【LangChain】LangChain 相关概念、快速上手
🌈个人主页:秦jh__https://blog.csdn.net/qinjh_?spm=1010.2135.3001.5343
🔥 系列专栏:https://blog.csdn.net/qinjh_/category_13137010.html

目录
前言
💬 hello! 各位铁子们大家好哇。
今日更新了LangChain相关内容
🎉 欢迎大家关注🔍点赞👍收藏⭐️留言📝
本章节环境说明
- Python 3.13
- 本章节使用到的 LangChain 相关包:第一部分
requirements.txt 如下所示:
langchain-openai==0.3.33
langchain==0.3.27
langchain-deepseek==0.1.4
langchain-ollama==0.3.6
langchain-tavily==0.2.12
langchain-chroma==0.2.5
langchain-community==0.3.22
nltk==3.9.2
langchain-redis==0.2.4
unstructured==0.18.15
markdown==3.9
redisvl==0.10.0
安装命令: pip install -r requirements.txt
3.本章节使用到的 LangChain 相关包:第二部分
pinecone==7.3.0
langchain-pinecone==0.2.12注意:
- 这部分需要学习到 【三、核心组件-7.3.4 Pinecone 向量存储】 后才可安装。原因是安装 langchain-pinecone 时,会同时安装依赖包 simsimd 。安装此包后,会导致 【三、核心 组件-7.3.3 Redis 向量存储】 的 MMR 搜索不可用。该问题目前官方尚未解决。
- 若安装 langchain-pinecone 高版本,如 0.2.3 (支持 Python 3.13),可能会无法成功。 原因是其依赖包 numpy 要求 numpy=1.26.4 ,而该范围的 numpy 不支持 Python 3.13。该问题目前官方尚未解决。
快速上手
内容与目标
对于 LangChain,它是一个用于开发 由大语言模型 (LLM) 驱动的应用程序的框架。
通过前几个章节,我们已经说明尽管大模型的在某些方面表现振奋人心,但使用原生 LLM 可能会存在 一些问题,例如将其当作搜索引擎去使用,LLM 生成的答案可能要比其他搜索引擎查到的答案更符合 你的预期,但要是在复杂的场景下使用,如将 LLM 嵌入应用程序时却遭遇了全新难题:
- 简单提示词(Prompt)得到的答案经常出现幻觉?
- 提示词结构是否可以统一规范?
- 如何实现开发过程中大模型的轻松、灵活切换?
- 大模型输出是非结构化的,怎样与要求结构化数据的程序接口交互?
- 如何克服预训练模型知识陈旧的问题,引入实时更新?
- 如何连接模型与外部工具或系统,执行具体任务?
- ...
LangChain 框架的核心目标就是应对这些挑战。它通过将自然语言处理流程拆解为标准化组件,让开 发者能够自由组合并高效定制工作流。
详细过程
步骤1:申请 API key 并配置环境变量
申请 API key
以 OpenAI 为例,官网地址:https://platform.openai.com/(魔法上网)
如果没有账号先注册账号,登录成功后,出现 settings 图标,点击 settings,选择 API keys 配置页 面:
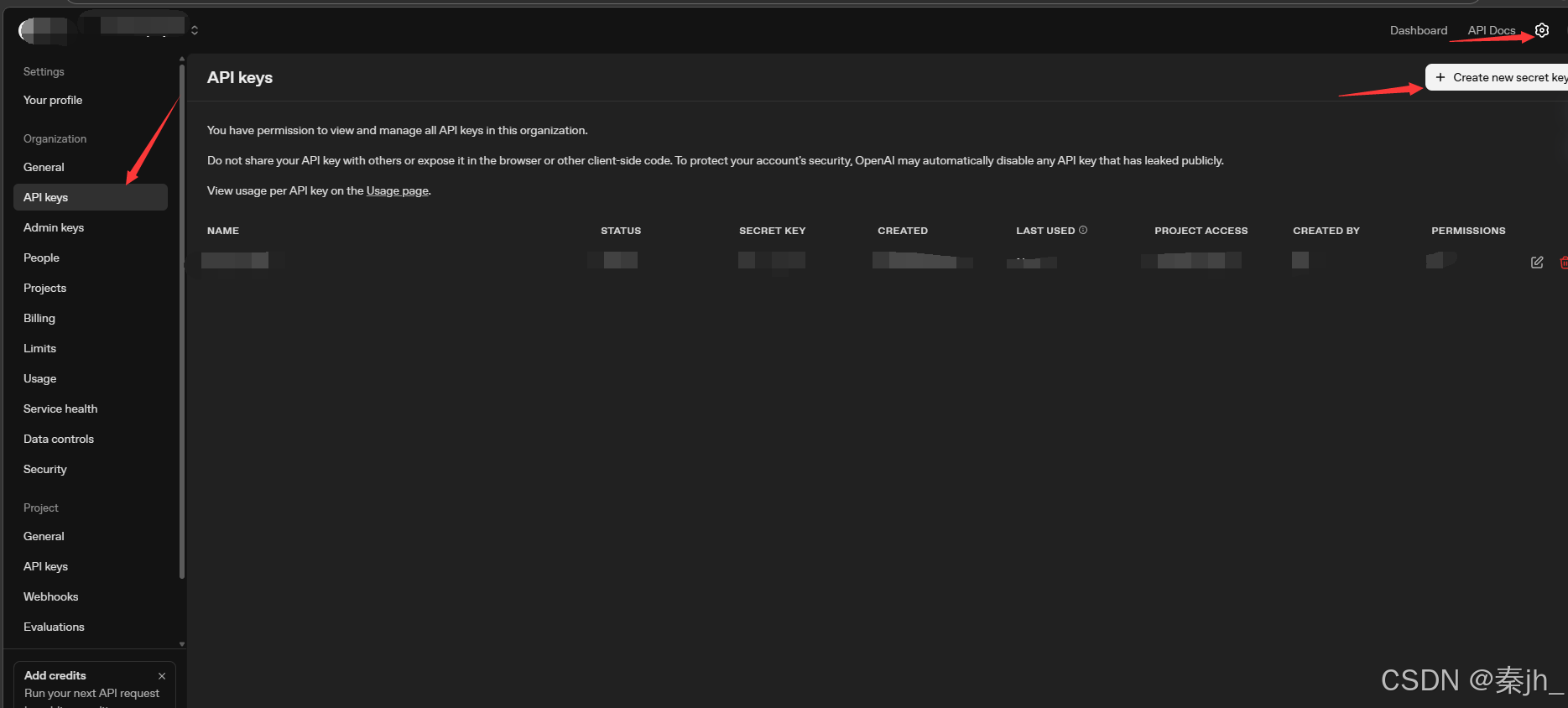
将 API Key 在自己本地保存好,后续接入 ChatGPT 时需要使用。
配置环境变量
将 API Key 配置在环境变量中主要是为了保证其隐私性。由于 api key 比较隐私,为避免在程序中暴 露,可提前将各个 api key 配置在环境变量中,这样在程序中就可以通过获取对应环境变量拿到 api key,保证了 api key 的隐私。
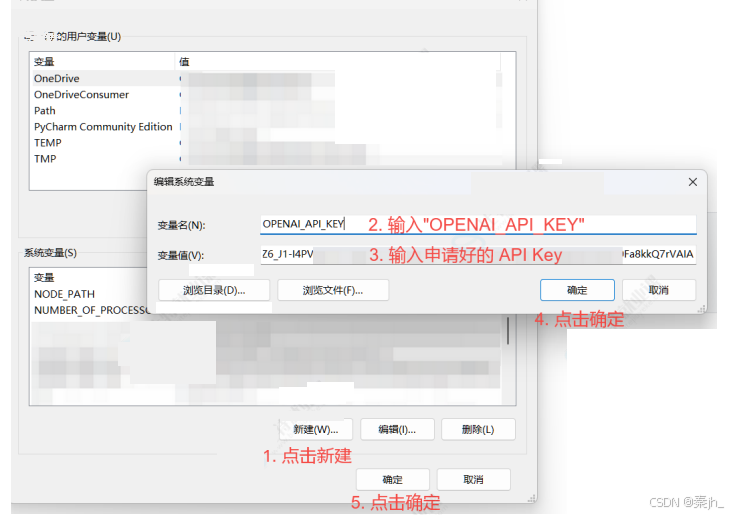
步骤2:定义大模型
安装 OpenAI 包
pip install -U langchain-openai
定义大模型
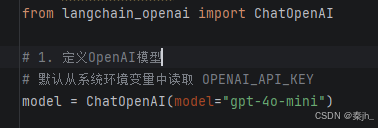
步骤3:定义消息列表
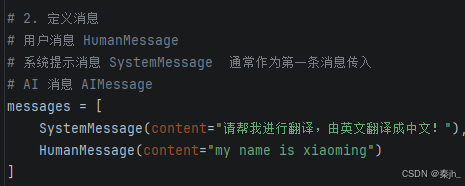
参数说明:
- SystemMessage :表示 系统角色 消息,系统消息通常作为输入消息序列中的第一条传入,是 用来启动 AI 行为的消息。
- HumanMessage :表示 用户角色 消息,是来自用户的、从用户传递到模型的消息。
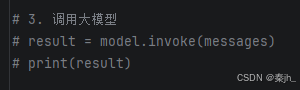
步骤4:调用大模型
model 是 LangChain Runnable (可运行)接口的实例,这意味着 model 提供了一个标准接口供 我们与之交互。要简单地调用模型,我们可以将 消息列表 传递给 .invoke 方法。
使用 .invoke 方法进行大模型调用,核心代码:
输出结果(调试可以看见 result 类型为 AIMessage):
content='你好!' additional_kwargs={'refusal': None} response_metadata= {'token_usage': {'completion_tokens': 2, 'prompt_tokens': 20, 'total_tokens': 22, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_name': 'gpt-5-mini-2024-07-18', 'system_fingerprint': 'fp_560af6e559', 'id': 'chatcmpl-C5l29mi6KkQSFO3qaElDJD5Lj9nBn', 'service_tier': 'default', 'finish_reason': 'stop', 'logprobs': None} id='run--777ef0be-55c2-411a-a4ab104a45c22f20-0' usage_metadata={'input_tokens': 20, 'output_tokens': 2, 1 2 3 4 5 6 1 2 1 'total_tokens': 22, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}
输出说明:
- AIMessage :来自 AI 的消息。从聊天模型返回,作为对提示(输入)的响应。
- content :消息的内容。
- additional_kwargs :与消息关联的其他有效负载数据。对于来自 AI 的消息,可能包括模 型提供程序编码的工具调用。
- response_metadata :响应元数据。例如:响应标头、logprobs、令牌计数、模型名称。
- 侧重于 “响应”本身的信息,比如这次请求的 ID、使用的模型版本、以及服务提供商返回 的所有原始元数据。它主要用于调试、日志记录和获取请求的上下文信息。
- usage_metadata :消息的使用元数据,例如令牌计数。
- 侧重于 “资源消耗”的量化信息,即这次请求消耗了多少 Token。它主要用于成本计算、 监控和预算控制。
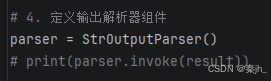
步骤5:输出解析
若只想输出聊天模型返回的结果字符串,可以使用 StrOutputParser 输出解析器组件,将大模型 输出结果解析为最可能的字符串。核心代码:
步骤6:链式执行
通过上述步骤,无论是调用大模型,还是输出解析,我们发现,每次都调用了一个 invoke() 方法,最 终才会得到我们想要的结果。
对于 LangChain,它给我们提供了链式执行的能力,即我们只需要定义各个“组件”,将它们“链起 来”,一次性执行即可得到最终效果。
注意:以上描述只是为了好理解,并不是其真正定义。
完整代码参考:
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableSequence
from langchain_openai import ChatOpenAI
# 1. 定义OpenAI模型
# 默认从系统环境变量中读取 OPENAI_API_KEY
model = ChatOpenAI(model="gpt-4o-mini")
# 2. 定义消息
# 用户消息 HumanMessage
# 系统提示消息 SystemMessage 通常作为第一条消息传入
# AI 消息 AIMessage
messages = [
SystemMessage(content="请帮我进行翻译,由英文翻译成中文!"),
HumanMessage(content="my name is xiaoming")
]
# 3. 调用大模型
# result = model.invoke(messages)
# print(result)
# 链式体现在哪里???
# 4. 定义输出解析器组件
parser = StrOutputParser()
# print(parser.invoke(result))
# 5. 定义链
# 执行链
chain = model | parser
# chain = RunnableSequence(first=model, last=parser)
# chain = model.pipe(parser)
print(chain.invoke(messages))
引出 LangChain 相关概念
Runnable 接口
Runnable 接口是使用 LangChain Components(组件)的基础。
概念说明: Components(组件):用来帮助当我们在构建应用程序时,提供了一系列的核心构建块,例如语 言模型、输出解析器、检索器、编译的 LangGraph 图等。
Runnable 定义了一个标准接口,允许 Runnable 组件:
- Invoked(调用): 单个输入转换为输出。
- Batched(批处理): 多个输入被有效地转换为输出。
- Streamed(流式传输): 输出在生成时进行流式传输。
- Inspected(检查): 可以访问有关 Runnable 的输入、输出和配置的原理图信息。
- Composed(组合): 可以组合多个 Runnable,以使用 LCEL 协同工作以创建复杂的管道。
因此,在快速上手中,我们定义的语言模型(model)、输出解析器(StrOutputParser)都是 Runnable 接口的实例!他们都使用了 Invoked(调用)的能力
LangChain Expression Language
LangChain Expression Language(LCEL):采用声明性方法,从现有 Runnable 对象构建新的 Runnable 对象。
通过 LCEL 构建出的新的 Runnable 对象,被称为 RunnableSequence ,表示可运行序列。 RunnableSequence 就是一种 链 (参考步骤6)。通过调试 步骤6 就能发现,chain 的类型就是 RunnableSequence 。如下所示:
![]()
重要的是, RunnableSequence 也是 Runnable 接口的实例 ,它实现了完整的 Runnable 接口, 因此它可以用与任何其他 Runnable 相同的姿势使用。
回顾一下:
chain = model | parser
chain.invoke(messages) # 链是 Runnable 接口实例,允许invoke调用可以看到,LCEL 其实是一种编排解决方案,它使 LangChain 能够以优化的方式处理链的运行时执 行。任何两个 Runnable 实例都可以“链”在一起成序列。上一个可运行对象的 .invoke() 调用 的输出作为输入传递给下一个可运行对象。方法就是使用 | (管道/运算符):
它通过两个 Runnable 对象去创建一个 RunnableSequence 。实际上 LangChain 重载了 | 运算 符,使用 | 运算符就相当于:
from langchain_core.runnables import RunnableSequence
chain = RunnableSequence(first=model, last=parser)除此之外,可以使用 .pipe 方法代替。这也相当于 | 运算符:
在 Unix/Linux 系统中, pipe() 系统调用和 | 管道操作符都用于实现进程间通信,这里同样也 是迁移过来的用法。
chain = model.pipe(parser)
欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐
 69
69 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)