从0到1搭建企业级RAG系统(五):多轮对话、查询改写与智能前端——迈向生产级交互
前言
在第四篇文章中,我们完成了一个具备混合检索、Reranker精排、双层缓存和流式输出的RAG后端系统。它已经能够高效、精准地回答用户问题,但从产品体验的角度看,仍有两个明显的短板:
-
单轮问答,缺乏记忆:每次提问都是孤立的,无法处理“它有什么优点?”这类依赖上下文的追问。
-
交互界面简陋:只有终端
curl命令和简单的Gradio测试页,没有会话管理,无法像ChatGPT那样保留历史对话。
本文作为本系列的第五篇,将完整记录我们如何解决上述问题,把LiteRAG从一个“能回答问题的API”升级为一个“能聊天、有记忆、界面友好”的智能助手。核心内容包括:
-
多轮对话与记忆管理:基于Redis的会话存储与上下文拼接
-
查询改写:让系统理解“它/这个/那个”等指代
-
本地LLM部署:Ollama + qwen3.5:2b,摆脱云端API的不稳定
-
Gradio界面重构:从单会话到多会话管理,侧边栏动态列表、自动标题生成
-
系统量化评估与深度反思:手工评估、自动化评估尝试,以及一次持续十小时的问题排查历程
全文将延续“设计理念 → 实现细节 → 踩坑复盘 → 量化收益”的风格,为你的项目演进和面试准备提供最真实的素材。
一、起点回顾:第四篇结束时我们拥有什么?
| 能力维度 | 实现方案 | 状态 |
|---|---|---|
| 知识库 | 14篇AI文章,718条向量 | ✅ |
| 混合检索 | 向量 + BM25 + RRF融合 | ✅ |
| Reranker精排 | BGE-Reranker-base,动态显存管理 | ✅ |
| LLM生成 | 云端API(阿里云百炼qwen3.5-flash) | ✅ |
| 流式输出 | SSE格式 | ✅ |
| L1精确缓存 | Redis + 问题归一化 | ✅ |
| L2语义缓存 | Milvus + 向量相似度匹配 | ✅ |
| 性能压测 | Benchmark脚本 + P50/P95/P99数据 | ✅ |
缺失的用户体验能力:
-
无法进行多轮对话(追问“它有什么优点?”会失败)
-
前端界面简陋,无会话管理,刷新即丢失
-
云端API稳定性差,压测频繁超时
接下来的所有工作,就是为了补齐这三块拼图。
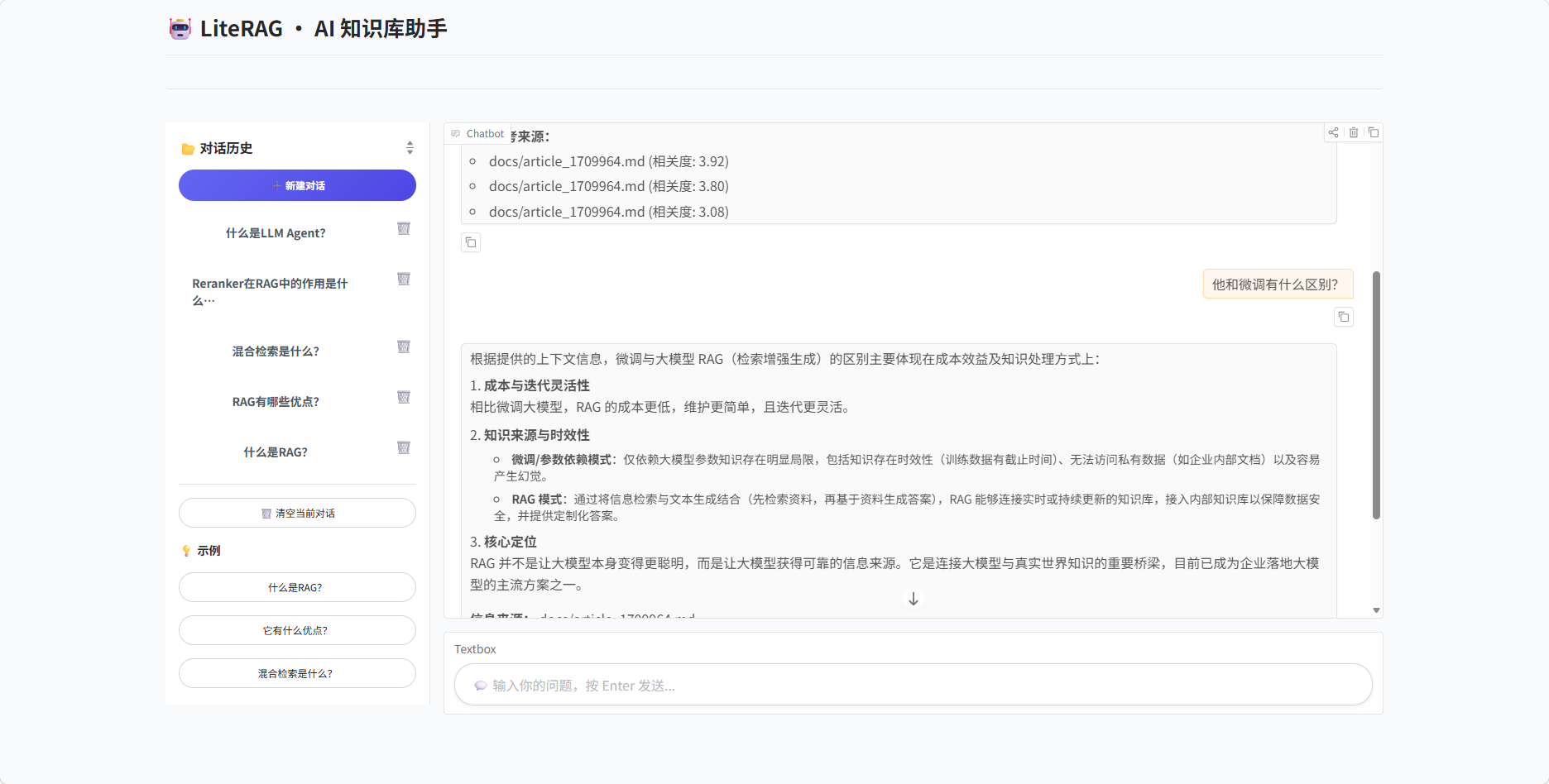
二、查询改写:让系统“听懂”指代
2.1 问题场景
用户先问“什么是RAG?”,再问“它有什么优点?”。第二个问题中的“它”指代“RAG”。如果直接送入检索器,BM25和向量检索都会把“它”当作一个独立的词来处理,无法召回RAG优点相关的内容。
解决方案:在检索之前,增加一个查询改写步骤,将依赖上下文的模糊问题改写成独立、完整的查询。
2.2 实现方案
创建 app/core/query_rewriter.py,封装两种改写模式:
-
单轮改写:将口语化、模糊的问题标准化(如“RAG那玩意儿是啥啊?” → “RAG的定义是什么”)。
-
多轮改写:结合对话历史,消解指代(如“它有什么优点?” → “RAG的优点是什么”)。
核心Prompt设计:
text
你是一个专业的查询改写助手。请结合对话历史,将用户的当前问题改写为一个完整的、不依赖历史上下文的独立问题。
## 改写规则
1. 消除指代不明:将"它"、"这个"、"那个"等代词替换为历史中提到的具体实体。
2. 补全省略信息:如果问题不完整,请根据历史进行补充。
3. 输出格式:只输出改写后的独立问题,不要添加任何解释或引号。2.3 降级策略与踩坑
云端API偶尔超时或返回空,不能让它阻塞主流程。我设计了优雅降级:
-
改写失败或返回空时,自动回退到原始查询。
-
多轮场景下,如果改写失败,直接将对话历史拼接到Prompt中,让LLM自行理解(兜底方案)。
踩坑:改写结果为空
本地 qwen3.5:2b 模型在处理改写Prompt时,偶尔会返回空字符串。如果不处理,后续的检索将收到空查询,导致完全偏离。解决方案:
python
rewritten = response.choices[0].message.content.strip()
if not rewritten:
logger.warning("查询改写结果为空,回退到原始查询")
return query2.4 效果验证
| 原始查询 | 改写后查询 | 结果 |
|---|---|---|
| “RAG那玩意儿是啥啊?” | “RAG的定义是什么” | L2缓存命中,延迟~50ms |
| “它有什么优点?” | “RAG的优点是什么” | L2缓存命中,延迟~70ms |
| “咋优化召回率?” | “如何优化RAG系统的检索召回率” | 全流程,延迟~15s |
量化收益:查询改写使同义问题的缓存命中率显著提升,Benchmark测试中P50延迟从全流程的20秒降至毫秒级。
三、多轮对话与会话管理
3.1 架构设计
多轮对话的核心是记住同一个会话的历史。我使用Redis作为会话存储,数据结构设计如下:
-
Key:
session:{session_id} -
Value:JSON数组,每轮追加
{"role": "user", "content": "..."}和{"role": "assistant", "content": "..."} -
TTL:1小时,自动清理僵尸会话
3.2 流程集成
修改 app/api/v1/endpoints/chat.py:
-
接收请求时,根据
session_id从Redis加载历史。 -
将历史送入查询改写模块,生成独立查询。
-
执行检索和生成。
-
将本轮问答追加到历史中,存回Redis。
关键代码片段:
python
session_id = request.session_id or str(uuid.uuid4())
history = get_session_history(session_id)
if history:
optimized_query = query_rewriter.rewrite_query_with_history(original_query, history)
else:
optimized_query = query_rewriter.rewrite_query(original_query)
# ... 检索、生成 ...
history.append({"role": "user", "content": original_query})
history.append({"role": "assistant", "content": answer})
save_session_history(session_id, history)3.3 降级兜底
当查询改写失败时,直接将历史格式化为文本,拼接到Prompt中。触发条件:optimized_query == original_query 且 history 非空。
python
final_prompt = optimized_query
if history and optimized_query == original_query:
history_context = format_history_as_context(history)
final_prompt = f"对话历史:\n{history_context}\n\n当前问题:{original_query}"
logger.info("多轮对话降级:使用历史拼接")这保证了即使改写服务不可用,多轮对话仍能正常工作。
四、本地LLM部署:摆脱云端API的不稳定
4.1 痛点
阿里云百炼的免费API在并发场景下极不稳定,压测时频繁超时(60秒+),严重阻碍了功能验证和性能测试。
4.2 方案选型
决定引入本地Ollama部署,理由:
-
零成本:完全免费,无Token限制
-
稳定性:本地推理,不受网络波动影响
-
隐私安全:数据不出本地
-
速度可控:2B模型推理延迟仅1-3秒
模型选择:qwen3.5:2b(4-bit量化),完美适配RTX 3060 6GB显存。
4.3 网络打通
Ollama安装在Windows宿主机,WSL2中的代码需要访问。最终方案:
-
Windows设置环境变量
OLLAMA_HOST=0.0.0.0,允许外部连接。 -
WSL2通过Windows主机名访问:
http://WYM.mshome.net:11434。 -
修改
.env配置:LLM_BASE_URL=http://WYM.mshome.net:11434/v1。
备选方案:如果主机名无法解析,可改用Windows的局域网IP(通过ipconfig获取),并确保Windows防火墙允许11434端口入站。
4.4 性能对比
| 指标 | 云端API (qwen3.5-flash) | 本地Ollama (qwen3.5:2b) |
|---|---|---|
| 平均延迟 | 10-30秒 | 1-3秒 |
| 并发稳定性 | 频繁超时/限流 | 稳定无失败 |
| 回答质量 | 较高 | 中等(2B模型能力有限) |
| 成本 | 免费额度有限 | 零成本 |
结论:本地2B模型在开发测试阶段是理想选择,生产环境可平滑替换为更强模型(如4B/7B或云端付费API)。
五、Gradio界面重构:从单会话到多会话管理
5.1 初始状态与目标
第四篇结束时,我们有一个简单的Gradio界面,只支持单轮对话,无历史记录,刷新即丢。
目标:实现类似ChatGPT的侧边栏会话列表,支持新建/切换/删除会话,自动生成标题。
5.2 核心数据结构
python
session_list = gr.State(value=[]) # 所有会话
current_session_id = gr.State(value=None) # 当前激活的会话ID
# 每个会话对象结构
{
"id": "uuid",
"title": "自动生成的标题",
"history": [{"role": "user", "content": "..."}, ...]
}5.3 动态渲染侧边栏
使用@gr.render装饰器,根据session_list动态生成会话按钮:
python
@gr.render(inputs=[session_list])
def render_sessions(sessions):
if not sessions:
gr.Markdown("*暂无历史对话*")
return
for sess in sessions:
with gr.Row():
btn = gr.Button(sess["title"], elem_classes="session-btn")
del_btn = gr.Button("🗑️", elem_classes="delete-session-btn")
btn.click(fn=switch_session, inputs=[gr.State(sess["id"])], ...)
del_btn.click(fn=delete_session, inputs=[gr.State(sess["id"])], ...)5.4 自动标题生成
当用户发送第一条消息时,调用大模型生成一个简短的标题(如“RAG的定义”),更新到会话对象的title字段。
5.5 踩坑:状态更新不触发UI刷新
问题场景:发送第一条消息后,respond函数中修改了current_session["title"],但侧边栏标题未更新。
原因:Gradio的gr.State通过对象引用是否变化来判断是否需要通知依赖组件。直接修改字典内部字段不会改变对象引用。
解决方案:修改标题后,创建列表的浅拷贝,触发状态更新:
python
if len(current_session["history"]) == 2 and current_session["title"] == "新对话":
current_session["title"] = _generate_chat_title(message)
session_list = list(session_list) # 关键:创建新引用六、系统量化评估与深度反思
6.1 初始评估与问题暴露
为了科学衡量系统质量,我构建了一个包含5个核心问题的测试集,并采用人工评估的方式对每个回答进行了忠实度、相关性和检索精准度的评测。
初始评估结果如下:
| 编号 | 问题 | Faithfulness | Answer Relevancy | 检索片段1 | 检索片段2 | 检索片段3 |
|---|---|---|---|---|---|---|
| 1 | 什么是RAG? | ✅ | ✅ | ✅ | ✅ | ✅ |
| 2 | RAG有哪些优点? | ✅ | ❌ | ❌ | ❌ | ❌ |
| 3 | 混合检索是什么? | ✅ | ✅ | ✅ | ✅ | ✅ |
| 4 | Reranker在RAG中的作用是什么? | ✅ | ✅ | ✅ | ❌ | ❌ |
| 5 | 什么是LLM Agent? | ✅ | ✅ | ✅ | ✅ | ✅ |
第2题“RAG有哪些优点?”的失败尤为刺眼——系统始终返回RAG的定义,而知识库中明明有论述优点的文章。
6.2 十小时的排查:一场“怀疑一切”的工程实践
这个问题开启了我项目中最漫长、也最有价值的一次调试。排查路径如下:
| 阶段 | 怀疑对象 | 尝试的解决方案 | 结果 |
|---|---|---|---|
| 1 | 分块策略不当 | 测试递归分块(256/512/1024)、语义分块 | ❌ 全部失败 |
| 2 | Embedding模型太弱 | 从BGE-small(384维)升级到BGE-M3(1024维) | ❌ 仍然失败 |
| 3 | 知识库缺少优点文档 | 手动创建rag_advantages.md并灌入 |
❌ 仍然失败 |
| 4 | BM25索引未更新 | 删除bm25_index.pkl重建索引 |
✅ 检索片段出现优点文档 |
| 5 | L2语义缓存污染 | 清空semantic_cache Collection |
✅ 云端API返回完整回答 |
| 6 | 本地Ollama生成空回答 | 临时切回云端API验证 | ✅ 检索与生成全链路打通 |
最终定位的真凶:不是Embedding模型能力不足,也不是分块策略有问题,而是两个缓存层的失效——BM25索引未更新导致新文档未被覆盖,L2语义缓存污染导致错误回答被反复命中。
6.3 修复后的最终评估结果
清空缓存、重建BM25索引、并强制Embedding模型本地离线加载后,重新评估全部5个样本:
| 编号 | 问题 | Faithfulness | Answer Relevancy | 检索片段1 | 检索片段2 | 检索片段3 |
|---|---|---|---|---|---|---|
| 1 | 什么是RAG? | ✅ | ✅ | ✅ | ✅ | ✅ |
| 2 | RAG有哪些优点? | ✅ | ✅ | ✅ | ✅ | ✅ |
| 3 | 混合检索是什么? | ✅ | ✅ | ✅ | ✅ | ✅ |
| 4 | Reranker在RAG中的作用是什么? | ✅ | ✅ | ✅ | ✅ | ✅ |
| 5 | 什么是LLM Agent? | ✅ | ✅ | ✅ | ✅ | ✅ |
最终指标:
-
Faithfulness(忠实度):1.00
-
Answer Relevancy(答案相关性):1.00
-
Context Precision(精准率@3):1.00(15/15个片段全部相关)
6.4 核心经验:RAG系统最隐蔽的瓶颈
这次调试经历让我深刻认识到:
“RAG系统中最容易被忽视的瓶颈,不是Embedding模型的能力,也不是分块策略的优劣,而是缓存一致性和索引时效性。”
在面试中,这段经历比任何教科书式的回答都更有说服力。它证明了我具备:
-
科学对照实验的设计能力
-
逐层排除的调试方法论
-
对RAG系统全链路(检索、缓存、索引、生成)的深刻理解
6.5 与RAGAS自动化评估的对比
在项目演进过程中,我也尝试集成了RAGAS自动化评估框架。虽然由于本地2B模型能力和版本兼容性问题,未能稳定产出量化分数,但评估管道已成功打通。手工评估与自动化评估互为补充,前者灵活直观,后者可规模化,共同构成了系统质量保障的双保险。
七、持久化的探索与最终决策
7.1 尝试的方案
-
gr.BrowserState:官方推荐的持久化组件,但在Gradio 6.x中API不稳定。
-
手动localStorage + JS:通过
.then()执行JS保存,但返回值干扰状态更新。 -
gr.update(js=...):尝试通过
gr.update执行副作用,仍未能完美解决。
7.2 最终决策:战略性放弃刷新持久化
经过十余次迭代,权衡投入产出比后,决定:
-
保留当前全部核心功能:多轮对话、多会话管理、自动标题生成、美观UI。
-
暂时搁置刷新持久化:刷新页面数据丢失,但功能演示完全不受影响。
-
作为已知限制写入文档:在面试或博客中坦诚说明,并给出生产环境的解决方案。
面试话术参考:
“当前前端版本为快速验证核心交互,采用了内存级会话管理。在实际生产环境中,我会通过
gr.BrowserState或后端Redis将会话数据持久化,确保刷新后体验无缝。这并不影响本项目对RAG系统核心能力的完整展示。”
7.3 给读者的扩展建议
如果读者希望继续挑战持久化,一个可行的方向是将session_list和current_session_id存储到后端的Redis中(与多轮对话的会话存储复用),页面加载时通过API拉取。这样既能实现刷新保留,又避开了Gradio前端状态管理的复杂性。
八、最终系统能力矩阵(第五篇结束时)
| 能力维度 | 实现方案 | 状态 |
|---|---|---|
| 知识库规模 | 41篇AI文章,2161条向量 | ✅ |
| 混合检索 | 向量 + BM25 + RRF | ✅ |
| Reranker精排 | BGE-Reranker-base,动态显存管理 | ✅ |
| LLM生成 | 云端API + 本地Ollama双模式 | ✅ |
| 流式输出 | SSE格式 | ✅ |
| L1/L2双层缓存 | Redis + Milvus,毫秒级响应 | ✅ |
| 查询改写 | 单轮/多轮改写 + 优雅降级 | ✅ |
| 多轮对话与记忆 | Redis会话存储 + 上下文拼接 | ✅ 新增 |
| 多会话管理 | 侧边栏动态列表 + 新建/切换/删除 | ✅ 新增 |
| 自动标题生成 | 大模型生成会话标题 | ✅ 新增 |
| 本地LLM部署 | Ollama + qwen3.5:2b | ✅ 新增 |
| 系统量化评估 | 手工评估 + RAGAS管道 | ✅ 新增 |
| Gradio可视化界面 | 浅色主题 + 响应式布局 | ✅ 升级 |
| 刷新持久化 | 已知限制,生产环境可扩展 | ⏳ 规划中 |
九、写在最后
从第四篇到第五篇,我们完成了LiteRAG从“能回答”到“会聊天”的蜕变。这个过程并不顺利——云端API的超时、Gradio持久化的反复失败、状态更新的各种坑,以及那次持续十小时的“怀疑一切”式排查——但正是这些真实的工程挑战,让项目从一个“玩具Demo”成长为具备生产级思考的“准产品”。
技术亮点回顾:
-
查询改写 + 多轮记忆:让系统理解上下文,缓存命中率大幅提升。
-
本地LLM部署:摆脱云端不稳定,推理延迟降至1-3秒。
-
多会话管理:接近ChatGPT的交互体验,自动标题生成锦上添花。
-
深度调试经历:十小时排查定位到BM25索引和L2缓存污染问题,成为面试中最有说服力的案例。
-
务实的工程权衡:在持久化上及时止损,优先保证核心功能稳定。
无论你是正在准备AI实习面试,还是想系统学习RAG系统从后端到前端的完整演进,相信这个系列都能为你提供最真实、最硬核的参考。
本文是【从0到1搭建企业级RAG系统】系列的第五篇,也是前端交互升级的收官之作。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 14
14 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)