一文读懂 Qwen3.6 GGUF 量化命名:从 Q4_K_M 到 UD-IQ3_XXS,别再下错模型了!
摘要:Qwen3.6-35B-A3B 开源了超多 GGUF 量化版本,但面对满屏的
UD-Q5_K_M、IQ3_XXS、mmproj等命名,你是不是一脸懵?本文手把手拆解 llama.cpp 量化命名规范,帮你快速选对适合自己显存的版本,避免踩坑!
最近阿里通义实验室开源了 Qwen3.6-35B-A3B,作为一款仅激活 3B 参数就能媲美 27B 稠密模型的 MoE 架构大模型,它迅速成为了端侧部署的热门选择。不过打开 ModelScope 或 Hugging Face 一看,好家伙,几十个 GGUF 文件扑面而来——UD-Q5_K_M、IQ3_XXS、MXFP4……这些命名到底啥意思?哪个适合自己的显卡?
今天这篇就帮你彻底理清 llama.cpp GGUF 量化命名规范,从此下载模型不再迷茫!
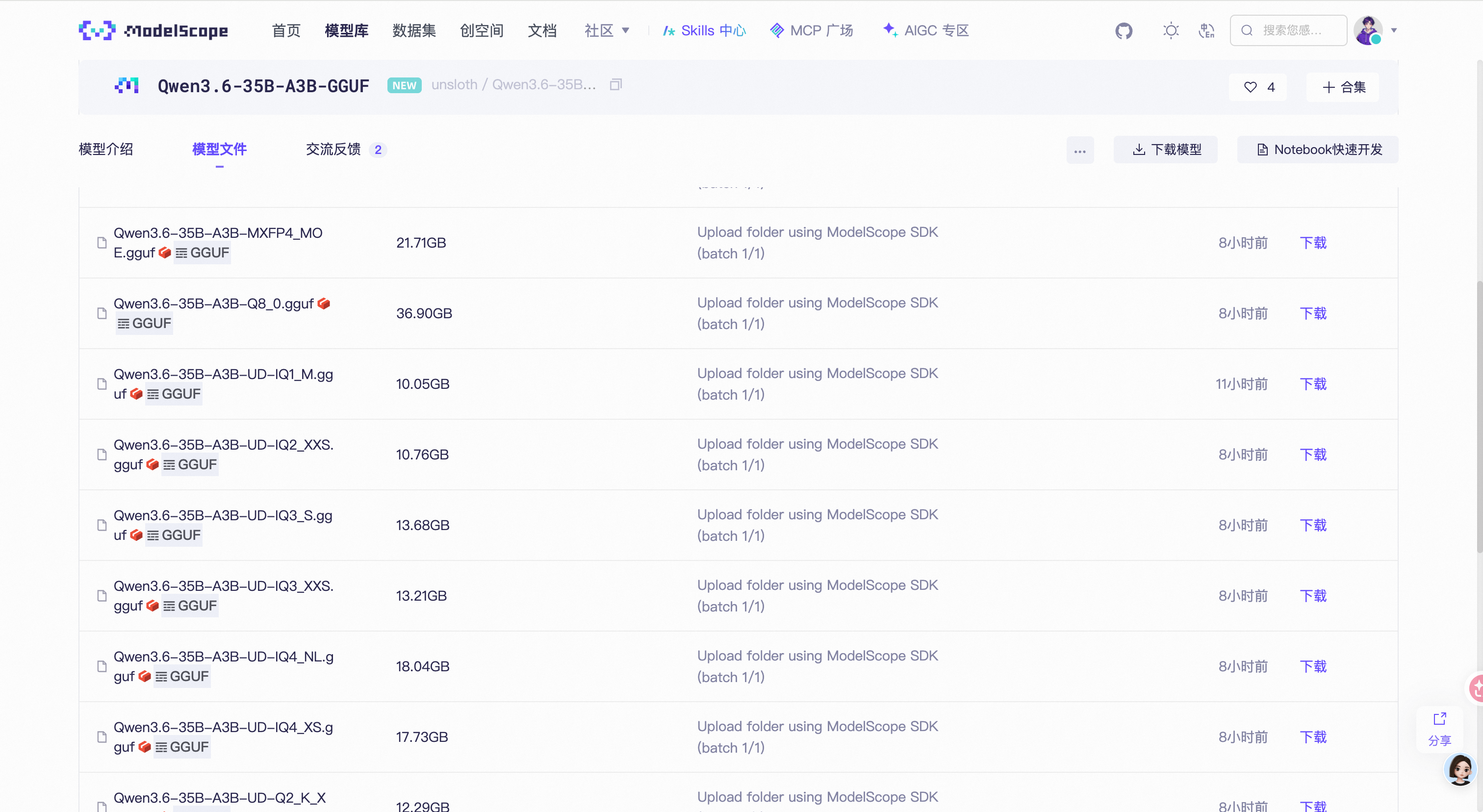
命名结构全景解析
GGUF 文件的命名遵循一套相对固定的规则:
Qwen3.6-35B-A3B-[量化方案]-[量化级别]_[变体].gguf
下面我们从左到右逐个拆解。
一、前缀部分:模型身份标识
| 字段 | 含义 |
|---|---|
| Qwen3.6-35B-A3B | 模型名称:Qwen3.6 系列,35B 总参数,3B 激活参数(MoE 架构) |
| UD | Unsloth Dynamic 量化(Unsloth 团队优化的动态量化方案,质量更优) |
| MXFP4 | Microsoft 的 FP4 浮点格式(4-bit 浮点,需 RTX 50 系显卡支持) |
| BF16/F32 | Brain Float 16 / Float 32(原始精度,非量化,体积最大) |
小贴士:看到 UD 前缀优先选,这是 Unsloth 团队优化的版本,同等体积下精度通常更好。
二、核心量化类型:IQ / Q / K 是什么?
| 类型 | 全称 | 说明 |
|---|---|---|
| IQ | Importance Quantization | 重要性感知量化,智能识别关键权重并保留更高精度,适合追求质量的用户 |
| Q | Standard Quantization | 标准量化,中规中矩 |
| K | K-quants | llama.cpp 改进的量化算法,通过优化分组策略提升质量,推荐优先选择 |
选择建议:同等条件下,K-quants > 标准 Q > IQ(视具体实现而定),Q4_K_M 通常是性价比之王。
三、量化级别:数字越小,体积越小
| 数字 | 含义 | 典型显存占用 | 适用场景 |
|---|---|---|---|
| Q2 | 2-bit 量化 | ~10GB | 极限压缩,质量损失较大 |
| Q3 | 3-bit 量化 | ~13-17GB | 低显存设备应急使用 |
| Q4 | 4-bit 量化 | ~17-21GB | 甜点级,大多数用户首选 |
| Q5 | 5-bit 量化 | ~24-27GB | 高质量需求,接近原始精度 |
| Q6 | 6-bit 量化 | ~29-32GB | 接近无损,需大显存 |
| Q8 | 8-bit 量化 | ~37GB | 几乎无损,但体积爆炸 |
四、后缀变体:S/M/L 怎么选?
| 后缀 | 含义 | 说明 |
|---|---|---|
| _XXS | Extra Extra Small | 极小体积,精度最低,仅应急 |
| _XS | Extra Small | 超小体积,适合速度优先 |
| _S | Small | 小体积,速度较快 |
| _M | Medium | 黄金平衡点,推荐! |
| _L / _XL | Large / Extra Large | 大体积,最高精度 |
| _NL | Non-Linear | 非线性量化,特殊优化场景 |
| _K_M / _K_X | K-quants 变体 | K-quants 下的 Medium/Extra Large 分级 |
记忆口诀:S 快 M 稳 L 准,日常用 M,追求极致选 L,显存紧张选 S。
五、特殊文件:mmproj 和 imatrix 是干嘛的?
| 文件名 | 用途 | 是否必须 |
|---|---|---|
| mmproj-xxx.gguf | Multi-Modal Projector(多模态投影器/视觉编码器) | ✅ 用视觉功能时必须 |
| imatrix_unsloth.gguf | Importance Matrix(重要性矩阵) | ❌ 可选,用于提升 IQ 量化质量 |
多模态使用示例:
./llama-cli \
--model Qwen3.6-35B-A3B-UD-Q5_K_M.gguf \
--mmproj mmproj-BF16.gguf \
--image your_image.jpg \
--prompt "描述这张图片"
六、实战选型:以 32GB 显存(Orin NX)为例
| 推荐度 | 版本 | 大小 | 说明 |
|---|---|---|---|
| ⭐⭐⭐ | UD-Q5_K_M | 26.46GB | 最佳平衡点,精度高且留有余量 |
| ⭐⭐⭐ | UD-Q5_K_S | 24.94GB | 性价比之选,速度更快 |
| ⭐⭐☆ | UD-Q4_K_M | 16.60GB | 速度快,但精度略降 |
| ⭐⭐☆ | UD-Q6_K | 29.06GB | 精度最高,但接近显存上限 |
避坑提醒:
- ❌ Q8_0 (36.90GB) → 超出 32GB 显存,需内存 offload,速度暴跌
- ❌ MXFP4 (21.71GB) → 需要硬件 FP4 支持(RTX 50 系列),老显卡别下
七、一张图看懂命名
UD-Q4_K_M = Unsloth Dynamic + 4-bit K-quants + Medium 变体
↑ ↑ ↑ ↑
量化方案 量化算法类型 比特数 精度/体积等级
总结
| 场景 | 推荐版本 |
|---|---|
| 16GB 显存 | UD-Q4_K_M / UD-Q4_K_S |
| 24GB 显存 | UD-Q5_K_S |
| 32GB 显存 | UD-Q5_K_M / UD-Q6_K |
| 纯文本推理 | 任意主模型 |
| 图文多模态 | 主模型 + mmproj-BF16.gguf |
选对量化版本,能让你的大模型在有限显存里跑出最佳性能。希望这篇解析能帮你告别选择困难症,快速找到适合自己设备的模型!
标签:Qwen3.6 llama.cpp 大模型量化
感谢阅读!如果这篇文章帮到了你,欢迎点赞收藏转发,让更多小伙伴少走弯路~ 有任何问题欢迎在评论区留言交流!
本文为原创内容,版权归作者所有,转载需注明出处。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐
 11
11 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)