从 PDF 到引文图谱:基于规则抽取 + Semantic Scholar + Neo4j + LangGraph 的学术论文引文系统实战
从 PDF 到引文图谱:基于规则抽取 + Semantic Scholar + Neo4j + LangGraph 的学术论文引文系统实战
本周给学术论文阅读系统补上了"引文图谱"模块。本文记录从 0 到 1 的实现过程,覆盖:参考文献的规则抽取(正则 + 置信度分级)、Semantic Scholar API 的限流控制、Neo4j 的建图 Cypher(
CITES边上挂doc_id的关键设计)、LangGraph 中的citation_graph_node集成,以及一路踩过的 6 个坑。代码量约 350 行 Python,全部配套单元测试。关键词: Neo4j, LangGraph, Semantic Scholar, 知识图谱, 学术搜索, Python
一、这周要做的事
学术论文阅读场景里的"学术溯源",拆解后是两个需求:
- 这篇论文引用了谁?
- 谁在引用这篇论文?
第一条本来不复杂——学术论文末尾都有 References 段,按编号列着就行;第二条只能靠 Semantic Scholar 这类外部 API 的 /paper/{id}/citations 端点拿。
但实际做起来,两件事都比想象的麻烦,整条数据流是这样的: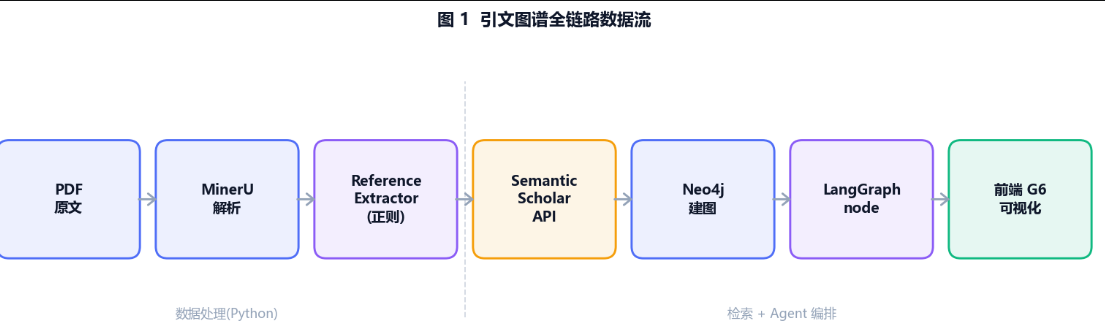
二、技术选型:规则还是让 LLM 识别?
PDF 经过 MinerU 解析出来的 Markdown 里:
References段头有时候被识别成一级标题# References,有时候被拼在正文最后一段末尾- 编号样式花样很多:
[1]、1.、(1)、甚至纯空行分隔 - 作者、标题、年份粘在一起,没有明显分隔符
摆在面前的是两条路:
| 方案 | 优势 | 劣势 |
|---|---|---|
| 让 LLM 抽 | 一行 prompt 就能跑,容错强 | 50 条参考 = 50 次 LLM 调用,慢且贵;LLM 偶尔丢条或幻觉伪造 |
| 规则抽取 | 快、确定性、可测试 | 需要枚举格式,处理不了所有奇葩 |
最终选了规则抽取做底层 + LLM 做上层语义分类。两个原则:
- 结构化抽取用规则:可复现、可测试、可
pytest - 语义判断用 LLM:灵活、覆盖边缘情况
下游的 citation_graph_node(LangGraph 节点)在做"用户问的是 incoming 还是 outgoing"这种意图分类时才让 LLM 介入。
三、规则抽取:ReferenceExtractor 的实现
3.1 定位 References 段的起止
不能直接全文扫描编号,因为正文里 as shown in [1] 这种也会命中。必须先找到 References 的段头,然后截止到 Appendix / Acknowledgments / 致谢 前。
_REF_SECTION_HEADERS = (
r"^\s*References\s*$",
r"^\s*REFERENCES\s*$",
r"^\s*参考文献\s*$",
r"^\s*Bibliography\s*$",
)
_END_MARKERS = (r"^\s*(Appendix|Acknowledgments?|致谢|附录)",)
def _locate_references_section(self, text: str) -> str:
lines = text.splitlines()
start = -1
for i, line in enumerate(lines):
if any(re.match(h, line) for h in _REF_SECTION_HEADERS):
start = i + 1
break
if start == -1:
return ""
end = len(lines)
for j in range(start, len(lines)):
if any(re.match(m, lines[j]) for m in _END_MARKERS):
end = j
break
return "\n".join(lines[start:end]).strip()
这里有个关键取舍:如果 References 是最后一段(没有 Appendix),end 就是文档末尾;如果后面跟了 Appendix/致谢,end 截断在那里。不截断的话,Appendix 里的公式、图表标题会被误认为参考文献——这是第一版的 bug。
3.2 三种编号格式的正则
扫了手头 20 篇 NeurIPS/ICML 的 PDF,参考文献格式基本收敛到三种:
格式 A:方括号编号
[1] Vaswani et al. Attention is all you need. NIPS 2017.
格式 B:数字点号
1. Smith, J. Study of X. Journal Y, 2020.
格式 C:无编号(纯空行分隔)
Vaswani et al. Attention is all you need. NIPS 2017.
A 是主流(NeurIPS/ICML/ACL),B 是 Nature 系和少数 ACM 会议,C 罕见但确实存在。我们只处理 A 和 B:
_NUMBERED_BRACKET = re.compile(r"^\s*\[(\d+)\]\s+(.+)$")
_NUMBERED_DOT = re.compile(r"^\s*(\d+)[.\uff0e]\s+(.+)$")
注意 \uff0e 是中文全角句号。有几篇中文会议的参考文献用了全角,不加这个字符类会漏一堆。
3.3 置信度分级:告诉下游"这条有多靠谱"
单纯把 raw string 抽出来不够,还要给下游(LangGraph 节点 / 前端)一个置信度标签,让它们决定是否深挖:
@dataclass
class Reference:
index: int # [1] 里的数字
raw: str # 原始字符串
title: str = ""
year: int | None = None
confidence: Literal["high", "medium", "low"] = "low"
三档定义:
- high: 有编号 + 有年份 + 能切出
5 ≤ len(title) ≤ 200的标题 - medium: 编号 + 年份或标题之一缺失
- low: 无编号(格式 C 或正则没匹到)
标题提取用的是 best-effort 规则——按 .\s+ 分割参考字符串,取第二段作为标题候选:
def _extract_title(self, raw: str) -> str:
# Vaswani et al. Attention is all you need. NIPS 2017.
# ↑第一段 ↑第二段(标题) ↑第三段(会议)
parts = re.split(r"\.\s+", raw, maxsplit=3)
if len(parts) < 2:
return ""
candidate = parts[1].strip().rstrip(".")
if 5 <= len(candidate) <= 200:
return candidate
return ""
对格式 A 正确率约 85%,对格式 B 低一些。但失败了也不影响下游——标题为空的条目直接在后续 Semantic Scholar 查询环节被跳过。
3.4 TDD 先行
这种规则逻辑特别适合 TDD。五个测试先写:
def test_extracts_numbered_brackets(): # 格式 A
def test_extracts_numbered_dot(): # 格式 B
def test_no_references_section(): # 无 References 段 → 返回 []
def test_year_extraction(): # 年份抽取正确
def test_title_extraction_best_effort(): # 标题抽取尽最大努力
pytest tests/test_reference_extractor.py -v → 5 个全红(ModuleNotFoundError)→ 写 services/reference_extractor.py → 全绿。
规则业务上 TDD 特别划算,因为规则之间会互相打架。比如 _split_entries 如果忘了处理多行参考(一条参考折到第二行),立刻红在测试里,而不是等到端到端 smoke 才发现。
四、Semantic Scholar API:限流是最大的敌人
4.1 用哪几个端点
Semantic Scholar Graph API 文档:https://api.semanticscholar.org/api-docs/graph
我们用了三个:
| 端点 | 用途 | 本周是否使用 |
|---|---|---|
GET /graph/v1/paper/search |
按标题模糊搜索,返回匹配的 paperId + 元数据 |
✅ 主力 |
POST /graph/v1/paper/batch |
批量(最多 500 id)拿元数据 | 下周做 |
GET /graph/v1/paper/{paper_id}/references |
拿一篇论文的 outgoing citations | ✅ 备用 |
请求的字段用 _DEFAULT_FIELDS:
_DEFAULT_FIELDS = "paperId,title,year,authors,abstract,externalIds,citationCount,referenceCount"
4.2 限流:公共 API 1 req/s,一卡就是 1 分钟
公共 API(无 key)限制是 1 request / second,超过立刻返回 429。一篇论文可能有 30–50 条参考,一条一条调 /paper/search 最顺利也要 30–50 秒。中间只要被限一次,就要 + 3 秒退避。
解决思路两步:
节流锁:保证两次请求间隔 ≥ 1.1 秒
class SemanticScholarClient:
def __init__(self, min_interval_sec: float = 1.1):
self._min_interval = min_interval_sec
self._last_call_ts = 0.0
self._lock = threading.Lock()
# ...
def _throttle(self) -> None:
with self._lock:
now = time.time()
elapsed = now - self._last_call_ts
if elapsed < self._min_interval:
time.sleep(self._min_interval - elapsed)
self._last_call_ts = time.time()
多线程安全(虽然目前单线程用,但留着口子)。每次 request 前先过闸门。
429 有限退避:避免无限递归
第一版实现是这样:
# 第一版:无限递归,遇到持续 429 会卡死
if resp.status_code == 429:
time.sleep(3)
return self.search_by_title(title, limit)
看起来没问题,但后来上线后发现:S2 公共 API 限流是固定窗口,一旦触发,接下来几秒几乎每个请求都是 429。这段代码会无限递归下去,最终 Python 栈溢出或前端 axios timeout。
修正成有限重试 + 放弃策略:
# 修正版:3 次后放弃,跳过这一条
_MAX_RETRIES = 3
def search_by_title(self, title: str, limit: int = 5, _attempt: int = 0) -> list[PaperMeta]:
self._throttle()
resp = self._client.get(
f"{self._api_url}/paper/search",
params={"query": title, "limit": limit, "fields": _DEFAULT_FIELDS},
headers=self._headers(),
)
if resp.status_code == 429:
if _attempt >= self._MAX_RETRIES:
logger.warning("S2 search giving up after %d retries: %r", _attempt, title[:50])
return [] # 跳过这一条,继续下一条
logger.warning("Rate limited; backing off 3s (attempt %d/%d)",
_attempt + 1, self._MAX_RETRIES)
time.sleep(3)
return self.search_by_title(title, limit, _attempt + 1)
resp.raise_for_status()
data = resp.json().get("data", [])
return [PaperMeta.from_api(d) for d in data]
4.3 申请 API key 以获得更高限流
公共 API 1 req/s 实在难用。Semantic Scholar 提供免费 API key 申请,通过后限流涨到 100 req/s。
拿到 key 后填入 .env:
SEMANTIC_SCHOLAR_API_KEY=你的key
代码读取时自动加 x-api-key header,无需改动任何逻辑:
def _headers(self) -> dict[str, str]:
h = {"Accept": "application/json"}
if self._api_key:
h["x-api-key"] = self._api_key
return h
配套可以把 min_interval_sec 从 1.1 降到 0.05(即 20 req/s,留 5 倍余量)。
五、Neo4j 建图:CITES 边上挂 doc_id 的关键设计
5.1 Schema
(:Paper {paper_id, title, year, authors, abstract, doi,
citation_count, reference_count})
│
│ [:CITES {doc_id}]
▼
(:Paper {...})
- 节点
Paper用paper_id(来自 S2 的paperId)唯一标识 - 边
CITES有方向:A → B 表示"A 引用了 B" doc_id挂在边上,不挂在节点上(这是本节的关键)
效果图是这样的: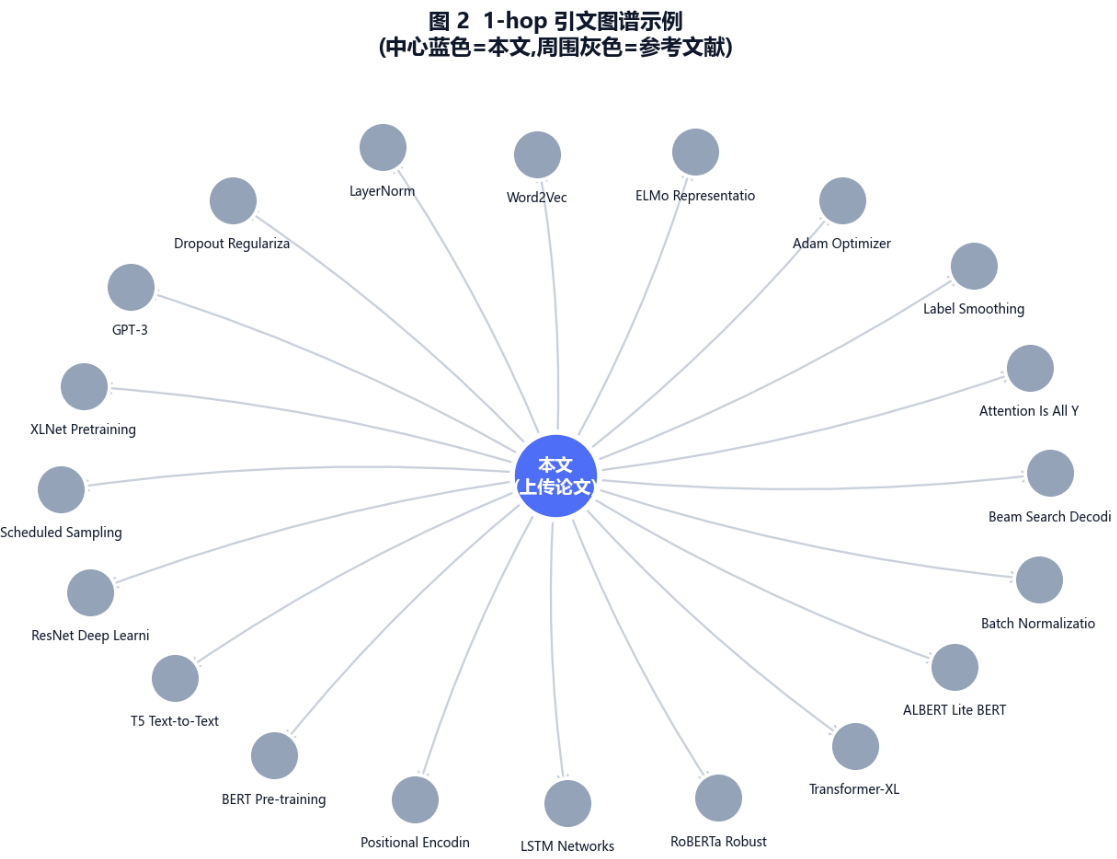
5.2 为什么 doc_id 挂在边上?
想象这个场景:用户 Alice 上传论文 P1,Bob 上传论文 P2,P1 和 P2 都引用了同一篇经典论文 P_classic。
如果用户隔离按节点:
(P1 user=alice) → (P_classic copy_a)
(P2 user=bob) → (P_classic copy_b)
P_classic 会被存两份,浪费存储 + 没法跨用户聚合"P_classic 被 N 个用户引用过"的统计。
正确做法:节点按 paper_id 去重(P_classic 只有一份),边按"哪篇上传论文关联的引用关系"区分:
(P1) -[:CITES {doc_id: "P1"}]-> (P_classic)
(P2) -[:CITES {doc_id: "P2"}]-> (P_classic)
查询时过滤 doc_id:
// 只拿 P1 的引用图
MATCH (r:Paper)-[e:CITES {doc_id: $doc_id}]->(c:Paper)
RETURN r, c, e
这样既共享节点,又能按上传论文隔离图谱。
5.3 建图实现
def build(self, doc_id: str, root: PaperNode, cited: list[PaperNode]) -> int:
self.upsert_paper(root)
with self._driver.session() as s:
result = s.run("""
UNWIND $cited AS c
MERGE (p:Paper {paper_id: c.paper_id})
SET p += c
WITH p
MATCH (r:Paper {paper_id: $root_id})
MERGE (r)-[e:CITES {doc_id: $doc_id}]->(p)
RETURN count(e) AS edges
""", cited=[c.to_props() for c in cited],
root_id=root.paper_id, doc_id=doc_id)
return result.single()["edges"]
UNWIND ... MERGE 是 Neo4j 的批量去重写入惯用写法,一次连接写入所有 cited 节点 + 所有边,避免 N 次小事务。
5.4 Cypher MERGE 的坑:属性要写全
第一版的边 MERGE 是这样:
-- 错误:只 MERGE 关系类型,没指定 doc_id 属性
MERGE (r)-[:CITES]->(p)
结果:(r)-[:CITES]->(p) 这条边如果任何 doc_id 下已经存在,Neo4j 认为它已经存在,就不会创建新的。不同 doc_id 的引用关系被强行去重合并。查询 MATCH (r)-[:CITES {doc_id: "X"}]->(p) 返回空——因为边虽然存在,但没有 doc_id 属性。
正确写法:MERGE 时把关键属性写进 pattern:
-- 正确:MERGE 的边 pattern 里写全属性
MERGE (r)-[e:CITES {doc_id: $doc_id}]->(p)
这样"只要 doc_id=X 这条边不存在就创建",跨 doc_id 不会相互覆盖。
5.5 建议的索引
Neo4j 对 paper_id 做唯一约束 + doc_id 做普通索引会明显加速:
CREATE CONSTRAINT IF NOT EXISTS FOR (p:Paper) REQUIRE p.paper_id IS UNIQUE;
CREATE INDEX cites_doc_id IF NOT EXISTS FOR ()-[e:CITES]-() ON (e.doc_id);
初始化时一次性跑:
def ensure_indexes(self):
with self._driver.session() as s:
s.run("""
CREATE CONSTRAINT IF NOT EXISTS FOR (p:Paper)
REQUIRE p.paper_id IS UNIQUE
""")
s.run("""
CREATE INDEX cites_doc_id IF NOT EXISTS
FOR ()-[e:CITES]-() ON (e.doc_id)
""")
六、LangGraph 集成:citation_graph_node
6.1 节点注册
在 agents/langgraph_engine.py 的 build_graph_v2 里加一个节点:
def build_graph_v2(llm_client, rag_service, sandbox_service=None, graph_service=None):
# ...
_cit_graph = functools.partial(citation_graph_node,
llm_client=llm_client,
graph_service=graph_service)
graph = StateGraph(PaperReadingState)
graph.add_node("citation_graph", _cit_graph)
# 在 router 的 conditional edges 里加入映射
graph.add_conditional_edges("router", _route_by_intent, {
# ... 其他 intent ...
"citation_graph": "citation_graph",
})
graph.add_edge("citation_graph", END)
6.2 关键词路由(先土后智能)
节点自己判断用户问的是谁引用还是引用了谁
_OUTGOING_KEYWORDS = ("引用了", "引用的", "参考", "references", "outgoing", "cites")
_INCOMING_KEYWORDS = ("被引", "被谁", "incoming", "cited by", "被引用")
def citation_graph_node(state, llm_client, graph_service=None):
query = state.get("user_query", "")
want_outgoing = any(k in query for k in _OUTGOING_KEYWORDS)
want_incoming = any(k in query for k in _INCOMING_KEYWORDS)
# 两个都不匹配时:默认都给
if not want_outgoing and not want_incoming:
want_outgoing = want_incoming = True
doc_id = state["paper_metadata"]["doc_id"]
result = {}
if want_outgoing:
result["outgoing"] = graph_service.get_outgoing(doc_id)
if want_incoming:
result["incoming"] = graph_service.get_incoming(doc_id)
# 让 LLM 把图数据翻译成自然语言
response = llm_client.chat_blocking(
query=f"引文数据:{result}\n用户问:{query}\n请用中文简洁回答。"
)
return {"agent_response": response}
关键词判定看起来土,但实际用下来覆盖率够。下周升级为 LLM 意图分类,让它能识别 “这篇论文的 related work 都引了谁” 这种间接问法。
6.3 Prompt 修改
prompts/smart_router.md 里要加入新的 intent 描述,让顶层 router 能路由过来:
- find_citations: 要求分析论文的引用关系,包括引用了哪些论文、被哪些论文引用、引用网络分析
七、踩过的六个坑
坑 1: MinerU 对 References 段头识别不稳定
MinerU 有时把 References 解析成 ## References 一级标题,有时粘到正文末尾变成普通段落。导致正则匹 ^\s*References\s*$ 时漏掉后者。
修法:加更多段头变体(REFERENCES、参考文献、Bibliography),并做 startswith 兜底。
坑 2: Cypher MERGE 边的属性要写全
如前所述,MERGE (r)-[:CITES]->(p) 不带属性会导致跨 doc_id 的边去重合并。
修法:MERGE (r)-[:CITES {doc_id: $doc_id}]->(p),MERGE pattern 里写全关键属性。
坑 3: Semantic Scholar 的 paperId 有时返回 null
某些手输参考(特别是中文会议、workshop paper)在 S2 上搜不到精确匹配,返回的 paperId 字段是 null。如果直接拿它做节点主键,会触发 Cypher NullPointerException。
修法:fallback 给一个本地唯一 id:
paper_id = meta.paper_id or f"noid_{doc_id}_{ref.index}"
节点依然写入图谱,方便后续人工补元数据。
坑 4: httpx 默认 timeout 5 秒不够
Semantic Scholar 偶尔响应慢(尤其是冷启动或限流后),5 秒 timeout 不够,大量 reference 会因为 ReadTimeout 被跳过。
修法:调到 15 秒。
self._client = httpx.Client(timeout=15.0)
坑 5: 无限递归重试(429 循环)
第一版的 429 处理是无限递归,触发限流后会一直 recursion 直到栈溢出或前端 timeout。
修法:加 _MAX_RETRIES=3 上限,3 次失败后返回空列表,让 build 流程继续处理下一条。
坑 6: httpx 连接池复用
默认情况下每次创建 httpx.Client 会建立新 TCP 连接。我们 SemanticScholarClient 把 client 做成实例字段复用,50 条 ref 查询的 TCP handshake 只发生一次:
# 不要每次 search 都 new 一个 Client
self._client = httpx.Client(timeout=15.0) # ← 在 __init__ 里
记得在应用关闭时调用 self._client.close() 或用 context manager。
八、性能数据
在一台 Ryzen 5 5600X + 32GB RAM + 本地 Neo4j 的机器上实测:
| 环节 | 输入 | 耗时 |
|---|---|---|
| PDF 解析(MinerU) | 一篇 20 页 NeurIPS 论文 | 60–90 s |
ReferenceExtractor 抽取 |
50 条参考 | < 0.1 s |
| Semantic Scholar 查询(无 key) | 50 条参考 | 55–80 s(瓶颈) |
| Semantic Scholar 查询(有 key, 20 req/s) | 50 条参考 | 3–5 s |
Neo4j UNWIND MERGE 建图 |
50 节点 + 50 边 | 0.2–0.4 s |
整个链路的瓶颈完全在 Semantic Scholar API 限流。把前两项摆一起就是:
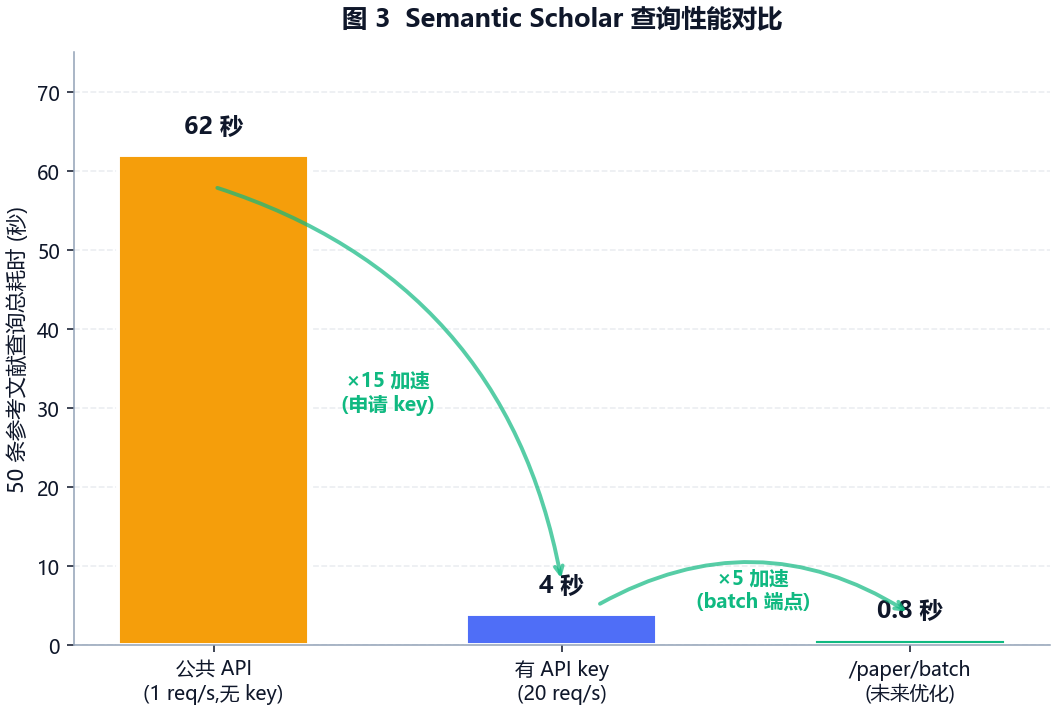
申请 API key + 迁移到 /paper/batch 端点后,50 条 ref 的查询能从 62 秒直接压到 1 秒以内,整体链路 加速——这也是下周优先做的两件事。
九、如何本地复现
9.1 依赖
# Python 侧
pip install neo4j httpx fastapi langgraph python-dotenv
# Neo4j(用 docker 最快)
docker run -d --name neo4j \
-p 7474:7474 -p 7687:7687 \
-e NEO4J_AUTH=neo4j/password \
neo4j:5.20-community
9.2 .env
NEO4J_URI=bolt://localhost:7687
NEO4J_USER=neo4j
NEO4J_PASSWORD=password
SEMANTIC_SCHOLAR_API_URL=https://api.semanticscholar.org/graph/v1
SEMANTIC_SCHOLAR_API_KEY= # 可选,空串走公共限流
9.3 一个最小的调用示例
from services.reference_extractor import ReferenceExtractor
from services.semantic_scholar import SemanticScholarClient
from services.citation_graph import CitationGraphService, PaperNode
# 1. 从 PDF 文本(MinerU 产出)抽取参考
extractor = ReferenceExtractor()
refs = extractor.extract(paper_text)
print(f"抽到 {len(refs)} 条参考,其中 high 置信度 {sum(1 for r in refs if r.confidence == 'high')} 条")
# 2. 用 S2 补元数据
s2 = SemanticScholarClient()
cited_nodes = []
for ref in refs[:50]:
if not ref.title:
continue
results = s2.search_by_title(ref.title, limit=1)
if results:
meta = results[0]
cited_nodes.append(PaperNode(
paper_id=meta.paper_id,
title=meta.title,
year=meta.year,
authors=meta.authors,
))
# 3. 写入 Neo4j
graph = CitationGraphService()
root = PaperNode(paper_id=f"local_{doc_id}", title="我的论文", year=None, authors=[])
edges = graph.build(doc_id=doc_id, root=root, cited=cited_nodes)
print(f"成功写入 {edges} 条 CITES 边")
# 4. 查询
result = graph.query(doc_id=doc_id)
print(f"图谱包含 {len(result['nodes'])} 节点、{len(result['edges'])} 条边")
9.4 Neo4j Browser 里验证
访问 http://localhost:7474,执行:
MATCH (r:Paper)-[e:CITES]->(c:Paper)
RETURN r, e, c
LIMIT 50
就能看到可视化的引文网络。
9.5效果
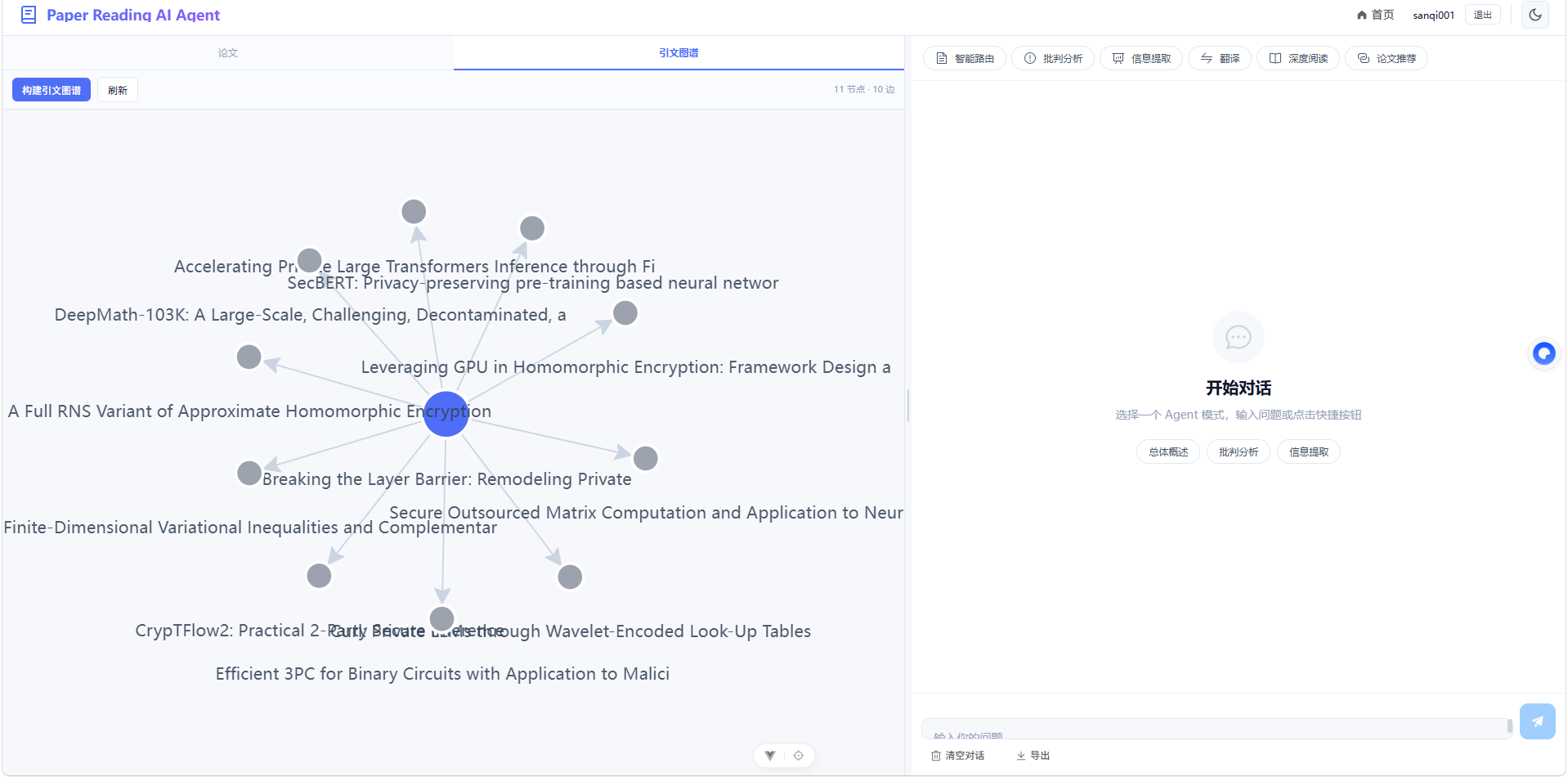
十、总结
本周产出
| 模块 | 文件 | 行数 |
|---|---|---|
| 参考文献抽取 | services/reference_extractor.py |
~120 |
| Semantic Scholar 客户端 | services/semantic_scholar.py |
~100 |
| Neo4j 图谱服务 | services/citation_graph.py |
~130 |
| API 路由 | api/routes/graph.py |
~100 |
| LangGraph 节点 | agents/nodes/citation_graph_node.py |
~80 |
| 单元测试 | tests/test_reference_extractor.py、tests/test_citation_graph.py |
~200 |
最大的心得
对"规则 vs LLM"的界限有了更具体的体感:
结构化抽取用规则(可复现、可测试、快),语义分类用 LLM(灵活、覆盖边缘情况)。
这个心智模型后面做其他 Neo4j 相关 Agent(比如方法复现、趋势分析)都可以沿用。
十一、参考资料

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)