从 DeepSeek 到 GLM:一次真实 AI 项目模型选型后,我为什么最终接入了蓝耘 MaaS 平台
今年 5 月,我给自己定了一个目标:做一个真正能落地的小型 AI 项目。
项目方向其实很简单。我想做一个内部文档问答系统。用户上传 PDF 文档之后,系统先完成向量检索,再调用大模型基于知识库内容回答问题,本质上就是现在比较常见的 RAG(Retrieval-Augmented Generation)方案。
一开始我对这个项目非常乐观。因为从技术角度看,逻辑并不复杂。LangChain 负责流程编排,向量数据库我直接选择 FAISS,前端用 Flask 简单写接口,整体开发路线我在第一周就已经规划好了。
但真正开始做之后,我很快发现,项目最大的麻烦根本不是代码,而是模型本身以及围绕模型产生的一系列部署问题。
第一阶段:模型选型,连续测试三套方案
项目正式开始时间是 5 月 3 日。
最开始,我给自己定了三个测试方案。
第一套方案是直接调用 DeepSeek 系列模型。
第二套方案是测试 GLM 系列模型。
第三套方案则是本地部署开源模型。
我的目标很明确,我需要找到一个适合中文文档理解,同时响应速度稳定,成本能够长期接受的方案。
为了尽可能减少主观判断,我专门写了一个简单测试脚本,对三个方案分别连续发起 50 次请求。
测试重点主要观察三个指标。
第一,请求平均响应时间。
第二,长文本上下文稳定性。
第三,连续调用过程中是否出现明显延迟波动。
测试代码大概是这样:
import time
for i in range(50):
start = time.time()
response = client.chat.completions.create(
model="glm-5.1",
messages=[
{"role":"user","content":"请根据上传文档总结主要内容"}
]
)
print("本次耗时:",time.time()-start)
连续测试两天之后,我简单整理了一份记录。
DeepSeek 模型在复杂推理任务中效果确实很好,但在连续请求过程中,响应时间波动比较明显。
本地部署虽然自由度最高,但硬件要求远比我想象中高。
我使用自己电脑上的 RTX4060(8GB 显存)尝试加载部分模型时,推理速度明显偏慢,某些模型甚至直接显存不足。
而 GLM 在中文语义理解和稳定性方面整体表现更均衡。
到这里,模型基本确定了。
但新的问题马上出现。
模型选好了,可项目到底跑在哪里?
第二阶段:我花了三天,结果一直在解决环境问题
一开始我并没有考虑使用云平台。
我习惯性认为,自己部署会更自由。
于是 5 月 8 日,我租了一台 GPU 服务器,准备手动部署推理环境。
结果真正开始之后,我才意识到自己太乐观了。
第一天,CUDA 版本不兼容。
第二天,Python 环境依赖冲突。
第三天,transformers 版本和推理框架不匹配。
后来好不容易把环境配置完成,真正加载模型之后又出现显存不足问题。
我现在还记得当时看着终端报错信息连续调试几个小时,却始终没有真正开始写业务逻辑。
那几天我第一次产生一种很强烈的感觉。
我明明是在做 AI 项目,但大部分时间居然都花在处理环境配置。
后来我粗略统计了一下。
真正花在业务开发上的时间不到总时间的 30%。
剩下大部分时间都浪费在部署环境和服务器配置上。
第三阶段:开始接触蓝耘,我第一次把精力重新放回开发本身
大概 5 月中旬,我偶然接触到蓝耘元生代平台。
最开始吸引我的,其实是它的 MaaS 平台。
原因很简单。
它把多个模型服务做了统一管理。
以前测试模型,我经常需要分别去不同平台申请 API,阅读不同接口文档,再针对不同格式做适配。
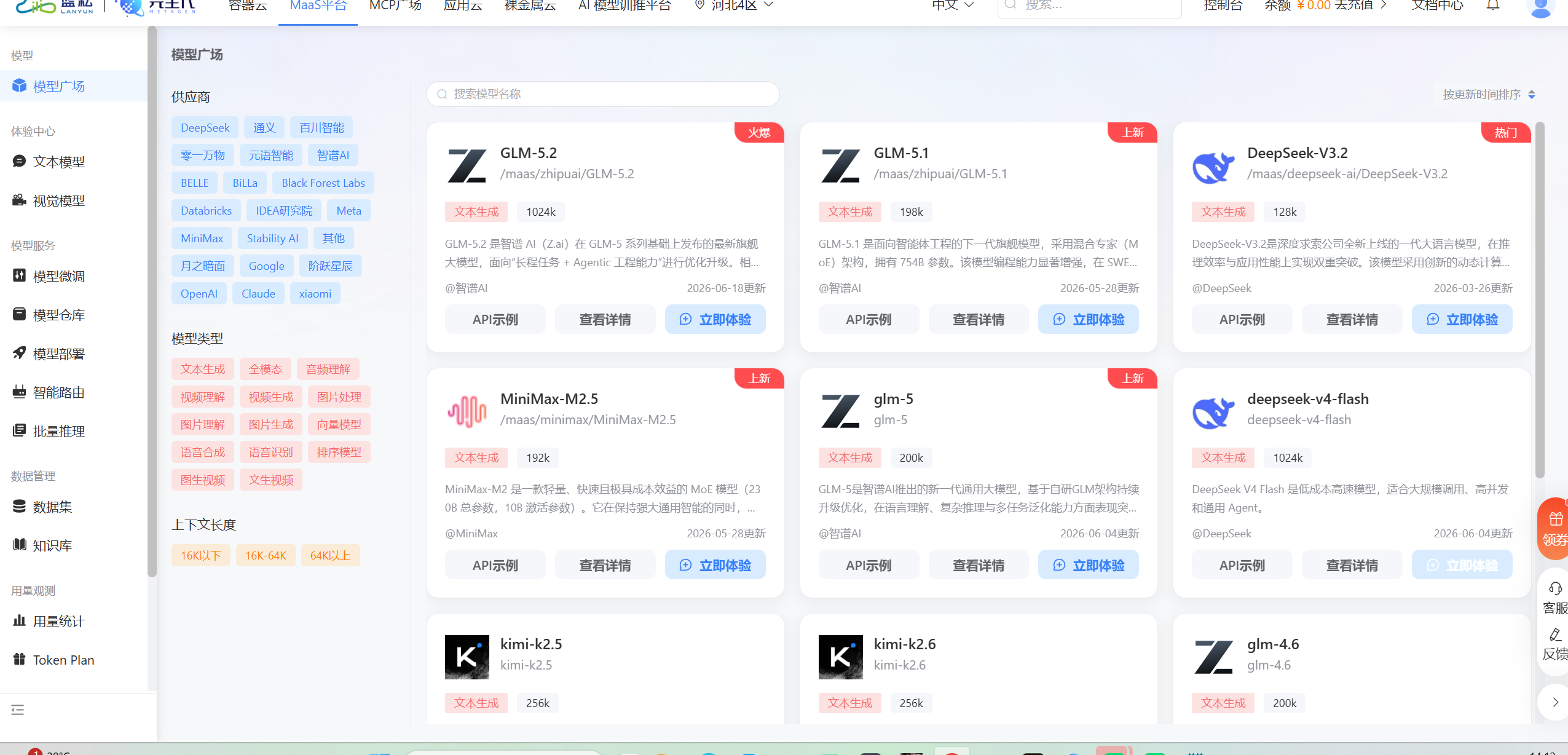
而蓝耘直接把多个主流模型集中在同一个控制台。
GLM-5.1、GLM-5.2、DeepSeek-V3.2、MiniMax 等模型都能直接查看。
对于我这种需要频繁做模型测试的人来说,这一点确实方便很多。
还有一点让我印象很深,反而不是模型本身,而是蓝耘提供的 API 文档完整度。
以前我接入一些模型平台时,经常会遇到文档不够详细的问题。比如请求参数说明过于简单,接口示例不完整,很多字段只能自己反复测试。尤其是流式输出(stream)、token 限制(max_tokens)、停止词(stop)这些参数,如果文档描述不清楚,调试过程会浪费很多时间。
而我在接入蓝耘 MaaS 平台时,第一感觉就是文档整理得非常规范。
这里以DeepSeek为例: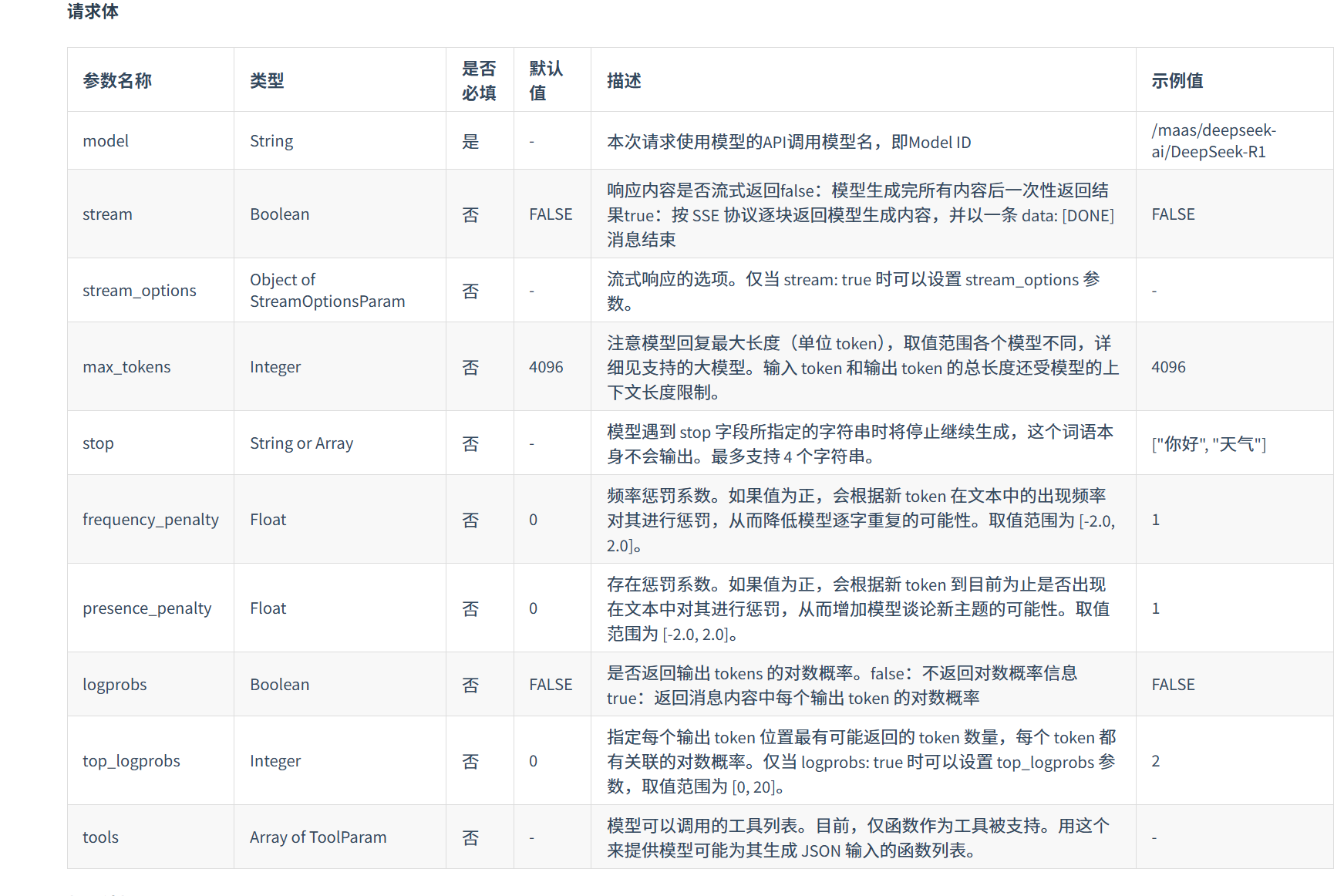

从接口地址https://maasapi.lanyun.net/v1/chat/completions,到 API Key 鉴权方式,再到请求体参数说明,几乎每个字段都有明确解释。像 stream 是否开启流式返回、frequency_penalty 重复惩罚参数、presence_penalty 主题惩罚参数,包括最终返回结果里的 token 用量统计,文档里都写得非常完整。
这一点对开发者来说其实很重要。
因为很多时候真正浪费时间的,并不是代码本身,而是反复查文档、猜接口字段含义,甚至通过报错信息去反推参数应该怎么传。
我当时按照官方文档里的 curl 示例,几乎第一次请求就成功返回结果。
curl https://maas-api.lanyun.net/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer API_KEY" \
-d '{
"model": "/maas/deepseek-ai/DeepSeek-R1",
"messages": [
{
"role":"user",
"content":"Hello!"
}
]
}'
以前接一些第三方接口,我经常花一两个小时排查参数问题。
但这次接入蓝耘,我基本没有遇到太多文档层面的阻碍。
这种体验其实让我意识到,一个成熟的平台提供的不只是模型能力,文档完整度本身也是开发效率的一部分。
真正接入之后,我做的第一件事依然是测试。
我用同样脚本连续发送 100 次请求。
整体体验最明显的感受就是稳定。
之前我最头疼的接口波动问题明显减少。
而且整个 API 调用方式基本兼容 OpenAI 标准接口。
我几乎没有额外修改代码。
以前处理接口适配要花半小时,现在直接替换 base_url 就能运行。
client = OpenAI(
api_key="your_key",
base_url="https://api.lanyun.net/v1"
)
GPU 按秒计费,第一次让我认真算了一次开发成本
后面我继续体验了蓝耘 GPU 算力资源。
这一点其实让我印象最深。
以前我租固定 GPU 服务器,一个月费用接近 800 元。
但问题是项目根本不是全天运行。
很多时候我一天真正测试只有两三个小时。
大量 GPU 时间实际上都在空闲。
蓝耘按秒计费的模式第一次让我认真计算成本。
我把连续两周测试时间简单统计了一下。
如果继续按照固定服务器租用方式,大约成本在 300 元左右。
而实际使用蓝耘 GPU 资源之后,同样测试周期下整体成本下降接近 30%。
对于个人开发者或者小团队来说,这种差距其实非常明显。
这次项目让我真正改变了一个看法
以前我一直觉得,大模型时代最重要的是模型能力。
谁模型参数更大,谁推理效果更强,谁就更有优势。
但这次项目之后,我第一次意识到自己之前忽略了一件事。
AI 项目真正影响开发效率的,往往并不是模型本身。
而是基础设施。
如果模型部署复杂、接口不稳定、GPU 成本太高,那么再好的模型也很难真正高效投入开发。
以前我总觉得自己在开发 AI 项目。
但回头看,我大量时间其实是在维护环境。
而蓝耘给我最大的改变,并不是某一个模型效果提升了多少。
而是它让我重新把精力放回“开发”本身。
最后一点真实感受
最近半年,大模型行业发展速度非常快。
几乎每个月都会出现新的模型、新的框架、新的部署方案。
以前开发者拼的是代码能力。
但现在我越来越觉得,未来开发者真正比拼的,很可能是使用基础设施的效率。
谁能够更快接入模型、更快完成部署、更低成本调用算力,谁就能更快把项目真正做出来。
至少对于我这次项目来说,蓝耘元生代平台确实帮我解决了之前最头疼的问题。
以前我总觉得自己在“折腾环境”。
而这一次,我终于感觉自己真正是在“做项目”。
这大概就是我这次最大的收获。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)