WSL 下 llama.cpp CUDA 编译血泪史:从 Wsl/Service/E_UNEXPECTED 到成功
【摘要】
最近在 WSL 2 环境下编译 llama.cpp 并启用 CUDA 加速时,遇到了一系列连环报错:从 WSL 服务崩溃 (Wsl/Service/E_UNEXPECTED),到 GCC 与 CUDA 版本不兼容导致的 _Float64 类型未定义错误。本文完整记录了从环境修复、版本统一、编译器降级到最终成功编译的全过程。如果你也正被这些问题困扰,希望这篇实战记录能帮你节省大量时间。
一、问题背景
我的环境配置:
- 硬件:NVIDIA GeForce RTX 2080 Ti
- Windows 驱动:536.23(支持 CUDA 12.2)
- WSL 发行版:Ubuntu 24.04
- 目标:编译 llama.cpp 并启用 CUDA 后端
一开始一切顺利,直到执行 cmake .. -DGGML_CUDA=ON 后,噩梦开始了。
二、踩坑全记录
坑 1:WSL 服务崩溃
$ wsl
灾难性故障
错误代码: Wsl/Service/E_UNEXPECTED

原因分析:WSL 后台服务卡死或组件损坏。
解决方案:
# 以管理员身份在 PowerShell 中执行
wsl --shutdown
wsl --update # 修复 WSL 组件

如果问题依旧,可以尝试修复注册表权限或运行 DISM /Online /Cleanup-Image /RestoreHealth。
坑 2:CUDA 版本不一致
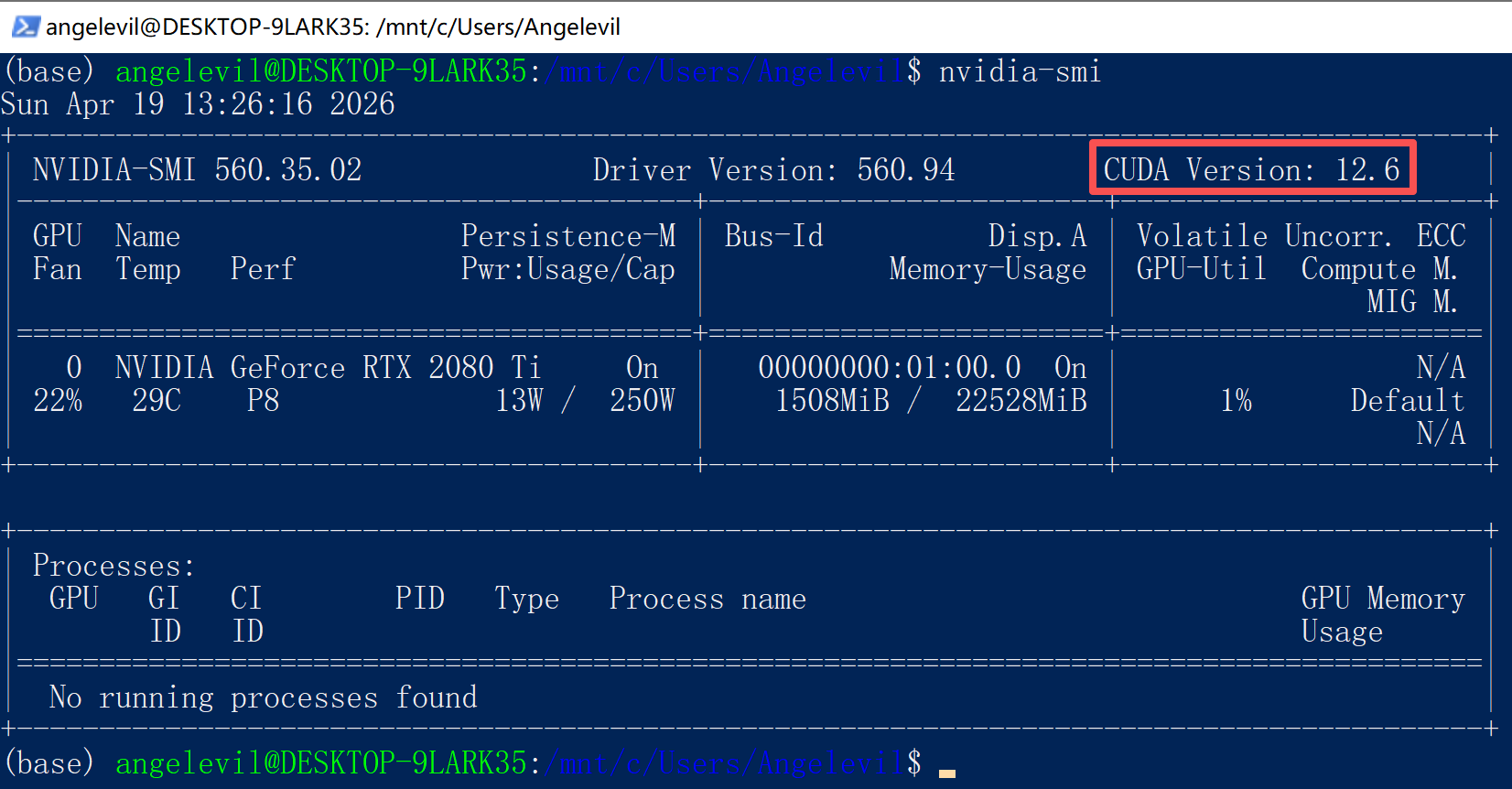
$ nvidia-smi # 显示 CUDA Version: 12.2
$ nvcc --version # 显示 release 12.9
原因分析:驱动支持的最高 CUDA 版本是 12.2,但 nvcc 是 12.9,版本不匹配会导致编译出的二进制可能无法执行。
解决方案:降级 CUDA 工具包到 12.2,或升级 Windows 驱动。我选择了降级:
# 卸载旧版本
sudo apt remove --purge nvidia-cuda-toolkit
# 安装 CUDA 12.2(从 NVIDIA 官网下载)
wget https://developer.download.nvidia.com/compute/cuda/12.2.0/local_installers/cuda_12.2.0_535.54.03_linux.run
sudo sh cuda_12.2.0_535.54.03_linux.run --toolkit
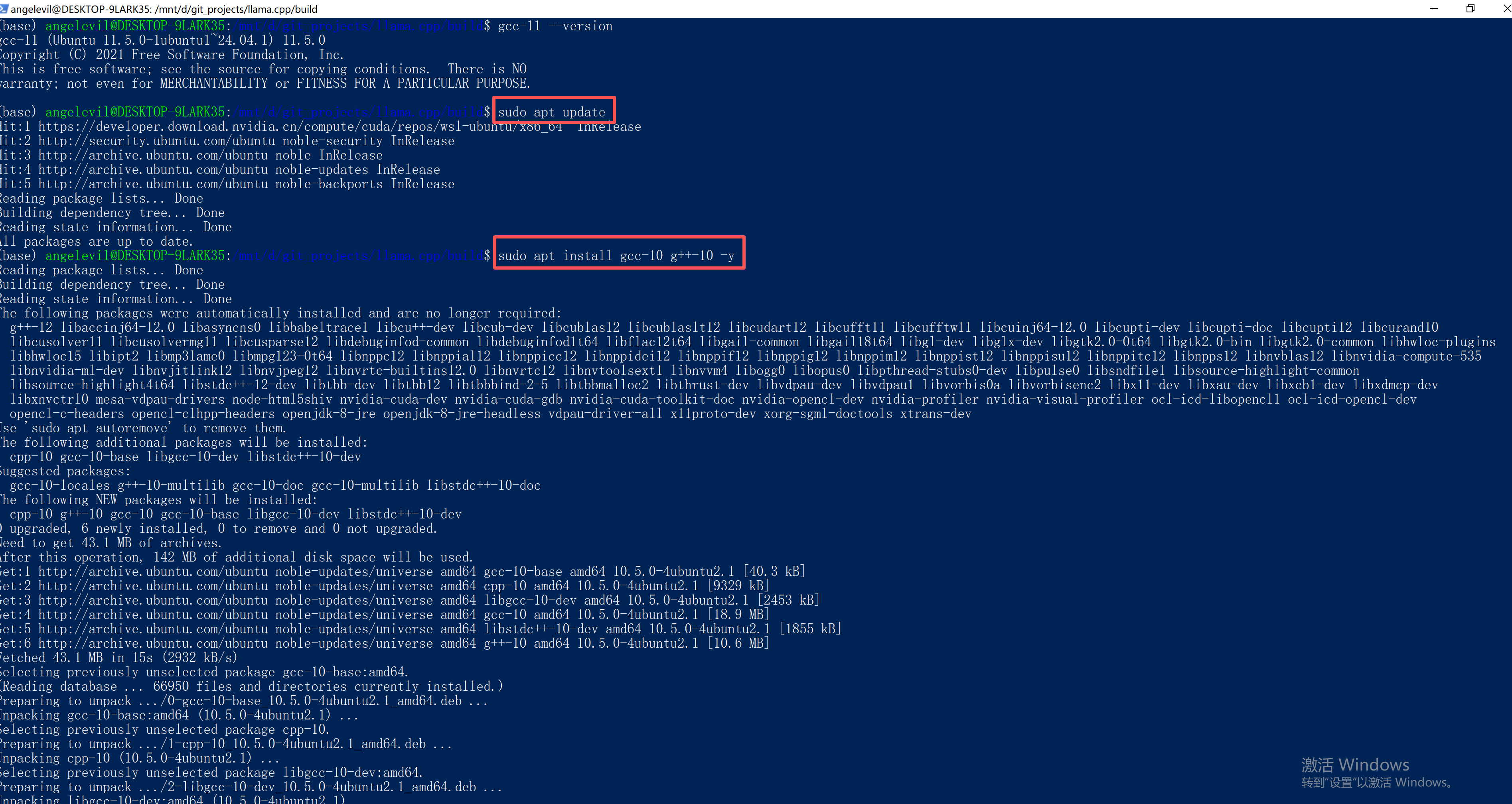
坑 3:GCC 版本不兼容
# error: #error -- unsupported GNU version! gcc versions later than 12 are not supported!
原因分析:我的 GCC 是 13.3,而 CUDA 12.2 官方只支持到 GCC 12。
解决方案:降级到 GCC 10(最稳妥):
sudo apt install gcc-10 g++-10
gcc --version

坑 4:nvcc 仍调用系统默认 GCC
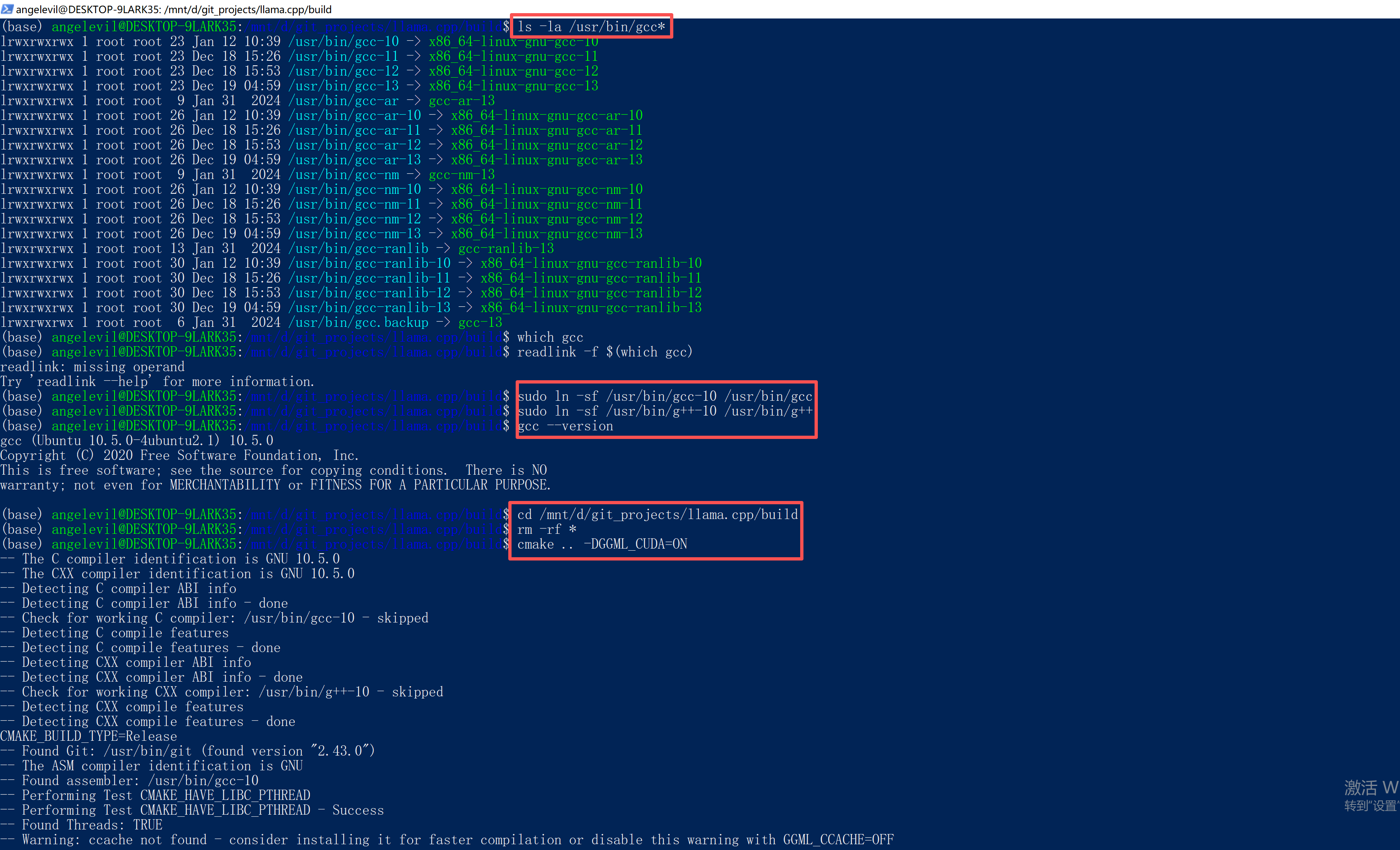
即使设置了 CC=/usr/bin/gcc-10,nvcc 仍然调用的是 gcc 命令(指向 GCC 13)。
解决方案:创建软链接强制使用 GCC 10:
sudo ln -sf /usr/bin/gcc-10 /usr/bin/gcc
sudo ln -sf /usr/bin/g++-10 /usr/bin/g++
坑 5:_Float64 类型未定义
编译过程中出现大量类似错误:
error: ‘_Float64’ does not name a type; did you mean ‘_Float16’?
error: ‘_Float128’ was not declared in this scope
原因分析:这是 GCC 13 + CUDA 12.9 + glibc 2.40 头文件冲突的连锁反应。降级到 GCC 10 后该问题自动消失。
三、最终成功配置
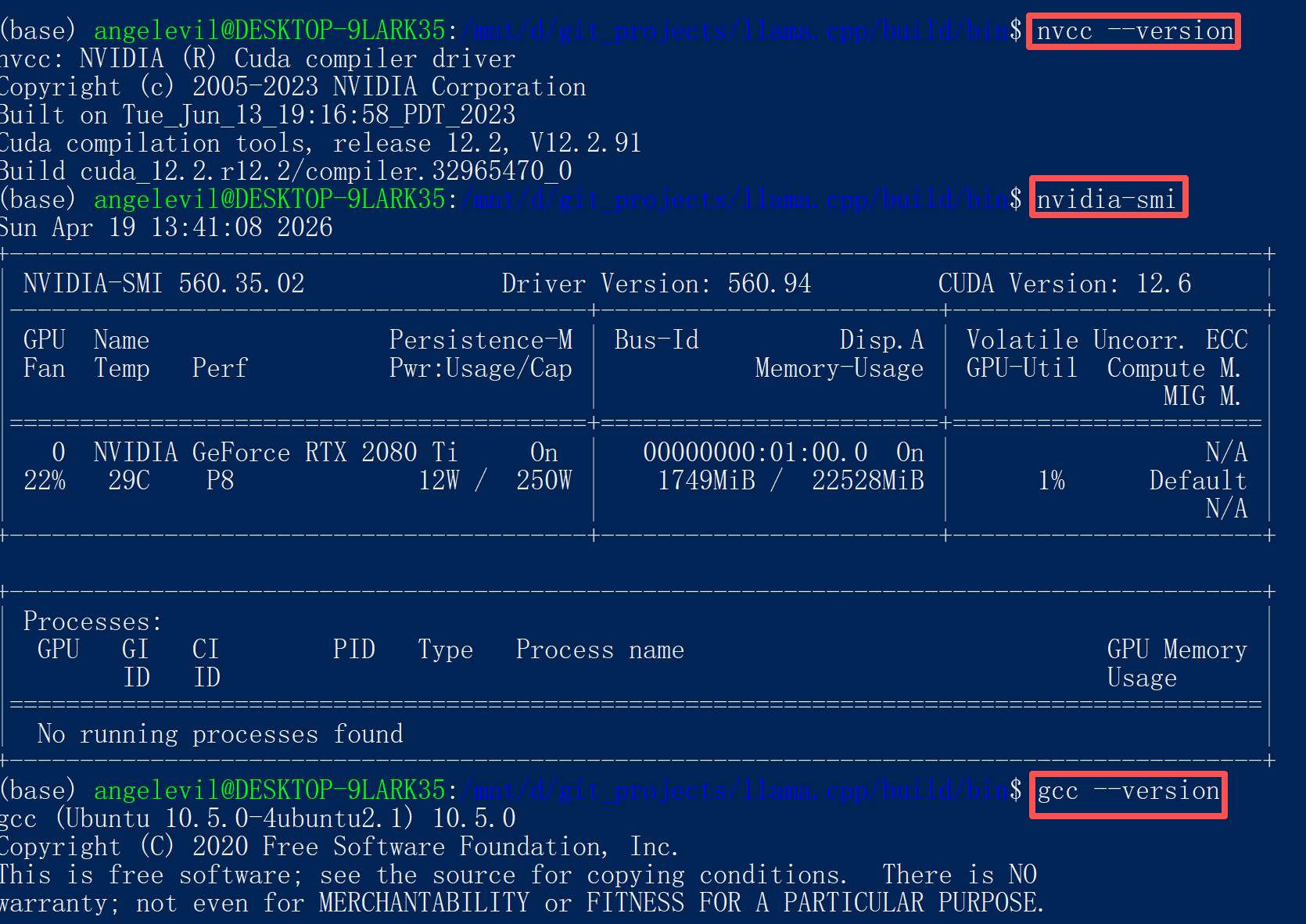
# 检查环境
$ gcc --version
gcc (Ubuntu 10.5.0-4ubuntu2.1) 10.5.0
$ nvcc --version
Cuda compilation tools, release 12.2, V12.2.91
$ nvidia-smi | grep CUDA
CUDA Version: 12.2
四、重新编译
cd /mnt/d/git_projects/llama.cpp/build
rm -rf *
cmake .. -DGGML_CUDA=ON
make -j4
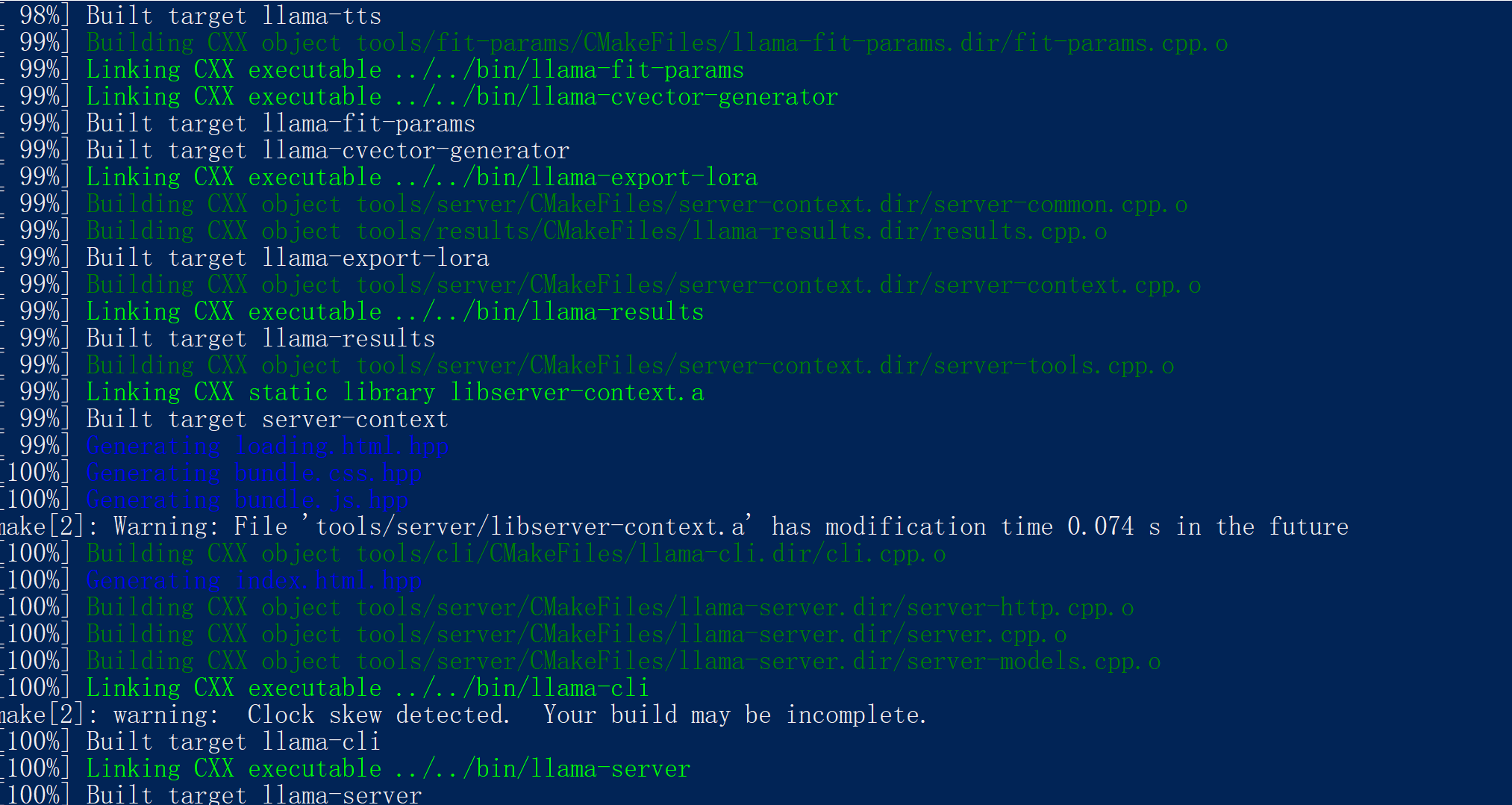
最终输出:
[100%] Built target llama-server
[100%] Built target llama-cli

✅ 编译成功!
五、经验总结
| 问题 | 解决方案 |
|---|---|
| WSL 服务崩溃 | wsl --shutdown + wsl --update |
| CUDA 版本不匹配 | 统一到驱动支持的版本(12.2) |
| GCC 版本过高 | 降级到 CUDA 官方支持的版本(GCC 10) |
| nvcc 编译器路径错误 | 创建 /usr/bin/gcc 软链接指向正确版本 |
六、避坑建议
- 版本统一是王道:
nvcc --version和nvidia-smi显示的 CUDA 版本必须一致或前者≤后者。 - 不要追新 GCC:CUDA 对宿主编译器版本要求苛刻,GCC 10 是万金油选择。
- 软链接优于环境变量:
nvcc硬编码调用gcc,修改PATH或CC不一定有效。 - 遇到
_Float64错误:99% 是 GCC 版本问题,降级即可。
写在最后
编译一个开源项目,踩坑是常态,但每一次排错都是成长。希望这篇记录能帮你少走弯路。如果你有更好的解决方案,欢迎评论区交流!
祝大家编码顺利,永不报错! 🚀
本文标签: #WSL #CUDA #llama.cpp
本文为原创内容,版权归作者所有,转载需注明出处。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐
 15
15 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)