2026年使用 Gemini 进行网页抓取:Python 实战指南
网页抓取(Web Scraping)的技术范式较之过去已发生了根本性的改变。传统脚本由于过度依赖精确的 HTML 标签而显得十分脆弱,前端开发人员稍稍调整一下页面布局,爬虫就会瞬间崩溃。
而 Gemini 却非常擅长在杂乱无章的网页结构中梳理信息。通过将页面内容直接输入给大模型,您可以精准提取所需数据,再也无需时刻盯着那些脆弱不堪的代码。因此,构建现代化的网页抓取流水线正带来一种完全不同的开发体验。
一、为什么选择 Gemini 进行网页抓取?
在传统模式下,提取数据细节意味着必须要在源码中搜寻精确的 CSS 选择器。一旦目标网站更新了页面模版,爬虫脚本要么直接报错,要么就会抓取到完全错误的数据。
大语言模型(LLM)的出现改变了这一局面,它们能够基于上下文来理解并处理内容。您只需在提示词中索要价格或作者信息,即便底层的 HTML 结构已经改得面目全非,大模型依然能够准确地将它们找出来。
Gemini 的网页抓取技术可以轻松处理杂乱且无结构的数据。假设您正在解析一个房地产网站,房产描述信息在某一个页面上可能整齐地罗列在表格里,包含“3 室 2 卫”,而在另一个页面上则被深埋在一段长篇大论的文本中。
传统的脚本遇到这种不一致的情况往往会直接报错,而 Gemini 却能抽丝剥茧般地提取出核心事实并将其格式化。打造一套稳健、免维护的网页抓取流水线,核心正是依赖这种强大的自适应能力。
二、URL 上下文工具:让 Gemini 自动抓取网页
为了大幅简化数据提取的流程,谷歌推出了 URL 上下文(URL Context)工具。您可以直接在提示词中传入 URL,API 会首先检查谷歌内部的索引缓存来获取内容;如果该页面是全新的,它会自动平滑切换到实时抓取模式。这一机制让您无需再编写任何自定义的网络请求代码。
您只需在脚本中初始化该工具,并告知模型需要寻找的内容即可。在单次请求中,您最多可以传入 20 个 URL。不过,该工具也有其局限性:URL 上下文工具无法访问付费墙内、需要登录的页面,或者是处于私有网络中的任何内容。
如果目标网站超出了此类公共页面的边界,API 会在返回的响应元数据(Metadata)中报错提示检索失败。在构建可靠的自动化网页抓取流水线时,理解这些限制条件至关重要。
三、何时仍需手动抓取 HTML
在某些特定的场景下,URL 上下文工具可能无法采集到所需的信息。例如,那些充斥着大量动态内容、必须通过滚动或点击才能加载的网站,对于简单的抓取工具往往只会返回一个空白页面。同样,那些隐藏在身份验证之后,或部署了强力反爬虫防护(如 Cloudflare)的网站,也会瞬间封禁 API 的原生抓取请求。
在这种情况下,通过 Playwright 或 httpx 等库亲自处理网络请求可以为您夺回绝对的控制权。您可以借此注入自定义的请求头、管理登录会话,并轮换 IP 地址以绕过针对数据中心的封禁。
为了防止被秒封,将您的网络请求路由至住宅代理(Residential Proxies)正成为一项刚需。在利用 Gemini 进行网页抓取的业务中,牢牢掌控网络连接是克敌制胜、啃下高防护目标的唯一途径。
四、项目初始化:Python 虚拟环境
配置一个隔离的虚拟环境可以有效避免版本冲突,保持依赖项的纯净。请创建一个新目录,切换进去并初始化您的工作空间:
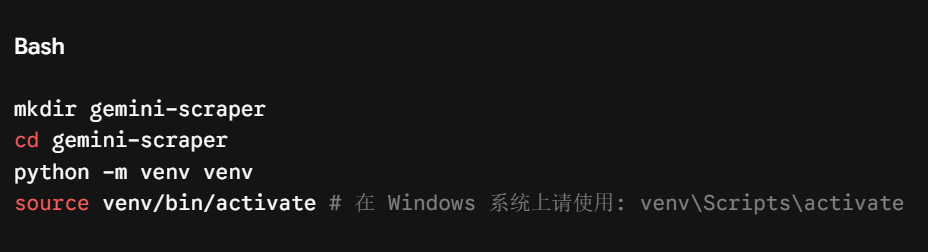
接下来,创建一个 requirements.txt 文件来声明核心库:用于调用 API 的 google-genai,以及用于抓取和解析 HTML 的 requests 和 beautifulsoup4。运行 pip install -r requirements.txt 即可下载安装所有依赖。
五、配置 Gemini:API 密钥、模型与客户端初始化
获取您的 Google Gemini API 密钥,并将其安全地存储为环境变量。虽然重新生成一个密钥只需几秒钟,但保护好您的 Gemini API 密钥、使其不暴露在公共版本控制系统中,是一个必须养成的硬性安全习惯。
接着,选择合适的 Gemini 模型:对于常规的基础网页抓取任务,Gemini 3 Flash 凭借其极高的速度与性价比成为了不二之选;而 Pro 级别的模型,则更适合用于对规模庞大、极其复杂的原始 HTML 结构进行深度逻辑推理。
请牢记,每个级别的模型都有其速率限制(Rate Limits)。当您准备扩大 HTTP 请求规模时,在代码中引入带有指数退避重试机制(Exponential Backoff Retries)的错误处理方案,能为您省去大量的烦恼。
六、抓取与预处理网页 HTML
如果您选择自己来处理网络连接,requests 库便是标准的开发工具。首先,运行以下命令确保已安装所需的库:

然后,您可以向目标 URL 发送 HTTP 请求并获取网页源码:
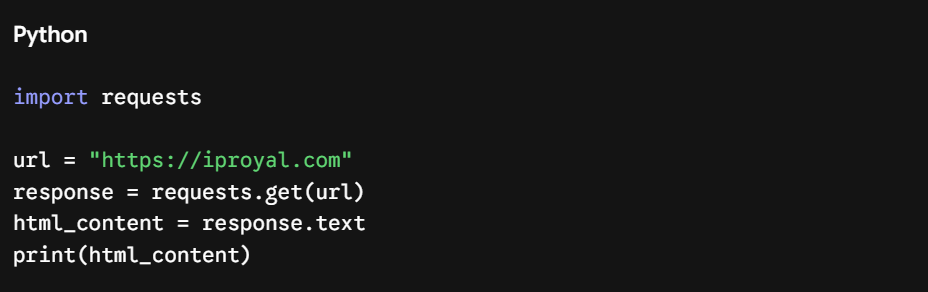
然而,将动辄数万行的原始 HTML 文本直接塞给 Gemini API 会在转瞬间烧光您的 Token 额度。利用 BeautifulSoup 剔除其中的 <script> 标签、<style> 样式块以及导航栏等样板内容,能够有效地帮助模型聚焦核心文本。
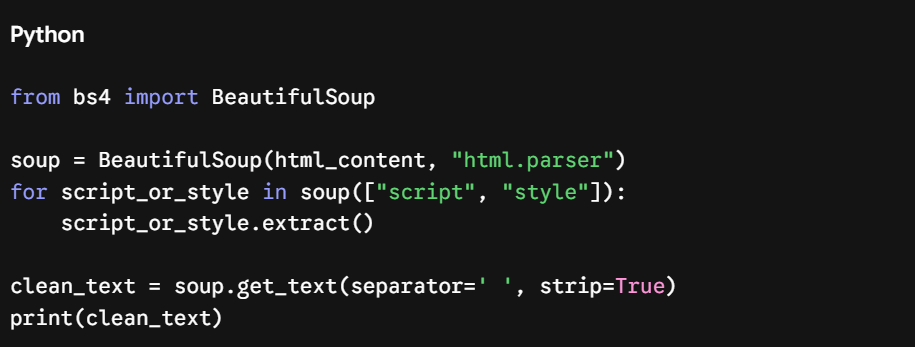
若想追求更高的效率,您还可以在将清洗后的 HTML 送入 API 之前将其转换为 Markdown 格式;这样能极致地压缩传输体积,仅保留最具语义价值的核心内容。
七、利用 Gemini 提取结构化数据
将无结构的数据转化为符合预期、格式整齐的报文,正是人工智能的拿手好戏。在现代的 Gemini API 中,您大可不必在提示词里苦苦哀求它给您返回一个 JSON 文件,而是可以直接在配置项中传入一个严格的 Schema(例如 Pydantic 模型),API 层面会百分之百保证输出完美符合结构的数据。
同时,将模型的温度(Temperature)调低,可以有效防止模型对您抓取到的数据进行“艺术创作”。请抛弃那些在提示词里要求输出 Markdown 格式的 JSON、然后再手动解析字符串的过时偏方。通过强制执行原生 Schema 校验,Gemini 每次都能稳定可靠地为您返回开箱即用的干净 JSON 数据。
八、保存与复用抓取到的数据
在存储方面,将这些结构化的输出直接转储到本地的 JSON 文件中,通常就足以应对即时的数据分析,或者也可以直接将其加载到 Pandas DataFrame 中进行进一步的数据清洗。随着项目规模的扩大,这些格式完美的 JSON 对象还可以通过流水线直接输送到您的数据库中。
九、局限性、反爬防御与成本
AI 抓取技术并不能自动瓦解网络层面的反爬防御。无论您使用的是原生的 URL 上下文工具还是自定义的爬虫脚本,一旦撞上验证码(CAPTCHA),或是因使用了已知的云服务商 IP 而触发了行为防火墙,您的抓取请求在送达 Gemini 之前就会被瞬间拦截。
当频繁遭遇封禁时,您需要更换不同的 IP 地址——此时可以借由住宅代理来确保每次请求都拥有全新的 IP。将您的网络流量路由至真实的住宅网络连接中,能让您的爬虫看起来就像是一个坐在家里上网的普通用户。这是在大规模采集数据时,避免被网站永久拉黑唯一可靠的方案。
在财务开销方面,成本与您的 Token 消耗量直接挂钩。如果盲目地去抓取整个网站的历年归档,费用很快就会飙升;这正是为什么在前文中反复强调“HTML 数据清洗”至关重要的原因,它是维持整个抓取流水线盈利的关键。
当然,您也可以将这些模型接入检索增强生成(RAG)流水线中,将抓取到的数据直接喂给企业内部的知识库。与运行那些随时可能崩溃的传统脆弱脚本相比,这种极高的灵活性完全对得起它按 Token 计费的开销。在推进大规模网页抓取业务时,您需要在这两者之间做好精妙的成本平衡。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)