Claude Opus 4.7 发布!能力获得飞跃提升
昨天,4月16日,Anthropic 宣布,最新模型 Claude Opus 4.7 已正式发布。
与 Opus 4.6 相比,Opus 4.7 在高级软件工程方面有明显提升,尤其是在最困难的任务上。用户反馈称,他们现在可以更放心地把过去必须密切监督的高难度编程任务交给 Opus 4.7。它在处理复杂、长时运行的任务时更加严谨和稳定,能更精准地遵循指令,并会在给出结果前主动设计方式验证自己的输出。
这个模型的视觉能力也有了显著增强:它能以更高分辨率理解图像。在完成专业任务时,它在界面、幻灯片和文档生成上也更有品味、更具创造力。虽然它的整体能力仍不如 Anthropic 当前最强的 Claude Mythos Preview(这个最强模型就是之前传的 Opus 5.0),但在多项基准测试中,Opus 4.7 都比 Opus 4.6 表现更好。
Anthropic 官方给出的总体对比图
Opus 4.7 在多个基准上高于 Opus 4.6,但仍然弱于内部的 Mythos Preview。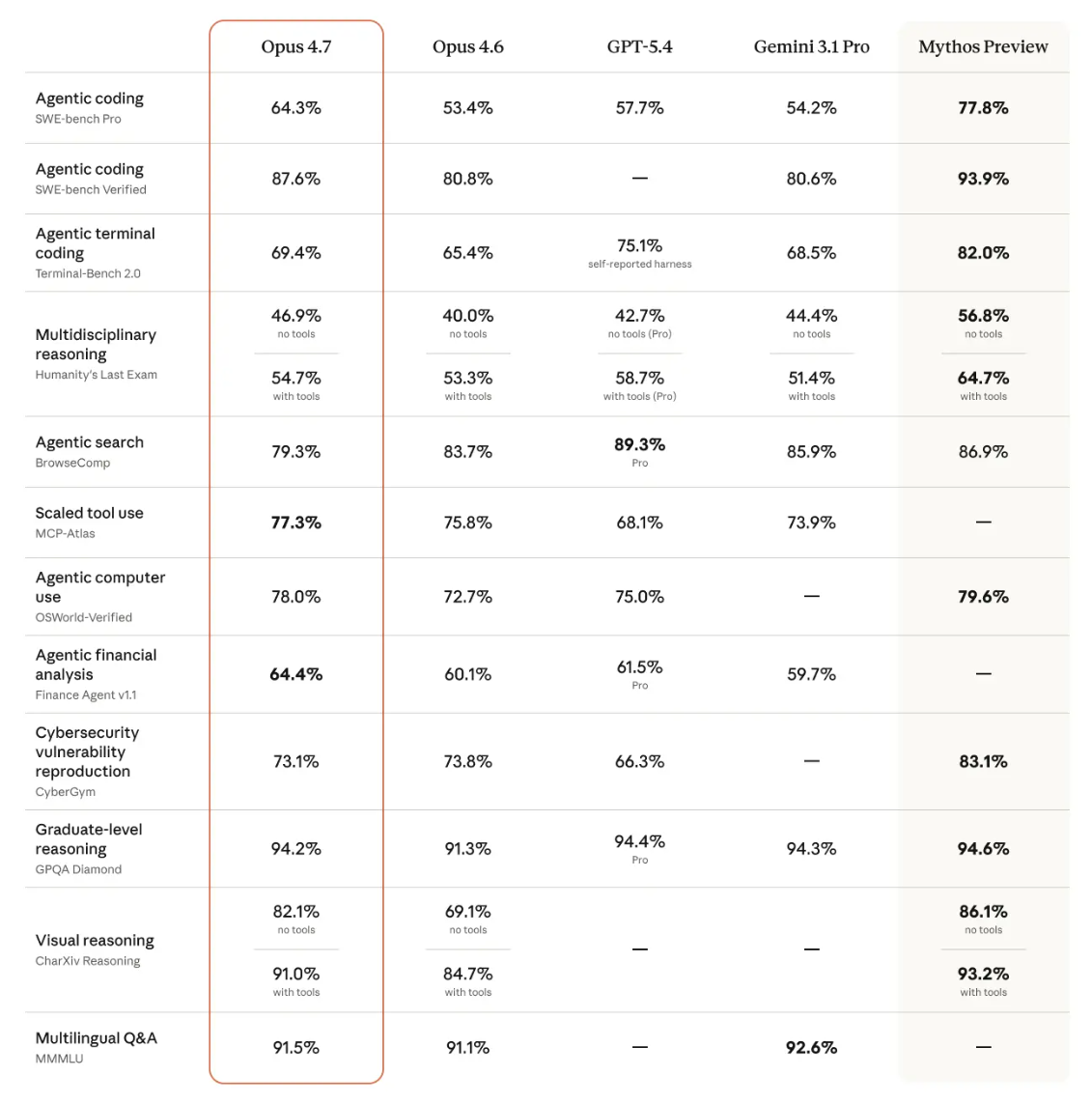
Opus 4.7 现已在所有 Claude 产品、Claude API、Amazon Bedrock、Google Cloud Vertex AI 和 Microsoft Foundry 上可用。价格与 Opus 4.6 保持一致:每百万输入 token 5 美元,每百万输出 token 25 美元。
能力提升
指令遵循更强
Opus 4.7 在遵循指令方面显著更强。这也意味着,为旧模型编写的一些提示词,到了 4.7 上可能会产生意料之外的结果:以前的模型可能会更宽松地理解指令,或直接忽略其中一部分,而 Opus 4.7 倾向于按字面更严格地执行。因此,用户应相应重新调整提示词和测试框架。
多模态能力增强
Opus 4.7 对高分辨率图像的处理更强。它可接收长边最高 2576 像素的图像,约 375 万像素,超过此前 Claude 模型的 3 倍以上。这让很多依赖细节识别的多模态场景成为可能,例如读取密集截图的电脑操作智能体、从复杂图表中提取数据,以及需要像素级参考精度的工作。
现实工作能力更强
除在金融智能体评测中达到先进水平外,Anthropic 的内部测试还显示,Opus 4.7 比 Opus 4.6 更像一位高效的金融分析师,能够输出更严谨的分析和模型、更专业的演示文稿,以及跨任务更紧密的整合结果。它在 GDPval-AA 这类衡量金融、法律等高价值知识工作能力的第三方评测中同样达到领先水平。
记忆能力更好
Opus 4.7 提供 1M 的上下文窗口,让其更善于使用基于文件系统的记忆。它能在长时间、跨会话的工作中记住重要说明,并在后续任务中使用这些信息,因此新任务需要的前置上下文更少。
安全策略略微减弱
虽然Opus 4.7 相比 Opus 4.6 安全策略减弱,但评估显示,它在欺骗、逢迎、配合滥用等令人担忧的行为上仍保持较低比例。在某些方面,Opus 4.7 比 Opus 4.6 更强,例如诚实性,以及抵御恶意提示注入攻击的能力;但在另一些方面,它略有减弱,例如在某些受控物质相关问题上,给出过于详细减害建议的倾向。Anthropic 的对齐评估认为,这个模型“总体上对齐良好且值得信赖,但其行为仍未达到完全理想”。同时,Mythos Preview 依然是他们评估中训练出来的对齐性最强的模型。Anthropic 还表示,Opus 4.7 已加入会自动检测并拦截被禁止或高风险网络安全用途请求的安全防护措施。
其它更新
分词器更新
Opus 4.7 使用了更新后的 tokenizer,提升了模型处理文本的方式。代价是,相同输入在新模型下可能会映射成更多 token,大约是原来的 1.0 到 1.35 倍,取决于内容类型。
更细的 effort 控制
Opus 4.7 新增 xhigh(extra high)级别,位于 high 和 max 之间,让用户能更细致地控制高难问题中“推理深度”和“延迟”之间的权衡。在 Claude Code 中,所有方案的默认 effort 级别已提升到 xhigh。官方建议在编程或智能体场景中优先从 high 或 xhigh 开始测试。尤其在智能体场景的后续轮次中,Opus 4.7 在较高 effort 级别下会投入更多思考。这会提升其在困难问题上的可靠性,但也意味着它可能生成更多输出 token。
Claude Platform(API)更新
除了支持更高分辨率图像外,平台还上线了公开测试版的任务预算(task budgets),方便开发者控制 Claude 在长时间运行任务中的 token 消耗分配。
Claude Code 更新
新增 /ultrareview 命令,可启动更深入的审查会话,找出细心审查者才会发现的 bug 和设计问题。Pro 和 Max 用户可免费体验 3 次 ultrareview。Anthropic 同时把 auto mode 扩展到了 Max 用户,使 Claude 能代表用户做部分权限决策,从而以更少打断运行更长的任务。
适用场景
高级编程
Opus 4.7 可以在较少监督下生成可投入生产环境的代码,规划更周密,长时间持续工作更稳定,在大型代码库中也更可靠,还能主动发现并修正自己的错误。
AI 智能体
它适合驱动生产级智能体工作流,能稳定地编排复杂的多工具任务,善于谨慎规划,并能结合记忆在跨会话工作中持续学习。
企业工作流
它能跨会话保持上下文,管理复杂、跨天的大型项目,在表格、幻灯片和文档等日常知识工作中表现出专业水准。
总结
Opus 4.7 相对 Opus 4.6,在编程能力上显著增强,在高难度任务上表现突出,视觉分辨率提升至过去的三倍多,但是相应地,消耗 token 也更多,百万 token 的价格维持不变。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 2
2 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)