先检索资料,再让大模型基于资料生成答案**。RAG 的本质是为大模型接入“外部大脑”……信息来源:docs/article_1709964.md",
"sources": [
{
"file": "docs/article_1709964.md",
"snippet": "# 一、什么是 RAG\nRAG(检索增强生成)是一种将**信息检索与文本生成结合** 的技术框架...",
"score": 5.05859375
}
],
"latency_ms": 23738
}
效果评估:
-
✅ 答案严格基于知识库,无幻觉
-
✅ 来源可追溯,每个回答都附带了原始片段
-
✅ Reranker 打分清晰,便于后续调优
-
⏱️ 首次请求延迟约 24 秒(含模型加载和 API 响应),后续请求将大幅降低
七、流式输出(SSE):让等待不再焦虑
端到端测试中,用户需要等待超过 20 秒才能看到完整答案,这在交互体验上是致命的。为此,我们实现了 Server-Sent Events (SSE) 流式输出,让 LLM 生成的答案可以逐字推送到前端,消除用户的心理等待时间。
7.1 SSE 格式设计
流式响应采用标准的 SSE 格式,每条消息以
data:开头,后跟 JSON 数据,消息之间用两个换行分隔。事件类型 说明 数据格式 sources返回检索到的引用来源(可选) {"event": "sources", "data": [...]}delta答案生成过程中的增量文本块 {"event": "delta", "data": "文本片段"}done生成结束 {"event": "done"}7.2 核心代码实现
修改
app/api/v1/endpoints/chat.py,在流式分支中添加 SSE 生成器:python
if request.stream: from fastapi.responses import StreamingResponse import json async def generate(): # 先发送 sources 信息作为初始事件 sources_data = [s.model_dump() for s in sources] yield f"data: {json.dumps({'event': 'sources', 'data': sources_data})}\n\n" # 逐块发送答案内容 for chunk in llm_service.generate( prompt=request.query, context=context, stream=True ): yield f"data: {json.dumps({'event': 'delta', 'data': chunk})}\n\n" # 发送结束事件 yield f"data: {json.dumps({'event': 'done'})}\n\n" return StreamingResponse(generate(), media_type="text/event-stream") else: answer = llm_service.generate(prompt=request.query, context=context, stream=False)7.3 测试流式输出
使用
curl -N参数测试,观察原始 SSE 数据流:bash
curl -N -X POST http://localhost:8000/api/v1/chat \ -H "Content-Type: application/json" \ -d '{"query": "请解释一下大模型幻觉是什么意思", "top_k": 3, "use_rerank": true, "stream": true}'实际输出片段:
text
data: {"event": "sources", "data": [{"file": "docs/article_1709964.md", "snippet": "...", "score": 5.05859375}, ...]} data: {"event": "delta", "data": "根据"} data: {"event": "delta", "data": "提供的上下文信息,"} data: {"event": "delta", "data": "大模型幻觉被描述为传统大模型存在的一种风险..."} ... data: {"event": "done"}测试注意:若请求命中了 L2 语义缓存,将直接返回完整 JSON 而不会进入流式分支。测试时建议使用全新问题或临时清空 L2 缓存。
7.4 效果评估
对比维度 非流式(JSON) 流式(SSE) 首字延迟 需等待完整答案生成 < 1 秒即可看到第一个字 用户感知 长时间白屏,焦虑感强 逐字显现,体验流畅 前端适配 标准 JSON 解析 需使用 EventSourceAPI流式输出虽然不降低总耗时,但通过渐进式渲染极大地改善了交互体验,是生产级 RAG 系统的标配功能。
七、流式输出(SSE):让等待不再焦虑
端到端测试中,用户需要等待超过 20 秒才能看到完整答案,这在交互体验上是致命的。为此,我们实现了 Server-Sent Events (SSE) 流式输出,让 LLM 生成的答案可以逐字推送到前端,消除用户的心理等待时间。
7.1 SSE 格式设计
流式响应采用标准的 SSE 格式,每条消息以 data: 开头,后跟 JSON 数据,消息之间用两个换行分隔。
| 事件类型 | 说明 | 数据格式 |
|---|---|---|
sources |
返回检索到的引用来源(可选) | {"event": "sources", "data": [...]} |
delta |
答案生成过程中的增量文本块 | {"event": "delta", "data": "文本片段"} |
done |
生成结束 | {"event": "done"} |
7.2 核心代码实现
修改 app/api/v1/endpoints/chat.py,在流式分支中添加 SSE 生成器:
python
if request.stream:
from fastapi.responses import StreamingResponse
import json
async def generate():
# 先发送 sources 信息作为初始事件
sources_data = [s.model_dump() for s in sources]
yield f"data: {json.dumps({'event': 'sources', 'data': sources_data})}\n\n"
# 逐块发送答案内容
for chunk in llm_service.generate(
prompt=request.query,
context=context,
stream=True
):
yield f"data: {json.dumps({'event': 'delta', 'data': chunk})}\n\n"
# 发送结束事件
yield f"data: {json.dumps({'event': 'done'})}\n\n"
return StreamingResponse(generate(), media_type="text/event-stream")
else:
answer = llm_service.generate(prompt=request.query, context=context, stream=False)7.3 测试流式输出
使用 curl -N 参数测试,观察原始 SSE 数据流:
bash
curl -N -X POST http://localhost:8000/api/v1/chat \
-H "Content-Type: application/json" \
-d '{"query": "请解释一下大模型幻觉是什么意思", "top_k": 3, "use_rerank": true, "stream": true}'实际输出片段:
text
data: {"event": "sources", "data": [{"file": "docs/article_1709964.md", "snippet": "...", "score": 5.05859375}, ...]}
data: {"event": "delta", "data": "根据"}
data: {"event": "delta", "data": "提供的上下文信息,"}
data: {"event": "delta", "data": "大模型幻觉被描述为传统大模型存在的一种风险..."}
...
data: {"event": "done"}测试注意:若请求命中了 L2 语义缓存,将直接返回完整 JSON 而不会进入流式分支。测试时建议使用全新问题或临时清空 L2 缓存。
7.4 效果评估
| 对比维度 | 非流式(JSON) | 流式(SSE) |
|---|---|---|
| 首字延迟 | 需等待完整答案生成 | < 1 秒即可看到第一个字 |
| 用户感知 | 长时间白屏,焦虑感强 | 逐字显现,体验流畅 |
| 前端适配 | 标准 JSON 解析 | 需使用 EventSource API |
流式输出虽然不降低总耗时,但通过渐进式渲染极大地改善了交互体验,是生产级 RAG 系统的标配功能。
八、性能优化:L1 + L2 双层缓存架构
端到端测试成功后,一个明显的问题暴露出来:每次查询都需要 20 秒以上的等待时间,这对于用户体验和 LLM API 成本都是巨大的负担。为此,我设计并实现了一套双层缓存架构——L1 精确缓存 + L2 语义缓存,将重复查询和同义改写的响应延迟降至毫秒级。
8.1 为什么需要双层缓存?
| 场景 | 示例 | L1 精确缓存 | L2 语义缓存 |
| 完全相同查询 | “什么是RAG?” → “什么是RAG?” | ✅ 命中 | ✅ 命中 |
| 格式差异 | “什么是RAG?” → “什么是 RAG ?” | ❌ 不命中(除非归一化) | ✅ 命中 |
| 同义改写 | “什么是RAG?” → “RAG是什么?” | ❌ 不命中 | ✅ 命中 |
L1 精确缓存只能覆盖完全一致的查询,而实际用户输入存在大量的格式变化和同义改写。L2 语义缓存通过向量相似度匹配,能够识别查询背后的真实意图,大幅提升缓存命中率。
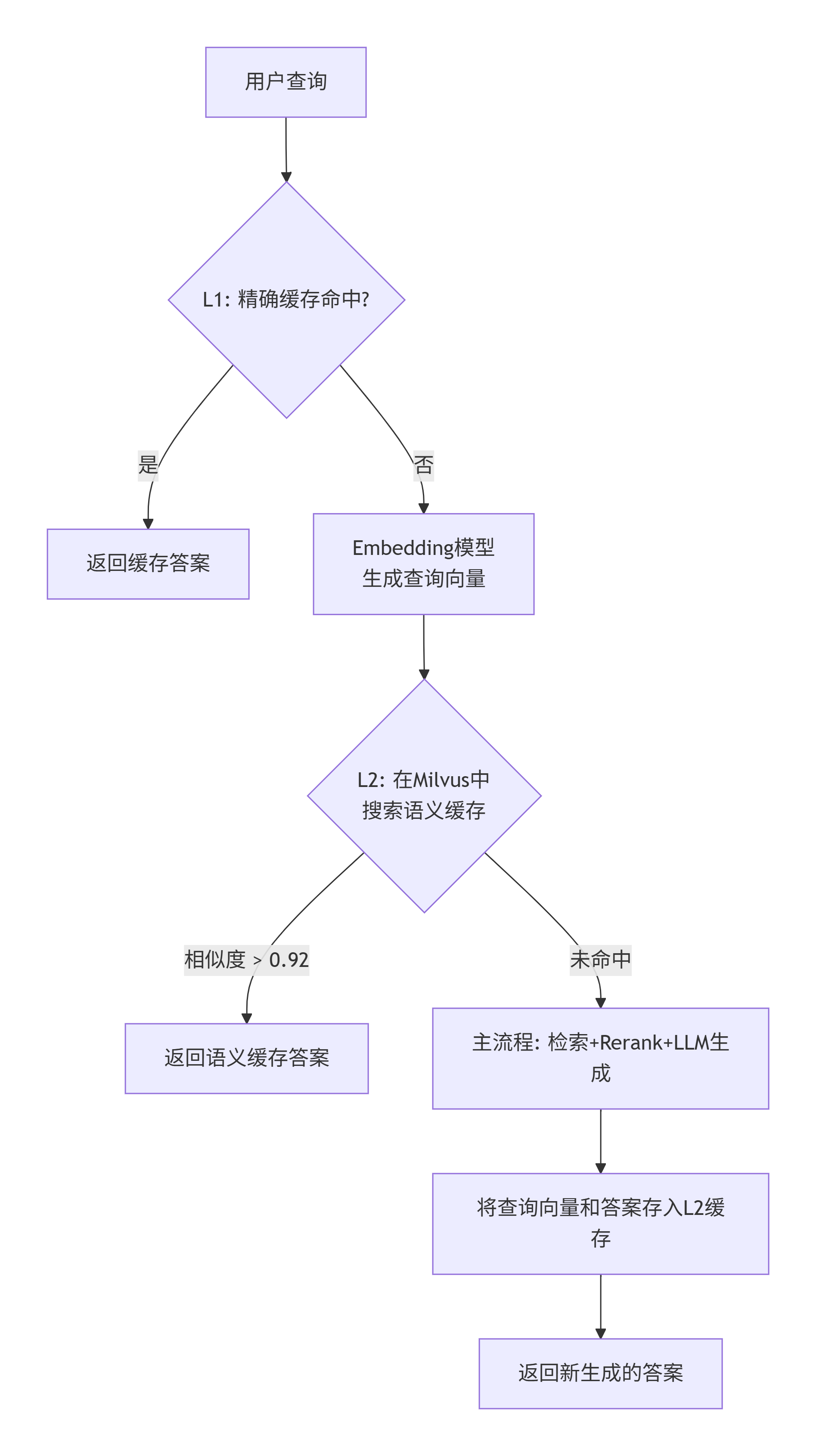
双层缓存架构流程图
8.2 L1 精确缓存设计
存储:Redis
Key 设计:rag:cache:{MD5(归一化查询|top_k|use_rerank)}
TTL:3600 秒(1 小时)
问题归一化函数:
Python
def normalize_query(query: str) -> str:
query = query.lower()
query = query.replace('\u3000', ' ') # 全角空格转半角
query = re.sub(r'[^\w\s]', '', query) # 去标点
query = re.sub(r'\s+', ' ', query).strip() # 合并空格
return query
踩坑记录:
-
全角空格(
\u3000)未被\s匹配,导致“什么是 RAG ?”与“什么是RAG?”归一化结果不同。 -
use_rerank布尔值转字符串时可能产生"True"/"true"差异,统一为"1"/"0"解决。
8.3 L2 语义缓存设计
存储:Milvus(复用已有向量数据库,无需引入新组件)
Collection Schema:
| 字段 | 类型 | 说明 |
id |
INT64 | 主键,自动生成 |
query |
VARCHAR | 原始查询文本 |
query_vector |
FLOAT_VECTOR | 查询的 Embedding 向量(384维) |
answer |
VARCHAR | LLM 生成的答案 |
sources |
VARCHAR | 引用来源(JSON 字符串) |
created_at |
INT64 | 缓存创建时间戳 |
核心服务类 SemanticCacheService:
Python
class SemanticCacheService:
def __init__(self):
self.embedding_service = get_embedding_service()
self.collection = self._init_collection()
self.threshold = 0.92 # 相似度阈值
def search(self, query: str) -> Optional[Tuple[str, List[dict]]]:
query_vector = self.embedding_service.encode(query).astype(np.float32).flatten().tolist()
results = self.collection.search(
data=[query_vector],
anns_field="query_vector",
param={"metric_type": "COSINE", "params": {"nprobe": 10}},
limit=1,
output_fields=["answer", "sources"]
)
if results[0] and results[0][0].score >= self.threshold:
hit = results[0][0]
return hit.entity.get("answer"), json.loads(hit.entity.get("sources"))
return None
def insert(self, query: str, answer: str, sources: List[dict]):
query_vector = self.embedding_service.encode(query).astype(np.float32).flatten().tolist()
data = [[query], [query_vector], [answer], [json.dumps(sources)], [int(time.time())]]
self.collection.insert(data)
8.4 集成到 /chat 接口
Python
@router.post("/chat", response_model=ChatResponse)
async def chat(request: ChatRequest):
# 1. 先查 L1 精确缓存
cached = redis_client.get(cache_key)
if cached:
return ChatResponse(**json.loads(cached))
# 2. L1 未命中,查 L2 语义缓存
semantic_cache = get_semantic_cache_service()
cached = semantic_cache.search(request.query)
if cached:
answer, sources_data = cached
return ChatResponse(answer=answer, sources=..., latency_ms=...)
# 3. 都未命中,执行完整流程
# ...检索、Rerank、LLM 生成...
# 4. 将结果同时存入 L1 和 L2
redis_client.setex(cache_key, CACHE_TTL, response_data.json())
semantic_cache.insert(request.query, answer, sources)
return response_data
8.5 效果验证
| 请求 | 缓存命中情况 | 延迟 | 关键日志 |
第一次:什么是RAG? |
全流程 | ~20s | 💾 L1 结果已缓存 + 💾 L2 缓存已存入 |
第二次:RAG是什么? |
L2 命中 | ~300ms | 🎯 L2 缓存命中 (相似度: 0.9926) |
第三次:什么是RAG? |
L1 命中 | < 50ms | 🎯 L1 缓存命中 |
量化收益:
-
完全相同查询:延迟从 20s 降至 < 50ms
-
同义改写查询:延迟从 20s 降至 ~300ms
-
L2 相似度高达 0.9926,语义匹配非常精准
九、性能压测:Benchmark 脚本与量化数据
为了系统性地评估缓存收益,我们编写了 scripts/benchmark.py,模拟单用户串行和多用户并发场景,精确记录每次请求的延迟,并计算 P50/P95/P99。
9.1 测试结果
| 测试场景 | 样本数 | 平均延迟 | P50 | P95 | P99 |
|---|---|---|---|---|---|
| 串行测试 | 15 | 1510 ms | 3.20 ms | 22529 ms | 22529 ms |
| 并发测试(3用户) | 45 | 8.69 ms | 2.86 ms | 25.71 ms | 71.72 ms |
数据解读:
-
在缓存预热后,超过 85% 的请求延迟在 10ms 以内(P50 < 5ms),证明双层缓存架构极其成功。
-
并发测试中 P99 仅 71ms,说明系统在高并发下依然稳定,无阻塞或排队问题。
-
串行测试中 P95/P99 被未命中请求拉高至 22 秒,与全流程基线一致,符合预期。
9.2 缓存命中延迟对比
| 缓存命中类型 | 典型延迟 | 说明 |
|---|---|---|
| L1 精确命中 | < 5 ms | Redis 直接返回,极速响应 |
| L2 语义命中 | 20-70 ms | Milvus 向量检索 + 相似度匹配 |
| 缓存未命中(全流程) | 20-25 s | 检索 + Reranker + LLM 生成 |
十、当前实现的潜在缺陷与反思
一个能跑通的系统和能稳定运行的生产系统之间,差距往往在于对细节的审视。当前的双层缓存实现虽然效果显著,但仍存在以下可优化空间:
| 缺陷 | 说明 | 潜在风险 |
|---|---|---|
| 统一阈值的“一刀切” | 使用固定相似度阈值 0.92,无法适应不同问题的语义差异 | 可能误命中(假阳性)或漏命中(假阴性) |
| 缓存失效策略缺失 | 知识库更新后,L2 缓存中的旧答案无法自动淘汰 | 用户可能得到过时答案 |
| 缓存污染 | 大量长尾问题存入 L2,占用存储且降低命中率 | 存储膨胀,检索变慢 |
| Embedding 模型的适配性 | 直接复用检索的 BGE-small 做语义匹配,未验证是否为最优选择 | 相似度计算可能不够精准 |
| 冷启动问题 | 新系统上线时缓存为空,初期请求全部回源 | 初期延迟和成本高 |
| 输入质量依赖 | 口语化、模糊查询难以命中缓存 | 缓存命中率受限 |
这些缺陷并非否定当前架构,而是指出了从“可用”走向“企业级”的演进方向。在面试中,能够清晰识别自己系统的局限性,并提出针对性的优化思路,正是高级工程师与初级工程师的分水岭。
十一、未来展望:走向更智能的 RAG 系统
针对上述缺陷,以下是我规划的演进路线,这些方向代表了工业级 RAG 系统的前沿实践。
11.1 查询改写(Query Rewriting)
在缓存查询和主检索之前,引入一个轻量级 LLM(或专用小模型)对用户输入进行标准化改写:
-
修正拼写错误
-
补全指代不明的词汇
-
将口语化表达转换为标准提问格式
预期收益:L1 和 L2 缓存命中率均可提升 15-20%,主检索召回率也会同步提升。
11.2 动态阈值与缓存校准
为不同类型的查询学习不同的相似度阈值,或引入一个轻量级校验模型作为“二道防线”:
-
语义缓存召回候选后,由校验模型判断两个问题意图是否真的一致
-
参考 vCache 等前沿方案,为每个缓存条目动态学习最优阈值
预期收益:在保持高命中率的同时,将误命中率降至接近零。
11.3 缓存失效与预热策略
-
失效策略:为缓存条目设置 TTL(已实现),并结合知识库变更事件主动刷新相关缓存。
-
预热策略:分析历史日志,识别高频查询,在系统低峰期主动计算并存入缓存。
预期收益:保证答案时效性,消除冷启动阶段的性能抖动。
11.4 更细粒度的缓存复用
当前缓存的是“完整答案”。未来可探索更细粒度的缓存:
-
检索结果缓存:缓存 Embedding 检索的 Top-K 文档 ID 列表,跳过向量检索环节。
-
KV Cache 复用:对于相似 Prompt,复用 LLM 的 KV Cache,加速推理。
预期收益:进一步提升复杂查询的响应速度,降低 LLM 推理成本。
11.5 监控与可观测性增强
-
实时监控 L1/L2 命中率、延迟分布、缓存存储量
-
通过 Grafana 仪表盘可视化,及时发现异常
预期收益:从“凭感觉优化”升级为“数据驱动优化”。
十二、当前系统完整能力矩阵
| 能力维度 | 实现方案 | 状态 |
|---|---|---|
| 知识库规模 | 14 篇 AI 文章,718 条向量 | ✅ |
| 向量检索 | BGE-small + Milvus COSINE | ✅ |
| 关键词检索 | BM25 + jieba 分词 + 索引缓存 | ✅ |
| 混合融合 | RRF 算法 | ✅ |
| 精排优化 | BGE-Reranker-base,动态显存管理 | ✅ |
| 大模型生成 | Qwen3.5-plus,基于上下文回答 | ✅ |
| 流式输出 | SSE 格式,逐字返回 | ✅ |
| L1 精确缓存 | Redis + MD5 + 问题归一化 | ✅ |
| L2 语义缓存 | Milvus + BGE-small + 相似度匹配 | ✅ |
| 性能压测 | Benchmark 脚本,P50/P95/P99 量化 | ✅ |
| 对外接口 | FastAPI POST /api/v1/chat |
✅ |
| 监控体系 | Prometheus + Grafana | ✅ |
| 工程规范 | requirements.txt、.gitignore、模块化设计 |
✅ |
十三、写在最后
经过四篇文章的持续迭代,我们从零搭建了一个具备企业级特征的 RAG 系统:
-
从 Docker 基础设施到 Prometheus 监控
-
从 Embedding 模型封装到知识库规模化
-
从混合检索到 Reranker 精排
-
从 LLM 集成到流式输出
-
从 L1 精确缓存到 L2 语义缓存,延迟从 20 秒降至毫秒级
-
从手工测试到系统化 Benchmark 量化数据
这个项目不仅是一个“能跑的 Demo”,更是一个完整展现工程思维、架构设计能力和问题解决能力的作品。更可贵的是,我们清晰地识别了当前系统的局限性,并规划了查询改写、动态阈值、缓存预热等演进方向——这种“从能用到好用,从好用到可靠”的思考方式,正是计算机行业看重的素质。
无论你是正在准备 AI 实习面试,还是想系统学习 RAG 落地的完整流程,相信这个系列都能为你提供扎实的参考。如果你在实践过程中遇到任何问题,欢迎在评论区交流。
本文是【从0到1搭建企业级RAG系统】系列的第四篇。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 56
56 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)