Claude Opus 4.7 同样文本的 token 数增加最多 35%,AI Agent 运营成本正在指数级增长
上个月我们内部的一个客服 agent 上线了三周,账单出来的时候,负责算成本的同事把截图发进群里没说话。
一个日均处理 2000 个 ticket 的 agent,三周花了将近 6,000。这还只是 API 调用费,不包括基础设施。
我们之前估算的是每月 $800。
差了将近 8 倍。
这不是个例。Hacker News 上最近两篇帖子同一天冲上首页——一篇讨论 Claude Opus 4.7 新 tokenizer 导致同样文本的 token 数增加最多 35%,获得了 621 分和 438 条评论;另一篇直接标题就问:"Are the costs of AI agents also rising exponentially?",220 分,评论区一片哀嚎。
说实话,这个问题其实不难回答。难的是,大多数团队在上线之前根本没有认真算过这道数学题。
一次 agent 调用究竟消耗多少 token
先建立直觉。
最简单的单次 LLM 调用:一个系统提示,一条用户消息,一个回复。这种情况下 token 消耗是可预期的。但 agent 和这个场景有本质区别——它是一个循环,每次循环都会把所有历史记录重新打包发给模型。
一个典型的客服 agent 调用链是这样的:
-
系统提示(角色定义、工具描述、业务规则):约 2,000-4,000 tokens
-
工具定义(查询订单、更新状态、发起退款等 5 个工具):约 1,500 tokens
-
对话历史(随轮次累积):第 1 轮 50 tokens,第 5 轮可能是 800 tokens
-
模型输出(reasoning + tool call + 回复):约 300-800 tokens per round
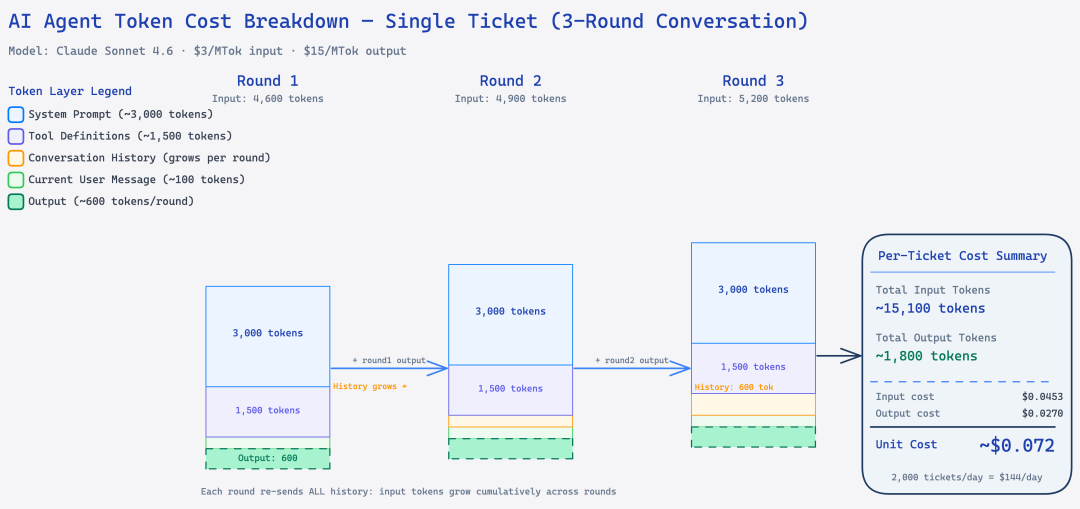
单个 ticket 平均需要 3 轮对话才能解决。到第 3 轮时,input token 数大概是:
第3轮 input = 系统提示(3000) + 工具定义(1500) + 对话历史(约600) + 当前消息(100) ≈ 5,200 tokens三轮加起来,一个 ticket 的 total input tokens 大概是:
-
第 1 轮:4,700 tokens
-
第 2 轮:5,000 tokens
-
第 3 轮:5,200 tokens
-
输出合计(3轮):约 1,800 tokens
单个 ticket:约 16,700 tokens
用 Claude Sonnet 4.6( 15/MTok output)来算:
input cost = 15,100 tokens × $3 / 1,000,000 = $0.0453
output cost = 1,800 tokens × $15 / 1,000,000 = $0.0270
单 ticket 成本 ≈ $0.072日均 2000 个 ticket:$0.072 × 2000 = $144/天,月成本约 $4,320。
这个数字和实际账单完全吻合。
为什么成本会"指数级"增长
"指数级"这个词不是夸张。
上下文是一个不断膨胀的雪球
在 multi-turn agent 里,每一轮的 input 包含所有历史轮次的内容。这意味着:
-
第 1 轮:输入 N tokens
-
第 2 轮:输入 N + round1_output tokens
-
第 3 轮:输入 N + round1_output + round2_output tokens
-
第 n 轮:以此类推
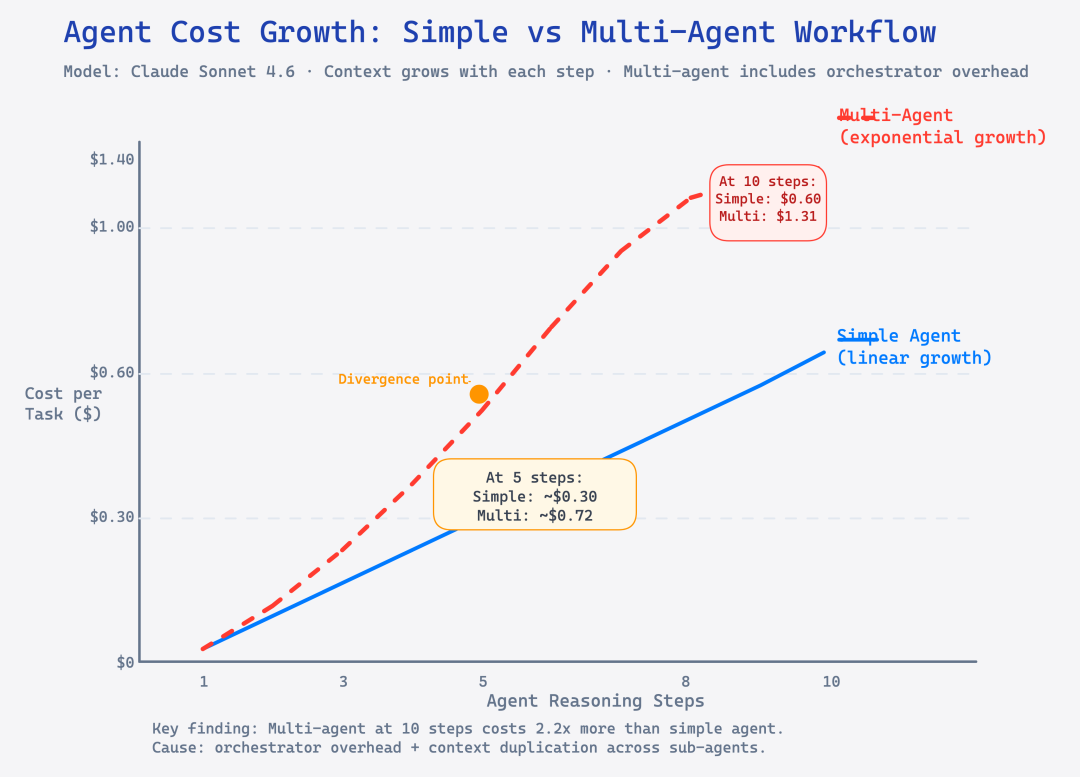
如果每轮输出平均 500 tokens,第 10 轮的 input 就比第 1 轮多了 9 × 500 = 4,500 tokens。这还是在 N 不变的情况下。实际上系统提示也会随业务复杂度增长。
一个需要 10 步推理的代码调试 agent,和一个需要 3 轮的客服 agent 相比,token 成本可能高出 5-10 倍——不是因为任务逻辑复杂,而是纯粹因为上下文长度在滚雪球。
Multi-agent workflow 的成本乘数效应
更麻烦的场景是 multi-agent orchestration。当一个 orchestrator agent 把任务分解给多个 sub-agent 时,每个 sub-agent 都会产生独立的 token 消耗,最后 orchestrator 还要读取所有 sub-agent 的输出来做汇总。
假设一个研究 agent 由 1 个 orchestrator + 3 个 sub-agent 组成:
|
角色 |
轮次 |
单次 input |
输出 |
小计 |
|---|---|---|---|---|
|
Orchestrator |
2轮 |
6,000 |
1,200 |
~13,200 |
|
Sub-agent A(搜索) |
5轮 |
8,000 |
800 |
~44,000 |
|
Sub-agent B(分析) |
4轮 |
10,000 |
1,500 |
~46,000 |
|
Sub-agent C(写作) |
3轮 |
12,000 |
3,000 |
~45,000 |
单次任务合计约 148,200 tokens,用 Opus 4.7( 25)算下来是:
input: ~120,000 × $5 / 1M = $0.60
output: ~28,200 × $25 / 1M = $0.705
单次任务成本 ≈ $1.31如果这个 agent 每天跑 500 次任务,月成本接近 $20,000。
Opus 4.7 的新 tokenizer:一个被低估的成本炸弹
这是最近 HN 讨论的核心之一。Claude Opus 4.7 换用了新 tokenizer,Anthropic 在文档里直接写明:对同样的文本,新 tokenizer 可能多计 最多 35% 的 token。
坦白讲,这里有个很容易踩到的坑。很多团队升级模型时只看 benchmark 评分,不会重新核算 token 数。如果你的系统提示是 3,000 tokens(旧 tokenizer),切到 Opus 4.7 之后可能变成 4,050 tokens。在高并发场景下,这 35% 的差异会直接反映在账单上。
一个月跑 1000 万次 LLM 调用的系统,仅因为 tokenizer 升级,账单可能突增 30% 以上——即使你什么代码都没改。
真实账单里最让人意外的部分
我们在自检账单时发现了几个反直觉的模式。
工具定义 token 是被忽视的隐形成本
很多人只关注用户消息和系统提示的 token 数,忽略了工具定义本身的开销。
Claude 的 tool use 定价文档里有个细节:除了你定义的工具内容本身,系统还会自动注入一个 tool use system prompt。以 Opus 4.7 为例,auto tool choice 模式下额外增加 346 tokens。
如果你定义了 10 个工具,每个工具的 schema 平均 200 tokens,加上系统注入的 346 tokens,仅工具定义就是 2,346 tokens。这些 tokens 每一轮对话都要重复计费。
一个 5 轮对话:2,346 × 5 = 11,730 tokens,全部是工具定义的重复消耗。
Reasoning 模型的隐藏成本
用 Claude Sonnet 4.6 开启 extended thinking 时,thinking tokens 是以 output token 价格计费的——$15/MTok。
一个需要深度推理的任务,thinking token 可能有 3,000-10,000 tokens。即便最终的可见输出只有 500 tokens,你实际支付的 output cost 是它的 6-20 倍。
这不是说 extended thinking 不值,有些任务确实需要。但如果你只是把它当做"更准确的 GPT"来用,没有针对性地控制 thinking budget,账单会非常难看。
三个反直觉的成本优化策略
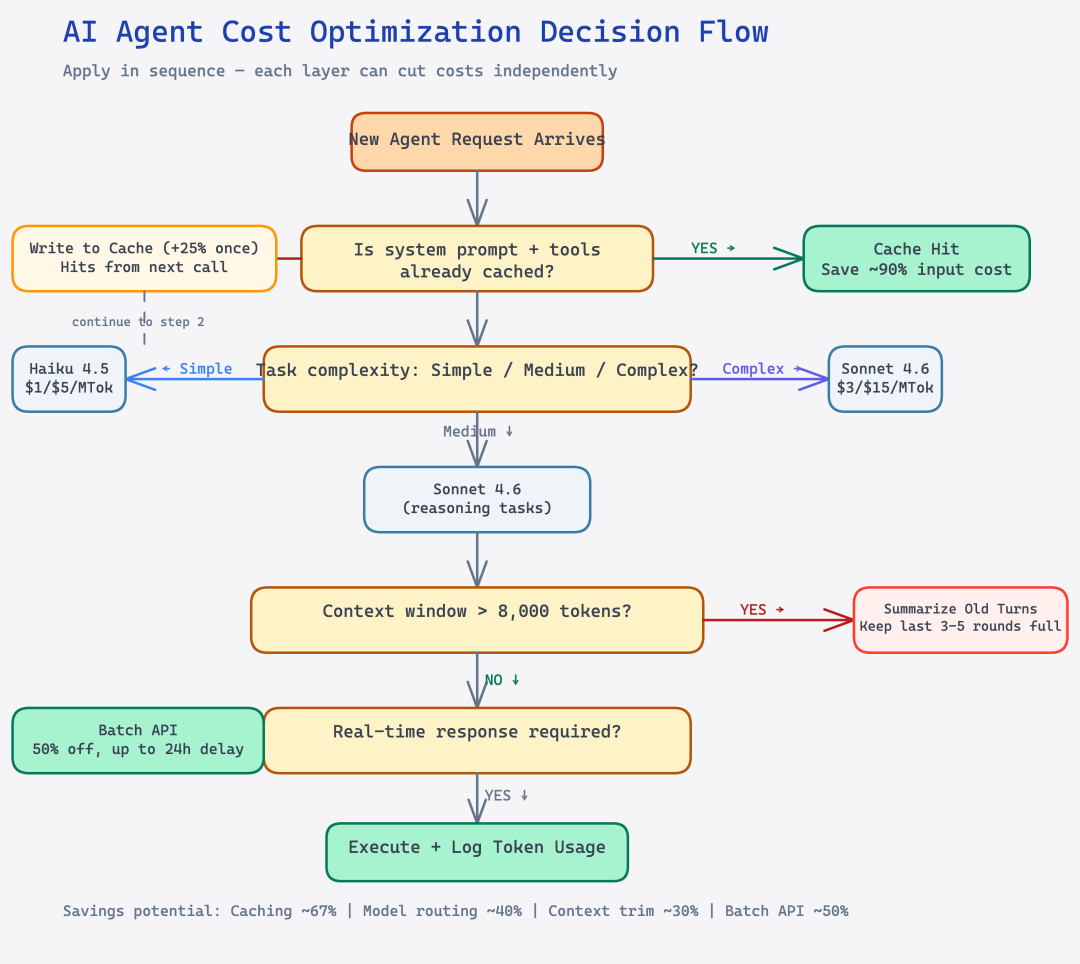
策略一:主动缓存,而不是压缩上下文
大多数人遇到高 token 消耗的第一反应是压缩:精简系统提示、截断历史记录。这个思路没错,但有个更划算的做法经常被忽视:prompt caching。
Claude 的 prompt caching 机制是这样的:
-
5 分钟 TTL cache write:1.25x 标准 input 价格
-
Cache hit(读取缓存):0.1x 标准 input 价格
也就是说,只要一个缓存过的 prompt 块在 5 分钟内被读取一次,你就回本了(1.25 write + 0.1 read < 2.0 × 2 reads)。
实际效果有多显著?官方文档里给了一个例子:系统提示 100,000 tokens,首次请求写入缓存 0.05。**单次节省 92%**。
对高频 agent 来说,系统提示、工具定义这些内容几乎不变,天然适合缓存。我们把系统提示和工具定义放进 1 小时 TTL 的缓存后,input cost 下降了 67%。
需要注意的是:1 小时 TTL 的 cache write 是 2x 价格,适合低频但稳定的场景;5 分钟 TTL 是 1.25x,适合高并发场景(每 5 分钟内会有多次调用)。
策略二:模型路由,不是模型降级
"用便宜的模型"是个好思路,但"把所有请求都降级到 Haiku"通常不是正确答案。
更有效的做法是模型路由(model routing):
-
分类型路由:工具调用(查库存、查订单状态)用 Haiku,需要理解上下文、做判断的步骤用 Sonnet,只有真正复杂的推理任务才用 Opus
-
分轮次路由:第 1 轮理解意图用 Sonnet,中间执行步骤用 Haiku,最终生成回复用 Sonnet
-
动态路由:根据 input 长度和复杂度动态选择模型
以客服 agent 为例,5 个 tool call 里有 3 个是查询操作(Haiku 完全可以处理),最终生成人工回复才需要 Sonnet。这样的路由策略可以把模型成本压低 40-60%,而质量下降几乎感知不到。
Haiku 4.5 是 5/MTok output;Sonnet 4.6 是 15。同样的逻辑,用 Haiku 的成本是 Sonnet 的 1/3。
策略三:上下文裁剪,但裁什么有讲究
上下文压缩是对的,但不能无脑截断最早的轮次。
一个更精细的策略是分层裁剪:
-
近期轮次完整保留(最近 3-5 轮):agent 需要记住刚才做了什么
-
早期轮次摘要化:用一个独立的小 LLM 调用把前 N 轮对话压缩成摘要,成本远低于保留全文
-
工具调用结果精简:很多工具返回的 JSON 里有大量无用字段,在喂给下一轮之前做一次 schema 过滤
一个典型的 10 轮对话,不加处理的 context 可能是 50,000 tokens,用分层裁剪压缩后通常可以控制在 15,000-20,000 tokens 以内,同时保留所有关键信息。
一个踩坑案例:开启 thinking 反而更贵
我们有个内部工具,负责分析合同文本里的风险条款。最初用 Sonnet 4.6 不开 extended thinking,准确率勉强够用,偶尔会漏掉隐藏条款。
有人提议开启 extended thinking,测试效果确实好了不少。但上线前没有仔细算过成本。
上线后第一周,这个工具的 API 账单是之前的 4.3 倍。
复盘之后才发现:合同文本本身很长(平均 20,000 tokens),thinking budget 没有设置上限,模型动不动就用掉 8,000-12,000 thinking tokens,而这些全部按 output 价格计费。
修复方案是设置 max_tokens for thinking,把 thinking budget 压到 3,000 tokens,并且针对特定的高价值合同场景才启用 thinking,日常简单查询用普通模式。调整后成本回落,准确率只下降了不到 5%。
这个案例的教训是:extended thinking 不应该默认全量启用,它是一个需要根据 ROI 精细控制的开关。
Batch API:被低估的 50% 折扣
如果你的 agent 任务不需要实时响应,Batch API 是最简单粗暴的成本优化手段。
Anthropic 的 Batch API 提供 50% 折扣,输入和输出都打五折:
|
模型 |
标准 input |
Batch input |
标准 output |
Batch output |
|---|---|---|---|---|
|
Sonnet 4.6 |
$3/MTok |
$1.5/MTok |
$15/MTok |
$7.5/MTok |
|
Opus 4.7 |
$5/MTok |
$2.5/MTok |
$25/MTok |
$12.5/MTok |
|
Haiku 4.5 |
$1/MTok |
$0.5/MTok |
$5/MTok |
$2.5/MTok |
代价是延迟:Batch API 的响应时间最长可能到 24 小时。
适合用 Batch API 的场景:
-
离线数据分析(日报、周报生成)
-
大规模文档处理(合同批量审查、内容分类)
-
非实时的知识库更新
-
A/B 测试时的模型评估
我们把所有非实时分析任务都切到了 Batch API,这部分的月度成本直接砍掉了一半。
怎么算你的 agent 会烧多少钱
给一个简单的估算模型:
基本参数:
-
D= 日均任务数 -
R= 平均轮次数 -
S= 系统提示 + 工具定义 token 数(fixed cost per round) -
H= 对话历史平均 token 数(随轮次增长) -
O= 平均输出 token 数 per round -
Pi= input 单价($/MTok) -
Po= output 单价($/MTok)
单轮 input tokens:
input_per_round(n) = S + H × (n-1) + user_msg_tokens单任务总成本:
task_cost = Σ(n=1 to R) [input_per_round(n) × Pi/1M] + R × O × Po/1M月成本:
monthly_cost = D × 30 × task_cost把这个模型套进去算一遍,通常会发现比直觉估算高 3-5 倍。因为大多数人估算时只考虑了"有效"的业务内容 token,忘了系统提示、工具定义、历史累积这些乘以轮次之后的放大效应。
常见问题
Q:用更便宜的模型(比如 Haiku)不就解决问题了吗?
A:降级模型可以解决部分问题,但不能解决根本问题。上下文膨胀的成本是随轮次线性增长的,即使用 Haiku,一个 20 轮的对话的 input cost 仍然是 1 轮的 20 倍。治本的方式是控制 context 长度和调用轮次,降级只是在对的任务上选对的模型。
Q:prompt caching 能给 multi-agent 场景省多少?
A:取决于系统提示和工具定义的比例。一般来说,如果系统提示 + 工具定义占到每轮 input 的 40% 以上(大多数 agent 都是这样),加上 prompt caching 之后可以节省 30-60% 的 input cost。在高频场景(每分钟 10 次以上调用)效果更显著,5 分钟 TTL 的命中率接近 100%。
Q:Claude 4.7 的新 tokenizer 会不会让我现有的提示词成本大幅上升?
A:如果你升级到 Opus 4.7,是的,需要重新评估。新 tokenizer 对代码、技术文档、多语言内容的影响较大,纯英文的系统提示影响相对小一些。建议在灰度切量前先用 tokenizer 工具对比一下你的实际系统提示,如果差值超过 15%,要重新做成本测算。
Q:extended thinking 值得用吗?
A:分场景。对于需要复杂推理、多步骤逻辑、容错率低的任务(比如法律文本分析、复杂代码调试),thinking 的准确率提升往往值得额外的成本。对于日常的 Q&A、数据查询、内容生成,标准模式已经足够,不必为了"更强的模型"而无脑开启 thinking。一个实用规则:如果任务错一次的代价超过 $0.50,才考虑用 extended thinking。
Q:有没有更系统的方式监控 agent 的成本?
A:API 响应里的 usage 字段会返回 cache_creation_input_tokens、cache_read_input_tokens、input_tokens、output_tokens 四个维度,可以直接打到 metrics 系统里做监控。建议设置每日成本告警,阈值设在预期成本的 120%。超出时先看 cache hit rate——如果低于 60%(高频场景),通常说明 prompt caching 没有生效或者上下文结构有问题。
成本控制的本质是架构决策
说到底,AI agent 的成本问题不是账单管理问题,是架构设计问题。
哪些内容必须放进系统提示、哪些工具是每轮都需要的、上下文应该保留多少、什么任务需要强模型——这些选择在写第一行代码时就定了基调。事后来优化成本,通常只能削减 20-30%;从架构层面把这些问题想清楚,节省 60-80% 完全可能。
我们那个账单超出预期 8 倍的客服 agent,最后通过 prompt caching + 模型路由 + 上下文裁剪,把月成本从 1,400。没有改任何业务逻辑,只是在 token 的流动路径上做了设计。
如果你也在搭 agent,建议现在就把那道数学题算一遍,别等账单出来才开始优化。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 13
13 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)