04 claude code Token 预算管理 - 上下文窗口动态计算
参考文献
https://ccb.agent-aura.top/docs/context/token-budget
一,前置知识
先看一下最新大模型上下文长度:
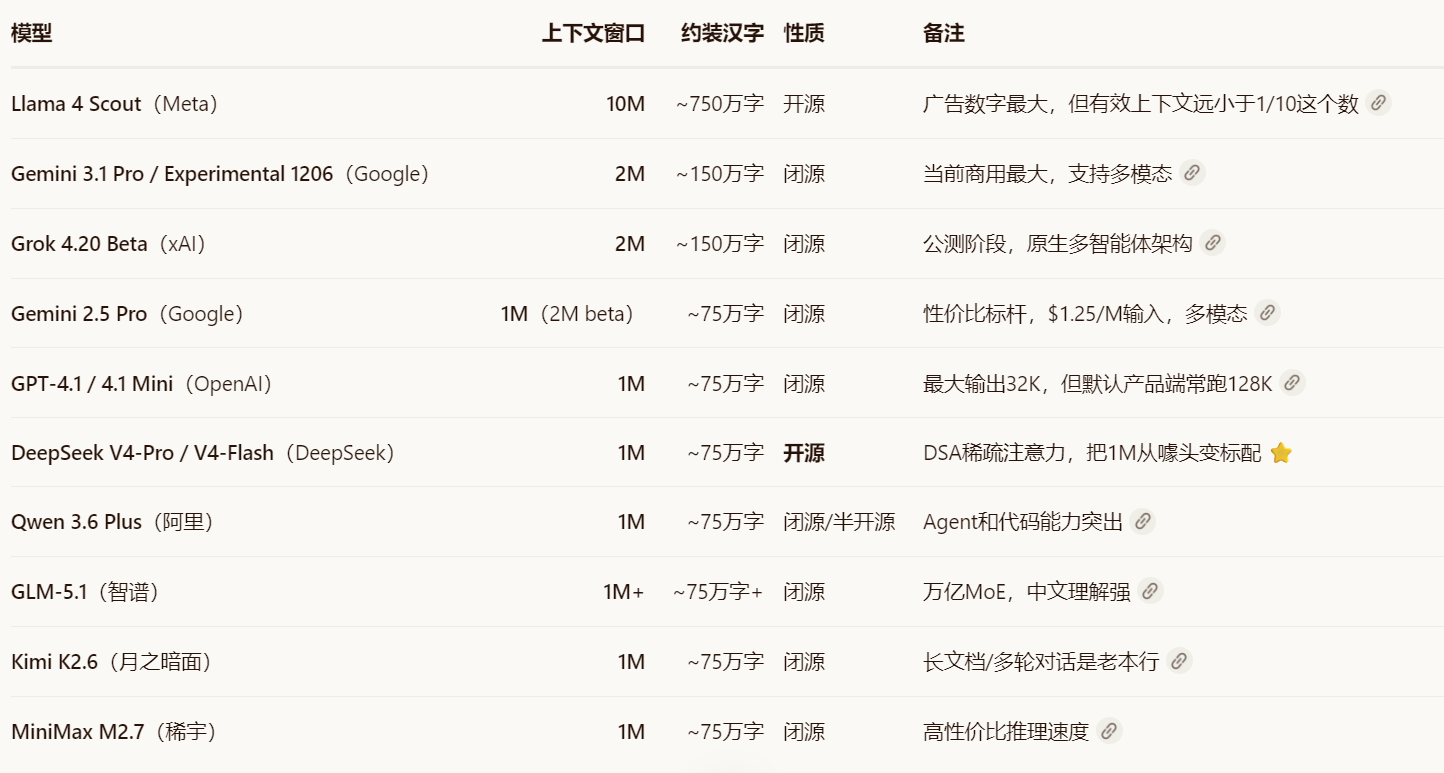
众所周知 标称上下文 ≤ Input + Output ≤ Context Window
|
词 |
本质 |
常见单位 |
备注 |
|---|---|---|---|
|
上下文 |
模型“能看到的总 token 预算”(一次前向传播的窗口容量) |
tokens(如 200K / 1M) |
这是容量上限,不等于“都能用得好” |
|
输入 Input |
你这次实际塞进去的内容(system prompt + 历史 + 附件/文件 + 当次问题)占掉的 token 数 |
tokens |
必须满足 Input ≤ Context Window(否则截断/报错) |
|
输出 Output |
模型这次最多生成多少 token(另一个独立上限,常见 4K/8K/16K/128K 不等) |
tokens |
输出和输入共享同一块窗口: Input + Output ≤ Context Window(很多实现里就是这样算) |
|
有效上下文 Effective Context |
在给定任务下,模型仍能稳定利用信息的位置深度/宽度(召回、引用、推理正确率不掉下去的那段) |
不是一个官方刻度,是一段“高质量区” |
总是 ≤ 标称上下文,而且随任务难度收缩 |
二,Claude Code 的上下文窗口
Claude Code 的默认上下文窗口为 200K tokens(MODEL_CONTEXT_WINDOW_DEFAULT = 200_000),但实际可用于对话的空间远小于此:
上下文窗口(200K)
├── 系统提示词(~15-25K,缓存后成本低)
├── 工具定义(~10-20K,含 MCP 工具)
├── 用户上下文(CLAUDE.md、git status 等)
├── 输出预留(maxOutputTokens)
│ ├── 默认上限:64K
│ ├── 实际默认:8K(slot-reservation 优化)
│ └── 触顶自动升级:一次 64K 重试
└── 剩余:对话历史空间(随对话增长)
输入 Input = 窗口大小 - min(maxOutputTokens, 20K),需要为压缩摘要需要预留输出空间。
有必要修改Claude Code 的默认上下文窗口大小吗?
有必要,而且基本属于"必改项"
Claude Code 的 200K上下文不是从模型动态探测出来的,而是客户端对"未知/第三方模型"的一个保守默认值。当你把后端换成了 DeepSeek V4(实际支持 1M tokens context window),不改的话就等于白白浪费掉 80% 的上下文能力——长代码库、大型重构、多文件联读这些 V4 最擅长的场景直接被腰斩。
"claude code默认上下文长度是2..." https://yb.tencent.com/s/pUPsnT59Nga0
修改方式: 直接在改模型名称为 deepseek-v4-pro[1m]
那么当超过Claude Code 的默认上下文窗口,系统会如下压缩呢?
上下文压缩机制实现:
自动压缩(Auto Compact)是什么?
简单来说,自动压缩就是 Claude Code 的"上下文垃圾回收"机制——当对话历史越攒越多、token 用量逼近模型上下文窗口上限时,系统自动把较早的历史消息打包 summarization(摘要化),用一个简短的摘要替掉大段原始对话,从而腾出 token 空间让对话能继续下去。
类比:就像你开了一个超长的微信聊天,聊了三万字后手机弹出"存储空间不足"——自动压缩相当于有个管家默默把前面聊过的内容总结成一段"会议纪要",放进聊天顶部,然后删掉原始流水账。
什么时候会自动压缩?
1. 核心阈值(以默认 200K 窗口为例)
|
到达的 token 水位 |
发生了什么 |
|---|---|
|
~167K( |
⚠️ Warning 闪烁——系统弹出建议压缩的提示,但还没动手 |
|
~180K(真正的触发线) |
🔄 自动压缩正式触发—— |
|
~197K( |
🚫 Blocking——新消息被阻止写入,强制要求压缩 |
关键常量在 src/services/compact/autoCompact.ts:
-
AUTOCOMPACT_BUFFER_TOKENS = 13,000 → 这是留给"执行压缩操作本身"的安全余量(压缩需要调 API 写摘要,也要消耗 token) -
WARNING_THRESHOLD_BUFFER_TOKENS = 20,000 → 触发点前 20K 就开始警告 -
MANUAL_COMPACT_BUFFER_TOKENS = 3,000 → 最后防线,再不压缩就彻底写不进去了
2. 触发前的"缓冲阶段"——Micro-Compact(微压缩)
并不是一到 180K 就立刻做全量压缩。在此之前,系统会先走一个更轻量的渐进策略:
Micro-Compact:只压缩旧的工具调用结果
-
对
FileRead、Bash、Grep、Glob、WebSearch、WebFetch、FileEdit、FileWrite这些工具产生的老旧结果,替换为简短占位符(如[image]、[document]或直接删减) -
图片/文档附件从消息中剥离
-
每次替换释放一些 tokens,可能把全量压缩推迟很久
只有 micro-compact 也顶不住了,才进入真正的全量压缩。
3. 全量压缩做了什么
一旦确定要全量压缩,compactConversation()的执行链大致是:
1. 执行 PreCompact hooks(允许用户注入自定义指令)
2. 先尝试轻量的 Session Memory 压缩
3. 不行的话 → 全量压缩:
- 剥离图片/文档附件 → 占位符
- 剥离 skill 附件(压缩后会重新注入)
- 通过 forked agent 发摘要请求(复用了主线程的 prompt cache!)
- 如果摘要请求本身爆了上下文 → truncateHeadForPTLRetry() 从最老消息开始删,重试最多3次
4. 压缩成功 → 重建上下文(摘要消息 + 最近5个文件重读 + 各种增量重新注入)
5. 更新缓存基线压缩后,原本几万 token 的历史对话变成一个不可见的 user 消息摘要(类似 <summary>之前我们做了…</summary>),后面跟着最近未压缩的部分继续对话。
什么情况下自动压缩「不会」触发?(逃逸条件)
shouldAutoCompact()有多个 gate:
|
条件 |
原因 |
|---|---|
|
当前查询本身就是 |
防递归死锁——压缩过程中不能再触发压缩 |
|
设置了 |
手动关闭 |
|
用户配置 |
用户选择 |
|
Context Collapse 模式激活 |
collapse 自己管上下文,不归 auto-compact 管 |
|
Reactive Compact 实验模式开启 |
实验路径接管 |
|
连续失败 ≥ 3 次( |
熔断(circuit breaker)——不再反复尝试 |
一句话总结
自动压缩 = 对话历史快把 200K 上下文窗口撑满时,Claude Code 自动把早期内容提炼成摘要、清理工具垃圾、剥离附件,把 token 账单"压扁",让对话能继续跑。 大约到 ~180K tokens(默认窗口下)正式触发,之前先靠 micro-compact 拖延一阵,之后走 forked agent 做全量摘要替换,全程还精心防止递归死锁和缓存失效。
如何进行压缩呢?
那么这个压缩只是简单的在当前会话调用模型总结吗?当前不是
那么如何进行压缩呢?就是上文提到的:
通过 forked agent 发摘要请求(复用了主线程的 prompt cache!)
如果摘要请求本身爆了上下文 → truncateHeadForPTLRetry() 从最老消息开始删,重试最多3次
Claude Code 在自动压缩时,会 fork 一个副 agent 来生成历史摘要,并复用主线程已经缓存好的上下文以节省成本;如果这个摘要请求因为上下文太长而失败,它会从最老的消息开始逐步删除内容并重试,最多 3 次,超过则放弃压缩,防止系统陷入无限递归或彻底不可用。
为什么要用 forked agent 发摘要请求?
自动压缩发生在 主对话正在进行中。
如果直接让“正在回答你问题的那个 Claude”同时去做“总结历史”,会有两个问题:
-
上下文污染:摘要任务会混入当前对话,影响主回答质量
-
死锁风险:摘要本身又要占 token,可能直接把主线程撑爆
所以做法是:
临时 fork 一个“副 agent”
副 agent 只读上下文,不负责回答你
专门用来生成「历史对话摘要」
摘要生成完 → 主线程把原历史替换成摘要 → 继续服务你
什么叫“复用了主线程的 prompt cache”?
这是 性能与成本优化 的关键点。
Prompt Cache 是什么?
Claude 系列模型支持 prompt caching:
-
相同的长上下文前缀(比如系统提示、已读文件、历史对话)
-
第一次送进去会被缓存
-
后续请求只要前缀一致,不用重新算,便宜且快
这里的复用意味着:
-
主线程已经把大量上下文加载进 cache 了
-
fork 出来的 agent 共享同一个 cache key
-
所以:
-
✅ 不用重新上传几十万 token
-
✅ 摘要请求极快、极便宜
-
✅ 不会因为“重复传上下文”而提前爆掉
-
一句话:用最小的代价,借主线程已经付过钱的上下文,去生成摘要。
如果“摘要请求本身”爆了上下文怎么办?
这是最讽刺也最危险的情况:
为了压缩上下文而发起的摘要请求,自己又超出了上下文窗口。
此时不能无限递归压缩(否则会死循环),于是有了这个逻辑:
1️⃣ truncateHeadForPTLRetry()是什么?
字面意思:
Truncate Head(砍头)+ PTL(Prompt Too Long)+ Retry(重试)
流程如下:
摘要请求返回 error:Prompt too long
↓
truncateHeadForPTLRetry()
↓
从【最老的 messages】开始删
(系统消息、早期对话、工具结果)
↓
再试一次摘要请求
↓
最多重试 3 次2️⃣ 具体删什么?
删除顺序是高度保守的:
|
删除优先级 |
内容 |
|---|---|
|
✅ 最先删 |
最早的用户/助手普通对话 |
|
✅ 其次 |
老旧的工具调用结果 |
|
⚠️ 尽量不删 |
系统 prompt、当前任务相关文件 |
|
❌ 绝不删 |
正在执行的 tool use 本身 |
目标只有一个:
👉 让摘要请求能成功返回,哪怕丢一点历史细节
3️⃣ 为什么要限制“最多 3 次”?
这是 熔断器(circuit breaker) 的一部分:
-
如果删了 3 轮还失败
-
说明上下文已经结构性不可压缩
-
此时:
-
放弃自动压缩
-
回退给主线程报错
-
由更高层策略接管(比如提示用户手动
/compact)
-
否则就会变成:
“压缩压缩压缩压缩…” → 无限递归 → 永远卡死
提示词里“说了什么” vs “没说什么”
压缩程度完全交给模型自行判断,提示词只规定“内容要覆盖什么”,不规定“要缩到多短”。
✅ 明确要求的(内容维度)
|
要求 |
示例 |
|---|---|
|
必须覆盖 9 个固定章节 |
Primary Request、Files、Errors、Pending Tasks… |
|
必须保留技术细节 |
file names、full code snippets、function signatures |
|
必须按时间顺序分析 |
Chronologically analyze each message |
|
必须包含 |
结构化输出 |
|
禁止调用任何工具 |
NO_TOOLS_PREAMBLE / TRAILER |
❌ 完全没有要求的(规模维度)
|
未限制项 |
说明 |
|---|---|
|
❌ 压缩比例 |
没有 50%、30%、10% 这类数字 |
|
❌ 最大 token 数 |
没有 |
|
❌ 最小信息损失 |
反而强调 thorough / precise / complete |
|
❌ 摘要长度上限 |
完全没提 |
👉 提示词的隐含目标是:信息保真 > 长度压缩。
具体的提示词如下

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)