Anthropic 把 SOC 误报率从 33% 砍到 7%,真正在干活的不是 Claude
你打开监控面板,看到 1200 条 P2 级告警在排队。按你们 SOC 团队过去三年的经验,里面大概有 33% 是误报——但你不能直接 dismiss,每条都得点进去看上下文:这个 IP 之前有没有出现过、这个用户有没有相关 Slack 讨论、这个文件 hash 在威胁库里是不是已知的。
平均每条 4 分钟。1200 条,80 个工时,分给 8 个 L1 分析师,一个晚上的事。
然后 Anthropic 在 2026 年 5 月 12 日发了一篇博文,告诉你他们内部用 Claude 搭了套叫 CLUE 的检测平台,把同样的活干完只需要 12000 次自动化 query 加 27000 次 tool call,30 天内省掉 1870 个工时,相当于 234 个人日,误报率从 33% 砍到了 7%。
我第一次读这篇博文的时候,本能反应是:又一篇大厂秀肌肉的软文吧。但作为做了快十年后端架构、最近两年都在帮团队接入 AI Agent 的人,我把博文从头到尾扒了两遍,又对照着 Dropzone 的第三方解读、Cybersecurity Dive 的 CISO 调查、Microsoft Security Copilot 和 Crowdstrike Charlotte AI 的公开数据看了一圈,得出一个有点反直觉的结论:
这套系统跑出 33%→7% 的效果,跟 Claude 模型本身的关系,可能只占三成。
剩下七成是什么?是数据治理、是分层 cascading inference、是 Tool Calling 编排、是 confidence score 分级、还有他们敢于"打破合规惯性"的那种产品哲学。
这五件事,模型可以换,但工程决策抄不抄得动,决定了你们企业能不能复现 CLUE 这个效果。这篇文章就把这五个决策一个一个拆开。
资料来源:Anthropic 官方博客《How Anthropic uses Claude for security operations》(2026-05-12,作者 Jackie Bow),配套 YouTube 视频 FPPTnI88RR8,以及 Dropzone AI 的第三方解读。
SOC 自动化 15 年,到 CLUE 这里改了游戏规则
先把时间线铺一下,不然你看不出 CLUE 为什么是个分水岭。
2005 年 Splunk 上市,SIEM(Security Information and Event Management)这个范式被钉死——把所有日志拽到一个地方,靠规则和搜索查异常。这是 SOC 的第一代基础设施。
2014 年 Phantom Cyber 出现,2018 年被 Splunk 收购,SOAR(Security Orchestration, Automation and Response)成型——你写 playbook,告警来了照剧本走:先查 IP 信誉、再拉用户上下文、然后判断是否隔离主机。这是 SOC 的第二代,把"流程"自动化了。
但 SOAR 有个天花板:playbook 是确定性的,攻击是非确定性的。一个攻击者只要改一个字符、绕一个步骤、走一个新的入口,你的 playbook 就匹配不到,告警还是得 fall back 到人工。Security Boulevard 在 2026 年 3 月那篇《The SOAR Ceiling》写得很直接:playbook 自动化已经到了它的结构性极限,再堆规则只是徒增维护成本,不会再带来检测能力的提升。
2023 年 4 月,Microsoft 发布 Security Copilot,第一个把 LLM 塞进 SOC 工作流的大厂产品。再后来 Crowdstrike Charlotte AI、Palo Alto Cortex XSIAM、Google Security Operations、Splunk ES Premier 全部跟进。这是第三代——LLM-assisted SOC,但骨子里还是"工具加强版",分析师是主体,LLM 是助手。
2026 年 5 月 12 日,Anthropic 发那篇博文之前,他们当时的 CISO Jason Clinton 已经在 RSA 2025 上公开说过一句话:"我们没有传统意义上的 L1/L2 SOC 团队了。"
CLUE 是这句话的工程实现。它不是 LLM 助手,是把整个分诊工作流交给 agentic loop 跑——一个告警进来,Sonnet 做初步分诊、判断要不要展开调查;要的话就 fan-out 一堆 sub-agent,每个 sub-agent 拉一类上下文(Slack、文档、代码仓库、数据仓库),最后用 Opus 做高风险判断,输出一个带 confidence score 的结论给分析师。
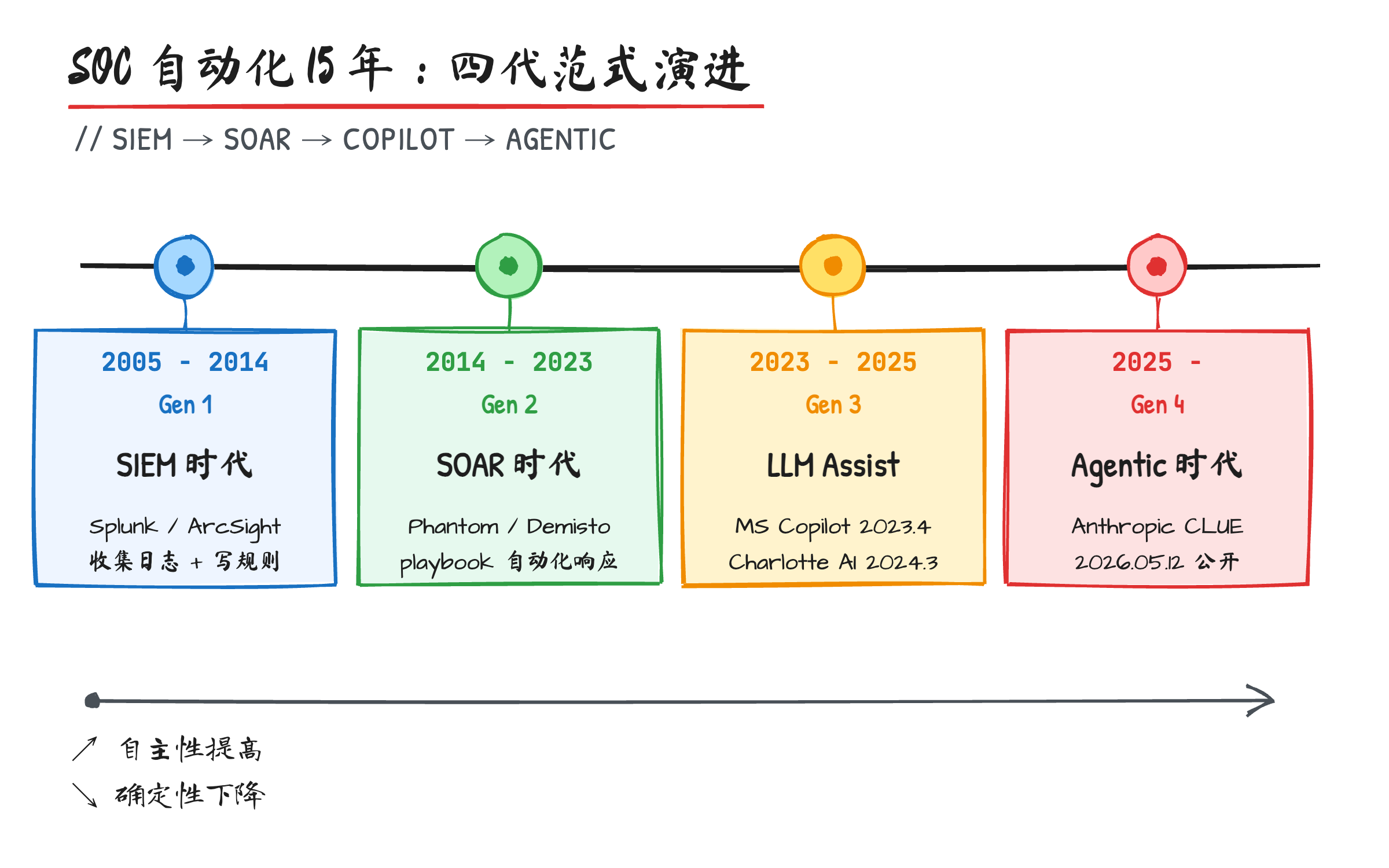
15 年时间,从"把日志集中起来",到"把流程剧本化",再到"让 LLM 当助手",最后到"让 Agent 直接接管 L1"。CLUE 不是又一次技术升级,是范式更迭。
但这并不意味着你们公司明天就能照搬。
先把 5 个常见误解打破
围绕 CLUE 的舆论场里,我看到至少 5 个被反复引用、但其实是误读的观点。先把这些拆掉,后面讲架构才能讲得清。
误解一:CLUE 是 Anthropic 要发布的产品。
不是。CLUE 是 Anthropic Detection Platform Engineering 团队自用的内部平台,不卖、不开源、目前也没有任何商业化计划。Jackie Bow 在原博文里说得很清楚——"我们分享这些是为了让安全社区受益",但分享的是工程经验和模式,不是代码或 SaaS。
误解二:CLUE 替代了 SOC 分析师。
也不是。它替代的是 L1 的重复性分诊工作——那种"看到告警就要去查 5 个系统拼上下文"的体力活。L2/L3 的深度调查、威胁狩猎、事件响应还是分析师做。Jackie Bow 原话:"Our analysts now operate at a fundamentally different level—asking questions that drive strategic security improvements."
误解三:CLUE 的核心创新是"自然语言查询"。
这是最容易被表面看走眼的地方。自然语言界面只是 UI 层,真正的核心是 agentic loop + sub-agent fan-out + Tool Calling 编排。一个调查 session 平均要 25 次 tool call、11 次 query,这背后是非常激进的工具调用编排策略,不是简单的"我用自然语言问问题"。
误解四:33%→7% 主要是 Claude 模型的功劳。
这是最关键的误解。Anthropic 原文里其实写得很清楚:"Claude enriches alerts with context from Slack messages, documentation, code repositories, and data warehouses"。换句话说,误报率砍掉 26 个百分点的主因,是终于把全公司的上下文喂到了告警判断里——之前 SOC 工具看到一个可疑登录,能拿到的就是 IP + 用户 + 时间,现在 Claude 能顺手翻 Slack 看用户有没有说"我要去东京出差"。数据治理不到位的企业,换什么模型都救不了。
误解五:非确定性是 AI SOC 的优势。
Jackie 在原文里引用了 Rich Sutton 的《The Bitter Lesson》,强调 CLUE 故意拥抱非确定性——"Traditional security tools treat inconsistency as a bug. CLUE treats it as a feature."这在 Anthropic 这种自管合规的公司是优势,但你要是金融行业、医疗行业、政府客户,审计员看到"同一个告警今天判定隔离明天判定放行"会直接 fail 你的 SOC2。非确定性是不是优势,取决于你的合规边界谁来定。
打破这 5 个误解之后,再看 5 个工程决策就清晰多了。
决策一:自然语言只是表层,内核是 Tool Calling vs RAG 的取舍
读 CLUE 博文的时候,绝大多数文章会把"分析师可以用自然语言提问"作为最大亮点。我恰恰认为这是最不重要的部分——任何接了 LLM 的产品都能做这一层。
真正的架构选择,是Tool Calling 而不是 RAG。
我画一张图说明白这两条路径的差异。
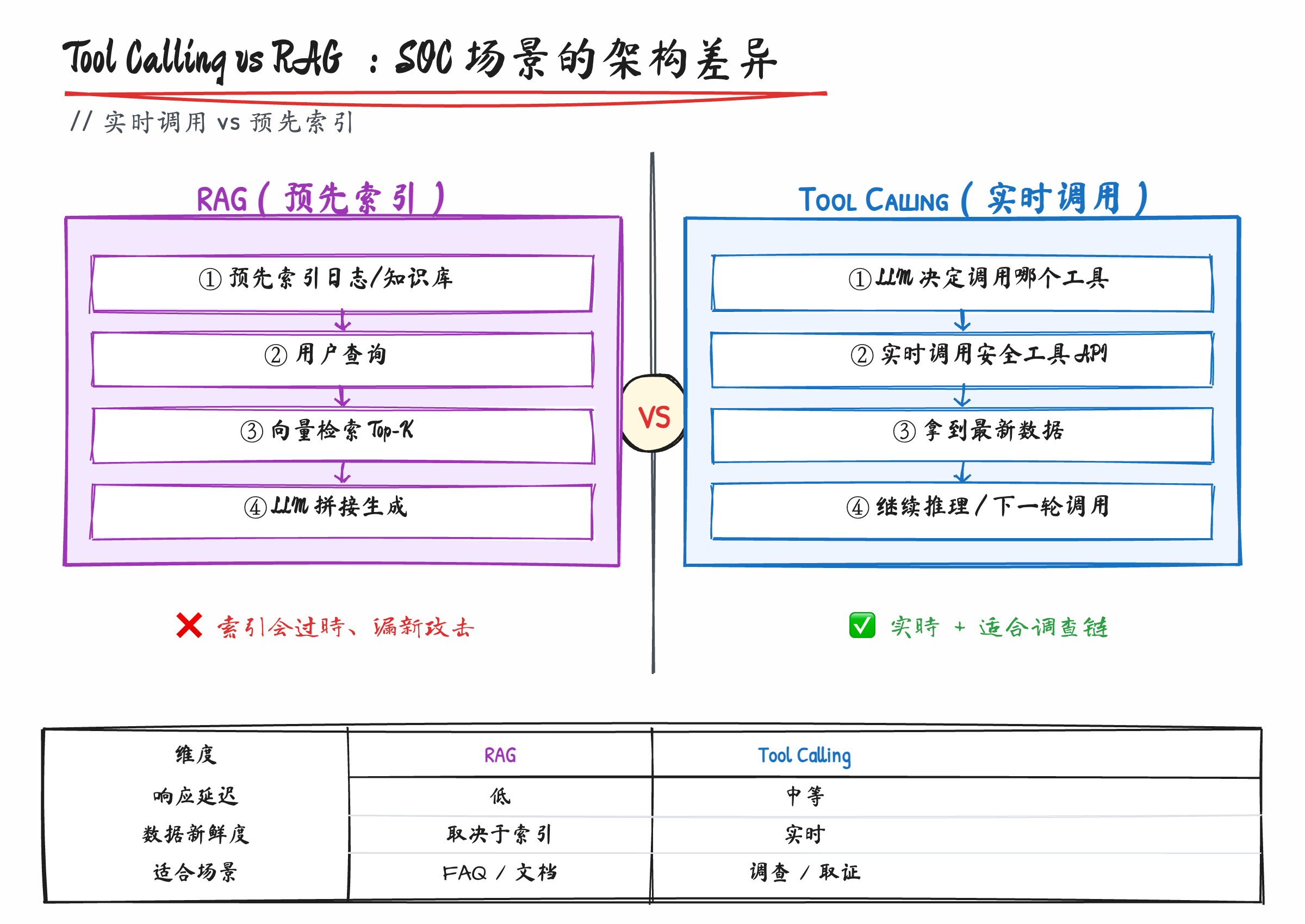
RAG 的路径是:把日志、文档、上下文先做 embedding,存到向量库里,告警来了把告警内容向量化,去向量库里召回相似的、相关的文档喂给 LLM。这是过去两年最主流的 LLM 应用模式。
但 SOC 场景里 RAG 有几个致命问题:
第一,安全数据不能缓存。 你今天 embedding 的 Slack 消息,半小时后这个用户改了说法、撤回了、或者从 Asia 区跑去了 EU 区,向量库里的还是老数据。攻击的特征是"新颖",缓存的索引天然漏新。
第二,召回有损。 向量召回是基于语义相似度的,但安全调查需要的常常是"精确匹配"——这个用户在最近一小时内,是不是发过一条提到 "VPN" 的消息?这种问题向量召回经常召回不到。
第三,可解释性差。 分析师事后做调查复盘,你告诉他"模型从向量库里召回了 12 篇文档,这是其中得分最高的 3 篇"——这是一个黑盒。审计也不答应。
Tool Calling 把这三个问题全绕开了。每个数据源都被封装成一个 tool(search_slack、get_user_context、query_warehouse),LLM 在调查时按需调用,每次调用都拉实时数据、每次都有明确的查询条件、每个 tool call 都可以记录到审计日志里。
代价是慢——一次调查 25 次 tool call 加 11 次 query,单次 3-4 分钟。RAG 路径基本是秒级。
但在 SOC 这个场景,慢 4 分钟换准确率和可审计性,是非常合理的取舍。况且自动化跑,慢 4 分钟也是机器在干活,不占人工。
这就是为什么我说自然语言界面只是表层。如果哪天 Anthropic 决定换 GPT-5 或者 Gemini 跑 CLUE,只要那个模型 Tool Calling 能力 OK,效果差异不会很大。但如果有人想抄 CLUE 的形,结果用了 RAG 路径,那从架构开始就走偏了。
决策二:33%→7% 里,"上下文接入"贡献远超模型本身
回到那个最容易被读错的数据:误报率从 33% 降到 7%。
我把这个数字放在第二个决策里讲,是因为它直接关系到企业自评的问题——你们公司有没有可能复现这个效果?
先看 Anthropic 自己列的上下文源头:Slack 消息、内部文档、代码仓库、数据仓库。这四个东西放在一起,已经能勾勒出他们的数据栈是什么样子:
- Slack 全量索引并可查询——意味着所有沟通都在 Slack,且 SOC 有读权限
- 内部文档统一可访问——意味着 wiki、设计文档、运维手册都在一处
- 代码仓库可调用——意味着 GitHub Enterprise 或类似,且能跨仓库搜索
- 数据仓库可查询——意味着所有结构化业务数据都在一个 warehouse 里(大概率是 Snowflake 或 BigQuery)
你们公司是不是这样?我接触过的大部分国内中大型企业是:邮件用 outlook、IM 用钉钉+企微+Slack 混用、文档分散在 confluence/腾讯文档/飞书、代码在 GitLab 私有部署、业务数据在 6 个不同的库里。
在这种数据栈上跑 CLUE,Claude 能拉到的上下文只有原始的告警字段,效果会迅速退化到接近 SOAR——因为你给不了它"丰富 context"。33% 还是 33%,砍不下去。
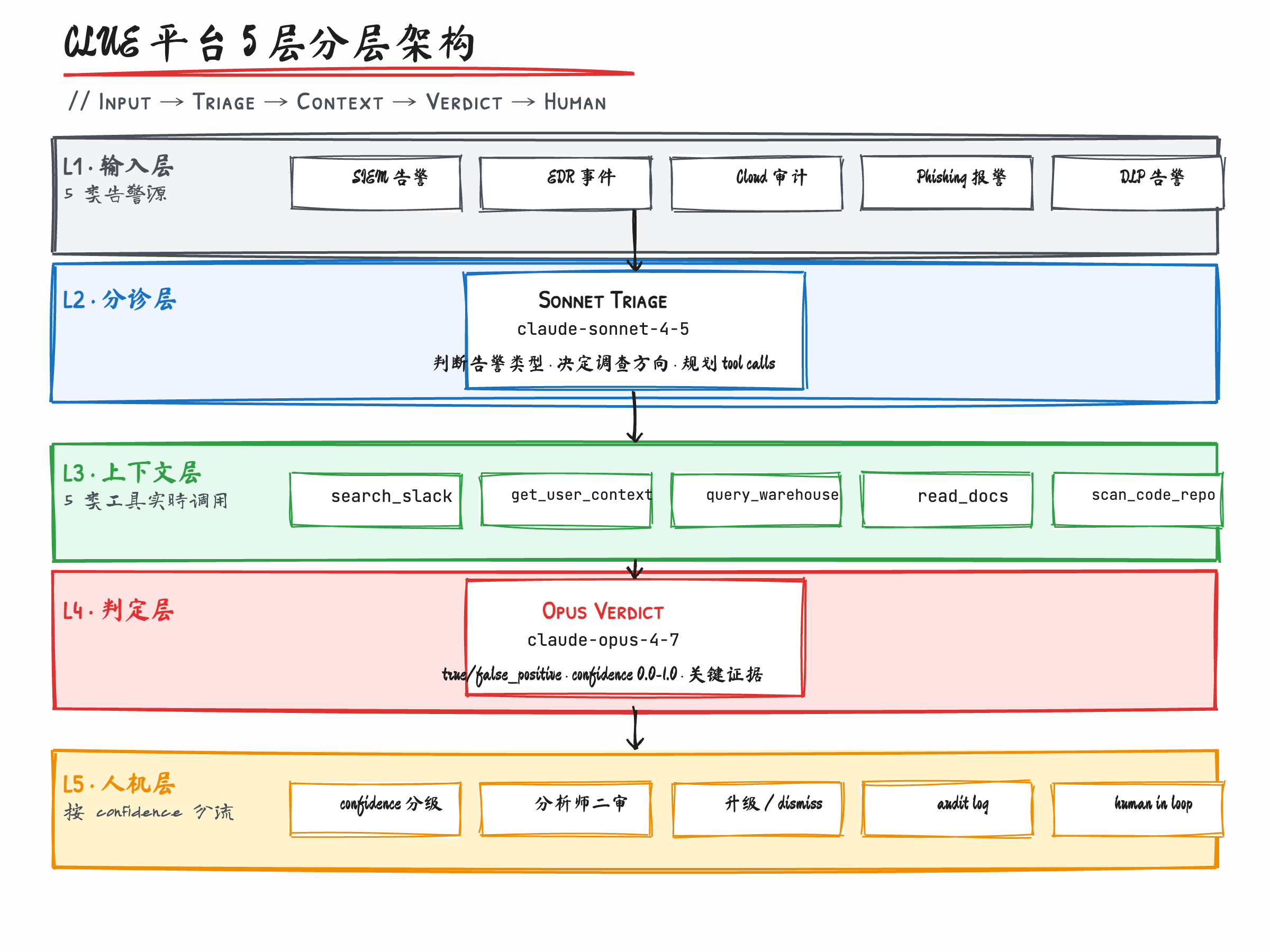
我做这个判断的依据,除了上面这个推理,还有一个对照:Crowdstrike Charlotte AI 公开的 triage 准确率是 98%,但它的数据源被限定在 endpoint 自己的遥测信号里——也就是 Falcon agent 采到的进程、文件、网络事件。这个 98% 在 endpoint-centric 的场景里成立。
Microsoft Security Copilot 的 phishing 准确率提升 77%、6.5 倍加速,本质上是因为它能调用 Microsoft 365 的全套元数据——邮件、Teams、SharePoint、Entra ID 都在同一个租户里,上下文是天然贯通的。
CLUE 的 33%→7%、Charlotte AI 的 98%、Security Copilot 的 77%,这三个数字背后都是"上下文密度"在起作用,模型差异是次要因素。
架构师视角的判断: 如果你们公司过去两三年没做过数据治理,现在想直接上 AI SOC,第一步不是选模型不是选向量库,是先把数据栈拉通。这件事的难度和工作量,远大于接 Claude API。
我见过有团队上来就买 SaaS 的 AI SOC 产品,三个月之后发现告警准确率没什么变化——一查,能给 LLM 的上下文还是原来那些字段,多花的钱全给了模型 API。前期不做数据治理,AI 在垃圾上跑还是垃圾。
决策三:Sonnet + Opus 分层 cascading inference 才是 token 经济学
CLUE 的博文里提到他们用 Sonnet 和 Opus 两个模型,但没明说怎么分工。我倒推了一下他们的成本结构,得到一个比较可靠的猜测:Sonnet 干 23 次 tool call,Opus 干剩下的 2 次关键判断。
为什么这么推?
先做一个粗算。Anthropic 公开的 Claude API 价格(2026 年 5 月):
- Sonnet:input $3 / 1M tokens,output $15 / 1M tokens
- Opus:input $15 / 1M tokens,output $75 / 1M tokens
Opus 比 Sonnet 贵 5 倍。如果 25 次 tool call 全用 Opus,按平均每次 call 输入 5k token、输出 1k token 算,单次调查就是:
input: 25 × 5000 × $15/1M = $1.875
output: 25 × 1000 × $75/1M = $1.875
total: 约 $3.75 / 单次调查
按 Anthropic 公布的 30 天 12000 次 query,加上 27000 次 tool call 大概对应几千次完整调查,一个月光 LLM 费用就是几万美元。
但如果把架构改成 cascading:
分诊层 (Sonnet):判断告警类型,输出该用什么工具调查
└─→ 23 次例行 tool call (Sonnet):拉 Slack、查文档、调代码
└─→ 2 次高风险判断 (Opus):最终结论 + confidence score
成本立刻下来:
Sonnet (23 calls): 23 × 5000 × $3/1M + 23 × 1000 × $15/1M = $0.69
Opus (2 calls): 2 × 8000 × $15/1M + 2 × 2000 × $75/1M = $0.54
total: 约 $1.23 / 单次调查
省了三分之二。
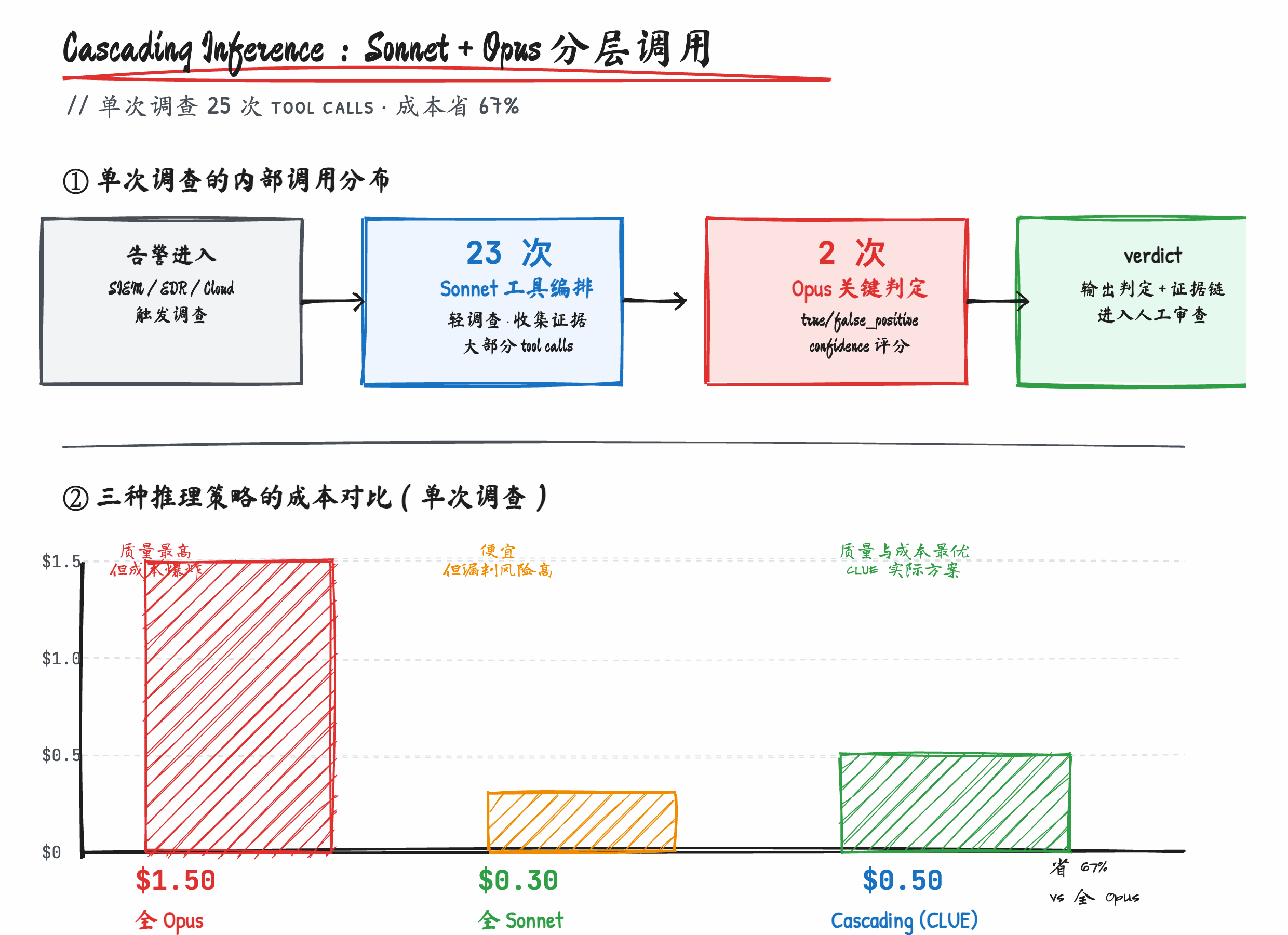
更重要的是,这种分层不是简单的"便宜模型 + 贵模型",是让贵模型只用在它真正贵得有道理的地方:最终判定。前面 23 次 tool call 本质是"查询并拼接上下文",Sonnet 完全 hold 得住;最后的"这个告警是真威胁还是误报,confidence 多少"才需要 Opus 的推理深度。
架构师视角的判断: 这是 CLUE 里最容易抄的一部分,也是最先该抄的一部分。任何用 LLM 跑安全场景的团队,第一天就该把 cascading inference 这个模式立起来。一刀切用最贵的模型,是新手 token 经济学。
具体怎么写代码?给一个最小骨架(伪代码,体现核心思路):
from anthropic import Anthropic
client = Anthropic()
def investigate(alert):
# Phase 1: Sonnet 做分诊,决定调用哪些工具
triage = client.messages.create(
model="claude-sonnet-4-5",
tools=ALL_SECURITY_TOOLS,
messages=[{
"role": "user",
"content": f"分诊以下告警,输出需要调查的方向:{alert}"
}]
)
# Phase 2: Sonnet 跑 tool calls 拉上下文(agentic loop)
context = run_tool_loop(triage, model="claude-sonnet-4-5")
# Phase 3: Opus 做最终判定,输出 confidence score
verdict = client.messages.create(
model="claude-opus-4-7",
messages=[{
"role": "user",
"content": f"""
告警:{alert}
调查发现的上下文:{context}
输出:
1. 判定:true_positive / false_positive
2. confidence: 0.0-1.0
3. 关键证据列表
"""
}]
)
return verdict
关键设计点:
- Phase 1 和 Phase 2 用同一个 Sonnet 实例,复用 agentic loop 能力
- Phase 3 切到 Opus,只做"信息已齐全的最终判断"这一件事
- 上下文从 Phase 2 流到 Phase 3,但只取关键证据,不是把所有 tool 响应都塞进去——这是控制 Opus 的输入 token 关键
我自己在帮一个团队做内部 AI 告警分诊的 POC 时,第一版偷懒全用 Opus 跑,月成本测算下来要 8 万美元;改成 cascading 之后降到 2.5 万,准确率反而略有提升(因为 Sonnet 做 tool call 时不会"想太多"导致跑偏)。
决策四:Confidence Score 不是给 UI 看的,是给"漏判成本"算账的
CLUE 的另一个工程决策是给每个判定输出 confidence score,分析师按 score 决定看哪些。
这听起来很标准——任何 ML 系统输出预测都会带置信度。但绝大多数团队的实现是这样的:
confidence > 0.9:直接通过
0.7 < confidence < 0.9:标黄,分析师抽查
confidence < 0.7:标红,必须人工处理
阈值 0.9、0.7 是怎么定的?拍脑袋。或者说"行业经验"。
架构师视角的判断: 这种拍脑袋定阈值是 AI SOC 的隐形巨坑,CLUE 真正高级的地方是把阈值定义反过来——不是按 score 分级,是按"漏判成本"反向定阈值。
什么意思?
假设你们公司一个真实勒索软件入侵的损失是 500 万美元,一个误报让分析师多花 15 分钟(成本约 50 美元)。那么:
- 如果 confidence > X,自动 dismiss 告警的代价是"漏判一个真威胁",期望损失 = (1-X) × $5,000,000
- 如果 confidence < X,人工复核的代价是"多看一个误报",期望损失 = X × $50
X 应该定在哪里?让两边期望损失相等:
(1 - X) × 5,000,000 = X × 50
5,000,000 - 5,000,000 × X = 50 × X
5,000,000 = 5,000,050 × X
X ≈ 0.99999
换句话说,在勒索软件这个场景下,confidence 不到 99.999% 你都该让人看,因为漏一个真的代价远远高于多看一个假的。
这才是定阈值的正确方式。不是"经验上 0.9",是根据这类告警的漏判成本和误判成本反推。
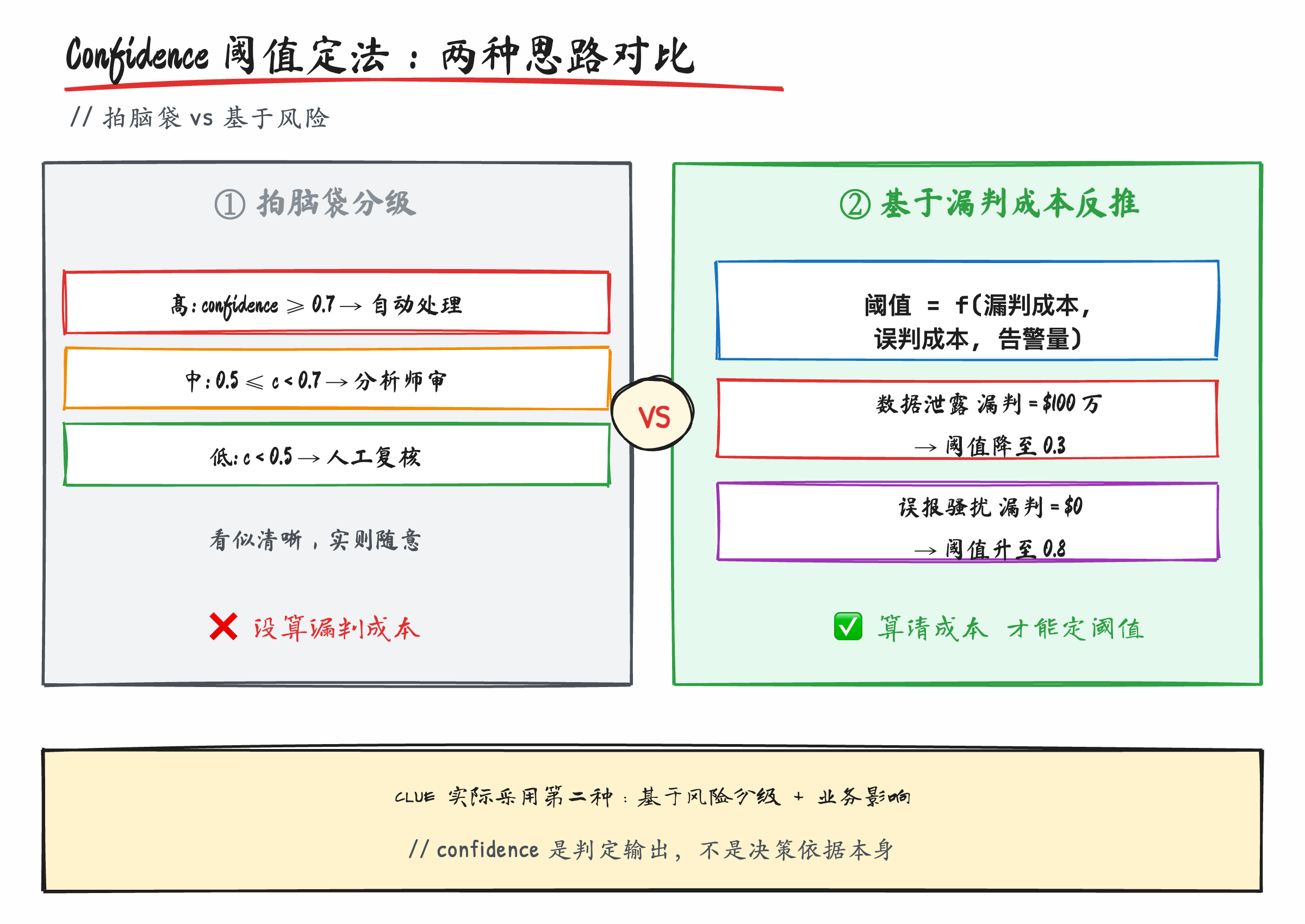
CLUE 在原文里没明说他们具体怎么定阈值,但 Jackie 反复强调"human-in-the-loop"是按风险分级的。这暗示了背后有一套差异化的成本评估逻辑——不是所有告警走同一个阈值,是按告警类型、资产敏感度、潜在影响来动态算。
我见过一个比较真实的踩坑:某金融客户上线 AI 告警分诊,CISO 拍板设了 0.85 的阈值。两个月后发生一次真实数据泄露事件,事后复盘发现那条原始告警 confidence 是 0.83,被自动 dismiss 了。事故定责的时候,CISO 自己也说不清楚 0.85 这个数字怎么来的。
这就是为什么 confidence score 不能"给 UI 看"——它是工程决策,不是显示需求。每一个阈值都该有明确的成本依据,能被审计追问。
决策五:非确定性 vs 合规——CLUE 故意打破了 SOAR 范式
最后这一条最哲学,但也最容易被国内企业忽略。
CLUE 博文里有一段被引用最多的话:
"Embracing non-determinism: Traditional security tools treat inconsistency as a bug. CLUE treats it as a feature."
Jackie 引用 Rich Sutton 2019 年那篇《The Bitter Lesson》作为理论背书——大意是:AI 历史上一次次证明,让通用方法(scale + 学习)取代手工规则,长期会赢。SOAR playbook 是手工规则,CLUE 的 agentic loop 是通用方法,所以 CLUE 长期会赢。
这个判断没错。但有个前提条件:你的合规环境允许非确定性。
我把过去 15 年 SOC 的"确定性范式"和 CLUE 的"非确定性范式"做个对比:
| 维度 | 传统 SOAR | CLUE 模式 |
|---|---|---|
| 同一告警 | 输入相同,输出永远相同 | 同样输入,不同时间可能不同结论 |
| 处理路径 | 完全可重放、可审计 | 路径由 LLM 决定,事后可记录但不可重放 |
| 失败模式 | 已知失败模式,可枚举 | 失败模式开放,包括幻觉、越权调用 |
| 合规审计 | 友好——"为什么这样处理"有 playbook | 困难——"为什么这次没调用 X tool"答不上来 |
| 攻击防御 | 攻击者可以预测并绕过 | 攻击者难以预测,但防御者也难以保证 |

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐
 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)