二、Claude Code 核心配置详解:settings.json 与三层记忆体系
前言
当你安装好 Claude Code,兴冲冲地打开它开始编程,可能会遇到这些问题:
- 每次新会话都要重新交代项目背景,AI 像失忆了一样
- AI 总是试图执行你不希望的操作,比如删除文件、安装依赖
- 不同项目的规则混在一起,写 React 项目时它用 Python 风格
这些问题的根源是:你还没有配置 Claude Code。
Anthropic 官方反复强调一个观点:模型能力是地板,配置质量才是天花板。花时间把配置做好,比追最新模型版本更有实际收益。
本文将深入讲解 Claude Code 的两大核心配置机制:settings.json 权限配置和三层记忆体系,帮你把 Claude Code 从"能用"变成"好用"。
1. settings.json — Claude Code 的"控制面板"
1.1 什么是 settings.json?
settings.json 是 Claude Code 的核心配置文件,控制着 AI 的行为边界、权限范围和功能开关。你可以把它理解为给 AI 定的"规矩"——哪些事情可以直接做,哪些事情需要问你,哪些事情绝对禁止。
1.2 配置文件的三个层级
Claude Code 设计了三级配置文件体系,从全局到项目级,层层覆盖:

↓ 优先级递增,后者覆盖前者同名配置
💡 最佳实践:通用的安全规则放在全局配置中,项目特定的配置放在项目级配置中。个人偏好(如你本地的测试环境地址)放在
.local.json中。
1.3 核心配置项详解
一个典型的 settings.json 长这样:
{
"permissions": {
"allow": [
"Read",
"Write",
"Bash(npm *)",
"Bash(git *)",
"Bash(node *)",
"Bash(python *)",
"Bash(npx *)"
],
"deny": [
"Bash(rm -rf *)",
"Bash(git push --force *)",
"Bash(sudo *)"
]
},
"model": "sonnet",
"autoCompactThreshold": 80
}
1.3.1 权限控制(permissions)
这是最重要的配置,决定了 AI 在执行操作时是否需要问你确认:
| 权限配置 | 说明 | 示例 |
|---|---|---|
allow |
白名单,AI 可直接执行,不再弹窗确认 | "Read" — 读取文件 |
deny |
黑名单,AI 绝对禁止执行 | "Bash(rm -rf *)" — 禁止递归删除 |
| 未配置的 | 每次执行前都会弹窗询问用户 | 默认行为 |
推荐的安全配置:
{
"permissions": {
"allow": [
"Read",
"Write",
"Edit",
"Bash(npm *)",
"Bash(npx *)",
"Bash(git status)",
"Bash(git diff *)",
"Bash(git log *)",
"Bash(git add *)",
"Bash(git commit *)",
"Bash(ls *)",
"Bash(cat *)",
"Bash(find *)",
"Bash(grep *)"
],
"deny": [
"Bash(rm -rf *)",
"Bash(git push --force *)",
"Bash(git reset --hard *)",
"Bash(sudo *)",
"Bash(curl * | sh)",
"Bash(wget * | sh)"
]
}
}
⚠️ 安全提醒:初学者建议保持默认设置(所有操作都需确认),等熟悉了 Claude Code 的行为模式后再逐步放开白名单。
1.3.2 模型选择(model)
{
"model": "sonnet"
}
Claude Code 支持通过别名或具体模型名切换模型:
| 模型别名 | 适用场景 | 特点 |
|---|---|---|
haiku |
简单补全、格式化、小修改 | 速度极快,成本最低 |
sonnet |
日常开发、功能实现(默认推荐) | 速度与质量最佳平衡 |
opus |
复杂架构设计、疑难 Bug、算法难题 | 推理能力最强,成本较高 |
模型选择的四种方式(优先级从高到低):
1. claude --model opus ← 启动参数(临时)
2. export ANTHROPIC_MODEL=opus ← 环境变量
3. settings.json → "model": "opus" ← 配置文件(推荐)
4. 会话中 /model 命令 ← 运行时切换
1.3.3 上下文压缩阈值(autoCompactThreshold)
{
"autoCompactThreshold": 80
}
当上下文使用量达到该百分比时,Claude Code 会自动压缩对话历史为摘要,腾出空间。默认值通常为 80,意味着上下文使用 80% 时自动压缩。
💡 建议设置为 60~70,避免等到上下文快满了才压缩——那时 AI 已经开始"遗忘"早期内容,回答质量下降。
1.3.4 其他常用配置
{
"env": {
"ANTHROPIC_BASE_URL": "https://api.example.com",
"ANTHROPIC_AUTH_TOKEN": "your-api-key",
"HTTP_PROXY": "http://127.0.0.1:7890",
"HTTPS_PROXY": "http://127.0.0.1:7890",
"CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC": "1"
},
"cleanupPeriodDays": 30,
"autoMemoryEnabled": true
}
| 配置项 | 说明 |
|---|---|
ANTHROPIC_BASE_URL |
API 代理地址(使用第三方服务时需要) |
ANTHROPIC_AUTH_TOKEN |
API 密钥 |
HTTP_PROXY / HTTPS_PROXY |
网络代理(国内用户通常需要) |
CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC |
设为 "1" 禁用自动更新、遥测等非必要流量 |
cleanupPeriodDays |
会话记录保留天数,默认 30 天 |
autoMemoryEnabled |
自动记忆开关,默认 true |
2. 三层记忆体系 — 让 AI 越用越懂你
Claude Code 的每个会话默认从全新的上下文窗口开始。为了实现跨会话的知识传递,官方设计了三层记忆体系,每一层解决不同层次的问题:
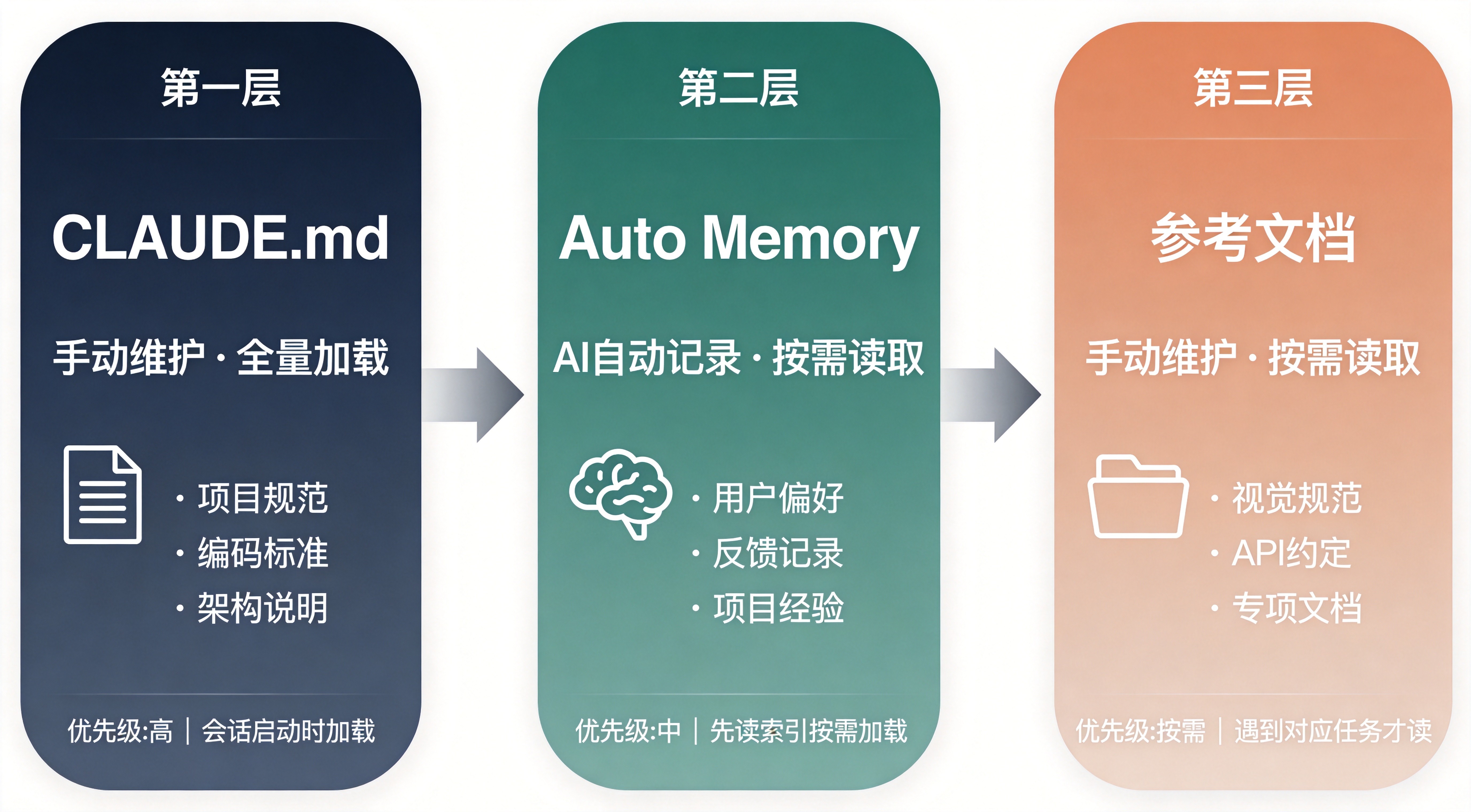
2.1 第一层:CLAUDE.md — 项目的"入职手册"
CLAUDE.md 是 Claude Code 中最重要的配置文件。它就像你给新来的实习生写的"项目入职手册"——告诉 AI 这个项目的背景、技术栈、编码规范和当前进度。
没有 CLAUDE.md:AI 每次开始工作都要花时间"重新认识"你的项目。
有了 CLAUDE.md:AI 一启动就知道项目的全部背景,效率大幅提升。
2.1.1 CLAUDE.md 的三级位置
Claude Code 为 CLAUDE.md 设计了三个层级,同时生效、不冲突:
┌─────────────────────────────────────────────────────────────┐
│ 全局级 ~/.claude/CLAUDE.md │
│ → 所有项目都会读取 │
│ → 适合写:个人偏好、回复语言、身份信息 │
│ 例如:"永远用中文回答"、"我是后端工程师" │
├─────────────────────────────────────────────────────────────┤
│ 项目级 项目根目录/CLAUDE.md │
│ → 仅当前项目生效 │
│ → 适合写:技术栈、架构、编码规范、进度(提交 Git 团队共享) │
├─────────────────────────────────────────────────────────────┤
│ 文件夹级 子目录/CLAUDE.md │
│ → 仅该子目录生效 │
│ → 适合写:模块专属约定 │
│ 例如:src/payment/CLAUDE.md 写支付模块踩过的坑 │
└─────────────────────────────────────────────────────────────┘
优先级:文件夹级 > 项目级 > 全局级
💡 还有两个特殊位置:
CLAUDE.local.md(项目根目录):个人项目偏好,不提交 Git- 组织级策略文件(
/Library/Application Support/ClaudeCode/CLAUDE.md):由 IT 统一管理,无法被个人排除
2.1.2 编写 CLAUDE.md
快速生成:在项目目录启动 Claude Code,输入 /init,AI 会自动扫描项目并生成一份 CLAUDE.md 初稿。
手动编写模板:
# 项目名称
## 项目概述
一句话描述这个项目做什么。
## 技术栈
- 前端:Next.js 14 + TypeScript + Tailwind CSS
- 后端:Next.js API Routes
- 数据库:Prisma + PostgreSQL
- 部署:Vercel
## 项目结构
src/
├── app/ # Next.js App Router 页面
├── components/ # React 组件
│ ├── ui/ # 通用 UI 组件
│ └── features/ # 业务组件
├── lib/ # 工具函数
├── prisma/ # 数据库 Schema
└── types/ # TypeScript 类型定义
## 编码规范
- 使用函数式组件 + React Hooks
- 组件文件使用 PascalCase(如 UserCard.tsx)
- 工具函数使用 camelCase
- 所有数据库操作通过 Prisma Client
- API 返回统一格式:{ success, data?, error? }
## 构建与测试
- 安装依赖:npm install
- 开发模式:npm run dev
- 构建:npm run build
- 测试:npm test
- 类型检查:npx tsc --noEmit
## 当前状态
- 用户认证模块已完成
- 商品列表 API 开发中
- 搜索功能待开发
## 注意事项
- .env 文件包含敏感信息,不要提交到 Git
- prisma/dev.db 是本地数据库,不提交
- 所有新功能先创建 Git 分支再开发
编写原则:
| 原则 | 说明 |
|---|---|
| 保持简洁 | 控制在 200 行以内,过长会消耗过多上下文 |
| 足够具体 | 写"使用 2 空格缩进"而不是"正确格式化代码" |
| 写明禁忌 | 把"不要做什么"也写清楚 |
| 保持更新 | 项目加了功能、踩了坑,及时同步更新 |
| 避免冲突 | 不同文件中的规则不要互相矛盾 |
进阶用法 — 导入外部文件:
CLAUDE.md 支持 @path/to/file 语法导入其他文件:
有关项目概述,请参阅 @README.md
有关可用命令,请参阅 @package.json
## 额外规范
- Git 工作流参见 @docs/git-workflow.md
- API 设计参见 @docs/api-design.md
2.1.3 使用 .claude/rules/ 组织规则
对于大型项目,可以将指令拆分为多个独立文件:
项目根目录/
└── .claude/
└── rules/
├── testing.md # 测试规范
├── api-design.md # API 设计规范
├── security.md # 安全规范
└── frontend/
├── components.md # 组件开发规范
└── styling.md # 样式规范
路径范围规则(按需加载,节省上下文):
---
paths:
- "src/api/**/*.ts"
---
# API 开发规则
- 所有 API 端点必须包括输入验证
- 使用标准错误响应格式
- 包含 OpenAPI 文档注释
这样配置的规则,只有在 Claude 处理 src/api/ 下的 TypeScript 文件时才会加载。
2.2 第二层:Auto Memory — AI 的"工作笔记本"
如果说 CLAUDE.md 是你主动立下的规矩,那 Auto Memory 就是 AI 在干活过程中默默记下的设计笔记。
2.2.1 工作原理
Auto Memory 让 Claude 从日常交互中自动积累知识,无需手动配置:
你与 Claude Code 对话
│
▼
┌──────────────────┐
│ 后台分析对话内容 │
│ 提取有价值的信息 │
└────────┬─────────┘
│
▼
┌─────────────────────────────────────┐
│ 自动记忆存储 │
│ │
│ ~/.claude/projects/<project>/ │
│ memory/ │
│ ├── MEMORY.md ← 核心索引 │
│ ├── debugging.md ← 调试笔记 │
│ ├── api-conventions.md ← API 决策 │
│ └── ... │
└─────────────────────────────────────┘
加载机制:
- 每次会话启动时,先加载
MEMORY.md的前 200 行(或 25KB)作为索引 - 遇到具体问题时,AI 按需读取对应的子文件获取详细信息
- 不会把所有记忆一次性全部塞进上下文
2.2.2 自动记忆记录什么?
| 类型 | 含义 | 示例 |
|---|---|---|
user |
关于你的信息 | 你是 Go 专家但不熟悉 React |
feedback |
你给过的工作指导 | “不要 mock 数据库”、“回复要简洁” |
project |
项目相关信息 | 进度、决策、技术选型 |
reference |
外部资源索引 | “设计文档在 docs/design.md” |
2.2.3 启用与管理
# 在 Claude Code 会话中输入
/memory
# 在菜单中选择"启用 Auto Memory"
也可以通过配置文件控制:
{
"autoMemoryEnabled": true
}
管理技巧:
- 用
Ctrl+O查看当前被加载的记忆内容 - 记错了直接跟 AI 说"忘掉刚才说的 XX",它会删除
- 用
/memory打开记忆文件夹,手动编辑或删除记忆文件 - 主动说"记住 XX",AI 会写入自动记忆
2.3 第三层:自建参考文档 — 专项知识按需加载
某些知识不适合全塞进 CLAUDE.md(太长、太专业),但 AI 需要时必须能查到。这就是第三层记忆的作用。
2.3.1 典型场景
docs/
├── brand-visual.md # 品牌视觉规范:颜色、字体、间距
├── copywriting-style.md # 产品文本风格:语调、术语表
└── api-conventions.md # API 约定:请求响应格式、错误码
在 CLAUDE.md 中加上指引:
## 外部参考文档
- 修改前端视觉、调颜色、调间距时 → 必读 `docs/brand-visual.md`
- 写产品文案、按钮文字、提示语时 → 必读 `docs/copywriting-style.md`
- 写 API、定义返回格式时 → 必读 `docs/api-conventions.md`
这样 AI 只在"需要的时候"才去读完整文档,既保证准确性,又不占多余上下文。
2.3.2 与 .claude/rules/ 的区别
| 特性 | 自建参考文档 | .claude/rules/ |
|---|---|---|
| 存放位置 | 项目任意目录 | .claude/rules/ 固定目录 |
| 加载方式 | 通过 CLAUDE.md 中的指引按需读取 | 可通过 paths 字段自动按需加载 |
| 适用场景 | 专项知识(设计规范、业务规则) | 编码规范、测试规范等技术规则 |
| 维护方式 | 手动维护 | 手动维护 |
3. 三层记忆的协作关系
三层记忆不是孤立的,它们在每次会话中协同工作:
┌─────────────────────────────────────────────────────────────┐
│ 会话启动 │
│ │ │
│ ┌────────────┼────────────────┐ │
│ ▼ ▼ ▼ │
│ 加载 CLAUDE.md 加载 MEMORY.md 等待按需调用 │
│ (全量注入) (前200行索引) (参考文档) │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌──────────────────────────────────────────┐ │
│ │ 合并到系统上下文 │ │
│ │ CLAUDE.md(明规则)+ 记忆索引(隐规则) │ │
│ └──────────────────────┬───────────────────┘ │
│ │ │
│ ▼ │
│ 开始会话交互 │
│ │ │
│ ┌───────────┼───────────┐ │
│ ▼ ▼ ▼ │
│ AI 执行任务 遇到专项知识 需要详细记忆 │
│ │ → 读参考文档 → 读记忆子文件 │
│ │ │ │ │
│ └───────────┼───────────┘ │
│ │ │
│ ▼ │
│ 会话结束 │
│ │ │
│ ▼ │
│ ┌───────────────────────┐ │
│ │ 后台分析本次对话 │ │
│ │ 提取有价值信息 │ │
│ │ 写入 Auto Memory │ │
│ └───────────────────────┘ │
└───────────────────────────────────────────────────────────────┘
一句话总结:
- 第一层 CLAUDE.md:你主动写的"明规则",全量加载,优先级最高
- 第二层 Auto Memory:AI 自己记的"隐规则",按需读取,越用越懂你
- 第三层参考文档:手动维护的专项知识,AI 遇到对应任务才读
本质认知:Agent 的所有"记忆",本质上都是在合适的时候向大模型注入压缩过的上下文。三层记忆是组织这些上下文的分层策略,核心目标是在有限的上下文窗口中,最大化注入有价值的信息。
4. 实战配置清单
4.1 新手起步配置
// ~/.claude/settings.json
{
"permissions": {
"allow": ["Read"],
"deny": [
"Bash(rm -rf *)",
"Bash(sudo *)"
]
},
"model": "sonnet"
}
先保持最小权限,所有写操作和命令执行都需确认,逐步熟悉后再放开。
4.2 团队项目推荐配置
// 项目/.claude/settings.json
{
"permissions": {
"allow": [
"Read",
"Write",
"Edit",
"Bash(npm *)",
"Bash(git status)",
"Bash(git diff *)",
"Bash(git add *)",
"Bash(git commit *)",
"Bash(npx tsc --noEmit)",
"Bash(npm test)"
],
"deny": [
"Bash(rm -rf *)",
"Bash(git push --force *)",
"Bash(git reset --hard *)",
"Bash(sudo *)"
]
},
"model": "sonnet",
"autoCompactThreshold": 70
}
4.3 快速配置流程
1. 安装 Claude Code
npm install -g @anthropic-ai/claude-code
2. 全局配置
vim ~/.claude/settings.json ← 设置基础权限和模型
3. 进入项目目录
cd your-project
4. 生成项目说明
claude
> /init ← 自动生成 CLAUDE.md
5. 开启自动记忆
> /memory ← 选择"启用 Auto Memory"
6. 编辑全局偏好
> /memory ← 选择"全局 CLAUDE.md"
写入个人偏好(如"永远用中文回答")
7. 开始使用
直接描述需求即可
5. 常见问题
CLAUDE.md 写了但 AI 不遵守?
- 运行
/memory确认文件已被正确加载 - 检查文件是否在正确位置
- 指令写得更具体:“使用 2 空格缩进” 而非 “正确格式化”
- 检查是否有跨文件的冲突规则
上下文用完了怎么办?
| 命令 | 效果 | 适用时机 |
|---|---|---|
/compact |
压缩历史为摘要,保留关键决策 | 同一任务对话过长,还要继续 |
/clear |
彻底清空,等于重开 | 一个任务结束,开始全新任务 |
/context |
查看上下文占比和各部分占用 | 诊断什么在消耗上下文 |
💡 心法:宁可多
/clear几次重新介绍背景,也不要一直聊下去。每次/clear都是给 AI 一次重新聚焦的机会。
自动记忆记错了怎么办?
直接告诉 AI “忘掉 XX”,或者用 /memory 打开记忆文件夹手动删除。所有记忆文件都是纯文本 Markdown,可以直接编辑。
6. 总结
Claude Code 的配置体系可以概括为两个核心机制:
| 机制 | 解决的问题 | 核心文件 |
|---|---|---|
| settings.json | “AI 能做什么、不能做什么” | ~/.claude/settings.json |
| 三层记忆 | “AI 知道什么、该记住什么” | CLAUDE.md + Auto Memory + 参考文档 |
settings.json 控制行为边界——权限白名单让日常操作更顺畅,权限黑名单防止危险操作,模型选择平衡性能与成本。
三层记忆 管理知识传递——第一层 CLAUDE.md 是全量注入的明规则,第二层 Auto Memory 是按需读取的隐规则,第三层参考文档是专项知识的按需加载。三者配合,让 AI 越用越懂你。
配置不是一次性的工作,而是持续优化的过程。随着你对 Claude Code 的使用越来越深入,不断调整权限、完善 CLAUDE.md、校准自动记忆,AI 会逐渐从一个"聪明的陌生人"变成"真正懂你的搭档"。
参考资源
官方文档
| 资源 | 链接 | 说明 |
|---|---|---|
| Claude Code 官方文档 | docs.anthropic.com/en/docs/claude-code | 完整使用文档 |
| Claude Code 记忆系统 | docs.anthropic.com/en/docs/claude-code/memory | 记忆系统官方指南 |
| Claude Code 权限管理 | docs.anthropic.com/en/docs/claude-code/permissions | 权限与安全配置 |
| Anthropic API 文档 | docs.anthropic.com | API 参考与模型说明 |
社区资源
| 资源 | 链接 | 说明 |
|---|---|---|
| Karpathy 的 Claude Skills | github.com/multica-ai/andrej-karpathy-skills | Karpathy 分享的几百行通用规则 |

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)