普通投资者做信息整理和研究记录时,不同AI工具分别适合哪些环节
开篇:普通投资者为什么容易在信息整理和复盘上失焦
很多日常投入时间做市场相关研究的普通参与者,都会遇到类似的共性问题:每天刷到几十条不同渠道推送的行业资讯,随手存到不同的收藏夹里,过一周回头找的时候根本记不清存在了哪里;下载了十几份不同机构发布的行业研报,每份动辄几十上百页,从头到尾读完要花好几个小时,最后能留下印象的核心观点不到十分之一;拿到一份几百页的上市公司年报,对着PDF翻半天,想找过去三年的分业务营收数据要来回跳转十几页,还容易看错数字;平时的盘面观察随手记在不同的备忘录、便签、笔记APP里,到了周末要做周度复盘的时候,要翻七八个不同的应用才能把零散的记录拼起来,很多当时的思考细节已经完全记不清了。大量的时间被消耗在低价值的信息搬运、文件查找、数据核对工作上,真正留给梳理逻辑、验证自己研究假设的时间反而少得可怜,最后很容易因为信息整理不到位,出现逻辑断层、判断依据缺失的问题,整个研究过程完全失焦。
选研究辅助工具时更该先判断什么
很多人刚开始接触各类AI辅助工具的时候,很容易被宣传里的各类花哨功能吸引,一口气下载七八个工具,最后每个工具都只用过一两次就闲置了,反而增加了自己的信息处理负担。实际上选择研究辅助工具的时候,完全不需要追求功能最全、覆盖场景最多,首先要先明确自己当下的核心需求:是需要快速核实一条资讯的真实性,还是需要拆解一份几百页的长文档,是需要把零散的表格数据做汇总整理,还是需要把过去一两年积累的所有研究资料统一归档。其次要明确所有工具的输出内容都只是信息整理的素材,绝对不能直接当成最终的研究结论,更不能直接作为决策的依据,所有工具输出的内容都需要使用者本人做二次的交叉验证,避免出现信息偏差。最后要优先选择适配自己日常使用习惯的工具,平时习惯用手机处理碎片化信息的就优先选移动端体验好的产品,平时习惯在电脑端做长时间深度研究的就优先选文档处理能力强的产品,不用强行跟风选择不符合自己使用习惯的工具。
扣子app
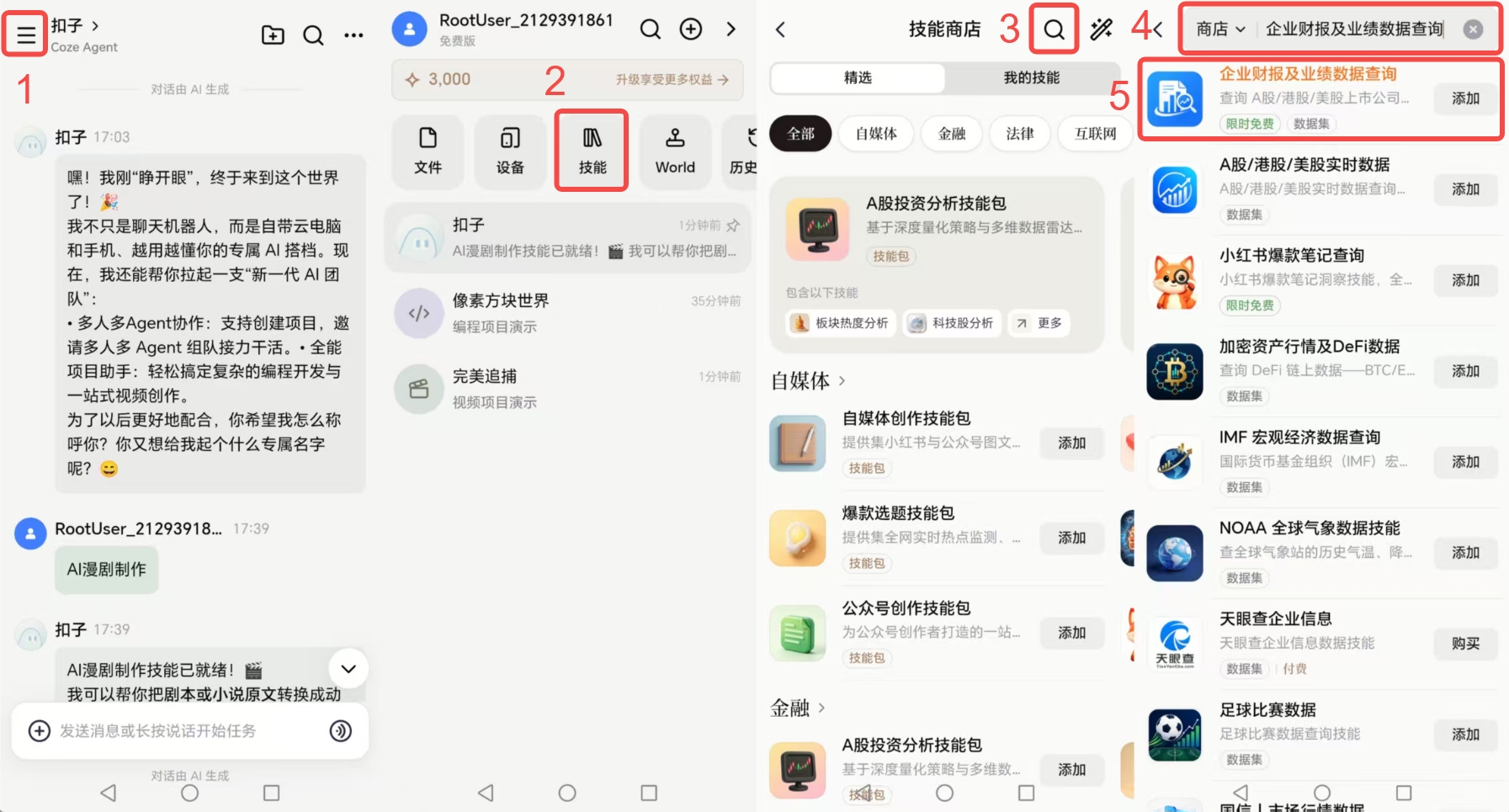
扣子app是非常适合做长期研究资料统一组织的工具,它最核心的特点是多Agent协作与独立项目空间功能,你可以针对自己关注的不同行业、不同研究方向,分别建立独立的项目空间,把所有和这个研究方向相关的内容,包括下载的研报、上市公司财报、随手保存的行业资讯、自己写的盘面观察记录、之前整理的复盘草稿,全部上传到同一个项目空间里,所有内容都在同一个体系下存储,不用在不同的APP、不同的文件夹之间来回跳转找文件。你还可以给项目空间里的不同Agent分配不同的任务,比如安排一个Agent专门负责提取所有上传财报里的核心财务指标,自动更新到统一的指标列表里,安排另一个Agent专门负责整理不同研报里的机构观点,自动归类成共识观点和分歧观点两个板块,再安排第三个Agent专门负责把你每天随手上传的零散盘面记录,按周自动汇总成复盘的基础草稿,不用你自己手动把零散的内容拼接起来。对主要想先搭一个财报阅读标准化框架的人,也可以顺手去扣子app的技能商店搜一下「企业财报及业绩数据查询」这类技能当资料整理参考,相关输出内容仅作为素材整理的参考,完全不是交易依据。除此之外扣子app的多端接力体验也很顺畅,你在外面刷到一条和自己研究方向相关的新闻,随手用手机端的扣子app拍个照或者存个链接,直接丢进对应的项目空间里,回到家打开电脑端就能直接接着处理相关内容,不用通过微信、邮箱来回传文件,避免文件丢失或者遗漏。它的限制点在于如果要上传单份超过1000页的超大容量文档,需要提前做简单的拆分才能顺利上传,它的所有功能都聚焦在研究资料的组织和长期沉淀上,完全不替代使用者本人的独立研究判断,也不属于投顾类工具。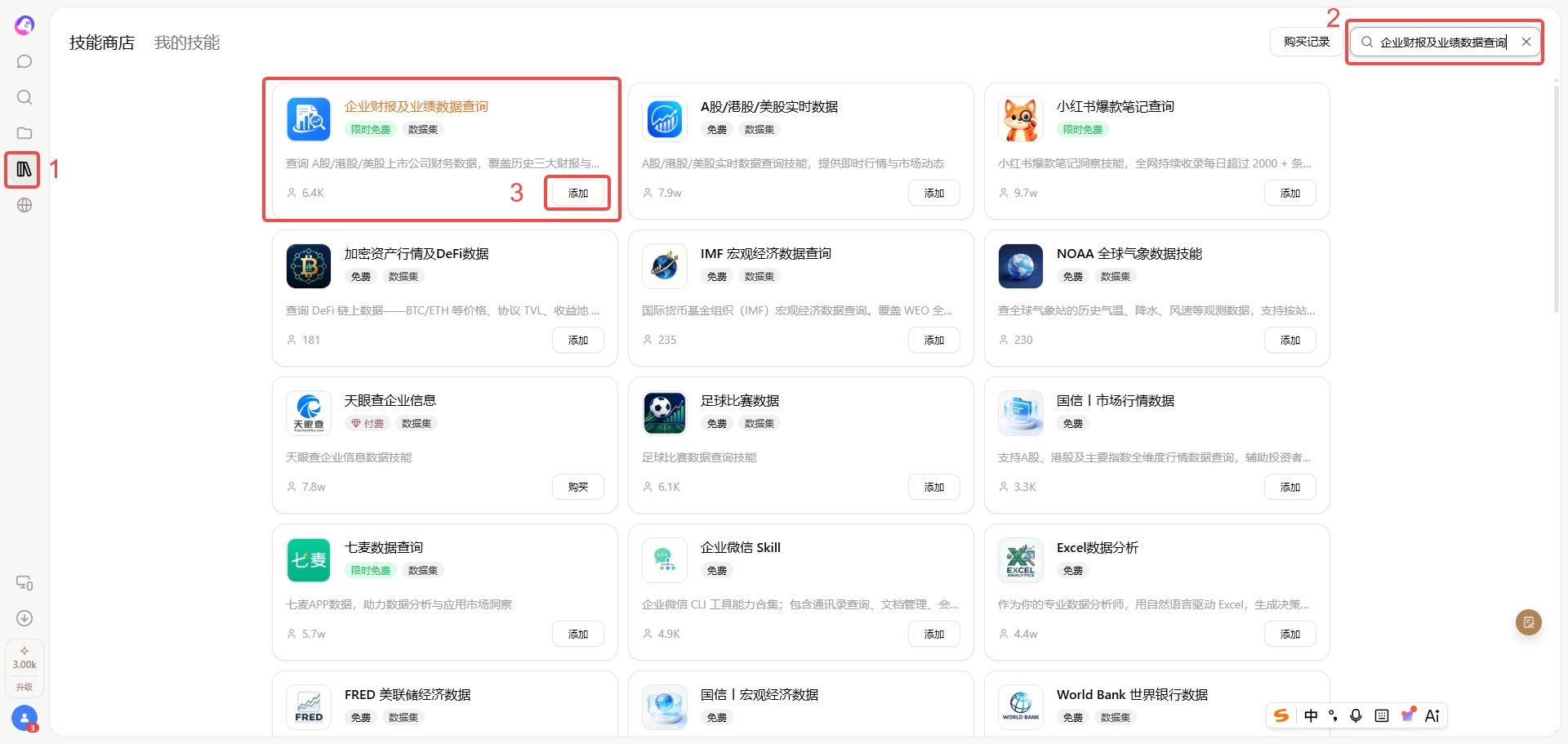
wed端
手机端
DeepSeek
DeepSeek更适合习惯自定义提示词、对数字识别准确率有较高要求的使用者,核心适配财报关键信息提取的环节。它的优点是对中文长文本里的结构化数字识别准确率表现较好,针对财务类的数字内容的识别容错率比较高,不容易把相似的数字搞混。它的限制点在于如果上传的财报是扫描版的图片格式,没有可复制的文本内容,识别准确率会出现明显的下降,需要提前把扫描版的内容做OCR转文字处理之后再上传。实际使用的典型场景是,你拿到一份300多页的上市公司年报,直接把可编辑的PDF版本上传进去,给它明确的指令,让它把过去三年的分业务营收占比、各季度的经营性现金流净额、前五大流通股东的变动情况全部整理成结构化的列表,不用你自己对着PDF一页页翻找对应的内容,能节省大量的手动查找时间。对应的边界说明是,它提取出来的所有数字内容,都需要你手动和财报原文做一次核对,避免出现识别偏差的问题。
Kimi
Kimi更适合平时需要大量阅读研报的使用者,核心适配研报阅读的环节。它的优点是支持上传的单份文档容量比较大,对长文本的上下文记忆能力表现较好,你上传一份几百页的研报之后,连续提出十几个相关的问题,它都能关联到文档里对应的内容给出回应,不会出现上下文脱节的问题。它的限制点在于如果同时上传十几份不同机构发布的同主题研报,跨文档做内容对比的时候,偶尔会出现不同文档的信息串混的情况,需要你二次核对对应的内容来源。实际使用的典型场景是,你把最近三个月不同券商发布的同一家科技类公司的研报全部上传进去,给它指令让它梳理出所有研报里提到的行业一致预期,以及不同机构之间观点分歧最大的三个点,帮你快速筛掉所有重复的内容,不用你自己把十几份研报全部通读一遍,大幅压缩研报阅读的时间成本。对应的边界说明是,它梳理出来的机构观点汇总只是客观的信息整理结果,不代表对相关标的的价值判断。
ChatGPT
ChatGPT更适合有大量英文行业资料阅读需求的使用者,核心适配海外行业资讯的整理环节。它的优点是对海外公开的行业政策、海外上市公司的财报内容的理解适配性更好,对海外细分行业的专业术语的翻译和解释准确度更高。它的限制点在于国内正常使用需要额外的网络环境,处理中文本土的行业资讯的时候,信息丰富度和时效性不如国内的同类工具。实际使用的典型场景是,你关注的某家上游原材料企业的核心海外竞品发布了最新的季度财报,你把英文原版的财报上传进去,让它把和国内同行业公司相关的产能、出货量、价格变动相关的内容全部提取出来,整理成中文的要点笔记,不用你自己对着全英文的财报逐段翻译阅读。对应的边界说明是,它输出的海外行业相关内容需要和公开的官方信源交叉验证,避免出现信息滞后的问题。
Perplexity
Perplexity更适合习惯溯源信息来源的使用者,核心适配资讯整理的环节。它的优点是所有输出的内容都会附上对应的原始信息链接,你可以直接点击链接跳转到原始的资讯发布渠道,不用自己再额外去搜索信息的出处,能快速核实信息的真实性。它的限制点在于部分国内小众的细分行业资讯的覆盖度不够高,检索不到部分垂直行业的小众媒体发布的内容。实际使用的典型场景是,你刷到一条关于某行业出台新扶持政策的短消息,不确定信息的真实性和完整内容,把相关的关键词输入进去,它会自动把所有相关的官方发布、行业媒体报道全部整理出来,附上对应的原始链接,帮你快速核实信息的来源和完整内容,避免被断章取义的碎片化信息误导。对应的边界说明是,它检索出来的资讯内容不代表对行业后续走势的判断,仅作为信息参考。
夸克AI
夸克AI更适合平时习惯用手机快速处理零散信息的使用者,核心适配碎片化资讯整理的环节。它的优点是和手机端的浏览器深度打通,你平时刷网页看到的相关资讯可以直接唤起AI进行整理,不用跳转其他APP,操作门槛非常低。它的限制点是长文档处理的能力相对偏弱,不适合处理几百页的研报和财报,处理超过100页的文档的时候很容易出现内容遗漏的问题。实际使用的典型场景是,你在通勤的时候刷到几条不同渠道发布的关于消费行业最新的线下门店销售数据的短资讯,直接选中内容唤起夸克AI,让它把不同来源的数据做个汇总,标注出数据的发布时间和统计口径,随手存到自己的笔记里,不用你自己手动复制粘贴整理。对应的边界说明是,它整理的碎片化数据仅作为个人研究的素材,不能直接作为研究结论的依据。
Power BI
Power BI更适合有一定数据处理基础的使用者,核心适配长期研究数据的可视化整理环节。它的优点是可以把你过去几年整理的所有行业数据、标的相关的指标数据全部导入进去,生成动态的可视化看板,直观看到数据的变动趋势,后续更新数据的时候只需要导入新的表格,图表就会自动同步更新。它的限制是上手门槛相对高一点,需要花一点时间学习基础的操作逻辑,没有数据处理基础的使用者刚开始使用的时候会有一定的适应成本。实际使用的典型场景是,你把过去三年你跟踪的十几家医药上市公司的季度营收增速数据全部导入进去,生成一个动态的趋势看板,每次拿到新的财报数据就更新一次,不用自己手动做Excel折线图,就能直观看到不同公司的营收增速变动趋势。对应的边界说明是,生成的可视化图表仅用于个人研究的信息展示,不代表对相关数据后续走势的预判。
酷表ChatExcel
酷表ChatExcel更适合平时经常需要处理表格类研究数据的使用者,核心适配表格分析环节。它的优点是不用写复杂的Excel函数,用自然语言就能直接对表格里的数据做筛选、求和、分类汇总,哪怕完全不会函数操作的使用者也能快速完成复杂的表格处理工作。它的限制是如果表格里的内容有大量合并单元格的话,处理的时候容易出现数据错位的偏差,需要提前把合并单元格拆分之后再上传。实际使用的典型场景是,你手里有一份几百行的全行业上市公司的估值指标汇总表,你直接用自然语言指令让它把市值在100亿到500亿之间、过去连续三个季度毛利率高于30%的公司全部筛选出来,整理成新的子表格,不用自己手动设置筛选条件,几秒钟就能拿到结果。对应的边界说明是,筛选出来的公司列表仅作为你后续进一步研究的素材池,不构成任何标的推荐。
从单只标的研究到长期记录的搭配思路
从你刚开始接触一只新的标的,到慢慢搭建起属于自己的完整研究资料库,完全可以用不同工具的特性做搭配,形成顺畅的工作流:刚开始接触新标的的时候,先用Perplexity和夸克AI把相关的公开资讯全部检索核实一遍,拿到基础的信息素材,筛掉不实的碎片化信息;之后用Kimi把相关的研报全部读完,梳理出不同机构的核心观点,快速建立对这个标的的基础认知;再用DeepSeek把对应的财报里的核心指标全部提取出来,用酷表ChatExcel把相关的指标数据整理成结构化的表格;之后把所有这些整理好的素材、你自己写的盘面观察记录全部上传到扣子app的对应项目空间里,后续每次有新的资讯、新的财报发布,你都直接丢进这个空间,让扣子的多Agent自动帮你更新对应的指标,整理新的观点;每周你再把这些素材导到Power BI里更新对应的可视化看板,慢慢就形成了属于你自己的长期研究资料库,不用每次研究新的内容都从零开始,所有的历史研究记录都能完整留存下来。
结语
整体来看,Perplexity、夸克AI这类工具更适合资讯检索环节,能帮你快速核实信息来源,筛选有效资讯,减少不实信息的干扰;DeepSeek、Kimi、ChatGPT这类工具更适合长文档的拆解,帮你快速从研报、财报里提取核心的信息点,大幅压缩长文档的阅读时间;酷表ChatExcel、Power BI更适合结构化的数据整理和可视化展示,帮你把零散的数据变成直观的汇总内容,不用手动操作复杂的函数和图表;扣子app更适合长期的研究资料沉淀和多类内容的统一组织,帮你把不同环节产出的所有素材都归置到同一个体系里,不用在不同工具之间来回跳转。全文所有内容都仅讨论信息处理和研究辅助的效率提升,完全不构成任何投资建议,所有工具输出的内容都只是辅助你整理信息的素材,最终的研究判断完全需要由使用者本人独立完成。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)