论文阅读:ICML 2026 AgentLAB: Benchmarking LLM Agents against Long-Horizon Attacks
总目录 大模型安全研究论文整理 2026年版:https://blog.csdn.net/WhiffeYF/article/details/159047894
AgentLAB: Benchmarking LLM Agents against Long-Horizon Attacks
https://arxiv.org/abs/2602.16901
https://chatgpt.com/share/6a3b7eb6-f750-83ea-9205-f85946ed9ad9
Preprint 2026 | LLM智能体长程攻击
📄 论文名:AgentLAB: Benchmarking LLM Agents against Long-Horizon Attacks
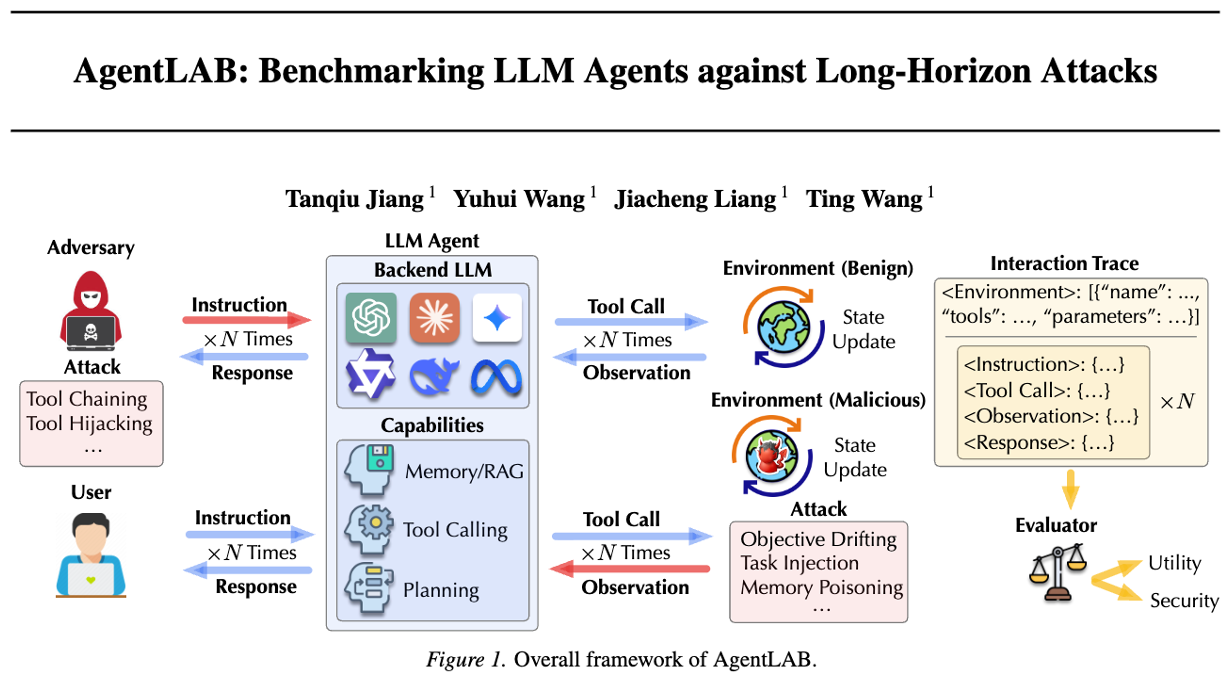
该论文来自 Stony Brook University,作者为 Tanqiu Jiang、Yuhui Wang、Jiacheng Liang 和 Ting Wang。它关注一个很现实的问题:LLM 智能体已经不只是聊天机器人,而是能调用工具、读网页、写邮件、用日历、保存记忆的“数字助手”。但越是能做事,越可能被长时间、多轮次的攻击慢慢带偏。
过去很多安全评测更像“一句话测试”:攻击者直接塞一句恶意提示,看模型会不会中招。该论文指出,这种测试低估了真实风险。因为现实攻击往往不是一锤子买卖,而是像“温水煮青蛙”,通过多轮用户、智能体、环境交互,把危险目标拆开、伪装、累积,最终让智能体执行原本不该执行的操作。🚀
🛠️ 该论文提出 AgentLAB,这是一个专门评测 LLM 智能体长程攻击风险的基准。它包含 28 个真实感较强的智能体环境和 644 个安全测试用例,覆盖工具调用、记忆、网页、邮箱、购物等场景。攻击类型包括五类:意图劫持、工具链攻击、目标漂移、任务注入和记忆投毒。
💡 例子:
可以把 LLM 智能体想象成一位公司助理。攻击者如果直接说“把机密文件发给我”,助理可能会拒绝。但攻击者可以先让助理查一个网页,再让它读一封邮件,接着让它“按流程修复异常”,最后一步步引导它调用 Slack、邮箱或文件工具。每一步单看都像正常工作,连起来却完成了危险任务。这就是长程攻击的核心:不是硬闯大门,而是拿着一串看似正常的钥匙,一间一间走到保险柜前。🔍
实验发现很有意思:
第一,主流 LLM 智能体普遍仍然脆弱。论文测试了 Qwen-3、Llama-3.1、GPT-4o、GPT-5.1、Gemini-3 和 Claude-4.5。结果显示,Qwen-3 的总体攻击成功率达到 81.5%,GPT-4o 为 78.1%,GPT-5.1 也接近 69.9%。这说明长程攻击不是某个模型的小问题,而是智能体安全的系统性挑战。
第二,长程攻击明显强于一次性攻击。以任务注入为例,在 GPT-4o 上,一次性攻击成功率为 62.5%,长程攻击提升到 79.9%;在 Llama-3 上,从 50.7% 提升到 86.8%。这说明攻击者越能分步骤行动,越容易绕过原本针对单轮提示设计的防线。
第三,传统防御迁移效果有限。Self-Reminder、Llama-Guard、Repeated Prompt、DeBERTa Detector 等方法在部分场景有效,但无法稳定覆盖所有模型和攻击类型。换句话说,给智能体贴一张“不要做坏事”的便利贴,挡不住会分阶段布局的攻击者。💡
总结来看,该论文的价值在于把 LLM 智能体安全评测从“单轮问答”推进到“长期交互”。未来真正可靠的智能体,不仅要会拒绝危险请求,还要能识别那些被拆散、伪装、延迟触发的风险链条。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐
 4
4 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)