LangGraph-AI应用开发框架(四)
·
目录
【案例三】基于LangGraph实现的代理式RAG(检索增强生成)系统
a.节点1:决策节点generate_query_or_respond
【案例三】基于LangGraph实现的代理式RAG(检索增强生成)系统
一.案例介绍

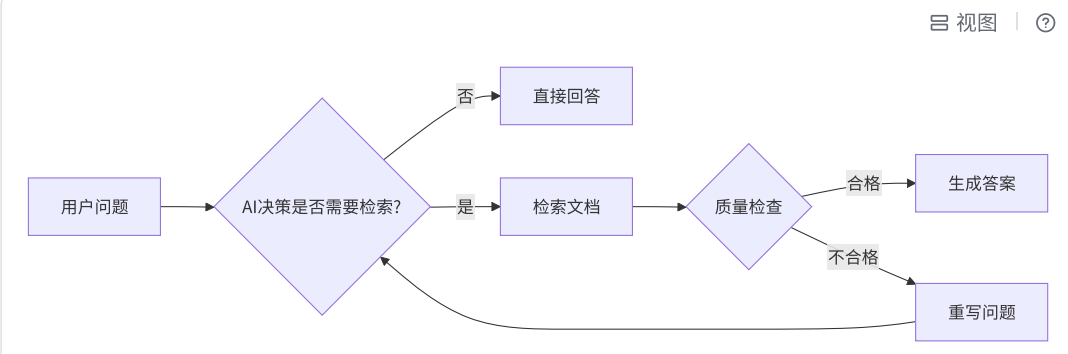
![]()
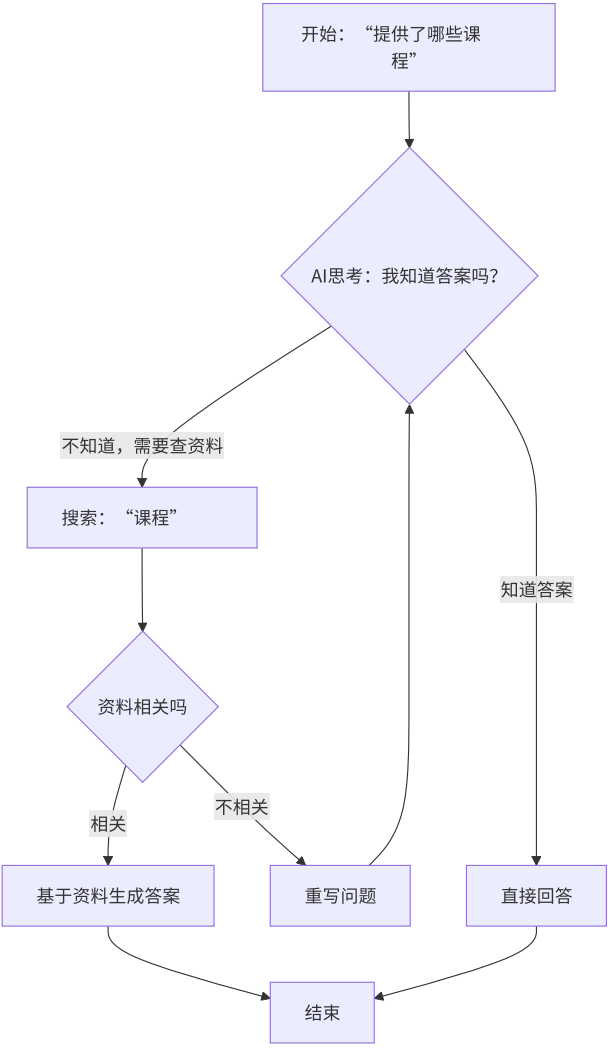

二.编码思路

三.代码实现
1.步骤一:准备"知识库"并创建"检索工具"
import langchain
langchain.verbose = False
langchain.debug = False
langchain.llm_cache = None
from langchain.chat_models import init_chat_model
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_core.messages import HumanMessage
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_classic.tools.retriever import create_retriever_tool
from langchain_community.embeddings import ZhipuAIEmbeddings
import os
# 聊天模型与嵌入模型
api_key = os.getenv("ZHIPUAI_API_KEY") # 从环境变量读取
# 智谱模型(OpenAI 兼容模式,零报错)
model = ChatOpenAI(
model="glm-4",
api_key=api_key,
base_url="https://open.bigmodel.cn/api/paas/v4/",
temperature=0
)
import os
import requests
from langchain_core.embeddings import Embeddings
# ===================== 【真正能用】智谱 Embedding =====================
class ZhipuEmbedding(Embeddings):
def __init__(self, api_key=None):
self.api_key = api_key or os.getenv("ZHIPUAI_API_KEY")
self.url = "https://open.bigmodel.cn/api/paas/v4/embeddings"
self.model = "embedding-3"
def embed_query(self, text: str):
return self._get_embedding(text)
def embed_documents(self, texts: list[str]):
return [self._get_embedding(t) for t in texts]
def _get_embedding(self, text: str):
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
data = {
"model": self.model,
"input": text
}
response = requests.post(self.url, json=data, headers=headers)
return response.json()["data"][0]["embedding"]
# 初始化(直接用)
embeddings = ZhipuEmbedding()
# 加载文档列表
paths = [
"../Docs/markdown/企业介绍.md",
"../Docs/markdown/C++开发方向.md",
"../Docs/markdown/Java开发方向.md",
"../Docs/markdown/测试开发方向.md"
]
docs = [UnstructuredMarkdownLoader(path).load() for path in paths]
docs_list = [item for sublist in docs for item in sublist]
# from_tiktoken_encoder: 使用 tiktoken 编码器来计算长度的文本分割器
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base",
chunk_size=1000,
chunk_overlap=50
)
doc_splits = text_splitter.split_documents(docs_list)
# 使用内存中向量存储和 OpenAI 嵌入
vectorstore = InMemoryVectorStore.from_documents(
documents=doc_splits,
embedding=embeddings
)
# 使用 LangChain 的预构建 create_retriever_tool 创建检索器工具:
retriever = vectorstore.as_retriever(search_kwargs={"k": 2})
# 创建检索器工具
retriever_tool = create_retriever_tool(
retriever,
"retrieve_tool",
"搜索并返回有关XX就业的信息。"
)
retriever_tool.invoke({"query":"比特C++方向有哪些课程"})

return Tool(
name=name,
description=description,
func=func,
coroutine=afunc,
args_schema=RetrieverInput,
response_format=response_format,
)测试:
# 测试
test_queries = [
"XX提供了哪些课程",
"Java开发方向的课程安排",
"测试开发方向的主线课程有哪些",
"C++开发方向的项目列表",
"Redis课程内容是什么"
]
for query in test_queries:
print("-" * 50)
print(f"查询: {query}\n")
result = retriever_tool.invoke({"query": query})
# 只显示前100个字符,避免输出过长
content_preview = result[:100] + "..." if len(result) > 100 else result
print(f"结果预览: {content_preview}")
print(f"结果长度: {len(result)} 字符")2.步骤二:设计"工作流程节点"

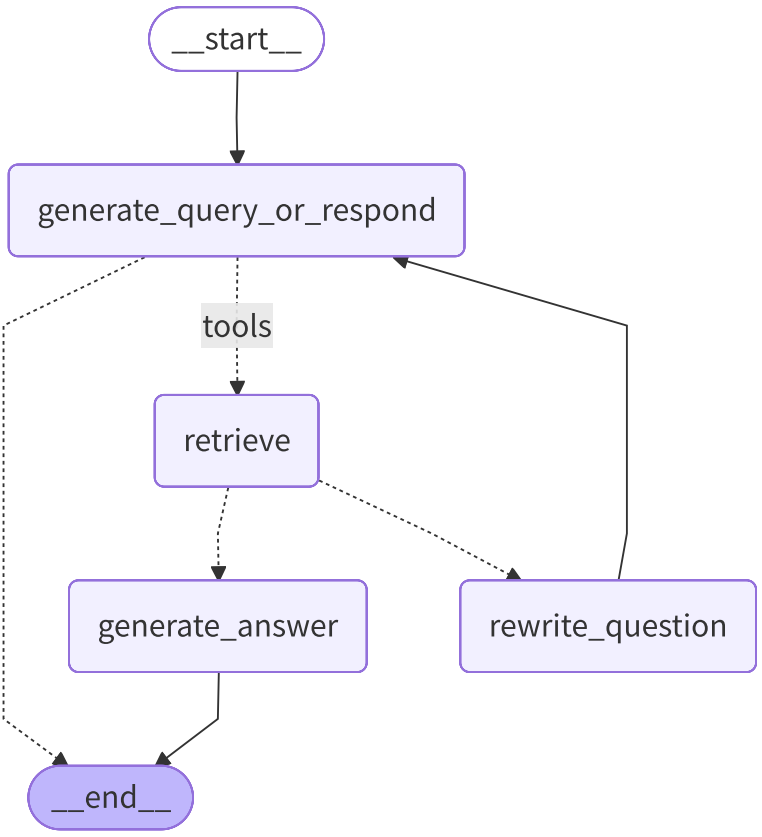
a.节点1:决策节点generate_query_or_respond

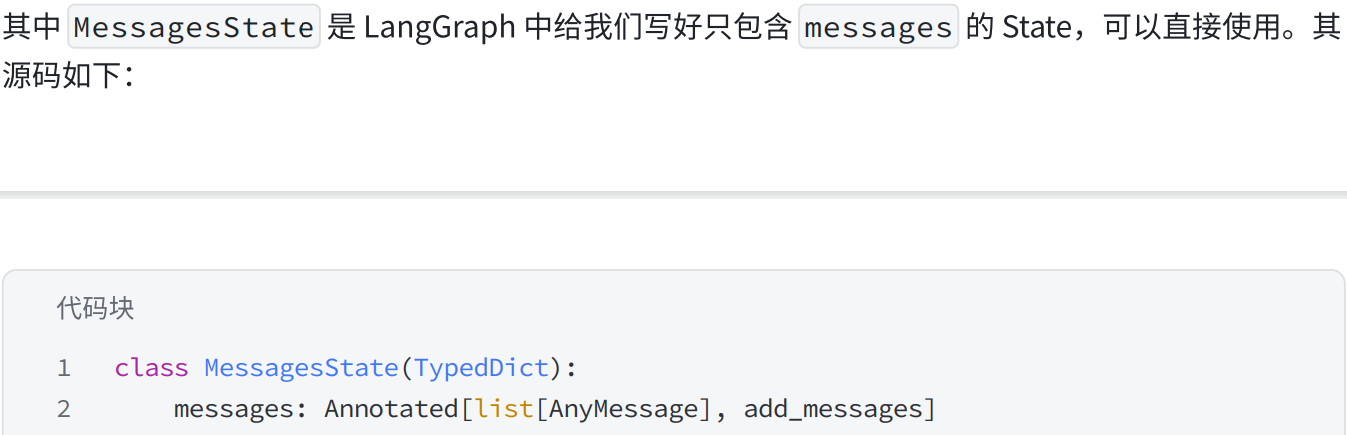
from langgraph.graph import MessagesState
def generate_query_or_respond(state: MessagesState):
"""调⽤模型以基于当前状态⽣成响应。
给定问题,它将决定使⽤检索⼯具检索,或者简单地响应⽤⼾。"""
response = (
model.bind_tools([retriever_tool]).invoke(state["messages"])
)
return {"messages": [response]}

b.节点2:检索器工具节点retrieve
![]()
from langgraph.prebuilt import ToolNode
retrieve_node = ToolNode([retriever_tool])
![]()
c.节点3:问题优化节点rewrite_question
![]()
#节点3
REWRITE_PROMPT = (
"查看输⼊并尝试推断潜在的语义意图/含义。\n"
"这是最初的问题:"
"\n ------- \n"
"{question}"
"\n ------- \n"
"提出⼀个改进后的问题:"
)
def rewrite_question(state: MessagesState):
"""重写原始用户问题"""
#state messages 包含 [H,A,T]
question = state["messages"][0]
prompt = REWRITE_PROMPT.format(question=question)
result = model.invoke([HumanMessage(content=prompt)])
#将修改后的问题,设置成为用户消息
return {
"messages": [HumanMessage(content=result.content)]
}就是生成提示词,将问题重写,并改成用户消息

from langchain_core.messages import convert_to_messages
input_messages = {
"messages": convert_to_messages(
[
{
"role": "user",
"content": "提供了哪些课程?",
},
{
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "1",
"name": "retrieve_bit",
"args": {"query": "课程"},
}
],
},
{"role": "tool", "content": "你好", "tool_call_id": "1"},
]
)
}
response = rewrite_question(input_messages)
print(response["messages"][-1]["content"])d.节点4:答案生成节点generate_answer
![]()
# ⽣成答案
GENERATE_PROMPT = (
"你是负责回答问题的助⼿。 "
"使⽤以下检索到的上下⽂⽚段来回答问题。 "
"如果你不知道答案,就说你不知道。 "
"最多只⽤三句话,回答要简明扼要。\n"
"Question: {question} \n"
"Context: {context}"
)
def generate_answer(state: MessagesState):
"""生成答案"""
#state message 包含[H A T]
#用问题 + 检索结果
question = state["messages"][0].content
context = state["messages"][-1].content
prompt = GENERATE_PROMPT.format(question=question, context=context)
return {
"messages": [model.invoke([HumanMessage(content=prompt)])]
}
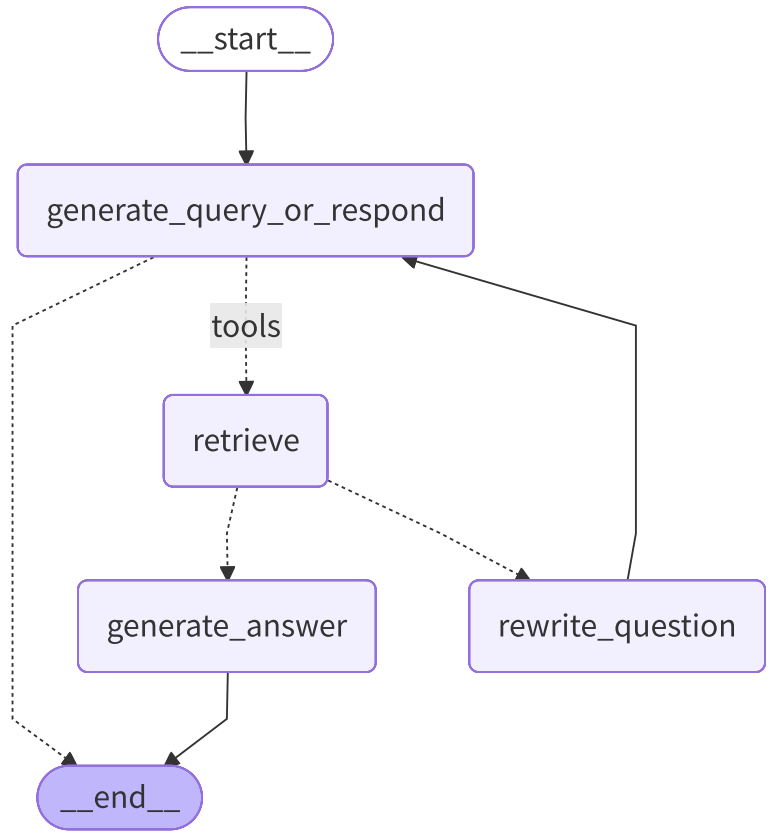
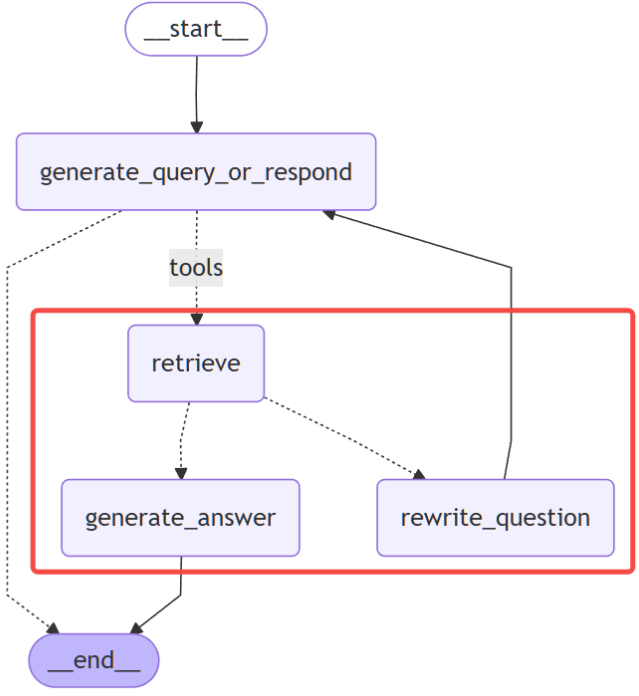
3.步骤三:组装"工作流水线"
![]()
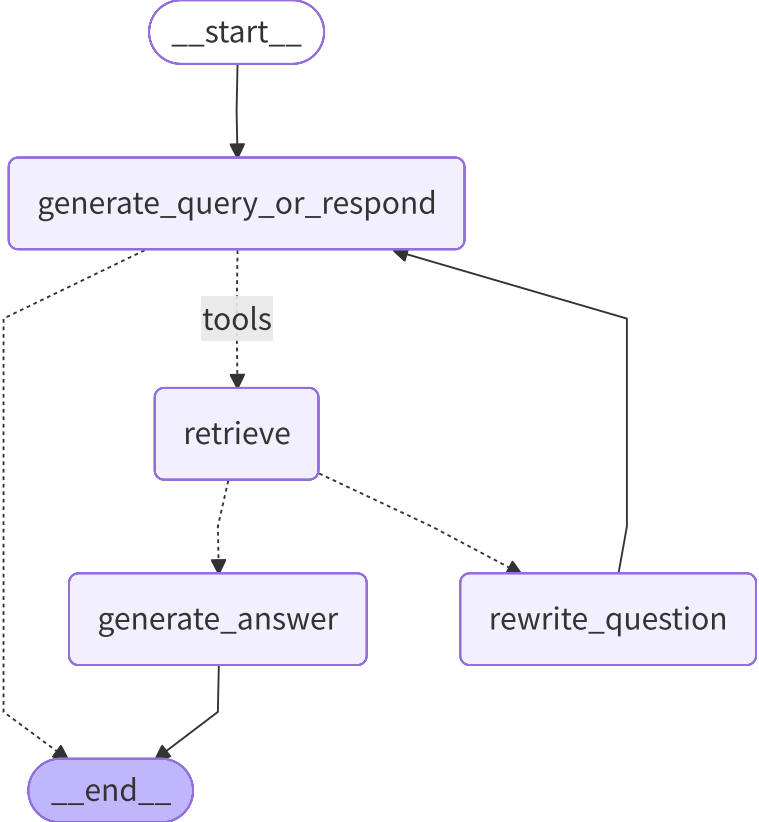
a.添加节点与入口点
# 组装Graph
from langgraph.graph import StateGraph, START, END
from langgraph.prebuilt import ToolNode, tools_condition
workflow = StateGraph(MessagesState)
workflow.add_node(generate_query_or_respond)
workflow.add_node("retrieve", ToolNode([retriever_tool]))
workflow.add_node(rewrite_question)
workflow.add_node(generate_answer)
workflow.add_edge(START, "generate_query_or_respond")
b.条件边1:LLM决策是否需要进行知识库检索
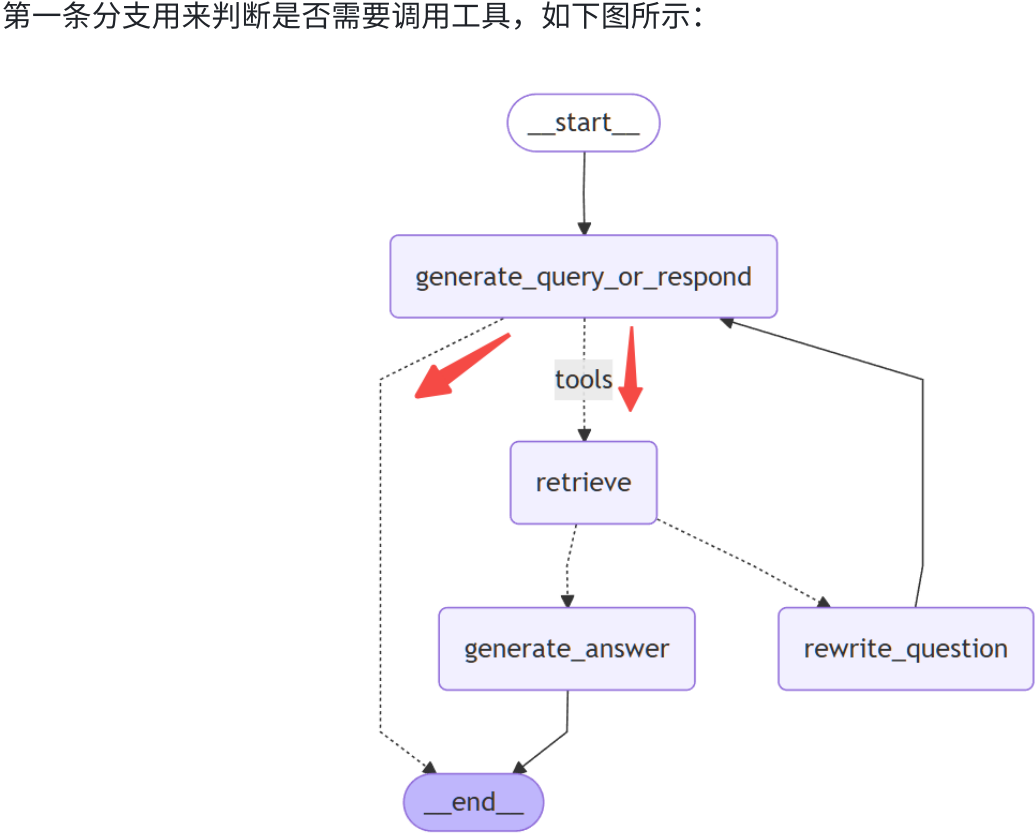

workflow.add_conditional_edges(
"generate_query_or_respond",
# 评估 LLM 决策
tools_condition,
{
"tools": "retrieve", # 将条件输出转换为图中的节点
"__end__": END,
},
)
c.条件边2:检测【检索到的文档】是否与【问题】相关

GRADE_PROMPT = (
"你是⼀个评分员,评估检索到的⽂档与⽤⼾问题的相关性。 \n "
"以下是检索到的⽂档: \n\n {context} \n\n"
"以下是⽤⼾的问题: {question} \n"
"如果⽂档包含与⽤⼾问题相关的关键字或语义,则将其评为相关。 \n"
"给出⼀个⼆元分数“yes”或“no”,以表明该⽂档是否与问题相关。"
)
def grade_documents(state: MessagesState) -> Literal["rewrite_question", "generate_answer"]:
"""确定检索到的文档与问题是否相关"""
# 问题 + 检索到的文档 与 问题是否相关
user_messages = filter_messages(state["messages"], include_types="human")
question = user_messages[-1].content
tool_message = state["messages"][-1]
context = tool_message.content
# ✅ 修复1:用正确的提示词(不是生成答案的!)
prompt = GRADE_PROMPT.format(question=question, context=context)
# ✅ 修复2:不用结构化输出,智谱不支持!只取 yes/no
result = model.invoke([HumanMessage(content=prompt)])
score = result.content.strip().lower()
# ✅ 修复3:简单判断字符串
if "yes" in score:
return "generate_answer"
else:
return "rewrite_question"d.添加结束点并编译
workflow.add_edge("generate_answer", END)
workflow.add_edge("rewrite_question", "generate_query_or_respond")
graph = workflow.compile()
e.运行RAG
for chunk in graph.stream(
{
"messages": [HumanMessage(content="C++开发⽅向的项⽬列表")]
}
):
for node, update in chunk.items():
print(f"由节点 {node} 更新消息:")
if node != "rewrite_question":
update["messages"][-1].pretty_print()
print("\n\n")

四.总代码
from pydantic import BaseModel, Field
import langchain
from langgraph.constants import START,END
import os
os.environ["LANGCHAIN_TRACING_V2"] = "false" # 关闭追踪,直接消除警告
from langgraph.graph import MessagesState, StateGraph
from langgraph.prebuilt import ToolNode, tools_condition
langchain.verbose = False
langchain.debug = False
langchain.llm_cache = None
from typing import Literal
from langchain.chat_models import init_chat_model
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_core.messages import HumanMessage, filter_messages
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_classic.tools.retriever import create_retriever_tool
from langchain_community.embeddings import ZhipuAIEmbeddings
import os
# 聊天模型与嵌入模型
api_key = os.getenv("ZHIPUAI_API_KEY") # 从环境变量读取
# 智谱模型(OpenAI 兼容模式,零报错)
model = ChatOpenAI(
model="glm-4",
api_key=api_key,
base_url="https://open.bigmodel.cn/api/paas/v4/",
temperature=0
)
import os
import requests
from langchain_core.embeddings import Embeddings
# ===================== 【真正能用】智谱 Embedding =====================
class ZhipuEmbedding(Embeddings):
def __init__(self, api_key=None):
self.api_key = api_key or os.getenv("ZHIPUAI_API_KEY")
self.url = "https://open.bigmodel.cn/api/paas/v4/embeddings"
self.model = "embedding-3"
def embed_query(self, text: str):
return self._get_embedding(text)
def embed_documents(self, texts: list[str]):
return [self._get_embedding(t) for t in texts]
def _get_embedding(self, text: str):
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
data = {
"model": self.model,
"input": text
}
response = requests.post(self.url, json=data, headers=headers)
return response.json()["data"][0]["embedding"]
# 初始化(直接用)
embeddings = ZhipuEmbedding()
# 加载文档列表
paths = [
"../Docs/markdown/企业介绍.md",
"../Docs/markdown/C++开发方向.md",
"../Docs/markdown/Java开发方向.md",
"../Docs/markdown/测试开发方向.md"
]
docs = [UnstructuredMarkdownLoader(path).load() for path in paths]
docs_list = [item for sublist in docs for item in sublist]
# from_tiktoken_encoder: 使用 tiktoken 编码器来计算长度的文本分割器
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base",
chunk_size=1000,
chunk_overlap=50
)
doc_splits = text_splitter.split_documents(docs_list)
# 使用内存中向量存储和 OpenAI 嵌入
vectorstore = InMemoryVectorStore.from_documents(
documents=doc_splits,
embedding=embeddings
)
# 使用 LangChain 的预构建 create_retriever_tool 创建检索器工具:
retriever = vectorstore.as_retriever(search_kwargs={"k": 2})
# 创建检索器工具
retriever_tool = create_retriever_tool(
retriever,
"retrieve_tool",
"搜索并返回有关XX就业的信息。"
)
# print(retriever_tool.invoke({"query": "XXC++方向有哪些课程"}))
#
# # 测试
# test_queries = [
# "XX提供了哪些课程",
# "Java开发方向的课程安排",
# "测试开发方向的主线课程有哪些",
# "C++开发方向的项目列表",
# "Redis课程内容是什么"
# ]
#
# for query in test_queries:
# print("-" * 50)
# print(f"查询: {query}\n")
# result = retriever_tool.invoke({"query": query})
# # 只显示前100个字符,避免输出过长
# content_preview = result[:100] + "..." if len(result) > 100 else result
# print(f"结果预览: {content_preview}")
# print(f"结果长度: {len(result)} 字符")
# ------------------- RAG 检索系统 -------------------
#1.状态
#对话,一般要维护一共messages
# class MessageState(TypedDict):
# messages: Annotated[list[AnyMessage], operator.add]
# llm_calls: int
#graph里面有信息类
#2.节点2
def generate_query_or_respond(state:MessagesState):
"""调用模型 基于当前状态生成响应 使用检索工具或者简单回答"""
result = model.bind_tools([retriever_tool]).invoke(state["messages"])
return {
"messages": [result]
}
# generate_query_or_respond({
# "messages": [
# HumanMessage(content="比特提供了哪些课程")
# ]
# })["messages"][-1].pretty_print()
#工具节点:帮我们执行工具
retriever_node = ToolNode([retriever_tool])
#节点3
REWRITE_PROMPT = (
"查看输⼊并尝试推断潜在的语义意图/含义。\n"
"这是最初的问题:"
"\n ------- \n"
"{question}"
"\n ------- \n"
"提出⼀个改进后的问题:"
)
def rewrite_question(state: MessagesState):
"""重写原始用户问题"""
#state messages 包含 [H,A,T]
question = state["messages"][0]
prompt = REWRITE_PROMPT.format(question=question)
result = model.invoke([HumanMessage(content=prompt)])
#将修改后的问题,设置成为用户消息
return {
"messages": [HumanMessage(content=result.content)]
}
#节点4
# ⽣成答案
GENERATE_PROMPT = (
"你是负责回答问题的助⼿。 "
"使⽤以下检索到的上下⽂⽚段来回答问题。 "
"如果你不知道答案,就说你不知道。 "
"最多只⽤三句话,回答要简明扼要。\n"
"Question: {question} \n"
"Context: {context}"
)
def generate_answer(state: MessagesState):
"""生成答案"""
#state message 包含[H A T]
#用问题 + 检索结果
question = state["messages"][0].content
context = state["messages"][-1].content
prompt = GENERATE_PROMPT.format(question=question, context=context)
return {
"messages": [model.invoke([HumanMessage(content=prompt)])]
}
#3.图,边,节点
workflow = StateGraph(MessagesState)
workflow.add_node("generate_query_or_respond",generate_query_or_respond)
workflow.add_node(generate_answer)
workflow.add_node(rewrite_question)
workflow.add_node("retrieve",retriever_node)
workflow.add_edge(START,"generate_query_or_respond")
workflow.add_conditional_edges(
"generate_query_or_respond",
tools_condition,#判断是否包含工具调用
{
"tools":"retrieve",
"__end__":END,
}
)
GRADE_PROMPT = (
"你是⼀个评分员,评估检索到的⽂档与⽤⼾问题的相关性。 \n "
"以下是检索到的⽂档: \n\n {context} \n\n"
"以下是⽤⼾的问题: {question} \n"
"如果⽂档包含与⽤⼾问题相关的关键字或语义,则将其评为相关。 \n"
"给出⼀个⼆元分数“yes”或“no”,以表明该⽂档是否与问题相关。"
)
def grade_documents(state: MessagesState) -> Literal["rewrite_question", "generate_answer"]:
"""确定检索到的文档与问题是否相关"""
# 问题 + 检索到的文档 与 问题是否相关
user_messages = filter_messages(state["messages"], include_types="human")
question = user_messages[-1].content
tool_message = state["messages"][-1]
context = tool_message.content
# ✅ 修复1:用正确的提示词(不是生成答案的!)
prompt = GRADE_PROMPT.format(question=question, context=context)
# ✅ 修复2:不用结构化输出,智谱不支持!只取 yes/no
result = model.invoke([HumanMessage(content=prompt)])
score = result.content.strip().lower()
# ✅ 修复3:简单判断字符串
if "yes" in score:
return "generate_answer"
else:
return "rewrite_question"
workflow.add_conditional_edges(
"retrieve",
grade_documents,#判断是否包含工具调用
["generate_answer","rewrite_question"]
)
workflow.add_edge("generate_answer",END)
workflow.add_edge("rewrite_question","generate_query_or_respond")
#4.编译图
graph = workflow.compile()
#5.执行图(支持流式输出)
# graph.invoke()
for chunk in graph.stream(
{
"messages":[HumanMessage(content="测试开发方向的主线课程有哪些?")],
}
):
# print(chunk)
for node,update in chunk.items():
print(f"由节点{node}更新消息")
update["message"][-1].pretty_print()
print("\n\n")
欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 11
11 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)