纵向随访数据预测模型如何挑选?这项研究告诉你为什么GMERF更胜一筹(附R代码)

源自风暴统计网:一键统计分析与绘图的网站
从临床角度而言,糖尿病前期(Prediabetes)的早期识别具有重要公共卫生意义——通过生活方式干预和药物治疗,完全有可能延缓甚至阻止糖尿病的发生。
然而,有效的风险筛查工具仍然缺乏。这引出了一个核心的统计学问题:如何利用纵向随访数据,构建能够准确识别高风险个体的预测模型?
今天我们就基于一篇文献,探讨在处理具有重复测量特征的纵向数据时,应当如何选择合适的预测模型。

该研究共纳入5361名年龄>20岁、基线健康且至少参与两轮随访的参与者,旨在比较广义线性混合模型(GLMM)、随机森林(RF)和广义混合效应随机森林(GMERF)三种方法在糖尿病前期风险预测中的表现。
纵向数据的特点:组内相关性的挑战
首先,让我们理解本研究中数据的特点与挑战。
研究数据来源于一项始于1998年的前瞻性队列研究,每3-4年进行一次随访,目前已开展7个阶段。
经筛选后共纳入5361名参与者,他们在多个时间点接受了随访,因此数据具有典型的纵向数据结构。研究包含32个潜在预测变量,涵盖人口学特征、病史、体格检查和血液生化指标。
-
此类数据的一个关键统计学特征是,同一受试者的多次测量之间存在组内相关性。
个体的生物学特征随时间的变化并非独立,而是受其自身基线水平、遗传背景和生活方式等因素的共同影响。
这种相关性结构若在建模时被忽略,将导致对样本信息的错误估计,并影响模型的推断和预测泛化能力。
三种预测模型应当如何选择
为什么不同的预测模型在处理此类纵向数据时会表现出差异?关键在于它们对数据结构的假设和处理方式不同。本研究系统比较了以下三种模型:
模型一:GLMM(广义线性混合模型)
作为处理纵向数据的经典参数模型,它通过引入随机效应来刻画个体的异质性,从而正确建模数据的组内相关性。
然而,GLMM的局限在于需要预先指定预测变量与结局间的线性关系,难以捕捉现实中可能存在的非线性效应和高阶交互作用。这可能是其预测性能略逊于GMERF的原因。
模型二:RF(随机森林)
通过集成多棵决策树,能够自动捕捉变量的非线性关系和复杂交互。
但RF的基本假设是样本独立同分布。当应用于纵向数据时,它会将同一受试者的多次测量视为相互独立的观测,完全忽略数据的聚类结构即组内相关性。
这种对数据结构特征的忽视,导致模型对样本量的错误估计,使得变量重要性评估产生偏倚。最终在本研究的性能比较中,RF表现最差。
模型三:GMERF(广义线性混合效应随机森林)
作为一种将两者优势相结合的混合模型,GMERF核心原理是在GLMM框架下,用随机森林替代原有的线性固定效应部分。
-
通过随机效应部分,GMERF保留了对数据组内相关性的建模能力;
-
通过随机森林部分,它又能自动拟合预测变量与结局间的非线性关系和交互效应。
这种双重建模能力使其既克服了GLMM的线性假设束缚,又弥补了RF忽视数据结构的缺陷。
值得注意的是,腰臀比在所有模型中均位居前列,提示中心性肥胖指标的核心地位。
时间变量在GMERF中成为重要预测因子,反映出风险的动态演变趋势——随着随访阶段的推进,即使其他风险因素不变,个体累积暴露风险也在增加。
研究结果显示,GMERF在准确性、敏感性、特异性、F1分数和ROC曲线下面积等所有评价指标上均表现最优,RF最差。

这一结果我们可以从统计学方面进行解释:
首先,RF的性能劣势源于其对数据结构的忽视——独立性假设的违背导致模型对样本信息的过度估计,将相关观测误认为独立重复,使得变量重要性评估产生偏倚,最终影响预测泛化能力。
GLMM通过随机效应正确建模了组内相关性,因而表现优于RF。但其线性假设限制了捕捉复杂效应的能力,导致预测性能略逊于GMERF。
GMERF的成功在于同时兼顾了数据相关性和函数形式灵活性——随机效应部分控制了个体水平的异质性,随机森林部分则自动拟合了预测变量与结局间的非线性关系和交互效应,实现了两种方法的优势互补。
文章小结
本研究通过对GLMM、RF和GMERF三种模型的系统比较,揭示了纵向数据分析中模型选择的核心原则——必须与数据结构相匹配。
GMERF作为一种将随机效应与随机森林相结合的混合模型,在保持对组内相关性建模能力的同时,赋予模型拟合非线性关系的灵活性,在糖尿病前期风险预测任务中展现出最优性能。
其识别的核心风险因素——腰臀比、年龄、腰围、甘油三酯——具有明确的临床可操作性和公共卫生意义。
代码实操:从零实现GMERF
理解了理论,我们来动手实现。以下是完整的GMERF函数:
# 加载必要的包library(tidyverse)library(ranger)library(lme4)
# GMERF核心函数gmerf_ranger <- function(y, data, gr, fam, b0=NULL, toll=1e-4, itmax=100, ...) {
original_order <- unique(pull(data, !!sym(gr))) Z <- matrix(rep(1, nrow(distinct(data, !!sym(gr))))) rownames(Z) <- original_order
if (is.null(b0)) { b <- rep(0, length = length(Z)) } else { b <- b0 }
names(b) <- original_order all.b <- list() all.b[[1]] <- b variables_ <- names(data)
# 构建固定效应公式 formula_ <- formula( paste0(y, ' ~ ', paste0(variables_[which(!variables_ %in% c(gr, y, 'student_id'))], collapse = ' + ') ) )
# 初始GLM拟合 glm_fit <- glm(formula = formula_, data = data %>% select(-contains('_id')), family=fam)
eta_df <- data %>% mutate(!!sym(gr) := as.character(!!sym(gr)), eta = predict(glm_fit, data = ., type="link"))
eta <- eta_df %>% pull(eta)
it <- 1 conv <- FALSE
# 迭代优化:核心算法循环 while (it < itmax && !conv) {
targ_step1 <- Z * b
rf_df <- data.frame(targ_tmp = targ_step1[,1]) %>% rownames_to_column(gr) %>% inner_join(eta_df, by = gr) %>% mutate(targ = eta - targ_tmp)
# 随机森林拟合残差 rf_fit <- ranger( y = rf_df$targ, x = select(rf_df, -targ, -eta, -targ_tmp, -contains('_id')), importance = "impurity", seed = 123, ... )
rf_df <- rf_df %>% mutate(fx = predict(rf_fit, data=.)$predictions, outcome_tmp = eta - fx)
# 线性混合模型更新随机效应 formula_2_ <- formula(paste0('outcome_tmp ~ 0 + (1 | ', gr, ')')) glmm_fit <- lmer(formula_2_, data = rf_df)
b <- matrix(ranef(glmm_fit)[[gr]][['(Intercept)']]) all.b[[it+1]] <- b
# 收敛判断 M <- max(abs(b - all.b[[it]])) i <- which.max(abs(b - all.b[[it]])) tr <- M / all.b[[it]][i]
if (tr < toll) { conv <- TRUE } else { conv <- FALSE } it <- it + 1 }
if (!conv) { warning("The algorithm did not converge.") }
result <- list( final_glmm = glmm_fit, final_rf = rf_fit, b = b, it = it ) return(result)}
# 预测函数predict_gmerf <- function(object, newdata, gr = 'school_id', link_fn = NULL) { final_glmm <- object$final_glmm final_rf <- object$final_rf
logit_preds <- newdata %>% mutate( !!sym(gr) := factor(school_id), rf_preds = predict(final_rf, data=.)$predictions, ) %>% inner_join( data.frame(ranef(final_glmm))%>% select(!!sym(gr) := grp, condval), by = gr ) %>% mutate( logit_pred = condval + rf_preds ) %>% pull(logit_pred)
if (is.null(link_fn)){ return(logit_preds) } if (link_fn == 'binomial'){ return(plogis(logit_preds)) }}为了验证算法有效性,我们生成具有组内相关性的模拟数据:
# 生成模拟数据set.seed(123)n_schools <- 50 # 50个组(学校ID)n_per_school <- 10 # 每组10条数据n <- n_schools * n_per_school
sim_data <- tibble( student_id = 1:n, # 个体ID school_id = rep(1:n_schools, each = n_per_school), # 分组变量 x1 = rnorm(n), # 协变量1 x2 = rbinom(n, 1, 0.5), # 协变量2 x3 = runif(n), # 协变量3)
# 生成随机效应(模拟个体异质性)re <- rnorm(n_schools, 0, 0.8)sim_data$re <- re[sim_data$school_id]
# 生成连续型结果 ysim_data <- sim_data %>% mutate( y = 1.2*x1 + 0.9*x2 + 1.5*x3 + re + rnorm(n, 0, 1) )
# 调用gmerf_rangerfit <- gmerf_ranger( y = "y", # 因变量 data = sim_data, # 数据 gr = "school_id", # 分组变量 fam = gaussian(), # 分布 num.trees = 200 # 随机森林参数)
# 调用预测函数pred <- predict_gmerf( object = fit, newdata = sim_data, gr = "school_id")从上面完整的代码中,我们可以清晰看到GMERF的三个关键优势:
1.随机效应部分——对应组内相关性建模
glmm_fit <- lmer('outcome_tmp ~ 0 + (1 | school_id)', data = rf_df)这行代码通过随机截距捕捉了同一学校(或同一患者)多次测量之间的相关性,这正是GLMM能够正确处理纵向数据结构的关键。
2. 随机森林部分——对应非线性关系捕捉
rf_fit <- ranger(y = rf_df$targ, x = select(rf_df, -targ, ...))随机森林不需要预设函数形式,能自动发现腰臀比、年龄等变量与结局之间的复杂非线性关系和高阶交互作用。
3. 迭代优化机制——两种方法的优势融合
while (it < itmax && !conv) { # 交替优化:随机森林拟合残差 → 混合模型更新随机效应}这个迭代过程确保了模型能够同时优化固定效应的非线性部分和随机效应的组内相关部分。
运行上述代码后,我们可以运行下列代码得出结果:
# 查看模型结构summary(fit)
# 提取变量重要性(对应文献中腰臀比、年龄等核心 predictors)importance <- fit$final_rf$variable.importanceprint(importance)
# 查看随机效应分布(个体异质性)ranef(fit$final_glmm)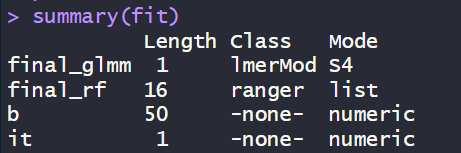

结果解读:GMERF如何兼顾双重优势?
1. 从模型结构看
summary(fit) 显示 b 包含50个数值,对应50个学校的随机效应——每个学校有独特的基线水平,这正是"数据相关性被建模"的直接证据。it=1 表明算法快速收敛。
2. 从预测值看
前10个预测值:0.06, 1.37, 1.96, 0.47, 1.45, 2.13, 1.39, -1.33, -0.76, -0.21
发现了吗?第1-7个全为正,第8-10个全为负。这是因为第1-7个来自随机效应为正的学校,第8-10个来自随机效应为负的学校。
普通RF不会出现这种"整组同号"的模式——这证明了随机效应成功捕捉了组内相关性。
3. 从组内波动看
学校1内部(第1-7个):0.06到2.13,跨度2.07。如果只有随机效应(纯GLMM),同校学生预测值应完全相同。这里的波动正是随机森林捕捉非线性关系所导致的个体差异。
综上所述,随机效应带来"组间差异+组内相似",随机森林带来"个体波动"——两者结合,才是GMERF胜出的原因。
完整代码来自:
https://github.com/Chhr1s/GMERF_Ranger/blob/main/gmerf_ranger_fn.R
最后,在文末给郑老师我们团队打个广告吧,大家不要见怪哈!
我们将提供专业的临床预测模型统计服务哦


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)