DeepSeek-OCR:少看多记,突破 OCR 效率极限
摘要:DeepSeek-OCR 通过“视觉压缩”技术,在不牺牲 OCR 准确率的前提下大幅降低了 Token 使用量。本文详细解析了其核心架构 DeepEncoder,展示了如何通过 16 倍压缩将 1024x1024 图像的视觉 Token 压缩至 256 个。实验数据表明,该模型在 10 倍压缩率下仍能保持 97% 的精度,甚至在 20 倍压缩下也能维持 60% 的准确率。这不仅是一个高效的端到端 OCR 系统,更为长文本上下文压缩提供了一种全新的视觉解决方案。
文档解析能否在不牺牲 OCR 准确率的情况下减少 token 使用量?
今天的文章将告诉你答案。
1、重新思考长上下文:用视觉压缩文本
当涉及到长上下文时,大型语言模型就会碰壁。序列长度拉得越长,内存和计算成本就越会飙升,而且这种增长不是线性的,是二次方的。这种扩展曲线一直是许多长上下文策略的阿喀琉斯之踵。
这里有一个聪明的想法:与其试图将越来越长的序列强行塞进语言模型,如果我们完全改变输入会怎样?
核心思想是这样的:将包含文本的文档图像输入到视觉编码器中,将其提炼为最佳且可管理(或最小)数量的视觉 token,然后将这些 token 交给语言解码器重建原始文本。这种方法在现有文档上得到了验证,主要是在 OCR 领域。
这就是**“上下文光学压缩”**。虽然听起来可能有些反直觉,但它是有效的,在接近 10 倍的压缩比下实现了 97% 的 OCR 精度,即使在 20 倍的比率下也能保持约 60% 的准确率。
这种方法最容易在 OCR 任务中进行定量验证,因为在视觉输入和文本输出之间存在自然的压缩-解压缩映射,并且有明确的指标来评估性能。这正是 DeepSeek-OCR 最初被提出的原因。
2、DeepSeek-OCR 究竟如何执行 OCR
2.1 端到端 OCR 管道
从核心上讲,DeepSeek-OCR 获取整个页面,无论是扫描文档还是场景图像,并将其直接输入到一个统一的管道中。图像首先经过 DeepEncoder,它将图像切成块并提取视觉特征。在将这些特征传入全局注意力之前,它应用了一个 16 倍的压缩步骤,显著减少了视觉 token 的数量。
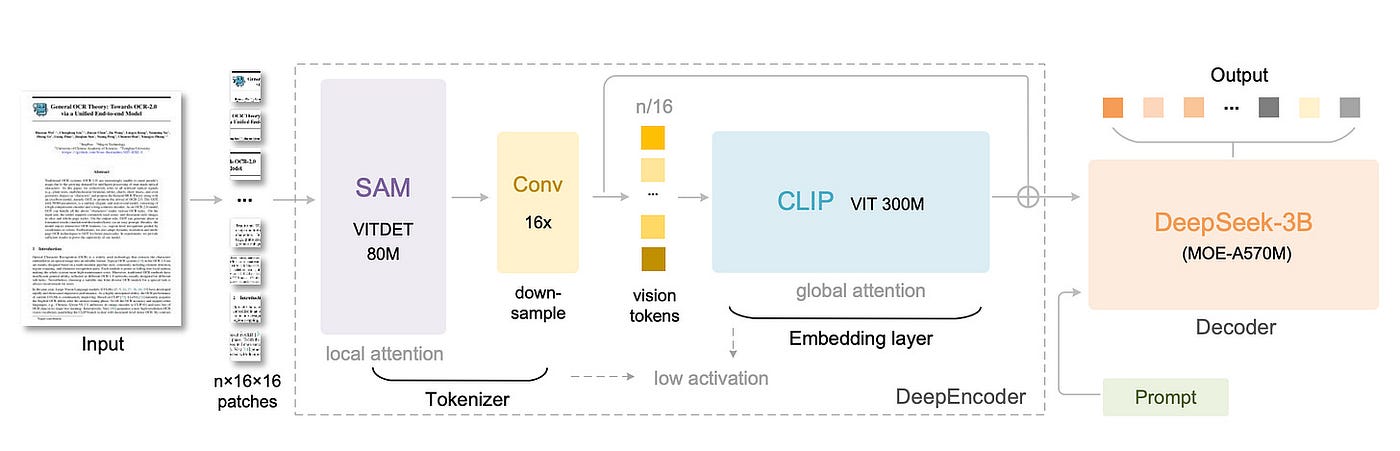
这些压缩后的视觉 token 随后被传递给一个轻量级的 MoE 解码器(基于 DeepSeek-3B-MoE),该解码器直接生成相应的文本或结构化输出。换句话说,它在一个流畅的步骤中读取图像并写出文本。
2.2 更少 Token 和更快推理的秘密
DeepSeek-OCR 背后的架构针对 token 效率进行了优化,且没有牺牲性能。
DeepEncoder 由一个两阶段编码器构建。前半部分专注于局部感知,通过 SAM 基础的视觉感知组件(具体是 ViTDet) 使用窗口注意力;后半部分处理全局理解,使用密集注意力(通过 CLIP-large)。在两者之间,一个由两个卷积层组成的模块(每个步长为 2) 将视觉 token 下采样(压缩)了 16 倍。因此,对于一个通常会产生 4096 个 token 的 1024×1024 图像,这种压缩在进入全局注意力之前将其减少到了仅 256 个。这极大地削减了内存使用和序列长度。
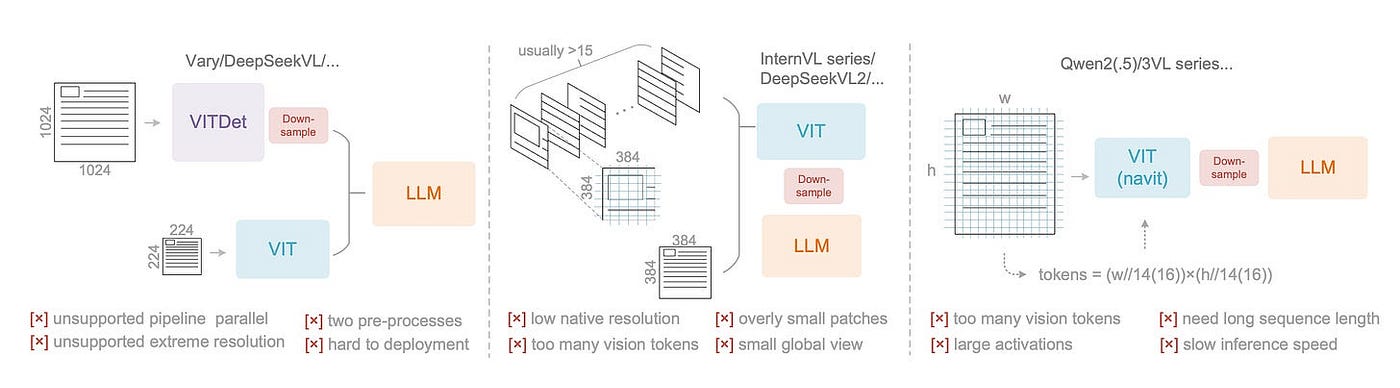
为了处理不同复杂度的文档,DeepSeek-OCR 支持多种分辨率模式 —— Tiny, Small, Base, Large, Gundam, 和 Gundam-M —— 对应不同数量的视觉 token(范围从 64 到近 2000)。对于像报纸这样的密集布局,它使用了一种平铺局部视图加全局视图的智能组合,他们称之为“高达模式(Gundam mode)”,以平衡准确性和速度。
在解码方面,它使用了一个总共有 30 亿参数的 MoE 解码器。在推理过程中,它仅激活 64 个专家中的 6 个,加上 2 个共享专家,总共约 5.7 亿个活跃参数。这赋予了它大型模型的表现力,同时以小型模型的效率运行。
3、DeepSeek-OCR 如何像阅读文本一样阅读图像
训练一个模型读取图像并输出结构化文本并非易事。在 DeepSeek-OCR 看似简单的输出背后,是一个精心设计的管道和训练过程,旨在教模型不仅仅是看,而是去理解。
3.1 专用数据引擎
DeepSeek-OCR 性能的支柱是其数据的规模和多样性。团队构建了他们所谓的“数据引擎”,由几个组件组成:
- OCR 1.0 涵盖传统文档和场景文本。这包括 3000 万页的多语言 PDF(带有精细和粗略的注释)、来自 LAION 和 Wukong 的各 1000 万张自然图像(带有中英文标签),以及 300 万份与纯文本配对的 Word 文档。精细注释使用一种丰富的格式,将布局元数据(如段落坐标和标签)直接嵌入到文本旁边,坐标被归一化为 1000 个区间。

- OCR 2.0 使用合成数据解决更复杂的结构化解析任务。这包括用 pyecharts 和 matplotlib 渲染的 1000 万个图表,使用 RDKit 从 SMILES 字符串生成的 500 万个化学结构图,以及 100 万个受教育材料启发的平面几何图形。
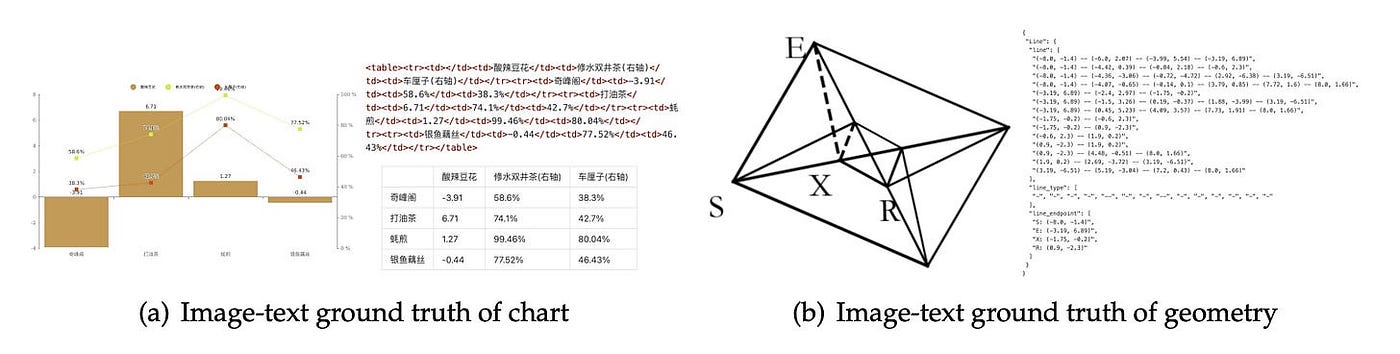
- 为了完善数据,他们包含了通用视觉数据和纯文本语料库。这确保了模型保留更广泛的视觉理解和扎实的语言建模能力。最终的训练混合大约是 70% 的 OCR 任务,20% 的通用视觉,和 10% 的纯文本。
3.2 两阶段训练过程
训练主要分为两个阶段。
首先,他们使用下一个 token 预测(NTP)框架训练 DeepEncoder。它在两个 epoch 中看到了长度为 4096 的序列,使用 AdamW 和余弦学习率调度进行优化。这一阶段帮助编码器学习如何将图像转化为压缩但有意义的视觉 token。
随后是对整个 DeepSeek-OCR 管道的全面端到端训练。这是通过四个阶段的管道并行完成的,为了稳定性,管道的部分被冻结;具体来说,视觉分词器的 SAM 和压缩器组件 被冻结,而 CLIP 部分保持解冻并被训练。
训练使用 640 的全局批大小运行,同样使用 AdamW。该设置在效率与灵活性之间取得了平衡,使得在不过度消耗算力的情况下进行扩展成为可能。
3.3 推理时的智能 Token 核算
一个值得注意的细节是模型的 token 效率是如何被评估的。在为了保持纵横比而填充图像的模式中,DeepSeek-OCR 计算“有效视觉 token”的数量,以报告和分析有多少 token 对应于原始图像内容。这为理解更高压缩比下的性能提供了一个更精确的指标。
4、评估
4.1 挑战压缩极限(在 Fox 上)
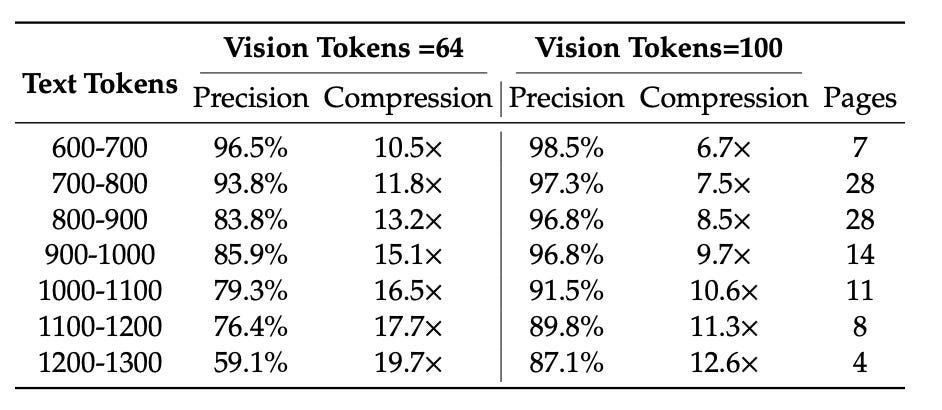
为了测试极限,DeepSeek-OCR 在 Fox 基准测试上进行了实验,该基准测试包含每页 600 到 1300 个文本 token 的英文文档。它尝试了两种设置,Tiny(64 个视觉 token)和 Small(100 个 token),并比较了不同压缩级别的 OCR 准确性。
这是他们的发现:
- 在约 10 倍压缩下,模型仍能达到约 97% 的精度
- 在 10 到 12 倍时,它保持良好,约为 90%
- 即使在接近 20 倍时,它仍能维持约 60%
考虑到基准测试的格式并不总是与模型的输出风格完美匹配,现实世界的表现可能比原始数字略好。这仍然是一个强烈的信号,表明 DeepSeek-OCR 可以处理严重的压缩而不崩溃。
4.2 真实文档上的实际 OCR 性能
当然,基准测试结果只是图景的一部分。真正的考验是模型在杂乱的现实世界文档上的表现,这正是 OmniDocBench 发挥作用的地方。
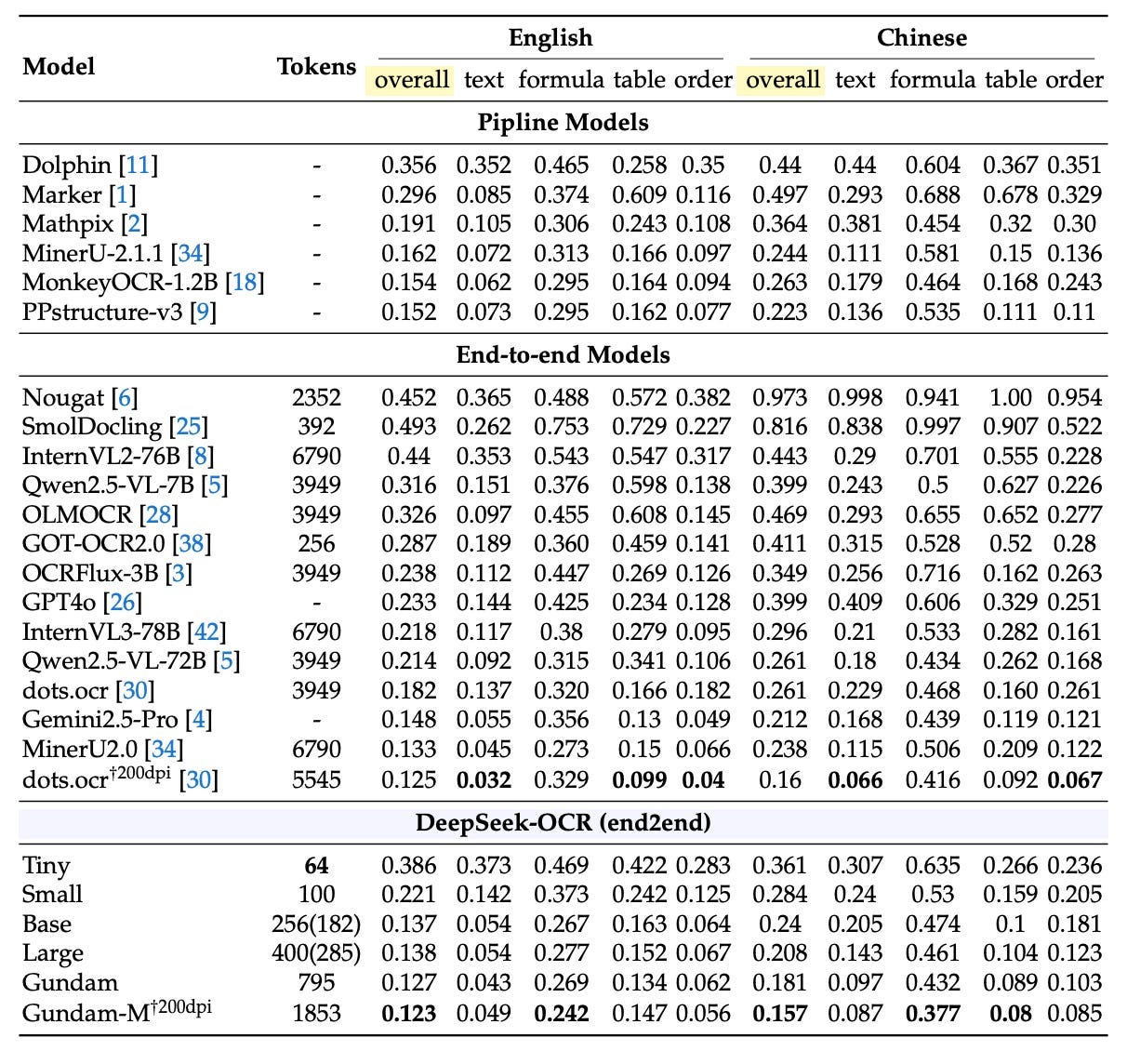
使用编辑距离作为指标(越低越好),DeepSeek-OCR 即使在紧张的 token 预算下也能提供可靠的结果:
- 仅用 100 个视觉 token(Small 模式,640×640 分辨率),它就优于 GOT-OCR2.0,后者需要 256 个 token。
- 在 400 个 token(Large 模式,填充后 285 个有效 token)下,它与几个最先进的模型相当。
- 在 Gundam 模式下,这是一种使用不到 800 个 token 的混合设置,它实际上击败了 MinerU2.0,后者每页依赖近 7000 个视觉 token。
这些结果表明,DeepSeek-OCR 不仅仅是一个学术原型。它是一个已经在生产中用于大规模数据生成的实用工具,以一小部分的计算成本提供有竞争力的 OCR 性能,能够在单个 GPU 上每天生产超过 20 万页的训练数据。
5、思考
审视训练设置和结果,有一点很重要需要澄清:DeepSeek-OCR 不接收文本。它接收图像。 这是一个关键的区别。
它所做的是量化文本通过视觉表示的效果,以及你可以将这种压缩推进多远而仍能获得准确的解码。在这个意义上,DeepSeek-OCR 作为一个代理测试平台,服务于一个更大的想法:使用视觉作为载体,光学地压缩长文本上下文。
但要明确的是,DeepSeek-OCR 尚未完全证明在真实 LLM 工作流中的端到端长上下文压缩。这仍然是一个开放的挑战。
那么 DeepSeek-OCR 到底是什么?本质上,它是一个端到端的 OCR 系统,旨在推动性能和效率的边界。但在这个过程中,它也让我们得以一窥如果我们开始不仅仅将视觉视为输入,而是作为大规模文本压缩的媒介时可能发生的事情。在这个意义上,该项目具有双重功能:构建更好的 OCR 管道,同时悄悄地测试通过视觉通道进行长上下文压缩的可行性。
当然,从理解现代 OCR 系统如何工作以及该领域的发展方向来看,DeepSeek-OCR 也是有价值的。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 12
12 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)