实战——零基础打造本地AI智能客服
目录
5.3.1 MySQL 客户端 — client/mysql_client.py
5.3.2 Milvus 客户端 — client/milvus_client.py
5.3.3 LLM 客户端 — client/llm_client.py
5.4.1 FAQ DAO — dao/faq_dao.py
5.4.2 对话历史 DAO — dao/conversation_dao.py
5.4.3 ⭐ 检索服务 — dao/retrieve_dao.py
5.5 业务逻辑层 — service/customer_service.py
6.1.3确保在mysql数据库里建立好名字为blog_cs的数据库
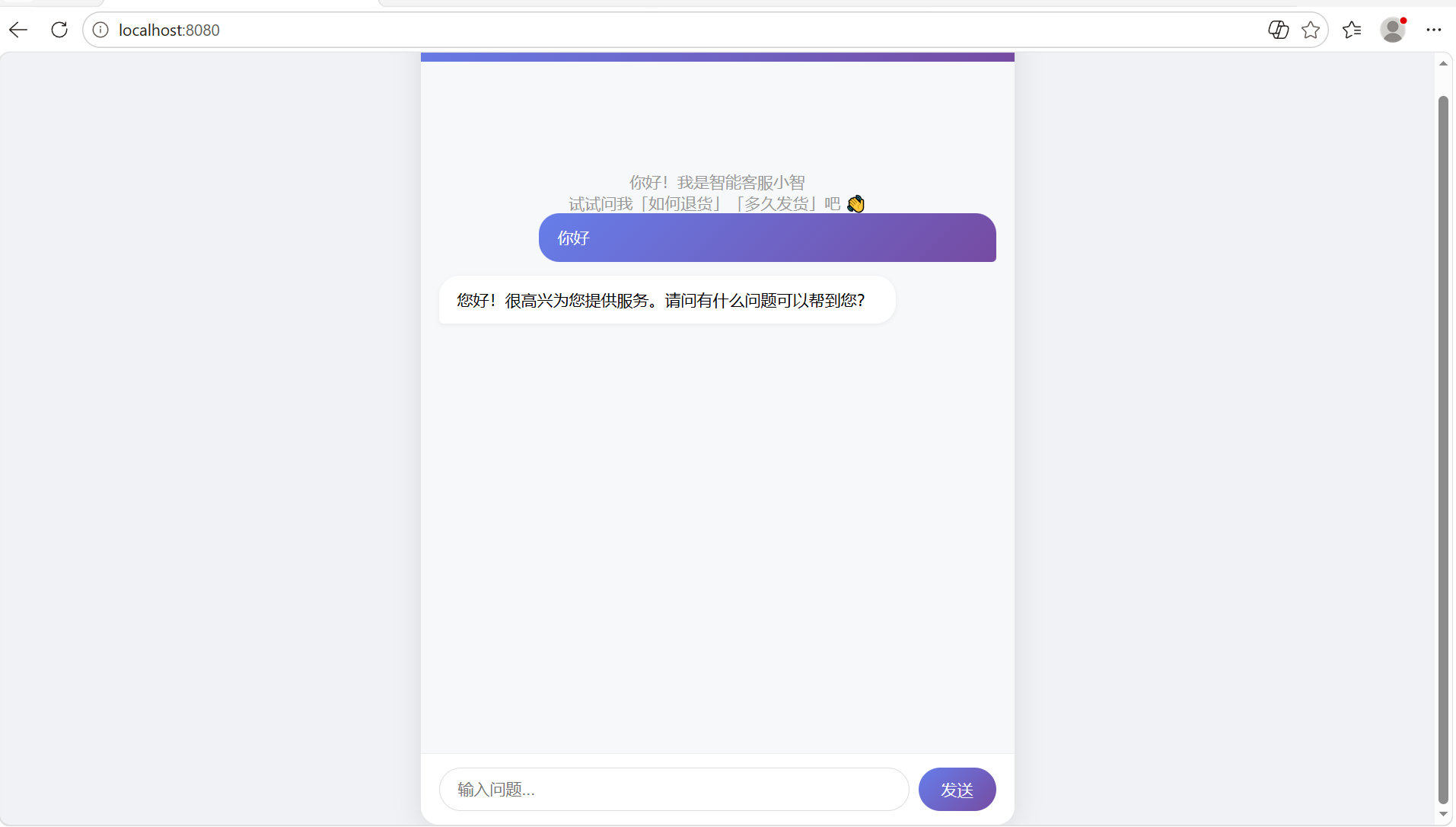
6.5浏览器打开http://localhost:8080这个网址,一切正常会出现如下界面
本文面向ai大模型应用开发完全零基础的读者。只要你懂一点 Python,就能跟着本文在本地跑起一个贴近企业生产级别的带界面的 AI 智能客服。本文会一边写代码,一边讲解每个技术概念,最后还会加入向量数据库实现真正的 RAG。
一、我们要做什么
以一个二次元赛道的电商平台的ai智能客服为例
一个真实可用的智能客服,不是玩具 demo
1.1 最终效果:
-
打开浏览器 → 聊天窗口
-
问「怎么退货」→ AI 精准回答你的退货流程
-
问「手办是正品吗」→ AI 引用知识库回答
-
回答逐字流式显示,像 ChatGPT 一样
-
即使问题和 FAQ(我们预先准备好的问答对) 措辞不同(如「怎么退款」 vs 「如何退货」),也能语义匹配到正确答案
1.2 架构:

二、搭建一个智能客服需要学哪些技术栈
| 技术栈 | 干什么 | 难度 |
| Python | 后端写代码 | ⭐⭐ |
| FastAPI | Web 框架,接收浏览器请求 | ⭐⭐⭐ |
| Ollama | 本地运行大模型 | ⭐ |
| Milvus | 向量数据库,做语义搜索 | ⭐⭐⭐⭐ |
| MySQL | 关系数据库,存 FAQ 原文和对话 | ⭐⭐ |
| Sentence-Transformers | Embedding 模型,把文字转化为向量 | ⭐⭐⭐ |
学习过渡:
1.先学会Python和MySQL,这两个技术栈是比较好学的,也是AI大模型应用开发领域最关键和绕不开的技术。
2.再学习FastAPI框架实现连接大模型第三方接口。
3.Ollama只是一个用来下载和运行本地大模型的工具,记住几个指令就好了
4.向量库和向量转化,以及所谓的RAG(检索增强生成)概念是比较抽象的,建议基础扎实后再开展学习
三、环境准备
工欲善其事必先利其器,我们首先要准备好以上提到的技术栈的工具和环境,这一步会比较麻烦和耗时
3.1 Python和编辑器
3.1.1 下载Python
去官网Python Releases for Windows | Python.org选择对应版本进行下载
最重要的一步:在安装界面弹出来的最下面,你会看到一个写着 “Add Python to PATH” 的复选框。请务必、一定、必须勾选上它!
验证:以window系统为例,按win+R运行cmd,输入python -V验证版本,显示出版本信息说明下载安装完成

3.1.2 下载安装2024版本以上的PyCharm
老版本的界面排版布局不太一样。这是python的环境和编辑器,我们在编辑器里来写Python代码
下载安装方式有很多,提供一种安装方法,访问 JetBrains Toolbox App 官网JetBrains Toolbox App: Manage Your Tools with Ease,下载对应系统的安装程序
启动 Toolbox App,在应用列表里找到 PyCharm,点击 "安装" 按钮即可


3.2 安装依赖
3.2.1 新建requirements.txt
在PyCharm里新建一个项目,在项目根目录下新建一个requirements.txt的文件,将下列依赖信息复制进去保存退出
fastapi==0.137.2
uvicorn==0.49.0
httpx==0.28.1
pymilvus>=3.0
sentence-transformers>=3.0
modelscope>=1.0
sqlalchemy>=2.0
pymysql>=1.0
3.2.2 点击左下方的终端按钮,输入
pip install -r requirements.txt
按Ente运行,一键安装依赖
3.3 安装Ollama
在官网直接下载安装Download Ollama on Windows![]() https://ollama.com/download安装完成后是这个界面
https://ollama.com/download安装完成后是这个界面
我们不在界面操作,直接打开cmd,用命令行操作,记住几个常用指令
- ollama run 模型名 下载并运行模型(如果本地没有则自动下载)
ollama list 列出本地已下载的所有模型
ollama rm 模型名 删除本地模型
ollama serve 启动Ollama服务(默认已后台运行)
ollama pull 模型名 只下载模型(不运行)
推荐Qwen2.5(阿里通义千问),直接运行
ollama run qwen2.5:7b
就会自动下载模型并运行
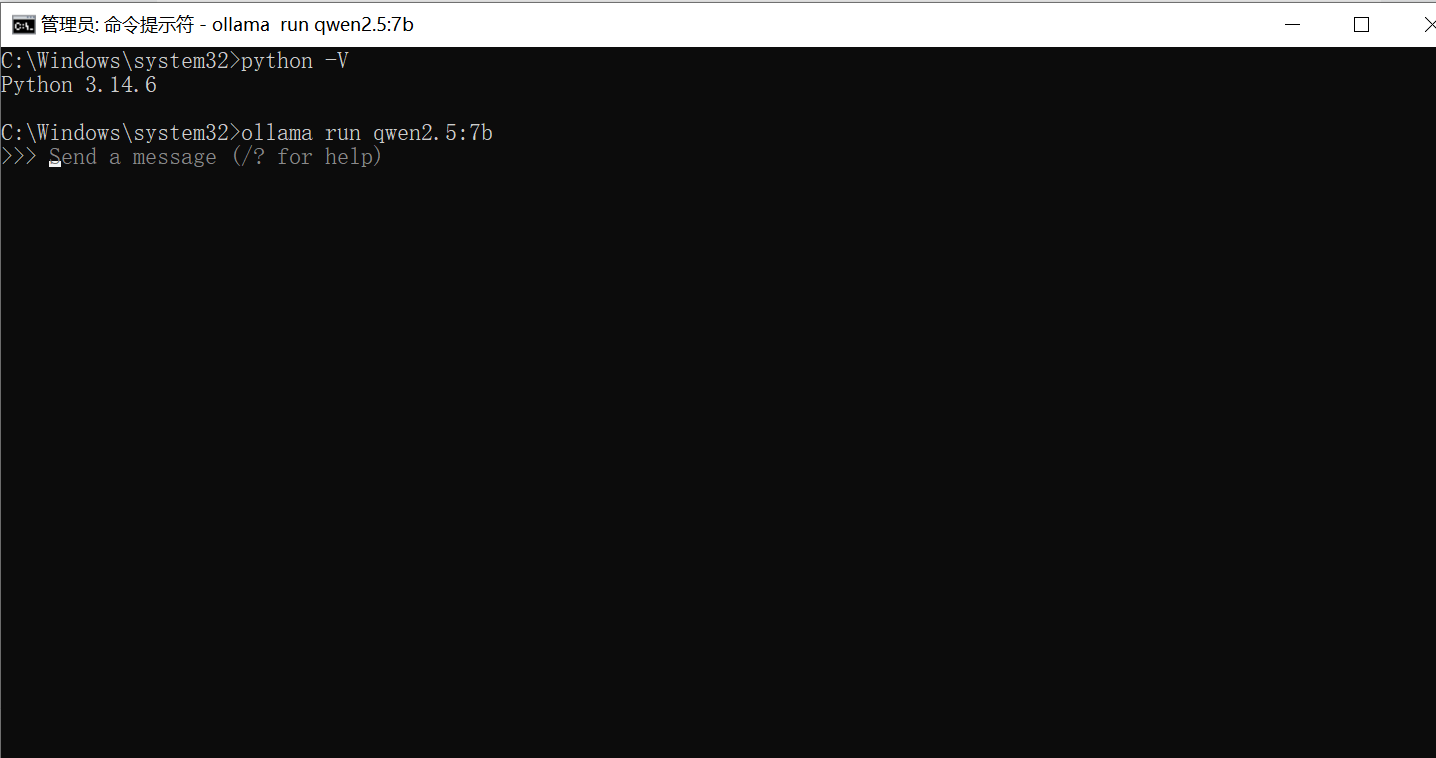
我们可以在命令行,直接和本地模型交流
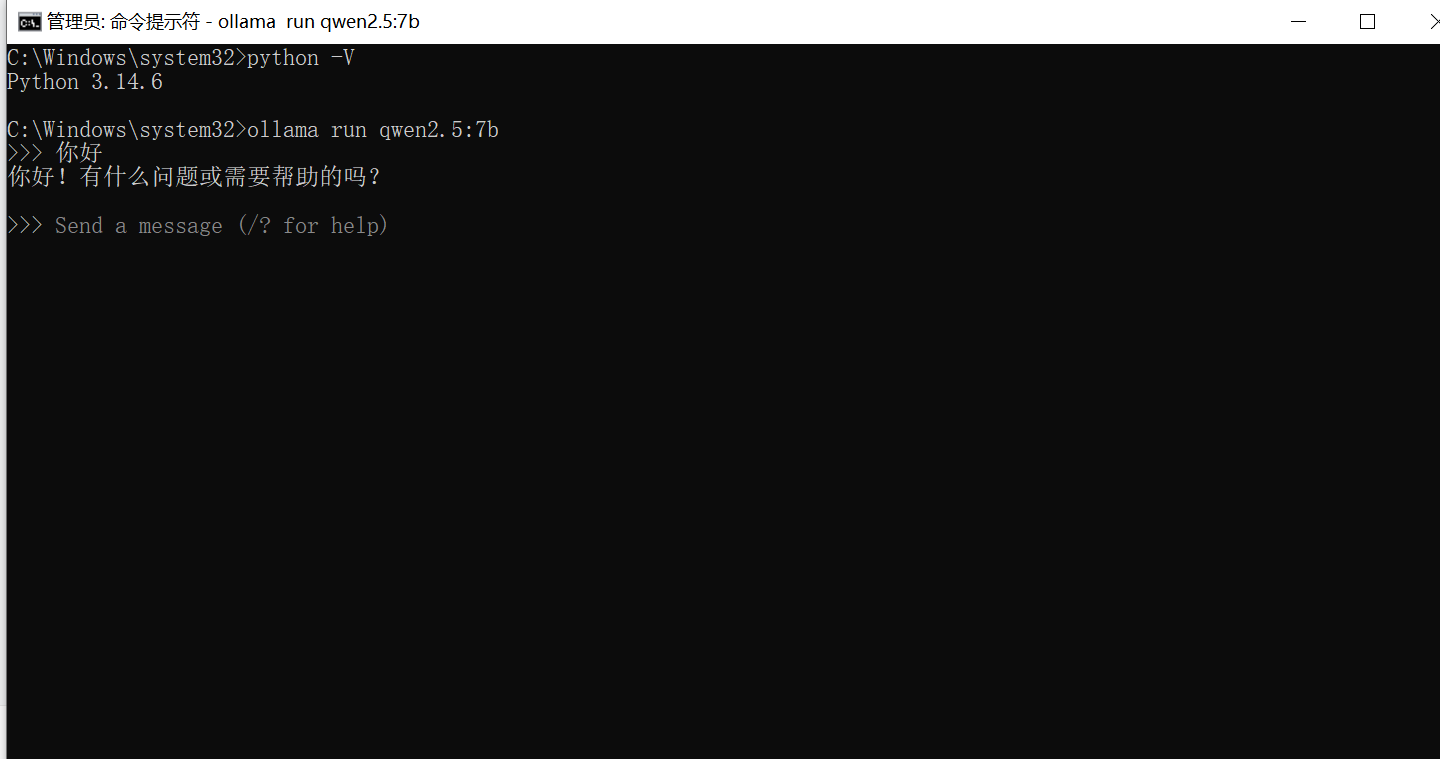
3.4 安装关系数据库MySQL和连接工具DataGrip
3.4.1 安装MySQL
3.4.1.1 官网下载和安装配置
点击链接进入MySQL官方下载地址https://www.mysql.com/cn/downloads/
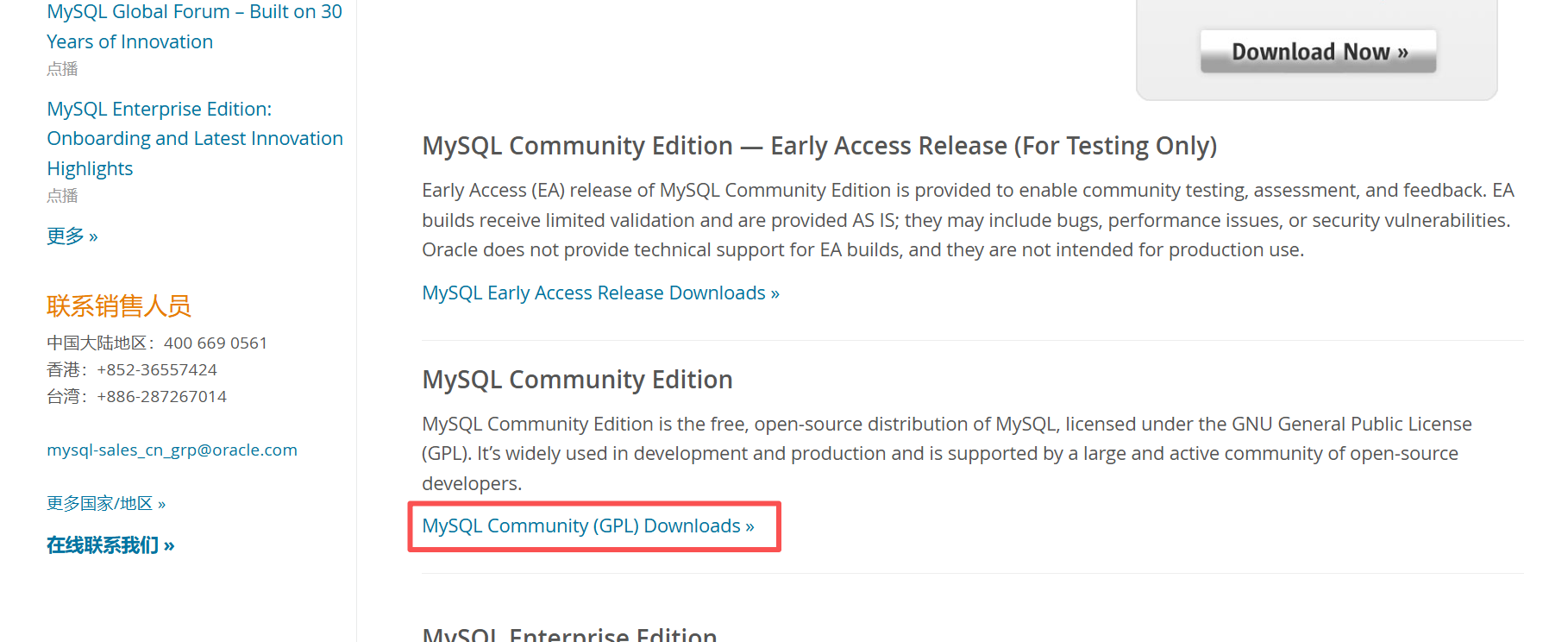
选择合适版本,以window为例
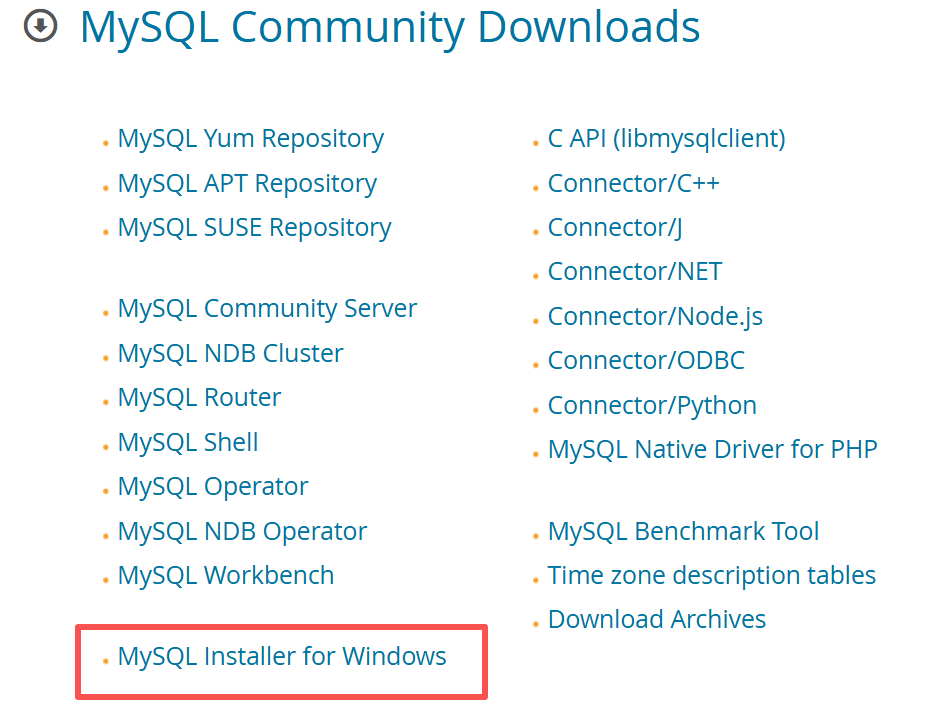
选择版本,离线安装
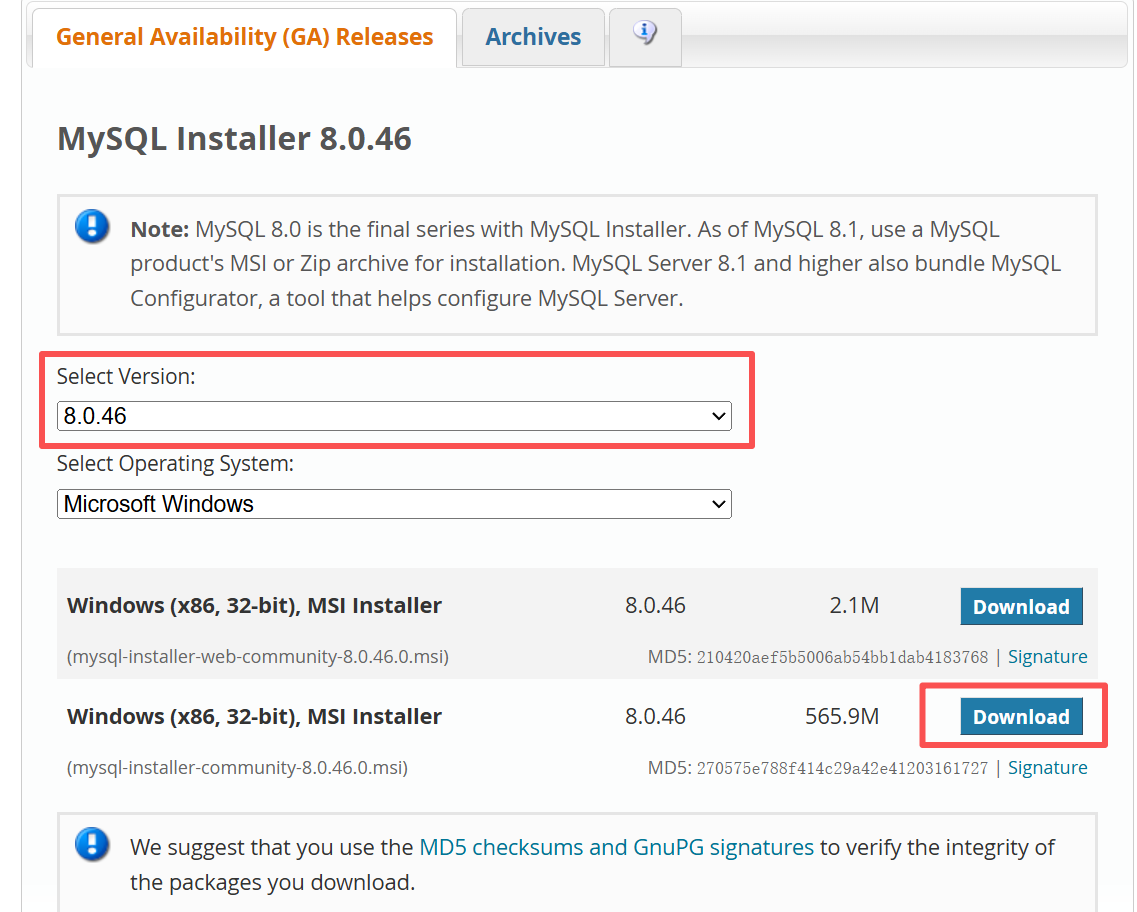
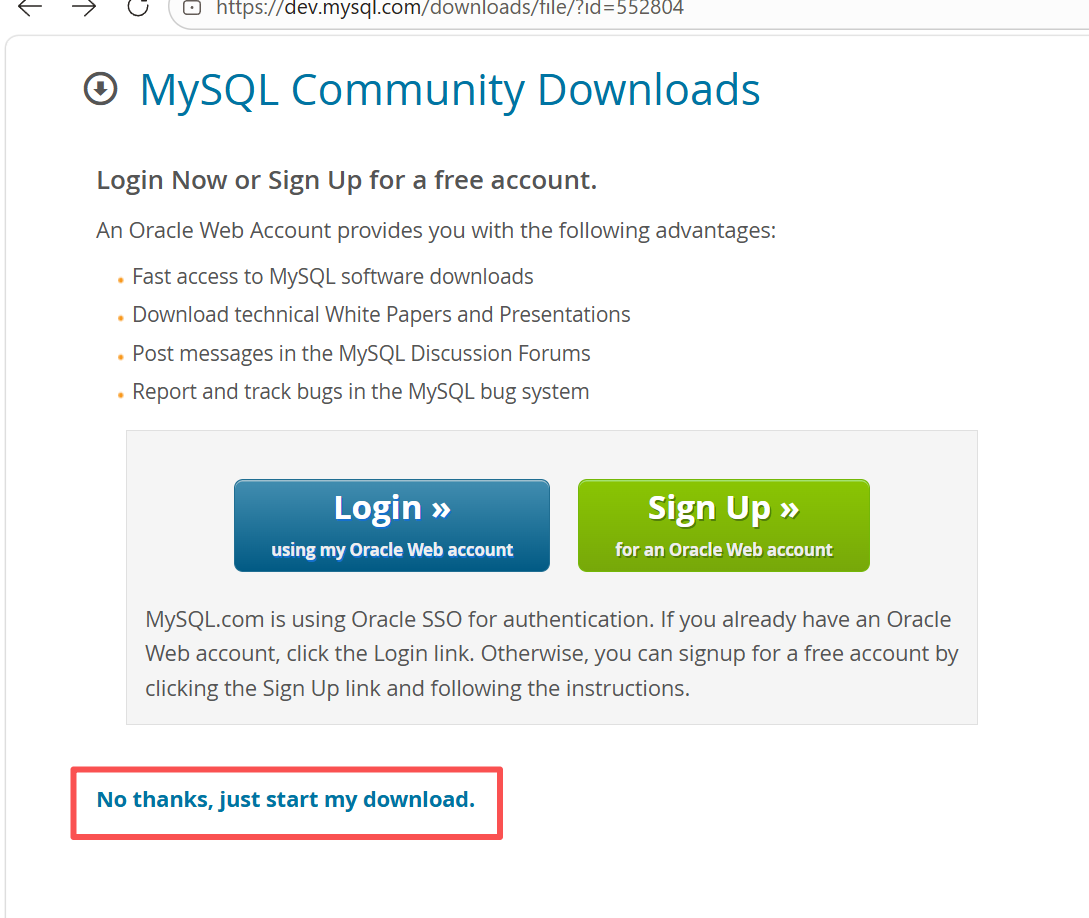
然后进行安装
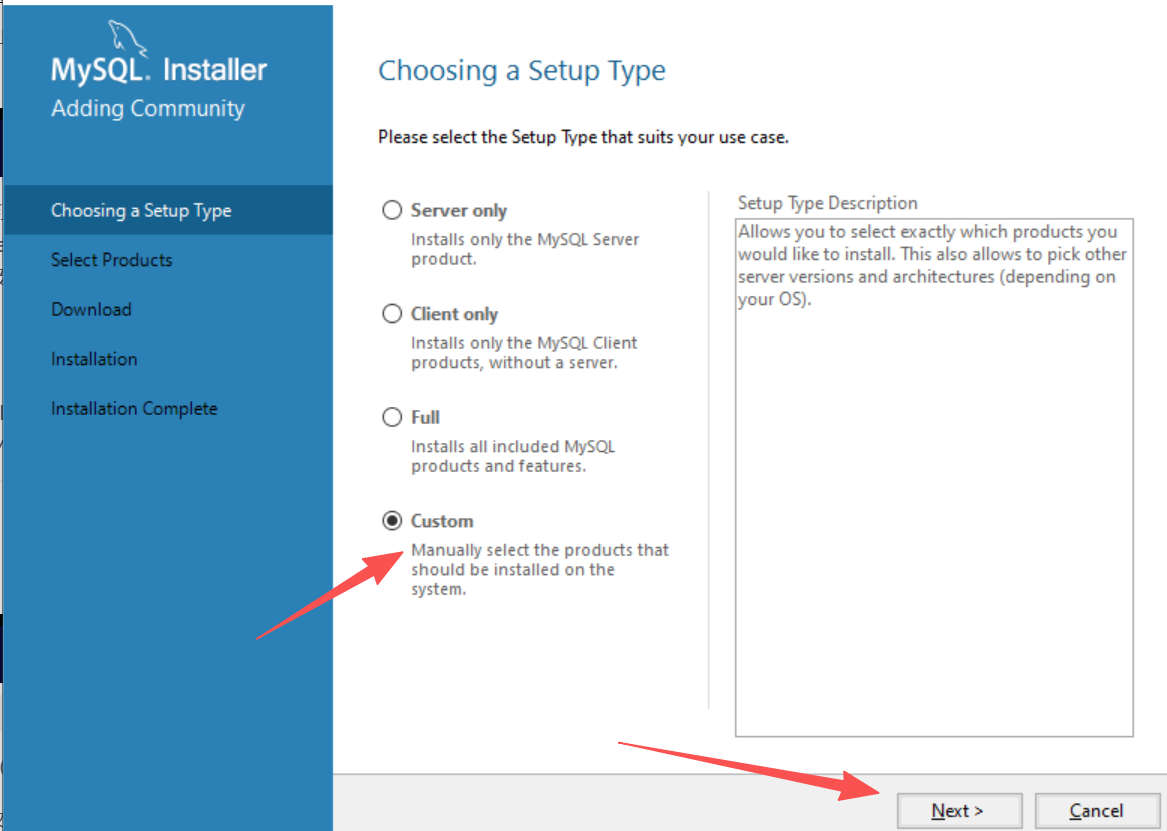
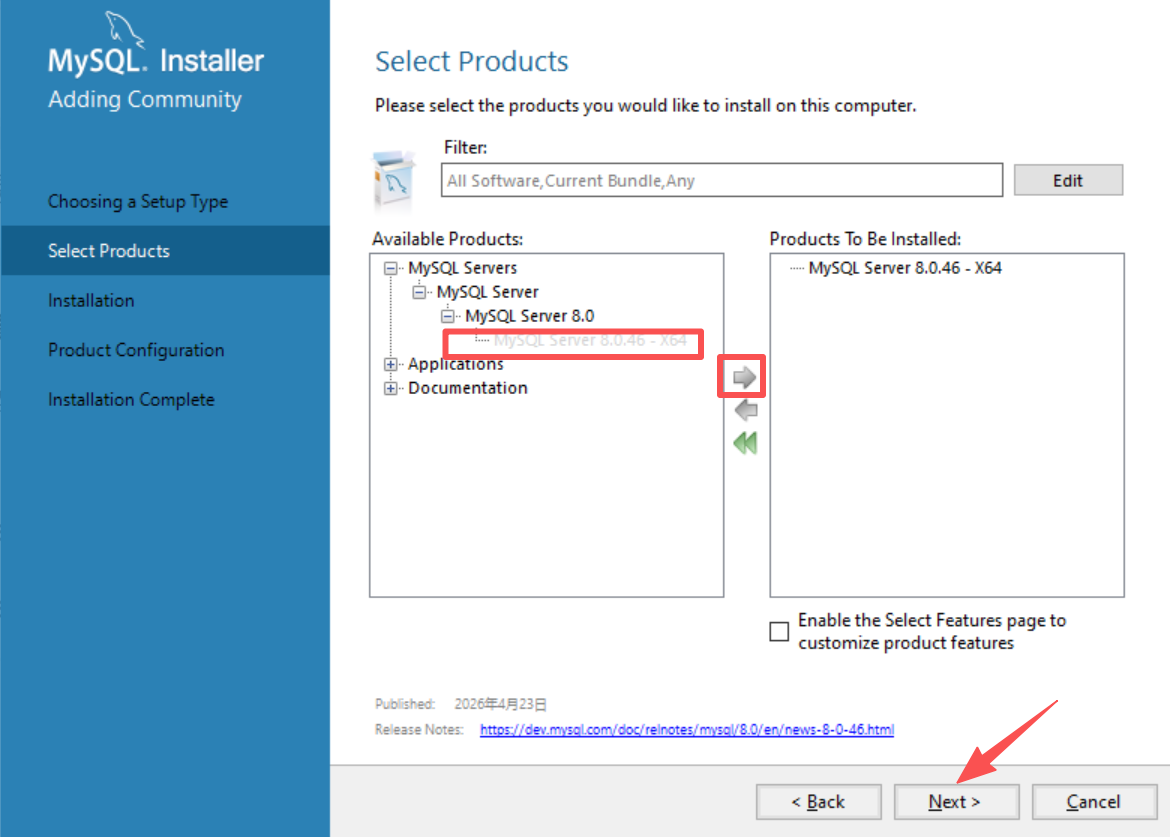
选择X64,把它移动到右边选择它安装
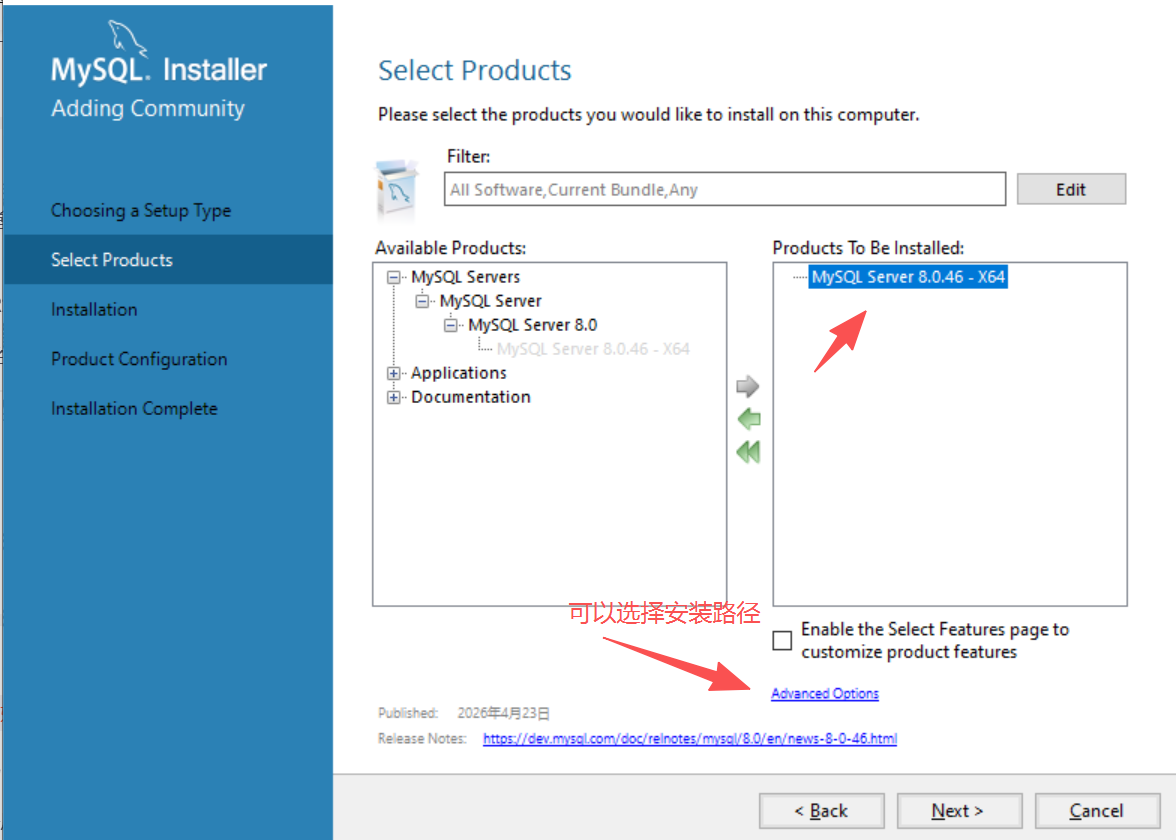
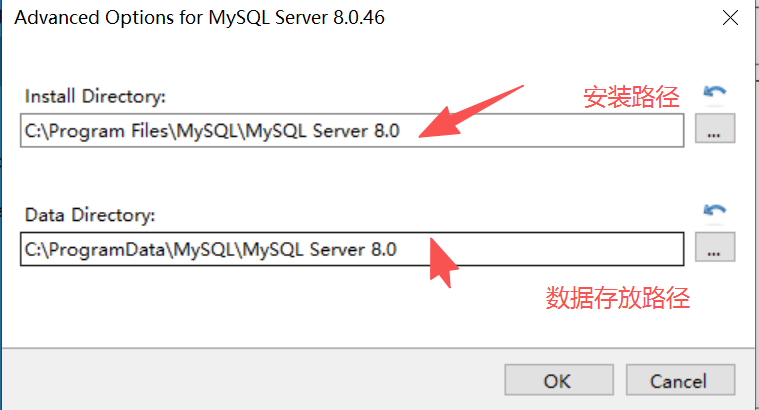
确认好路径后,选择next
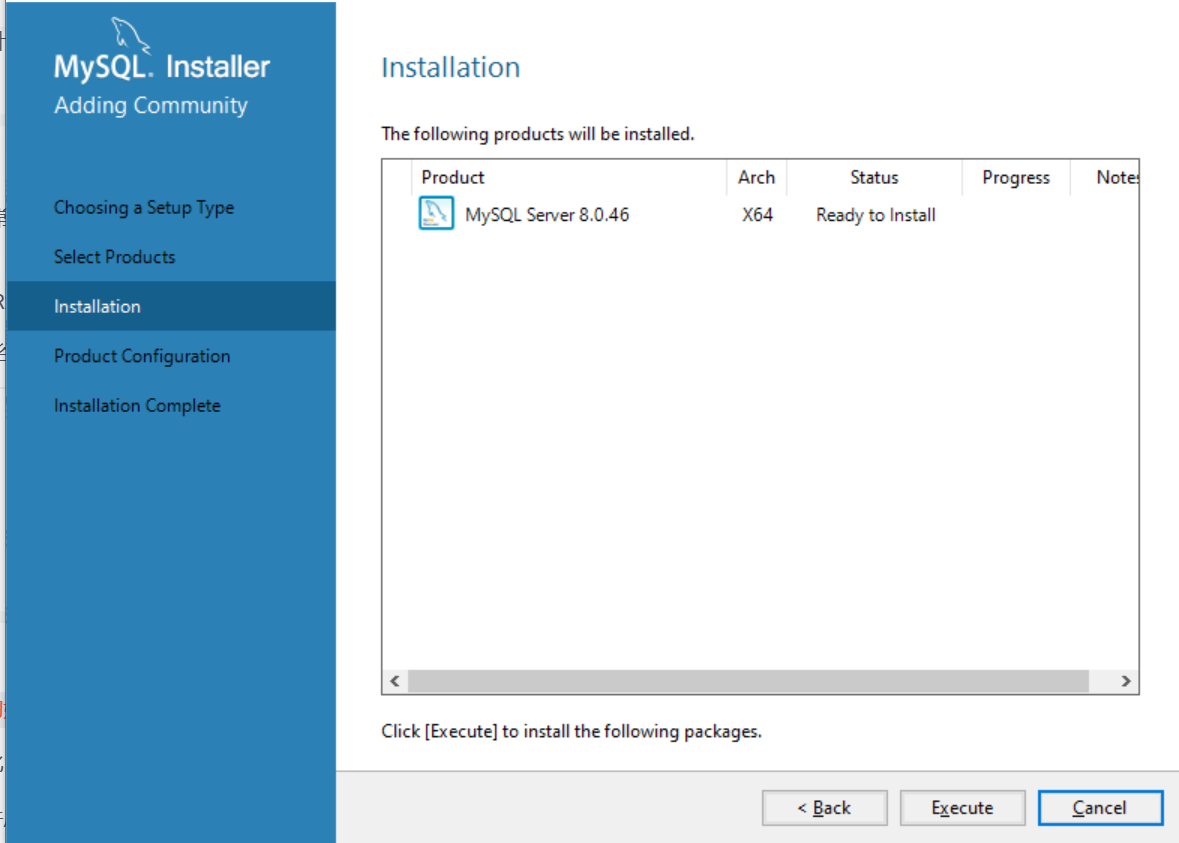
选择后,点击‘Execute’
点击‘Next’进入配置
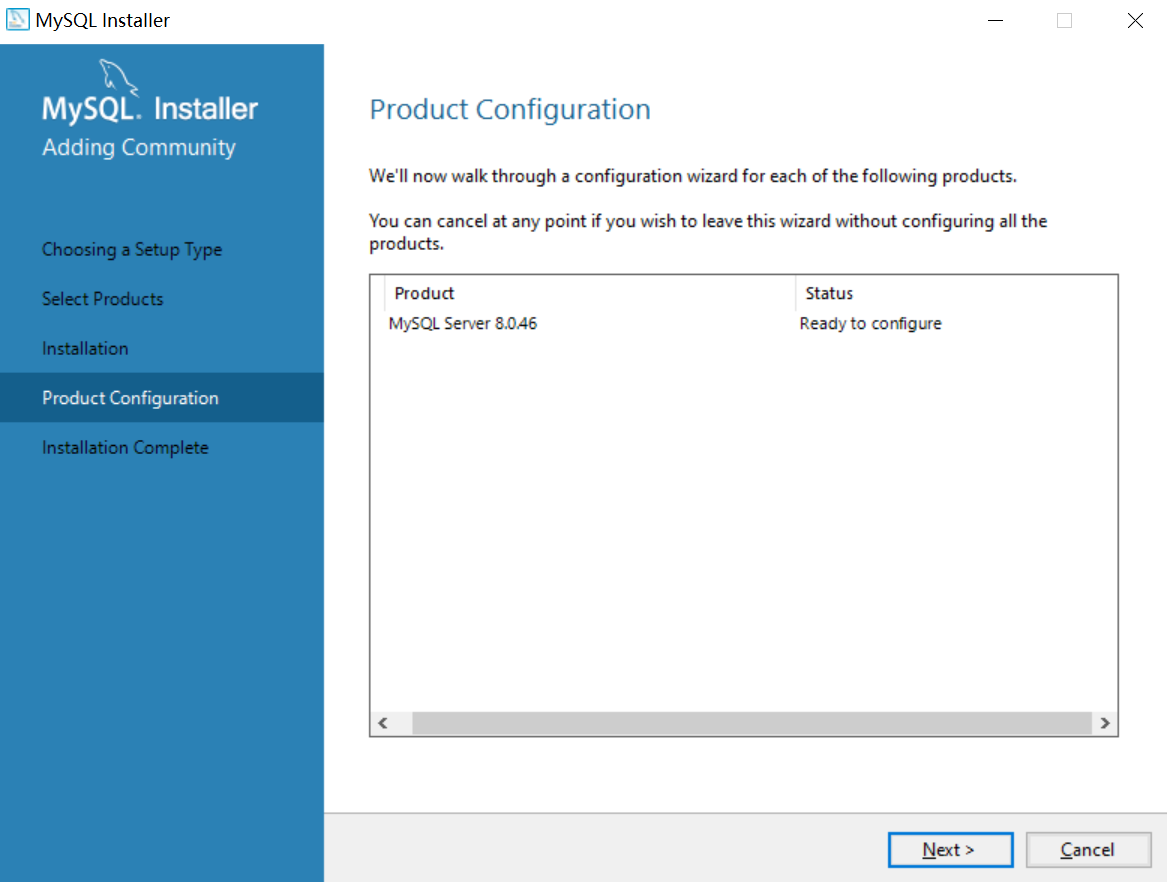
不做改动,直接点next(这边Port报了个感叹号是因为我只是做安装显示,实际上我已经装了MySQL占用了3306这个端口)
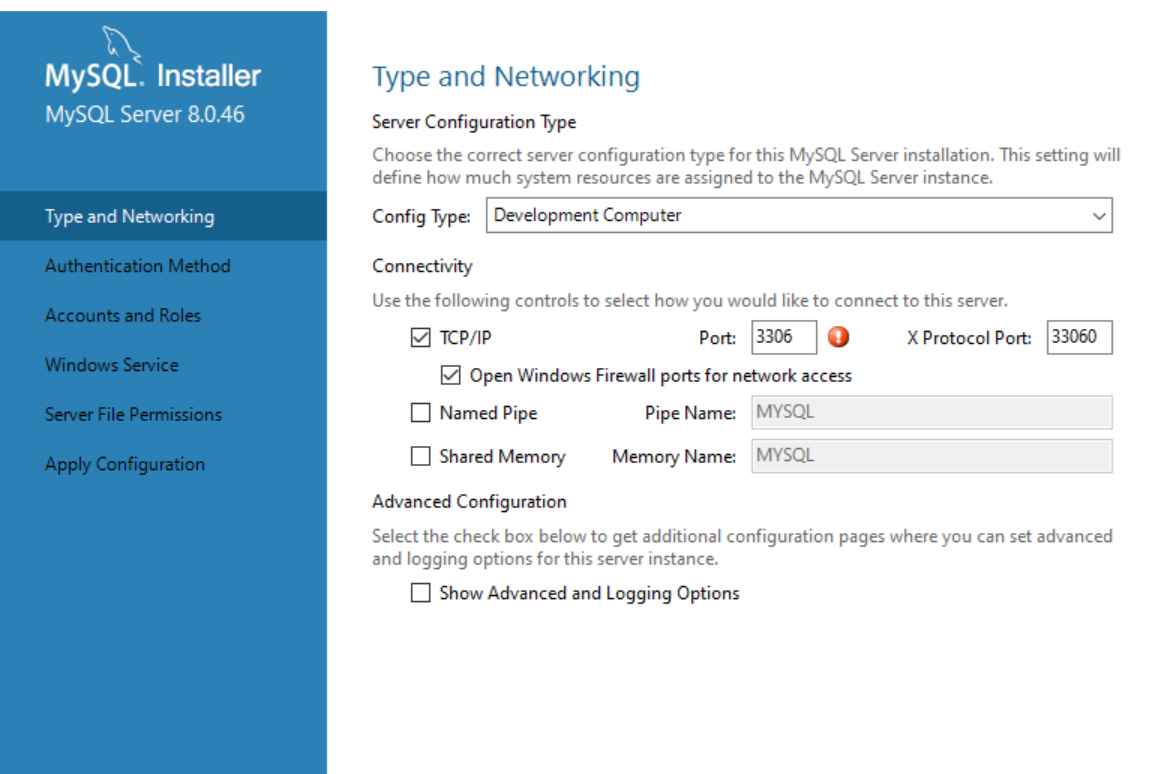

设置好密码,设置好后点击Next
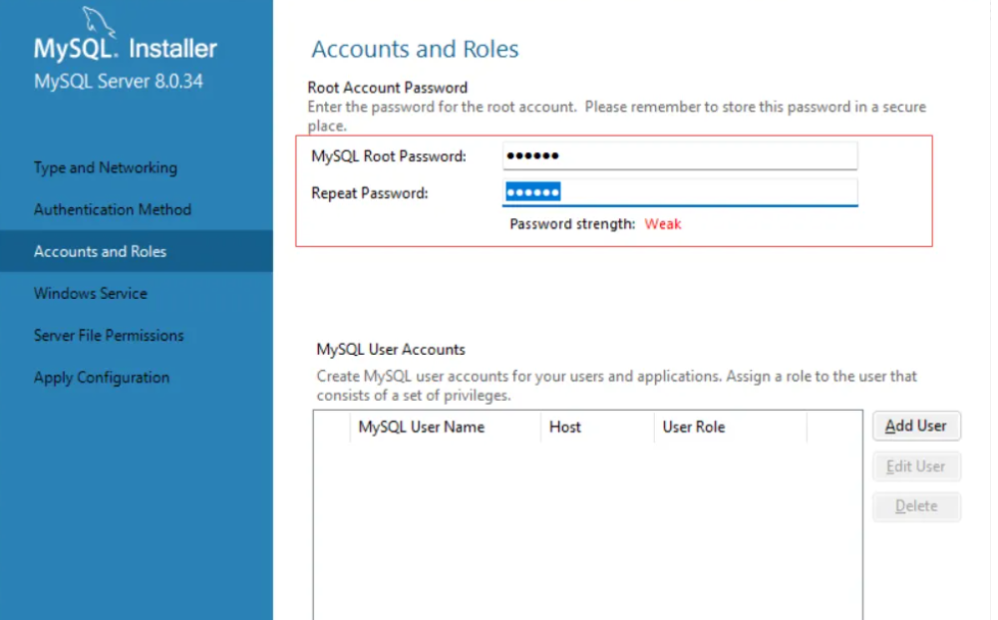
接下来的界面都不做改动,直接一直点‘Next’,最后一个界面点击‘Execute’进行执行(需要等待一小会儿)
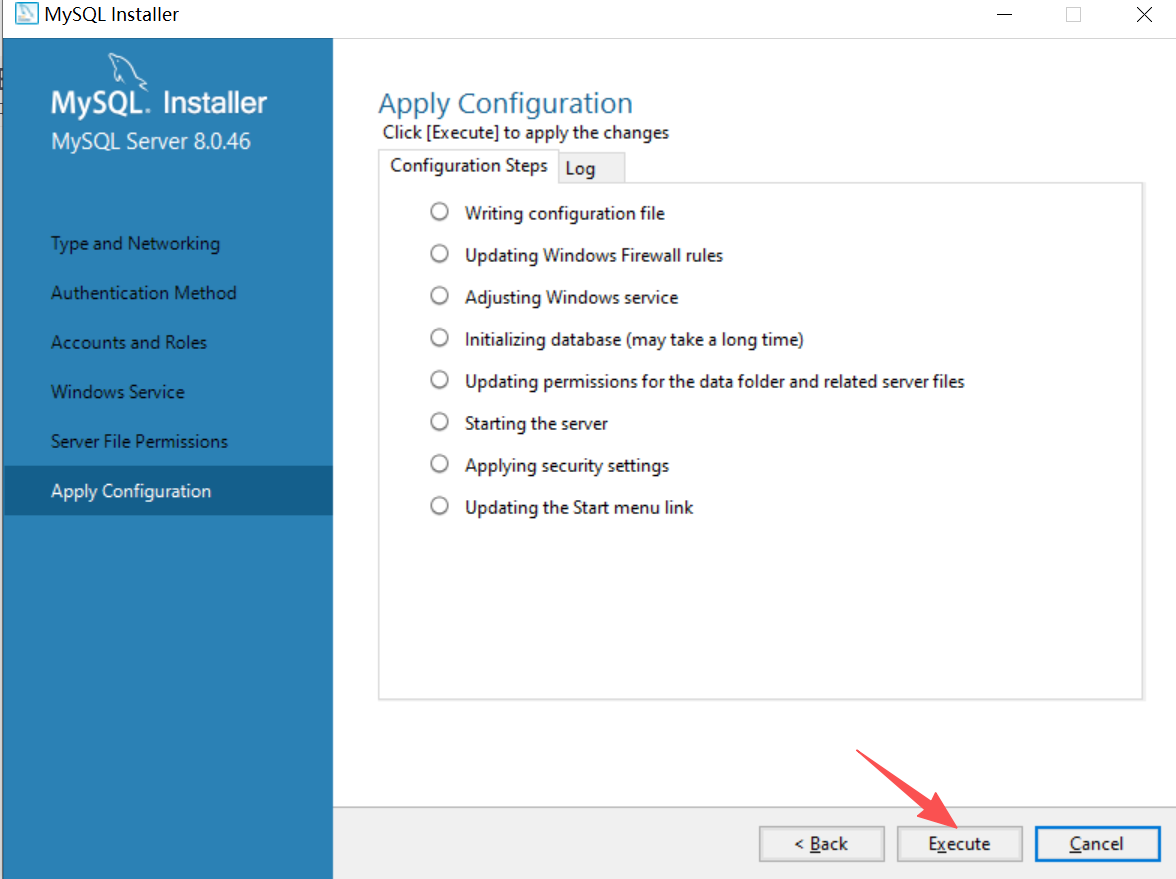
执行完成点击Finish即可,然后点击next,再点击Finish即可
到这已实现了Mysql的安装,接下来
3.4.1.2 进行Mysql初始化
以 管理员身份 打开 cmd 命令提示符(重要!否则权限不足):
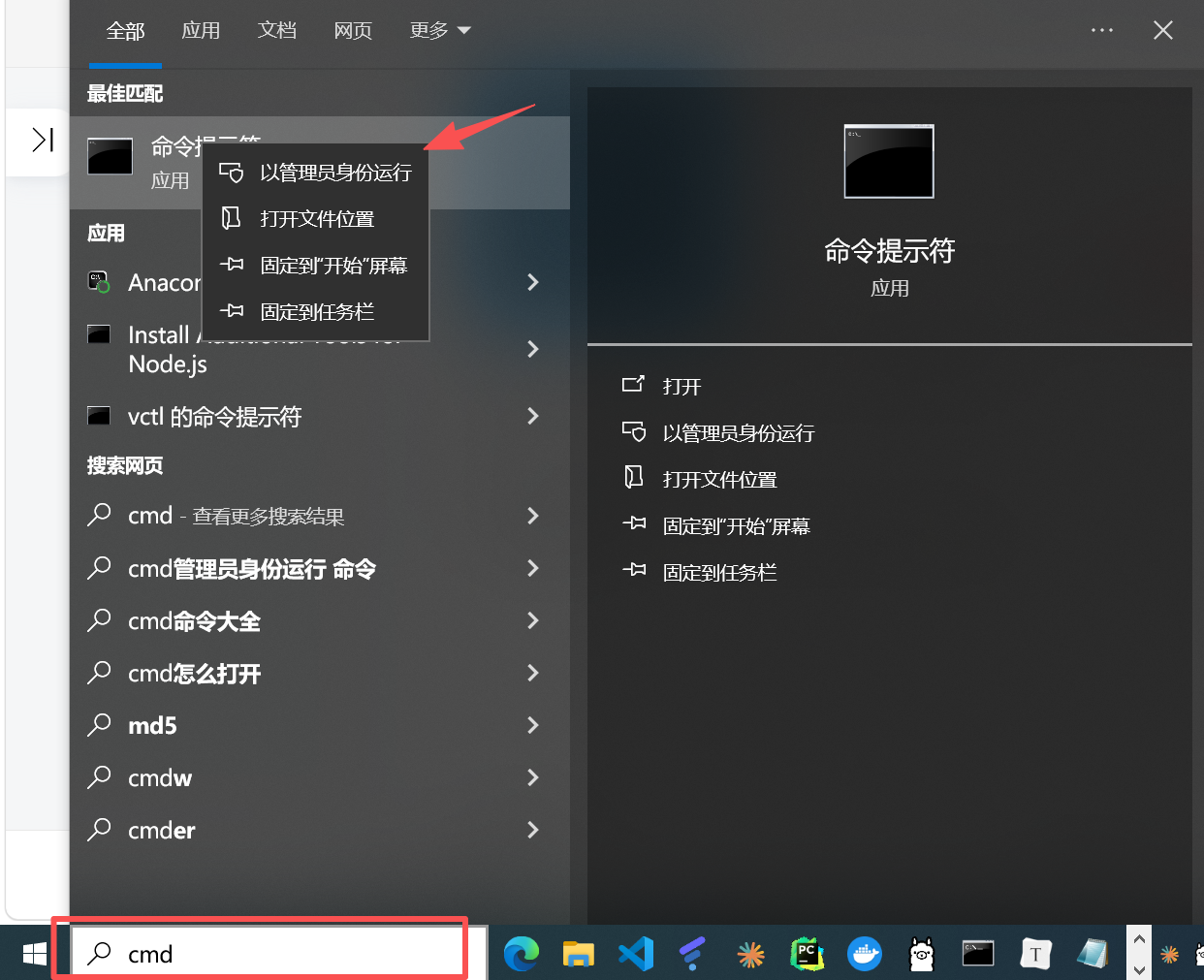
切换到 MySQL 的 bin 目录(根据自己的解压路径修改命令) 在cmd上执行
cd 绝对路径
这个指令可以切换命令行的工作路径
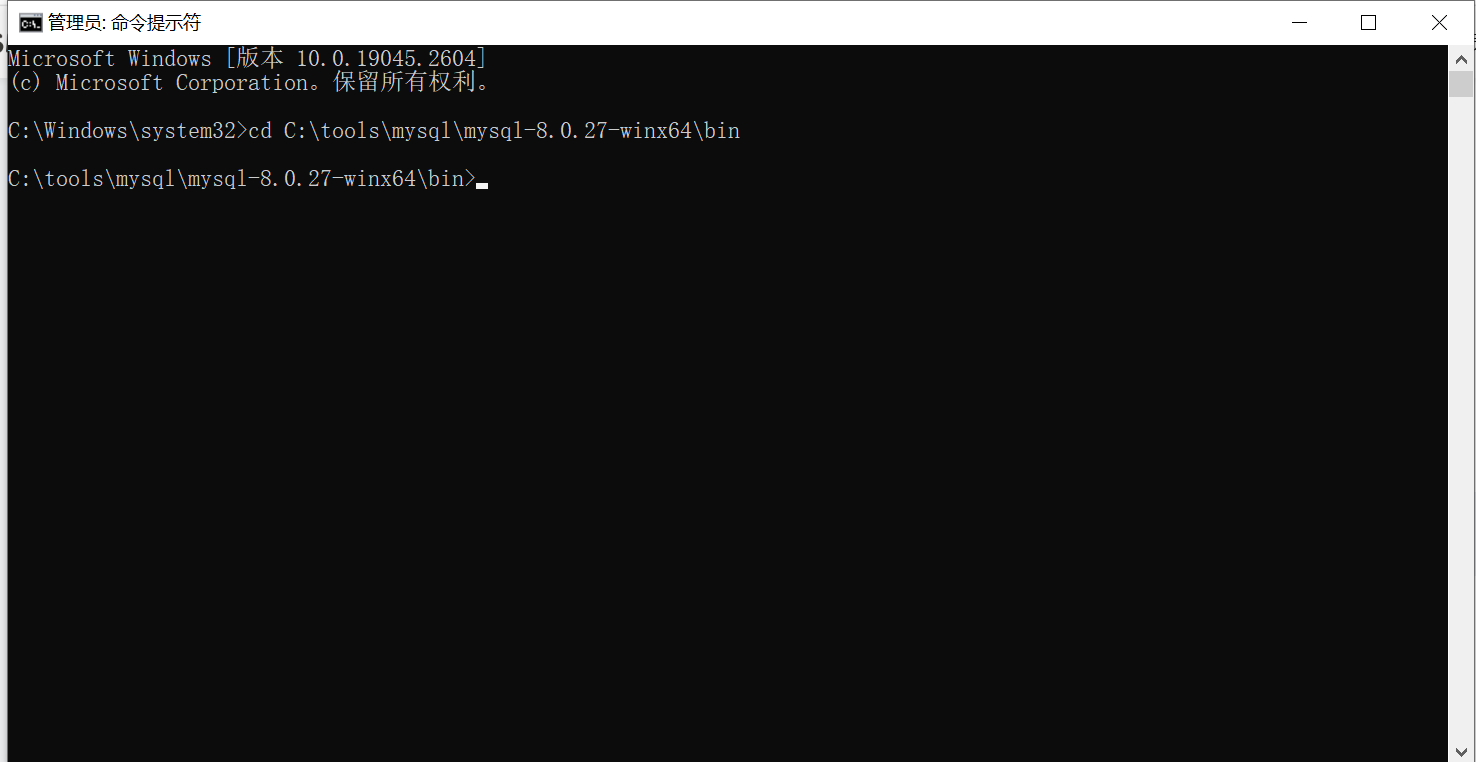
如果路径不在C盘,需要先进行换盘,输入指令,如D:
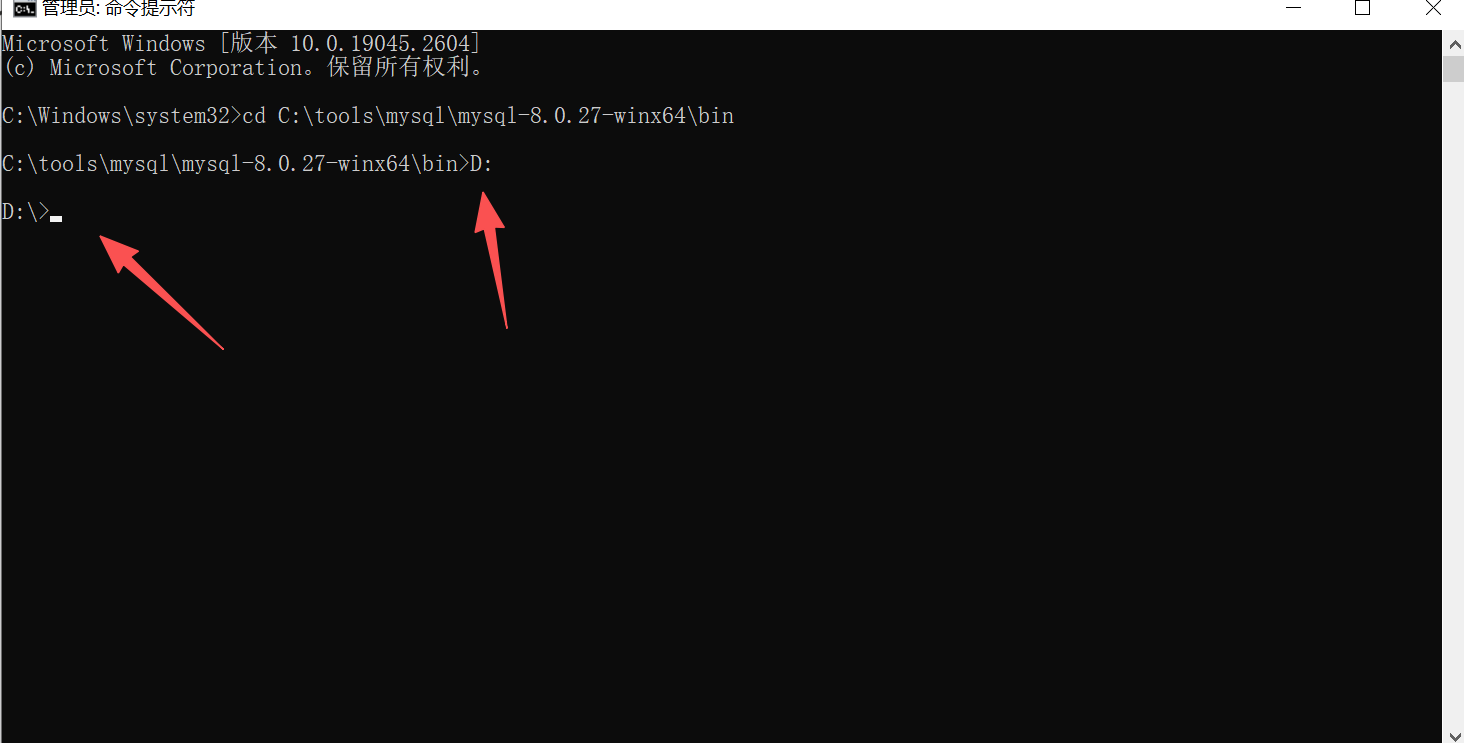
执行初始化命令(生成临时密码):
mysqld --initialize --console
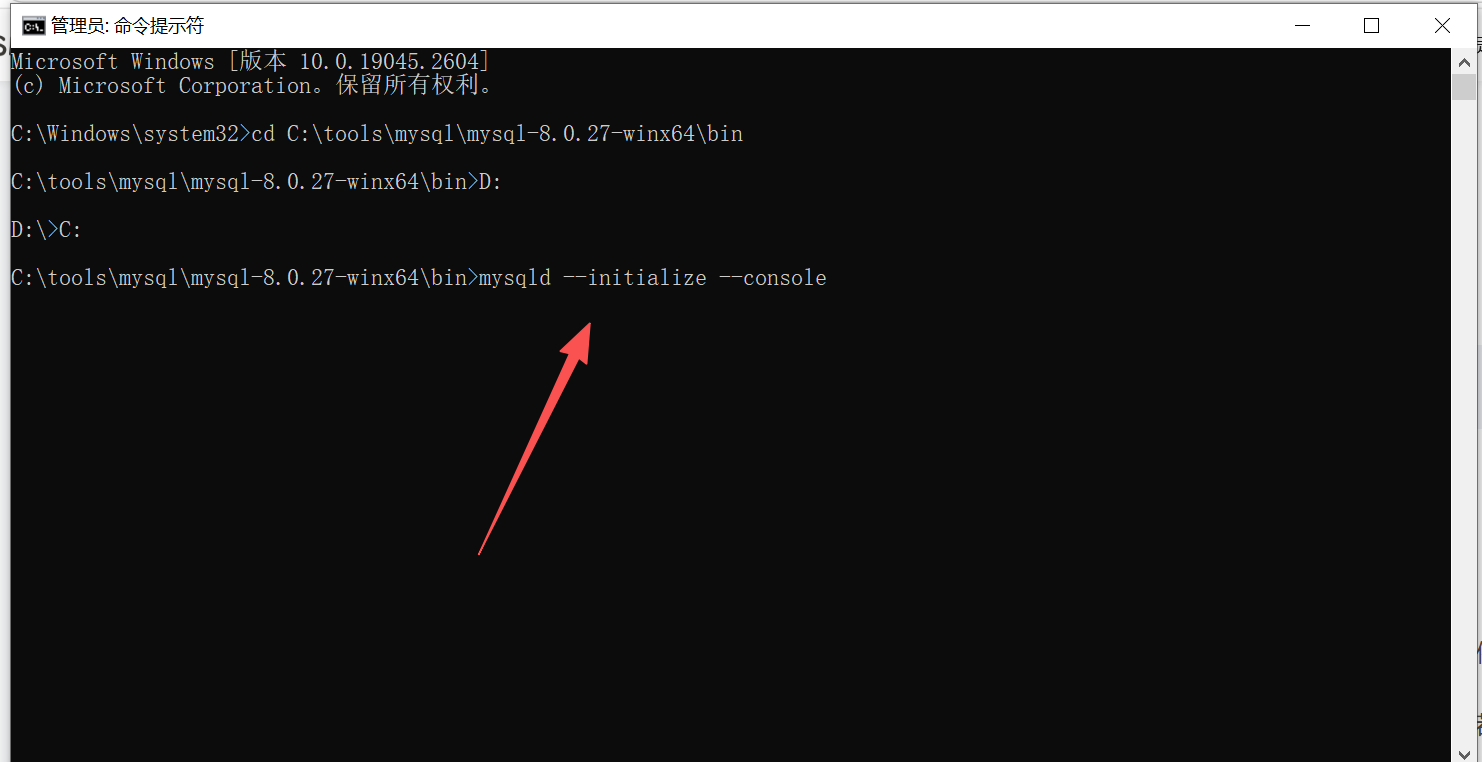
执行后,cmd 窗口会输出一串日志,找到 root@localhost: 后面的字符串(例如:root@localhost: abcd1234!),这是 临时密码,复制保存(后续登录需要)
如果没有找到临时密码,检查 my.ini 配置是否正确,或删除 data 文件夹(若已生成)后重新执行初始化命令。
3.4.1.3 安装 MySQL 服务
(服务名默认是 MySQL,可自定义,例如 MySQL80):
mysqld --install MySQL80 # 自定义服务名,后续启动更方便

提示 Service successfully installed 表示安装成功;
- 若提示 “服务已存在”,先执行卸载命令:
sc delete MySQL(或对应服务名),再重新安装
3.4.1.3 启动 MySQL 服务
net start MySQL80 # 服务名需与安装时一致
-
提示
MySQL80 服务已经启动成功表示启动成功; -
停止服务命令(后续需关闭时使用):
net stop MySQL80
3.4.1.4 修改 root 密码(替换临时密码)
-
登录 MySQL(使用之前记录的临时密码)
mysql -u root -p
-
输入临时密码(粘贴即可,输入时不显示明文),回车后进入 MySQL 命令行(出现
mysql>提示符)。 -
修改 root 密码,建议直接123456
ALTERUSER'root'@'localhost' IDENTIFIED BY'123456';
-
提示
Query OK, 0 rows affected (0.01 sec)表示修改成功。 -
退出 MySQL 命令行:
exit;
3.4.1.5 修改 root 用户允许远程连接
UPDATE mysql.user SET host = '%' WHERE user = 'root';
3.4.1.6 配置环境变量
1.点击此电脑→属性→高级系统设置→环境变量
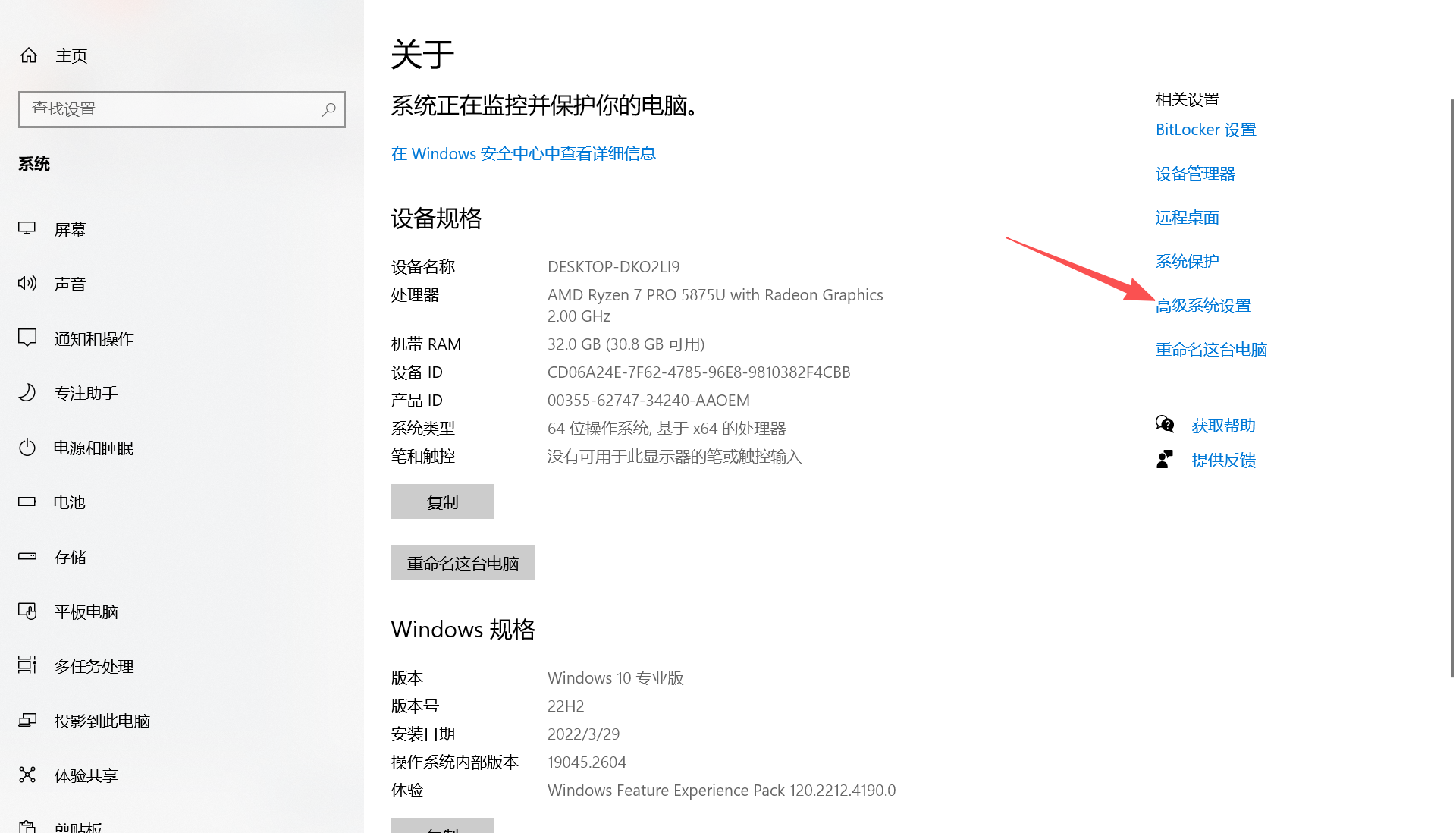
在系统变量找到‘Path’点击编辑
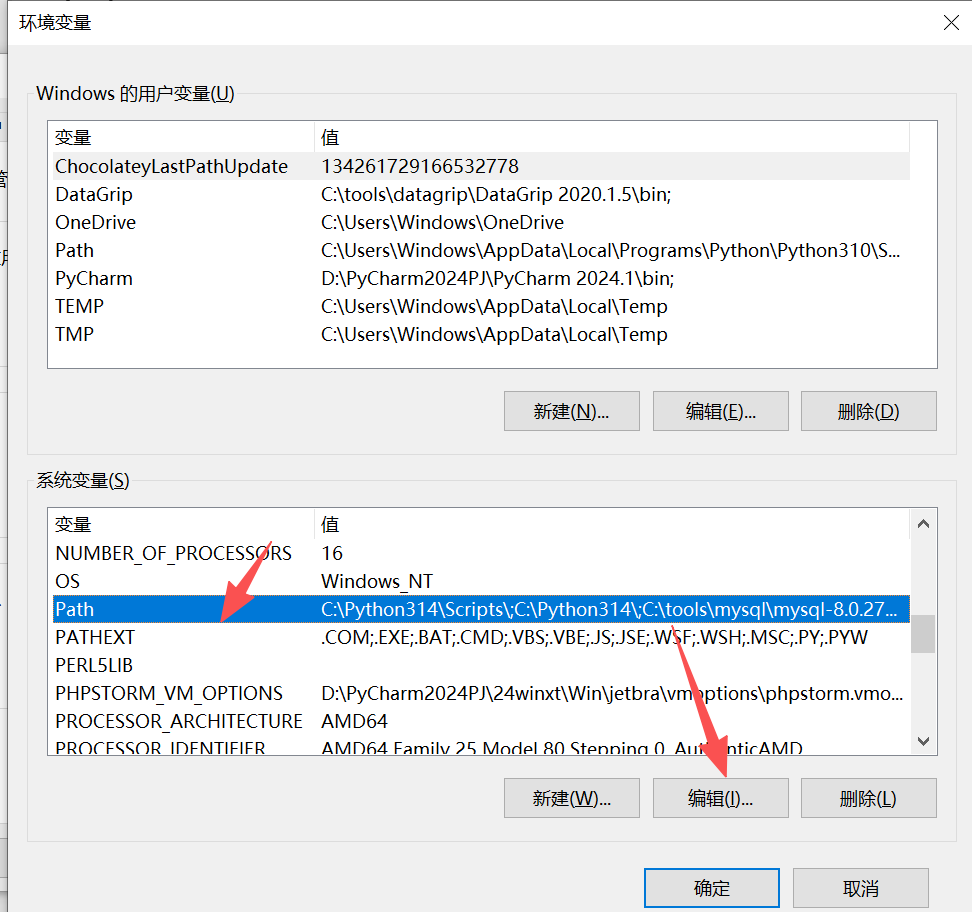
点击新建,然后复制MySQL安装路径下的bin文件夹的根目录,粘贴进去,再点击确定
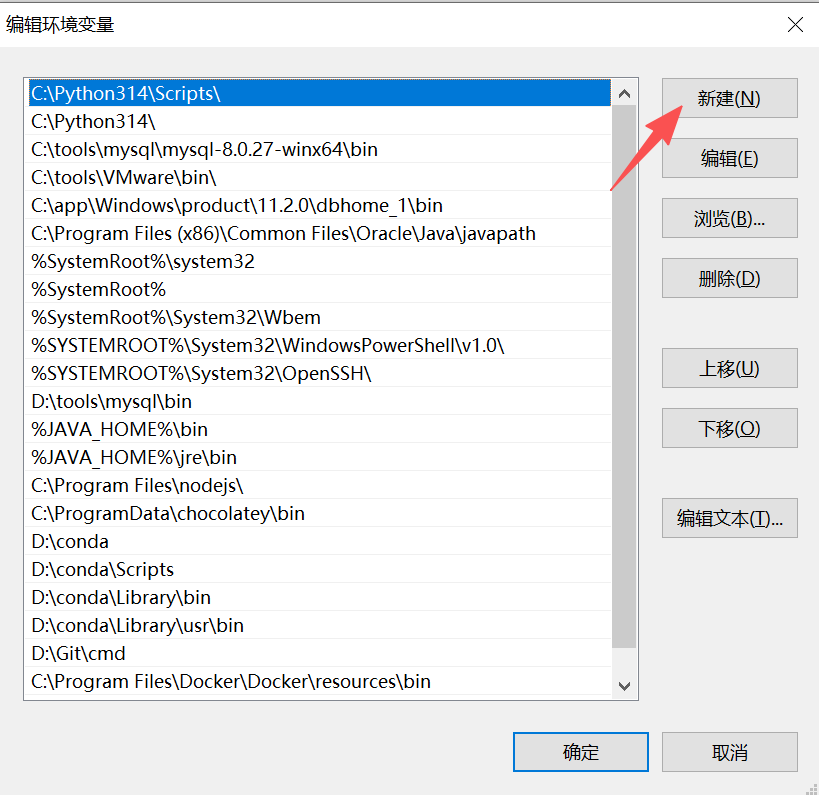
这里也点击确定
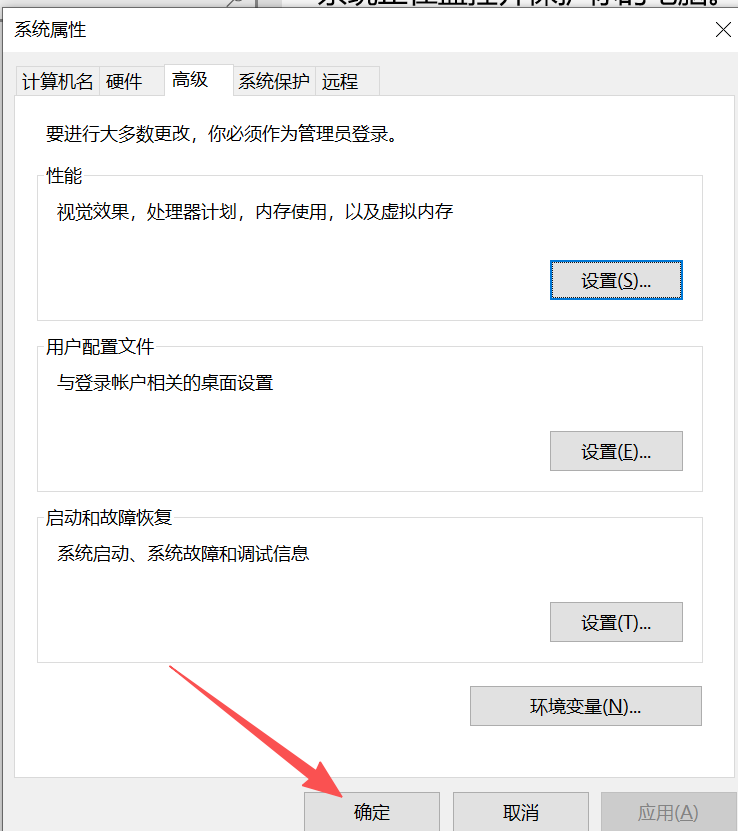
3.4.1.7 验证配置
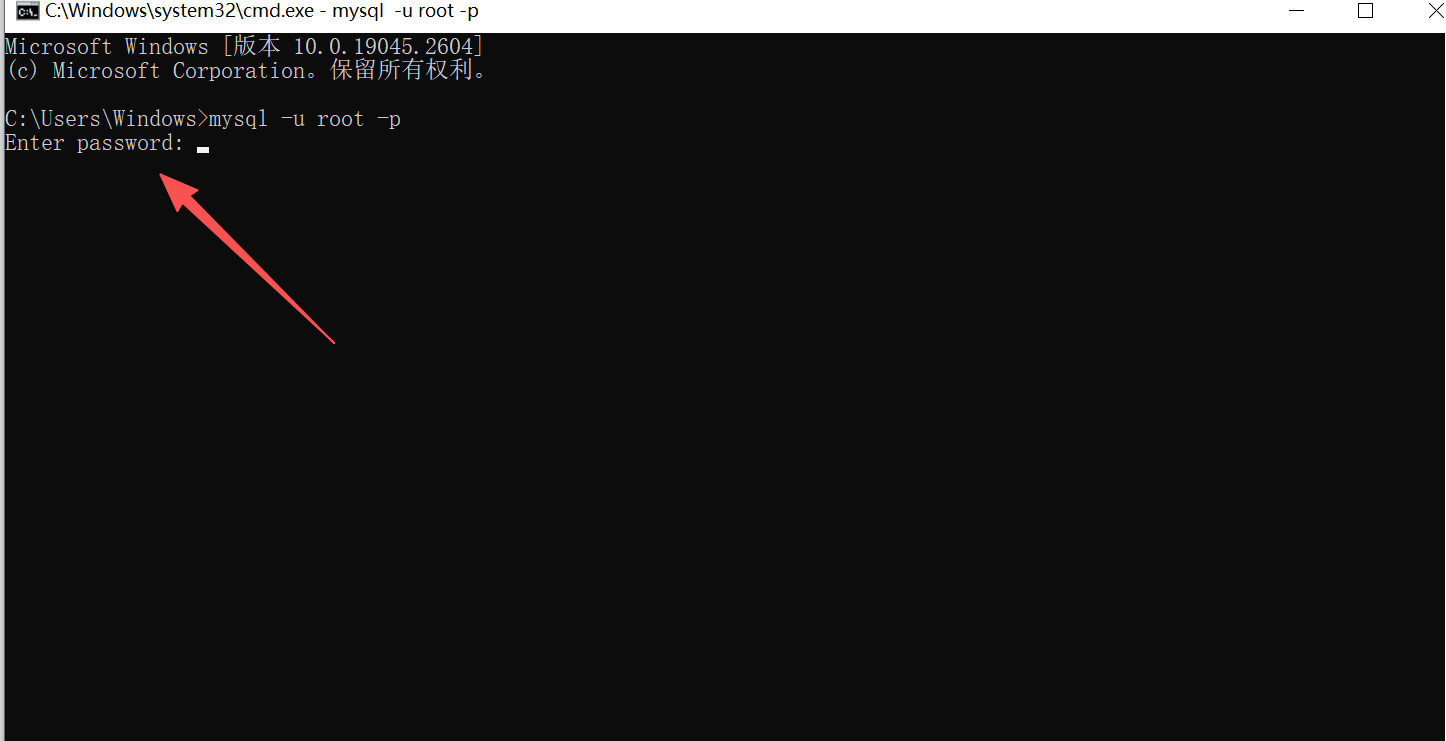
打开一个cmd窗口,输入
mysql -u root -p
出现让你输入密码的提示,说明配置成功
3.4.2 安装 DataGrip
和前面PyCharm一样,在 Toolbox App里找到 DataGrip,进行安装

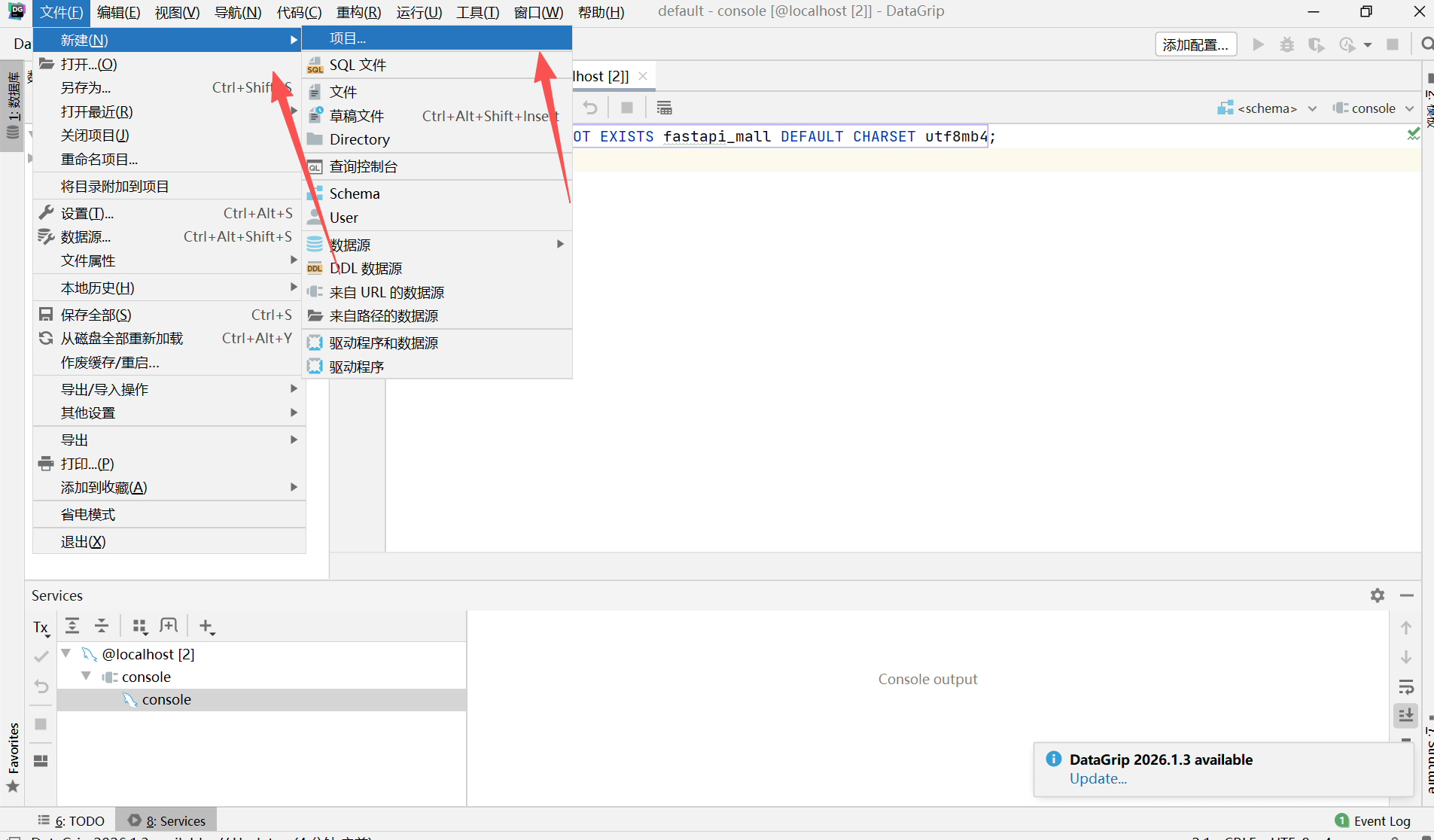
3.4.3 把 DataGrip 和 MySQL 连起来
安装好之后,需要在 DataGrip 里配置一下,让它知道去哪里找你的 MySQL“仓库
打开 DataGrip,在欢迎界面或主界面左上角点击"New Project"新建项目
选择 "Data Source"(数据源) -> "MySQL"
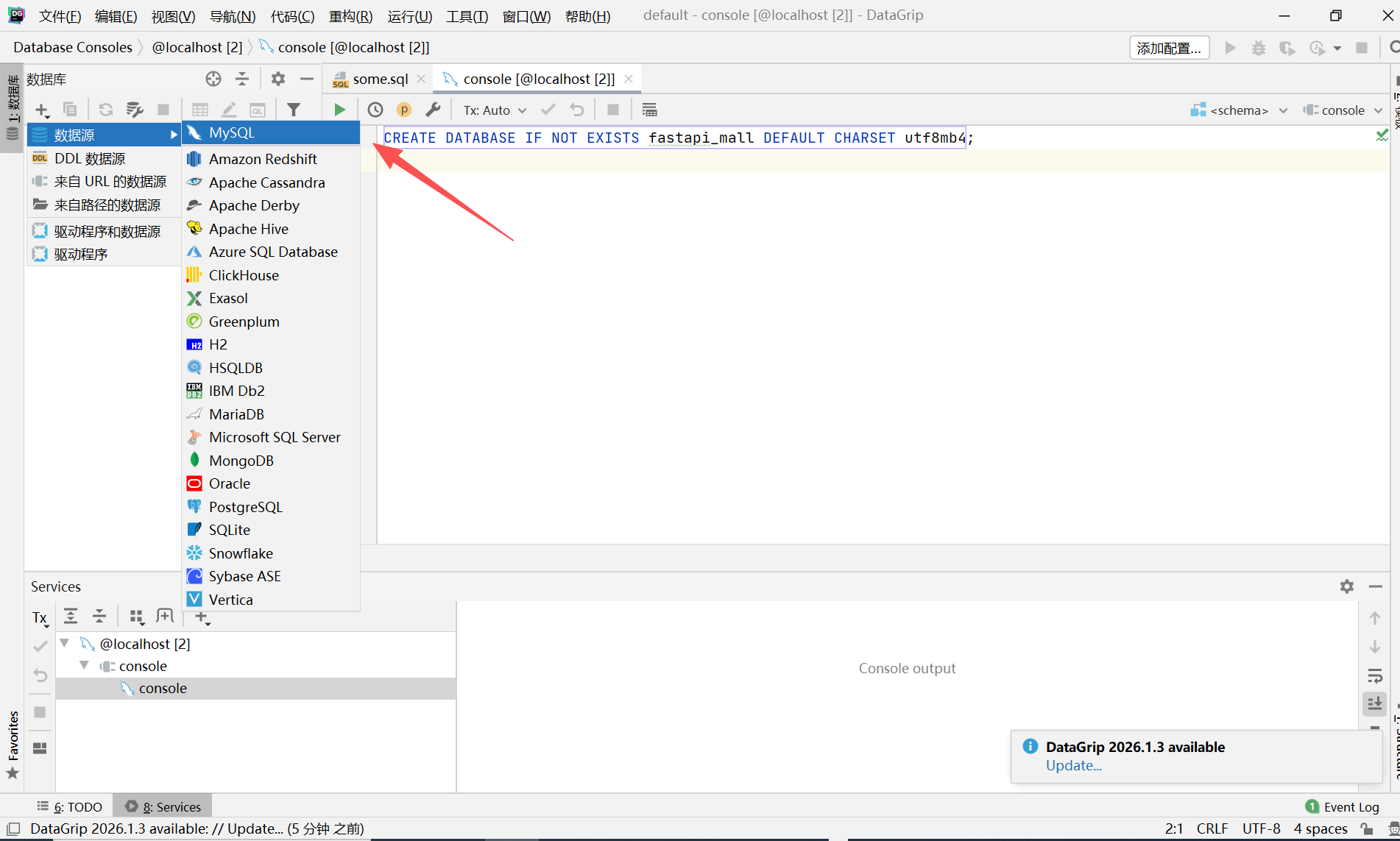
在弹出的配置窗口中,填写信息:
-
Host:
localhost(因为数据库就在你电脑上) -
Port:
3306(MySQL的默认端口) -
User:
root -
Password: 你安装MySQL时设置的密码
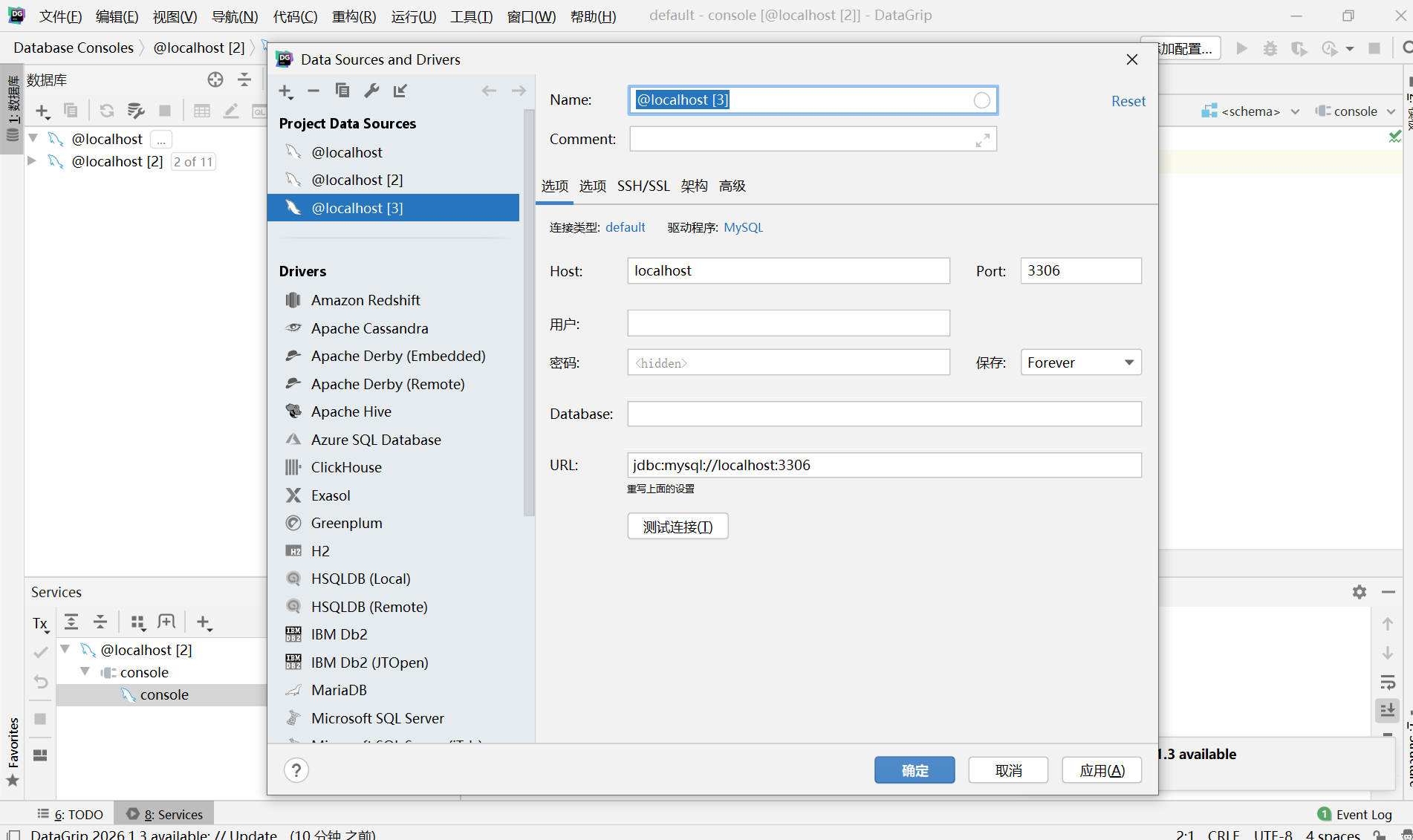
点击 "Test Connection"(测试连接),如果提示成功,就说明一切OK了!之后你就可以通过 DataGrip 的图形界面来创建数据库、写SQL查询、管理数据了
如果提示无效时区,只需要点击‘设置时区’,随便选择一个后,点击确定,就可以了
3.4 安装向量数据库Milvus和向量库可视化工具attu
3.4.2 attu 安装
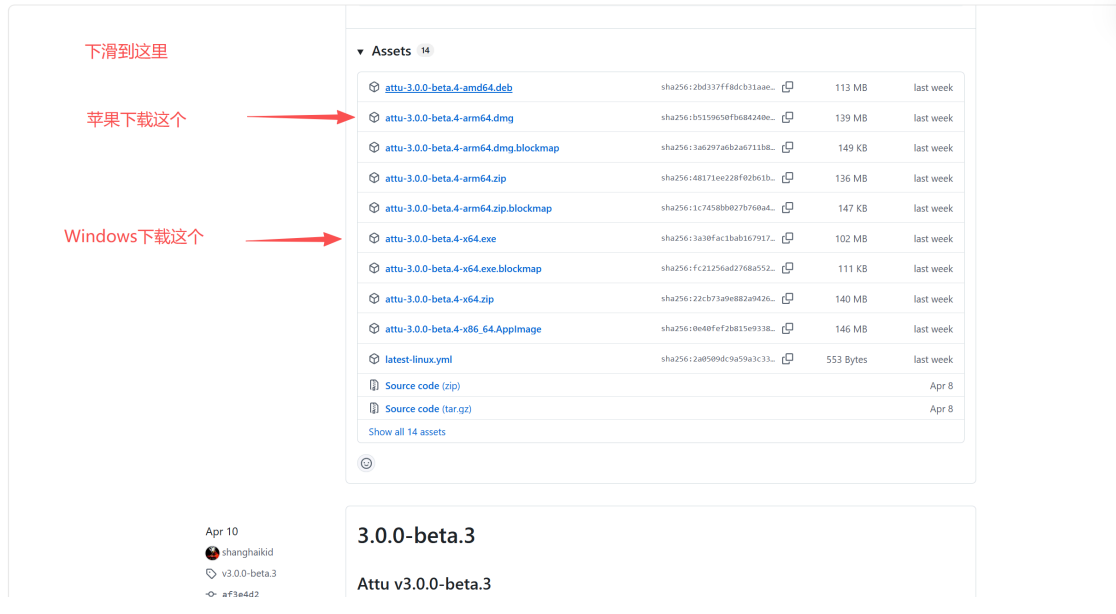
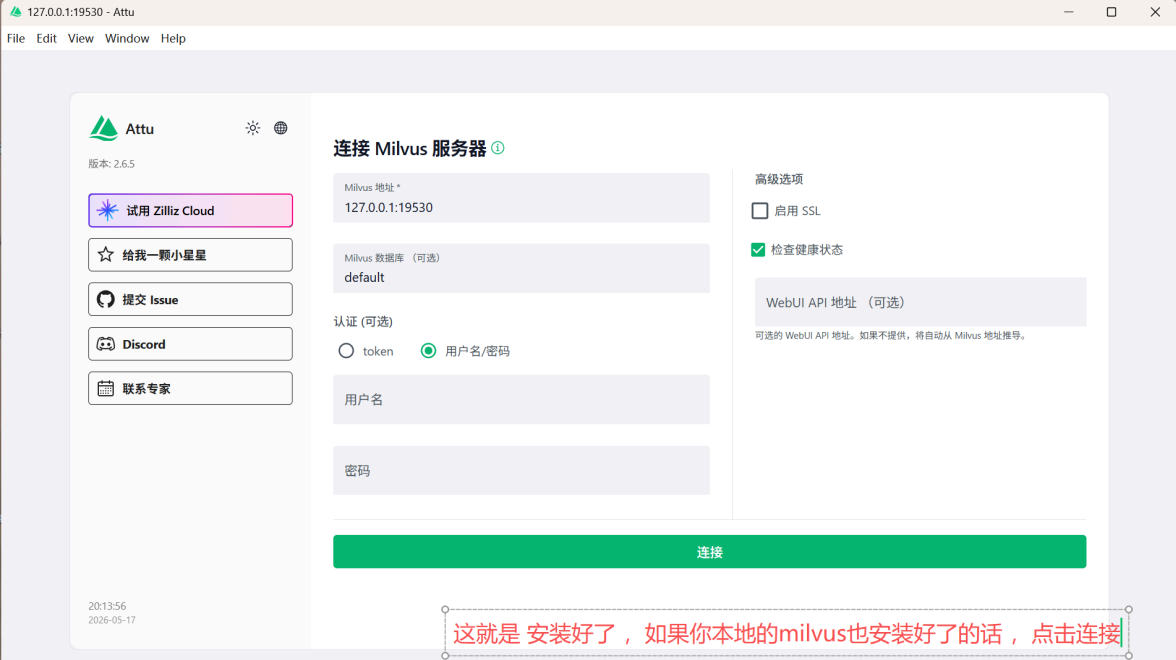
3.5 安装Embedding 模型
Embedding 模型是业内做RAG的标配,功能是将数据转化为向量
这里推荐选择BAAI/bge-large-zh-v1.5模型,这是中文RAG的经典选择
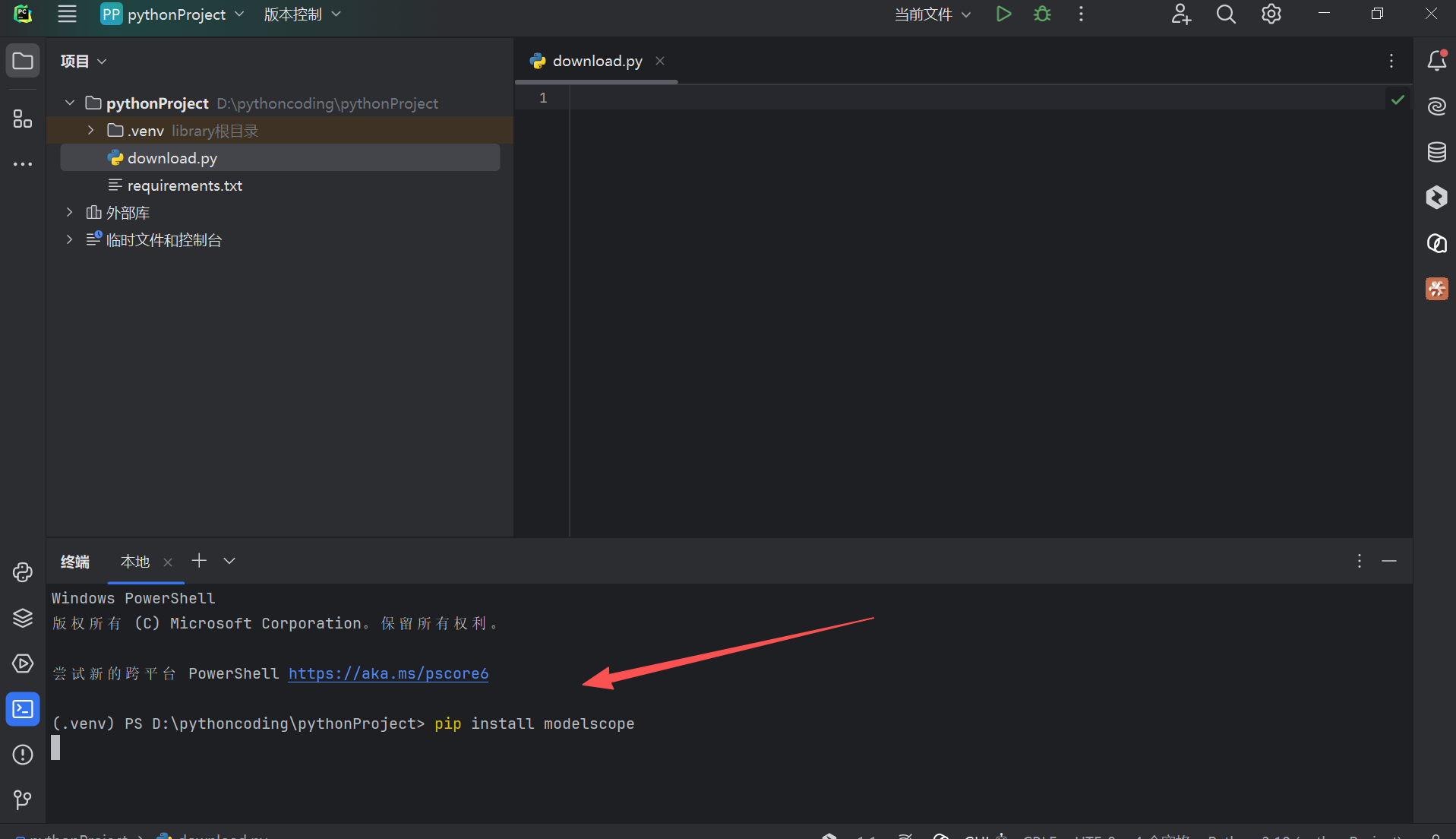
打开Pycharm,新建一个py文件
在终端运行
pip install modelscope
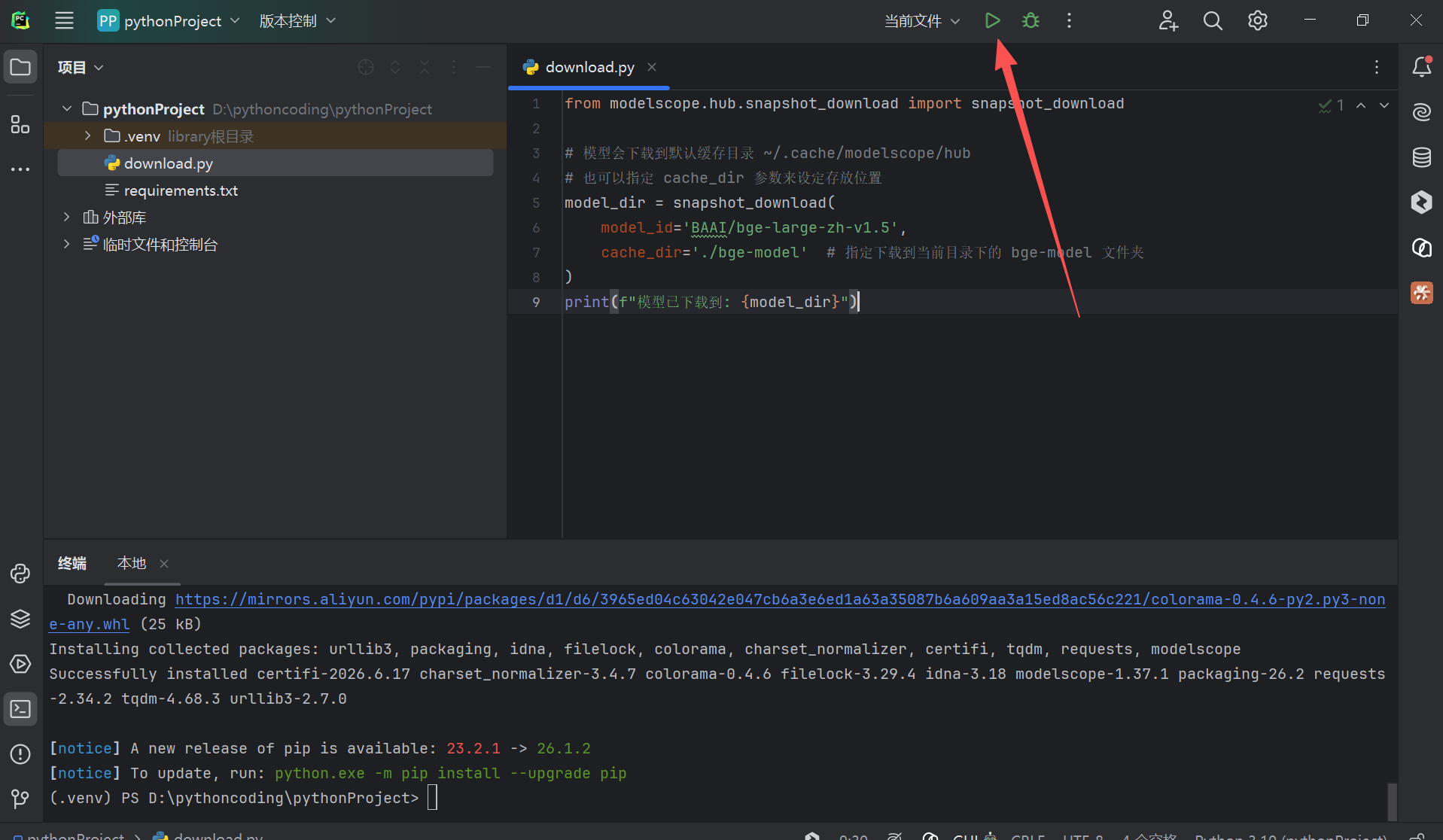
然后在新建的py文件里复制下列代码
from modelscope.hub.snapshot_download import snapshot_download
# 模型会下载到默认缓存目录 ~/.cache/modelscope/hub
# 也可以指定 cache_dir 参数来设定存放位置
model_dir = snapshot_download(
model_id='BAAI/bge-large-zh-v1.5',
cache_dir='./bge-model' # 指定下载到当前目录下的 bge-model 文件夹
)
print(f"模型已下载到: {model_dir}")
然后点击运行,来开启下载,模型大小1.3G左右,需要等一会
下载完成后,就可以把这个文件删除了
四、架构设计
4.1 架构一览
这是本文的核心。
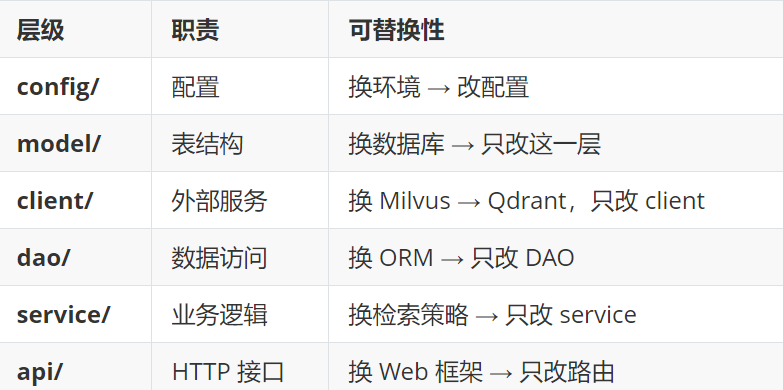
一个好的项目不是把所有代码塞进一个文件,而是分层架构、职责分离
智能客服/
├── requirements.txt # Python 依赖清单
├── prompts.yaml # Prompt 模板(集中管理,调整 prompt 不改代码)
├── main.py # ⭐ 应用入口(启动服务 或 投喂数据)
│
├── config/ # 配置层
│ ├── __init__.py
│ └── settings.py # 全局配置:数据库、Ollama、Milvus、Embedding
│
├── model/ # 数据模型层(SQLAlchemy ORM)
│ ├── __init__.py
│ └── models.py # Faq 知识库表 + ChatLog 对话记录表
│
├── client/ # 第三方客户端层(封装外部服务)
│ ├── __init__.py
│ ├── mysql_client.py # MySQL 连接引擎 + 会话管理
│ ├── milvus_client.py # Milvus 向量库连接 + 集合管理
│ └── llm_client.py # Ollama 大模型 API 封装(同步+流式)
│
├── dao/ # 数据访问层(Data Access Object)
│ ├── __init__.py
│ ├── faq_dao.py # FAQ 增删改查
│ ├── conversation_dao.py # 对话历史存取
│ └── retrieve_dao.py # ⭐ RAG 混合检索(Milvus向量 + MySQL关键词)
│
├── service/ # 业务逻辑层
│ ├── __init__.py
│ └── customer_service.py # ⭐ 智能客服核心:意图识别 → 检索 → 生成
│
├── api/ # API 路由层(对外接口)
│ ├── __init__.py
│ └── customer.py # FastAPI 路由:/chat/stream、对话历史
│
├── utils/ # 工具层
│ ├── __init__.py
│ ├── embedding.py # Embedding 模型加载(单例,只加载1次)
│ └── prompt_loader.py # Prompt 模板加载器(从 prompts.yaml 读取)
│
├── data/ # 数据初始化
│ └── feed.py # ⭐ 数据投喂:写入 12 条 FAQ → MySQL + Milvus
│
└── static/ # 前端静态资源
└── index.html # 聊天界面(纯 HTML/CSS/JS,零框架依赖)
4.2 每个文件的功能速查表
| 文件 | 层级 | 一句话说明 |
| main.py | 入口 | 创建 FastAPI 应用,注册路由,支持 --feed 投喂数据 |
| config/settings.py | 配置 | 统一管理数据库、Ollama、Milvus 等所有可配置项 |
| model/models.py | 模型 | 定义 Faq(FAQ知识库)和 ChatLog(对话日志)两张表 |
| client/mysql_client.py | 客户端 | 创建 SQLAlchemy 引擎,提供 get_session() 获取数据库会话 |
| client/milvus_client.py | 客户端 | 连接 Milvus,管理 Collection(创建/获取/索引) |
| client/llm_client.py | 客户端 | 连封装 Ollama API(同步调用 + 流式生成) |
| dao/faq_dao.py | 数据访问 | FAQ 表的增删改查,业务层不直接写 SQL |
| dao/conversation_dao.py | 数据访问 | 对话历史存取,按 session_id 查询 |
| dao/retrieve_dao.py | 数据访问 | RAG 核心:混合检索(Milvus 向量 → MySQL 关键词降级) |
| service/customer_service.py | 业务 | 核心逻辑:意图识别 → 检索知识 → 组装 Prompt → 调用 LLM |
| api/customer.py | 接口 | 定义 /chat/stream(SSE流式)和 /history/{id} 两个接口 |
| utils/embedding.py | 工具 | 加载 BGE 模型,encode("文字") → 1024维向量 |
| utils/prompt_loader.py | 工具 | 从 prompts.yaml 读取 Prompt 模板,业务代码不硬编码 Prompt |
| data/feed.py | 初始化 | 投喂 12 条 FAQ:写 MySQL 建表 + 向量化写 Milvus |
| prompts.yaml | 配置 | Prompt 模板文件,调整 Prompt 只需改这个文件 |
| static/index.html | 前端 | 聊天界面,纯 HTML+CSS+JS,fetch 消费 SSE 流 |
4.3 根据架构进行模仿
在Pyhcarm的根目录里先建立好对应的软件包、目录和文件,文件内部先空白不填(新手注意软件包和目录的区别)
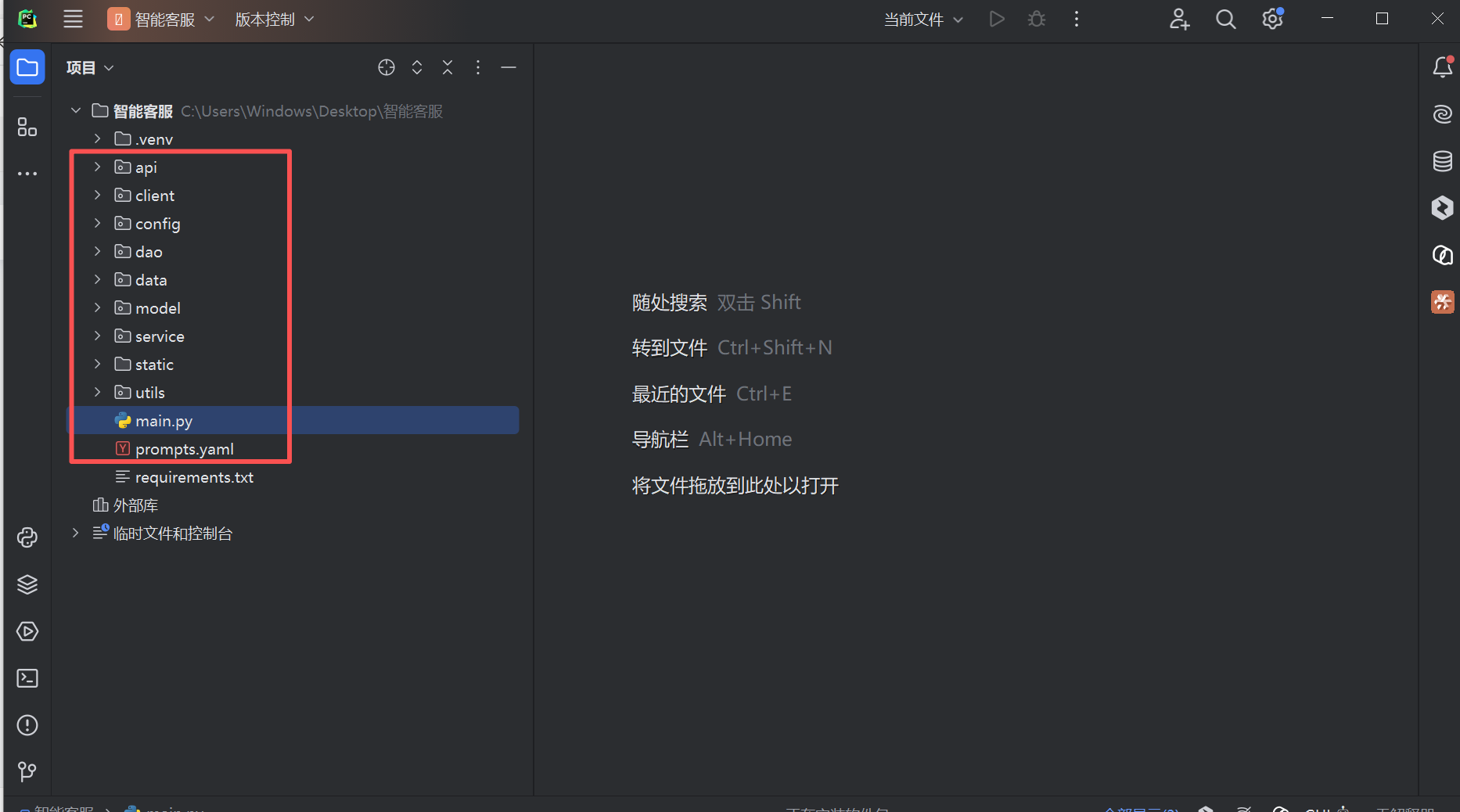
五、逐层拆解:从配置到前端
新手直接将代码复制进对应文件
按调用链路从下往上讲:配置 → 模型 → 客户端 → 数据访问 → 业务 → API → 入口
5.1 配置层 — config/settings.py
干什么:项目里所有可配置的东西都在这里——数据库地址、Ollama 地址、Milvus 参数、Embedding 模型名。一处修改,全局生效。
"""
settings.py — 集中配置
======================
职责:
1. 统一管理所有可配置项(数据库、Ollama、Milvus、Embedding 模型等)
2. 一处修改,全局生效,避免配置散落在各文件中
3. 支持通过环境变量覆盖默认值
使用方式:
from config import settings
engine = create_engine(settings.DATABASE_URL)
"""
import os
class Settings:
"""全局配置单例"""
# ======================== MySQL ========================
DB_HOST: str = os.getenv("DB_HOST", "localhost")
DB_PORT: int = int(os.getenv("DB_PORT", "3306"))
DB_USER: str = os.getenv("DB_USER", "root")
DB_PASSWORD: str = os.getenv("DB_PASSWORD", "123456")
DB_NAME: str = os.getenv("DB_NAME", "blog_cs")
@property
def DATABASE_URL(self) -> str:
"""组装 SQLAlchemy 连接字符串"""
from urllib.parse import quote_plus
return (
f"mysql+pymysql://{self.DB_USER}:{quote_plus(self.DB_PASSWORD)}"
f"@{self.DB_HOST}:{self.DB_PORT}/{self.DB_NAME}?charset=utf8mb4"
)
# ======================== Ollama(本地大模型) ========================
OLLAMA_BASE_URL: str = os.getenv("OLLAMA_BASE_URL", "http://localhost:11434/v1")
LLM_MODEL: str = os.getenv("LLM_MODEL", "qwen2.5:7b")
# ======================== Milvus(向量数据库) ========================
MILVUS_HOST: str = os.getenv("MILVUS_HOST", "localhost")
MILVUS_PORT: int = int(os.getenv("MILVUS_PORT", "19530"))
MILVUS_COLLECTION: str = "blog_cs" # 集合名称
EMBEDDING_DIM: int = 1024 # BGE-large-zh 输出 1024 维
# ======================== Embedding 模型 ========================
EMBEDDING_MODEL: str = "BAAI/bge-large-zh-v1.5"
# ======================== RAG 检索参数 ========================
RAG_TOP_K: int = 3 # 检索返回最多 K 条 FAQ
SIMILARITY_THRESHOLD: float = 0.5 # 向量相似度最低阈值
# ======================== 应用 ========================
APP_TITLE: str = "智能客服·完整版"
APP_PORT: int = 8080
# 模块级单例 — 全局统一使用这一个实例
settings = Settings()
设计要点:这里用了最简单的 class,方便零基础上手。正式项目可以升级为 pydantic-settings,支持 .env 文件和类型校验。
5.2 数据模型层 — model/models.py
干什么:用 Python 类定义数据库表结构。SQLAlchemy 会自动把类映射为 MySQL 表,你操作 Python 对象就等于操作数据库。
"""
models.py — 数据模型层(SQLAlchemy ORM)
======================================
职责:
1. 定义数据库表结构,映射为 Python 类
2. Faq:FAQ 知识库表(问题+答案+分类)
3. ChatLog:对话日志表(记录用户提问和 AI 回复)
设计理念:
ORM(对象关系映射)让你操作 Python 对象就等于操作数据库。
不用写 SQL,类型安全,自动防 SQL 注入。
使用方式:
from model.models import Faq, ChatLog
faq = Faq(question="如何退货", answer="在「我的订单」...", category="订单")
"""
from sqlalchemy import Column, Integer, String, Text, DateTime
from sqlalchemy.orm import declarative_base
from sqlalchemy.sql import func
# 声明基类 — 所有 ORM 模型继承它
Base = declarative_base()
class Faq(Base):
"""FAQ 知识库表
存储常见问题及标准答案,智能客服的核心知识来源。
字段说明:
- id: 主键,自增
- question: 标准问题(如"如何退货"),用于向量检索匹配
- answer: 标准答案,作为 LLM 生成的参考资料
- category: 分类标签(订单/物流/支付/商品/会员)
- created_at: 创建时间,自动填充
"""
__tablename__ = "faq"
id = Column(Integer, primary_key=True, autoincrement=True)
question = Column(String(500), nullable=False, comment="问题")
answer = Column(Text, nullable=False, comment="答案")
category = Column(String(100), default="通用", comment="分类")
created_at = Column(DateTime, server_default=func.now(), comment="创建时间")
class ChatLog(Base):
"""对话日志表
记录每一轮用户提问和 AI 回复,可追溯、可分析。
字段说明:
- id: 主键,自增
- session_id: 会话 ID,同一轮对话共享,用于区分不同用户的会话
- role: 角色(user=用户提问 / assistant=AI 回复)
- content: 消息内容
- intent: 意图类型(faq/order/product/chitchat),用于统计分析
- created_at: 创建时间,自动填充
"""
__tablename__ = "chat_log"
id = Column(Integer, primary_key=True, autoincrement=True)
session_id = Column(String(64), nullable=False, comment="会话ID")
role = Column(String(20), nullable=False, comment="user 或 assistant")
content = Column(Text, nullable=False, comment="消息内容")
intent = Column(String(50), default="", comment="意图分类")
created_at = Column(DateTime, server_default=func.now(), comment="创建时间")
5.3 第三方客户端层 — client/
这一层封装了三个外部服务,统一用单例模式(整个应用只创建一个连接实例)
5.3.1 MySQL 客户端 — client/mysql_client.py
干什么:创建 SQLAlchemy 引擎,管理数据库连接池
"""
mysql_client.py — MySQL 数据库客户端(单例模式)
==============================================
职责:
1. 创建 SQLAlchemy 引擎和会话工厂(整个应用共享一个引擎)
2. 提供 get_session() 获取数据库会话
3. 提供 create_all() 自动建表
4. 单例模式:引擎只创建一次,避免重复连接
使用方式:
from client.mysql_client import engine, get_session
with get_session() as session:
faq = session.query(Faq).first()
"""
from sqlalchemy import create_engine
from sqlalchemy.orm import Session, sessionmaker
from config import settings
from model.models import Base
class MySQLClient:
"""MySQL 数据库客户端(单例)"""
_instance = None
def __new__(cls):
if cls._instance is None:
cls._instance = super().__new__(cls)
cls._instance._connect()
return cls._instance
def _connect(self):
"""创建引擎和会话工厂"""
self._engine = create_engine(
settings.DATABASE_URL,
echo=False, # 不打印 SQL 日志
pool_size=5, # 连接池大小
max_overflow=10, # 最大溢出连接数
pool_recycle=3600, # 1 小时后回收连接
)
self._session_factory = sessionmaker(bind=self._engine)
@property
def engine(self):
"""SQLAlchemy 引擎(用于 create_all 等 DDL 操作)"""
return self._engine
def create_all(self):
"""根据 ORM 模型自动创建所有表(如果表已存在则跳过)"""
Base.metadata.create_all(self._engine)
def get_session(self) -> Session:
"""获取一个新的数据库会话(用完记得 close)"""
return self._session_factory()
# 模块级单例 — 全应用共享
mysql = MySQLClient()
为什么要单例:数据库连接是昂贵的资源。创建一次引擎,全局复用连接池,避免每次请求都重新建立 TCP 连接。
5.3.2 Milvus 客户端 — client/milvus_client.py
干什么:连接 Milvus 向量数据库,管理 Collection(集合)
"""
milvus_client.py — Milvus 向量数据库客户端(单例模式)
=====================================================
职责:
1. 连接 Milvus 向量数据库
2. 管理 Collection(集合):创建、获取、检查存在
3. 单例模式:连接只建立一次,全局复用
4. 连接失败时自动降级(不影响应用启动,向量检索不可用时可走 MySQL)
设计说明:
Milvus 是专门存储和搜索向量的数据库。
我们把 FAQ 的问题转成 1024 维向量存在 Milvus 中,
用户提问时也转成向量,然后用余弦相似度找最接近的 FAQ。
使用方式:
from client.milvus_client import milvus
col = milvus.get_collection("blog_cs")
hits = col.search(data=[vec], anns_field="embedding", ...)
"""
from pymilvus import connections, Collection, CollectionSchema, FieldSchema, DataType, utility
from config import settings
class MilvusClient:
"""Milvus 向量数据库客户端(单例)"""
_instance = None
def __new__(cls):
if cls._instance is None:
cls._instance = super().__new__(cls)
cls._instance._connect()
return cls._instance
def _connect(self):
"""连接 Milvus,连接失败时标记不可用(降级运行)"""
try:
connections.connect(
host=settings.MILVUS_HOST,
port=settings.MILVUS_PORT,
timeout=5,
)
self._connected = True
print(f"[Milvus] 已连接 {settings.MILVUS_HOST}:{settings.MILVUS_PORT}")
except Exception as e:
print(f"[Milvus] 连接失败(向量检索将降级为 MySQL 关键词): {e}")
self._connected = False
@property
def connected(self) -> bool:
return self._connected
def has_collection(self, name: str) -> bool:
"""检查集合是否存在"""
if not self._connected:
return False
return utility.has_collection(name)
def create_collection(self, name: str) -> Collection:
"""创建 FAQ 向量集合
集合包含 4 个字段:
- id: 主键(与 MySQL faq 表的 id 对应)
- question: 问题文本(方便检索时直接返回原文)
- answer: 答案文本
- embedding: 问题对应的 1024 维向量
索引参数说明:
- metric_type: COSINE(余弦相似度),值越接近 1 越相似
- index_type: IVF_FLAT(倒排索引+精确计算),平衡速度和精度
- nlist: 64(聚类中心数),数据量大时可调大
"""
schema = CollectionSchema(fields=[
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=False),
FieldSchema(name="question", dtype=DataType.VARCHAR, max_length=500),
FieldSchema(name="answer", dtype=DataType.VARCHAR, max_length=2000),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=settings.EMBEDDING_DIM),
])
col = Collection(name=name, schema=schema)
col.create_index(
field_name="embedding",
index_params={
"metric_type": "COSINE",
"index_type": "IVF_FLAT",
"params": {"nlist": 64},
},
)
print(f"[Milvus] 集合 '{name}' 已创建,维度={settings.EMBEDDING_DIM}")
return col
def get_collection(self, name: str) -> Collection:
"""获取已有集合,并加载到内存(必须先 load 才能搜索)"""
if not self._connected:
raise ConnectionError("Milvus 不可用,请确认服务已启动")
if not utility.has_collection(name):
raise ValueError(f"集合 '{name}' 不存在,请先运行数据投喂")
col = Collection(name=name)
col.load() # 加载到内存,必须执行
return col
# 模块级单例 — 全应用共享
milvus = MilvusClient()
Milvus 的关键概念:
-
Collection:相当于 MySQL 的"表"
-
embedding 字段:FLOAT_VECTOR 类型,存 1024 个浮点数
-
COSINE:余弦相似度,值域 [-1, 1],越接近 1 越相似
-
nlist:聚成 64 组,搜索时只查最近的 nprobe 组,大幅加速
5.3.3 LLM 客户端 — client/llm_client.py
"""
llm_client.py — Ollama 大模型客户端(单例模式)
=============================================
职责:
1. 封装 Ollama API 调用(兼容 OpenAI 格式:POST /v1/chat/completions)
2. 提供同步 chat() 方法
3. 提供流式 chat_stream() 方法(逐 token 返回,SSE 推送用)
4. 单例模式复用 httpx 连接池,避免每次请求都重新建立 TCP 连接
使用方式:
from client.llm_client import llm
answer = llm.chat("请帮我翻译...")
async for token in llm.chat_stream("请帮我..."):
print(token, end="")
"""
import json
import httpx
from config import settings
class LLMClient:
"""Ollama 大模型客户端(单例,同步 + 流式)"""
_instance = None
def __new__(cls):
if cls._instance is None:
cls._instance = super().__new__(cls)
cls._instance._connect()
return cls._instance
def _connect(self):
"""初始化 httpx 客户端(同步 + 异步)"""
self._base_url = settings.OLLAMA_BASE_URL.rstrip("/")
self._model = settings.LLM_MODEL
# 同步客户端
self._client = httpx.Client(
base_url=self._base_url,
headers={"Content-Type": "application/json"},
timeout=httpx.Timeout(120.0),
)
# 异步客户端(用于流式 SSE)
self._async_client = httpx.AsyncClient(
base_url=self._base_url,
headers={"Content-Type": "application/json"},
timeout=httpx.Timeout(120.0),
)
def _build_payload(self, prompt: str, temperature: float = 0.7) -> dict:
"""构建 Ollama API 请求体"""
return {
"model": self._model,
"messages": [{"role": "user", "content": prompt}],
"temperature": temperature,
"max_tokens": 1024,
}
# ======================== 同步对话 ========================
def chat(self, prompt: str, temperature: float = 0.7) -> str:
"""同步调用大模型,返回完整回复文本"""
try:
resp = self._client.post(
"/chat/completions",
json=self._build_payload(prompt, temperature),
)
resp.raise_for_status()
return resp.json()["choices"][0]["message"]["content"].strip()
except httpx.ConnectError:
raise RuntimeError(f"无法连接 Ollama ({self._base_url}),请确认 ollama serve 已启动")
except httpx.HTTPStatusError as e:
raise RuntimeError(f"Ollama API 错误 ({e.response.status_code}): {e.response.text[:200]}")
# ======================== 流式对话(逐 token 生成) ========================
async def chat_stream(self, prompt: str, temperature: float = 0.7):
"""流式调用大模型,逐 token yield,用于 SSE 推送
用法:
async for token in llm.chat_stream(prompt):
yield f"data: {json.dumps({'token': token})}\n\n"
"""
payload = self._build_payload(prompt, temperature)
payload["stream"] = True # 开启流式
try:
async with self._async_client.stream(
"POST", "/chat/completions", json=payload
) as resp:
resp.raise_for_status()
async for line in resp.aiter_lines():
if line.startswith("data: "):
data = line[6:]
if data == "[DONE]":
break
try:
chunk = json.loads(data)
token = chunk["choices"][0].get("delta", {}).get("content", "")
if token:
yield token
except (json.JSONDecodeError, KeyError, IndexError):
continue
except httpx.ConnectError:
raise RuntimeError(f"无法连接 Ollama ({self._base_url})")
except httpx.HTTPStatusError as e:
raise RuntimeError(f"Ollama 流式错误 ({e.response.status_code})")
# 模块级单例 — 全应用共享
llm = LLMClient()
Ollama 的兼容性:它封装了和 ChatGPT 完全相同的 API 格式,所以调 Ollama 和调 OpenAI 的代码几乎一样。换模型只需改 base_url。
5.4 数据访问层 — dao/
DAO(Data Access Object)层封装所有数据库操作。业务层不需要写 SQL,调 DAO 方法即可
5.4.1 FAQ DAO — dao/faq_dao.py
干什么:FAQ 表的 CRUD(增删改查)。
"""
faq_dao.py — FAQ 知识库数据访问层
=================================
职责:
1. 封装 FAQ 表的所有数据库操作(增删改查)
2. 对外提供清晰的 Python 方法,内部使用 SQLAlchemy ORM
3. 业务层不需要写任何 SQL
使用方式:
from dao.faq_dao import FaqDao
dao = FaqDao(session)
faq = dao.get_by_id(1)
"""
from typing import List, Optional
from sqlalchemy.orm import Session
from model.models import Faq
class FaqDao:
"""FAQ 知识库 DAO"""
def __init__(self, session: Session):
self.session = session
# ======================== 查询 ========================
def get_all(self) -> List[Faq]:
"""获取全部 FAQ"""
return self.session.query(Faq).all()
def get_by_id(self, faq_id: int) -> Optional[Faq]:
"""按 ID 获取单条 FAQ"""
return self.session.query(Faq).filter(Faq.id == faq_id).first()
def get_by_category(self, category: str) -> List[Faq]:
"""按分类获取 FAQ"""
return self.session.query(Faq).filter(Faq.category == category).all()
def search_keyword(self, keyword: str, limit: int = 5) -> List[Faq]:
"""关键词模糊搜索(MySQL LIKE)"""
return (
self.session.query(Faq)
.filter(Faq.question.contains(keyword))
.limit(limit)
.all()
)
# ======================== 增删改 ========================
def create(self, question: str, answer: str, category: str = "通用") -> Faq:
"""新增一条 FAQ"""
faq = Faq(question=question, answer=answer, category=category)
self.session.add(faq)
self.session.commit()
return faq
def update(self, faq_id: int, **kwargs) -> Optional[Faq]:
"""更新一条 FAQ(按关键字传入要更新的字段)"""
faq = self.get_by_id(faq_id)
if not faq:
return None
for key, value in kwargs.items():
if hasattr(faq, key):
setattr(faq, key, value)
self.session.commit()
return faq
def delete_by_id(self, faq_id: int) -> bool:
"""删除一条 FAQ"""
faq = self.get_by_id(faq_id)
if not faq:
return False
self.session.delete(faq)
self.session.commit()
return True
def delete_all(self):
"""清空全部 FAQ(投喂前调用)"""
self.session.query(Faq).delete()
self.session.commit()
def count(self) -> int:
"""FAQ 总数"""
return self.session.query(Faq).count()
5.4.2 对话历史 DAO — dao/conversation_dao.py
干什么:对话记录的存取。
"""
conversation_dao.py — 对话历史数据访问层
========================================
职责:
1. 封装 ChatLog 表的所有数据库操作
2. 保存对话消息、查询会话历史
使用方式:
from dao.conversation_dao import ConversationDao
dao = ConversationDao(session)
dao.save("session_001", "user", "如何退货")
"""
from typing import List
from sqlalchemy.orm import Session
from model.models import ChatLog
class ConversationDao:
"""对话历史 DAO"""
def __init__(self, session: Session):
self.session = session
def save(
self,
session_id: str,
role: str,
content: str,
intent: str = "",
) -> ChatLog:
"""保存一条对话消息"""
log = ChatLog(
session_id=session_id,
role=role,
content=content,
intent=intent,
)
self.session.add(log)
self.session.commit()
return log
def get_session_history(self, session_id: str, limit: int = 20) -> List[ChatLog]:
"""查询指定会话的历史消息(按时间正序)"""
return (
self.session.query(ChatLog)
.filter(ChatLog.session_id == session_id)
.order_by(ChatLog.created_at.asc())
.limit(limit)
.all()
)
def get_recent(self, limit: int = 50) -> List[ChatLog]:
"""获取最近的对话记录"""
return (
self.session.query(ChatLog)
.order_by(ChatLog.created_at.desc())
.limit(limit)
.all()
)
5.4.3 ⭐ 检索服务 — dao/retrieve_dao.py
干什么:这是 RAG 的核心——混合检索。优先 Milvus 向量检索,失败自动降级为 MySQL 关键词检索。
"""
retrieve_dao.py — RAG 检索服务(混合检索)
==========================================
职责:
1. 优先用 Milvus 向量检索(语义匹配)
2. Milvus 不可用时自动降级为 MySQL 关键词检索
3. 对外暴露统一的 hybrid_search_faq() 方法
RAG(检索增强生成)流程:
用户提问 → Embedding 向量化 → Milvus 搜 top3 相似 FAQ
→ 拼入 Prompt → Ollama 生成回答
为什么混合检索?
向量检索(Milvus): 语义匹配强,"怎么退款" 能匹配到 "如何退货"
关键词检索(MySQL LIKE):精确匹配强,对短词/专有名词更准
两者互补,任一可用都能保证基础服务
使用方式:
from dao.retrieve_dao import RetrieveService
svc = RetrieveService()
results = svc.hybrid_search_faq("如何退货", top_k=3)
"""
from typing import List, Dict
from client.milvus_client import milvus
from client.mysql_client import mysql
from utils.embedding import embedding_model
from config import settings
class RetrieveService:
"""混合检索服务 — 向量(Milvus)+ 关键词(MySQL)"""
def hybrid_search_faq(self, query: str, top_k: int = None) -> List[Dict]:
"""混合检索 FAQ:Milvus 向量优先 → MySQL 关键词降级
参数:
query: 用户问题
top_k: 返回数量,默认取配置值
返回:
[{"question": "如何退货", "answer": "...", "score": 0.92, "source": "vector"}, ...]
"""
if top_k is None:
top_k = settings.RAG_TOP_K
results: List[Dict] = []
# 1. 向量检索(Milvus)
try:
results = self._vector_search(query, top_k)
except Exception as e:
print(f"[检索] 向量检索失败,降级为 MySQL: {e}")
# 2. MySQL 关键词补全(向量结果不足 top_k 时填充)
if len(results) < top_k:
try:
keyword_results = self._keyword_search(
query, top_k - len(results)
)
results.extend(keyword_results)
except Exception as e:
print(f"[检索] MySQL 关键词检索失败: {e}")
return results[:top_k]
def _vector_search(self, query: str, top_k: int) -> List[Dict]:
"""Milvus 向量检索"""
query_vec = embedding_model.encode(query)
col = milvus.get_collection(settings.MILVUS_COLLECTION)
hits = col.search(
data=[query_vec],
anns_field="embedding",
param={
"metric_type": "COSINE",
"params": {"nprobe": 10}, # 搜索 10 个聚类
},
limit=top_k,
output_fields=["id", "question", "answer"],
)
results = []
for hit in hits:
for h in hit:
if h.distance >= settings.SIMILARITY_THRESHOLD:
results.append({
"question": h.entity.get("question"),
"answer": h.entity.get("answer"),
"score": round(h.distance, 3),
"source": "vector",
})
return results
def _keyword_search(self, query: str, limit: int) -> List[Dict]:
"""MySQL 关键词模糊匹配(降级方案)"""
session = mysql.get_session()
try:
from model.models import Faq
faqs = (
session.query(Faq)
.filter(Faq.question.contains(query))
.limit(limit)
.all()
)
results = []
for f in faqs:
# 简单计分:匹配字符数 / 总长度
score = sum(1 for c in query if c in f.question) / max(len(f.question), 1)
results.append({
"question": f.question,
"answer": f.answer,
"score": round(score, 3),
"source": "keyword",
})
return results
finally:
session.close()
def insert_faq_vectors(self, faq_list: list):
"""将 FAQ 列表向量化后写入 Milvus(数据投喂时调用)"""
if not faq_list:
return
col = milvus.get_collection(settings.MILVUS_COLLECTION)
# 批量向量化
questions = [f.question for f in faq_list]
vectors = embedding_model.encode_batch(questions)
# 组装插入数据
col.insert([
[f.id for f in faq_list], # id 列
questions, # question 列
[f.answer for f in faq_list], # answer 列
vectors, # embedding 列
])
col.flush() # 持久化到磁盘
print(f"[Milvus] {len(faq_list)} 条向量已写入")
为什么混合检索:
-
向量检索:语义强,"怎么退款" 能匹配 "如何退货"
-
关键词检索:精确强,对短词/专有名词更准
-
Milvus 挂了也不怕——自动降级,保证基础可用
5.5 业务逻辑层 — service/customer_service.py
干什么:智能客服的核心三段式流水线——意图识别 → 知识检索 → 答案生成。
"""
customer_service.py — 智能客服核心业务逻辑
=========================================
职责:
1. 意图识别:判断用户想问什么(faq / order / product / chitchat)
2. 知识检索:调用 RetrieveService 混合检索 FAQ
3. 答案生成:组装 Prompt → 调用 LLM 生成回复
4. 流式生成:逐 token 返回,供 SSE 推送
架构位置:
API 层(api/customer.py)→ 业务层(本文件)→ DAO 层(dao/)
不直接操作数据库,通过 DAO 和 Client 完成任务
使用方式:
from service.customer_service import CustomerService
svc = CustomerService()
result = svc.answer("如何退货") # → {"answer": "...", "intent": "faq", "sources": [...]}
"""
import json
from client.llm_client import llm
from dao.retrieve_dao import RetrieveService
from utils.prompt_loader import load_prompt
class CustomerService:
"""智能客服核心服务"""
def __init__(self):
self.retrieve = RetrieveService()
# ======================== 意图识别 ========================
def classify_intent(self, query: str) -> str:
"""识别用户意图
调用 LLM 做意图分类,返回类型:
- faq: 常见问题(退货/发货/支付等)
- product: 商品咨询
- order: 订单相关
- chitchat: 闲聊
- human: 需要转人工
"""
try:
template = load_prompt("intent_classification")
prompt = template.format(query=query)
response = llm.chat(prompt, temperature=0.1) # 低温确保稳定输出
return json.loads(response).get("intent", "faq")
except Exception:
return "faq" # 失败时默认走 FAQ 流程
# ======================== 完整回答(非流式) ========================
def answer(self, query: str, history: list = None) -> dict:
"""生成完整回答(同步,供非流式场景使用)
参数:
query: 用户问题
history: 对话历史列表 [{"role":"user","content":"..."}, ...]
返回:
{"answer": "AI回复内容", "intent": "faq", "sources": [...]}
"""
# 1. 意图识别
intent = self.classify_intent(query)
# 2. 检索相关知识
knowledge = self.retrieve.hybrid_search_faq(query)
# 3. 构建 Prompt
template = load_prompt("customer_service_prompt")
history_text = "\n".join(
[f"{h['role']}: {h['content']}" for h in (history or [])[-4:]]
)
knowledge_text = "\n".join(
[f"Q: {k['question']}\nA: {k['answer']}" for k in knowledge]
)
prompt = template.format(
knowledge=knowledge_text,
history=history_text,
query=query,
)
# 4. LLM 生成(失败时降级为直接返回检索到的第一条答案)
try:
answer = llm.chat(prompt)
except Exception:
answer = knowledge[0]["answer"] if knowledge else "抱歉,我暂时无法处理您的问题,请稍后再试。"
return {
"answer": answer,
"intent": intent,
"sources": knowledge,
}
# ======================== 流式回答(逐 token) ========================
async def answer_stream(self, query: str, history: list = None):
"""流式生成回答,逐 token yield
用法:
async for token in svc.answer_stream("如何退货"):
yield f"data: {json.dumps({'token': token})}\n\n"
"""
# 1. 意图识别
intent = self.classify_intent(query)
# 2. 检索
knowledge = self.retrieve.hybrid_search_faq(query)
# 3. 构建 Prompt
template = load_prompt("customer_service_prompt")
history_text = "\n".join(
[f"{h['role']}: {h['content']}" for h in (history or [])[-4:]]
)
knowledge_text = "\n".join(
[f"Q: {k['question']}\nA: {k['answer']}" for k in knowledge]
)
prompt = template.format(
knowledge=knowledge_text,
history=history_text,
query=query,
)
# 4. 流式生成
try:
async for token in llm.chat_stream(prompt):
yield token, intent, knowledge
except Exception:
# 降级:返回第一条检索结果的答案
fallback = knowledge[0]["answer"] if knowledge else "抱歉,服务暂不可用。"
yield fallback, intent, knowledge
分层的好处:API 层只管接收请求和返回响应,怎么意图识别、怎么检索、怎么生成——全部封装在 Service 层。将来换模型、换数据库、换检索策略,只改这一层。
5.6 API 路由层 — api/customer.py
干什么:定义对外接口(2 个 API + 1 个 HTML 页面)。
| 接口 | 方法 | 说明 |
| / | GET | 返回聊天界面 HTML |
| /chat/stream | POST | 核心:SSE 流式对话 |
| /history/{session_id} | GET | 查询对话历史 |
"""
customer.py — 智能客服 API 路由
===============================
职责:
1. 定义 FastAPI 路由(接口)
2. 解析请求参数,调用业务层
3. 返回标准 JSON 响应 / SSE 流式响应
4. 记录对话到 MySQL
接口列表:
GET / — 聊天界面(HTML)
POST /chat/stream — 流式对话(SSE)
GET /history/{id} — 查询对话历史
使用方式:
在 main.py 中注册: app.include_router(customer.router)
"""
import json
import uuid
from fastapi import APIRouter, Request, HTTPException
from fastapi.responses import StreamingResponse, HTMLResponse
from client.mysql_client import mysql
from dao.conversation_dao import ConversationDao
from service.customer_service import CustomerService
router = APIRouter(tags=["智能客服"])
# 业务层单例
_customer = CustomerService()
# ======================== 前端页面 ========================
@router.get("/", response_class=HTMLResponse)
async def index():
"""返回聊天界面"""
from pathlib import Path
html_path = Path(__file__).resolve().parent.parent / "static" / "index.html"
if html_path.exists():
return html_path.read_text(encoding="utf-8")
return "<h1>index.html 未找到</h1>"
# ======================== 流式对话(核心接口) ========================
@router.post("/chat/stream", summary="流式对话")
async def chat_stream(request: Request):
"""智能客服流式对话接口(SSE)
请求体:
{"query": "如何退货", "session_id": "abc123"}
响应(SSE 事件流):
data: {"token": "您"} ← 逐 token 推送
data: {"token": "可以"} ← ...
data: {"done": true, "sources": [...], "intent": "faq"} ← 结束标记
前端通过 fetch + ReadableStream 消费 SSE 流,实现打字机效果。
"""
# 1. 解析请求
body = await request.json()
query = body.get("query", "").strip()
session_id = body.get("session_id", uuid.uuid4().hex[:16])
if not query:
raise HTTPException(status_code=400, detail="请输入问题")
# 2. 记录用户消息到 MySQL
session = mysql.get_session()
try:
conv_dao = ConversationDao(session)
conv_dao.save(session_id=session_id, role="user", content=query)
finally:
session.close()
# 3. SSE 生成器
async def generate():
full_answer = ""
intent = ""
knowledge = []
try:
async for token, it, kn in _customer.answer_stream(query):
full_answer += token
intent = it
knowledge = kn
yield f"data: {json.dumps({'token': token}, ensure_ascii=False)}\n\n"
except Exception:
fallback = "抱歉,服务暂不可用。请确认 Ollama + Milvus + MySQL 均已启动。"
yield f"data: {json.dumps({'token': fallback, 'done': True, 'error': True}, ensure_ascii=False)}\n\n"
return
# 4. 保存 AI 回复到 MySQL
session2 = mysql.get_session()
try:
conv_dao2 = ConversationDao(session2)
conv_dao2.save(
session_id=session_id,
role="assistant",
content=full_answer,
intent=intent,
)
finally:
session2.close()
# 5. 发送结束标记(含检索来源,前端可展示)
yield f"data: {json.dumps({'done': True, 'session_id': session_id, 'intent': intent, 'sources': [{'question': k['question'], 'answer': k['answer'], 'score': k['score'], 'source': k['source']} for k in knowledge]}, ensure_ascii=False)}\n\n"
return StreamingResponse(generate(), media_type="text/event-stream")
# ======================== 查询对话历史 ========================
@router.get("/history/{session_id}", summary="查询对话历史")
async def get_history(session_id: str):
"""查询指定会话的对话记录"""
session = mysql.get_session()
try:
conv_dao = ConversationDao(session)
items = conv_dao.get_session_history(session_id)
return {
"code": 200,
"data": {
"session_id": session_id,
"total": len(items),
"messages": [
{
"id": m.id,
"role": m.role,
"content": m.content,
"intent": m.intent,
"created_at": m.created_at.strftime("%Y-%m-%d %H:%M:%S") if m.created_at else "",
}
for m in items
],
},
}
finally:
session.close()
SSE(Server-Sent Events)原理:
-
服务端不一次性返回结果,而是持续推送
data: {...}\n\n -
前端用
fetch+ReadableStream逐块读取 -
实现打字机效果——token 到了就显示,不等到全部生成完
5.7 数据初始化 — data/feed.py
干什么:一键初始化——建表 + 写入 12 条预设 FAQ + 向量化写入 Milvus。
"""
feed.py — 数据初始化与投喂脚本
==============================
职责:
1. 创建 MySQL 表结构(Faq + ChatLog)
2. 创建 Milvus 集合(含索引)
3. 写入 12 条预设 FAQ 到 MySQL
4. 将 FAQ 向量化后写入 Milvus
运行方式:
python -m data.feed # 模块方式
python main.py --feed # 命令行方式(通过 main.py 调用)
为什么需要这一步?
智能客服需要"知识"才能回答问题。这 12 条 FAQ 是种子数据,
上线后可以通过管理后台持续扩充。
"""
from client.mysql_client import mysql
from client.milvus_client import milvus
from dao.faq_dao import FaqDao
from dao.retrieve_dao import RetrieveService
from config import settings
# ======================== 12 条预设 FAQ ========================
FAQ_DATA = [
("订单", "你们是什么商城",
"我们是一家专注二次元潮玩的电商平台,主营手办、盲盒、毛绒玩偶、吧唧挂件、COS服饰、卡牌桌游等。"),
("订单", "如何退货",
"在「我的订单」找到对应订单,点击「申请售后」,填写退货原因并上传凭证。审核通过后按指引寄回商品,仓库签收确认后3-5个工作日退款到原支付账户。"),
("订单", "多久发货",
"下单后24-48小时内发货。预售商品以页面标注的出货时间为准。大促期间发货可能延迟1-3天。"),
("订单", "如何取消订单",
"待付款和待发货状态的订单可自行取消。已发货订单需先拒收再联系客服。"),
("物流", "怎么查询物流",
"在「我的订单」中点击对应订单,即可看到实时物流跟踪信息。合作物流商包括顺丰、圆通、中通、韵达等。"),
("物流", "商品破损怎么办",
"签收时当场拍照留证,在订单中申请售后并上传破损照片。手办类商品建议开箱时录制视频以便维权。"),
("物流", "包邮政策",
"订单满99元包邮(偏远地区除外)。银牌及以上会员满59元包邮。"),
("支付", "支持哪些支付方式",
"支持支付宝、微信支付和银行卡(银联)。大额订单建议使用支付宝或银行卡。"),
("支付", "退款多久到账",
"支付宝/微信支付1-3个工作日到账,银行卡3-5个工作日。超过5个工作日未到账请联系客服。"),
("商品", "手办是正品吗",
"平台所有商品均为官方授权正品,包括BANDAI万代、GoodSmile、Aniplex等品牌。支持验货,假一赔十。"),
("商品", "盲盒可以指定款式吗",
"盲盒的核心乐趣在于随机性。您可以选择「端盒」保证全套。部分商品支持已拆盒指定款式购买。"),
("会员", "会员等级怎么提升",
"根据累计消费金额自动升级:铜牌(500元)→银牌(2000元)→金牌(5000元)→钻石(10000元)。不同等级享受不同折扣。"),
]
# ======================== 主流程 ========================
def feed_all():
"""数据投喂:MySQL 建表 → 写入 FAQ → Milvus 建集合 → 写入向量"""
print("=" * 50)
print(" 智能客服 — 数据初始化")
print("=" * 50)
# 1. MySQL:建表 + 清空旧数据 + 写入新 FAQ
print("\n[1/4] MySQL 建表...")
mysql.create_all()
print(" ✓ 表结构已就绪")
print("\n[2/4] 写入 FAQ 到 MySQL...")
session = mysql.get_session()
try:
dao = FaqDao(session)
dao.delete_all()
for category, question, answer in FAQ_DATA:
dao.create(question=question, answer=answer, category=category)
count = dao.count()
print(f" ✓ {count} 条 FAQ 已写入")
finally:
session.close()
# 3. Milvus:建集合
print("\n[3/4] Milvus 创建集合...")
try:
if milvus.has_collection(settings.MILVUS_COLLECTION):
from pymilvus import utility
utility.drop_collection(settings.MILVUS_COLLECTION)
print(f" 已删除旧集合 '{settings.MILVUS_COLLECTION}'")
milvus.create_collection(settings.MILVUS_COLLECTION)
print(f" ✓ 集合 '{settings.MILVUS_COLLECTION}' 已创建")
except Exception as e:
print(f" ⚠ Milvus 不可用,跳过向量写入(关键词检索仍可用): {e}")
print("\n" + "=" * 50)
print(" 初始化完成!(向量检索不可用,已降级为 MySQL)")
print("=" * 50)
return
# 4. 向量化 → 写入 Milvus
print("\n[4/4] FAQ 向量化并写入 Milvus...")
session2 = mysql.get_session()
try:
faqs = FaqDao(session2).get_all()
retrieve = RetrieveService()
retrieve.insert_faq_vectors(faqs)
print(f" ✓ {len(faqs)} 条向量已写入")
finally:
session2.close()
print("\n" + "=" * 50)
print(" 初始化完成!启动服务: python main.py")
print("=" * 50)
if __name__ == "__main__":
feed_all()
12 条 FAQ 覆盖的领域:
| 分类 | 问题示例 |
| 订单 | 如何退货、多久发货、如何取消订单 |
| 物流 | 怎么查询物流、商品破损怎么办、包邮政策 |
| 支付 | 支持哪些支付方式、退款多久到账 |
| 商品 | 手办是正品吗、盲盒可以指定款式吗 |
| 会员 | 会员等级怎么提升 |
5.8 应用入口 — main.py
干什么:最简洁的入口——创建 FastAPI 实例,注册路由,支持两种启动模式。
"""
main.py — 应用入口
==================
职责:
1. 创建 FastAPI 应用实例
2. 注册路由(customer 模块)
3. 配置 CORS 中间件(允许前端跨域)
4. 提供命令行入口:--feed(投喂数据)或直接启动服务
启动方式:
python main.py ← 启动服务(默认端口 8080)
python main.py --feed ← 投喂初始数据
"""
import sys
from fastapi import FastAPI
from fastapi.middleware.cors import CORSMiddleware
from config import settings
def create_app() -> FastAPI:
"""创建并配置 FastAPI 应用"""
app = FastAPI(
title=settings.APP_TITLE,
description="基于 RAG 架构的智能客服系统:Ollama + Milvus + MySQL + Sentence-Transformers",
version="2.0",
)
# CORS 跨域(允许前端页面调用 API)
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 注册智能客服路由
from api.customer import router
app.include_router(router)
return app
# 模块级 app 实例(uvicorn 需要 "main:app" 格式)
app = create_app()
if __name__ == "__main__":
if "--feed" in sys.argv:
# 投喂模式:写入初始数据
from data.feed import feed_all
feed_all()
else:
# 正常启动
import uvicorn
uvicorn.run(
"main:app",
host="0.0.0.0",
port=settings.APP_PORT,
reload=True,
log_level="info",
)
5.9 前端界面 — static/index.html
干什么:纯 HTML+CSS+JS 的聊天界面,零框架依赖,fetch 消费 SSE 流。
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>智能客服</title>
<style>
*{margin:0;padding:0;box-sizing:border-box}
body{font-family:'Microsoft YaHei',sans-serif;background:#f0f2f5;display:flex;justify-content:center;align-items:center;height:100vh}
.c{width:520px;height:720px;background:#fff;border-radius:16px;box-shadow:0 4px 24px rgba(0,0,0,.1);display:flex;flex-direction:column;overflow:hidden}
.h{background:linear-gradient(135deg,#667eea,#764ba2);color:#fff;padding:14px 20px;font-size:18px;font-weight:600;display:flex;justify-content:space-between}
.h b{font-size:12px;opacity:.8;font-weight:400}
.m{flex:1;overflow-y:auto;padding:16px;background:#f7f8fa}
.b{margin-bottom:12px;max-width:82%;padding:10px 16px;border-radius:18px;font-size:14px;line-height:1.6;word-wrap:break-word;animation:fade .3s}
.b.u{margin-left:auto;background:linear-gradient(135deg,#667eea,#764ba2);color:#fff;border-radius:18px 18px 4px 18px}
.b.a{margin-right:auto;background:#fff;box-shadow:0 1px 4px rgba(0,0,0,.06);border-radius:18px 18px 18px 4px}
.dot{display:flex;gap:4px;padding:4px 0}.dot span{width:8px;height:8px;border-radius:50%;background:#bbb;animation:dot 1.4s infinite}.dot span:nth-child(2){animation-delay:.2s}.dot span:nth-child(3){animation-delay:.4s}
@keyframes dot{0%,80%,100%{transform:scale(.6)}40%{transform:scale(1)}}@keyframes fade{from{opacity:0;transform:translateY(10px)}to{opacity:1;transform:translateY(0)}}
.inp{display:flex;padding:12px 16px;border-top:1px solid #eee;background:#fff}
.inp input{flex:1;border:1px solid #ddd;border-radius:24px;padding:10px 16px;font-size:14px;outline:none}
.inp button{margin-left:8px;padding:10px 20px;background:linear-gradient(135deg,#667eea,#764ba2);color:#fff;border:none;border-radius:24px;cursor:pointer;font-size:14px}
.inp button:disabled{opacity:.5}
.src{font-size:11px;color:#666;margin-top:6px;padding:6px 8px;background:#e8f5e9;border-radius:8px;border-left:3px solid #4caf50}
.src b{color:#2e7d32}
.welcome{text-align:center;color:#999;margin-top:80px;font-size:14px}
</style>
</head>
<body>
<div class="c">
<div class="h">智能客服 <b>Ollama + Milvus + MySQL</b></div>
<div class="m" id="msgs">
<div class="welcome">你好!我是智能客服小智<br>试试问我「如何退货」「多久发货」吧 👋</div>
</div>
<div class="inp">
<input id="in" placeholder="输入问题..." οnkeydοwn="if(event.key==='Enter')send()">
<button id="btn" οnclick="send()">发送</button>
</div>
</div>
<script>
const m=document.getElementById('msgs'),i=document.getElementById('in'),b=document.getElementById('btn');
function add(role,txt){const d=document.createElement('div');d.className='b '+role;d.textContent=txt;m.appendChild(d);m.scrollTop=m.scrollHeight;return d}
async function send(){
const q=i.value.trim();if(!q||b.disabled)return;i.value='';add('u',q);b.disabled=true;
const t=add('a','');t.innerHTML='<div class="dot"><span></span><span></span><span></span></div>';
try{
const r=await fetch('/chat/stream',{method:'POST',headers:{'Content-Type':'application/json'},body:JSON.stringify({query:q})});
const rd=r.body.getReader(),dc=new TextDecoder();let buf='';t.textContent='';
while(1){const{value,done}=await rd.read();if(done)break;buf+=dc.decode(value,{stream:true});
const ls=buf.split('\n');buf=ls.pop()||'';
for(const l of ls){if(l.startsWith('data: ')){
try{const d=JSON.parse(l.slice(6));if(d.token)t.textContent+=d.token;if(d.done&&d.sources&&d.sources.length){const s=document.createElement('div');s.className='src';s.innerHTML='<b>'+d.sources[0].source+'</b> '+d.sources.map(x=>x.question+' (相似度:'+x.score+')').join(' | ');t.appendChild(s)}}catch(e){}}}}
}catch(e){t.textContent='抱歉,服务暂不可用。请确认 Ollama + Milvus + MySQL 均已启动。'}
b.disabled=false}
</script>
</body>
</html>
5.10 Prompt 模板 — prompts.yaml
干什么:所有 Prompt 模板集中在此 YAML 文件。调 prompt 不用改代码,改这个文件即可
customer_service_prompt: |
【参考资料】
{knowledge}【对话历史】
{history}【用户问题】
{query}你是一个专业的电商客服助手,请基于参考资料回答用户问题。
intent_classification: |
用户输入:"{query}"
判断意图,只返回JSON:{{"intent": "类型"}}
六、完整启动流程
6.1 基础设施
6.1.1 确保ollama处于运行状态,然后运行模型
ollama pull qwen2.5:7b
6.1.2 确保向量库milvus处于运行状态
- 如果是在docker桌面管理,直接点击启动
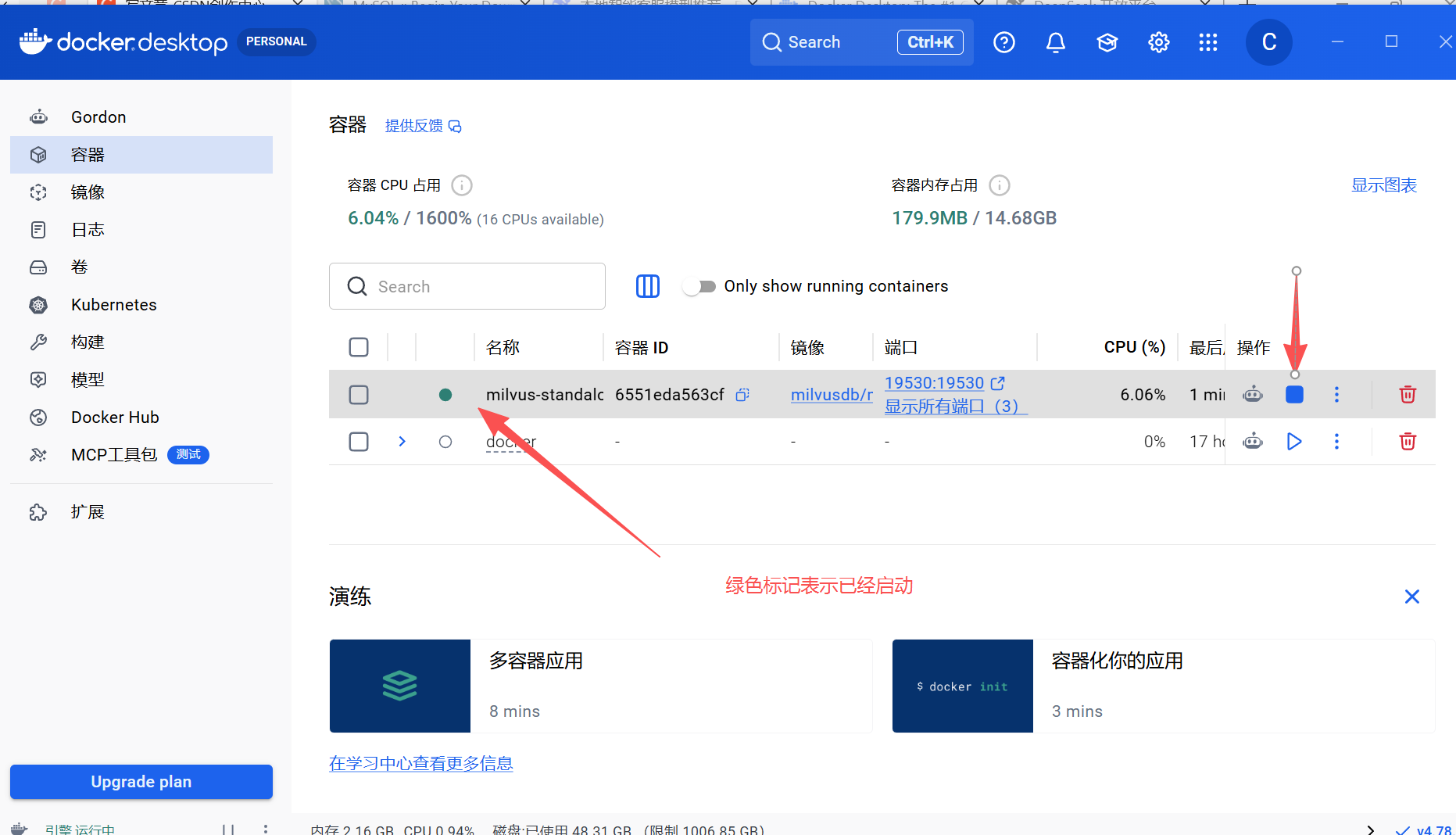
6.1.3确保在mysql数据库里建立好名字为blog_cs的数据库
直接在cmd里输入
mysql -u root -p -e "CREATE DATABASE blog_cs"
6.2确认依赖已经安装完成无遗漏
pip install -r requirements.txt
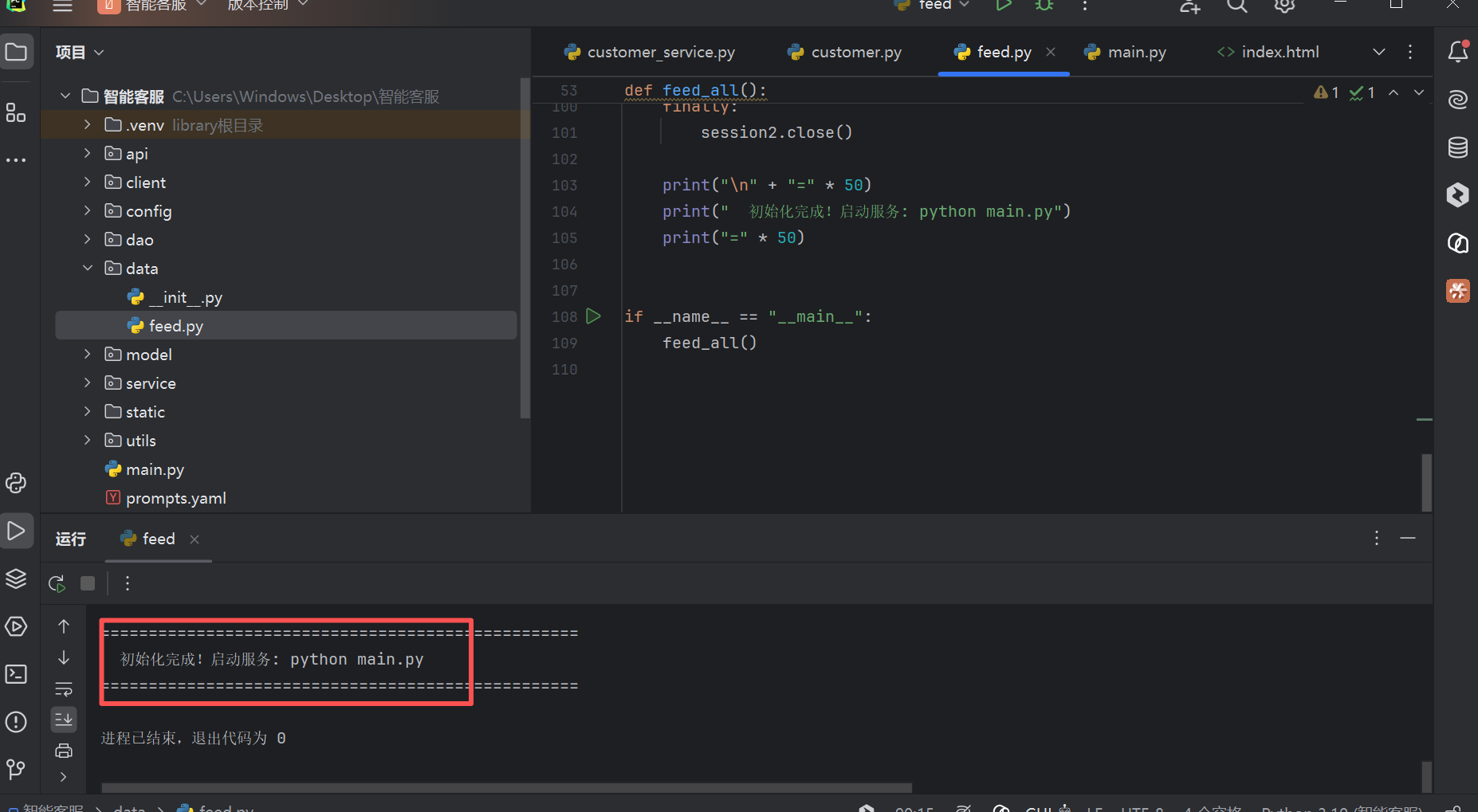
6.3 投喂数据(建表 + 写入 FAQ + 向量化)
- 运行data/feed.py,出现如下信息代表投喂完成
6.4 启动服务,运行main.py
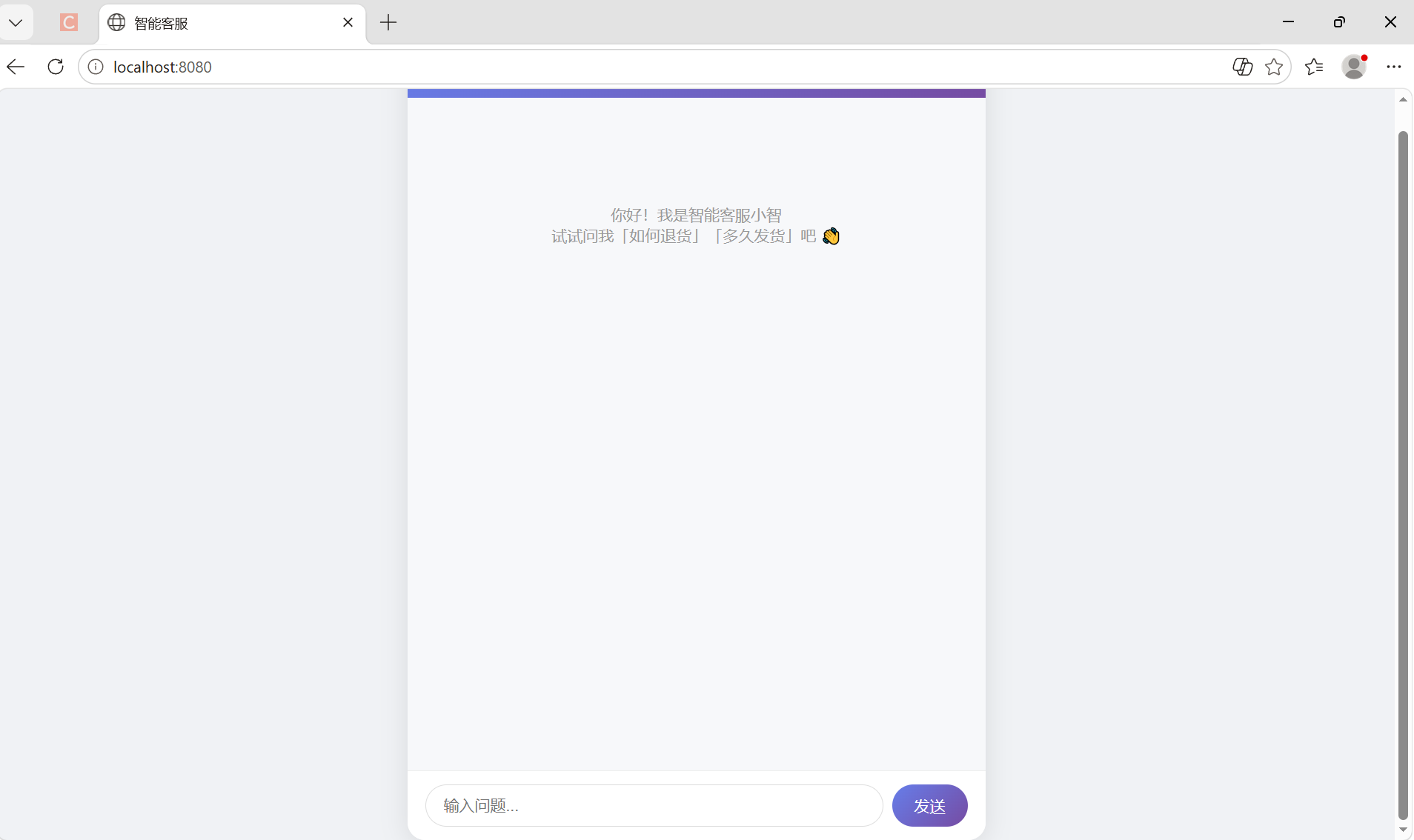
6.5浏览器打开http://localhost:8080
这个网址,一切正常会出现如下界面
七、架构回顾:请求如何走完一圈
7.1 用户输入「怎么退款」→ 回到响应
整个链路:
浏览器 (static/index.html)
│ POST /chat/stream {"query": "怎么退款"}
▼
api/customer.py ← 解析请求,获取 session_id
│
▼
service/customer_service.py ← 核心三段式
│ ├── ① classify_intent("怎么退款") → LLM 返回 → "faq"
│ ├── ② retrieve.hybrid_search_faq("怎么退款")
│ │ ├── utils/embedding.py → [0.12, -0.34, ...] (1024维)
│ │ ├── client/milvus_client.py → search() → top3 FAQ
│ │ └── 降级: dao/faq_dao.py → MySQL LIKE
│ └── ③ load_prompt("customer_service_prompt").format(...)
│ └── utils/prompt_loader.py ← prompts.yaml
│
▼
client/llm_client.py ← Ollama API (流式)
│ POST /v1/chat/completions {"stream": true}
│ ← data: {"choices":[{"delta":{"content":"您"}}]}
│ ← data: {"choices":[{"delta":{"content":"可以"}}]}
▼
api/customer.py ← StreamingResponse (SSE)
│ data: {"token": "您"}\n\n
│ data: {"token": "可以"}\n\n
│ data: {"done": true, "sources": [...]}\n\n
▼
浏览器 ← fetch + ReadableStream → 打字机效果
7.2 为什么这样分层?
每一层只做一件事,层与层之间通过接口约定通信
八、总结与进阶方向
8.1 你现在有什么
一个架构完整的智能客服系统:
-
✅ RAG 混合检索(Milvus 向量 + MySQL 关键词自动降级)
-
✅ 12 条 FAQ 覆盖订单/物流/支付/商品/会员
-
✅ 流式输出(SSE + 打字机效果)
-
✅ 对话历史持久化(MySQL)
-
✅ 意图识别(faq / order / product / chitchat / human)
-
✅ 清晰的分层架构(config → model → client → dao → service → api → main)
8.2 可以往哪些方向扩展
-
更多数据源:接入真实商品库、订单系统、物流信息
-
多模态:支持图片输入(用户拍照上传破损商品)
-
对话摘要:用 LLM 对长对话做摘要,减少上下文窗口压力
-
知识库管理后台:可视化增删改 FAQ,不需要重新投喂
-
监控与统计:记录每轮对话的耗时、用户满意度
-
容器化部署:Docker Compose 一键启动(MySQL + Milvus + Ollama + App)
九.结语
虽然智能客服就搭建完成了,但是这中间很多知识点实际上我们是跳过了,如果你的目标不仅仅是满足于了解于浅层,而是真的想往ai大模型应用开发这个2023年才新兴的领域学习和发展的话,是需要自己去学习以上所用到的技术栈的。
后续我也会出几期博客从ai大模型应用开发的角度,从最基础的Python和MySQL,到向量库和RAG去系统模块化地,深入具体地,讲解以上用到的所有技术栈的,以及更进阶的ai网关、机器学习等等,敬请期待

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)