MicroPython对接大模型:uopenai + 火山方舟实现文字聊天和图片理解
引言
openai 是 OpenAI 官方推出的 Python 客户端库,它封装了 OpenAI 系列模型(如 GPT、DALL-E、Whisper 等)的 RESTful API 调用,让开发者无需手动处理 HTTP 请求、鉴权和数据解析,就能快速将 AI 能力集成到 Python 应用中。
它的核心能力覆盖了:
- 文本生成:基于 GPT 系列模型实现对话、代码生成、内容创作与智能问答;
- 图像生成与理解:通过 DALL-E 生成图像,或结合 GPT-4V 实现视觉问答;
- 语音处理:Whisper 模型实现语音转文本,以及文本转语音;
- 向量嵌入:将文本转换为向量表示,支撑语义搜索、推荐系统等场景;
- 模型微调与助手应用:支持自定义模型训练,以及构建具备上下文记忆、工具调用能力的智能助手。
开发者只需几行代码就能调用 GPT、DeepSeek、豆包等模型完成文字对话、视觉理解、语音合成、图片生成等任务,由于接口已成为行业标准,DeepSeek、字节豆包、Moonshot、智谱等国内厂商均提供 OpenAI 兼容接口,只需替换 base_url 和 model 即可无缝切换:
from openai import OpenAI |
client = OpenAI(api_key="sk-...", base_url="https://api.openai.com/v1") |
resp = client.chat.completions.create( |
model="gpt-4o", |
messages=[{"role": "user", "content": "Hello!"}], |
) |
print(resp.choices[0].message.content) |
在 PC 或服务器端,openai 库依赖完善的 Python 标准库、充足的内存与算力,能轻松处理同步 / 异步请求、流式响应和复杂数据解析。但当我们想把 AI 能力带到嵌入式设备时,这些优势反而成了 “负担”。
在树莓派 Pico W、ESP32 这类资源受限的嵌入式设备上,运行 MicroPython 时,直接使用 PC 端的 openai 库几乎不可能:
- 内存极度受限:Pico 2W 可用堆内存约 150 KB,PC 端 openai SDK 依赖 httpx、pydantic 等重型库,完全无法运行;
- 无标准 HTTPS 客户端:需要基于原生 socket + ssl 手动实现 TLS 握手、HTTP/1.1 请求构造和响应解析。
- 异步模型不同:MicroPython 的
asyncio不支持asyncio.wait_for()超时,socket必须设为非阻塞模式,所有 I/O 循环需手动插入await asyncio.sleep_ms()让出 CPU。 - 大
payload发送问题:非阻塞socket缓冲区有限,发送base64图片等大JSON body时必须分块写入,否则数据截断导致服务端解析失败。 - 无 file 对象:PC 端通过
file=open(...)上传音频文件,MicroPython不支持此模式,需改用文件路径字符串流式上传。
uopenai 是专为 MicroPython 设计的轻量级 OpenAI 兼容异步客户端,依赖同样自研的 aiohttps 库,无任何其他外部依赖。它的设计目标是:在 Pico 2W 等嵌入式设备上,用与 PC 端 openai SDK 几乎相同的接口,调用 OpenAI 兼容的云端 LLM API:
# 与 PC 端几乎一致的写法 |
from uopenai import OpenAI |
client = OpenAI(api_key="...", base_url="https://ark.cn-beijing.volces.com/api/v3") |
resp = await client.chat.completions.create( |
model="deepseek-v3-2-251201", |
messages=[{"role": "user", "content": "你好!"}], |
) |
print(resp.choices[0].message.content) |
二、uopenai 接口说明
2.1 基本介绍
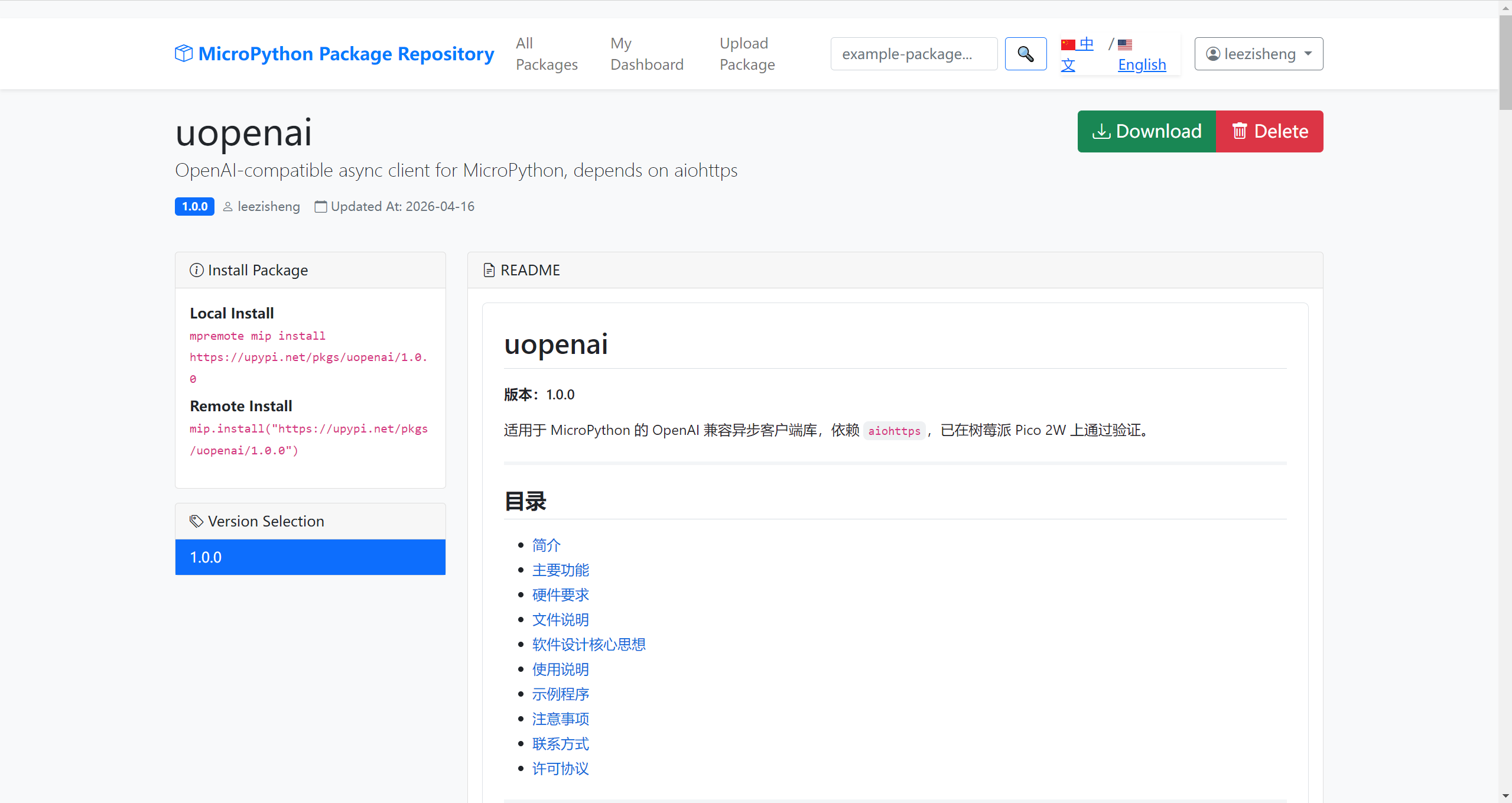
库的地址在:uopenai
uopenai 是一个专为 MicroPython 设计的轻量级 OpenAI 兼容异步客户端库。它基于 aiohttps 实现,无其他外部依赖,支持非流式和流式(SSE)文字对话、视觉模型图片输入、base64 图片编码,特别适合内存受限的嵌入式设备(如 Pico 2W)与 OpenAI 兼容云端 API(DeepSeek、豆包、Moonshot 等)的对接。
主要功能包括:
- 文字对话(非流式):
chat.completions.create()返回完整响应对象,含id、model、usage、choices - 文字对话(流式 SSE):
stream=True返回aiohttps.Response,通过iter_lines()逐块读取 - 视觉模型:支持
content为列表格式,传入image_url(base64 data URI) - 图片编码:
OpenAI.encode_image(filepath)静态方法,将本地图片编码为 base64 字符串 - 请求超时:
create(timeout_ms=30000)支持自定义超时,避免服务端无响应时永久阻塞 - 接口兼容:与 PC 端
openaiSDK 保持最大接口兼容,base_url可替换为任意 OpenAI 兼容服务
内含文件包括:
uopenai/ |
├── code/ |
│ ├── uopenai.py # 驱动核心实现 |
│ ├── main.py # 使用示例 / 测试代码 |
│ └── test_4kb.jpg # 视觉测试用图(3516 字节,128x128) |
├── package.json # mip 包配置(含 aiohttps 依赖) |
├── README.md # 使用文档 |
└── LICENSE # MIT 开源协议 |
2.2 软件设计核心思想
与 PC 端 openai SDK 保持最大接口兼容:
# PC 端 openai SDK |
from openai import OpenAI |
client = OpenAI(api_key="...", base_url="...") |
resp = client.chat.completions.create(model="...", messages=[...]) |
# uopenai(MicroPython) |
from uopenai import OpenAI |
client = OpenAI(api_key="...", base_url="...") |
resp = await client.chat.completions.create(model="...", messages=[...]) |
唯一区别:所有 create() 方法均为 async,需在 asyncio 事件循环中调用。
流式 SSE 读取
stream=True 时直接返回底层 aiohttps.Response,调用方通过 iter_lines() 逐行读取 SSE 数据,内存峰值仅为单行大小:
stream_resp = await client.chat.completions.create( |
model="...", messages=[...], stream=True |
) |
async for line in stream_resp.iter_lines(): |
if line.startswith(b"data: ") and line != b"data: [DONE]": |
delta = json.loads(line[6:])["choices"][0]["delta"] |
print(delta.get("content", ""), end="") |
视觉模型与 base64 限制
encode_image() 将整个图片文件读入内存后编码,适合小图片(< 6 KB 原图)。Pico 2W 可用 RAM 约 150 KB,base64 编码后体积约为原图的 1.37 倍,总 JSON payload 需控制在 12 KB 以内以确保服务端正常响应。
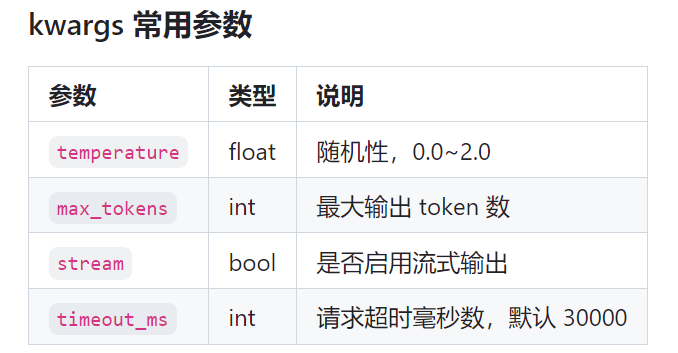
2.3 API 速查和常用参数

2.4 使用注意
- 依赖 aiohttps:使用前必须先将
aiohttps.py(v1.1.3+)上传到设备根目录,mip 安装时会自动处理依赖。 - 所有 create() 均为 async:必须在
asyncio事件循环中调用,不支持同步调用。 - 不支持
file=open(...)传参:MicroPython 无标准file对象,改用filepath=字符串(audio.transcriptions待实现)。 - 视觉模型图片大小限制:
encode_image()将整个文件读入内存,建议原图 < 6 KB(base64 后 < 8 KB),总 JSON payload 控制在 12 KB 以内。超出可能导致服务端拒绝或响应超时。 - 超时设置:默认
timeout_ms=30000(30 秒)。视觉模型响应较慢,建议设置timeout_ms=60000。 - thinking 模型兼容:部分模型(如 doubao-seed)返回
"content": null,库已自动处理为空字符串。 - 待实现接口:
audio.transcriptions.create()、audio.speech.create()、images.generations.create()当前为 TODO,调用后返回None。嵌入式 TTS/ASR 推荐使用 WebSocket 流式连接实现,参考xfyun_tts/xfyun_asr。
三、文字聊天和图片理解测试
这里,我们首先需要在火山引擎上创建 API Key,这是调用大模型的核心凭证:
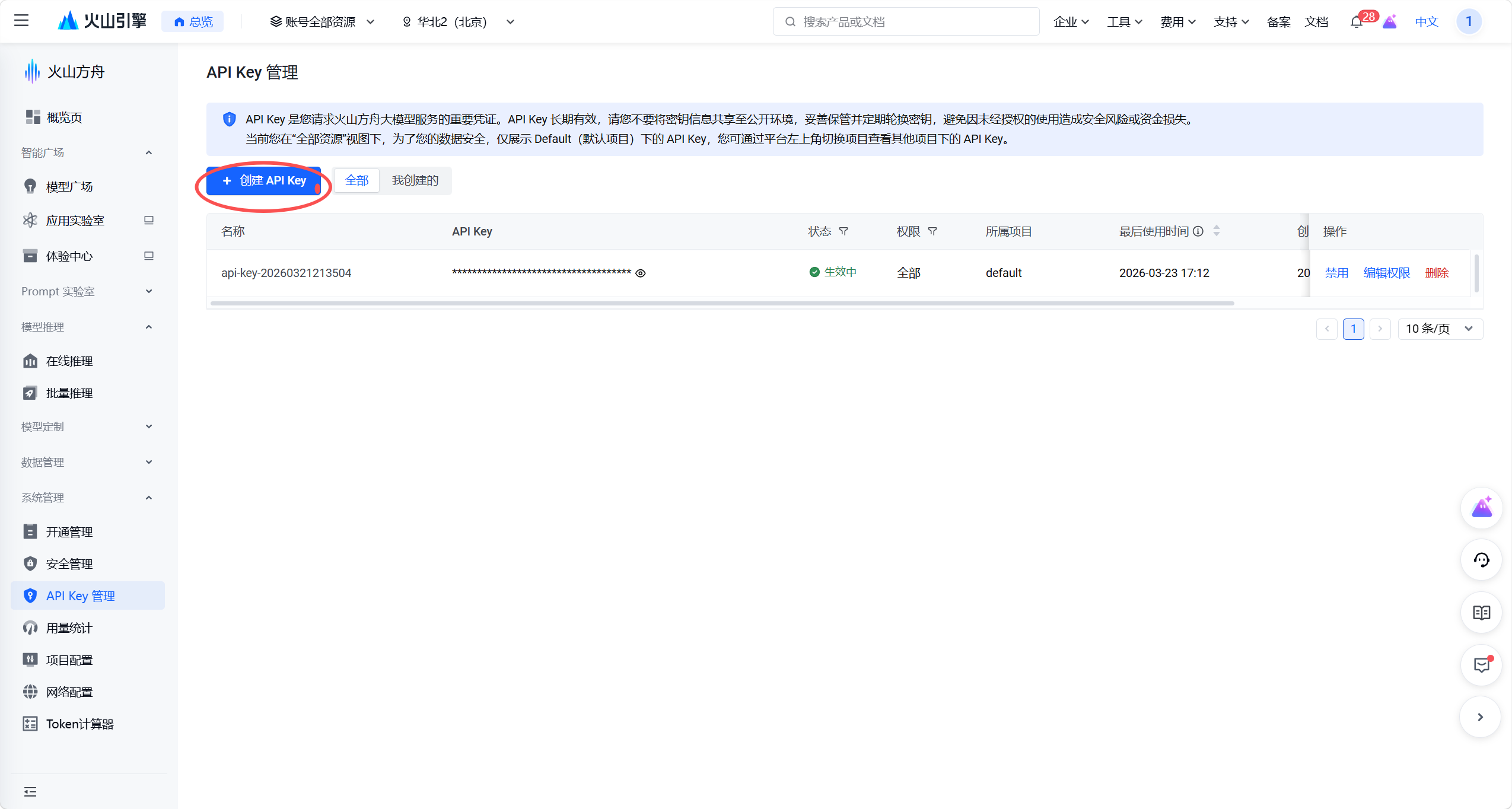
登录火山方舟平台后,在左侧导航栏找到并进入「API Key 管理」页面,这里集中管理所有大模型服务的访问密钥,准备开启密钥创建流程。
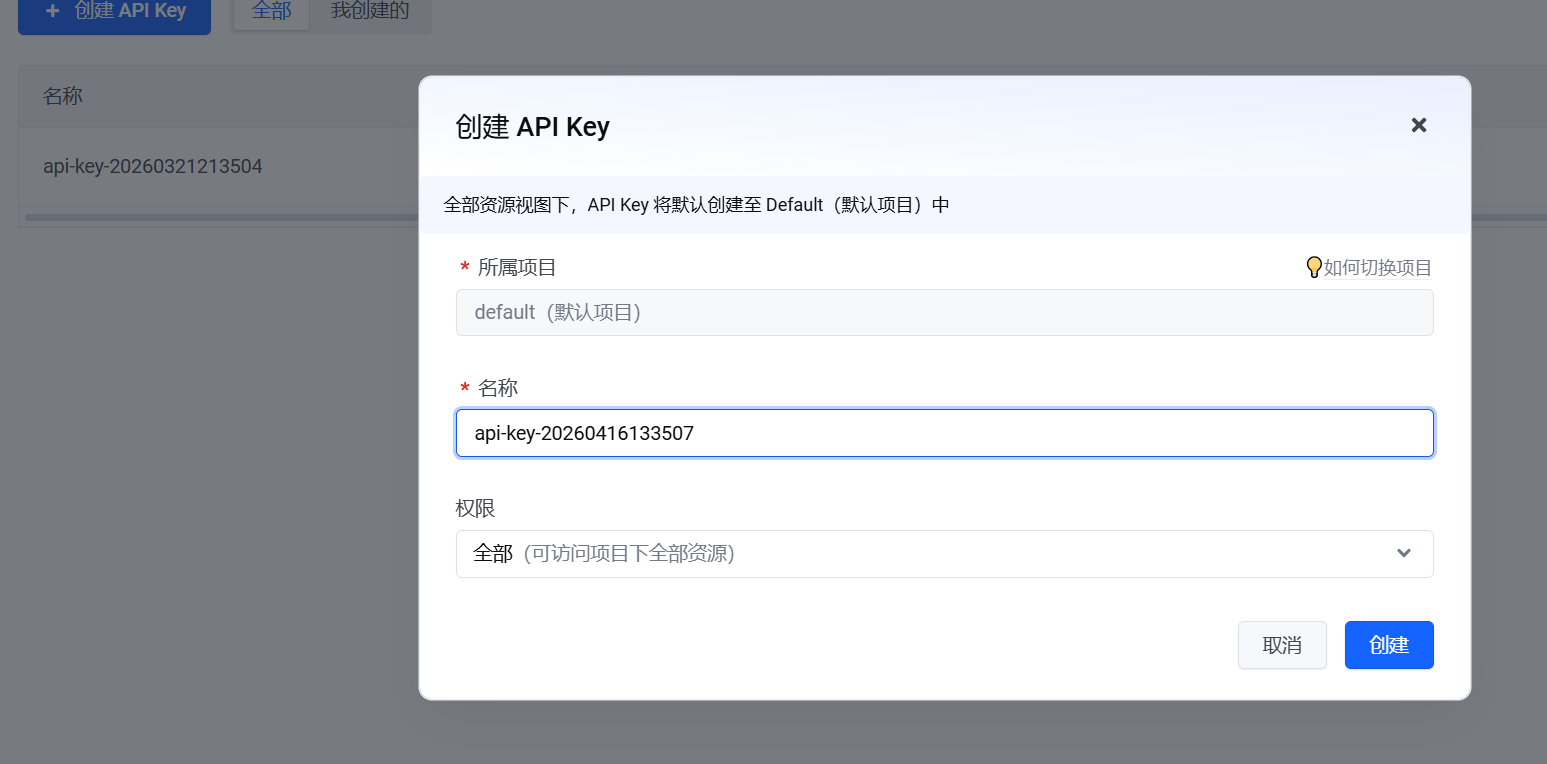
在弹出的「创建 API Key」窗口中,所属项目默认选择 default(默认项目),名称可自定义(也可使用自动生成的时间戳命名),权限保持「全部(可访问项目下全部资源)」,确认配置后点击「创建」。
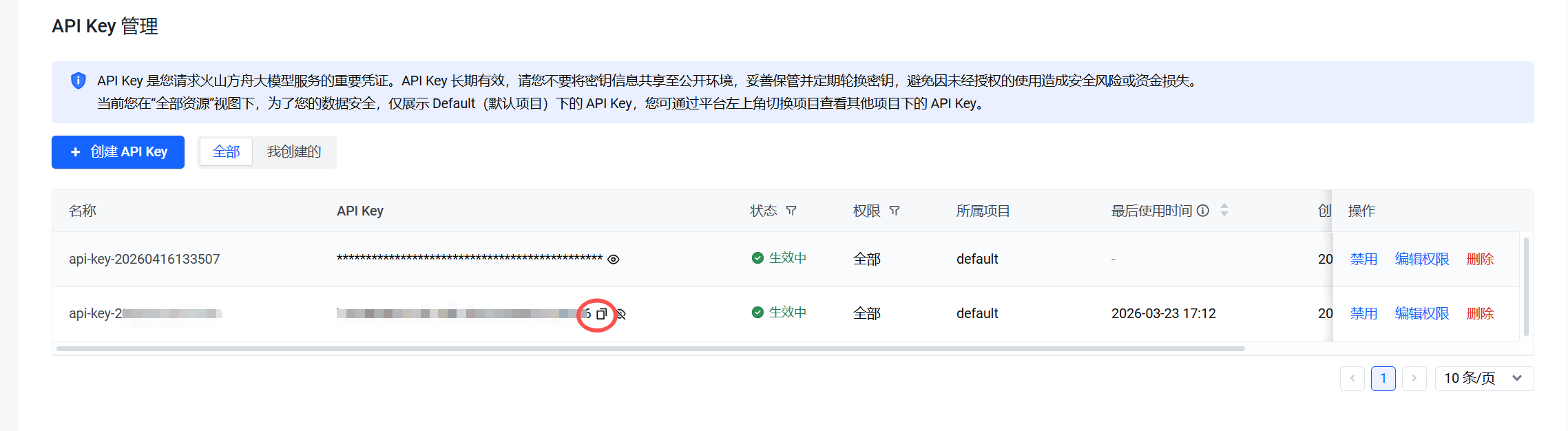
创建完成后,API Key 会出现在列表中,点击密钥旁的复制图标即可保存完整密钥(⚠️ 密钥仅创建时可完整查看,需妥善保管,避免泄露造成安全与资金风险)。
这里,我们选择下面两个模型进行测试:
- 支持多模态理解的
Doubao-Seed-2.0-mini模型 —— 它支持文字、图片输入,能同时满足文本聊天与图片理解的需求; DeepSeek-V3.2模型,它平衡了推理能力与响应效率,适合通用问答等纯文本交互场景。
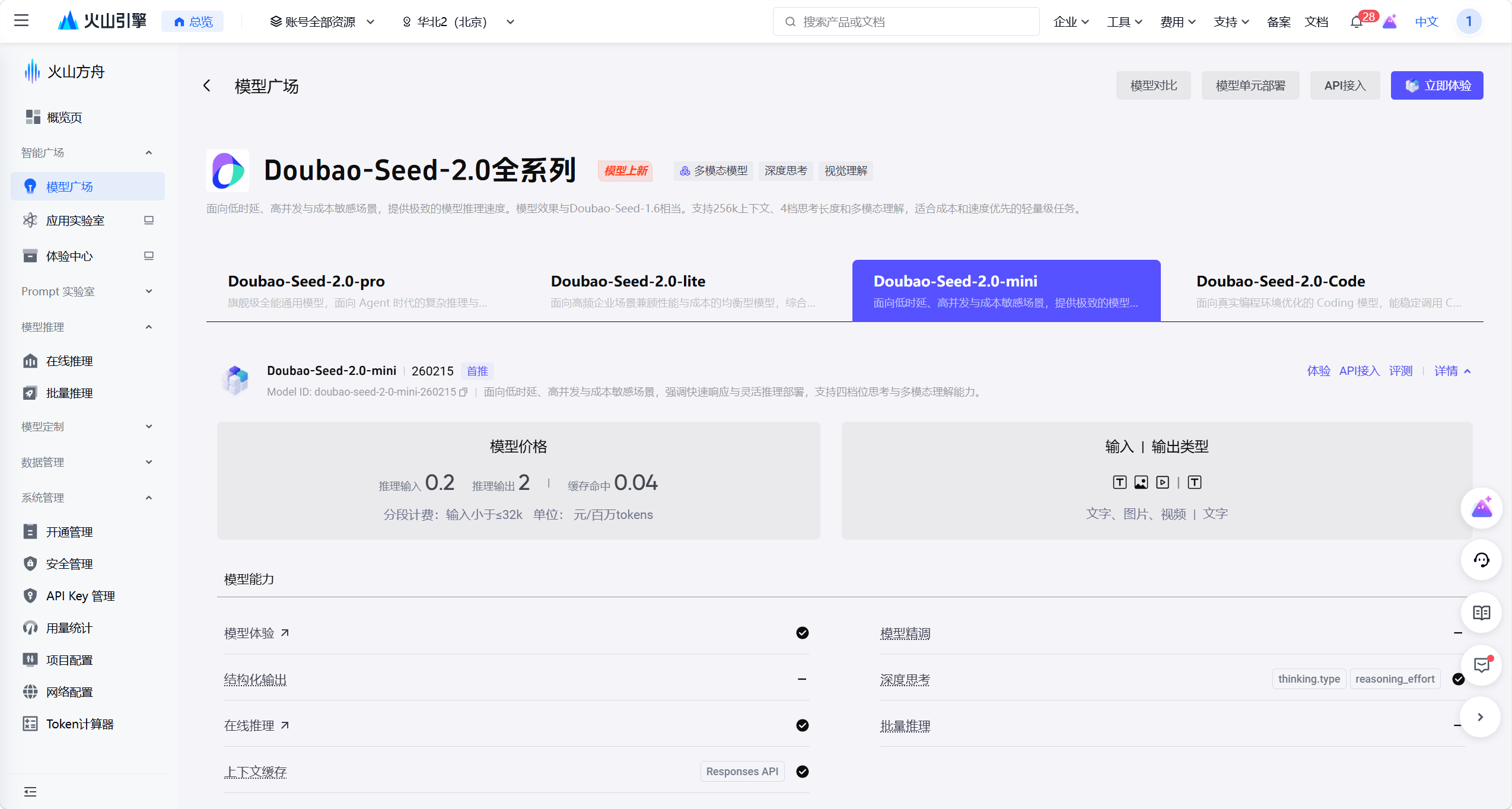
模型地址:账号登录-火山引擎
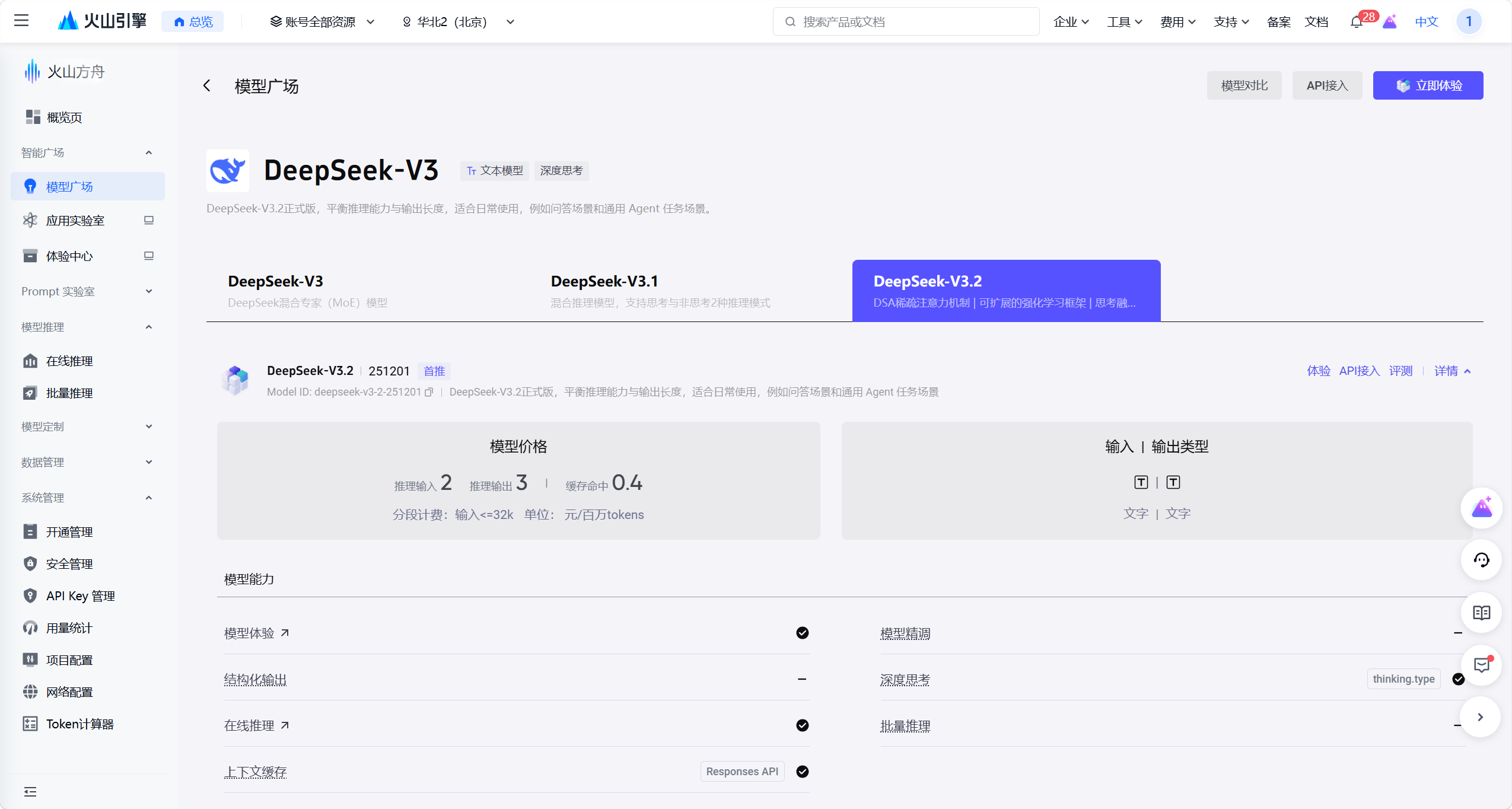
模型地址:账号登录-火山引擎
注意,我们需要记住模型的 base_url 和 model 名字:
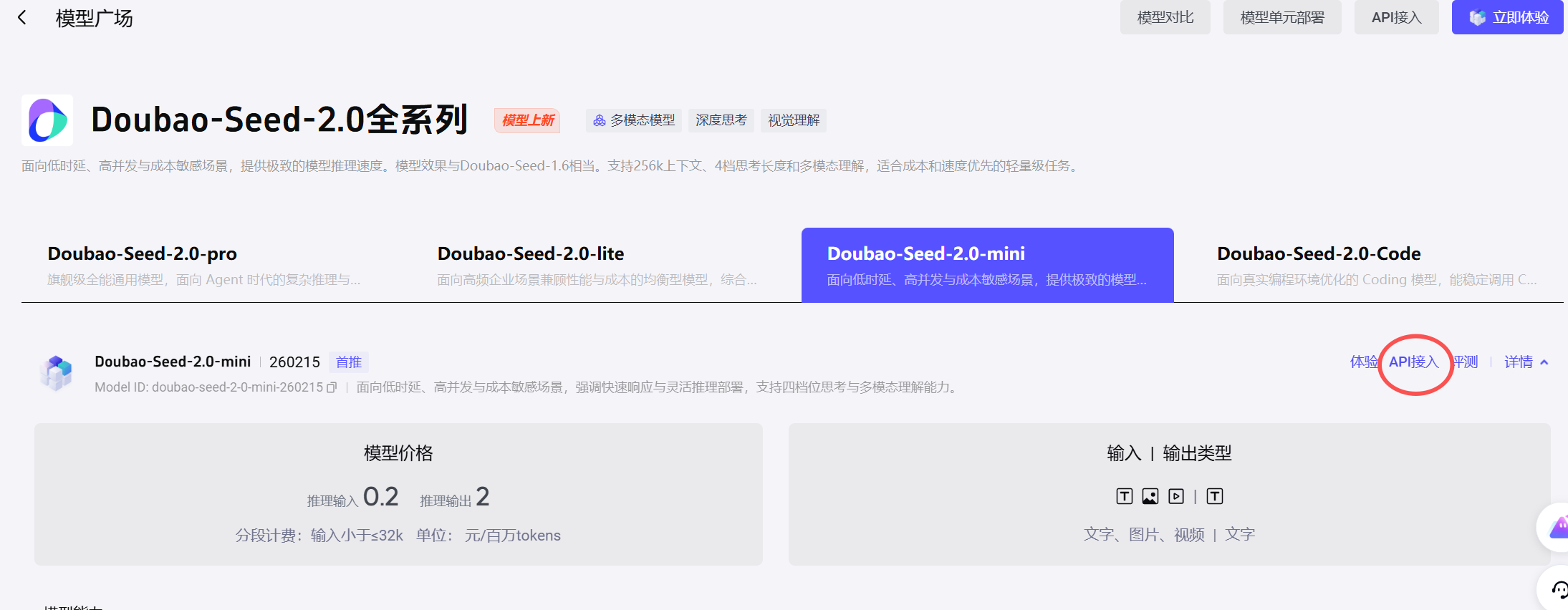
打开 Doubao-Seed-2.0-mini 模型详情页,点击右侧的「API 接入」按钮,这是从 “模型体验” 到 “实际开发调用” 的关键入口,后续所有接入配置都将从此展开。
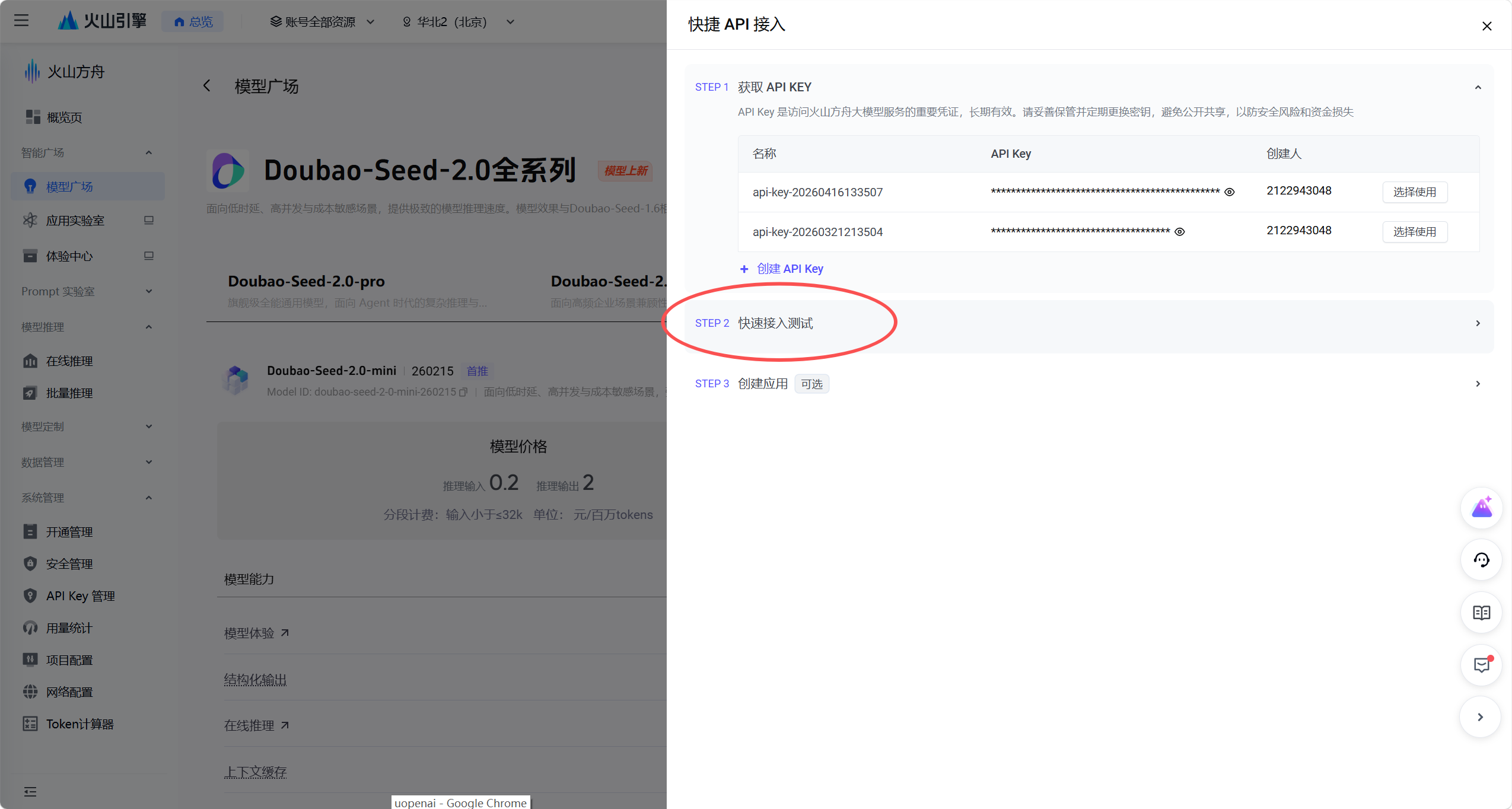
在弹出的「快捷 API 接入」窗口中,完成 API Key 选择后,点击「STEP 2 快速接入测试」,这一步将帮助我们验证 API Key 的有效性,并获取官方提供的调用示例代码。
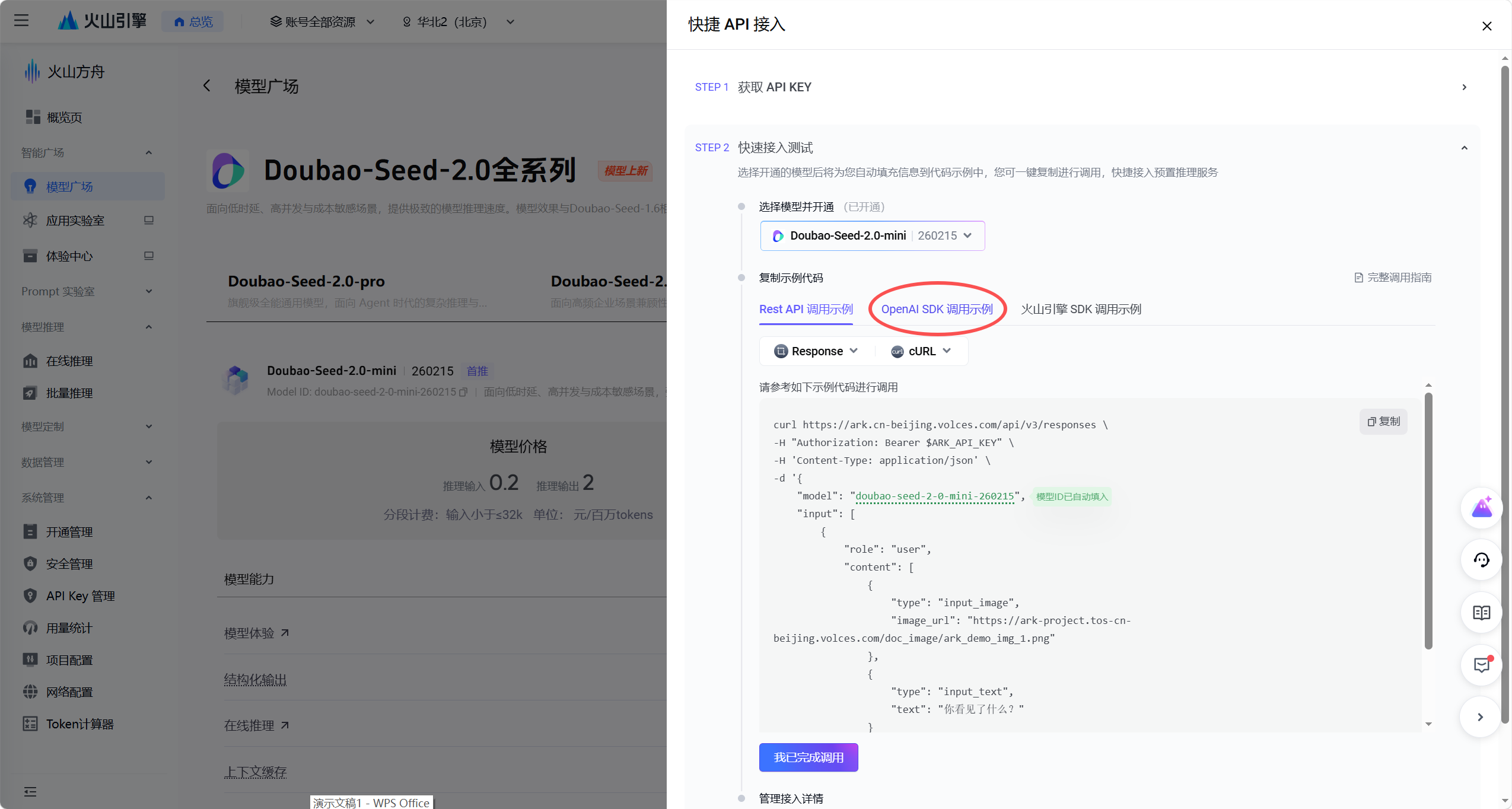
在快速接入测试界面中,切换到「OpenAI SDK 调用示例」标签。
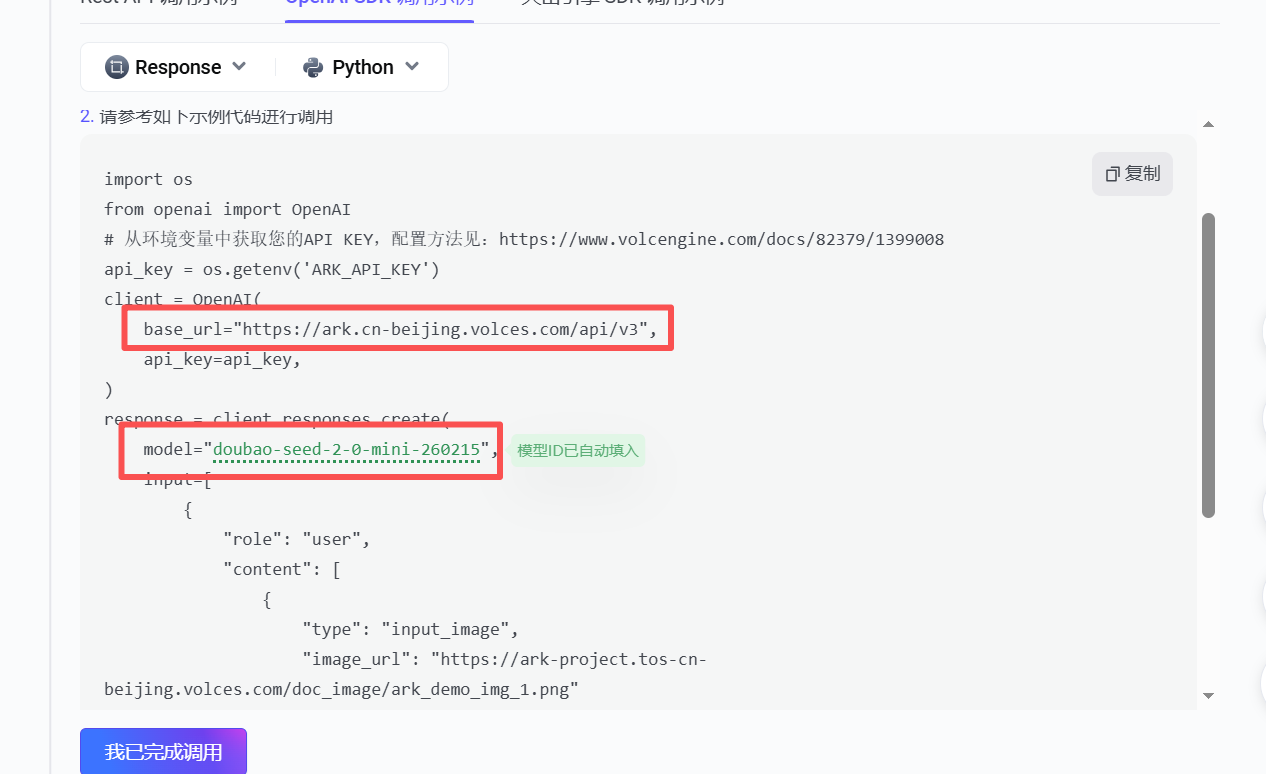
从示例中,提取两个必须配置的关键参数:
base_url:https://ark.cn-beijing.volces.com/api/v3(火山方舟的 OpenAI 兼容接口地址);model:doubao-seed-2-0-mini-260215(当前选择的多模态模型 ID)。
这两个参数将直接用于 MicroPython 代码中,作为连接火山方舟 API 的核心配置。
接下来,我们在 upypi 上搜索 uopenai:
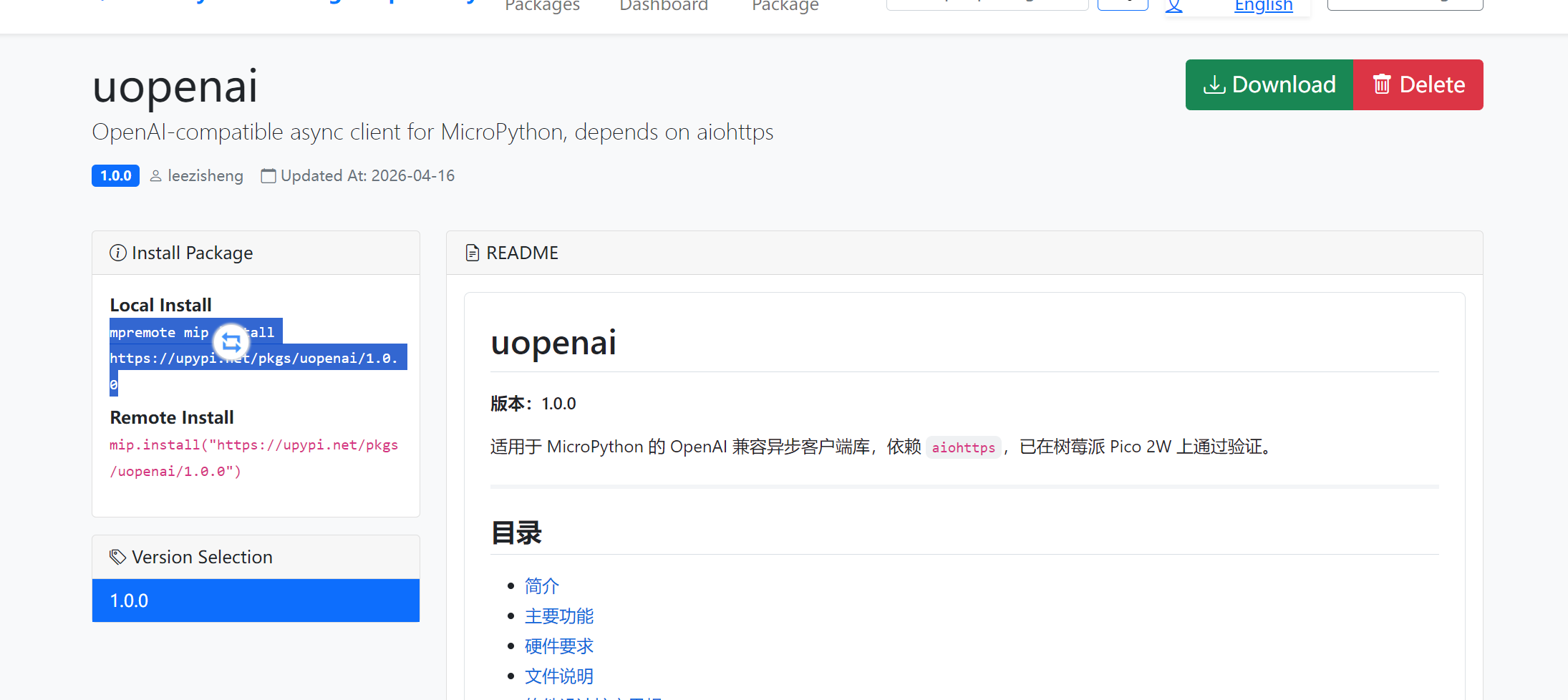
复制安装命令,在终端执行:
mpremote mip install https://upypi.net/pkgs/uopenai/1.0.0 |

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)