大语言模型筛选肿瘤相关基因!这篇 IF12+ 文章的思路值得好好思考学习一下
生信碱移
HKLLM-RG肿瘤基因
HKLLM-RG:大语言模型直接筛选肿瘤相关基因?
疾病相关基因挖掘其实就是大部分研究者的一手工作,接着后面个性发挥的表型、机制实验。传统方法基本上就是文献阅读、高通量测序、生信分析,可以说具有一定门槛,或者费时费力。
最近看到一篇华西医院发表的 Molecular Therapy [IF 12.0],作者做的就是直接用大语言模型(LLM)来筛选出肿瘤相关基因。标题当然也是围绕主线,突出一个大语言模型赋能:”An LLM-powered discovery in prostate cancer“。

DOI: 10.1016/j.ymthe.2026.02.003
作者主要做的就是 LLM + 外部专家知识来进行核心基因筛选,虽然并不涉及方法开发,但好歹是个新鲜的流程,正文中称为分层知识引导的风险基因识别 LLM 方法(HKLLM-RG)。
顾名思义,这个方法的输入,不是原始测序矩阵,而是两大类“知识型输入”。首先是 LLM 自带的内部知识,也就是模型预训练时学到的生物医学和癌症相关知识。作者明确写了,方法会利用 LLM 的 internal, pretrained biomedical knowledge。
然后则是外部专家知识(external expert knowledge),也算是文章的创新点,可以分成两层:
-
• 通用癌症知识层:来自 5 篇高质量癌症综述,覆盖基因组学、转录组学、蛋白组学、表观组学、代谢组学;
-
• 前列腺癌专门知识层,来自前列腺癌研究,覆盖流行病学、发病机制、诊断、治疗、预防。
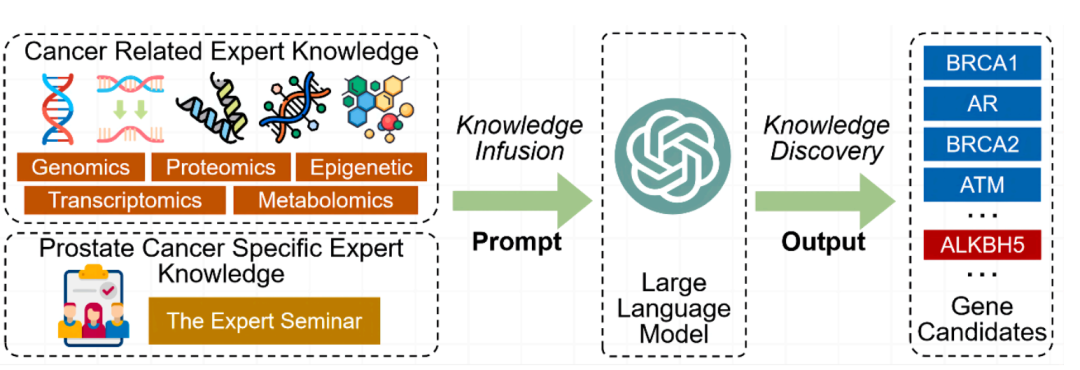
整体流程:基于两大类知识输入的 LLM 用于鉴定前列腺癌核心基因。
除了上面的内容以外,与大语言模型对话的提示词(Prompt)以及具体的分析也是有设计的好吧。小编主要讲比较关键的两个点,具体大家可以阅读原文:
-
• 数量上,提示词明确 LLM 要输出前 50 个与前列腺癌风险最相关的人类基因。
-
• 可重复性方面,要求 LLM 重复运行 30 次,统计高频出现的基因,减少随机性。
在此基础上,作者还进行了性能评估,比较了几个知名的 LLM,证明 HKLLM-RG 的设计确实可以增强核心基因的挖掘能力:
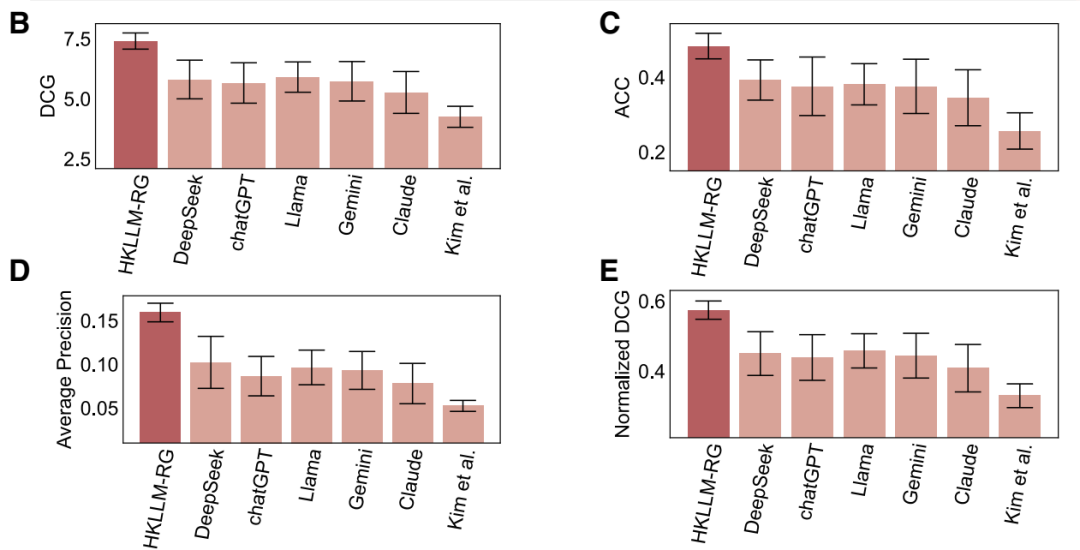
性能评估:计算了 HKLLM-RG 与 Chatgpt, DeepSeek 等模型的多性能指标。
作者把 30 次分析得到的 top 50 列表做整合,其中 ALKBH5 因为兼具 m6A 调控重要性并且在前列腺癌中研究不足,被选中做深入研究。之后就进入实验部分了:
-
• 看 ALKBH5 在临床样本和数据库里是不是异常
-
• 看它对细胞增殖/迁移/成瘤有没有影响
-
• 看它是不是通过 ferroptosis 起作用
-
• 找它的下游分子 CHRM3
-
• 证明 ALKBH5 对 CHRM3 的调控是 m6A 依赖的
-
• 再往下追到 ZNF281、GPX4、SLC3A2、AKT
-
• 最后验证联合治疗
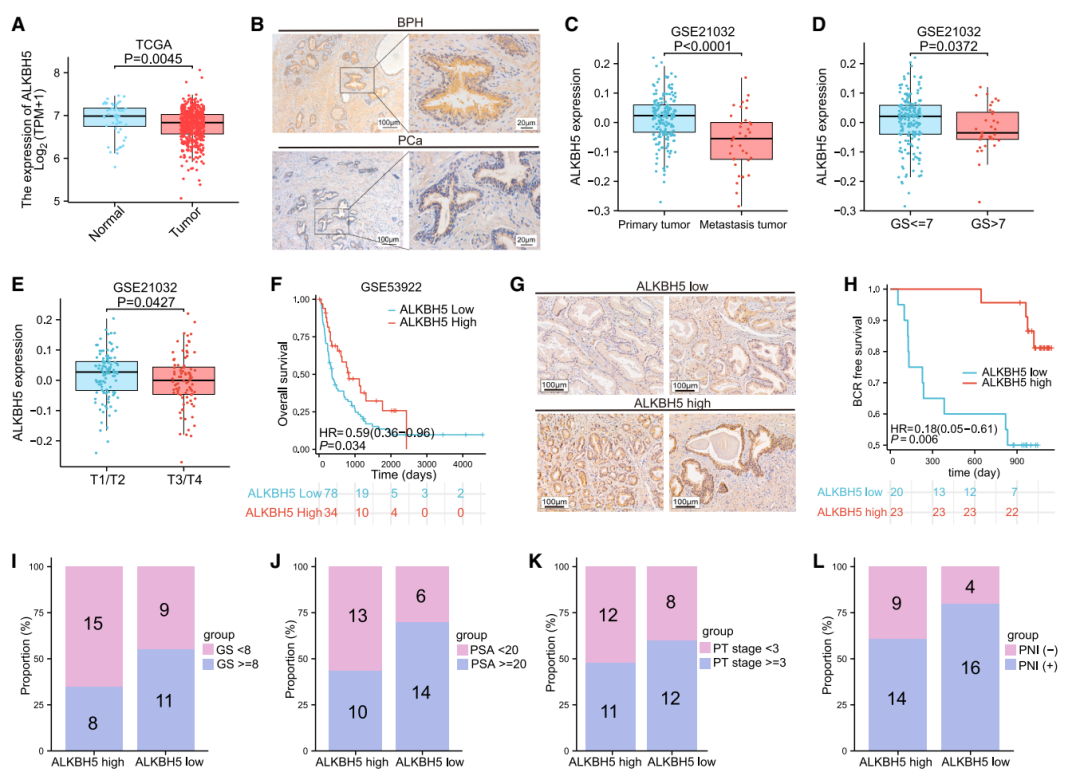
图:ALKBH5 的表达异常。其余实验结果小编不做展示,可以自行阅读学习。
换个癌种又是一篇
真是从算法工程师到提示词工程师了
不过还是有一些基础生信分析的
收藏学习了

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)